如何在 Ubuntu 22.04 上安装 Elasticsearch、Logstash 和 Kibana(Elastic Stack)
介绍
Elastic Stack(以前称为 ELK Stack)是由 Elastic 制作的开源软件集合,它允许您搜索、分析和可视化从任何生成的日志任何格式的源,一种称为_集中式日志记录_的做法。在尝试识别服务器或应用程序的问题时,集中式日志记录非常有用,因为它允许您在一个地方搜索所有日志。它也很有用,因为它允许您通过在特定时间范围内关联它们的日志来识别跨多个服务器的问题。
Elastic Stack 有四个主要组件:
-
Elasticsearch:分布式 RESTful 搜索引擎,存储所有收集到的数据。
-
Logstash:Elastic Stack 的数据处理组件,将传入数据发送到 Elasticsearch。
-
Kibana:用于搜索和可视化日志的 Web 界面。
-
Beats:轻量级、单一用途的数据传送器,可以将数据从数百或数千台机器发送到 Logstash 或 Elasticsearch。
在本教程中,您将在 Ubuntu 22.04 服务器上安装 Elastic Stack。您将学习如何安装 Elastic Stack 的所有组件——包括 Filebeat,一个用于转发和集中日志和文件的 Beat——并配置他们收集和可视化系统日志。此外,由于 Kibana 通常只能在 localhost 上使用,我们将使用 Nginx 来代理它,以便可以通过 Web 浏览器访问它。我们将在单个服务器上安装所有这些组件,我们将其称为_Elastic Stack 服务器_。
注意:安装 Elastic Stack 时,您必须在整个堆栈中使用相同的版本。在本教程中,我们将安装整个堆栈的最新版本,在撰写本文时,它们是 Elasticsearch 7.7.1、Kibana 7.7.1、Logstash 7.7.1 和 Filebeat 7.7.1。
先决条件
要完成本教程,您将需要以下内容:
-
具有 4GB RAM 和 2 个 CPU 的 Ubuntu 22.04 服务器,由非 root sudo 用户设置。您可以按照 使用 Ubuntu 22.04 进行初始服务器设置 来实现。对于本教程,我们将使用运行 Elasticsearch 所需的最少 CPU 和 RAM。请注意,您的 Elasticsearch 服务器所需的 CPU、RAM 和存储量取决于您期望的日志量。
-
已安装 OpenJDK 11。请参阅 [安装默认 JRE/JDK] 部分(https://www.digitalocean.com/community/tutorials/how-to-install-java-with-apt-on-ubuntu-22-04#installing-the- default-jrejdk)在我们的指南[如何在 Ubuntu 22.04 上使用 Apt 安装 Java](https://www.digitalocean.com/community/tutorials/how-to-install-java-with-apt-on-ubuntu-22 -04) 进行设置。
-
Nginx 安装在您的服务器上,我们将在本指南后面将其配置为 Kibana 的反向代理。按照我们关于如何在 Ubuntu 22.04 上安装 Nginx 的指南进行设置。
此外,由于 Elastic Stack 用于访问有关您的服务器的重要信息,您不希望未经授权的用户访问这些信息,因此通过安装 TLS/SSL 证书来确保服务器安全非常重要。这是可选的,但强烈建议。
但是,由于您最终将在本指南的过程中更改您的 Nginx 服务器块,因此完成 让我们在 Ubuntu 22.04 上加密 可能更有意义/tutorials/how-to-secure-nginx-with-let-s-encrypt-on-ubuntu-22-04) 指南在本教程的第二步末尾。考虑到这一点,如果您计划在您的服务器上配置 Let's Encrypt,在执行此操作之前,您需要准备好以下内容:
-
完全限定域名 (FQDN)。本教程将自始至终使用
your_domain。您可以在 Namecheap 上购买一个域名,在 Freenom 上免费获得一个,或者使用该域名您选择的注册商。 -
为您的服务器设置了以下两个 DNS 记录。您可以按照 this Introduction to DigitalOcean DNS 了解如何添加它们的详细信息。
-
带有
your_domain的 A 记录指向您服务器的公共 IP 地址。 -
带有
www.your_domain的 A 记录指向您服务器的公共 IP 地址。
第 1 步 — 安装和配置 Elasticsearch
Elasticsearch 组件在 Ubuntu 的默认软件包存储库中不可用。但是,它们可以在添加 Elastic 的包源列表后与 APT 一起安装。
所有包都使用 Elasticsearch 签名密钥进行签名,以保护您的系统免受包欺骗。已使用密钥进行身份验证的包将被您的包管理器视为信任。在此步骤中,您将导入 Elasticsearch 公共 GPG 密钥并添加 Elastic 包源列表以安装 Elasticsearch。
首先,使用 cURL(用于通过 URL 传输数据的命令行工具)将 Elasticsearch 公钥 GPG 密钥导入 APT。请注意,我们使用参数 -fsSL 来消除所有进度和可能的错误(服务器故障除外),并允许 cURL 在重定向时在新位置发出请求。将 curl 命令的输出传送到 gpg --dearmor 命令,该命令将密钥转换为 apt 可用于验证下载包的格式。
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch |sudo gpg --dearmor -o /usr/share/keyrings/elastic.gpg
接下来,将 Elastic 源列表添加到 sources.list.d 目录,APT 将在其中搜索新源:
echo "deb [签名者u003d/usr/share/keyrings/elastic.gpg] https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
文件的 [signed-byu003d/usr/share/keyrings/elastic.gpg] 部分指示 apt 使用您下载的密钥来验证 Elasticsearch 包的存储库和文件信息。
接下来,更新您的软件包列表,以便 APT 读取新的 Elastic 源:
sudo apt 更新
然后使用以下命令安装 Elasticsearch:
sudo apt install elasticsearch
Elasticsearch 现在已安装并准备好进行配置。使用您喜欢的文本编辑器编辑 Elasticsearch 的主配置文件,elasticsearch.yml。在这里,我们将使用 nano:
Sudonano /Etc/Earth c 海拱/Earth c 海拱。 yml
注意: Elasticsearch 的配置文件是 YAML 格式,也就是说我们需要维护缩进格式。确保在编辑此文件时不要添加任何额外的空格。
elasticsearch.yml 文件为您的集群、节点、路径、内存、网络、发现和网关提供了配置选项。大多数这些选项都在文件中预先配置,但您可以根据需要更改它们。为了演示单服务器配置,我们将仅调整网络主机的设置。
Elasticsearch 在端口 9200 上侦听来自任何地方的流量。您需要限制对 Elasticsearch 实例的外部访问,以防止外部人员通过其 [REST API](https://en.wikipedia.org/wiki/Representational_state)读取您的数据或关闭您的 Elasticsearch 集群_transfer)。要限制访问并因此提高安全性,请找到指定 network.host 的行,取消注释,然后将其值替换为 localhost,如下所示:
/etc/elasticsearch/elasticsearch.yml
. . .
# - - - - - - - - - - - - - - - - - 网络 - - - - - - - ---------------------
#
# 将绑定地址设置为特定 IP(IPv4 或 IPv6):
#
network.host: 本地主机
. . .
我们指定了 localhost 以便 Elasticsearch 监听所有接口和绑定的 IP。如果您希望它仅在特定接口上侦听,您可以指定其 IP 来代替 localhost。保存并关闭 elasticsearch.yml。如果您使用的是 nano,可以按 CTRL+X,然后按 Y,然后按 ENTER。
这些是您可以开始使用 Elasticsearch 的最低设置。现在您可以第一次启动 Elasticsearch。
使用 systemctl 启动 Elasticsearch 服务。给 Elasticsearch 一点启动时间。否则,您可能会收到有关无法连接的错误。
sudo systemctl 启动弹性搜索
接下来,运行以下命令以使 Elasticsearch 在每次服务器启动时启动:
sudo systemctl 启用弹性搜索
您可以通过发送 HTTP 请求来测试您的 Elasticsearch 服务是否正在运行:
curl -X GET“本地主机:9200”
您将看到显示有关本地节点的一些基本信息的响应,类似于以下内容:
输出{
“名称”:“弹性搜索”,
“cluster_name”:“弹性搜索”,
“cluster_uuid”:“n8Qu5CjWSmyIXBzRXK-j4A”,
“版本” : {
“数字”:“7.17.2”,
“build_flavor”:“默认”,
“build_type”:“deb”,
“build_hash”:“de7261de50d90919ae53b0eff9413fd7e5307301”,
“build_date”:“2022-03-28T15:12:21.446567561Z”,
“build_snapshot”:假,
“lucene_version”:“8.11.1”,
“minimum_wire_compatibility_version”:“6.8.0”,
“minimum_index_compatibility_version”:“6.0.0-beta1”
},
“标语”:“你知道,搜索”
}
现在 Elasticsearch 已经启动并运行了,让我们安装 Kibana,Elastic Stack 的下一个组件。
第 2 步 — 安装和配置 Kibana 仪表板
根据官方文档,您应该在安装Elasticsearch之后才安装Kibana。按此顺序安装可确保每个产品所依赖的组件正确就位。
因为您已经在上一步中添加了 Elastic 包源,您可以使用 apt 安装 Elastic Stack 的其余组件:
sudo apt install kibana
然后启用并启动 Kibana 服务:
sudo systemctl 启用 kibana
sudo systemctl 启动 kibana
因为 Kibana 被配置为只监听 localhost,所以我们必须设置一个 反向代理 以允许外部访问给它。我们将为此目的使用 Nginx,它应该已经安装在您的服务器上。
首先,使用 openssl 命令创建一个管理 Kibana 用户,您将使用该用户访问 Kibana Web 界面。例如,我们将此帐户命名为“kibanaadmin”,但为了确保更高的安全性,我们建议您为您的用户选择一个难以猜测的非标准名称。
以下命令将创建管理 Kibana 用户和密码,并将它们存储在 htpasswd.users 文件中。您将配置 Nginx 以要求此用户名和密码并立即读取此文件:
ho "kibanaadmin:`openssalpassword -apr1`" | sudo t -a /attack/nginx/hotpass.users
在提示符处输入并确认密码。记住或记下此登录信息,因为您将需要它来访问 Kibana Web 界面。
接下来,我们将创建一个 Nginx 服务器块文件。例如,我们将此文件称为 your_domain,尽管您可能会发现给您的文件起一个更具描述性的名称会有所帮助。例如,如果您为此服务器设置了 FQDN 和 DNS 记录,则可以在 FQDN 之后命名此文件。
使用 nano 或您喜欢的文本编辑器,创建 Nginx 服务器块文件:
sudo nano /etc/nginx/sites-available/your_domain
将以下代码块添加到文件中,确保更新 your_domain 以匹配您服务器的 FQDN 或公共 IP 地址。此代码将 Nginx 配置为将服务器的 HTTP 流量定向到 Kibana 应用程序,该应用程序正在侦听“localhost:5601”。此外,它将 Nginx 配置为读取 htpasswd.users 文件并要求基本身份验证。
请注意,如果您一直遵循 prerequisite Nginx 教程 到最后,您可能有已经创建了这个文件并用一些内容填充了它。在这种情况下,请在添加以下内容之前删除文件中的所有现有内容:
/etc/nginx/sites-available/your_domain
服务器 {
听 80;
server_name your_domain;
auth_basic "受限访问";
auth_basic_user_file /etc/nginx/htpasswd.users;
地点 / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header 升级 $http_upgrade;
proxy_set_header 连接“升级”;
proxy_set_header 主机 $host;
proxy_cache_bypass $http_upgrade;
}
}
完成后,保存并关闭文件。
接下来,通过创建指向 sites-enabled 目录的符号链接来启用新配置。如果您已经在 Nginx 必备项中创建了同名的服务器块文件,则无需运行此命令:
sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
然后检查配置是否有语法错误:
须藤 nginx -t
如果在您的输出中报告了任何错误,请返回并仔细检查您放置在配置文件中的内容是否已正确添加。在输出中看到 syntax is ok 后,继续并重新启动 Nginx 服务:
sudo systemctl 重新加载 nginx
如果您遵循初始服务器设置指南,则应该启用 UFW 防火墙。要允许连接到 Nginx,我们可以通过键入以下内容来调整规则:
sudo ufw 允许'Nginx Full'
注意: 如果您遵循先决条件 Nginx 教程,您可能已经创建了一个 UFW 规则,允许“Nginx HTTP”配置文件通过防火墙。因为 Nginx Full 配置文件允许 HTTP 和 HTTPS 流量通过防火墙,所以您可以安全地删除您在先决条件教程中创建的规则。使用以下命令执行此操作:
sudo ufw delete 允许'Nginx HTTP'
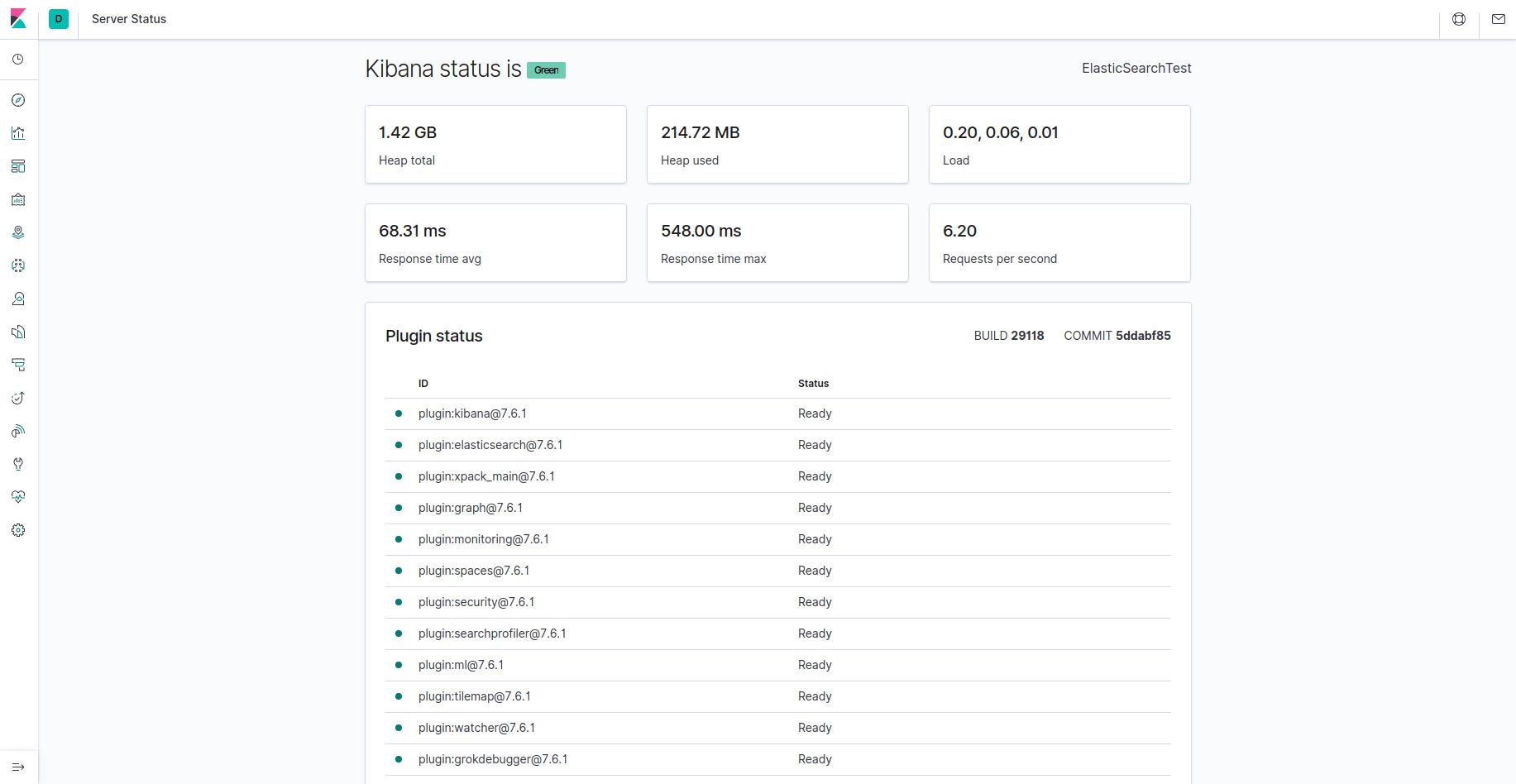
现在可以通过您的 FQDN 或 Elastic Stack 服务器的公共 IP 地址访问 Kibana。您可以通过导航到以下地址并在出现提示时输入您的登录凭据来检查 Kibana 服务器的状态页面:
http://your_domain/状态
此状态页面显示有关服务器资源使用情况的信息并列出已安装的插件。
注意:如前提条件部分所述,建议您在服务器上启用 SSL/TLS。您现在可以按照 Let's Encrypt 指南在 Ubuntu 22.04 上获取 Nginx 的免费 TLS 证书。获得 TLS 证书后,您可以返回并完成本教程。
现在 Kibana 仪表板已配置完毕,让我们安装下一个组件:Logstash。
第 3 步 — 安装和配置 Logstash
虽然 Beats 可以将数据直接发送到 Elasticsearch 数据库,但通常使用 Logstash 来处理数据。这将使您能够更灵活地从不同来源收集数据,将其转换为通用格式,并将其导出到另一个数据库。
使用以下命令安装 Logstash:
sudo apt install logstash
安装 Logstash 后,您可以继续进行配置。 Logstash 的配置文件位于 /etc/logstash/conf.d 目录中。有关配置语法的更多信息,您可以查看 Elastic 提供的配置参考。在配置文件时,将 Logstash 视为一个管道,它在一端接收数据,以一种或另一种方式处理它,然后将其发送到它的目的地(在这种情况下,目的地是 Elasticsearch),这会很有帮助。 Logstash 管道有两个必需元素,“输入”和“输出”,以及一个可选元素,“过滤器”。输入插件使用来自源的数据,过滤器插件处理数据,输出插件将数据写入目的地。

创建一个名为 02-beats-input.conf 的配置文件,您将在其中设置 Filebeat 输入:
它是 sudo / tc / gs sh / con f。 d/02 - 承担 ts - 输入。 conf
插入以下 input 配置。这指定了一个 beats 输入,它将在 TCP 端口 5044 上侦听。
/etc/logstash/conf.d/02-beats-input.conf
``标记
输入 {
节拍{
端口 u003d> 5044
}
}
保存并关闭文件。
接下来,创建一个名为 `30-elasticsearch-output.conf` 的配置文件:
```重击
它是 sudo / tc / gs sh / con f。 d / 30 - 地球海拱 - tput。 conf
插入以下“输出”配置。本质上,此输出配置 Logstash 以将 Beats 数据存储在 Elasticsearch 中,Elasticsearch 运行在 localhost:9200 的一个以使用的 Beat 命名的索引中。本教程中使用的 Beat 是 Filebeat:
/etc/logstash/conf.d/30-elasticsearch-output.conf
``标记 输出 { 如果 [@metadata][管道] { 弹性搜索{ 主机u003d> [“本地主机:9200”] 管理模板 u003d> 假 index u003d> "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" 管道 u003d> "%{[@metadata][管道]}" } } 别的 { 弹性搜索{ 主机u003d> [“本地主机:9200”] 管理模板 u003d> 假 index u003d> "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } }
保存并关闭文件。
使用以下命令测试您的 Logstash 配置:
```重击
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
如果没有语法错误,您的输出将显示 Config Validation Result: OK.几秒钟后退出 Logstash。如果您在输出中没有看到这一点,请检查输出中记录的任何错误并更新您的配置以更正它们。请注意,您将收到来自 OpenJDK 的警告,但它们不应导致任何问题并且可以忽略。
如果您的配置测试成功,请启动并启用 Logstash 以使配置更改生效:
sudo systemctl 启动logstash
sudo systemctl 启用logstash
现在 Logstash 运行正常并且配置齐全,让我们安装 Filebeat。
第 4 步 — 安装和配置 Filebeat
Elastic Stack 使用几个称为 Beats 的轻量级数据传送器从各种来源收集数据并将它们传输到 Logstash 或 Elasticsearch。以下是 Elastic 目前提供的 Beats:
-
Filebeat:收集和发送日志文件。
-
Metricbeat:从您的系统和服务中收集指标。
-
Packetbeat:收集和分析网络数据。
-
Winlogbeat:收集 Windows 事件日志。
-
Auditbeat:收集Linux审计框架数据并监控文件完整性。
-
Heartbeat:通过主动探测监控服务的可用性。
在本教程中,我们将使用 Filebeat 将本地日志转发到我们的 Elastic Stack。
使用 apt 安装 Filebeat:
sudo apt install filebeat
接下来,配置 Filebeat 以连接到 Logstash。在这里,我们将修改 Filebeat 自带的示例配置文件。
打开 Filebeat 配置文件:
Sudonano / 等 / Feebeart / Feebeart。 yml
注意: 与 Elasticsearch 一样,Filebeat 的配置文件是 YAML 格式。这意味着正确的缩进至关重要,因此请务必使用这些说明中指示的相同数量的空格。
Filebeat 支持多种输出,但您通常只会将事件直接发送到 Elasticsearch 或 Logstash 以进行额外处理。在本教程中,我们将使用 Logstash 对 Filebeat 收集的数据进行额外处理。 Filebeat 不需要直接向 Elasticsearch 发送任何数据,所以让我们禁用该输出。为此,请找到 output.elasticsearch 部分,并在以下行前面加上 # 注释掉它们:
/etc/filebeat/filebeat.yml
...
#output.elasticsearch:
# 要连接的主机数组。
#hosts: ["localhost:9200"]
...
然后,配置 output.logstash 部分。通过删除 # 取消注释行 output.logstash: 和 hosts: ["localhost:5044"]。这会将 Filebeat 配置为连接到 Elastic Stack 服务器上的 Logstash 端口“5044”,我们之前为该端口指定了 Logstash 输入:
/etc/filebeat/filebeat.yml
输出.logstash:
# Logstash 主机
主机:[“本地主机:5044”]
保存并关闭文件。
Filebeat 的功能可以通过 Filebeat 模块 进行扩展。在本教程中,我们将使用 system 模块,该模块收集和解析系统创建的日志常见 Linux 发行版的日志记录服务。
让我们启用它:
sudo filebeat 模块启用系统
您可以通过运行以下命令查看启用和禁用模块的列表:
sudo filebeat 模块列表
您将看到类似于以下内容的列表:
输出启用:
系统
禁用:
阿帕奇2
已审核
弹性搜索
它认为
iis
卡夫卡
木花
日志存储
mongodb
mysql
nginx
查询
PostgreSQL
雷迪斯
交通
...
默认情况下,Filebeat 配置为使用系统日志和授权日志的默认路径。在本教程的情况下,您不需要更改配置中的任何内容。可以在/etc/filebeat/modules.d/system.yml配置文件中看到模块的参数。
接下来,我们需要设置 Filebeat 摄取管道,它在将日志数据通过 logstash 发送到 Elasticsearch 之前解析日志数据。要加载系统模块的摄取管道,请输入以下命令:
sudo filebeat setup --pipelines --modules 系统
接下来,将索引模板加载到 Elasticsearch 中。 Elasticsearch index 是具有相似特征的文档的集合。索引用一个名称标识,用于在其中执行各种操作时引用索引。创建新索引时将自动应用索引模板。
要加载模板,请使用以下命令:
sudo filebeat setup --index-management -E output.logstash.enabledu003dfalse -E 'output.elasticsearch.hostsu003d["localhost:9200"]'
OutputIndex 设置完成。
Filebeat 附带了示例 Kibana 仪表板,可让您在 Kibana 中可视化 Filebeat 数据。在使用仪表板之前,您需要创建索引模式并将仪表板加载到 Kibana 中。
随着仪表板的加载,Filebeat 连接到 Elasticsearch 以检查版本信息。要在启用 Logstash 时加载仪表板,您需要禁用 Logstash 输出并启用 Elasticsearch 输出:
sudo filebeat setup -E output.logstash.enabledu003dfalse -E output.elasticsearch.hostsu003d['localhost:9200'] -E setup.kibana.hostu003dlocalhost:5601
几分钟后,您应该会收到类似于以下内容的输出:
OutputOverwriting ILM 策略已禁用。设置 `setup.ilm.overwrite:true` 以启用。
索引设置完成。
加载仪表板(Kibana 必须正在运行且可访问)
加载的仪表板
使用 setup --machine-learning 设置 ML 将在 8.0.0 中删除。请改用 ML 应用程序。
查看更多:https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
加载的机器学习作业配置
加载的摄取管道
现在您可以启动并启用 Filebeat:
sudo systemctl 启动文件节拍
sudo systemctl 启用文件节拍
如果您正确设置了 Elastic Stack,Filebeat 将开始将您的系统日志和授权日志传送到 Logstash,然后将这些数据加载到 Elasticsearch。
要验证 Elasticsearch 确实在接收此数据,请使用以下命令查询 Filebeat 索引:
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
您应该会收到与此类似的输出:
输出。 . .
{
“接受”:4,
“超时”:假,
“_shards”:{
“总数”:2,
“成功”:2,
“跳过”:0,
“失败”:0
},
“命中”:{
“全部的” : {
“价值”:4040,
“关系”:“eq”
},
“最大分数”:1.0,
“命中”:[
{
"_index" : "filebeat-7.17.2-2022.04.18",
"_type" : "_doc",
"_id" : "YhwePoAB2RlwU5YB6yfP",
“_score”:1.0,
“_资源” : {
“云” : {
“实例” : {
“id”:“294355569”
},
“提供者”:“数字海洋”,
“服务” : {
“名称”:“液滴”
},
“地区”:“tor1”
},
"@timestamp" : "2022-04-17T04:42:06.000Z",
“代理人” : {
“主机名”:“弹性搜索”,
“名称”:“弹性搜索”,
“id”:“b47ca399-e6ed-40fb-ae81-a2f2d36461e6”,
“ephemeral_id”:“af206986-f3e3-4b65-b058-7455434f0cac”,
“类型”:“文件节拍”,
“版本”:“7.17.2”
},
. . .
如果您的输出显示总命中数为 0,则 Elasticsearch 没有在您搜索的索引下加载任何日志,您需要检查您的设置是否有错误。如果您收到了预期的输出,请继续执行下一步,我们将在其中了解如何浏览 Kibana 的一些仪表板。
第 5 步 — 探索 Kibana 仪表板
让我们回到之前安装的 Kibana Web 界面。
在 Web 浏览器中,转到 Elastic Stack 服务器的 FQDN 或公共 IP 地址。如果您的会话被中断,您将需要重新输入您在第 2 步中定义的凭据。登录后,您应该会收到 Kibana 主页:
单击左侧导航栏中的 Discover 链接(您可能必须单击左下角的 Expand 图标才能查看导航菜单项)。在 Discover 页面上,选择预定义的 filebeat-* 索引模式以查看 Filebeat 数据。默认情况下,这将显示过去 15 分钟内的所有日志数据。您将看到一个带有日志事件的直方图,以及下面的一些日志消息:
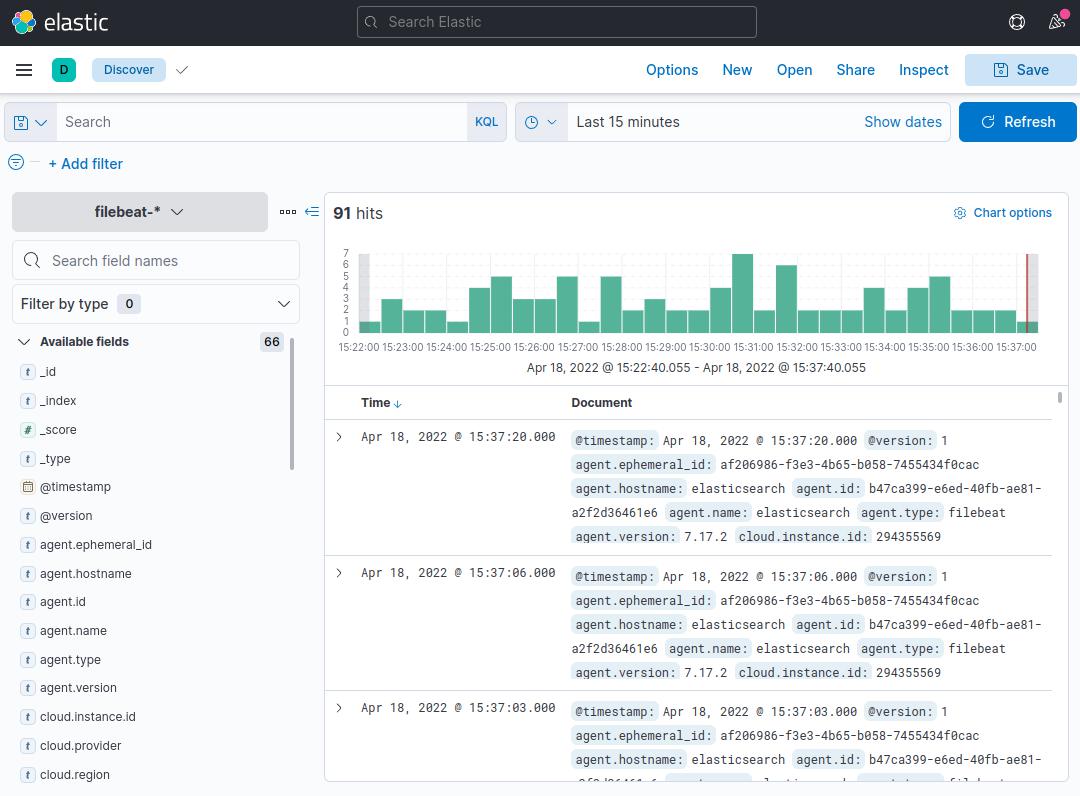
在这里,您可以搜索和浏览您的日志,还可以自定义您的仪表板。不过,此时不会有太多内容,因为您只是从 Elastic Stack 服务器收集系统日志。
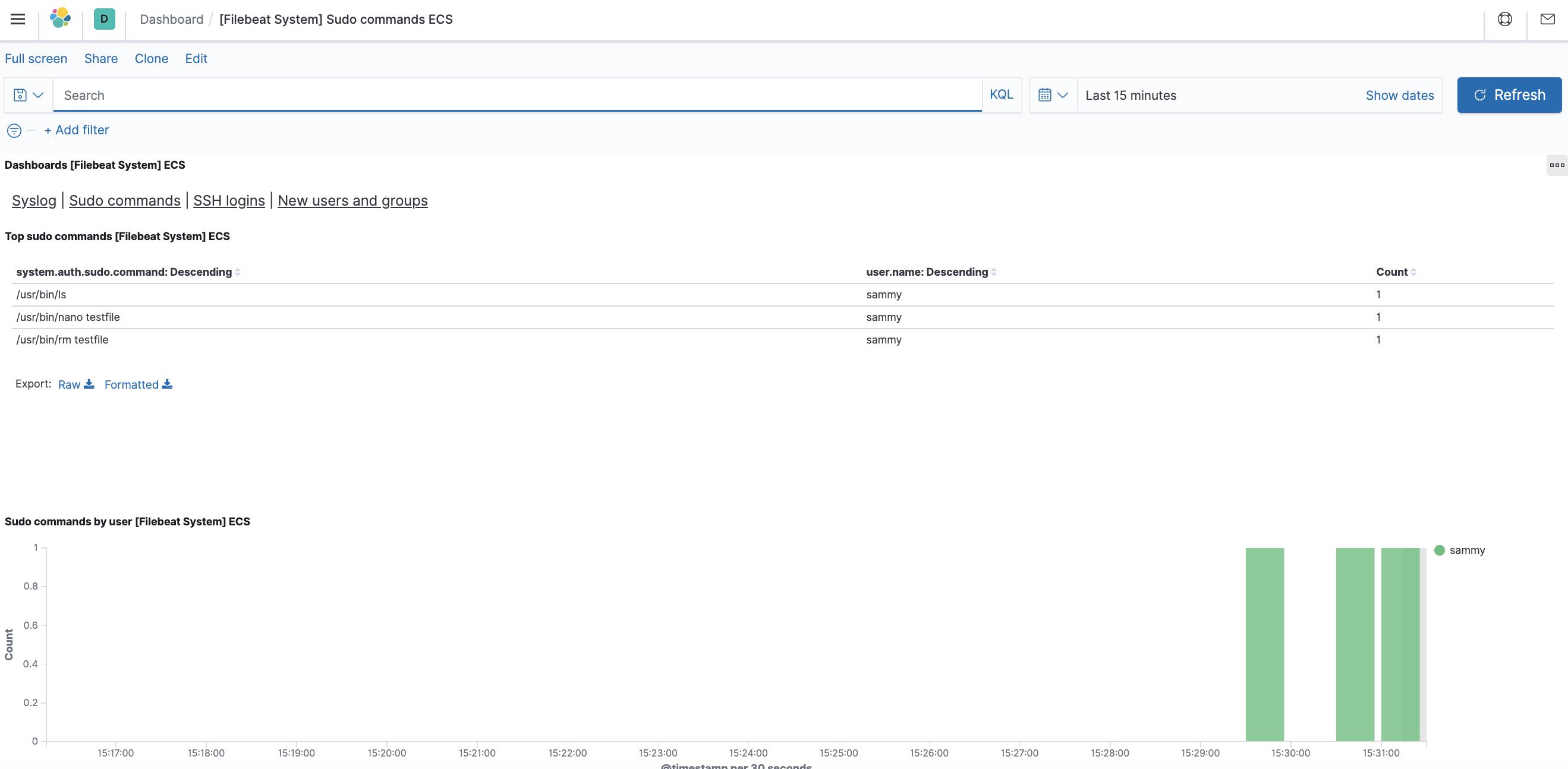
使用左侧面板导航到 Dashboard 页面并搜索 Filebeat System 仪表板。在那里,您可以选择 Filebeat 的“系统”模块附带的示例仪表板。
例如,您可以根据系统日志消息查看详细统计信息:

您还可以查看哪些用户使用了 sudo 命令以及何时使用:
Kibana 还有许多其他功能,例如图形和过滤,因此请随意探索。
结论
在本教程中,您学习了如何安装和配置 Elastic Stack 以收集和分析系统日志。请记住,您可以使用 Beats 将几乎任何类型的日志或索引数据发送到 Logstash,但如果使用Logstash 过滤器,因为这会将数据转换为 Elasticsearch 可以轻松读取的一致格式。

Ubuntu 社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 1
1- 0



 已为社区贡献1125条内容
已为社区贡献1125条内容

所有评论(0)