




- @2503_93566956
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
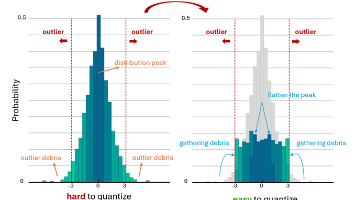
由于INT4表达能力有限,以及大模型激活异常值分布显著,大模型W4A4 INT4量化面临严峻的精度损失风险。本文分析了旋转量化的数学原理,并提出了基于分布转换的旋转量化算法(DartQuant),通过激活数据分布的平坦化,可有效降低W4A4量化误差。
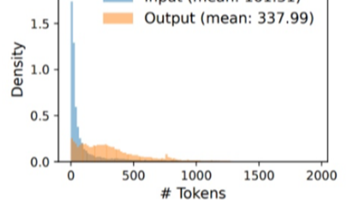
我们在2025年9月,基于vllm ascend框架,部署Qwen3-235B模型,对某企业的推理场景进行了性能调优(Attn:DP4TP4),性能达到0.94~1.87倍H800(Attn:TP16)。在这之后,基于Qwen3-235B模型上的调优经验,在Qwen3-30B上进行了类似配置下的测试,但vllm ascend(Attn:DP4)性能仅在0.6~0.7倍H800(Attn:TP4)。
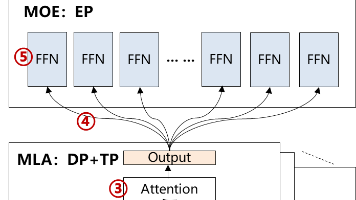
摘要:随着大模型规模扩展和多模态应用发展,模型压缩技术面临新挑战。传统深度学习时代采用量化、剪枝等技术压缩10M-100M级模型,而大模型时代需针对LLM推理特性(Prefill计算密集、Decode访存密集)发展新型压缩方法。当前关键技术包括:1)权重量化(AWQ、GPTQ)降低访存开销;2)KVCache压缩(RazorAttention、KVQuant)优化序列处理;3)稀疏化技术(Spar
由于INT4表达能力有限,以及大模型激活异常值分布显著,大模型W4A4 INT4量化面临严峻的精度损失风险。本文分析了旋转量化的数学原理,并提出了基于分布转换的旋转量化算法(DartQuant),通过激活数据分布的平坦化,可有效降低W4A4量化误差。
摘要:随着大模型规模扩展和多模态应用发展,模型压缩技术面临新挑战。传统深度学习时代采用量化、剪枝等技术压缩10M-100M级模型,而大模型时代需针对LLM推理特性(Prefill计算密集、Decode访存密集)发展新型压缩方法。当前关键技术包括:1)权重量化(AWQ、GPTQ)降低访存开销;2)KVCache压缩(RazorAttention、KVQuant)优化序列处理;3)稀疏化技术(Spar
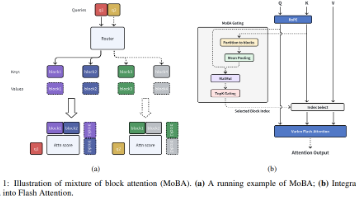
自上半年幻方发表NSA以来,原生稀疏Attention开始进入大众视野,直到十一之前DeepSeek-V3.2发布了DSA(DeepSeek Sparse Attention),原生稀疏Attention正式掀起应用热潮,当前已成为模型结构设计的重要考虑因素,然而稀疏Attention的未来趋势是block-wise还是token-wise稀疏,仍存在未知的发展可能,有待更进一步的检验。
由于INT4表达能力有限,以及大模型激活异常值分布显著,大模型W4A4 INT4量化面临严峻的精度损失风险。本文分析了旋转量化的数学原理,并提出了基于分布转换的旋转量化算法(DartQuant),通过激活数据分布的平坦化,可有效降低W4A4量化误差。