智源:ArXiv CLI重磅开源!2亿+开放论文,即将化身科研智能体的技能包
DeepXiv是由智源研究院联合高校与社区开发者共同研发的专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。该项目现已开源并免费开放使用。
DeepXiv 是专为智能体设计的科技文献基础设施,把论文搜索、渐进式阅读、热点追踪和深度调研变成可调用、可编排、可自动化的能力。
它做的不是把论文网站搬到命令行,而是把科技文献本身转化为智能体可以直接消费的数据接口与技能系统。
DeepXiv由智源研究院联合高校与社区开发者共同研发,项目现已开源并免费开放使用。
- GitHub:https://github.com/DeepXiv/deepxiv_sdk
- PyPI:https://pypi.org/project/deepxiv-sdk/
- API 文档:https://data.rag.ac.cn/api/docs
- 技术报告:https://arxiv.org/abs/2603.00084
引言
随着大模型智能体的快速发展,由 AI 驱动的自动化科研(Autonomous Research)正从概念快步走进现实。
从自动发现科学问题、生成研究计划,到设计理论方法、开展实验探究,科研智能体正在全流程、根本性地重塑科学研究的范式。
然而,要让智能体真正服务于科学研究,一个基础性的技术瓶颈亟待解决:智能体如何高效地使用科技文献?
智源研究院率先洞察这一核心痛点:今天,科技文献的利用方式仍然是为人类用户设计的。在传统模式下,智能体必须通过繁琐的互联网搜索及网页解析才能获取相关论文,还需进一步借助复杂的阅读工具,才能从高度视觉化的论文中提取有效信息。
这套基于搜索引擎(Search Engine)与图形用户界面(GUI)的基础设施,与智能体的工作方式高度不符,严重制约了智能体的工作效果与执行效率。
换句话说,我们坐拥海量开放科技文献,却缺少一套面向智能体的"科技文献基础设施"。
如果说过去的论文仅仅是"给人看的",那么现在,论文需要兼顾"给智能体看"这一全新需求。
一个行之有效的做法是:让论文成为 CLI,使智能体可以方便地获取并加以利用。
因此,智源研究院联合高校与开源社区攻坚突破,提出让论文适配 CLI 交互、搭建专属文献基础设施的核心思路,打通海量开放论文与智能体的衔接壁垒,为自动化科研筑牢核心基础设施底座。
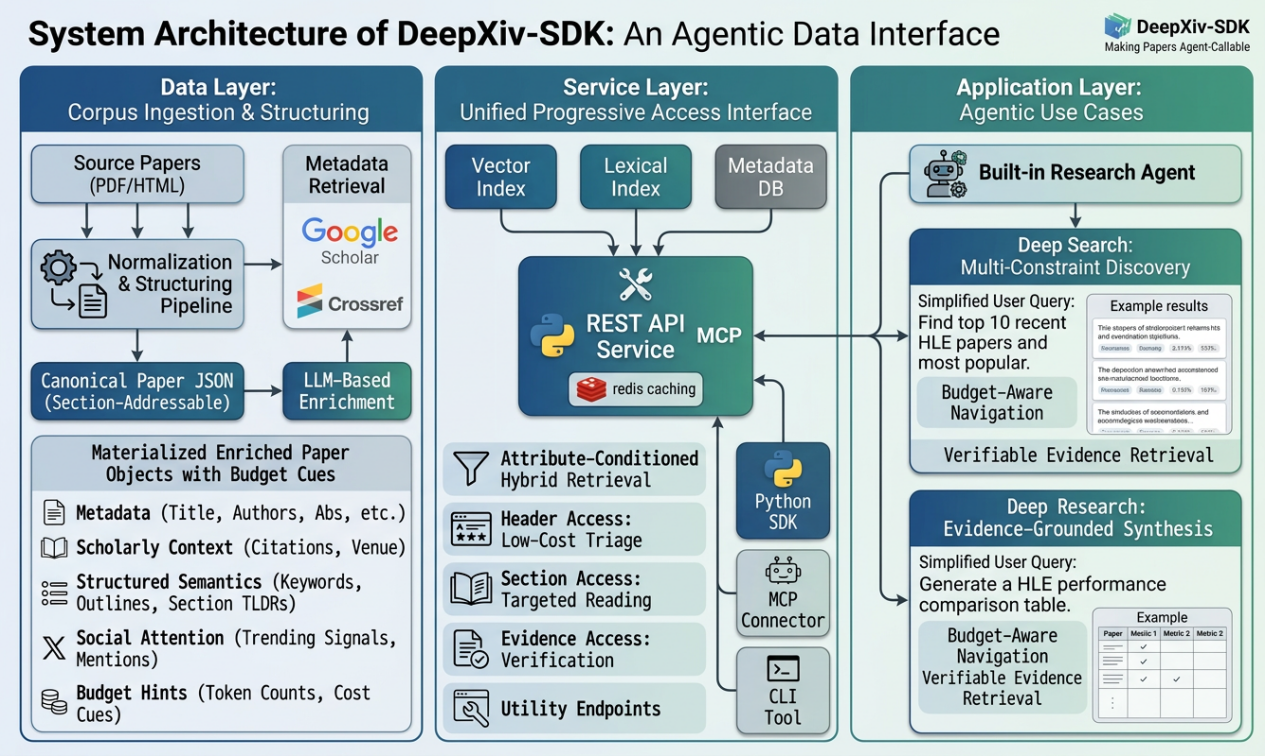
DeepXiv
DeepXiv 是面向智能体的科技文献综合性工具集,其目标是让开放科技文献从"人类可读"升级为"智能体可用"。
为此,DeepXiv 提供三大核心能力。
一、数据接入:把开放科技文献变成"智能体可消费的数据"
DeepXiv 可接入对智能体友好的数据格式,如JSON / Markdown 原生支持。论文数据变得直接可读、可用,智能体不再需要从复杂的 PDF 及 HTML 文件中"艰难扒取信息"。此外,智能体还可以直接获取标题、作者、摘要、参考文献等元信息,使论文利用更加便捷。
同时,对智能体而言,真正的考验不仅是如何获取信息,而是如何在有限上下文和有限推理预算下,精准地利用信息。围绕这一点,DeepXiv 提供了面向智能体优化的数据组织方式。如在预览(Preview)层面,DeepXiv 先快速获取论文核心信息,低成本判断相关性;再通过分块(Chunking)功能按结构或语义切分论文内容,支持论文局部精读;在整体阅读过程中,DeepXiv 还会实现渐进披露(Progressive Disclosure):先看少量、再按需展开,避免一次性灌入整篇长文。
这些设计带来的价值非常直接:降低 token 消耗、提升检索与阅读效率,同时支持复杂多步科研任务,让智能体得以专注于真正有价值的信息。
这并不是一种停留在理念层面的设计,而是可以直接落到具体调用方式中。围绕一个新研究主题,智能体最自然的动作不是一开始就把整篇论文全部读完,而是先搜索候选文献,再快速判断是否值得继续投入更多上下文预算,最后只展开真正关键的部分。例如:
|
Bash |
这组命令对应的正是一个非常贴近真实研究过程的文献利用路径:
- search 先找候选论文,
- --brief 预览论文核心信息,用极低成本判断论文价值,
- --head 帮助智能体掌握全文结构与章节分布,
- --section 让 Agent 按需读取 Introduction、Method、Experiments 这类最有价值的内容。其结果并不是简单地"少读一点",而是让智能体真正具备按信息价值分配 token 预算的能力。
Deepxiv 返回的论文内容,是完成解析的 markdown 或 json 格式,Agent 阅读无压力!比如下面就是--brief 和--head命令的返回内容。
|
YAML
|
|
JSON |
DeepXiv 已覆盖全量 ArXiv 数据,并保持每日增量更新。
与此同时,DeepXiv 正在快速扩展至更多开放文献源,包括 PubMed Central (PMC)、ACM、bioRxiv / medRxiv / ChemRxiv 等各类 *Rxiv,以及 Semantic Scholar,最终建立覆盖超过 2 亿篇开放科技文献的统一智能体接入层。
这种扩展并不会停留在"数据收进来了"这一层,而是会继续沿用面向智能体的统一服务方式对外提供。例如,在 PMC 场景下,智能体同样可以通过类似的命令直接获取论文内容:
|
Bash |
这意味着,随着更多开放文献源被接入,智能体面对的并不会是一组彼此割裂、调用方式各异的新接口,而仍然是一套可复用、可迁移、可自动化编排的文献利用方式。换句话说,未来无论是 ArXiv、PMC,还是更多 *Rxiv 与 OA 数据源,都会尽可能以一致的方法向智能体持续开放服务能力。
二、一站式能力集成:不只是检索,更是"帮智能体做事"
DeepXiv 自建有专属的论文搜索引擎,提供优化的检索结果及可配置的搜索模式。当然,仅仅把论文"搜出来"远远不够。基于搜索能力,DeepXiv 进一步打造了更丰富的技能:在问答能力层面,DeepXiv 可围绕文献直接完成信息提取与理解,例如:"论文的核心贡献是什么?""实验设置和对比基线是什么?",实现对文献的深入理解;同时DeepXiv 还可实现热点追踪,了解每天 / 每周 / 每月关于某一主题的热点论文有哪些?;在面向复杂问题时,DeepXiv 还将开展深入研究,例如:"过去三年关于 Agent Memory 的代表性工作有哪些?""多模态检索增强在金融场景中的公开基准及数据集有哪些?"
DeepXiv 的技能包仍在持续扩展,智能体可通过其内置 Skills 以及命令行 --help 机制进行感知并灵活调用。
这种"不只是检索,更是围绕任务去调用能力"的特点,在实际使用时会更明显。比如,一个很典型的热点追踪流程,可以简单到下面这样:
|
Bash |
先抓出近一周最热的论文池,再快速预览单篇论文内容,并补上它在社交媒体上的传播热度。接下来,智能体就可以顺着这条链路继续完成摘要、筛选、排序与生成周报。
而如果任务是进入一个新研究主题,流程同样可以非常直接:
|
Bash |
先找到候选论文,再查看结构,最后只读取最关键的实验部分。必要时,智能体还可以继续调用互联网搜索补充通用 Web 信息,或者基于Semantic Scholar数据库获取论文元数据。也就是说,DeepXiv 提供的不是孤立命令,而是一套可被智能体连续调用的科研任务能力集。
|
Bash |
如果希望进一步把这些能力直接收束成一个可交付任务,DeepXiv 还内置了深度调研 Agent。它可以把搜索、筛选、渐进式阅读、信息提取与归纳整理串成一条完整链路,让用户不必自己手动拼接每一步调用。例如,开发者可以直接让它回答"最近关于 Agent Memory 的代表性工作有哪些?"或者"过去一年有哪些值得关注的多模态检索增强论文?" 这使得 DeepXiv 不仅能提供底层命令,更能直接承接一部分高层科研任务。 当然,用户也可把 DeepXiv 直接封装成 Skills,注入任意 Agent,快速开始Agent 研究工作。
|
Bash |
三、丰富的接入形式:适配从智能体到开发者的全场景需求
DeepXiv 并不将自己限定为一个单点工具,而是提供多种接入形态,满足从智能体到开发者的多层需求。
首先,CLI 是 DeepXiv 的核心形态。通过命令行,智能体可以无缝接入文献搜索、论文获取、论文利用等全部能力,并通过编排运行脚本实现更复杂的工作流。
其次,DeepXiv 同样提供 MCP 接入能力,这意味着你可以将 DeepXiv 嵌入各类智能体开发框架,让"科技文献利用"成为智能体的标准工具。
再者,对于需要深度定制工作流的开发者,DeepXiv 也提供 Python SDK,使之灵活集成于高度定制化的科研智能体。
更重要的是,基于 deepxiv,开发者可以非常快速地封装出一批面向具体科研任务的定制化 Skills。比如,每周自动追踪某个方向的新论文、自动筛出带开源代码的工作、批量抽取实验设置与结果、生成某个主题的 baseline 表格,甚至持续维护某个研究方向的动态知识库。这意味着,DeepXiv 不只是提供一个"可调用的工具",而是在为日常科研工作流提供一层可快速复用、可持续扩展的能力底座。
实战演示:让 Codex 整理 30天内 Agent Memory 相关论文信息
如果说前面这些能力描述的是 DeepXiv 能做什么,那么更能体现它价值的,其实是它如何在一次真实任务中把这些能力串起来。
下面这个 demo,对应的是一个非常典型、也非常高频的科研需求:
帮我整理最近 1 个月 agent memory 相关 paper,看看都在什么数据集上跑的,效果如何,有没有开源。
这个任务看起来像是"找几篇论文总结一下",但真正做起来,通常会包含一整条链路:先确定时间范围,限定最近一个月。再围绕主题做搜索,并处理噪声结果,并对候选论文逐篇预览,筛掉只是词面相关但主题不符的工作。在找到真正 relevant 的论文后,继续查看结构与实验章节,并提取 benchmark、metrics、score、code link 等关键信息,最后整理成一张可交付、可继续编辑的 markdown baseline 表。
如果没有面向智能体的数据与工具支持,这个过程往往意味着来回切网页、翻 PDF、复制粘贴、再人工整理成表格。而在 DeepXiv 的工作流里,这件事可以被拆解成一组非常自然的动作。
第一步:按主题与时间范围搜索候选论文

首先,智能体会围绕用户主题做多个近义搜索,而不是只押宝一个 query:
|
Bash |
这样做的好处是,智能体可以先尽可能召回足够多的候选论文,再在后续步骤里用更低成本的方式逐步收缩范围。
在这一步里,它很快就能找到像 AdaMem、All-Mem、D-MEM、Memex(RL)、AndroTMem、LMEB 这类高相关论文,同时也能识别出一些只是沾到关键词、但其实不属于 agent memory 主线的结果。
第二步:先用 brief 做低成本筛选
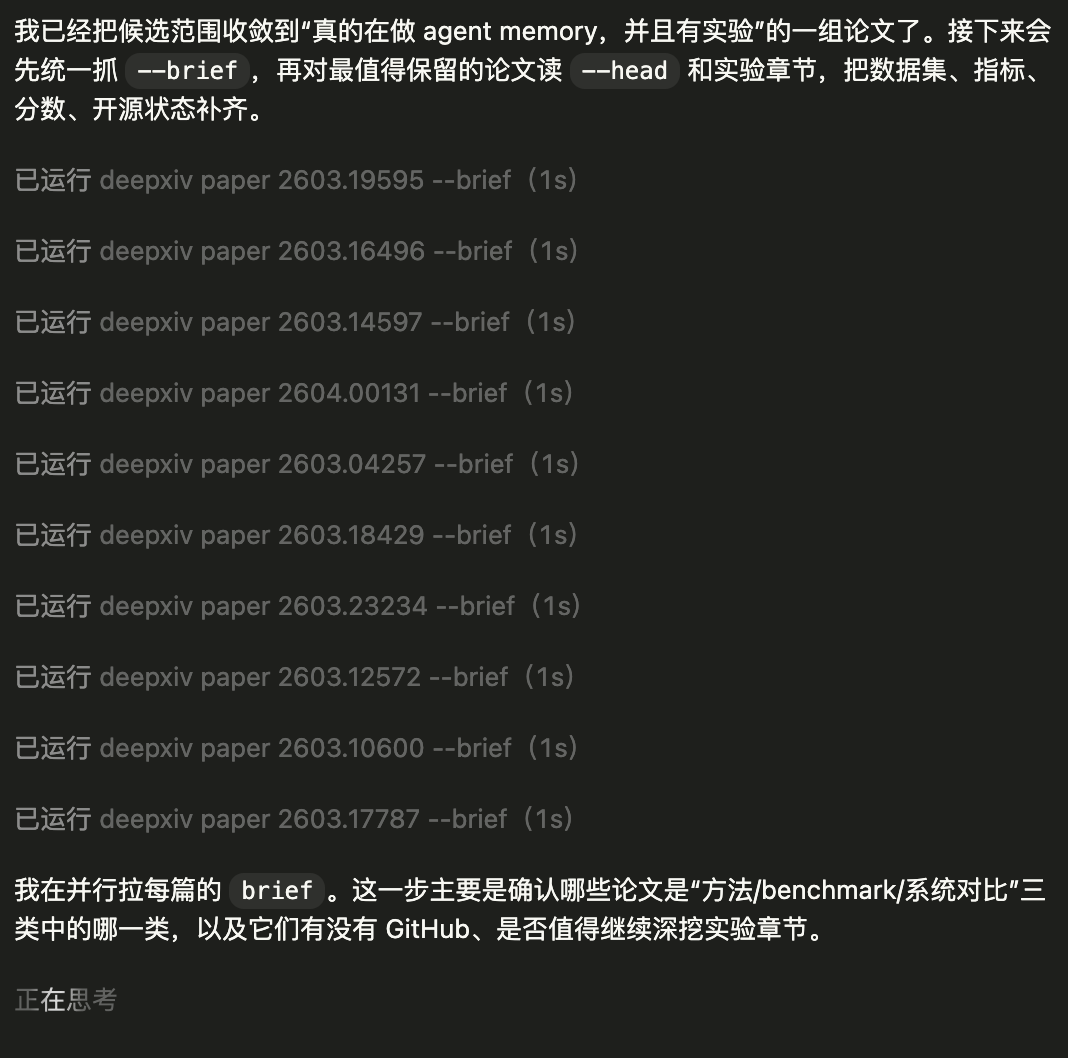
搜索出来的结果,没必要一上来就整篇通读。更合理的做法是先预览:
|
Bash |
--brief 会把标题、时间、TL;DR、关键词、GitHub 链接等最关键的信息先拿出来。对智能体来说,这一步的价值非常大,因为它可以用极低的 token 成本完成第一轮判断:比如说“这篇论文到底是不是在做 agent memory”、“它是方法论文、benchmark 论文,还是更偏系统/治理架构”、“有没有 GitHub,值不值得优先继续读”?
也正是在这一层,智能体可以快速把候选论文拆成主集合和次集合,避免在一堆边缘相关结果上浪费预算。
第三步:用 head 看结构,再只读实验相关章节
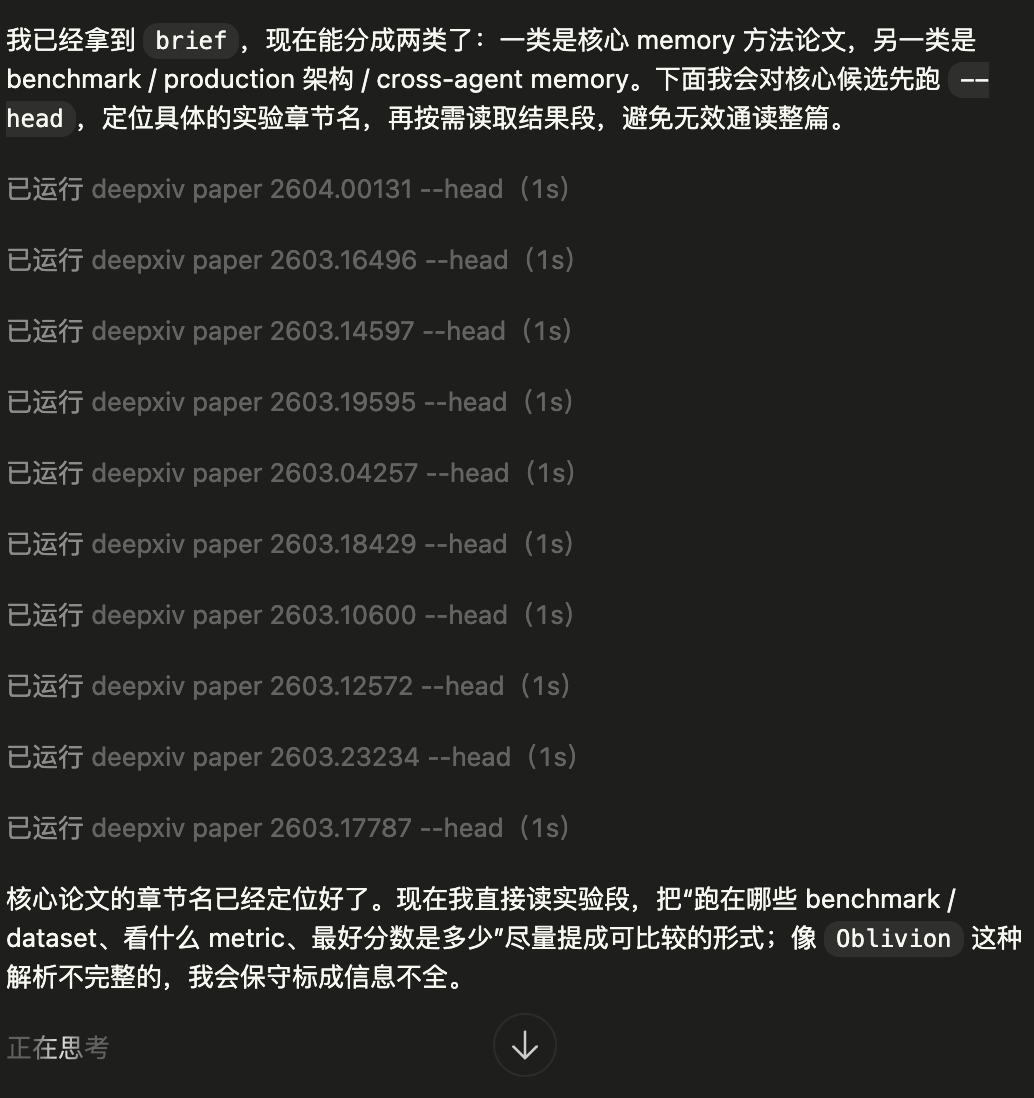
筛出真正 relevant 的论文之后,下一步不是"把全文喂进去",而是先看结构,再定点读取:
|
Bash |
这一步对应的是一个非常像人类研究者的过程:比如人类研究者会先看这篇论文有哪些章节,确认实验部分叫什么,再只展开 Experiments、Results、Evaluation 这种真正有 benchmark 和 score 的内容。如果有需要,再补读 Appendix 中的数据集或实验设置部分。

例如,在这次任务中,智能体就从实验章节里提取到了很多直接可比较的信息:
- AdaMem 在 LoCoMo 和 PERSONAMEM 上评测,LoCoMo 最高到 44.65 F1,PERSONAMEM 平均准确率 63.25%
- AndroTMem 提出 AndroTMem-Bench,并比较 raw history、summary、ASM 三种 history 表示,像 Gemini-3-Flash 在 ASM 下可达到 AMS 59.03 / TCR 65.05
- Memex(RL) 在改造后的 ALFWorld 上,把任务成功率从 24.22% 提升到 85.61%
- Trajectory-Informed Memory Generation 在 AppWorld 上把 held-out 场景的 SGC 从 50.0 拉到 64.3
- LMEB 作为 benchmark 则汇总了 22 个数据集、193 个 zero-shot retrieval 任务
换句话说,DeepXiv 在这里提供的不是"把论文内容给出来"这么简单,而是让智能体可以按照"先粗筛、再结构化定位、最后定点精读"的方式去消费文献。
第四步:自动落成 markdown baseline 表
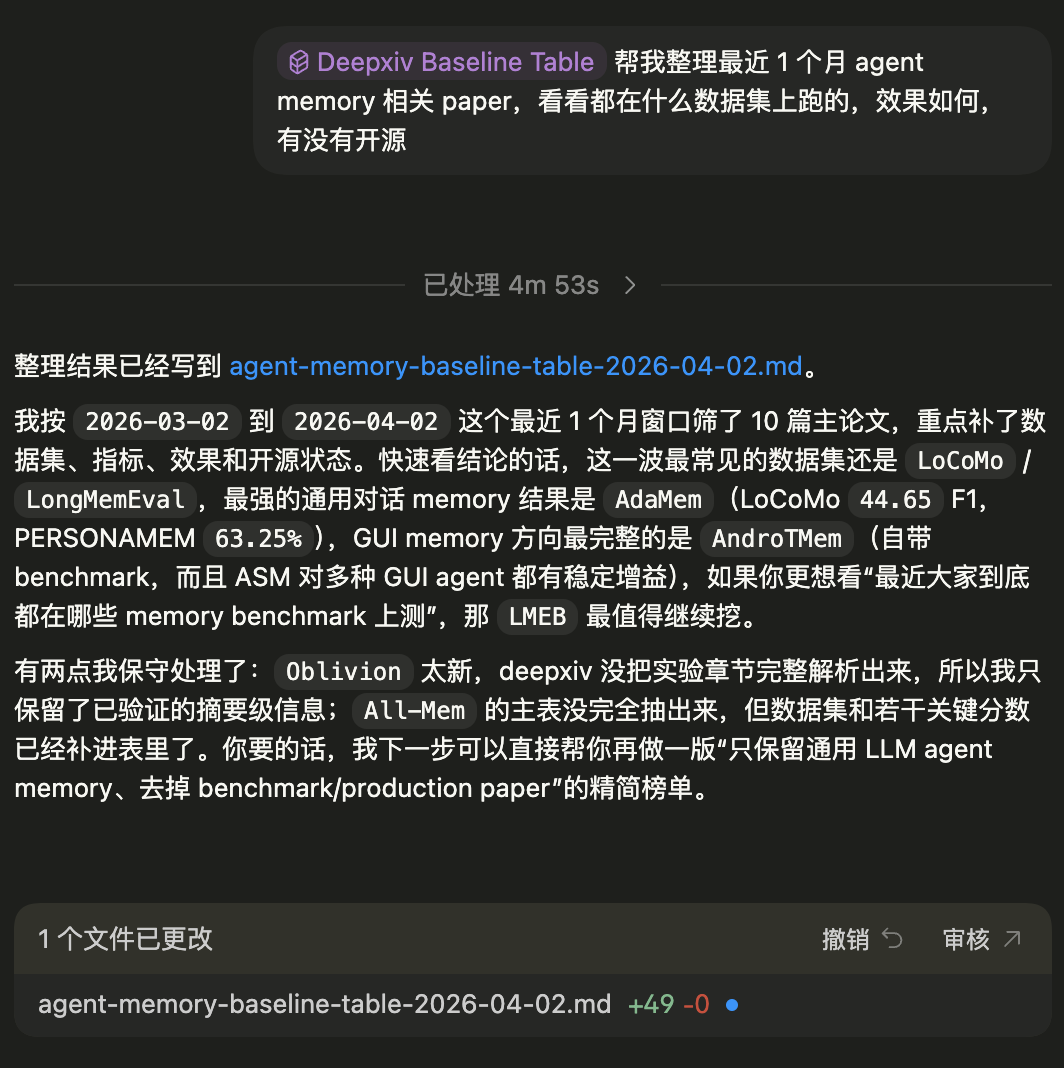
当论文、数据集、指标、分数和开源状态都被提取出来后,最后一步就是把它整理成结构化交付物。
在这次 demo 里,智能体最终把结果写成了一份 markdown 表格,包含:论文标题与 arXiv 链接,是否开源、代码地址,跑过哪些 benchmark / dataset,使用了什么指标,核心结果与可对比分数,对论文定位的简短备注等内容。
这一步很关键,因为它意味着 DeepXiv 服务的不是一次性问答,而是一个可以继续复用的研究资产:你可以直接把 markdown 文件继续改写成调研文档、slides、周报,或者作为后续项目的 baseline 起点。
这个 skills 已经放到 project 中,可以直接使用!例如,复制到 ~/.codex/skills/目录下即可在 codex 中直接唤出。
这个 demo 真正说明了什么
这个例子真正有意思的地方在于,它并不是一个"炫技式"任务,而是一个非常日常、非常真实的科研动作。
对于研究者而言,"最近一个月这个方向都出了什么工作、跑了哪些数据集、效果怎么样、有没有开源"本就是高频需求。而DeepXiv首次以真正贴近智能体工作流的方式完成了这一任务:其搜索是结构化的,无需网页解析;预览是低成本的,无需通读全文;阅读是渐进式的,仅展开关键章节;提取结果面向表格与下游任务,而非停留在自然语言总结;最终输出更可保存、可复用、可继续扩展,成为研究过程中的中间产物。
这也正是 DeepXiv 想解决的核心问题:不是把论文"搬上命令行",而是把论文真正变成智能体可以调用、筛选、阅读、分析、交付的一等对象。
如果说传统论文网站服务的是"人类点开页面然后自己读",那么 DeepXiv 服务的则是"智能体围绕科研任务主动调用文献能力并完成交付"。

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐


 10
10 0
0- 0



 已为社区贡献1030条内容
已为社区贡献1030条内容

所有评论(0)