




- @2201_75734742
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
比如,上图中的最终得到的,如果它作为下⼀层网络的输入,那么它就需要被广播发送到两个设备上。当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并⾏⼀般比较有优势,常见的视觉分类模型,如 ResNet50,比较适合采用数据并行。单机多卡训练,即并行训练。神经网络的训练不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信,才能做高效的分布式训

例如,在“I am learning LLM”的句子中,“-am”是辅助动词,“ learning”是主要动词,“ I”是主语名词,而“ LLM”是宾语。具体地,对于一个在训练在主任务上的大型神经网络,Probe是一个插入在其中间层的浅层神经网络,通常是一个分类器层。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做
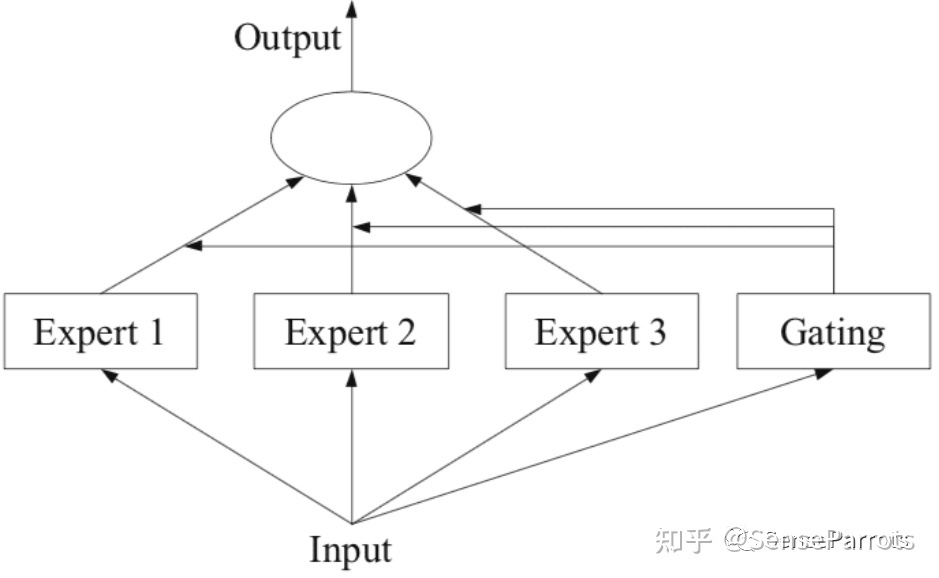
MoE 将预测建模任务分解为若干子任务,在每个子任务上训练一个专家模型(Expert Model),开发一个门控模型(Gating Model),门控模块用于选择使用哪个专家,组合各种专家。为了解决这个问题,提出了一种方式,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。然而,如果我们将门控函数。现在,我们转向另⼀类语
比如,上图中的最终得到的,如果它作为下⼀层网络的输入,那么它就需要被广播发送到两个设备上。当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并⾏⼀般比较有优势,常见的视觉分类模型,如 ResNet50,比较适合采用数据并行。单机多卡训练,即并行训练。神经网络的训练不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信,才能做高效的分布式训
首先需要分出子词,比如说单词“looked"和“looking”为训练语料,从语料中构建词表[l,o,o,k,e,d,i,n,g],然后“lo”出现频率最高,分成[lo,o,k,e,d,i,n,g],接下来“loo”出现频率最高,分成[loo,k,e,d,i,n,gh],以此类推,最后被分成子词“look”、“ing”、“ed”。传统的神经网络(包括CNN),输入和输出都是相互独立的,例如一张图片

比如,上图中的最终得到的,如果它作为下⼀层网络的输入,那么它就需要被广播发送到两个设备上。当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并⾏⼀般比较有优势,常见的视觉分类模型,如 ResNet50,比较适合采用数据并行。单机多卡训练,即并行训练。神经网络的训练不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信,才能做高效的分布式训
首先需要分出子词,比如说单词“looked"和“looking”为训练语料,从语料中构建词表[l,o,o,k,e,d,i,n,g],然后“lo”出现频率最高,分成[lo,o,k,e,d,i,n,g],接下来“loo”出现频率最高,分成[loo,k,e,d,i,n,gh],以此类推,最后被分成子词“look”、“ing”、“ed”。传统的神经网络(包括CNN),输入和输出都是相互独立的,例如一张图片
MoE 将预测建模任务分解为若干子任务,在每个子任务上训练一个专家模型(Expert Model),开发一个门控模型(Gating Model),门控模块用于选择使用哪个专家,组合各种专家。为了解决这个问题,提出了一种方式,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。然而,如果我们将门控函数。现在,我们转向另⼀类语
例如,在“I am learning LLM”的句子中,“-am”是辅助动词,“ learning”是主要动词,“ I”是主语名词,而“ LLM”是宾语。具体地,对于一个在训练在主任务上的大型神经网络,Probe是一个插入在其中间层的浅层神经网络,通常是一个分类器层。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做