Scraping 'Title' from image with Python and bs4
Answer a question
I'm new to scraping with Python and are in need of some assistance. I'm doing my own first project during my internship at a BI-consultant firm and are building a data model to use in Qlik Sense.
I've managed to scrape the names and values from: Transfermarkt but now I would like to scrape the title of both club and country (which are visualised with a picture). Image scraping is something else (as I can understand, and a whole different set of code is needed). But I want the title, for example "France". Can somebody point me in the right direction?
Code updated with Pablos response. Now I get the error:
Traceback (most recent call last):
File "c:/Users/cljkn/Desktop/Python scraper github/.vscode/Scraping Transfermarkt.py", line 33, in <module>
df = pd.DataFrame({"Players":PlayersList,"Values":ValuesList,"Nationality":NationalityList})
File "C:\Users\cljkn\Desktop\Python scraper github\.venv\lib\site-packages\pandas\core\frame.py", line 435, in __init__
mgr = init_dict(data, index, columns, dtype=dtype)
File "C:\Users\cljkn\Desktop\Python scraper github\.venv\lib\site-packages\pandas\core\internals\construction.py", line 254, in init_dict
return arrays_to_mgr(arrays, data_names, index, columns, dtype=dtype)
File "C:\Users\cljkn\Desktop\Python scraper github\.venv\lib\site-packages\pandas\core\internals\construction.py", line 64, in arrays_to_mgr
index = extract_index(arrays)
File "C:\Users\cljkn\Desktop\Python scraper github\.venv\lib\site-packages\pandas\core\internals\construction.py", line 365, in extract_index
raise ValueError("arrays must all be same length")
ValueError: arrays must all be same length
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers = {'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36'}
page = "https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop"
pageTree = requests.get(page, headers=headers)
pageSoup = BeautifulSoup(pageTree.content, 'html.parser')
Players = pageSoup.find_all("a", {"class": "spielprofil_tooltip"})
Values = pageSoup.find_all("td", {"class": "rechts hauptlink"})
Nationality = pageSoup.find_all("td", {"class": "flaggenrahmen"}, {"title"})
for nat in Nationality:
img = nat.find('img')
title = img.get('title')
PlayersList = []
ValuesList = []
NationalityList = []
for i in range(0,25):
PlayersList.append(Players[i].text)
ValuesList.append(Values[i].text)
NationalityList.append(Nationality[i].text)
NationalityList.append('title')
df = pd.DataFrame({"Players":PlayersList,"Values":ValuesList,"Nationality":NationalityList})
df.head()
df.to_csv (r'C:\Users\cljkn\Desktop\Python scraper github\export_dataframe.csv', index = False, header=True)
print(df)
Any direct help with coding or source material would be most appreciated.
Answers
Well in this case, we need to use regex. because the HTML mixed up with some attributes.
For example :
title="https://www.transfermarkt.us/spieler-statistik/wertvollstespieler/marktwertetop"/>
AND
title="France"
So we need to use re to match title which doesn't start with http:
import re
for item in soup.findAll("img", class_="flaggenrahmen", title=re.compile("^(?!http).*")):
print(item.get("title"))
Output will be:
France
England
Jamaica
Brazil
Senegal
Egypt
England
Belgium
Argentina
Spain
England
France
England
Portugal
France
Mali
Germany
France
Netherlands
Suriname
France
Slovenia
Belgium
Portugal
Netherlands
Germany
Argentina
Italy
Germany
Cote d'Ivoire
Spain
Brazil
Now we will go into another issue: where you have players with two clubs instead of one:
Such as:

Now let's fix this. here's the full code:
import requests
from bs4 import BeautifulSoup
import re
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'
}
r = requests.get(
"https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop", headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
names = []
values = []
nats = []
for name in soup.findAll("img", class_="bilderrahmen-fixed"):
names.append(name.get("alt"))
for value in soup.findAll("td", class_="rechts hauptlink"):
values.append(value.get_text(strip=True))
for td in soup.findAll("td", class_="zentriert"):
inner_grp = []
for item in td.findAll("img", class_="flaggenrahmen", title=re.compile("^(?!http).*")):
#print(item.get('title'), end='')
if item.get('title'):
inner_grp.append(item.get('title'))
if inner_grp:
nats.append(inner_grp)
with open("result.csv", 'w', newline="") as f:
writer = csv.writer(f)
writer.writerow(["Name", "Value", "Nat"])
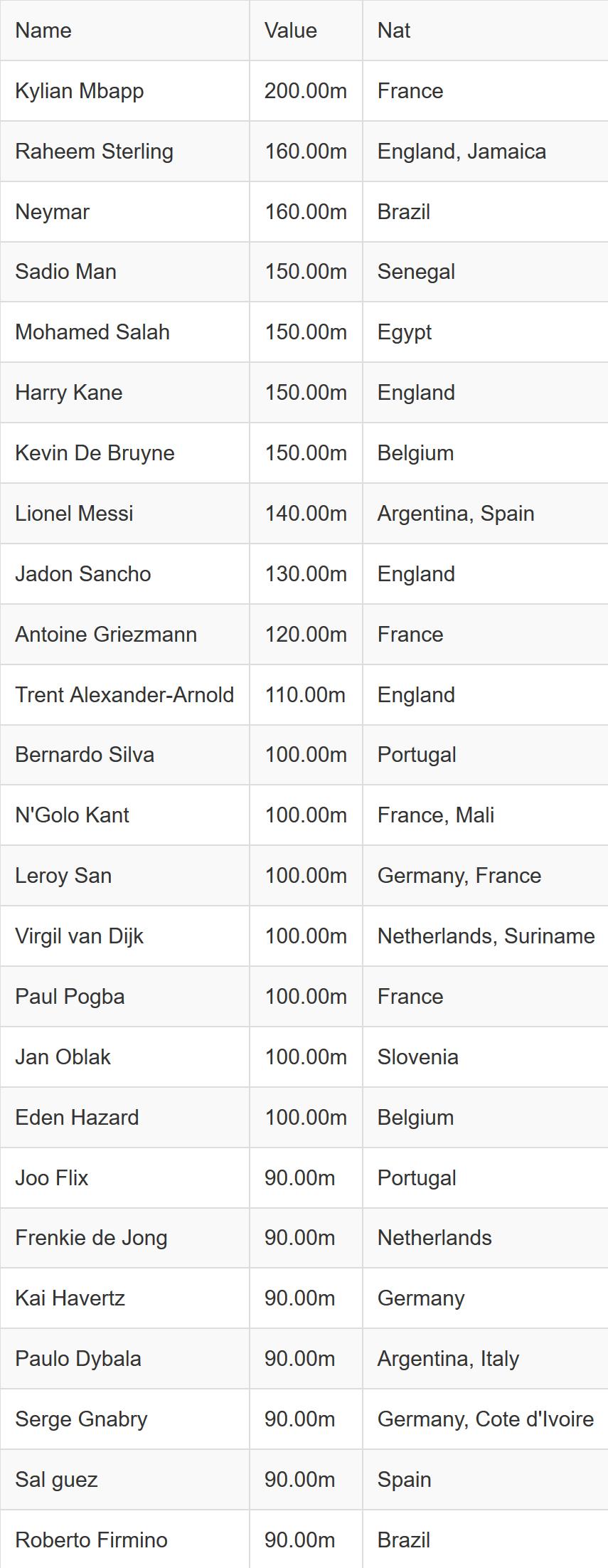
for a, b, c in zip(names, values, nats):
writer.writerow([a, b, ", ".join(c)])
print("Done")
Output: check-online

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)