BeautifulSoup find_all 没有找到一个类的所有容器
·
问题:BeautifulSoup find_all 没有找到一个类的所有容器
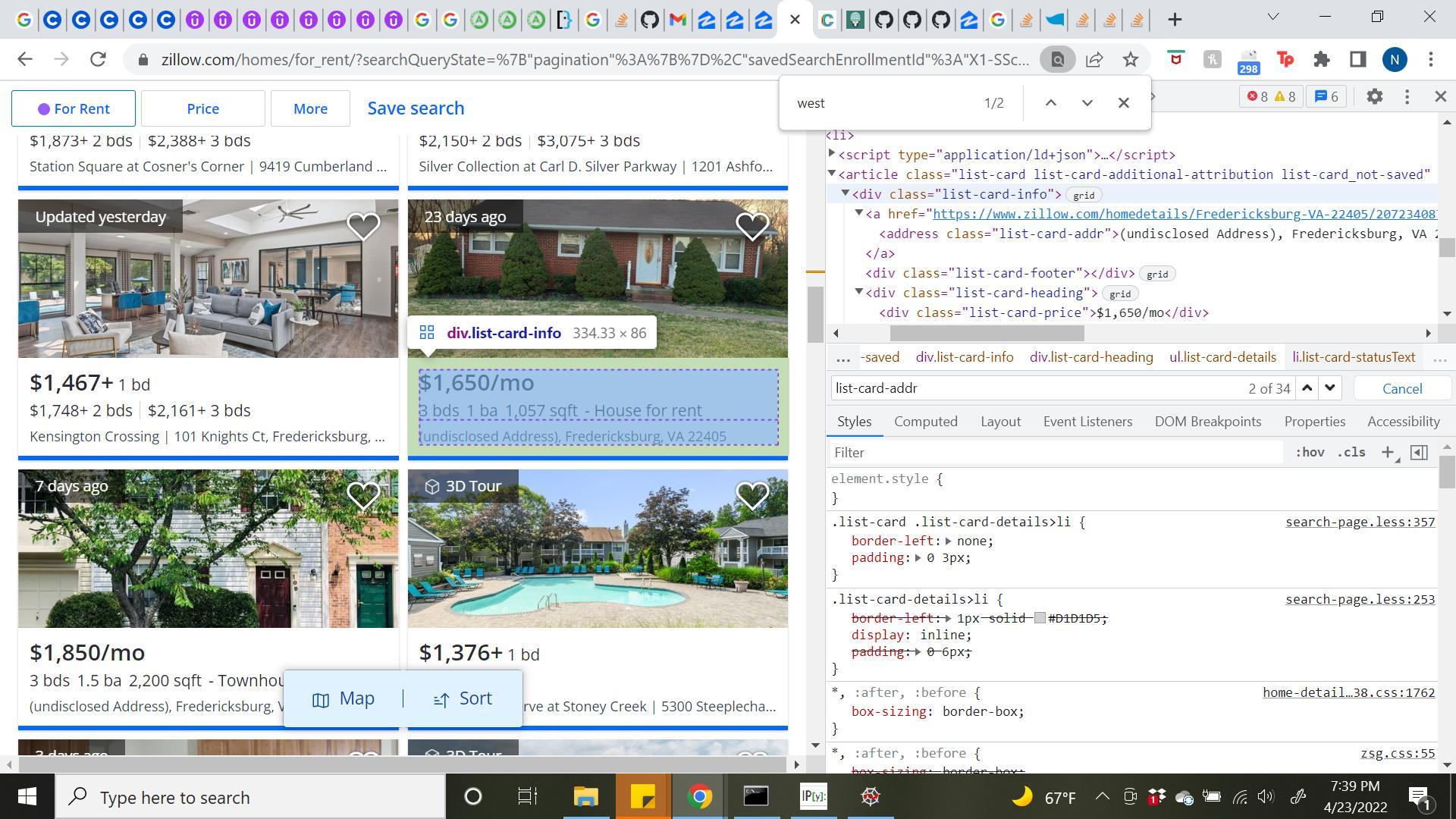
我正在尝试编写一个脚本来从 Zillow 页面上刮取一些数据(https://www.zillow.com/homes/for_rent/38.358484,-77.27869,38.218627,-77.498417_rect/X1-SSc26hnbsm6l2u1000000000\ _8e08t_sse/)。显然,我只是想从每个列表中收集数据。但是我无法从每个列表中获取数据,因为它只能找到我正在搜索的类的 9 个实例('list-card-addr'),即使我已经从列表中检查了它没有找到的 html 并且该类存在.任何人都知道这是为什么?这是我的简单代码
from bs4 import BeautifulSoup
import requests
req_headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.8',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
url="https://www.zillow.com/homes/for_rent/38.358484,-77.27869,38.218627,-77.498417_rect/X1-SSc26hnbsm6l2u1000000000_8e08t_sse/"
response = requests.get(url, headers=req_headers)
data = response.text
soup = BeautifulSoup(data,'html.parser')
address = soup.find_all(class_='list-card-addr')
print(len(address))
解答
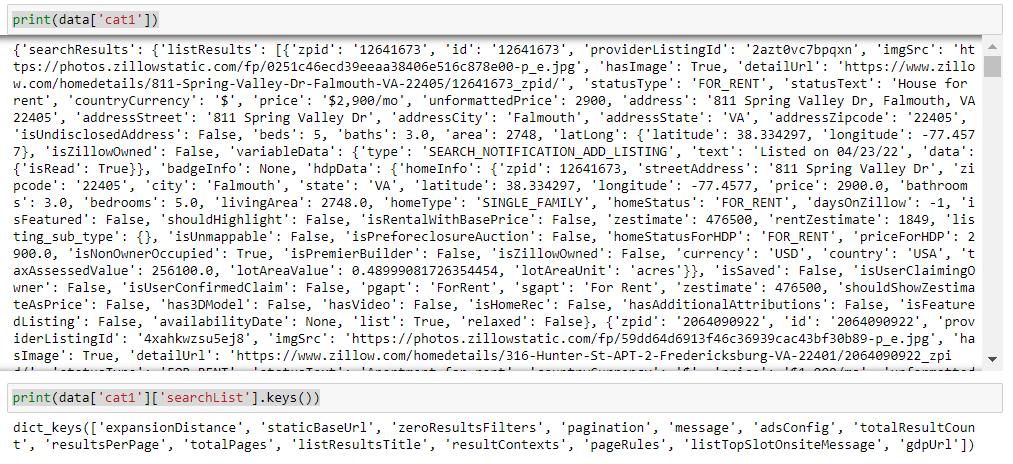
数据存储在评论中。您可以轻松地将其作为字符串定义 JavaScript 对象,您可以使用 json 处理它
import requests, re, json
r = requests.get('https://www.zillow.com/homes/for_rent/?searchQueryState=%7B%22pagination%22%3A%7B%7D%2C%22savedSearchEnrollmentId%22%3A%22X1-SSc26hnbsm6l2u1000000000_8e08t%22%2C%22mapBounds%22%3A%7B%22west%22%3A-77.65840518457031%2C%22east%22%3A-77.11870181542969%2C%22south%22%3A38.13250414385234%2C%22north%22%3A38.444339281260426%7D%2C%22isMapVisible%22%3Afalse%2C%22filterState%22%3A%7B%22sort%22%3A%7B%22value%22%3A%22mostrecentchange%22%7D%2C%22fsba%22%3A%7B%22value%22%3Afalse%7D%2C%22fsbo%22%3A%7B%22value%22%3Afalse%7D%2C%22nc%22%3A%7B%22value%22%3Afalse%7D%2C%22fore%22%3A%7B%22value%22%3Afalse%7D%2C%22cmsn%22%3A%7B%22value%22%3Afalse%7D%2C%22auc%22%3A%7B%22value%22%3Afalse%7D%2C%22fr%22%3A%7B%22value%22%3Atrue%7D%2C%22ah%22%3A%7B%22value%22%3Atrue%7D%7D%2C%22isListVisible%22%3Atrue%2C%22mapZoom%22%3A11%7D',
headers = {'User-Agent':'Mozilla/5.0'})
data = json.loads(re.search(r'!--(\{"queryState".*?)-->', r.text).group(1))
print(data['cat1'])
print(data['cat1']['searchList'].keys())
其中包含有关分页和下一个 url(如果适用)的详细信息,以获取所有结果。您在这里只要求第 1 页。
例如,打印地址
for i in data['cat1']['searchResults']['listResults']:
print(i['address'])

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)