
写文章




- @2301_77141825
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【论文阅读笔记】What does CLIP know about a red circle? Visual prompt engineering for VLMs
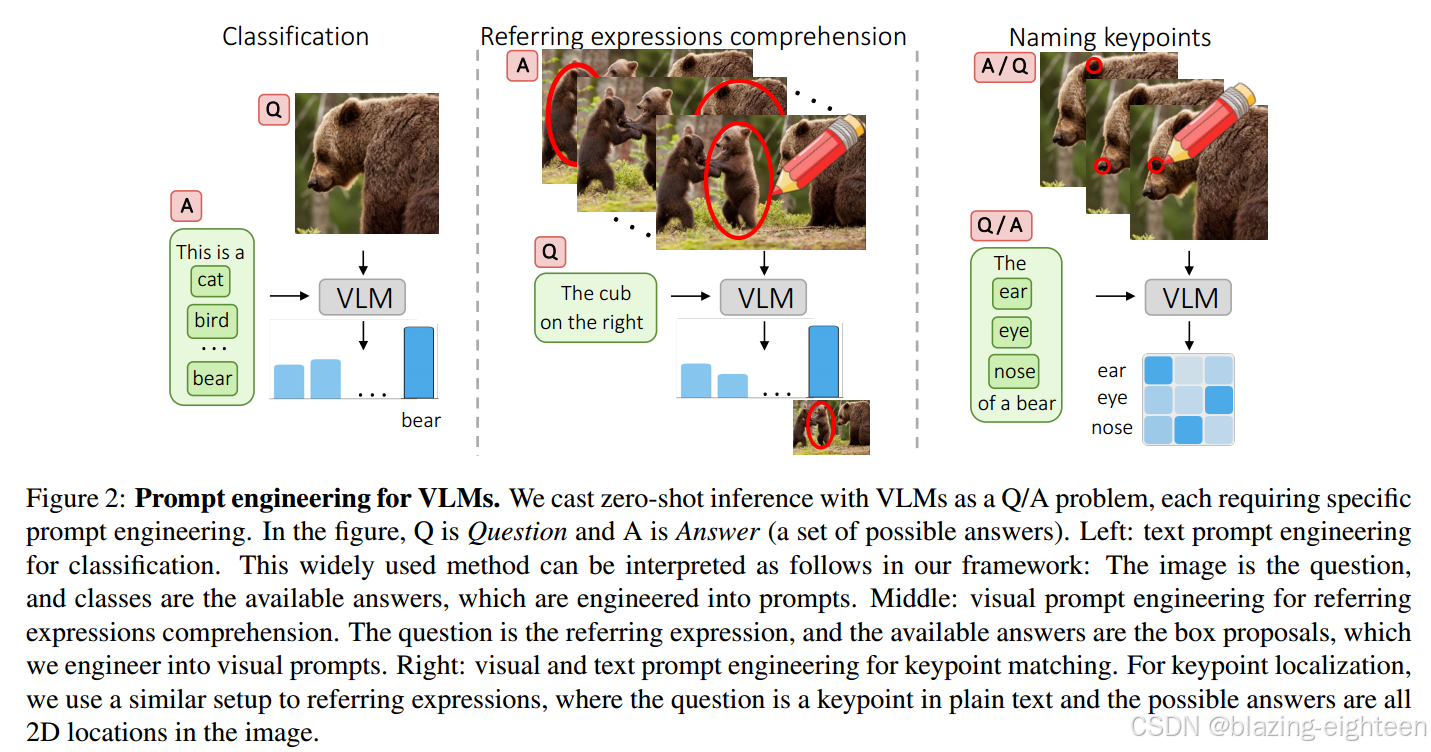
大规模视觉语言模型(例如 CLIP)学习了强大的图像文本表示,这些表示已在从零样本分类到文本到图像生成等众多应用中得到应用。尽管如此,它们通过提示解决新型判别任务的能力仍落后于大型语言模型(例如 GPT-3)。在这里,我们探索了视觉提示工程的想法,通过在图像空间而不是文本中进行编辑来解决分类以外的计算机视觉任务。具体来说,我们发现了 CLIP 的一项新兴能力,只需在对象周围画一个红色圆圈,我们就可
到底了