




- @2302_80464577
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
说明:由华南理工大学五人团队设计开发的3D水果切割游戏,目前未进行游戏打包发布,只能在Unity游戏引擎内编译运行体验,当前版本v1.0。本文基于原项目报告改版而成,原版本系5人共同写作完成。本文是关于该游戏项目开发的更详细的技术分享,同时包括一些项目的开发日志。
本篇博文实验内容参考自MIT实验课程:**16-825 Assignment 1: Rendering Basics with PyTorch3D (Total: 100 Points + 10 Bonus)**,素材相同,但是结合笔者自己的经验做了详细的讲解,还加入了一些内容的修改和创新。

说明:(1)本人挑战手写代码验证理论,获得一些AI工具无法提供的收获和思考,对于一些我无法回答的疑问请大家在评论区指教;(2)本系列文章有很多细节需要弄清楚,但是考虑到读者的吸收情况和文章篇幅限制,选择重点进行分享,如果有没说清楚或者解释错误的地方欢迎在评论区提出;(3)由于许多内容来自本人课程报告,要求用英文撰写,这里就不翻译成中文了;同时提出了不同的代码实现方案和分析思路。本篇文章主要分析全连

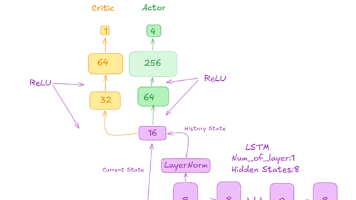
本篇文章记录笔者和其团队在完成Gym库(OpenAI发布)的LunarLander-v2地图时,基于传统强化学习算法Actor-Critic架构以及TD(1)时序差分算法(offline-learning)、epsilon-greedy策略、MBGD+AdamW训练(学习率恒定)的实战,通过迁移性的架构设计(FFN、LSTM)和超参数调优,取得了连续100轮均分+104.38分的成果。另外,动作比
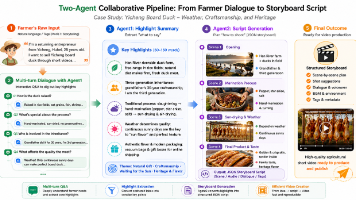
“农心向荣”项目和项目团队将智能体系统和原创复合微调技术与农产品视频创作赛道紧密结合,搭建NiceGUI-FastAPI Python一体化前后端系统,用户只需按照既定创作流程,描述清楚自己的创作需求,一键到底,强大的AI助手就能为你生成定制化的、片段级别的、从画面音频到多人物台词设计的、可能爆款的——视频拍摄建议(支持返稿和修改)!目前版本v1.0,GitHub&B站&CSDN同步转播,版本迭代
本篇文章讲一讲机器学习和深度学习模型算法常用的交叉熵损失,它的变形,以及常见应用场景和pytorch的代码适配情况(部分),很多都是自己做实践做项目和学习过程中的心得总结与经验分享,希望大家认真阅读。

最近在学习文本预处理(分词与词和位置嵌入)、自注意力机制(Self-Attention)、多头自注意力机制、Transformer Block和GPT-2、GPT-3的基本架构。本文是相关内容的第一篇文章,主要讲解大模型的基础架构和代码构建过程。

说明:(1)本人挑战手写代码验证理论,获得一些AI工具无法提供的收获和思考,对于一些我无法回答的疑问请大家在评论区指教;(2)本系列文章有很多细节需要弄清楚,但是考虑到读者的吸收情况和文章篇幅限制,选择重点进行分享,如果有没说清楚或者解释错误的地方欢迎在评论区提出;(3)由于许多内容来自本人课程报告,要求用英文撰写,这里就不翻译成中文了;同时提出了不同的代码实现方案和分析思路。本篇文章主要分析全连
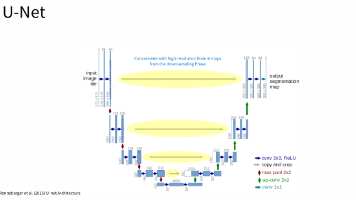
The project reconstructs UNet model(proposed in 2015) by hand, training and evaluating the model on ISIC-2017 challenge dataset in order to: (1)Well master the architecture and principle of UNet and b
说明:(1)本人挑战手写代码验证理论,获得一些AI工具无法提供的收获和思考,对于一些我无法回答的疑问请大家在评论区指教;(2)本系列文章有很多细节需要弄清楚,但是考虑到读者的吸收情况和文章篇幅限制,选择重点进行分享,如果有没说清楚或者解释错误的地方欢迎在评论区提出;(3)由于许多内容来自本人课程报告,要求用英文撰写,这里就不翻译成中文了;同时提出了不同的代码实现方案和分析思路。本篇文章主要分析全连