- @2401_84208172
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: AI Agent赛道火爆,但新手常被专业术语(如function call、RAG等)困扰,学习资料分散难成体系。本文分享一套系统化的AI Agent学习文档,包含三大阶段、26个核心问题拆解,从理论到实践全覆盖,助零基础者掌握智能体底层逻辑与搭建技能。配套完整大模型学习资源免费提供,适合所有想入局AI领域的学习者。

摘要: AI Agent赛道火爆,但新手常被专业术语(如function call、RAG等)困扰,学习资料分散难成体系。本文分享一套系统化的AI Agent学习文档,包含三大阶段、26个核心问题拆解,从理论到实践全覆盖,助零基础者掌握智能体底层逻辑与搭建技能。配套完整大模型学习资源免费提供,适合所有想入局AI领域的学习者。
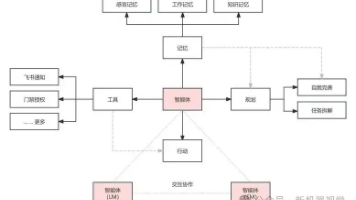
AI智能体(Agent)是基于大语言模型(LLM)的自主系统,由感知、决策、行动三大模块构成,具备任务分解、规划执行和工具调用能力。其核心在于Planning机制,采用思维链(COT)、思维树(TOT)等方法进行任务拆解,并通过ReAct等框架实现动态反思优化。AI Agent分为单Agent、多Agent等类型,优势包括自然交互和场景适应力,但存在可靠性不足、法律风险等局限。随着LLM技术的发展
随着 AI 技术不断成熟,智能体(AI Agent)的开发正经历一场“平民化”变革——就像建站从手写代码演进到使用 WordPress、Wix 等可视化工具一样,如今构建智能体也有了图形化、模块化的低代码平台。这些工具让我们得以跳过繁琐的技术实现,直接聚焦于核心业务逻辑与应用场景。本文将深入解析 Dify、n8n 和 Coze 这三大主流平台的功能特点、适用场景与差异,并提供实用的选型建议,助你高
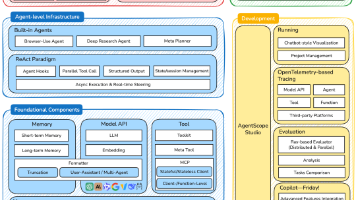
摘要:本文系统梳理了AI智能体开发框架的核心价值与主流工具选型。智能体框架通过封装通用功能(如状态管理、工具调用等)显著提升开发效率,实现模块化解耦。重点对比了四种代表性框架:AutoGen(对话驱动协作)、AgentScope(易用多智能体平台)、CAMEL(角色扮演协作)和LangGraph(图结构工作流),分析各自设计理念与技术路径。以AutoGen 0.7.4为例,详细阐述其分层架构、异步
企业级AI Agent(智能体)发展与应用前景 AI Agent正引领新一轮生产力革命,从内容生成迈向自主决策与任务执行的智能伙伴时代。报告揭示了2025年"Agent元年"的机遇与挑战,探讨了其在中国数字化场景中的落地路径。通过70余页的深度调研,报告系统梳理了AI Agent的核心概念、技术架构及企业级应用价值,覆盖智能客服、数据分析、流程优化等场景,并附实践案例与行业解决

文章解析企业级AI Agent工程化落地的四大核心趋势:MCP统一连接层、GraphRAG精准知识响应、AgentDevOps可控可靠、RaaS价值可衡量。介绍了营销运营、招聘HR等场景落地标准,以及从连接协议到结算口径的自检清单。AI Agent正从"工具"向"岗位专家"演进,通过工业化数据体系和强化学习优化,最终实现人机共存新生态。

谈到大模型,几乎人人都在讨论 AI Agent。但是大部分的现实情况都是,大家接到需求后,兴致勃勃的上手各种新兴的技术和框架:RAG、MCP、ReAct、LangChain 等等,很快就实现了一个非常 Fancy 的 Demo,演示效果非常好。但投入生产之后在初期会有一些用户很好奇,会尝试使用,流量还不错,但之后就是用户不断流失,直到无人问津。
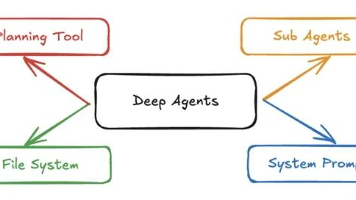
本文介绍了基于LangGraph构建的深度智能体(Deep Agents)框架,通过规划工具、子智能体系统和虚拟文件系统,使AI智能体能预先思考、分解任务、创建待办事项并生成子智能体。文章详细展示了如何使用deepagents库构建研究智能体,包括环境准备、组件定义和执行流程。深度智能体适合处理复杂任务,对于简单任务则建议使用简单智能体或LLM。
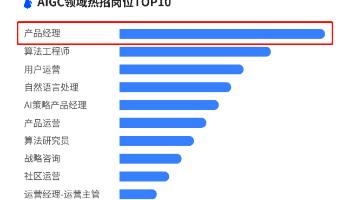
AI 相关的人才缺口已达 500 万,其中AI产品经理需求旺盛,薪资中位数再创新高,36k/月。如果是在头部公司,加上年终奖、项目奖金和期权等,一年50W不是梦想!随着Ai在不同业务场景中价值体现,AI产品经理岗位要求也越发细分,B端方向成为主阵地。不少人十分心动,没有吃上移动互联网的红利,这波AI红利一定不能再错过啦。