Python Pandas - 如何在 Excel 工作表的特定列中写入
·
回答问题
我无法通过在其中写入新值来使用 pandas 更新 Excel 工作表。我已经有一个从 MySheet1.xlsx 读取值的现有框架 df1。所以这需要要么是一个新的数据框,要么以某种方式复制和覆盖现有的数据框。
电子表格采用以下格式:
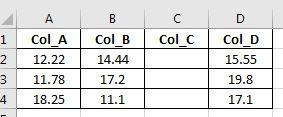
我有一个 python 列表:values_list u003d [12.34, 17.56, 12.45]。我的目标是在 Col_C 标题下垂直插入列表值。它目前正在水平覆盖整个数据帧,而不保留当前值。
df2 = pd.DataFrame({'Col_C': values_list})
writer = pd.ExcelWriter('excelfile.xlsx', engine='xlsxwriter')
df2.to_excel(writer, sheet_name='MySheet1')
workbook = writer.book
worksheet = writer.sheets['MySheet1']
如何得到这个最终结果?谢谢!
Answers
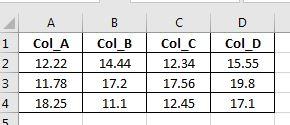
下面我提供了一个完全可重现的示例,说明如何使用 pandas 和 openpyxl 模块(Openpyxl 文档链接)修改现有的 .xlsx 工作簿。
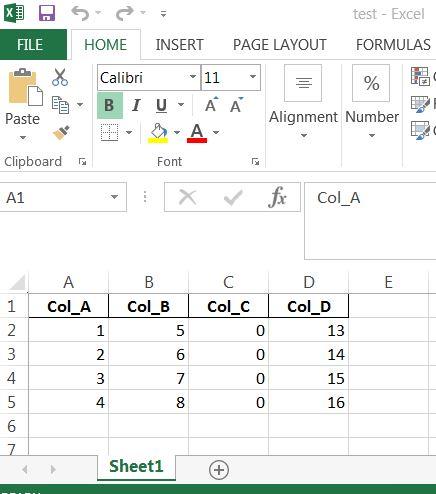
首先,出于演示目的,我创建了一个名为 test.xlsx 的工作簿:
from openpyxl import load_workbook
import pandas as pd
writer = pd.ExcelWriter('test.xlsx', engine='openpyxl')
wb = writer.book
df = pd.DataFrame({'Col_A': [1,2,3,4],
'Col_B': [5,6,7,8],
'Col_C': [0,0,0,0],
'Col_D': [13,14,15,16]})
df.to_excel(writer, index=False)
wb.save('test.xlsx')
这是此时的预期输出:
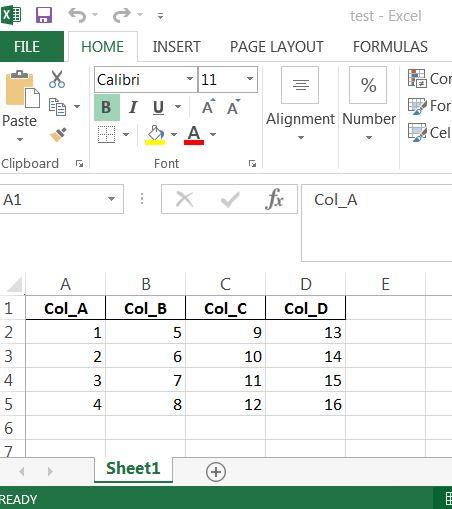
在第二部分中,我们加载现有工作簿('test.xlsx')并使用不同的数据修改第三列。
from openpyxl import load_workbook
import pandas as pd
df_new = pd.DataFrame({'Col_C': [9, 10, 11, 12]})
wb = load_workbook('test.xlsx')
ws = wb['Sheet1']
for index, row in df_new.iterrows():
cell = 'C%d' % (index + 2)
ws[cell] = row[0]
wb.save('test.xlsx')
这是最后的预期输出:

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)