Issues for data scraping with BeautifulSoup4
·
Answer a question
So basically i'm trying to scrape jobs website, my goal is to retrieve job title, company, salary, location. Which i'm planning to get into csv file so I could do some plotting of it. My current code is:
from urllib.request import urlopen as uReq
from bs4 import BeautifulSoup as soup
my_url = 'https://www.cvbankas.lt/?miestas=Vilnius&padalinys%5B0%5D=76&page=1'
#Opening up connection, grabbing the page
uClient = uReq(my_url)
page_html = uClient.read()
uClient.close()
#HTML parser
page_soup = soup(page_html, 'html.parser')
# grabs each product
containers = page_soup.findAll('div',{'class':'list_a_wrapper'})
contain = containers[0]
container = containers[0]
print(container.h3)
And returns me:
<h3 class="list_h3" lang="en">Senior Talent Manager</h3>
If I ask: container.h3['class'] this returns ['h3_class'] , If I ask: container.h3['lang'] I get en but I can't retrieve Senior Talent Manager
Here is on of the job add HTML code:
<div class="list_a_wrapper">
<div class="list_cell">
<h3 class="list_h3" lang="en">Senior Talent Manager</h3>
<span class="heading_secondary">
<span class="dib mt5">UAB „Omnisend“</span></span>
</div>
<div class="list_cell jobadlist_list_cell_salary">
<span class="salary_c">
<span class="salary_bl salary_bl_gross">
<span class="salary_inner">
<span class="salary_text">
<span class="salary_amount">2300-3300</span>
<span class="salary_period">€/mėn.</span>
</span>
<span class="salary_calculation">Neatskaičius mokesčių</span>
</span>
</span>
<div class="salary_calculate_bl js_salary_calculate_a" data-href="https://www.cvbankas.lt/perskaiciuoti-skelbimo-atlyginima-6732785">
<div class="button_action">Skaičiuoti »</div>
<div class="salary_calculate_text">Į rankas per mėn.</div>
</div>
</span> </div>
<div class="list_cell list_ads_c_last">
<span class="txt_list_1" lang="lt"><span class="list_city">Vilniuje</span></span>
<span class="txt_list_2">prieš 4 d.</span>
</div>
</div>
So what approach would be the best to scrape: title which is in h3, dib mt5, salary_amount, salary_calculation, list_city.
Answers
This script will get job title, company, salary, location from the page:
import requests
from bs4 import BeautifulSoup
url = 'https://www.cvbankas.lt/?miestas=Vilnius&padalinys%5B0%5D=76&page=1'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
for h3 in soup.select('h3.list_h3'):
job_title = h3.get_text(strip=True)
company = h3.find_next(class_="heading_secondary").get_text(strip=True)
salary = h3.find_next(class_="salary_amount").get_text(strip=True)
location = h3.find_next(class_="list_city").get_text(strip=True)
print('{:<50} {:<15} {:<15} {}'.format(company, salary, location, job_title))
Prints:
UAB „Omnisend“ 2300-3300 Vilniuje Senior Talent Manager
UAB „BALTIC VIRTUAL ASSISTANTS“ Nuo 2700 Vilniuje SENIOR .NET C# DEVELOPER
UAB „Lexita“ 1200-2500 Vilniuje IT PROJEKTŲ VADOVAS (-Ė)
UAB „Nordcode technology“ 1200-2000 Vilniuje PHP developer (mid-level)
UAB „Nordcurrent Group“ Nuo 2300 Vilniuje SENIOR VAIZDO ŽAIDIMŲ TESTUOTOJAS
UAB „Inlusion Netforms“ 1500-3500 Vilniuje Senior C++ Programmer to work with Unreal (UE4) game engine
UAB „Solitera“ 1200-2800 Vilniuje Java(Spring Boot) Developer
UAB „Metso Lithuania“ Nuo 1300 Vilniuje BI DATA ANALYST
UAB „Atticae“ 1000-1500 Vilniuje PHP programuotojas (-a)
UAB „EIS Group Lietuva“ 2000-7000 Vilniuje SYSTEM ARCHITECT
UAB GF Bankas Nuo 1200 Vilniuje HelpDesk specialistas (-ė)
Tesonet 1000-3000 Vilniuje Swift Developer (Security Product)
UAB „Mark ID“ 1000-3000 Vilniuje Full Stack programuotojas
...and so on.
EDIT: To save as csv, you can use this script:
import requests
import pandas as pd
from bs4 import BeautifulSoup
all_data = []
for page in range(1, 9):
url = 'https://www.cvbankas.lt/?padalinys%5B0%5D=76&page=' + str(page)
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
for h3 in soup.select('h3.list_h3'):
job_title = h3.get_text(strip=True)
company = h3.find_next(class_="heading_secondary").get_text(strip=True)
salary = h3.find_next(class_="salary_amount")
salary = salary.get_text(strip=True) if salary else '-'
location = h3.find_next(class_="list_city").get_text(strip=True)
print('{:<50} {:<15} {:<15} {}'.format(company, salary, location, job_title))
all_data.append({
'Job Title': job_title,
'Company': company,
'Salary': salary,
'Location': location
})
df = pd.DataFrame(all_data)
df.to_csv('data.csv')
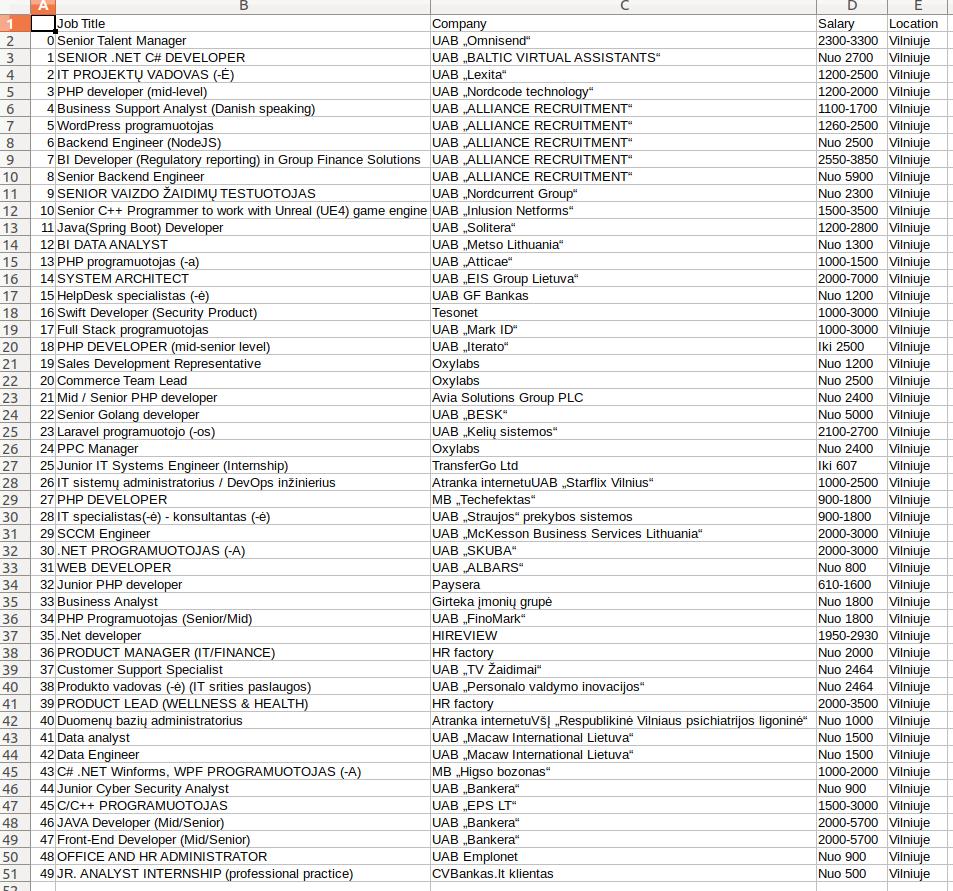
Saves data.csv (screenshot from LibreOffice):

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)