
强化学习之Gym基础入门(1)
目录简介Gym安装方法(anaconda安装法)程序代码-函数简介训练参数的基本平台openai的Gym,与tensorflow无缝连接,仅支持python,本质是一组微分方程,简单的模型手动推导,复杂的模型需要用一些强大的物理引擎,如ODE, Bullet, Havok, Physx等,Gym在搭建机器人仿真环境用的是mujoco,ROS里面的物理引擎是gazebo。...
目录
-
简介
训练参数的基本平台openai的Gym,与tensorflow无缝连接,仅支持python,本质是一组微分方程,简单的模型手动推导,复杂的模型需要用一些强大的物理引擎,如ODE, Bullet, Havok, Physx等,Gym在搭建机器人仿真环境用的是mujoco,ROS里面的物理引擎是gazebo。
下面是Gym中cartpole的模型,代码如下
thetaacc = (self.gravity * sintheta - costheta* temp) / (self.length * (4.0/3.0 - self.masspole * costheta * costheta / self.total_mass))
xacc = temp - self.polemass_length * thetaacc * costheta / self.total_mass它是一个开发、比较各种强化学习算法的工具库,提供了不少内置的环境,是学习强化学习不错的一个平台,gym库的一个很大的特点是可以可视化,把强化学习算法的人机交互用动画的形式呈现出来,这比仅依靠数据来分析算法有意思多了。
-
Gym安装方法(anaconda安装法)
anaconda安装
- 下载anaconda安装包
- 安装包所在目录文件夹(如下载文件夹),bash 对应的anaconda.sh文件,直接用Tab补全即可
- 安装过程会询问你是否将路径安装到环境变量中,键入yes, 至此Anaconda安装完成。你会在目录/home/你的用户名文件夹下面看到anaconda3。关掉终端,再开一个,这样环境变量才起作用。
$ cd 下载
$ bash Anaconda3-5.2.0-Linux-x86_64.sh利用anaconda建一个虚拟环境
Anaconda创建虚拟环境的格式为:conda create –n 你要创建的名字 python=版本号。如创建的虚拟环境名字为gymlab, 用的python版本号为3.4
$ conda create -n gymlab python=3.4操作完此步之后,会在anaconda3/envs文件夹下多一个gymlab。Python3.4就在gymlab下得lib文件夹中。
安装gym
1. 开一个新的终端,然后用命令source activate gymlab激活虚拟环境
$ source activate gymlab2. 将gym克隆到计算机中. 如果你的计算机中没有安装git, 那么可以键入:sudo apt install git.先安装git.
$ git clone https://github.com/openai/gym3. cd gym 进入gym文件夹, 进行gym的完全安装
$ sudo apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
$ pip install -e '.[all]'4. 在终端输入以下代码会使终端python的编译器变为anaconda,anaconda库比较多
export PATH="/home/robot/anaconda3/bin:$PATH"网上说需要加上export PYTHONPATH="/home/robot/gym:$PYTHONPATH"(感觉没用)
如果在终端报错,没有找到numpy,可以用以下命令解决,一般更新一下就行
常用命令:
conda list:列出当前已经安装的包
conda install numpy:使用conda安装numpy ,对于的卸载就是uninstall
pip install numpy:使用pip安装 ,对于的卸载就是uninstall
conda upgrade numpy:更新numpy的版本
pip install --upgrade numpy:版本更新
测试代码
import gym
import time
env = gym.make('CartPole-v0')
env.reset()
env.render()
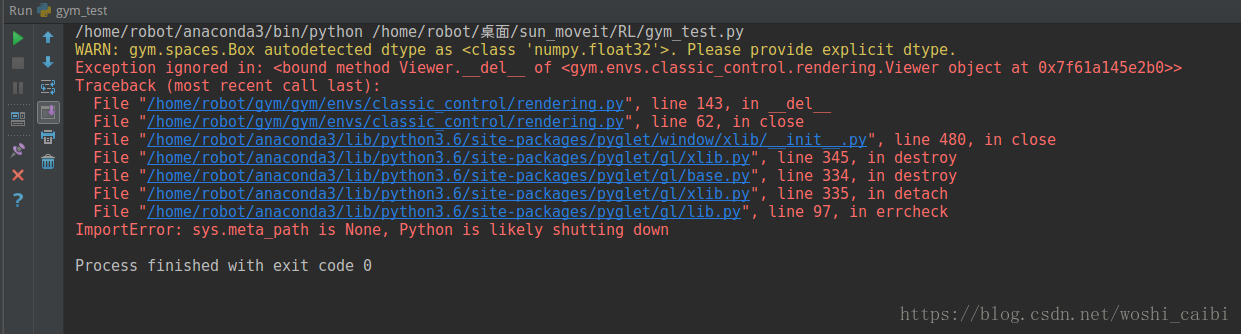
time.sleep(2)在pycharm中输入代码,需要在代码最后加上time.sleep(2)或者env.close(),否则会报以下错误;
在终端中输入代码,则不需要上述操作,但需要关掉终端,否则无法关闭仿真界面。
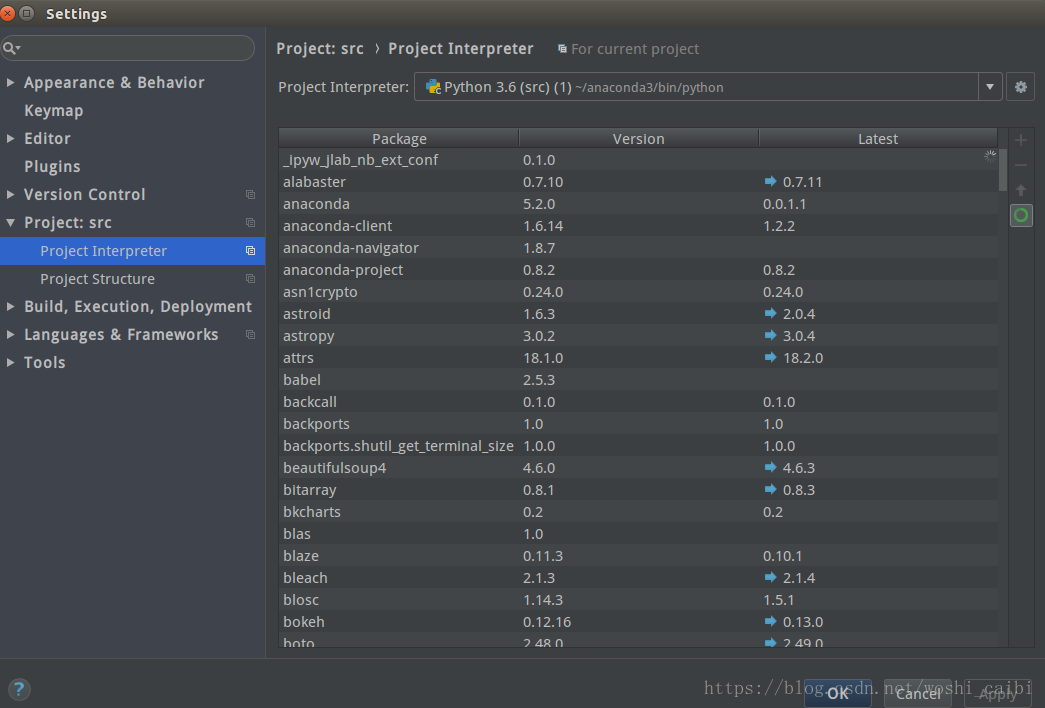
pycharm中的编译器需要改为anaconda的Python版本,点小齿轮添加
注意:
-
程序代码-函数
CartPole-v0 的环境文件在gym目录/gym/envs/classic_control/cartpole.py中.
该文件定义了一个CartPoleEnv的环境类,该类的成员函数有:seed(), step(),reset()和render(). 之前调用的就是CartPoleEnv的两个成员函数reset()和render()
1. reset() 初始化函数
def reset(self):
""" 重新初始化函数 """
# 利用均匀随机分布初试化环境的状态
self.state = self.np_random.uniform(low=-0.05, high=0.05, size=(4,))
# 设置当前步数为None
self.steps_beyond_done = None
# 返回环境的初始化状态
return np.array(self.state)2. render() 图像引擎
def render(self, mode='human'):
""" render()函数在这里扮演图像引擎的角色。一个仿真环境必不可少的两部分是物理引擎和图像引擎。物理引擎模拟环境中物体的运动规律;图像引擎用来显示环境中的物体图像 """
screen_width = 600
screen_height = 400
world_width = self.x_threshold*2
scale = screen_width/world_width
carty = 100 # TOP OF CART
polewidth = 10.0
polelen = scale * 1.0
cartwidth = 50.0
cartheight = 30.0
if self.viewer is None:
# 导入rendering模块,利用rendering模块中的画图函数进行图形的绘制
from gym.envs.classic_control import rendering
# 绘制600*400的窗口函数为screen_width*screen_height
self.viewer = rendering.Viewer(screen_width, screen_height)
# 创建cart矩形,rendering.FilledPolygon为填充一个矩形
l,r,t,b = -cartwidth/2, cartwidth/2, cartheight/2, -cartheight/2
axleoffset =cartheight/4.0
cart = rendering.FilledPolygon([(l,b), (l,t), (r,t), (r,b)])
# Transform给cart添加平移属性和旋转属性
self.carttrans = rendering.Transform()
cart.add_attr(self.carttrans)
# 在图上加入几何cart
self.viewer.add_geom(cart)
# 创建摆杆pole
l,r,t,b = -polewidth/2,polewidth/2,polelen-polewidth/2,-polewidth/2
pole = rendering.FilledPolygon([(l,b), (l,t), (r,t), (r,b)])
# 给pole设置颜色
pole.set_color(.8,.6,.4)
# 添加摆杆转换矩阵属性
self.poletrans = rendering.Transform(translation=(0, axleoffset))
pole.add_attr(self.poletrans)
pole.add_attr(self.carttrans)
# 加入几何体
self.viewer.add_geom(pole)
# 创建摆杆和台车之间的连接
self.axle = rendering.make_circle(polewidth/2)
self.axle.add_attr(self.poletrans)
self.axle.add_attr(self.carttrans)
self.axle.set_color(.5,.5,.8)
self.viewer.add_geom(self.axle)
#创建台车来回滑动的轨道,即一条直线
self.track = rendering.Line((0,carty), (screen_width,carty))
self.track.set_color(0,0,0)
self.viewer.add_geom(self.track)
if self.state is None: return None
# 设置平移属性
x = self.state
cartx = x[0]*scale+screen_width/2.0 # MIDDLE OF CART
self.carttrans.set_translation(cartx, carty)
self.poletrans.set_rotation(-x[2])
return self.viewer.render(return_rgb_array = mode=='rgb_array')
3. step() 物理引擎
def step(self, action):
""" 该函数在仿真器中扮演物理引擎的角色。其输入是动作a,输出是:下一步状态,立即回报,是否终止,调试项。该函数描述了智能体与环境交互的所有信息,是环境文件中最重要的函数。在该函数中,一般利用智能体的运动学模型和动力学模型计算下一步的状态和立即回报,并判断是否达到终止状态 """
assert self.action_space.contains(action), "%r (%s) invalid"%(action, type(action))
state = self.state
# 系统的当前状态
x, x_dot, theta, theta_dot = state
# 输入动作,即作用到车上的力
force = self.force_mag if action==1 else -self.force_mag
# 余弦函数
costheta = math.cos(theta)
# 正弦函数
sintheta = math.sin(theta)
# 车摆的动力学方程式,即加速度与动作之间的关系
temp = (force + self.polemass_length * theta_dot * theta_dot * sintheta) / self.total_mass
# 摆的角加速度
thetaacc = (self.gravity * sintheta - costheta* temp) / (self.length * (4.0/3.0 - self.masspole * costheta * costheta / self.total_mass))
# 小车的平加速度
xacc = temp - self.polemass_length * thetaacc * costheta / self.total_mass
# tau是更新步长0.02,下面是计算下一步的状态
x = x + self.tau * x_dot
x_dot = x_dot + self.tau * xacc
theta = theta + self.tau * theta_dot
theta_dot = theta_dot + self.tau * thetaacc
self.state = (x,x_dot,theta,theta_dot)
# 设定小车和摆杆的阈值
done = x < -self.x_threshold \
or x > self.x_threshold \
or theta < -self.theta_threshold_radians \
or theta > self.theta_threshold_radians
done = bool(done)
#
if not done:
reward = 1.0
elif self.steps_beyond_done is None:
# Pole just fell!
self.steps_beyond_done = 0
reward = 1.0
else:
if self.steps_beyond_done == 0:
logger.warn("You are calling 'step()' even though this environment has already returned done = True. You should always call 'reset()' once you receive 'done = True' -- any further steps are undefined behavior.")
self.steps_beyond_done += 1
reward = 0.0
return np.array(self.state), reward, done, {}-
参考文献和资料

苏州本地的技术开发者社区,在这里可以交流本地的好吃好玩的,可以交流技术,可以交流招聘等等,没啥限制。
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)