BeautifulSoup Web Scraping 在结果集中查找特定键的值
·
问题:BeautifulSoup Web Scraping 在结果集中查找特定键的值
我正在用漂亮的汤刮网页:
import requests
from bs4 import BeautifulSoup
r= requests.get("https://cooking.nytimes.com/recipes/1018849-classic-caprese-salad?action=click&module=Collection%20Page%20Recipe%20Card®ion=46%20Ways%20to%20Do%20Justice%20to%20Summer%20Tomatoes&pgType=collection&rank=1")
c= r.content
soup= BeautifulSoup(c, "html.parser")
result= soup.find("script", {"type": "application/ld+json"})
print(type(result))
<class 'bs4.element.Tag'> , 1
print(len(result))
0
这是“结果”的样子:
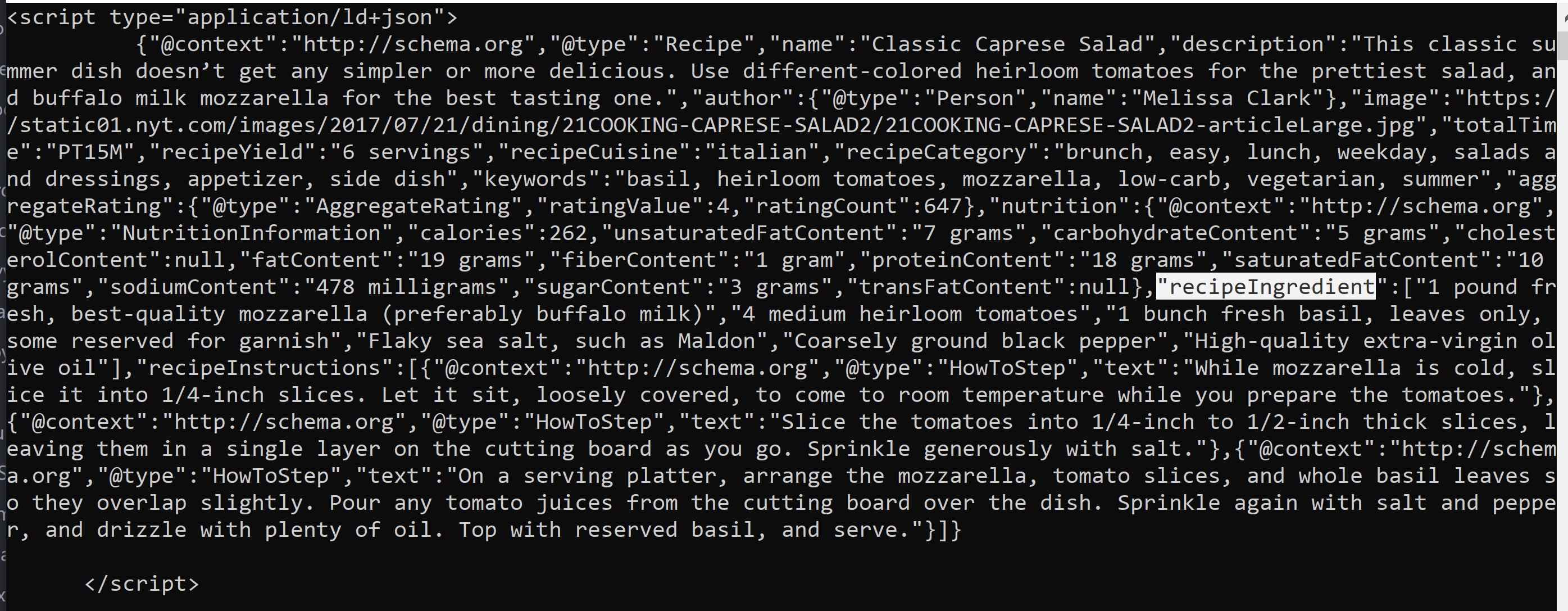
我无法将 recipeIngredient(在图像中突出显示)作为字典键访问。它给了我一个关键错误。
print(result['recipeIngredient'])
KeyError:'recipeIngredient'
我怎样才能做到这一点?我想从“结果”中提取这个:
“recipeIngredient”:[“1 磅新鲜,最优质的马苏里拉奶酪(最好是水牛奶)”,“4 个中等大小的传家宝西红柿”,“1 束新鲜罗勒,仅叶子,一些留作装饰”,“片状海盐,例如as Maldon","粗磨黑胡椒粉","优质特级初榨橄榄油"]
解答
您需要使用json.loads将脚本标签内的数据转换为 json。为了获取脚本标签内的数据,使用.get_text方法
import requests, json
from bs4 import BeautifulSoup
r= requests.get("https://cooking.nytimes.com/recipes/1018849-classic-caprese-salad?action=click&module=Collection%20Page%20Recipe%20Card®ion=46%20Ways%20to%20Do%20Justice%20to%20Summer%20Tomatoes&pgType=collection&rank=1")
c= r.content
soup= BeautifulSoup(c, "html.parser")
result= soup.find("script", {"type": "application/ld+json"})
data = json.loads(result.get_text())
print(data["recipeIngredient"])
输出:
['1 pound fresh, best-quality mozzarella (preferably buffalo milk)', '4 medium heirloom tomatoes', '1 bunch fresh basil, leaves only, some reserved for garnish', 'Flaky sea salt, such as Maldon', 'Coarsely ground black pepper', 'High-quality extra-virgin olive oil']

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)