如何使用Python循环遍历HTML表格并刮取表格数据

表格数据是网络上最好的数据来源之一。它们可以存储大量有用信息而不会丢失其易于阅读的格式,使其成为数据相关项目的金矿。
无论是抓取足球数据还是提取股市数据,我们都可以使用 Python 快速访问、解析和提取 HTML 表格中的数据,这要归功于 Requests 和 Beautiful Soup。
此外,我们在最后为您准备了一个黑白小惊喜,请继续阅读!
理解 HTML 表格的结构
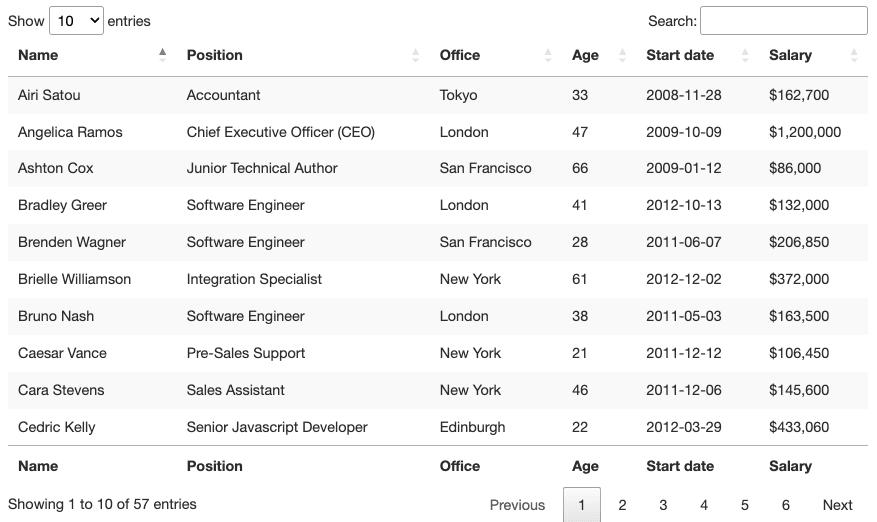
从视觉上看,HTML 表格是一组以表格格式显示信息的行和列。对于本教程,我们将抓取上面的表格:
为了能够抓取该表中包含的数据,我们需要更深入地研究它的编码。
一般来说,HTML 表格实际上是使用以下 HTML 标签构建的:
- : 它标志着一个 HTML 表格的开始
: 定义一行作为表格的标题
:表示数据所在的部分
: 表示表格中的一行
或者
: 定义表格中的一个单元格
然而,正如我们将在现实生活中看到的那样,并非所有开发人员在构建他们的表时都尊重这些约定,这使得一些项目比其他项目更难。尽管如此,了解它们的工作原理对于找到正确的方法至关重要。
让我们在浏览器中输入表格的 URL (https://datatables.net/examples/styling/stripe.html) 并检查页面以了解幕后情况。
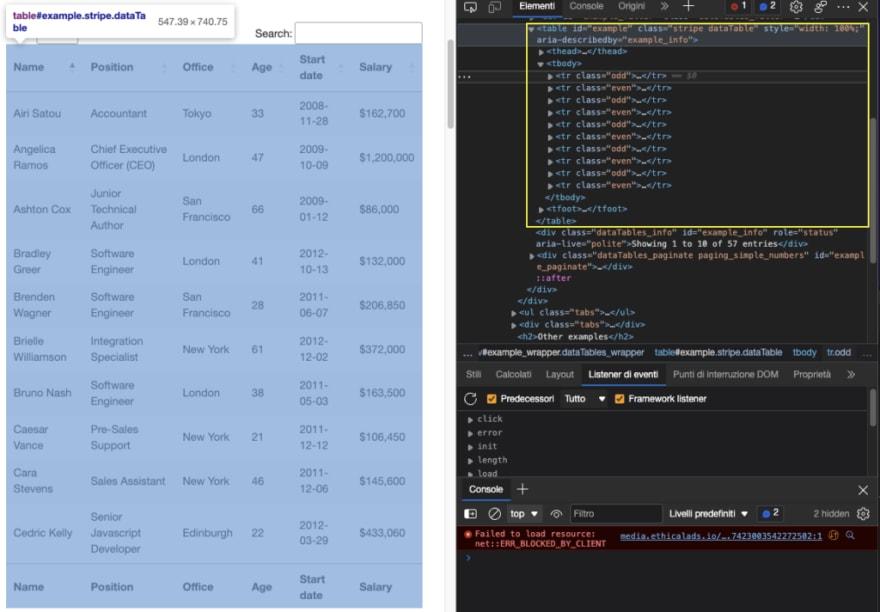
这就是为什么这是一个练习使用 Python 抓取表格数据的好页面的原因。有一个明确的
标签对打开和关闭表格,所有相关数据都在标签内。它只显示与前端选择的条目数相匹配的十行。
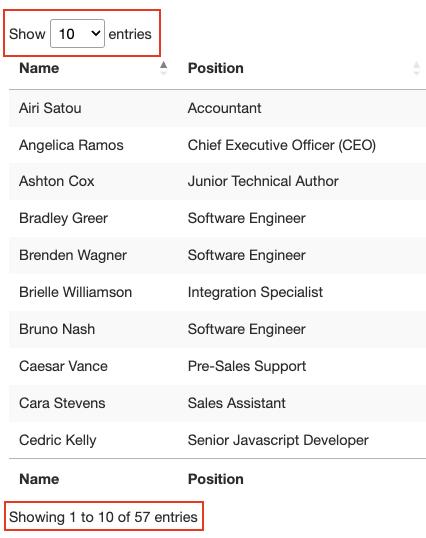
关于这个表还有一点需要了解的是,它总共有 57 个我们要抓取的条目,并且似乎有两种解决方案可以访问数据。首先是单击下拉菜单并选择“100”以显示所有条目:
或单击下一步按钮以在分页中移动。

那么会是哪一个呢?这些解决方案中的任何一个都会给我们的脚本增加额外的复杂性,因此,让我们先检查一下从哪里提取数据。
当然,因为这是一个 HTML 表,所以所有数据都应该在 HTML 文件本身上,而不需要 AJAX 注入。要验证这一点,右键单击>查看页面源。接下来,复制几个单元格并在源代码中搜索它们。
我们对来自不同分页单元格的更多条目做了同样的事情,是的,看起来我们所有的目标数据都在那里,即使前端没有显示它。
有了这些信息,我们就可以开始编写代码了!
##使用 Python 的 Beautiful Soup 抓取 HTML 表
因为我们要抓取的所有员工数据都在 HTML 文件中,所以我们可以使用Requests库发送 HTTP 请求,并使用解析响应使用Beautiful Soup。
**注意:**如果您是网络抓取的新手,我们在 Python 中为初学者创建了一个网络抓取教程。尽管您可以在没有经验的情况下跟随,但从基础开始总是一个好主意。
###1\。发送我们的主要请求
让我们为项目创建一个名为 python-html-table 的新目录,然后是一个名为 bs4-table-scraper 的新文件夹,最后,创建一个新的 python_table_scraper.py 文件.54
从终端,让我们pip3 install requests beautifulsoup4并将它们导入我们的项目,如下所示:
导入请求
从 bs4 导入 BeautifulSoup
要使用 Requests 发送 HTTP 请求,我们需要做的就是设置一个 URL 并通过 requests.get() 传递它,将返回的 HTML 存储在响应变量中并打印 response.status_code。
注意:如果你是 Python 的新手,你可以从终端使用命令 python3 python_table_scraper.py 运行你的代码。
url u003d 'https://datatables.net/examples/styling/stripe.html'
响应 u003d requests.get(url)
打印(response.status_code)
如果它正常工作,它将返回 200 状态码。其他任何事情都意味着您的 IP 被网站安装的反抓取系统拒绝。一个潜在的解决方案是将自定义标题添加到您的脚本以使您的脚本看起来更人性化——但这可能还不够。另一种解决方案是使用网络抓取 API 为您处理所有这些复杂性。
###2\。集成 ScraperAPI 以避免反抓取系统
ScraperAPI 是一个优雅的解决方案,可以避免几乎任何类型的反抓取技术。它使用机器学习和多年的统计分析来确定最佳标头和 IP 组合以访问数据、处理验证码并在每个请求之间轮换您的 IP。
首先,让我们创建一个新的 ScraperAPI 免费帐户来兑换 5000 个免费 API 和我们的 API Key。从我们帐户的仪表板中,我们可以复制我们的键值来构建请求的 URL。
http://api.scraperapi.com?api_keyu003d{Your_API_KEY}&urlu003d{TARGET_URL}
按照这个结构,我们用我们的数据替换持有者并再次发送我们的请求:
导入请求
从 bs4 导入 BeautifulSoup
url u003d 'http://api.scraperapi.com?api_keyu003d51e43be283e4db2a5afbxxxxxxxxxxxx&urlu003dhttps://datatables.net/examples/styling/stripe.html'
响应 u003d requests.get(url)
打印(response.status_code)

太棒了,它的工作没有任何问题!
###3\。使用 Beautiful Soup 构建解析器
在提取数据之前,我们需要将原始 HTML 转换为格式化或解析数据。我们将这个解析后的 HTML 存储到一个汤对象中,如下所示:
汤 u003d BeautifulSoup(response.text, 'html.parser')
从这里,我们可以使用 HTML 标签及其属性遍历解析树。
如果我们回到页面上的表格,我们已经看到表格包含在<table>标记之间,类别为stripe dataTable,我们可以使用它来选择表格。
table u003d soup.find('table', class_ u003d 'stripe')
打印(表)
**注意:**经过测试,添加第二个类(dataTable)并没有返回元素。实际上,在返回元素中,表的类只有stripe。你也可以使用 id u003d ‘example’。
这是它返回的内容:

现在我们抓取了表格,我们可以遍历行并抓取我们想要的数据。
###4\。循环遍历 HTML 表
回想一下表格的结构,每一行都由一个<tr>元素表示,其中有一个包含数据的<td>元素,所有这些都包裹在一个<tbody>标记对之间。
为了提取数据,我们将创建两个用于外观,一个用于获取表的<tbody>部分(所有行都在其中),另一个用于将所有行存储到我们可以使用的变量中:
对于 table.find_all('tbody') 中的employee_data:
行 u003d employee_data.find_all('tr')
打印(行)
在行中,我们将存储在表的主体部分中找到的所有<tr>元素。如果您遵循我们的逻辑,下一步是将每一行存储到一个对象中并循环遍历它们以找到所需的数据。
首先,让我们尝试使用.querySelectorAll()方法在浏览器控制台上选择第一个员工的姓名。这种方法的一个非常有用的特性是,我们可以越来越深入地实现层次结构,实现大于 (>) 符号来定义父元素(左侧)和我们想要抓取的子元素(右侧)。
document.querySelectorAll('table.stripe &amp;amp;gt; tbody &amp;amp;gt; tr &amp;amp;gt; td')[0]

那再好不过了。如你所见,一旦我们抓住所有
元素,这些成为节点列表。因为我们不能依赖一个类来抓取每个单元格,所以我们只需要知道它们在索引中的位置,第一个名称是 0。
从那里,我们可以像这样编写我们的代码:
对于行中的行:
名称 u003d row.find_all('td')[0].text
打印(名称)
简单来说,我们逐行获取每一行,并找到里面的所有单元格,一旦我们有了列表,我们只抓取索引中的第一个(位置 0)并使用 .text 方法完成抓取元素的文本,忽略我们不需要的 HTML 数据。

他们在那里,一个包含所有员工姓名的列表!其余的,我们只需遵循相同的逻辑:
位置 u003d row.find_all('td')[1].text
office u003d row.find_all('td')[2].text
年龄 u003d row.find_all('td')[3].text
start_date u003d row.find_all('td')[4].text
薪水 u003d row.find_all('td')[5].text
但是,将所有这些数据打印在我们的控制台上并不是很有帮助。相反,让我们将这些数据存储为一种新的、更有用的格式。
###5\。将表格数据存储到 JSON 文件中
虽然我们可以轻松地创建一个 CSV 文件并将我们的数据发送到那里,但如果我们可以使用抓取的数据创建新的东西,那将不是最易于管理的格式。
不过,这是我们几个月前做的一个项目,解释了如何创建一个 CSV 文件来存储抓取的数据。
好消息是 Python 有自己的 JSON 模块来处理 JSON 对象,所以我们不需要安装任何东西,只需导入它。
导入json
但是,在我们继续创建 JSON 文件之前,我们需要将所有这些抓取的数据变成一个列表。为此,我们将在循环之外创建一个空数组。
员工名单 u003d []
然后将数据附加到它,每个循环都将一个新对象附加到数组中。
员工列表。附加({
'名称':名称,
'位置':位置,
“办公室”:办公室,
“年龄”:年龄,
'开始日期': start_date,
“薪水”:薪水
})
如果我们使用print(employee_list),结果如下:

还是有点乱,但我们有一组准备好转换为 JSON 的对象。
注意: 作为测试,我们打印了employee_list的长度,它返回 57,这是我们抓取的正确行数(行现在是数组中的对象)。
将列表导入 JSON 只需要两行代码:
使用 open('json_data', 'w') 作为 json_file:
json.dump(employee_list, json_file, indentu003d2)
-
首先,我们打开一个新文件,传入我们想要的文件名称
(json_data)和“w”,因为我们要向它写入数据。 -
接下来,我们使用
.dump()函数转储数组(``employee_list``)和indent=2中的数据,这样每个对象都有自己的行,而不是所有内容都在一个不可读的行中。
###6\。运行脚本和完整代码
如果您一直在关注,您的代码库应如下所示:
#依赖关系
导入请求
从 bs4 导入 BeautifulSoup
导入json
url u003d 'http://api.scraperapi.com?api_keyu003d51e43be283e4db2a5afbxxxxxxxxxxx&urlu003dhttps://datatables.net/examples/styling/stripe.html'
#空数组
员工名单 u003d []
#请求和解析 HTML 文件
响应 u003d requests.get(url)
汤 u003d BeautifulSoup(response.text, 'html.parser')
#选择表
table u003d soup.find('table', class_ u003d 'stripe')
#将所有行存储到一个变量中
对于 table.find_all('tbody') 中的employee_data:
行 u003d employee_data.find_all('tr')
#循环遍历 HTML 表格以抓取数据
对于行中的行:
名称 u003d row.find_all('td')[0].text
位置 u003d row.find_all('td')[1].text
office u003d row.find_all('td')[2].text
年龄 u003d row.find_all('td')[3].text
start_date u003d row.find_all('td')[4].text
薪水 u003d row.find_all('td')[5].text
#将抓取的数据发送到空数组
员工列表。附加({
'名称':名称,
'位置':位置,
“办公室”:办公室,
“年龄”:年龄,
'开始日期': start_date,
“薪水”:薪水
})
#将数组导入JSON文件
使用 open('employee_data', 'w') 作为 json_file:
json.dump(employee_list, json_file, indentu003d2)
**注意:**我们为上下文添加了一些评论。
下面是 JSON 文件中的前三个对象:
! swz 100101 swz 100102 swz 100100
以 JSON 格式存储抓取的数据允许我们将信息重新用于新应用程序或
##使用 Pandas 抓取 HTML 表格
在您离开页面之前,我们想探索第二种抓取 HTML 表格的方法。只需几行代码,我们就可以从 HTML 文档中抓取所有表格数据,并使用 Pandas 将其存储到数据框中。
在项目目录中创建一个新文件夹(我们将其命名为 pandas-html-table-scraper)并创建一个新文件名 pandas_table_scraper.py。
让我们打开一个新终端并导航到我们刚刚创建的文件夹(cd pandas-html-table-scraper),然后从那里安装 pandas:
点安装熊猫
我们在文件顶部导入它。
将熊猫导入为 pd
Pandas 有一个名为read_html()的函数,它基本上为我们抓取目标 URL 并将所有 HTML 表作为 DataFrame 对象列表返回。
但是,要使其正常工作,HTML 表的结构至少需要体面一些,因为该函数将查找类似的元素
识别文件中的表。
要使用该函数,让我们创建一个新变量并将我们之前使用的 URL 传递给它:
employee_data u003d pd.read_html('http://api.scraperapi.com?api_keyu003d51e43be283e4db2a5afbxxxxxxxxxxxx&urlu003dhttps://datatables.net/examples/styling/stripe.html')
打印时,它会返回页面内的 HTML 表格列表。
! swz 100110 swz 100111 swz 100109
如果我们比较 DataFrame 中的前三行,它们与我们用 Beautiful Soup 抓取的数据完美匹配。
为了使用 JSON,Pandas 可以内置一个[.to\json()](https://appdividend.com/2022/03/15/pandas-to_json/#:~:text=To%20convert%20the%20object%20to,use%20the%20to_json()%20 function.) 函数。它将 DataFrame 对象列表转换为 JSON 字符串
我们需要做的就是调用 DataFrame 上的方法并传入路径、格式(拆分、数据、记录、索引等)并添加缩进以使其更具可读性:
employee_data[0].to_json('./employee_list.json', orientu003d'index', indentu003d2)
如果我们现在运行我们的代码,结果文件如下:

请注意,我们需要从索引 ([0]) 中选择我们的表,因为 .read_html() 返回一个列表而不是单个对象。
这是供您参考的完整代码:
将熊猫导入为 pd
employee_data u003d pd.read_html('http://api.scraperapi.com?api_keyu003d51e43be283e4db2a5afbxxxxxxxxxxxx&urlu003dhttps://datatables.net/examples/styling/stripe.html')
employee_data[0].to_json('./employee_list.json', orientu003d'index', indentu003d2)
有了这些新知识,您就可以开始抓取网络上几乎所有的 HTML 表格了。请记住,如果您了解网站的结构及其背后的逻辑,那么没有什么是您无法抓取的。
也就是说,这些方法仅在数据位于 HTML 文件中时才有效。如果遇到动态生成的表,则需要找到一种新方法。对于这些类型的表,我们创建了一个分步指南来使用 Python抓取 JavaScript 表,而无需无头浏览器。
直到下一次,快乐刮!
原文发表于 Scraper API:How to Use Python to Loop Through HTML Tables and Scrape Tabular Data

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)