




- @2601_94959365
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
库已提供基础支持,但需要注意该库的 ArkTS 版本已停止维护,建议使用 CAPI 版本(react-native-svg-capi)以获得更好的兼容性和性能。,按出现频率排序,问题现象贴合开发实际,解决方案均为「一行代码/简单配置」,所有方案均为鸿蒙端专属最优解,也是本次代码能做到。基于本次的核心路径描边动画代码,结合 RN 的内置能力,可轻松实现鸿蒙端开发中。的核心原因,零基础可直接套用,彻底
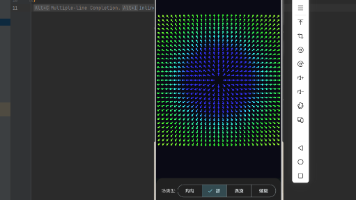
矢量场是空间中每一点都关联一个矢量的数学对象。在物理学中,矢量场用于描述流体流动、电磁场、引力场等不可见的力量。矢量场定义:矢量场示意:📐 1.2 流线与轨迹流线是矢量场中的曲线,其切线方向处处与场矢量方向一致。流线方程:轨迹与流线:🔬 1.3 典型流场类型基本流场:组合流场:流场示意:🎯 1.4 流场可视化方法主要可视化技术:🔧 二、流场可视化的 Dart 实现🧮 2.1 矢量场类⚡
本篇文章深入探讨了德劳内三角剖分的数学原理及其在 Flutter 中的可视化实现。

// 自定义计数器通知});/// 自定义表单验证通知});/// 自定义登录状态通知userName;});/// 使用示例@overrideappBar: AppBar(title: const Text('自定义 Notification')),SnackBar(${action/// 自定义计数器通知 class CounterNotification extends Notificati
flutter_tts 是一个功能强大的文字转语音(TTS)插件,支持将文本转换为语音输出。无论是无障碍应用、语音播报、导航提示还是教育类应用,flutter_tts 都能提供高质量的语音合成能力。flutter_tts 是一个功能强大的文字转语音插件,在 OpenHarmony 平台的适配已经非常成熟。FlutterTts 的核心 API 和使用方法文字转语音的完整流程语速、音调、音量的调节方法
webview_flutter 是 Flutter 官方维护的 WebView 插件,允许在 Flutter 应用中嵌入原生 WebView 组件。无论是展示网页内容、集成第三方服务、还是实现混合开发,webview_flutter 都是最核心的解决方案。webview_flutter 是 Flutter 生态中最常用的 WebView 插件,在 OpenHarmony 平台的适配已经非常成熟。w
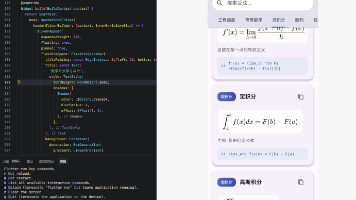
是一个强大的 LaTeX 数学公式渲染库,能够将 LaTeX 格式的数学公式转换为 Flutter 界面组件。该库基于 KaTeX 引擎,支持绝大多数 LaTeX 数学语法,为教育类应用、学术工具、科学计算器等提供了完整的数学公式显示能力。在 OpenHarmony 环境下,渲染 LaTeX 格式的数学公式支持行内公式和独立公式两种模式支持公式选择和复制功能支持公式自动换行支持自定义样式和错误处理
功能说明数据存储支持 bool、int、double、String、List 五种数据类型数据读取提供类型安全的读取方法数据删除支持单条删除和清空所有数据异步操作所有操作均为异步,不阻塞主线程是 Flutter 应用开发中不可或缺的轻量级存储方案。通过本文的"应用设置中心"示例,我们展示了如何在实际应用中使用该库进行数据持久化。无论是主题切换、字体调节,还是搜索历史管理,都能提供简单高效的解决方案
本篇文章深入探讨了元胞自动机在音乐可视化中的应用,从康威生命游戏到音频驱动的演化规则,构建了具有"生命感"的动态网格动画效果。
video_player 是 Flutter 官方维护的视频播放插件,提供跨平台的视频播放能力,支持网络视频、本地文件视频和 Asset 资源视频。无论是短视频应用、在线教育平台还是多媒体内容展示,video_player 都是最核心的解决方案。video_player 是 Flutter 生态中最常用的视频播放插件,在 OpenHarmony 平台的适配已经非常成熟。VideoPlayerCon
