如何在Python中进行实时语音活动检测?
·
回答问题
我正在对录制的音频文件执行语音活动检测,以检测波形中的语音与非语音部分。
分类器的输出看起来像(突出显示的绿色区域表示语音):
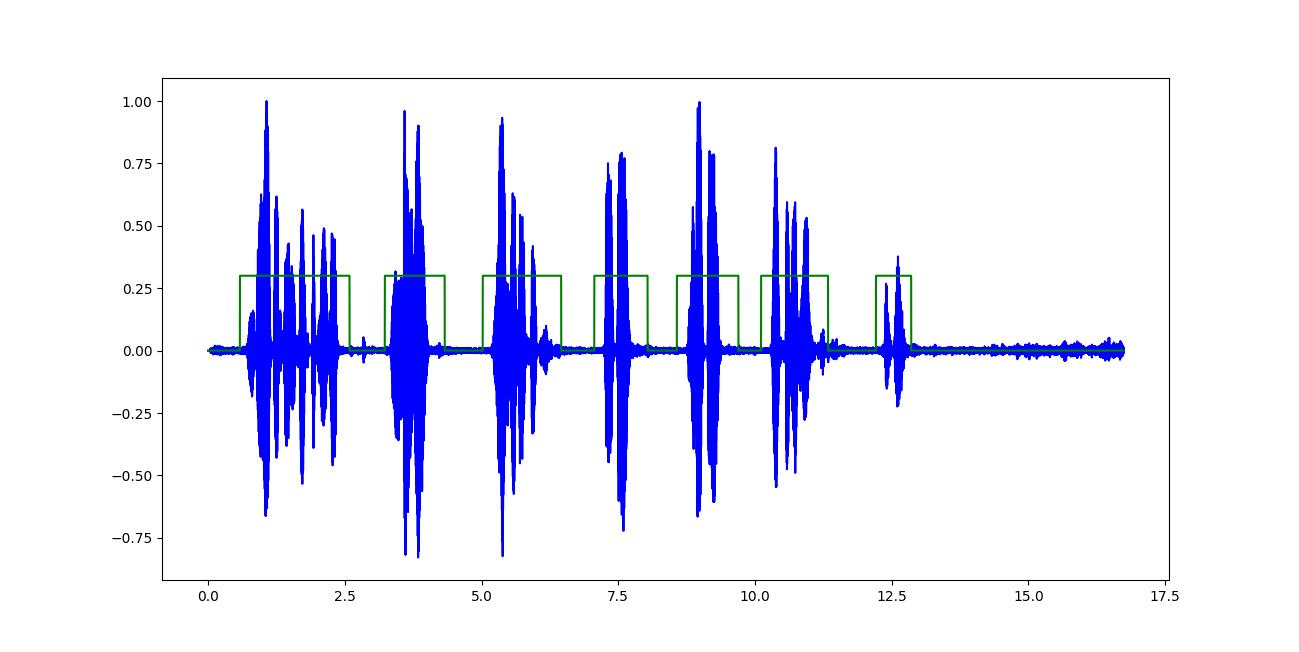
我在这里面临的唯一问题是使其适用于音频输入流(例如:来自麦克风)并在规定的时间范围内进行实时分析。
我知道PyAudio可用于动态记录来自麦克风的语音,并且有几个波形、频谱、频谱图等的实时可视化示例,但找不到与近实时进行特征提取相关的任何内容方式。
Answers
您应该尝试使用 Python 绑定到来自 Google](https://github.com/wiseman/py-webrtcvad)的[webRTC VAD。基于 GMM 建模,它轻量、快速并提供非常合理的结果。由于每帧都提供决策,因此延迟最小。
# Run the VAD on 10 ms of silence. The result should be False.
import webrtcvad
vad = webrtcvad.Vad(2)
sample_rate = 16000
frame_duration = 10 # ms
frame = b'\x00\x00' * int(sample_rate * frame_duration / 1000)
print('Contains speech: %s' % (vad.is_speech(frame, sample_rate))
此外,这篇文章可能对您有用。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)