




- @AI_OCR
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
媒资系统是媒体机构用于存储、管理、检索和分发音视频、图片、文本等数字资产的核心平台。
摘要:电信运营商在政策监管下亟需智能化身份核验方案。人脸核身技术通过计算机视觉、活体检测等实现"人证合一"验证,具备三大优势:安全合规(冒用率降低99.7%)、效率提升(核验时间从3分钟缩短至5秒)、体验优化(远程开卡率达65%)。核心技术包括四维检测(质量/活体/比对/OCR)及四大亮点(多模态决策/边缘计算/自适应风控/可视化审计)。该技术可延伸至金融、政务等领域,预计实施
藏语OCR技术面临文字结构复杂、历史档案退化、技术基础薄弱等难点。解决方案包括:预处理阶段的自适应二值化、核心识别技术的改进CRNN网络、后处理的藏语语言模型校正等。针对档案馆场景,设计了从数字化扫描到结构化存储的完整工作流程,通过迁移学习、数据增强等方法优化性能。当前主要挑战包括数据标注不足、垂直结构识别困难等,应用场景涵盖古籍数字化、档案检索系统等。未来发展方向将聚焦多模态融合、知识图谱构建等
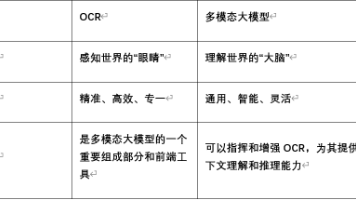
深度学习OCR与多模态大模型在媒资管理中的应用对比显示:OCR擅长精准提取图像文字,适合低成本文本化需求;而多模态大模型能实现跨模态语义理解、智能搜索等高级功能,但成本较高。实际应用中,建议采用分层架构,底层用OCR等专业模型处理基础特征,上层通过多模态大模型进行深度语义分析,分阶段实现从文本识别到智能理解的演进。两者不是替代关系,而是互补的技术组合。
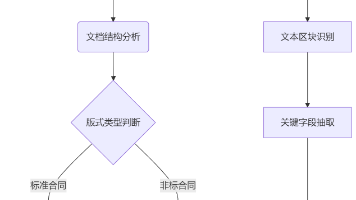
智能合同文本抽取技术方案解析 摘要:针对合同文档版式多样、条款复杂的特点,智能文本抽取技术采用多级解析流程:1)通过LayoutLMv3和OpenCV处理混合排版;2)运用BiLSTM-CRF和法律知识图谱识别专业术语;3)构建规则引擎验证条款逻辑。典型应用包括金融机构贷款审核(效率提升20倍)和跨国合同管理(谈判周期缩短60%)。前沿探索涉及LawGPT摘要生成和区块链存证,准确率达99.3%。
摘要:为解决医药行业资质审核中的文件格式多样、信息非结构化、规则复杂等问题,本方案提出基于AI技术的自动化审核系统。系统采用分层架构,通过OCR识别、NLP信息抽取、动态规则引擎等技术实现全流程自动化处理,能高精度提取关键字段并进行多维度校验,将审核时间从小时级缩短到分钟级,准确率提升至95%以上。系统支持规则动态配置和持续优化,形成完整的电子审计轨迹,有效提升审核效率、降低风险并确保合规性。
摘要:现代毕业证OCR技术通过深度学习与NLP结合实现高效识别,主要流程包括图像预处理、文本检测、文本识别和关键信息结构化处理。该技术广泛应用于招聘、教育、政务、金融等多个领域,能自动提取姓名、学校、专业等关键信息并转换为结构化数据。典型应用场景包括企业招聘学历审核、留学申请、政务服务和信贷评估等,显著提升信息处理效率,减少人工录入错误,改善用户体验,推动数字化服务升级。
智能文本抽取技术通过NLP、OCR和机器学习,实现对非结构化订单文档的自动化处理。核心技术包括OCR预处理、基于规则和机器学习的信息抽取(如BERT-CRF、LayoutLM模型),以及后处理校验。系统架构涵盖预处理、抽取引擎和结构化输出模块,应用于电商、供应链、财务票据等场景,处理效率提升50-100倍,准确率达95%以上。未来将向小样本学习、多模态大模型和RPA集成等方向发展,推动企业数字化转
少数民族OCR技术助力民族文化传承与数字化转型。该技术针对55个少数民族文字开发,需解决字符形态复杂、书写方向多样等特殊挑战。核心技术包括多方向文本检测、深度特征提取、语言模型优化等创新方案,在政务数字化、教育文化、金融服务等领域发挥重要作用。尽管面临资源匮乏、混合文本等挑战,但通过迁移学习、动态词典等创新方法,在藏文经书数字化、维汉双语票据识别等场景已取得显著成效。未来将向大模型适配、多模态融合
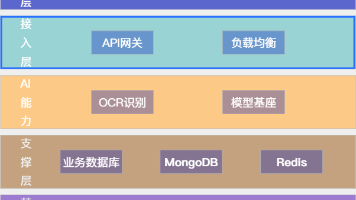
【摘要】智能文档处理(IDP)技术正从单纯字符识别向语义理解跃迁,其技术栈包含四层架构:基础层处理文档采集与预处理;核心层采用AI模型实现文档分类与信息提取,涵盖规则驱动、机器学习及前沿的大语言模型应用;协同层构建人工反馈闭环;输出层提供系统集成方案。技术选型需根据文档结构化程度,选择模板驱动、预训练模型微调或LLM方案。当前主流平台包括Azure、Google等云服务,以及ABBYY等专业OCR