I am making a script that repairs scanned documents and i now need a way to detect the image orientation and rotate the image so its rotation is correct.
Right now my script is unreliable and isn't that precise.
right now I look for a line and it rotates the first line it sees correctly but this barely works except for a few images
img_before = cv2.imread('rotated_377.jpg')
img_gray = cv2.cvtColor(img_before, cv2.COLOR_BGR2GRAY)
img_edges = cv2.Canny(img_gray, 100, 100, apertureSize=3)
lines = cv2.HoughLinesP(img_edges, 1, math.pi / 180.0, 100, minLineLength=100, maxLineGap=5)
angles = []
for x1,y1,x2,y2 in lines[0]:
angle = math.degrees(math.atan2(y2 - y1, x2 - x1))
angles.append(angle)
median_angle = np.median(angles)
img_rotated = ndimage.rotate(img_before, median_angle)
print("Angle is {}".format(median_angle))
cv2.imwrite('rotated.jpg', img_rotated)
I want to make a script that gets an image like this one(don't mind the image its for testing purposes) 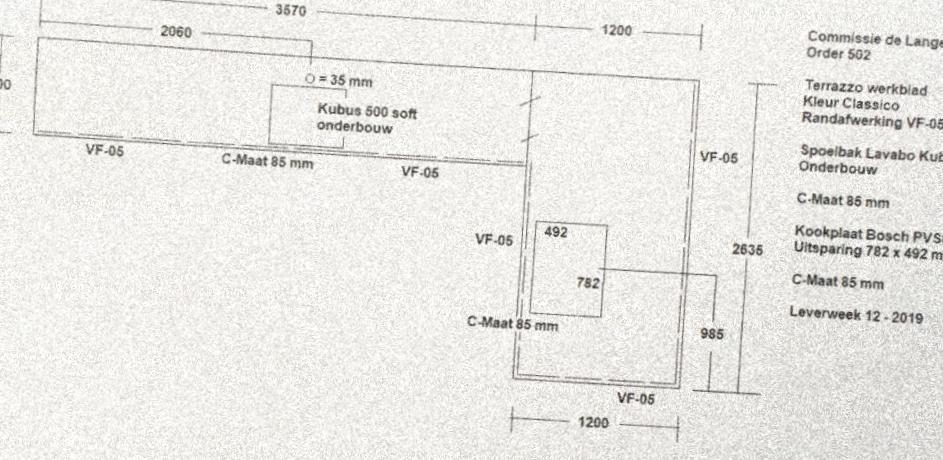
and rotates it in the right way so I get a correctly orientated image.
This is an interesting problem, i have tried with many approaches to correct orientation of document images but all of them have got different exceptions. I am sharing one of the approaches based on text orientation. For text region detection i am using gradient map of input image.
All other implementation details are commented in the code.
Please note that this only works if all the text present in image have same orientation.
#Document image orientation correction
#This approach is based on text orientation
#Assumption: Document image contains all text in same orientation
import cv2
import numpy as np
debug = True
#Display image
def display(img, frameName="OpenCV Image"):
if not debug:
return
h, w = img.shape[0:2]
neww = 800
newh = int(neww*(h/w))
img = cv2.resize(img, (neww, newh))
cv2.imshow(frameName, img)
cv2.waitKey(0)
#rotate the image with given theta value
def rotate(img, theta):
rows, cols = img.shape[0], img.shape[1]
image_center = (cols/2, rows/2)
M = cv2.getRotationMatrix2D(image_center,theta,1)
abs_cos = abs(M[0,0])
abs_sin = abs(M[0,1])
bound_w = int(rows * abs_sin + cols * abs_cos)
bound_h = int(rows * abs_cos + cols * abs_sin)
M[0, 2] += bound_w/2 - image_center[0]
M[1, 2] += bound_h/2 - image_center[1]
# rotate orignal image to show transformation
rotated = cv2.warpAffine(img,M,(bound_w,bound_h),borderValue=(255,255,255))
return rotated
def slope(x1, y1, x2, y2):
if x1 == x2:
return 0
slope = (y2-y1)/(x2-x1)
theta = np.rad2deg(np.arctan(slope))
return theta
def main(filePath):
img = cv2.imread(filePath)
textImg = img.copy()
small = cv2.cvtColor(textImg, cv2.COLOR_BGR2GRAY)
#find the gradient map
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
grad = cv2.morphologyEx(small, cv2.MORPH_GRADIENT, kernel)
display(grad)
#Binarize the gradient image
_, bw = cv2.threshold(grad, 0.0, 255.0, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
display(bw)
#connect horizontally oriented regions
#kernal value (9,1) can be changed to improved the text detection
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
connected = cv2.morphologyEx(bw, cv2.MORPH_CLOSE, kernel)
display(connected)
# using RETR_EXTERNAL instead of RETR_CCOMP
# _ , contours, hierarchy = cv2.findContours(connected.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
contours, hierarchy = cv2.findContours(connected.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) #opencv >= 4.0
mask = np.zeros(bw.shape, dtype=np.uint8)
#display(mask)
#cumulative theta value
cummTheta = 0
#number of detected text regions
ct = 0
for idx in range(len(contours)):
x, y, w, h = cv2.boundingRect(contours[idx])
mask[y:y+h, x:x+w] = 0
#fill the contour
cv2.drawContours(mask, contours, idx, (255, 255, 255), -1)
#display(mask)
#ratio of non-zero pixels in the filled region
r = float(cv2.countNonZero(mask[y:y+h, x:x+w])) / (w * h)
#assume at least 45% of the area is filled if it contains text
if r > 0.45 and w > 8 and h > 8:
#cv2.rectangle(textImg, (x1, y), (x+w-1, y+h-1), (0, 255, 0), 2)
rect = cv2.minAreaRect(contours[idx])
box = cv2.boxPoints(rect)
box = np.int0(box)
cv2.drawContours(textImg,[box],0,(0,0,255),2)
#we can filter theta as outlier based on other theta values
#this will help in excluding the rare text region with different orientation from ususla value
theta = slope(box[0][0], box[0][1], box[1][0], box[1][1])
cummTheta += theta
ct +=1
#print("Theta", theta)
#find the average of all cumulative theta value
orientation = cummTheta/ct
print("Image orientation in degress: ", orientation)
finalImage = rotate(img, orientation)
display(textImg, "Detectd Text minimum bounding box")
display(finalImage, "Deskewed Image")
if __name__ == "__main__":
filePath = 'D:\data\img6.jpg'
main(filePath)
Here is Image with detected text regions, from this we can see that some of the text regions are missing. Text orientation detection plays the key role here in overall document orientation detection so based on document type a few small tweaks should be made in the text detection algorithm to make this approach work better.
Here is the final image with correct orientation 
Please suggest modifications in this approaches to make it more robust.







 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)