如何使用 Python 只保留 Pandas 数据框中的连续值
·
回答问题
我有一个看起来像这样的数据框:
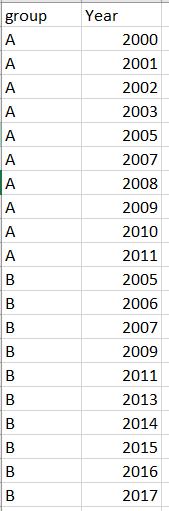
我想只保留每个组中的连续年份,例如下图,其中 A 组中的 2005 年和 B 组中的 2009 年和 2011 年被删除。
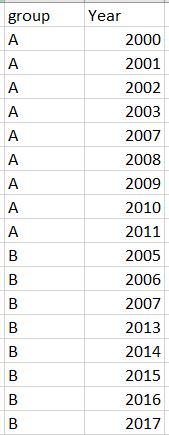
我使用df['year_diff']=df.groupby(['group'])['Year'].diff()创建了一个年差列,然后只保留年差等于1的行。
但是,此方法也会删除每个连续年份组中的第一行,因为第一行的年份差将为 NAN。例如,2000 年将从组 2000-2005 中删除。有没有办法可以避免这个问题?
Answers
shift
像 OP 一样获取年份差异。然后检查是否等于1或者之前的值是1
yd = df.Year.groupby(df.group).diff().eq(1)
df[yd | yd.shift(-1)]
group Year
0 A 2000
1 A 2001
2 A 2002
3 A 2003
5 A 2007
6 A 2008
7 A 2009
8 A 2010
9 A 2011
10 B 2005
11 B 2006
12 B 2007
15 B 2013
16 B 2014
17 B 2015
18 B 2016
19 B 2017
设置
谢谢你
a = [('A',x) for x in range(2000, 2012) if x not in [2004,2006]]
b = [('B',x) for x in range(2005, 2018) if x not in [2008,2010,2012]]
df = pd.DataFrame(a + b, columns=['group','Year'])

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)