图像生成(AI绘画)的发展史:从DALLE、DALLE 2、DALLE 3到Stable Diffusion、SDXL、SD3(含ControlNet详解)
前言
终于开写Stable Diffusion相关的了,为何执着于想写这个Stable Diffusion呢,源于三点
- 去年22年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开
- 去年22年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇ChatGPT原理文章下面留言:
——————
“ 点赞,十年前看你的svm懂了,但感觉之后好多年没写了,还有最近的AI绘画 stable diffusion 相关也可以写一下,以及相关的采样加速算法
我当时回复到:哈,十年之前了啊,欢迎回来,感谢老读者、老朋友
确实非常非常多的朋友都看过我那篇SVM笔记,影响力巨大,但SVM笔记之后,也还是写了很多新的博客/文章滴,包括但不限于:xgboost、CNN、RNN、LSTM、BERT等
今后基本每季度都有更新的计划,欢迎常来
关于Stable Diffusion,可以先看下这篇图解Stable Diffusion的文章 ”(此篇文章也是本文的参考之一) - 今23年3月中旬,当OpenAI宣称GPT4具备了CV多模态的能力之后,让我对AI绘画和CV多模态有了更强的动力去研究探索,并把背后的技术细节写出来
其实当时就想写了,但当时因为写各种开源平替模型的原理、部署、微调去了,所以一直没来得及写,包括之前计划的100篇论文也因此耽搁
今23年4.23,我所讲的ChatGPT原理课开课之后,终于有时间开写这篇多模态博客
然想写清楚stable diffusion和midjourney背后的技术细节,不得不先从扩散模型开始,于此便有了上一篇《图像生成的奠基与起源:从AE、VAE、VQ-VAE到扩散模型DDPM(含加噪、去噪全过程)、DDIM(含U-Net的简介)》——且如果你此前不了解何谓扩散模型、何谓DDPM,建议先看该文
- 援引上一篇文章的这段话“AI绘画随着去年stable diffusion和Midjourney的推出,使得文生图火爆异常,各种游戏的角色设计、网上店铺的商品/页面设计都用上了AI绘画这样的工具,更有不少朋友利用AI绘画取得了不少的创收,省时省力还能赚钱,真香”
且包括我司LLM项目团队开发的AIGC模特生成系统也用到了这方面的技术:基于SD二次开发 - 沿着上文之后,本文将写清楚下面表格中带下划线的模型,且不同颜色代表不同的发展线,比如
第一部分介绍CLIP BLIP这条线
25年8.22,本第一部分已独立出去成此文:《图文对比学习的发展史:从CLIP、BLIP、BLIP2到InstructBLIP(含MiniGPT4的详解)》
第二部分介绍DALL·E这条线
第三部分介绍stable diffusion这条线
1月 2月 3月 4月 5月 6月 8月 9月 10月 11月 20年 DETR DDPM DDIM
VisionTransf..
21年 CLIP
DALL·E
SwinTransformer MAE
SwinTransf..V2
22年 BLIP DALL·E 2 StableDiffusion
BEiT-3
Midjourney V3
23年 BLIP2 ControlNet VisualChatGPT
GPT4
Midjourney V5
SAM(Segment Anything Model) InstructBLIP FastSAM
(中科院版SAM)
MobileSAM
DALLE3 且过程中,如果有机会 则顺带介绍MiniGPT-4、VisualGPT到HuggingGPT、AutoGPT这几个模型
第一部分 从DALLE到DALLE 2、DALLE 3
1.1 DALL-E:Zero-Shot Text-to-Image Generation
有趣的是,DALL-E和CLIP一样,也是21年年初发布的,对应论文为《Zero-Shot Text-to-Image Generation》,其参数大小有着12B,其数据集是2.5 亿个图像文本对
- 通过上一篇文章可知,VQ-VAE的生成模式是pixcl-CNN +codebook,其中pixcl-CNN就是一个自回归模型
- OpenAI 将pixcl-CNN换成GPT,再加上那会多模态相关工作的火热进展,可以考虑使用文本引导图像生成,所以就有了DALL·E
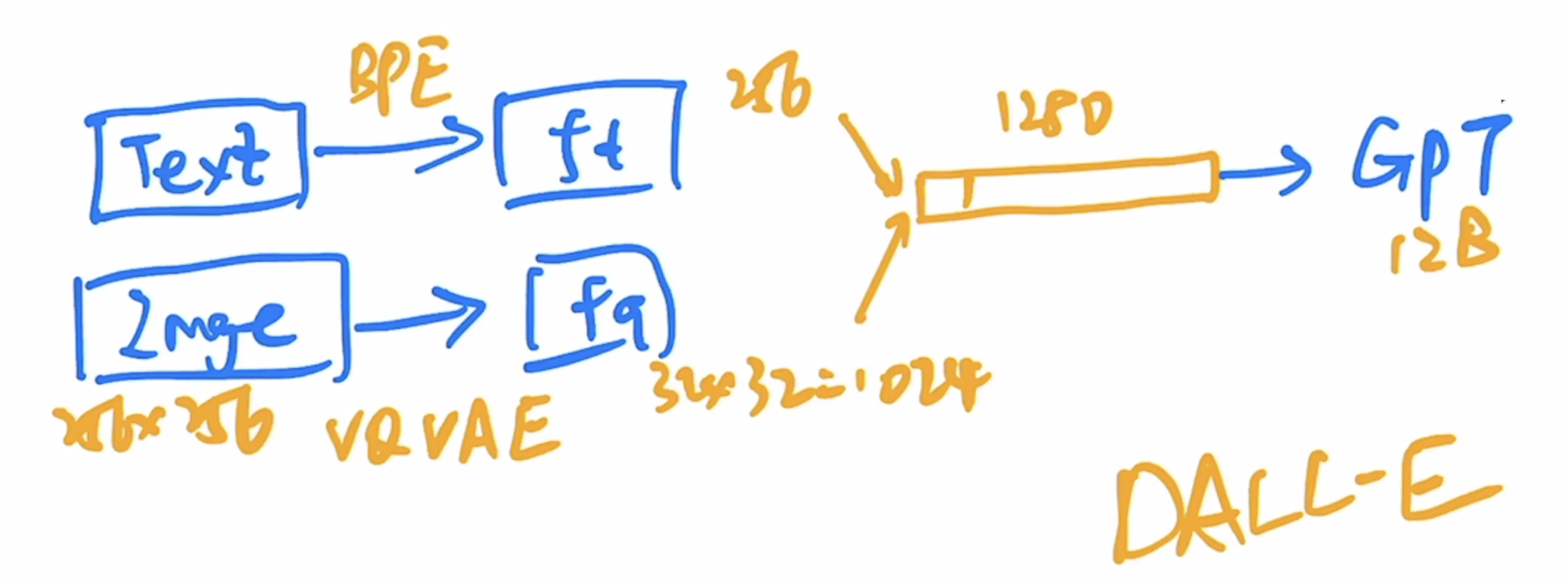
DALL·E和VQ-VAE-2一样,也是一个两阶段模型:
- Stage1:Learning the Visual Codebook
先是输入:一对图像-文本对(训练时),之后编码特征,具体编码时涉及到两个步骤
首先,文本经过BPE编码得到256维的特征
其次,256×256的图像经过VQ-VAE(将训练好的VQ-VAE的codebook直接拿来用),得到32×32的图片特征
We train a discrete variational autoencoder (dVAE) to compress each 256×256 RGB image into a 32 × 32 grid of image tokens - Stage2:Learning the Prior
重构原图
将拉直为1024维的tokens,然后连上256维的文本特征
,这样就得到了1280维的token序列,然后直接送入GPT(masked decoder)重构原图
推理时,输入文本经过编码得到文本特征,再将文本通过GPT利用自回归的方式生成图片,生成的多张图片会通过CLIP模型和输入的文本进行相似度计算,然后调出最相似(描述最贴切)的图像
1.2 DALLE 2:Hierarchical Text-Conditional Image Generation with CLIP Latents
对于DALL·E2而言,基本就是整合了CLIP和基于扩散模型的GLIDE,而后者则采用了两阶段的训练方式:文本 → 文本特征 → 图片特征 → 图片
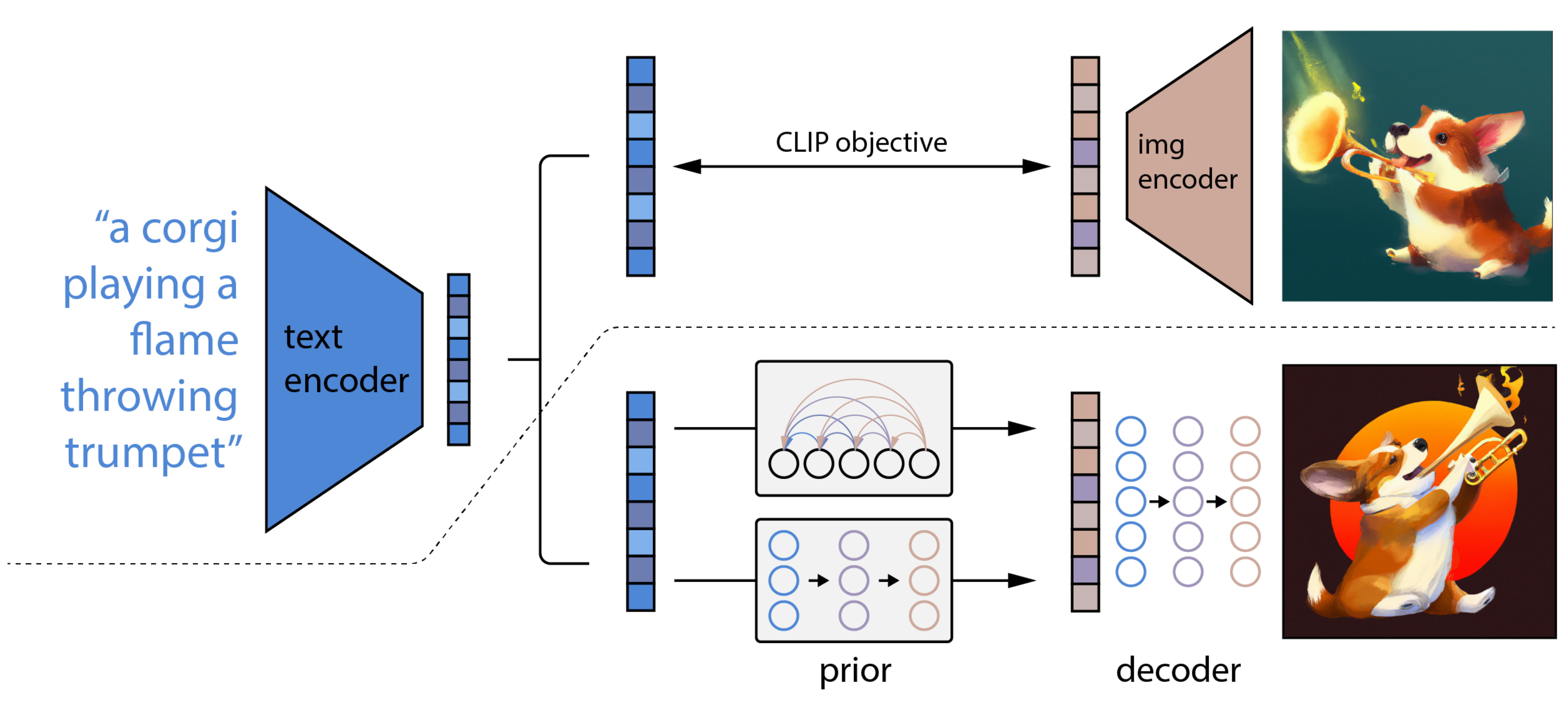
- CLIP训练过程:学习文字与图片的对应关系
如上图所示,CLIP的输入是一对对配对好的的图片-文本对(根据对应文本一条狗,去匹配一条狗的图片),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征,然后在这些输出的文字特征和图片特征上进行对比学习 - DALL·E2:prior + decoder
上面的CLIP训练好之后,就将其冻住了,不再参与任何训练和微调,DALL·E2训练时,输入也是文本-图像对,下面就是DALL·E2的两阶段训练:阶段一 prior的训练:根据文本特征(即CLIP text encoder编码后得到的文本特征),预测图像特征(CLIP image encoder编码后得到的图片特征)
换言之,prior模型的输入就是上面CLIP编码的文本特征,然后利用文本特征预测图片特征(说明白点,即图中右侧下半部分预测的图片特征的ground truth,就是图中右侧上半部分经过CLIP编码的图片特征),就完成了prior的训练
推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征,此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)
这里的decoder就是升级版的GLIDE(GLIDE基于扩散模型),所以说DALL·E2 = CLIP + GLIDE
1.3 DALLE 3:Improving Image Generation with Better Captions
我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强(其对应的论文为《Improving Image Generation with Better Captions》,作者为James Betker等人)
加之也要在七月官网的论文100课上讲DALLE三代的三篇论文,故接下来,咱们结合DALLE 3和相关paper好好看下DALLE 3的训练细节
1.3.1 为提高文本图像配对数据集的质量:基于谷歌的CoCa微调出图像字幕生成器
目前文生图模型的一个很大的问题是模型的文本理解能力,这个文本理解能力指的是生成的图像是否能和文本保持一致,也就是论文里面所说的prompt following能力
如论文中所说
- 论文提出来字幕改进(caption improvement)的方法
毕竟现在text-to-image模型现存的一个基本问题便是:这些模型训练所用的文本-图像配对数据的质量较差
We hypothesize that a fundamental issue with existing text-to-image models is the poor quality of the text and image pairing of the datasets they were trained on - 故论文提出可以通过改进「文本-图像配对数据集中的针对图像的文本描述的质量」来解决这个问题(We propose to address this by generating improved captions for the images in our dataset)
为实现这个目标,首先训练一个强大的图像字幕生成器(image captioner),以生成详细、准确的图像描述,然后我们便可以把这个图像字幕生成器应用到已有的文本-图像配对数据集中,以为各个图像生成更详细、准确的图像描述或字幕,最后在改进的数据集上训练text-to-image模型
We do this by first learning a robust image captioner which produces detailed, accurate descriptions of images. We then apply this captioner to our dataset to produce more detailed captions. We finally train text-to-image models on our improved dataset.
总之,对于稍微复杂的文本,目前的文生图模型生成的图像往往会容易忽略部分文本描述,甚至无法生成文本所描述的图像。这个问题主要还是由于训练数据集本身所造成的,更具体的是说是图像caption不够准确
- 一方面,图像常规的文本描述往往过于简单(比如COCO数据集),它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等
- 另外一方面,目前训练文生图的图像文本对数据集(比如LAION数据集)都是从网页上爬取的,图像的文本描述其实就是alt-text,但是这种文本描述很多是一些不太相关的东西,比如广告。训练数据的caption不行,训练的模型也就自然而然无法充分学习到文本和图像的对应关系,那么prompt following能力必然存在问题
1.3.1.1 什么是谷歌的CoCa
OpenAI最终基于谷歌的CoCa来训练这个image captioner来合成图像的caption,CoCa构建在encoder-decoder的基础上
- 其中,Image Encoder和Text Decoder均采用Transformer模型
- 其中,Image Encoder的参数量为1B,而Text Decoder的参数量达到1.1B,这样整个CoCa模型的参数量为2.1B(对于图像,其输入大小为288×288,而patch size为18x18,这样总共有256个image tokens。同时,这里也设计了两个更小模型:CoCa-Base和CoCa-Large)

不过这里将text decoder均分成两个部分:
- 一个单模态解码器unimodal text decoder
- 一个多模态解码器multimodal text decoder
然后增加一个cls token在文本的最后(CoCa相比CLIP额外增加了一个Multimodel Text Encoder来生成caption,如此,它训练的损失包含了CLIP的对比损失和captioing的交叉熵损失,所以CoCa不仅可以像CLIP那样进行多模态检索,也可以用于caption生成)
具体而言,如下图的左半部分所示
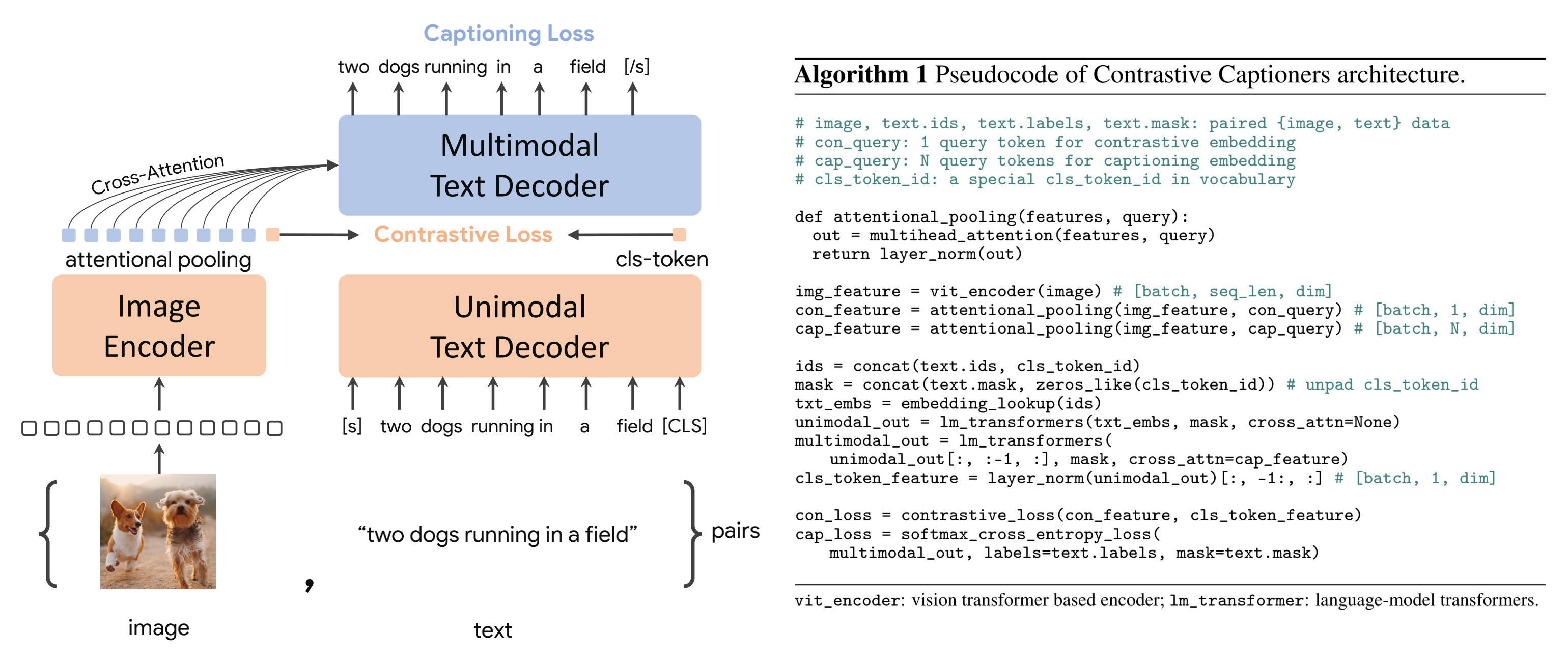
- unimodal text decoder不参与对图像特征的cross-attention(We omit cross-attention in unimodal decoder layers to encode text-only representations,相当于把 Transformer Decoder 中的cross attention去掉,只保留 masked self-attention 和 FFNN)
两个全局特征就可以实现图像-文本的对比学习「相当于image encoder和unimodal text decoder的两个[CLS]向量作为图片和文本的表示,进行batch 内对比学习,同 CLIP」 - multimodal text decoder将用来执行生成任务,这里也通过一个attention pooling对image encoder得到的特征进行提取,不过这里query数量定义为256,这样attention pooling可以得到256个特征,它作为multimodal text decoder的cross-attention的输入(cascademultimodal decoder layers cross-attending to image encoder outputs to learn multimodal image-textrepresentations)
相当于就是正常的Transformer Decoder,包含masked self-attention、cross-attention、FFNN,用于融合图片和文本信息,实现双模态,最后做文本生成 - 所以,CoCa将同时执行对比学习和文本生成任务,它的训练损失也包括两个部分:
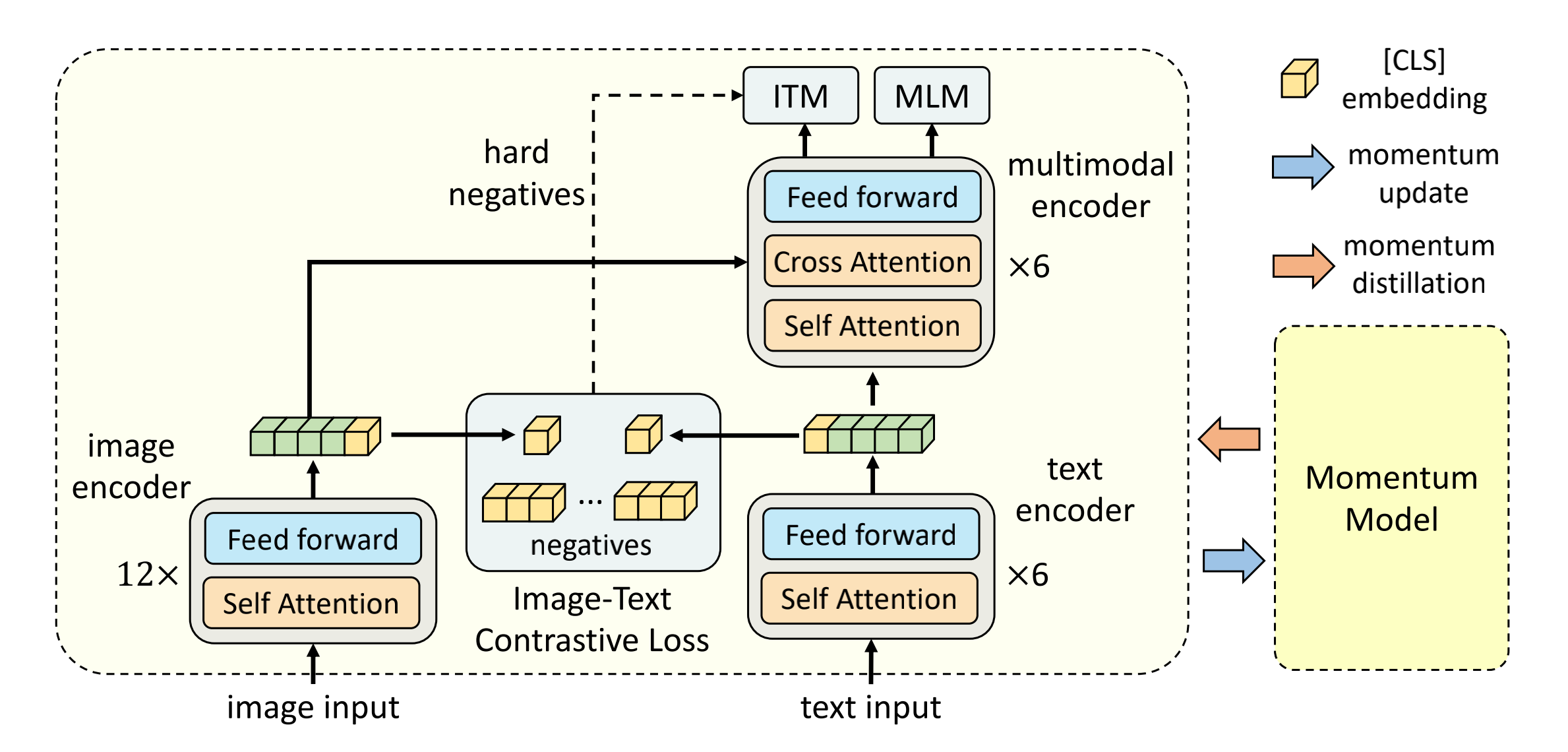
顺带说一句,这个CoCa和如下图所示的ALBEF(这是其论文)还挺像的,所以有人评论它两的关系就像BERT和RoBERTa(可以简单理解为是对BERT的精调)
- 但CoCa 与 ALBEF 最大的不同在于:CoCa 右侧处理文本和进行多模态融合的网络是一个 decoder,而非ALBEF那里是 encoder
- 再说一句,其实下图的下半部分不就是类似一个CLIP么?^_^
1.3.1.2 分别通过短caption、长caption微调预训练好的image captioner
为了提升模型生成caption的质量,OpenAI对预训练好的image captioner进行了进一步微调,这个微调包括两个不同的方案,两个方案构建的微调数据集不同
- 第一个方案的微调数据集是只描述图像主体的短caption(类似COCO风格的caption)
- 而第二个方案的微调数据集是详细描述图像内容的长caption
相应地,两个微调模型分别可以生成:短caption(short synthetic captions,简称SSC)、长caption(descriptive synthetic captions,简称DSC)
下图展示了三个样例图像各自的原始caption(ground-truth),以及生成的短caption、长caption

- 每个样例图像的原始caption是从网页上得到的alt-text,其质量较差
- 每个样例图像的合成的短caption简洁地描述了图像的主体内容
- 每个样例图像的合成的长caption详细描述了图像的很多内容,细节比较丰富
1.3.1.3 为提高合成caption对文生图模型的性能:采用描述详细的长caption,训练的混合比例高达95%
接下来要解决两个问题
- 通过实验来分析合成caption对文生图模型性能的影响
- 另外一点是探讨训练过程中合成caption和原始caption的最佳混合比例
这里之所以要混合合成caption和原始caption(opted to blend synthetic captions with ground truth captions),主要是为了防止模型过拟合到合成caption的某些范式
比如最常见的例子是合成的caption往往以"a"和"an"开头,解决这个问题最好的方法便是:通过接近the style and formatting that humans might use,以regularize our inputs to a distribution of text
所以,我们在训练过程中,在合成caption中混入原始caption(human-written text),相当于一种模型正则化
首先是合成caption对模型性能的影响,这里共训练了三个模型,它们的差异是采用不同类型的caption,分别是
- 只用原始caption
- 5%的原始caption + 95%的合成短caption
- 5%的原始caption + 95%的合成长caption
通过上一节对DALLE 2的分析,我们得知最后的文生图decoder模型是基于扩散模型的

而DALLE 3的论文中训练的文生图是latent diffusion模型
- 其VAE和SD一样都是8x下采样
- 而text encoder采用T5-XXL,之所以用T5-XXL,可能主要有两个原因,一方面T5-XXL可以编码更长的文本,另外一方面是T5-XXL的文本编码能力也更强
- 这里训练的图像尺寸为256x256(这只是实验,所以低分辨率训练就足够了),采用batch size为2048共训练50W步,这相当于采样了1B样本
论文中并没有说明UNet模型的具体架构,只是说它包含3个stages,应该和SDXL类似(SDXL包含3个stage,只下采样了2次,第一个stage是纯卷积,而后面两个stages包含attention)
这里只是想验证模型的prompt following能力,所以采用了CLIP score来评价模型,这里的CLIP score是基于以下两者的相似度,即
- CLIP ViT-B/32来计算生成图像的image embedding即
- 和text prompt对应的text embedding即
的余弦相似度(这里是生成了50000个图像并取平均值,并乘以100)
下图展示了采用三种caption训练的模型在CLIP score上的差异:
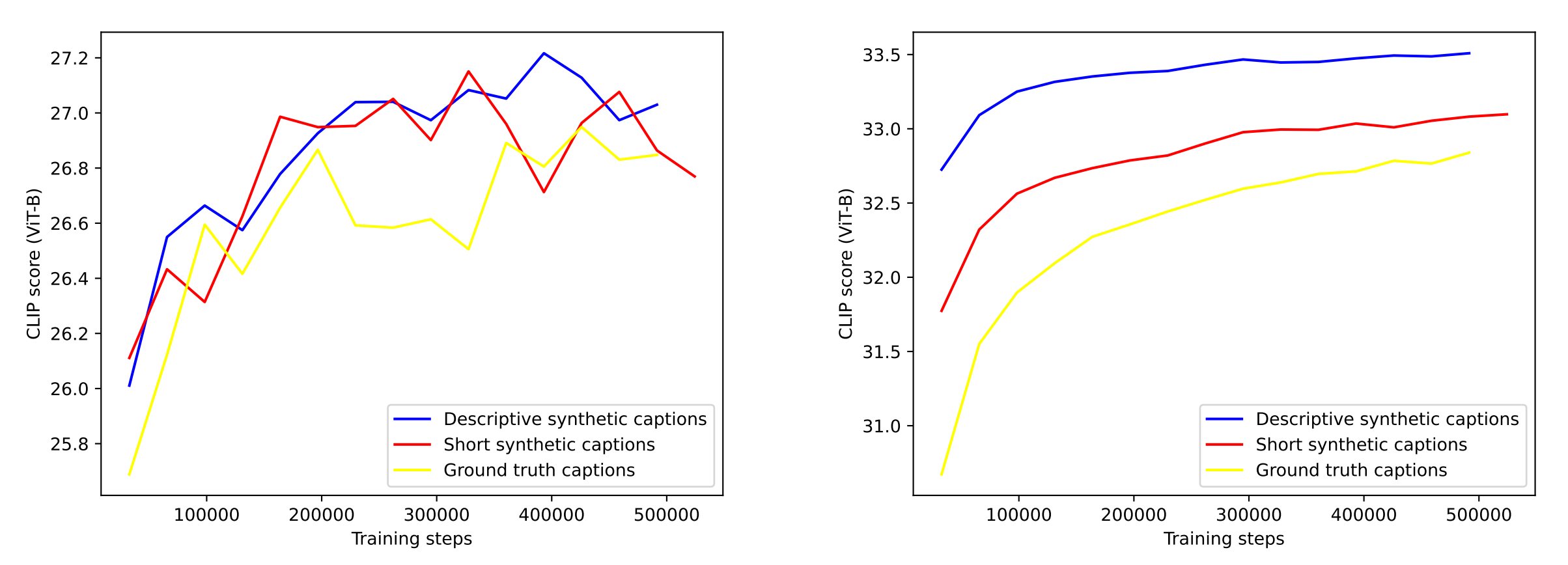
- 左图在计算CLIP score时,text采用原始caption(ground truth caption),从整体上来看,无论是采用合成的长caption还是短caption,其CLIP score比只采用原始caption要好一点,但是波动比较大
- 右图计算CLIP score时,text采用合成的长caption,这里就可以明显看到:合成长caption > 合成短caption > 原始caption,而且CLIP score要比左图要高很多
这说明采用长caption来计算CLIP score是比较合理的,因为图像的image embedding信息很大,而短文本信息少,所以两者的相似度就会低一些,而且还可能存在一定的波动
总之,从上面的实验来看,采用合成的长caption对模型的prompt following能力是有比较大的提升的。
接下来的问题就是通过实验来找到最佳的数据混合比例。所以又增加了混合比例为65%、80%、90%的实验,下图展示了不同混合比例训练出来的模型其CLIP score的差异,可以看到采用95%的合成caption训练的模型在效果上要明显高于采用更低比例的caption训练的模型。
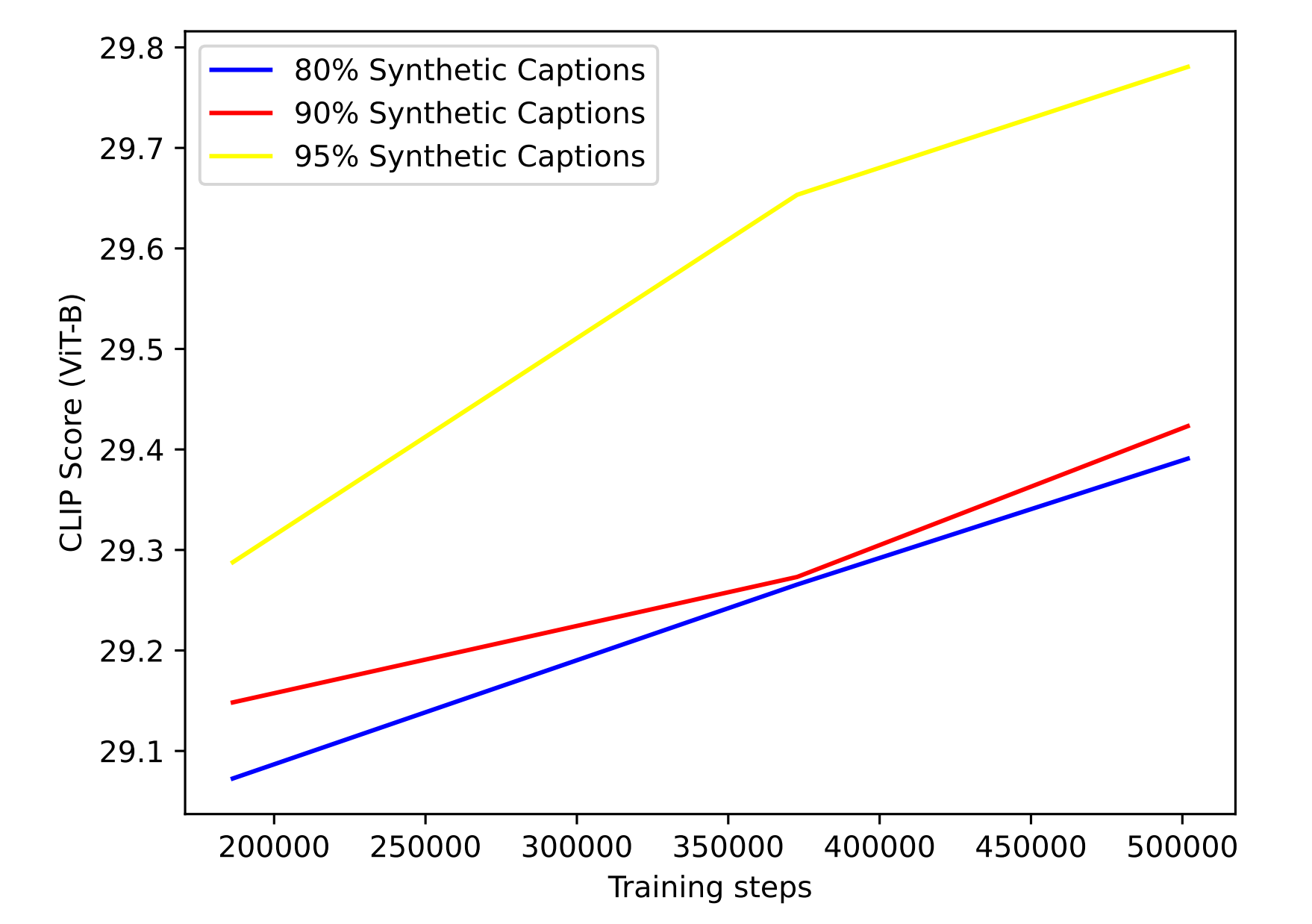
所以最终的结论是采用合成的caption对模型提升帮助比较大,而且要采用描述详细的长caption,训练的混合比例高达95%,这也是后面DALL-E 3的数据训练策略。
不过采用95%的合成长caption来训练,得到的模型也会“过拟合”到长caption上,如果采用常规的短caption来生成图像,效果可能就会变差
为了解决这个问题,OpenAI采用GPT-4来“upsample”用户的caption,下面展示了如何用GPT-4来进行这个优化,不论用户输入什么样的caption,经过GPT-4优化后就得到了长caption:

下图展示了三个具体的例子,可以看到使用优化后的长caption(图中第二排)其生成图像效果要优于原来的短caption(图中第一排):

所以,DALL-E 3接入ChatGPT其实是不得已而为之的事情,因为这样才能保证DALL-E 3的输入不偏离训练的分布
1.3.2 训练细节总结:原始caption和合成长caption混合训练 + T5 + latent decoder
DALLE 3的论文提到,DALL-E 3的具体实现有两个关键点:
- 首先,DALL-E 3也采用95%的合成长caption和5%的原始caption混合训练,这也应该是DALL-E 3性能提升的关键
- 另外,DALL-E 3的模型是上述实验中所采用的模型的一个更大版本(基于T5-XXL的latent diffusion模型),同时加上其它的改进(但论文中并没有说是具体的哪些改进,只说DALL-E 3也不应简单地归功于在合成caption的数据集上训练,所以DALL-E 3的其它改进应该也会比较重要)
目前DALL-E 3生成的图像的分辨率都是在1024x1024以上,所以DALL-E 3的模型应该类似于SDXL,采用递进式的训练策略(256 -> 512 -> 1024),而且最后也是采用了多尺度训练策略来使模型能够输出各种长宽比的图像
另外如小小将所说,附录里面给出了一个细节是
- DALL-E 3额外训练了一个latent decoder来提升图像的细节,特别是文字和人脸方面,这个应该是为了解决VAE所产生的图像畸变。这里采用的扩散模型是基于DDPM中的架构,所以是pixel diffusion
从直观上来看,这个latent decoder就是替换原始的VAE decoder,因此这个扩散模型的condition是VAE的latent
但是具体是怎么嵌入到扩散模型的UNet中,这里没有说明,最简单的方式应该是通过上采样或者一个可学习的网络将latent转变为和噪音图像一样的维度,然后与噪音图像拼接在一起- 同时为了加速,基于Consistency Models中提出的蒸馏策略将去噪步数降低为2步,所以推理是相当高效的
This diffusion decoder is a convolutional U-Net identical to the one described in Ho et al. (2020). Once trained, we used the consistency distillation process described in Song et al. (2023) to bring it down to two denoising steps

1.3.3 DALL-E 3的评测结果
对于DALL-E 3的评测,论文是选取了DALL-E 2和SDXL(加上refiner模块)来进行对比。模型评测包括自动评测和人工评测。
1.3.3.1 针对DALLE 3的自动评测
自动评测主要有3个指标
- 首先是计算CLIP score,评测数据集是从COCO 2014数据集中选择4096个captions
这里的评测数据集是Imagen中所提出的DrawBench评测集(共包括200个包含不同类型的prompts) - 然后是采用GPT-4V来进行评测
这里的评测是将生成的图像和对应的text输入到GPT-4V,然后让模型判断生成的图像是否和text一致,如果一致就输出正确,否则就输出不正确 - 最后是采用T2I-CompBench来评测
这个评测集包含6000个组合类型的text prompts,它包括多个方面,这里只选择color binding、shape binding和texture binding三个方面进行评测,评测是通过BLIP-VQA model来得到评分
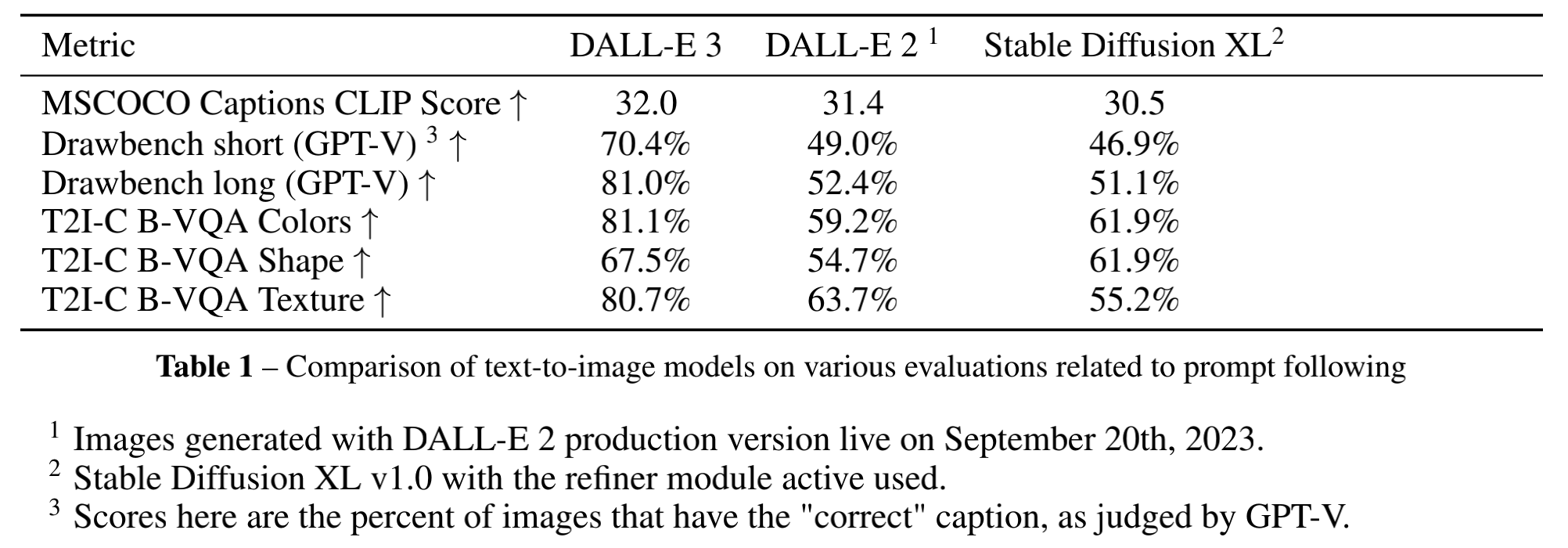
下表给出了DALL-E 3与其它模型的对比结果,可以看到DALL-E 3还是明显优于DALL-E 2和SDXL。不过自动评测所选择的三个指标都是评测模型的prompt following能力,并不涉及到图像质量
1.3.3.2 针对DALLE 3的人工评测
人工评测主要包括三个方面
- 第一个是prompt following,给出两张不同的模型生成的图像,让人来选择哪个图像和文本更一致
- 第二个是style,这里不给文本,只给两张图像,让人选择更喜欢的那个图像
- 第三个是coherence,这里也不给文本,让人从两张图像中选择包含更多真实物体的图像
可以看到后面的两个方面其实就是评测模型生成图像的质量,对于prompt following和style,这里使用的评测集是DALL-E 3 Eval,它共包含170个captions,是从用户应用场景收集得到的。而coherence方面的评测集是从COCO数据集抽样的250个captions,因为coherence是评测真实性,所以采用更偏真实场景的COCO数据集
另外,之前DrawBench评测集是采用GPT-4V来自动评测的,但是GPT-4V也会犯错,比如在计数方面,所以这里也额外增加了DrawBench评测集的人工评测。
所有人工评测的对比结果如表所示,可以看到DALL-E 3具有明显优势:

这里的ELO score是GLIDE中所提出的来计算胜率的指标:

尽管DALL-E 3在prompt following方面有很大的提升,但是它依然有一定的局限性
- 首先是模型在空间位置关系上还是会比较容易出错,当prompt包含一些位置关系描述如"to the left of",模型生成的图像并不一定会符合这样的位置关系,这主要是因为合成的caption在这方面也并不可靠
- 另外就是文字生成能力,虽然DALL-E 3在生成文字方面很强,但是还是会出现多词或者少词的情况,一个可能的原因T5-XXL的tokenizer并不是字符级的
- 还有一个比较大的问题是合成的caption会幻想图像中的重要细节,比如给一幅植物的绘图,image captioner可能会虚构出一个植物并体现在合成的caption上。这就意味着模型可能会学到错误的绑定关系,也导致模型在生成特定种类的东西并不可靠
- 最后一点是模型的安全性和偏见,这个是所有大模型所面临的问题,也是由于训练集所导致的,对于这点,DALL·E 3 system card有更多的评测
第二部分 通俗理解Stable Diffusion:文本到图像的潜在扩散模型LDM
2.1 SD与DDPM的对比
我们在上篇博客《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer》中,已经详细介绍了扩散模型DDPM,为方便对后续内容的理解,特再回顾下DDPM相关的内容(至于详细的请看上篇博客):
前向过程加噪
逆向过程去噪,由于反向扩散过程不可直接计算,因此训练神经网络来近似它,训练目标(损失函数)如下
所以,DDPM的关键是训练噪声估计模型,使其预测的噪声
与真实用于破坏的噪声
相近,具体怎么个训练过程呢?
- 比如可以选择选择一个训练图像,例如海边沙滩的照片,然后生成随机噪声图像,通过将此噪声图像添加到一定数量的步骤来损坏训练图像
- 然后通过一个噪声估计器U-Net 预测添加的噪声,使其与实际噪声做差异对比,从而建立损失函数做反向传播,最后更新噪声估计器的参数
说白了,就是通过告诉U-Net 我们在每一步添加了多少噪声,从而手把手一步步教U-Net 怎么去估计噪声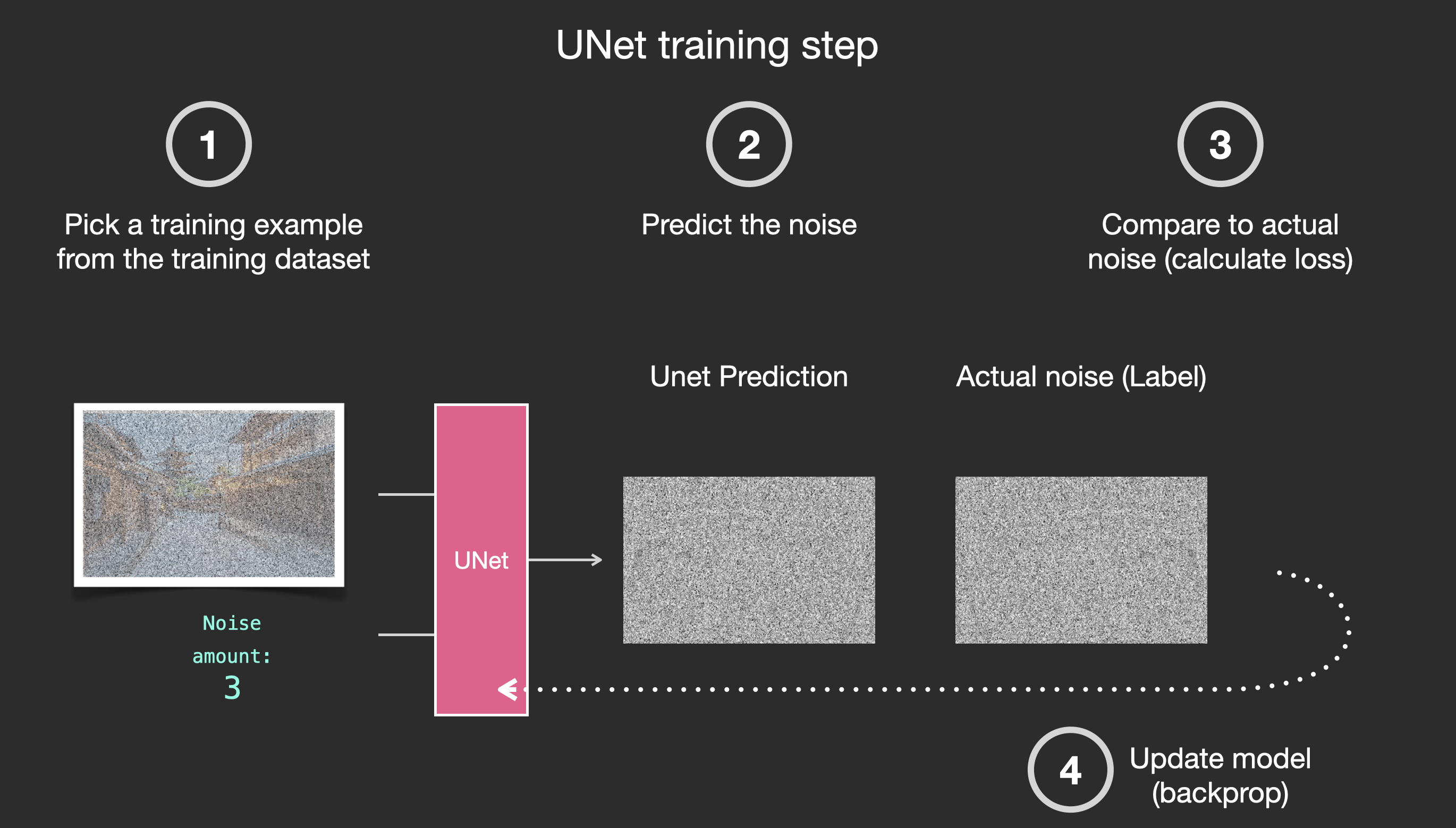
- U-Net训练好了之后(意味着其对噪声的估计比较准确了),我们便可以基于训练好的 U-Net 来生成图像
原理很简单,通过噪声估计器预测出噪声后,不模糊的图片便减去每一步添加的噪声以清晰化 不就ok了么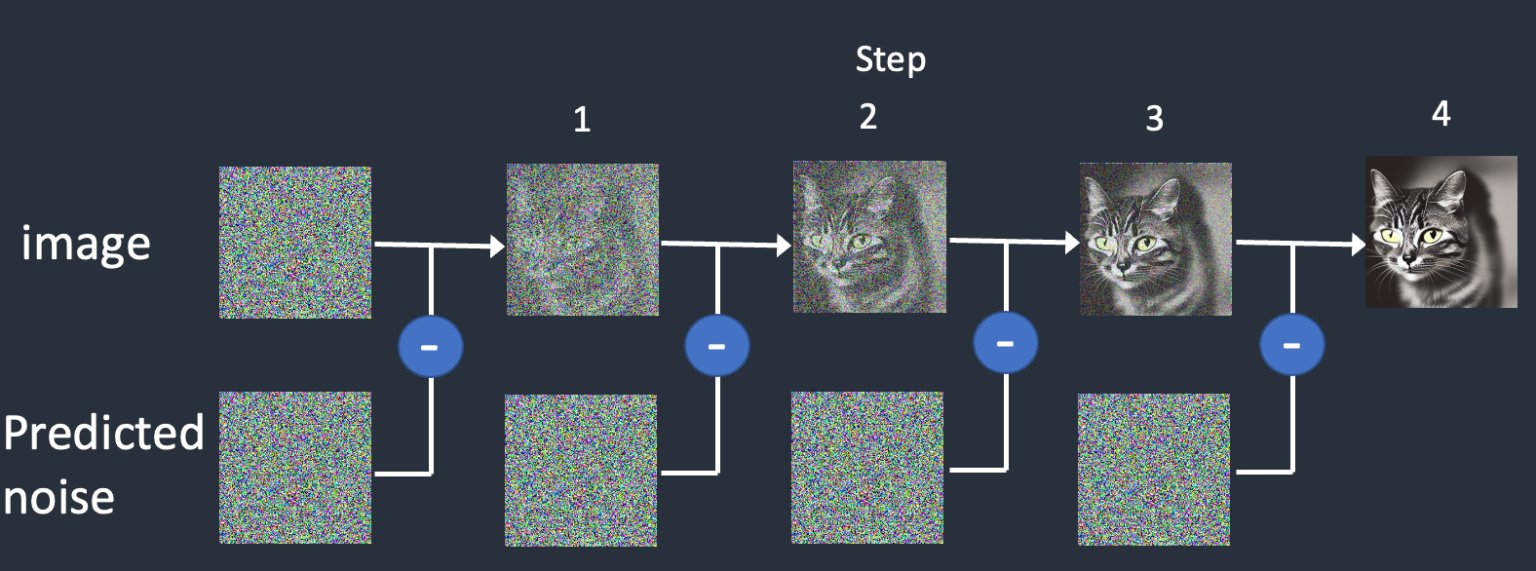
而如果用一句话介绍Stable Diffusion(SD对应的论文为《High-Resolution Image Synthesis with Latent Diffusion Models》,由慕尼黑大学和runway于2021年年底共同提交,其一作为Robin Rombach),可以理解为:改进版的DDPM,Stable Diffusion原来的名字叫:“Latent Diffusion Model”(LDM),很明显就是扩散过程发生隐空间中(即latent space,下文或其他地方也有说潜在空间或压缩空间之类的,都一个意思),其实就是对图片做了压缩
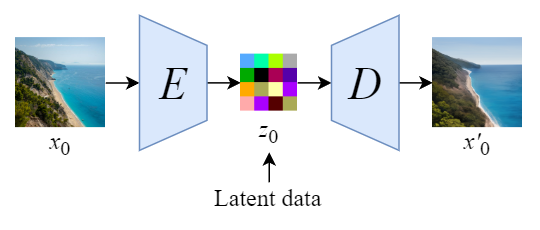
总之,Stable Diffusion会先训练一个自编码器,来学习将图像压缩成低维表示
- 通过训练好的编码器
,可以将原始大小的图像压缩成低维的latent data(图像压缩)
- 通过训练好的解码器
,可以将latent data还原为原始大小的图像
在将图像压缩成latent data后,便可以在latent space中完成扩散过程,对比下和Diffusion扩散过程的区别,如下图所示:
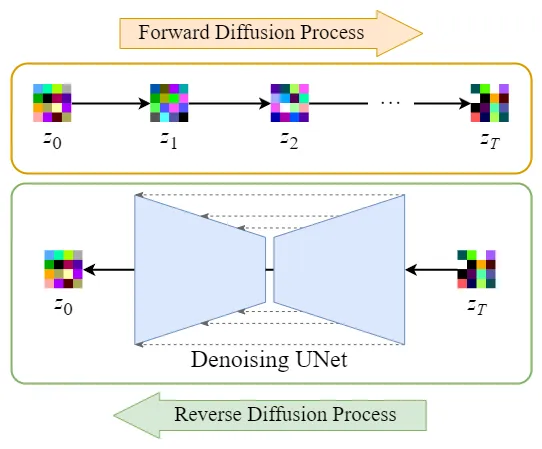
可以看到Diffusion扩散模型就是在原图 上进行的操作,而Stale Diffusion是在压缩后的图像
上进行操作
2.2 从模型结构和源码彻底理解Stable Diffusion
2.2.1 SD的模型结构:autoencoder + CLIP text encoder + UNet
stable diffusion和上面DALL E2的原理其实差不多,具体而言,会先后经历以下几个步骤「左边红色是像素空间 pixel space(含编码器和解码器
)、中间绿色区域是潜在空间latent space、右边灰色的是条件condition」
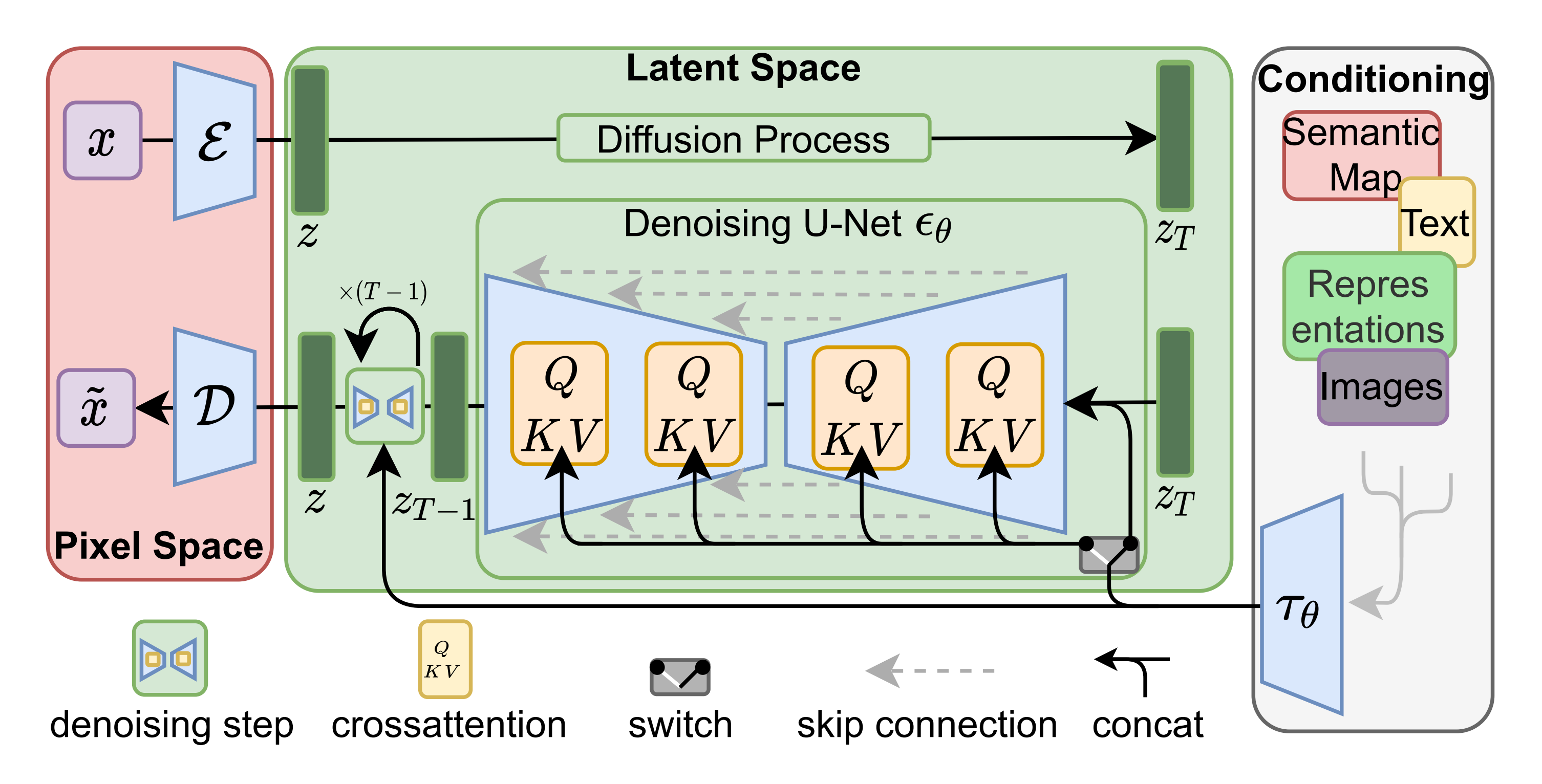
- 将图像从像素空间(Pixel Space)压缩到潜在空间(Latent Space)
图像编码器可以对图像
进行压缩,可以理解为它能忽略图片中的高频信息,只保留重要的深层特征,从而将
这个就是所谓的感知压缩(Perceptual Compression),即“将高维特征压缩到低维,接着在低维空间上进行操作”的方法具有普适性,可以很容易的推广到文本、音频、视频等不同模态的数据上 - 针对潜在空间的图片做扩散(Diffusion Process):添加噪声
对潜在空间Latent Space中的图片添加噪声,进行扩散过程,将其结果作为 U-Net 的输入 - 根据用户的输入text/prompt 获取去噪条件(Conditioning)
text encoder提取输入text/prompt的text embeddings(维度为77✖️768,意味着77个token嵌入向量,其中每个向量包含768个维度)
然后通过cross attention方式送入噪声估计模型UNet中作为去噪条件condition(当然了,去噪时可以灵活地以文本、图像和其他形式为条件,比如以文本为条件即text2img、以图像为条件即 img2img) - 噪声估计器U-Net 预测噪声,然后依据「去噪条件」去噪:生成图片的潜在表示
首先,噪声估计器 U-Net 将潜在噪声图像和文本提示作为输入,并预测噪声「该过程也在潜在空间(4x64x64 张量)中」
之后,基于上面第3步的去噪条件对图像通过 噪声估计器U-NET 进行去噪(Denoising),以获得生成图片的潜在表示
具体而言,可以分为以下4步骤
a ) 事实上,扩散模型可以理解为一个时序去噪自编码器,我们需要训练
使得预测的噪声与真实噪声相近,则目标函数为:
b ) 而在 Latent Diffusion Models 中,引入了预训练的感知压缩模型,它包含一个编码器
c ) 对于条件生成任务,我们将拓展为:
,这样就可以通过
来控制图片合成的过程,通过在 U-Net 上增加 cross-attention 机制来实现
而为了能够从不同的模态预处理,它用来将
,这样我们就可以很方便的引入各种形式的条件,例如文本、类别、layout等
d ) 最终模型可通过一个 cross-attention 将去噪条件引导融入到 UNet 中「作为query向量,
作为key和value向量 」,cross-attention 表示为:
其中是 UNet 的一个中间表征
最终,目标函数可以写为:
总之,加噪后的隐式表达
然后计算网络输出噪声和真实噪声的差距,最小化损失来反向传播更新参数,注意整个训练阶段VAE是冻结的
也如七月官网的「大模型线上营」中的一学员战士长所说,这里面有两个东西,一个是传统的diffuion,是通过预测噪声来还原成图片,另一个是unet里嵌入的注意力模块,用来控制你图片还原的方向 - 潜在空间转换成最终图像
图像解码器负责将去噪后的 latent 图像从潜在空间恢复到原始像素空间来生成最终图「各维度为:(3,512,512),即(红/绿/蓝, 宽, 高)」
下图亦可辅助理解
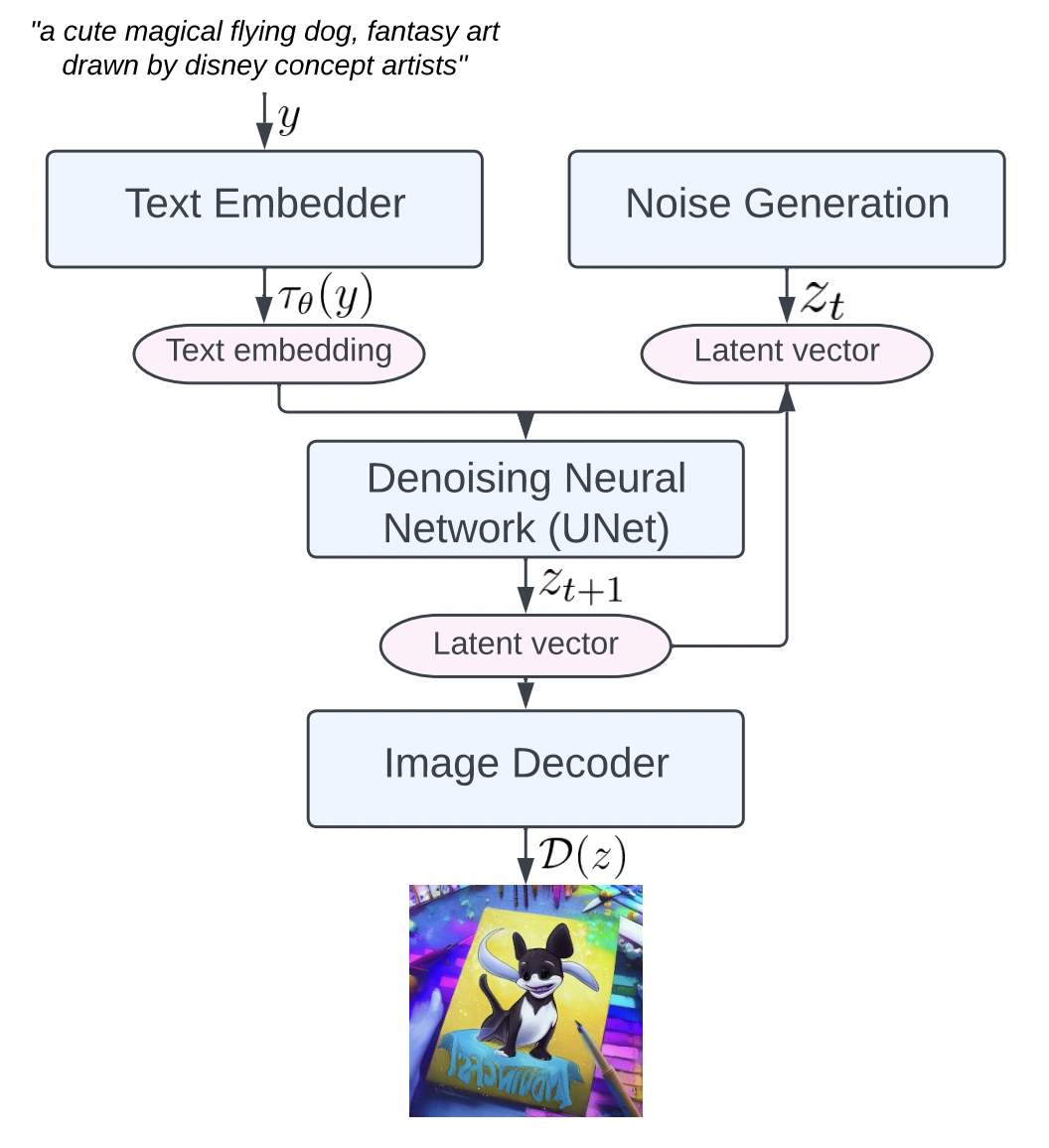
2.2.2 从源码层面理解SD
// 待更
2.3 给SD装上方向盘之ControlNet的详解及其应用:微调SD
SD的微调方式有多种,比如可以通过ControlNet微调SD「我司七月在线基于ControlNet微调SD或SD的二次开发,落地了一个AIGC模特生成平台,详见七月官网右上角的体验入口,至于其背后的原理则可以看下七月的SD课程、AIGC模特生成课程,或大模型项目开发线上营」
而什么是ControlNet呢?
- 说的直白点,之前,Stable Diffusion 最让人头疼的就是无法精确控制图像细节。不管是构图、动作、面部特征还是空间关系,即便提示词已经做了很详细的规定,但 SD 生成的结果,依然要坚持 AI 独特的想法
- 但 ControlNet 的出现就好像是给 SD 装上了「方向盘」——达到精准控图,许多商业化的工作流也因此催生
其对应的论文发布于23年2月份《Adding Conditional Control to Text-to-Image Diffusion Models》
接下来,咱们再详细解读下这个ControlNet
2.3.1 给Stable Diffusion附加上ControlNet:类似LoRA微调
通过上文的介绍可知,可以通过文本提示类似Stable Diffusion之类的生图工具生成图像,然而有的时候,想生成符合预期的图像,刚有文本提示还不够,可能还会给生图工具一些参考的图像,相当于文本可以作为prompt条件、参考图像也可以作为prompt条件
而ControlNet可以通过锁定原base模型Stable Diffusion的参数,并制作SD的可训练副本,其中,可训练副本通过零卷积层与原始锁定SD模型链接,而这个零卷积层的权重可以初始化为0,具体如下图所示

其中
- 一个神经模块将特征图
且,其中
分别表示特征图中的高度、宽度和通道数
- 为了在这样的模块中添加一个ControlNet,锁定原始模块并克隆一个可训练的副本,并使用零卷积层连接被锁定的原模型
该零卷积层表示为,是一个1×1的卷积层,其权重和偏置均初始化为零
顺带提一下,为何这里用的零卷积呢,而非别的某种卷积呢?你还真别说,作者团队还真曾尝试过用高斯权重初始化的标准卷积层替换零卷积,但性能会出现下降,具体情况在3.3.3节最后还会解释
当然,具体实践时,会用两个零卷积实例,参数分别为和
,从而有
- 至于下图右上角的
是希望添加到网络中的条件向量
2.3.2 用于文本到图像扩散的ControlNet——微调扩散模型
Stable Diffusion 本质上是一个包含编码器(如上面说过的,SD的原理详见此文)、中间块和跳跃连接解码器的 U-Net 「73-U-net: Convolutional networks for biomedical image segmentation,关于U-net的详解详见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的2.1.1 从扩散模型概念的提出到DDPM(含U-Net网络的简介)」

- 编码器和解码器各包含 12 个块,整个模型包含25 个块,包括中间块
在这 25 个块中,8 个块是下采样或上采样卷积层,而另外 17 个块是主块,每个主块包含 4 个 resnet 层和 2 个视觉transformer(即ViT),每个 ViT 包含若干交叉注意力和自注意力机制
例如,在上图左侧a图 中,“SD Encoder Block A” 包含 4 个 resnet 层和 2 个 ViTs,而“×3”表示该块重复三次
即diffusion timesteps are encodedwith a time encoder using positional encoding - 最终,ControlNet结构应用于U-net的每个编码器层级(相当于ControlNet作用在了U-net的每个编码器的副本上,即The ControlNet structure is applied to each encoder levelof the U-net),如上图右侧b图的右上角所示
具体来说,使用ControlNet创建了Stable Diffusion的12个编码块和1个中间块的可训练副本。这12个编码块分为4种分辨率resolutions(64×64,32×32, 16×16, 8×8),每种分辨率重复3次
最终这块的输出(通过13个领卷积层)添被加到U-net的12个跳跃连接和1个中间块上
the outputs are added to the 12 skip-connections and 1 middle block of the U-net
另,我必须负责任的指出:
- 上图b中ControlNet右上角是复制过来的参数,称之为可训练的副本
- 上图b中ControlNet右下角那些零卷积层 它们的参数只是一开始被0初始化,后续经过反向传播后,零卷积层变为非零并影响输出「反向传播更新 ControlNet 中的可训练副本和零卷积层,使零卷积权重通过学习过程逐渐过渡到优化值」
对于这点,从ControlNet的GitHub主页也可以证实到,即
Q: If the weight of a conv layer is zero, the gradient will also be zero, and the network will not learn anything. Why "zero convolution" works?
A: This is wrong. Let us consider a very simple:ControlNet/blob/main/docs/faq.md - 上图b中ControlNet右下角的零卷积层会连接 上图b中ControlNet右上角的可训练副本和上图左侧a中Stable Diffusion被冻结的u-net
这种方法加快了训练速度并节省了GPU内存。根据在单个NVIDIA A100PCIE 40GB上的测试,使用ControlNet优化Stable Diffusion仅需大约23%的额外GPU内存和34%的计算资源
关于上面的64×64,再具体说明下,Stable Diffusion 使用类似于 VQ-GAN [19] 的预处理方法将 512×512像素空间图像转换为较小的 64×64 潜在图像
- 为了将 ControlNet 添加到 Stable Diffusion 中,首先将每个输入条件图像(例如,边缘、姿势、深度等)从 512×512 的输入大小转换为 64×64的特征空间向量,以匹配 Stable Diffusion 的大小
- 特别地,作者团队使用一个小型网络
,由四个卷积层组成,使用 4×4 的卷积核和 2×2 的步幅(通过 ReLU 激活,分别使用 16、32、64、128通道,用高斯权重初始化并与完整模型一起训练)将图像空间条件
编码为特征空间条件向量
此外,条件向量
被传入ControlNet
2.3.3 ControlNet的训练、推理、消融实验
首先,对于ControlNet的训练
给定一个输入图像,图像扩散算法逐步向图像添加噪声,并生成一个噪声图像
,其中
表示添加噪声的次数
给定一组条件,包括时间步、文本提示
以及特定任务条件
,图像扩散算法学习一个网络
来预测添加到噪声图像
的噪声
整个扩散模型的总体学习目标是,这个学习目标直接用于通过ControlNet微调扩散模型
在训练过程中,随机将50%的文本提示替换为空字符串。这种方法增强了ControlNet直接识别输入条件图像(如边缘、姿态、深度等)语义的能力,以替代提示
在训练过程中,由于零卷积不会向网络添加噪声,模型应始终能够预测高质量的图像。且观察到,模型并不是逐渐学习控制条件,而是突然成功地遵循输入条件图像;通常在不到1万次优化步骤内完成,如下图所示,一般称之为“突然收敛现象”

其次,对于ControlNet的推理
可以通过多种方式进一步控制ControlNet的附加条件如何影响去噪扩散过程
比如无分类器引导的分辨率加权
- Stable Diffusion依赖于一种称为无分类器引导(CFG)的技术来生成高质量的图像
CFG的公式为,其中
、
、
、
分别是模型的最终输出、无条件输出、有条件输出和用户指定的权重
- 当通过ControlNet添加条件图像时,可以将其添加到
在具有挑战性的情况下,例如没有提示时,将其添加到
- 作者团队的解决方案是首先将条件图像添加到
乘以 Stable Diffusion 和 ControlNet 之间的每个连接,公式为
,其中
是第
个块的大小,例如
通过降低 CFG 引导强度,可以得到上图d 中所示的结果,可称之为 CFG 分辨率加权——组合多个 ControlNet - 为了将多个条件图像(例如,Canny 边缘和姿态)应用于单个 Stable Diffusion 实例,还可以直接将相应 ControlNet的输出添加到 Stable Diffusion 模型中,如下图所示
这种组合不需要额外的加权或线性插值
最后,在消融实验方面(证明两个零卷积结构的必要性)
研究了ControlNets的替代结构:
- 用高斯权重初始化的标准卷积层替换零卷积——如下图b所示
- 用一个单一的卷积层替换每个模块的可训练副本,称之为ControlNet-lite——如下图c所示

且提出了4种提示设置,以测试现实世界用户可能的行为:
- 无提示
- 不充分的提示,这些提示未能完全涵盖条件图像中的对象,例如本文的默认提示“高质量、详细且专业的图像”
- 条件图像语义的冲突提示
- 完美提示,描述必要的内容语义,例如“漂亮的房子”
可以很明显的看到
- 如上图a所示,4种设置中不论是哪一种设置,ControlNet的表现都是最好的
- 当零卷积被替换时(比如被替换成高斯权重初始化的标准卷积层),ControlNet的性能下降到与ControlNet-lite大致相同,这表明可训练副本的预训练骨干在微调过程中被破坏——上图b
- 轻量级的ControlNet-lite——上图c,不足以解释条件图像,并在条件不足和无提示的情况下失败
第三部分(选读) 从一致性模型Consistency Model(CM)、到Latent Consistency Models(LCM)
3.1 什么是一致性模型Consistency Model(CM)
3.1.1 Consistency Models的背景:AI绘画神器DALLE 3的解码器
关于我为何关注到这个一致性模型,说来话长啊,历程如下
- 我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强,加之也要在论文100课上讲DALLE三代的三篇论文
而在精读DALLE 3的论文时,发现其解码器用到了Consistency Models
当然,后来OpenAI首届开发者大会还正式发布了这个模型,让我对它越发好奇
- Consistency Models的第一作者宋飏也证实了该模型是DALLE 3的解码器
宋飏不算扩散圈的新人,因为早在2019年,斯坦福一在读博士宋飏和其导师通过此文《Generative Modeling by Estimating Gradients of the Data Distribution》提出了一种新方法来构建生成模型:即不需要估计数据的概率分布(数据概率的分布类似高维曲面),相反,它估计的是分布的梯度(分布的梯度可以看成是高维曲面的斜率)
至此,已确定必须得研究下这个「AI绘画神器DALLE 3的解码器:一步生成的扩散模型之Consistency Models」了
3.1.2 什么是Consistency Models:何以颠覆原来的扩散模型
根据本文上面的内容可知,扩散模型广泛应用于DALLE、stable diffusion等文生图的模型中,但一直以来扩散模型的一个缺点就是采样速度较慢,通常需要100-1000的评估步骤才能抽取一个不错的样本
23年5月,OpenAI的Yang Song、Prafulla Dhariwal、Mark Chen、Ilya Sutskever等人提出了Consistency Models(GitHub地址),相比扩散模型,其使用1个步骤就能获得不错的样本,整体效率至少提升100倍同时也极大地降低了算力成本,其中一作是华人宋飏(其本毕清华,博毕斯坦福)
- 基于连续时间扩散模型中的概率流(PF)常微分方程(ODE,Song等2021),其轨迹能够平滑过渡,将数据分布映射为可处理的噪声分布
- 随后,作者提出学习一种模型,可将任意时间步的任意点映射到轨迹的起始点
比如给定一个可将“数据”转换为“噪声”概率流(PF) ODE,可将ODE轨迹上的任何点「例如,下图中的,
和轨迹终点
),映射到它的轨迹起始点(例如,生成建模的
)」
且该模型的一个显著特性是自一致性:同一轨迹上的点会被映射到同一个初始点
Given a Probability Flow (PF) ODE that smoothlyconverts data to noise, we learn to map any point (e.g., xt,xt1 , and xT ) on the ODE trajectory to its origin (e.g., x0)for generative modeling. Models of these mappings arecalled consistency models, as their outputs are trained to beconsistent for points on the same trajectory
最终,作者将这类模型称为一致性模型
相比扩散模型,它主要有两大优势:
- 其一,无需对抗训练(adversarial training),就能直接生成高质量的图像样本
- 其二,相比扩散模型可能需要几百甚至上千次迭代,一致性模型只需要一两步就能搞定多种图像任务——包括上色、去噪、超分等,都可以在几步之内搞定,而不需要对这些任务进行明确训练(当然,如果进行少样本学习的话,生成效果也会更好)
原理上,一致性模型直接把随机的噪声映射到复杂图像上,输出都是同一轨迹上的同一点,所以实现了一步生成
3.1.3 Consistency Models的两种训练方法
一致性模型有两种训练方法
- 一种是通过蒸馏预训练扩散模型进行训练(Consistency models canbe trained either by distilling pretrained diffusion models)
By minimizing the difference between model outputs for these pairs, we can effectively distill a diffusion model into a consistency model, which allows generating high-quality samples with one network evaluation - 另外一种,也可以完全作为独立的生成模型进行训练
该方法完全消除了对预训练扩散模型的需要,允许单独训练一致性模型。这种方法将一致性模型定位为一个独立的生成模型家族
重要的是,这两种方法都不需要对抗性训练,并且对模型架构的限制很小,因此可以使用灵活的神经网络对一致性模型进行参数化
实验结果表明
- 一致性模型作为一种蒸馏方法,在一步和少步采样方面优于现有的蒸馏技术,如渐进式蒸馏
- 且当作为独立的生成模型进行训练时,一致性模型可以与现有的一步非对抗生成模型在标准基准测试汇总媲美,如CIFAR-10、ImageNet 64×64和LSUN 256×256
3.1.4 Consistency Models的推导
3.1.4.1 对扩散模型推导的回顾
首先回顾一下diffusion的算法原理
- 扩散模型通过高斯扰动将数据逐步扰动为噪声,然后通过顺序去噪步骤从噪声中生成样本。设
表示数据分布,扩散模型首先通过随机微分方程(SDE)对
Let pdata(x) denote the data distribution. Diffusion models start by diffusing pdata(x) with a stochastic differential equation (SDE)
其中,
是一个固定常数,
和
分别为漂移系数和扩散系数,
表示标准布朗运动
- 将
,因此
该随机微分方程(SDE)具有一个显著的性质,即存在一个常微分方程ODE,被 Song 等人(2021)称为概率流(Probability Flow, PF)ODE,其在时刻采样得到的解轨迹分布与
——————
或者说,为了通过该式得到一个常微分方程(ODE),需要消除随机项,在某些扩散模型中,比如Score-Based Generative Models,可以使用概率密度函数
来代替漂移项,进而定义一个无随机项的轨迹,称为ODE轨迹
总之,一致性模型的作者宋飏等人推导出,上述 SDE 存在一个ODE形式的解轨迹(ODE trajectory)
其中是
因此,扩散模型也被称为基于得分的生成模型 - 采用 EDM 中的 设置,设置
、
,训练一个得分模型
可将上述 ODE 转为 - 得到 ode 的具体形式后,利用现有的数值 ODE solver,如 Euler, Heun, Lms 等,即可解出 x(.)
当然,考虑到数值精确性,往往不会直接求出原图即,而是计算出一个
,持续这个过程来求出
// 待更
3.1.4.2 Consistency Models 的推导与源码解读

// 待更
3.2 潜在一致性模型Latent Consistency Models(LCM)
3.2.1 LCM与通用加速器LCM-LoRA
受到上文的Consistency Models的启发「其采用了一种一致性映射技术,巧妙地将普通微分方程(ODE)轨迹上的点映射到它们的起源,从而实现了快速的一步生成」,清华大学交叉信息研究院一团队(包括骆思勉和谭亦钦等人)于2023年11月推出Latent Consistency Models(潜一致性模型,简称LCM)
其通过将引导式逆扩散过程视为增强型概率流常微分方程(PF-ODE)的解决方案,LCM 能够在潜在空间中巧妙地预测此类常微分方程的解(By viewing the guided reverse diffusion process as the resolution of an augmented Probability Flow ODE (PF-ODE), LCMs adeptly predict the solution of such ODEs in latent space),该方法显著减少了迭代步骤的需求
- LCMs是从预训练的潜在扩散模型(LDMs)中提炼出来的(其paper:https://huggingface.co/papers/2311.05556、其项目主页:https://latent-consistency-models.github.io/),仅需要约32个A100 GPU训练小时
- 且考虑到对于专门的数据集,如动漫、照片逼真或幻想图像,还得使用潜在一致性微调LCF对LCM进行微调(或使用潜在一致性蒸馏LCD将预训练的LDM蒸馏为LCM),故为避免这种额外的步骤阻碍LCMs在不同数据集上的快速部署,该团队还提出了LCM-LoRA
使得可以在自定义数据集上实现快速、无需训练的推理,比如可以直接将该LoRA(即通过LCM蒸馏获得的LoRA参数)插入各种稳定扩散模型中,包括SD-V1.5(Rombach等,2022年),SSD-1B(Segmind,2023年)和SDXL(Podell等,2023年)等
和需要多步迭代传统的扩散模型(如Stable Diffusion)不同,LCM仅用1-4步即可达到传统模型30步左右的效果,LCM将文生图生成速度提升了5-10倍,世界自此迈入实时生成式AI的时代

3.2.2 LCM-LORA
潜在一致性模型LCM使用一阶引导蒸馏方法进行训练,利用预训练自编码器的潜在空间将引导扩散模型蒸馏成LCM。该过程涉及解决增强概率流动ODE(PF-ODE,确保生成的样本遵循导致高质量图像的轨迹),以下是LCD的伪代码

由于潜在一致性模型LCM的蒸馏过程是在预训练扩散模型的参数之上进行的,我们可以将潜在一致性蒸馏视为扩散模型的微调过程。因此,能够使用LoRA
LoRA通过应用低秩分解来更新预训练的权重矩阵
- 给定一个权重矩阵
,更新表示为
,其中
,
,且秩
- 在训练过程中,
保持不变,只对A和B应用梯度更新,对于输入
在这个方程中, 代表输出向量,
和
的输出在乘以输入
后相加。 通过将完整的参数矩阵分解为两个低秩矩阵的乘积,LoRA显著减少了可训练参数的数量,从而降低了内存使用量

3.2.3 LCM与其他类似项目的对比
|
模型名称 |
介绍 |
生成速度 |
训练难度 |
SD生态兼容性 |
|
DeepFloyd IF |
高质量、可生成文字,但架构复杂 |
更慢 |
更慢 |
不兼容 |
|
Kandinsky 2.2 |
比SDXL发布更早且质量同样高;兼容ControlNet |
类似 |
类似 |
不兼容模型和LoRA,兼容ControlNet等部分插件 |
|
Wuerstchen V2 |
质量和SDXL类似 |
2x - 2.5x |
更容易 |
不兼容 |
|
SSD-1B |
由Segmind蒸馏自SDXL,质量略微下降 |
1.6x |
更容易 |
部分兼容 |
|
PixArt-α |
华为和高校合作研发,高质量 |
类似 |
SD1.5十分之一 |
兼容ControlNet等部分插件 |
|
LCM (SDXL, SD1.5) |
训练自DreamShaper、SDXL,高质量、速度快 |
5x -10x |
更容易 |
部分兼容 |
|
LCM-LoRA |
体积小易用,插入即加速;牺牲部分质量 |
5x -10x |
更容易 |
兼容全部SD大模型、LoRA、ControlNet,大量插件 |
截止至2023/11/22,已支持LCM的开源项目:
- Stable Diffusion发行版,包括WebUI(原生支持LCM-LoRA,LCM插件支持LCM-SDXL)、ComfyUI、Fooocus(LCM-LoRA)、DrawThings
- 小模型:LCM-LoRA兼容其他LoRA,ControlNet
- AnimateDiff WebUI插件
3.3 SDXL Turbo:给定prompt 实时响应成图
Stability AI 推出了新一代图像合成模型 Stable Diffusion XL Turbo(其论文地址),使得只用在文本框中输入你的想法,SDXL Turbo 就能够迅速响应,生成对应内容。一边输入,一边生成,内容增加、减少,丝毫不影响它的速度


还可以根据已有的图像,更加精细地完成创作。手中只需要拿一张白纸,告诉 SDXL Turbo 你想要一只白猫,字还没打完,小白猫就已经在你的手中了

SDXL Turbo 模型的速度达到了近乎「实时」的程度,于是有人直接连着游戏,获得了 2fps 的风格迁移画面:

据官方博客介绍,在 A100 上,SDXL Turbo 可在 207 毫秒内生成 512x512 图像(即时编码 + 单个去噪步骤 + 解码,fp16),其中单个 UNet 前向评估占用了 67 毫秒,如此,我们可以判断,文生图已经进入「实时」时代
3.3.1 SDXL关键技术:对抗扩散蒸馏
3.3.1.1 两个训练目标:对抗损失和蒸馏损失
在SDXL之前
- 一致性模型CM(Consistency Models)通过对ODE轨迹施加一致性正则化(by enforcing a consistency regularization on the ODE trajector)来解决
即便迭代采样步骤减少到4-8步,依然能保持较好的性能,且在少样本设置下展示了强大的像素模型性能 - 而LCMs[38]专注于在对潜在扩散模型进行蒸馏时,仅用4步采样便取得了令人印象深刻的性能
LCMs focus on distilling latent diffusion models and achieve impressive performance at 4 sampling steps.
包括LCM-LoRA则引入了一种低秩适应[22]训练方法,以高效学习LCM模块,该模块可以插入到SD和SDXL [50, 54]的不同检查点中
Recently, LCM-LoRA [40] introduced a low-rank adaptation [22] training for efficiently learning LCM modules, which can be plugged into different checkpoints for SD and SDXL [50, 54] - InstaFlow [36]提出使用Rectified Flows[35]来促进更好的蒸馏过程
InstaFlow [36]propose to use Rectified Flows [35] to facilitate a better distillation proces
所有这些方法都存在共同的缺陷:通过四步合成的样本通常显得模糊,并且存在明显的伪影
考虑到GANs也可以作为独立的单步模型进行文本到图像合成的训练 [25,59],且采样速度不错(当然,性能落后于基于扩散的模型)
那何不在不破坏平衡的情况下,扩展GAN并整合神经网络架构呢?
- 而SDXL则引入了一种名为:对抗扩散蒸馏(Adversarial Diffusion Distillation,ADD)的技术,可高效地在仅1至4步内对大规模基础图像扩散模型进行采样,同时保持高图像质量
(a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1–4 steps while maintaining high image quality) - 其利用分数蒸馏,将大规模现成图像扩散模型作为教师信号,并结合对抗损失,即使在仅有一步或两步采样的低步数情况下,也能确保图像的高保真度
(We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps)
具体而言,研究者引入了两个训练目标的组合:

- 对抗损失,对抗损失迫使模型在每次前向传递时直接生成位于真实图像流形上的样本,避免了其他蒸馏方法中常见的模糊和其他伪影
- 分数蒸馏采样SDS 相对应的蒸馏损失,蒸馏损失使用另一个预训练(且固定)的扩散模型作为教师(比如可以使用预训练的扩散模型权重初始化模型),有效利用预训练diffusion model的丰富知识,从而显著改善对抗性损失的训练,类似通过CLIP改善文本对齐
最后,不使用仅解码器的架构来进行GAN训练,而是采用标准的扩散模型框架
3.3.1.2 训练的具体过程
ADD-student从预训练的UNet-DM中初始化权重 ,具有可训练权重
的鉴别器,以及具有冻结权重
的DM teacher(The ADD-student is initialized from a pretrained UNet-DM with weights θ, a discriminator with trainable weights ϕ, and a DM teacher with frozen weights ψ)
在训练过程中
- ADD-student从噪声数据
生成样本
噪声数据点是通过正向扩散过程从真实图像数据集
在作者的实验中,作者使用与student DM相同的系数和
,并从选择的学生时间步长集合
中均匀采样
- 生成的样本
和真实图像
被传递给鉴别器Discriminator,鉴别器的目标是区分它们
- 为了从DM teacher那里获得知识,将学生样本
(we diffuse student samples ˆxθ with the teacher’s forward process toˆxθ,t)
并使用教师的去噪预测作为蒸馏损失distillation loss的重建目标
(use the teacher’s denoising prediction ˆxψ (ˆxθ,t, t)as a reconstruction target for the distillation loss Ldistill)
因此,总体目标是
// 待更
3.4 SDXL-Lightning
// 待更
第四部分 SD最新版Stable Diffusion3
考虑到stable diffusion的原理在上文中已经讲的很清楚了,故本部分主要讲下最新版本的SD3(其对应的paper为《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》)
由于固定的文本表示直接输入模型并不理想『e.g., via cross-attention (Vaswani et al.,2017; Rombach et al., 2022)』
- 首先,24年5月份提出的SD3相比之前的SD一个最大的变化是采用Rectified Flow来作为生成模型,Rectified Flow在《Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow》被首先提出
但其实也有同期的工作比如《Flow Matching for Generative Modeling》提出了类似的想法 - 其次,Stability AI在U-ViT、DiT(这两架构的介绍见此文的第2.3节)的基础上并提出了一种新的架构,该架构包含可学习的streams,用于图像和文本token,从而实现了它们之间的双向信息流动(which enables a two-way flow of information between them)
4.1 流匹配Flow Matching:提高采样器性能(含Rectified Flow的详解)
为避免本文的篇幅过长,本部分已另行独立成文《一文通透流匹配Flow Matching——作为扩散模型的变体,广泛应用于文生图和具身动作模型去噪中(含Rectified Flow的详解)》
4.2 模型结构
对于文本条件下的图像采样,模型必须同时考虑文本和图像两种模态
- 类似LDM (Rombach et al., 2022),在预训练自动编码器的潜空间中训练文本到图像模型
Our general setup follows LDM (Rombach et al., 2022) for training text-to-image models in the latent space of a pretrained autoencoder
与将图像编码为潜在表示的方法类似,作者也遵循了先前的做法(Saharia et al., 2022b; Balaji et al., 2022),使用预训练且冻结的文本模型对文本条件
Similar to the encoding of images to latent representations, we also follow previous approaches (Saharia et al., 2022b; Balaji et al., 2022) and encode the text conditioning c using pretrained, frozen text models. Details can be found in Appendix B.2 - SD3的架构基于DiT
但DiT仅考虑类别条件的图像生成,并使用调制机制将扩散过程的时间步和类别标签作为网络的条件输入
DiT only considers class conditional image generation and uses a modulation mechanism to condition the network on both the timestep of the diffusion process and the class label的嵌入作为调制机制的输入。 然而,由于池化后的文本表示仅保留了关于文本输入的粗粒度信息(Podell等人,2023),因此网络还需要来自序列表示
的信息
Similarly, we use embeddings of the timestep t and cvec as inputs to the modulation mechanism. However, as the pooled text representation retains only coarse-grained infor- mation about the text input (Podell et al., 2023), the network also requires information from the sequence representation cctxt.
具体而言,作者添加了位置编码,并将潜在像素表示的图像patch编码序列
We construct a sequence consisting of embeddings of the text and image inputs. Specifically, we add positional encodings and flatten 2 × 2 patches of the latent pixel rep-resentation x∈ Rh×w×c to a patch encoding sequence of length 1 2 · h · 12 · w.
在将此patch编码和文本编码
After embedding this patch encoding and the text encoding cctxt to a common dimensionality concatenate the two sequences
随后,按照DiT的方法,应用一系列调制注意力机制和多层感知机MLP
4.2.1 借鉴DALLE 3的重字幕技术:提高文本-图像数据集的质量
由于DALLE 3已经证明了人类对图像本身的标题或描述通常忽略图片的很多细节(包括图中的背景、特定的场景、出现的文字等),而如果用视觉语言模型为图像数据集打上更详细的注释,则可以更好的训练text2image模型
故,SD3使用视觉语言模型CogVLM为他们的图像数据集创建合成的注释(synthetic annotations),不过考虑到合成标题可能导致文本到图像模型忘记VLM知识语料库中不存在的某些概念,故他们使用50%的原始标题和50%的合成标题(且做了实验,证明这种一半原始标题 一半合成标题的效果确实明显好于100%都是原始标题的情况)
4.2.2 在DiT的基础上,提出MM-DiT
遵循DiT并应用一系列调制注意力和MLP(We then follow DiT and apply a sequence of modulated attention and MLPs)

- 对于 MM-DiT,如上图左侧a所示,我们比较具有两组权重和三组权重的模型,其中后者分别处理CLIP、T5 token
请注意,DiT(使用文本和图像标记的串联)可以被解释为MM-DiT的一个特例,其中只有一个所有模态共享的权重集 - 由于文本和图像嵌入在概念上非常不同,SD3为这两种模态分别使用了两套独立的权重
Since text and image embeddings are conceptually quite different, we use two separate sets of weights for the two modalities
如上图右侧b所示
这等同于为每种模态分别配置两个独立的transformer,但在注意力操作时将两种模态的序列连接在一起,从而使两种表示既能在各自的空间中运作,又能相互考虑对方的信息
As shown in Figure 2b, this is equivalent to having two independent transformers for each modality, but joining the sequences of the two modalities for the attention operation, such that both representations can work in their own space yet take the other one into account
参考文献与推荐阅读
- Learning Transferable Visual Models From Natural Language Supervision
CLIP原始论文 - CLIP 论文逐段精读,这是针对该视频解读的笔记之一:CLIP和改进工作串讲
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP原始论文 - 多模态超详细解读 (六):BLIP:统一理解和生成的自举多模态模型
极智AI | 多模态新姿势 详解 BLIP 算法实现 - 理解DALL·E 2, Stable Diffusion和 Midjourney工作原理
- 读完 DALL-E 论文,我们发现大型数据集也有平替版
- Hierarchical Text-Conditional Image Generation with CLIP Latents
DALL E2原始论文 - DALL·E 2(内含扩散模型介绍),这是针对该视频解读的笔记
- DALL-E 3技术报告阅读笔记
- OpenAI一夜颠覆AI绘画!DALL·E 3+ChatGPT强强联合,画面直接细节爆炸
- CoCa:对比+生成式任务构建“全能型多模态模型”,这是其论文地址
- 关于CoCa的另外几篇文章:CoCa: 在图生文过程中加入对比学习、如何评价谷歌的 CoCa,在 ImageNet 上达到新的 SOTA:91.0%?
- 浅析多模态大模型的前世今生
-
SD的奠基论文《High-Resolution Image Synthesis with Latent Diffusion Models》,由慕尼黑大学和runway于2021年年底共同提交
- The Illustrated Stable Diffusion,这是图解SD的翻译版
- Stable Diffusion Clearly Explained!
How does Stable Diffusion paint an AI artwork? Understanding the tech behind the rise of AI-generated art. - Getting Started With Stable Diffusion
- 知乎上关于SD原理的几篇文章:Stable Diffusion 的技术原理是什么?、人工智能Ai画画——stable diffusion 原理和使用方法详解、十分钟读懂Stable Diffusion
- Memory-efficient array redistribution through portable collective communication
- stable diffusion 原理介绍 - AI绘画每日一帖
- How does Stable Diffusion work?
- Stable Diffusion 原理介绍与源码分析(一)
- 保姆级讲解 Stable Diffusion
- 李宏毅生成式AI模型diffusion model/stable diffusion概念讲解
- 速度惊人!手机跑Stable Diffusion,12秒出图,谷歌加速扩散模型破记录
- SDXL Turbo、LCM相继发布,AI画图进入实时生成时代:字打多快,出图就有多快
- 文生图10倍速,视频实时渲染!清华发布LCM:兼容全部SD大模型、LoRA、插件等
- 七月在线:AIGC下SD/MDJ的原理与实战课 [深度探究AI绘画/多模态]
首发之后的创作、修改、新增记录
- 23年的端午假期三天,持续完善BLIP/BLIP2、DALLE/DALLE 2等相关的内容
- 6.25,开始写SD的原理部分
- 6.26,考虑到公式太多 容易把初学者绕晕,故把理解SD划分为三层境界
第一层境界 不涉及任何公式,从意图层面整体理解SD
且初步写清SD的基本逻辑
顺带感叹,这几天在网上反复看了大量关于stable diffusion原理的解读文章
我站在初学者角度上,没有一篇令我满意
我也不知道怎么回事,把文章写通俗没有那么难啊.. - 6.27,修改SD的原理部分,以让逻辑清晰明确
- 6.28,写清楚DALL·E2的模型架构
- 6.29,写DALL·E的部分,并梳理全文逻辑
断断续续两个月,总算通过本文和上一篇文章把SD相关的基本写清楚了,后续就是不断优化所有行文细节
以让逻辑更清晰 细节更明确,初学最爱看
感叹过程中 被各种资料反复绕晕过,好在 终究还是像之前解读各种稍复杂点的模型一样
一如既往的绕出来了 - 7.7,优化对潜在空间的说明描述
- 7.16,润色关于噪声估计器的部分描述
- 10.30,开始新增DALLE 3的部分
前几天写完了旋转位置编码,未来几天都在持续写DALLE 3的技术细节
一方面,它生成图的质量确实挺高
二方面,近期需要为某合作伙伴做一个文生图的应用,所以研究下各个相关模型的技术细节 - 10.31,优化SD的部分
- 11.10,重读DALLE 3论文并优化相关细节的描述
如在微博上所说的,“为准备这周日的DALLE 3公开课,在一字一句重抠DALLE 3论文,但其本质不算论文,很多训练细节没透露
好在现在完全可以一字一句耐心读paper了,一年前还是有点痛苦的,加之研究能力的不断提升,可以通过研究相关paper去补齐它的训练细节” - 11.12,优化第二部分中关于DALLE、DALLE 2的部分内容,以为阐述更精准
比如关于DALLE 2的训练步骤 - 11.13,继续优化第二部分中关于DALLE 3部分内容的描述细节
- 11.23,因11.25要在fanbook上做SD的专场公开课,故优化本文关于SD的部分内容
-
24年1.5,因本文一读者于评论中留言提醒:DALL·E3在计算余弦相似度的时候,直接根据公式计算就行了,没必要再用1去减
一看,确实如此,特此修正,感谢该朋友的指出 - 2.23,在3.2.2节中补充了这句话:
- 2.27,把SDXL Turbo、LCM、SD3相关的内容放到新一篇文章中
- 3.5,因为要写新一篇关于SD3的博客,故对本文中关于SD的部分修订了一轮
以让本文的逻辑结构更清晰,且去掉相关的冗余与重复描述 - 10.6日,在此节「3.3 七月AIGC模特生成平台:通过ControlNet微调SD与SD的二次开发」的开头增加关于ControlNet的介绍链接
- 12.1,在本文第3.3节新增关于ControlNet的详解
-
25年5.4,在修订「Helix——Figure 02上的通用人形VLA:不用微调即可做多个任务的快与慢双系统,让两个机器人协作干活(含清华HiRT详解)」一文的过程中,因HiRT的理解模块用到了InstructBLIP,故再次注意到本文所介绍的BLIP2、InstructBLIP
特此,修订本文中的「BLIP2、InstructBLIP」相关部分 - 8.22,把本文的本第一部分已独立出去成此文:《视觉语言对比学习的发展史:从CLIP、BLIP、BLIP2、InstructBLIP(含MiniGPT4的详解)
- 8.26,把原本属于此文《文生图中从扩散模型到流匹配的演变:从SDXL到Stable Diffusion3(含Flow Matching和Rectified Flow的详解)》中的『SDXL到Stable Diffusion3』
转移到本文之中..
并完善改进本文最新的第三部分、第四部分的很多措辞,以更精准 - ..

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 114
114 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)