企业私有化部署LLM的最佳实践与模型选择指南
企业私有化部署LLM需平衡性能、成本与安全。高性能场景推荐vLLM+GPU方案,其扩展性强但部署复杂;中小企业可选Ollama快速部署。模型选择上,国产qwen3/GLM4.5性能优异,国际客户可考虑Gemma3/Llama4。建议采用混合云+私有网络策略,兼顾灵活性与安全性,并需提前评估硬件投入和团队技术能力。不同规模企业应结合自身需求选择最优部署方案,实现安全高效的AI应用落地。
私有化部署大型语言模型(LLM)已成为企业提升数据安全、满足合规要求和实现个性化应用的关键手段。针对不同企业的规模、性能需求及应用场景,选择合适的LLM部署方案尤为重要。以下是基于当前主流方案和开源模型的最佳实践总结。
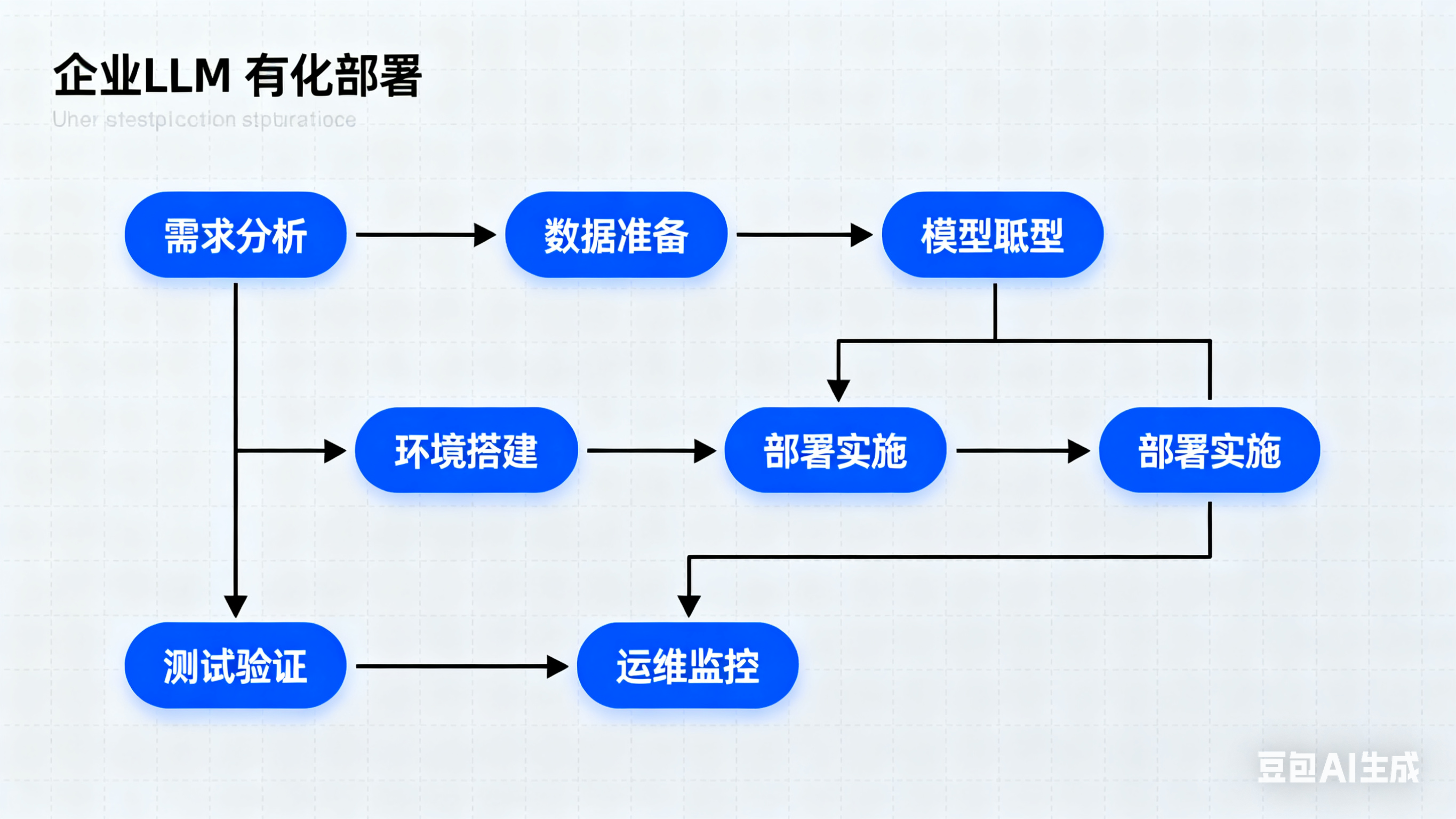
vLLM与Ollama的特点与选择
vLLM专注于高性能GPU推理,支持多用户并发请求,适合需要大规模、高性能的企业私有网络环境。其优势在于良好的扩展性以及针对GPU和服务器的性能调优,适合对响应速度和并发性能有较高要求的场景。然而,vLLM的部署和调优工程量较大,至少是Ollama的三倍,需求专业的GPU适配和参数调整。
Ollama则提供便捷的本地化部署方案,适合中小企业或需要快速上线的项目。其部署门槛和维护成本相对较低,能够快速实现模型的本地执行,但在大规模高并发时可能无法满足最高性能需求。
企业可根据自身规模、安全合规要求、硬件资源和业务场景,灵活选择vLLM 或 Ollama,甚至二者结合,采用混合云+私有网络的部署策略,既保障数据安全,又提高系统灵活性。

开源模型的选择与考量
目前市场上评价较高的开源模型包括中国的qwen3、GLM4.5,以及国外的Google Gemma 3和Meta的Llama 4。中国开源模型在性能和开放性方面领先,许多国外团队也基于中国开源模型进行定制和微调,但部分国外客户尤其是美国客户对中国模型存在顾虑,可能更倾向选用Gemma 3 或 Llama 4。
-
qwen3与GLM4.5:中国开源模型实力强劲,性能优良,广泛被业界认可,适合对性能有较高要求且愿意自主优化的项目。
-
Gemma 3:Google DeepMind最新推出,强调单GPU/TPU高效运算,支持大上下文和多模态,尤其适合中小企业、教育和科研,兼顾成本和性能。
-
Llama 4:Meta公司的代表作,被广泛应用于多种国外项目,开放度高但部分功能可能有所限制。
私有化部署的工程量与成本考虑
选择vLLM意味着较高的部署复杂度和工程投入,需要优化GPU相关参数和服务器环境,整体工作量是Ollama的3倍以上。而Ollama的便捷快速部署适合快速验证和应用场景落地。
另外,云端私有化选择如Azure OpenAI服务虽然功能全面,但成本较高,企业应权衡开源本地部署与云端服务的成本效益。

总结
-
大规模高性能场景,推荐以vLLM为基础,配合高性能GPU,确保良好扩展性和多用户并发处理能力。
-
快速本地化部署和中小企业,选择Ollama更合适,便于快速上线和运营。
-
模型选择应结合企业客户背景和合规需求,优先考虑qwen3和GLM4.5等国产强势开源模型,或面向部分国际客户则可选用Gemma 3、Llama 4。
-
部署策略可采用混合云+私有网络方式,兼顾灵活性和数据安全。
-
充分评估部署工程量和资源投入,合理规划硬件及技术团队建设。
通过合理选择部署方案和开源模型,企业能够实现安全、性能和成本的最佳平衡,满足私有化LLM应用的多样化需求。

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)