Multiple Classes, and IndexError: list index out of range Error's
问题:Multiple Classes, and IndexError: list index out of range Error's
当我尝试通过调用以下代码从“句子”类中打印一个示例时
examp3 = soup1.find_all(class_='sentence')
print(examp3[0].get_text())
它会给我一个如下所示的错误
Traceback (most recent call last):
File "/home/hudacse6/WebScrape/webscrape.py", line 33, in <module>
print(examp3[0].get_text())
IndexError: list index out of range
这是我要调用和打印的网页图片
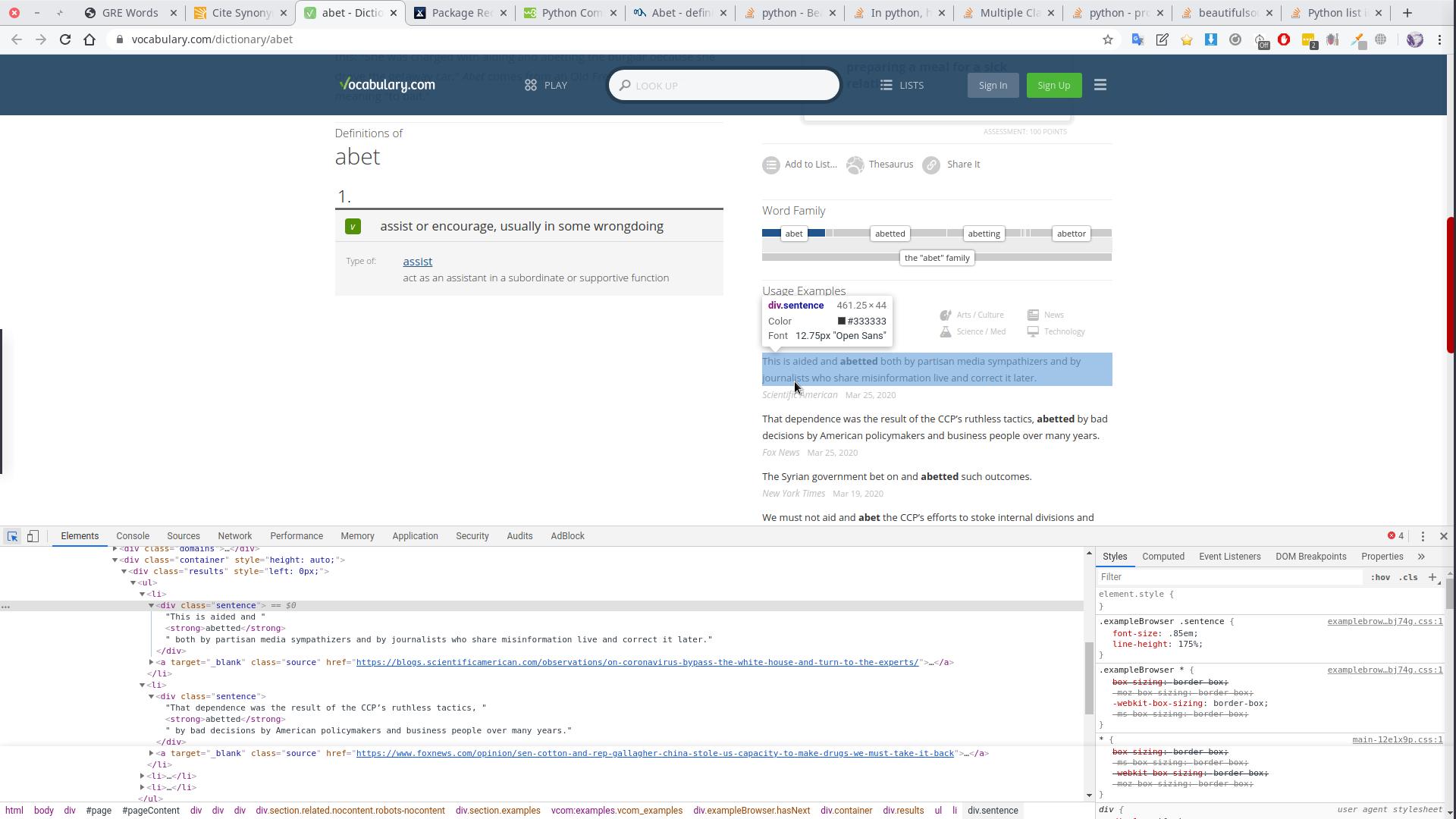
如何克服这个错误?
这是我的完整 html.parser 代码
import requests
from bs4 import BeautifulSoup
page1 = requests.get('https://www.vocabulary.com/dictionary/abet')
page2 = requests.get('https://www.thesaurus.com/browse/cite?s=t')
page3 = requests.get('https://dictionary.cambridge.org/dictionary/english/abet')
page4 = requests.get('https://www.merriam-webster.com/dictionary/abet')
soup1 = BeautifulSoup(page1.content, 'html.parser')
soup2 = BeautifulSoup(page2.content, 'html.parser')
soup3 = BeautifulSoup(page3.content, 'html.parser')
soup4 = BeautifulSoup(page4.content, 'html.parser')
synonyms2 = soup1.find_all(class_='short')
synonyms3 = soup1.find_all(class_='long')
print("Short Description of ABET: ", synonyms2[0].get_text(), "\n", )
print("Brief Description of ABET: ", synonyms3[0].get_text(), "\n", )
syn = soup2.find_all('a', class_='css-18rr30y etbu2a31')
find_syn = [syns.get_text() for syns in syn]
# print(syn[0].get_text())
print("Most relevant Synonyms of ABET: ", find_syn, "\n", )
print("Examples Of ABET: ")
exmp1 = soup3.find_all(class_='eg deg')
print(exmp1[0].get_text())
examp2 = soup4.find_all(class_='mw_t_sp')
print(examp2[0].get_text())
examp3 = soup1.find_all(class_='sentence')
print(examp3[0].get_text())
我曾尝试一次调用多个同名类以使用下面的代码打印类文本,但只调用并打印第一个类。第二个不工作。
#soup.findAll(True, {'class':['class1', 'class2']}) --Main Code
examp2 = soup4.findAll(True, {'class': ['mw_t_sp', 'ex-sent first-child t no-aq sents']})
print(examp2[1].get_text())
只这个印刷
ABET 的例子:
教唆犯罪
这是我称之为的图片。
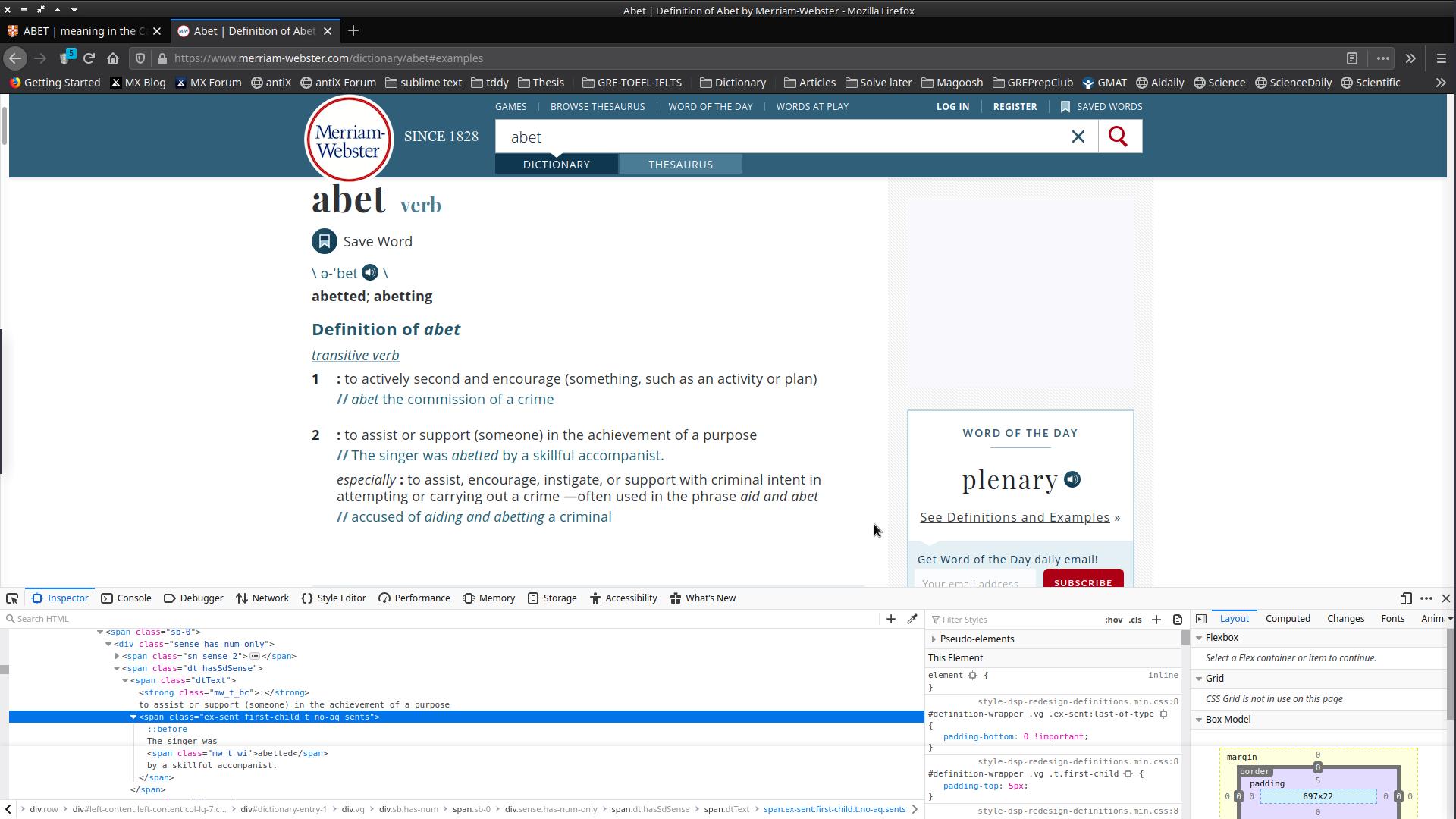
上面的代码有什么问题吗?
解答
页面https://www.vocabulary.com/dictionary/abet使用 javascript 加载“使用示例”下的内容。
BeautifulSoup 不像浏览器那样运行 javascript,因此您收到的请求没有任何class_='sentence'项。
“列表索引超出范围”错误,仅表示列表中没有元素 [0]。
您可能需要解析 json 响应(参见屏幕截图)或使用 selenium,这些方法更具挑战性。
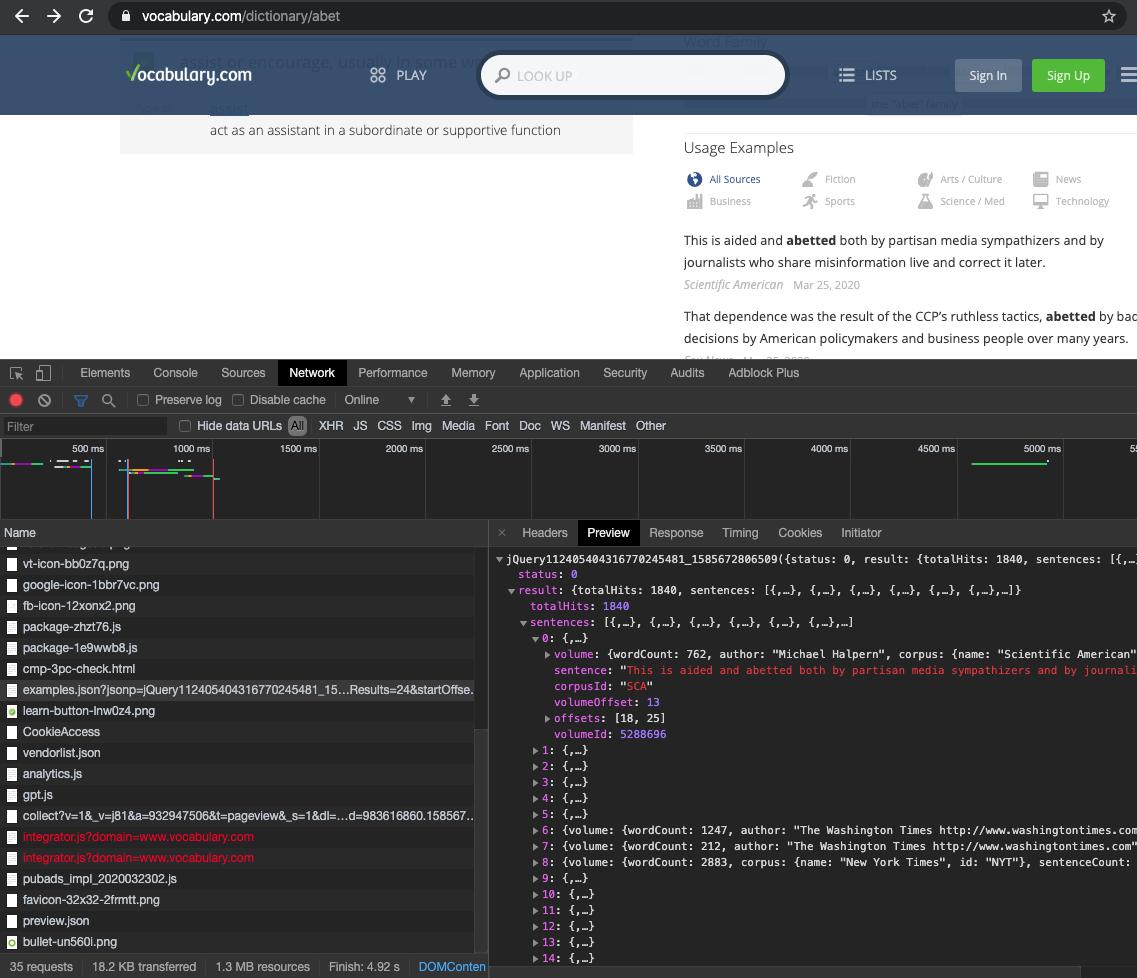
我可以帮助您处理 json 响应。
根据 chrome 中的网络 devTools 获取 de json 响应的完整链接类似于:https://corpus.vocabulary.com/api/1.0/examples.json?jsonpu003djQuery112407918468215082872_1585769422264&queryu003dabet&maxResultsu003d24&startOffsetu003d0&filteru003d0& _u003d1585769422265
我们可以尝试将其简化。此链接似乎工作正常:https://corpus.vocabulary.com/api/1.0/examples.json?queryu003dabet&maxResultsu003d4
所以:
import requests
from bs4 import BeautifulSoup
import json
def parse_vocabulary_com_examples (word):
num_of_examples = 4
url = "https://corpus.vocabulary.com/api/1.0/examples.json?query=" + word + "&maxResults=" + str(num_of_examples)
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
dictionary = json.loads(str(soup))
for i in range (0,num_of_examples):
print("------------------------------------------------------")
print("name:", dictionary["result"]["sentences"][i]["volume"]["corpus"]["name"])
print("sentence:", dictionary["result"]["sentences"][i]["sentence"])
print("datePublished:", dictionary["result"]["sentences"][i]["volume"]["dateAdded"][:10])
parse_vocabulary_com_examples("abet")
返回:
------------------------------------------------------
name: Scientific American
sentence: This is aided and abetted both by partisan media sympathizers and by journalists who share misinformation live and correct it later.
datePublished: 2020-03-25
------------------------------------------------------
name: Fox News
sentence: That dependence was the result of the CCP’s ruthless tactics, abetted by bad decisions by American policymakers and business people over many years.
datePublished: 2020-03-25
------------------------------------------------------
name: New York Times
sentence: The Syrian government bet on and abetted such outcomes.
datePublished: 2020-03-22
------------------------------------------------------
name: Washington Post
sentence: We must not aid and abet the CCP’s efforts to stoke internal divisions and spread disinformation.
datePublished: 2020-03-20
显然,您需要将它集成到您的解析器循环中,添加错误控制(没有结果,例如没有可用的日期,或有限的结果,小于 4 或没有)。还要遵守抓取政策;)
为了搜索所有类出现:
import requests
from bs4 import BeautifulSoup
page4 = requests.get('https://www.merriam-webster.com/dictionary/abet')
soup4 = BeautifulSoup(page4.content, 'html.parser')
examples = soup4.findAll(True, {'class': 'ex-sent first-child t no-aq sents'})
print("Number of elements found:", len(examples))
for i in examples:
print("------------------------------------------------------")
print(i.text.strip())
返回:
Number of elements found: 3
----------------------------------------------
abet the commission of a crime
----------------------------------------------
The singer was abetted by a skillful accompanist.
----------------------------------------------
accused of aiding and abetting a criminal
您可以尝试以下方法,但它返回 26 个匹配项,即“查看更多”按钮下的隐藏结果。请注意,搜索类现在是一个列表,它是一种限制较少的形式,因此可以获得更多结果。此外,类不能包含空格。
import requests
from bs4 import BeautifulSoup
page4 = requests.get('https://www.merriam-webster.com/dictionary/abet')
soup4 = BeautifulSoup(page4.content, 'html.parser')
examples = soup4.findAll(True, {'class': ['ex-sent', 'first-child', 't', 'no-aq', 'sents']})
print("Number of elements found:", len(examples))
for i in examples:
print("----------------------------------------------")
print(i.text.strip())

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)