在 python 中使用 Pandas ExcelWriter 时处理 Nan
·
回答问题
当我逐行遍历它并在 A 列中输出值时,我将如何更改以下代码以将 NaN 值处理为我的数据框中的空单元格?
excel = pd.ExcelWriter(f_name,engine='xlsxwriter')
wb = excel.book
ws = wb.add_worksheet('PnL')
for i in len(df):
ws.write(0,i,df.iloc[i]['A'])
Answers
我认为你可以使用fillna:
df = df.fillna(0)
或者:
df['A'] = df['A'].fillna(0)
但更好的是使用to_excel:
import pandas as pd
import numpy as np
# Create a Pandas dataframe from the data.
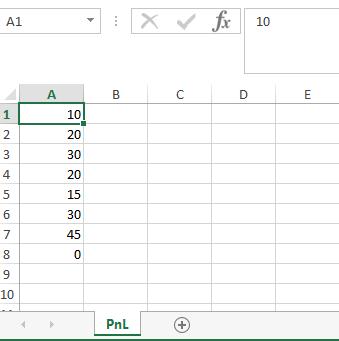
df = pd.DataFrame({'A': [10, 20, 30, 20, 15, 30, 45, np.nan],
'B': [10, 20, 30, 20, 15, 30, 45, np.nan]})
print df
A B
0 10 10
1 20 20
2 30 30
3 20 20
4 15 15
5 30 30
6 45 45
7 NaN NaN
#create subset, because cannot write Series to excel
df1 = df[['A']]
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('f_name.xlsx', engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object, instead NaN give 0
df1.to_excel(writer, sheet_name='PnL', na_rep=0)
如果要省略索引和标头,请添加参数index=False和header=False:
df1.to_excel(writer, sheet_name='PnL', na_rep=0, index=False, header=False)

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)