C++ 使用 GDB 调试/打印自定义类型:nlohmann json 库的案例
回答问题
我正在使用nlohmann 的 json C++ 实现进行项目。
如何在 GDB 中轻松探索 nlohmann JSON 键/值?
我尝试使用这个包装](http://www.yolinux.com/TUTORIALS/src/dbinit_stl_views-1.03.txt)的[STL gdb,因为它提供了帮助来探索 nlohmann 的 JSON 库正在使用的标准 C++ 库结构。但是我觉得不方便。
这是一个简单的用例:
json foo;
foo["flex"] = 0.2;
foo["awesome_str"] = "bleh";
foo["nested"] = {{"bar", "barz"}};
我想在 GDB 中拥有的东西:
(gdb) p foo
{
"flex" : 0.2,
"awesome_str": "bleh",
"nested": etc.
}
当前行为
(gdb) p foo
$1 = {
m_type = nlohmann::detail::value_t::object,
m_value = {
object = 0x129ccdd0,
array = 0x129ccdd0,
string = 0x129ccdd0,
boolean = 208,
number_integer = 312266192,
number_unsigned = 312266192,
number_float = 1.5427999782486669e-315
}
}
(gdb) p foo.at("flex")
Cannot evaluate function -- may be inlined // I suppose it depends on my compilation process. But I guess it does not invalidate the question.
(gdb) p *foo.m_value.object
$2 = {
_M_t = {
_M_impl = {
<std::allocator<std::_Rb_tree_node<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, nlohmann::basic_json<std::map, std::vector, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, long long, unsigned long long, double, std::allocator, nlohmann::adl_serializer> > > >> = {
<__gnu_cxx::new_allocator<std::_Rb_tree_node<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, nlohmann::basic_json<std::map, std::vector, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, long long, unsigned long long, double, std::allocator, nlohmann::adl_serializer> > > >> = {<No data fields>}, <No data fields>},
<std::_Rb_tree_key_compare<std::less<void> >> = {
_M_key_compare = {<No data fields>}
},
<std::_Rb_tree_header> = {
_M_header = {
_M_color = std::_S_red,
_M_parent = 0x4d72d0,
_M_left = 0x4d7210,
_M_right = 0x4d7270
},
_M_node_count = 5
}, <No data fields>}
}
}
Answers
我发现我自己的答案进一步阅读了有关 std::string](https://stackoverflow.com/a/38790538/7237062)的[打印的 GDB 功能和堆栈溢出问题。 short path 是最简单的。另一条路很艰难,但我很高兴我能做到这一点。有很多改进的空间。
- 这里有一个关于这个特殊问题的未解决问题https://github.com/nlohmann/json/issues/1952*
短路径 v3.1.2
我简单地定义了一个 gdb 命令如下:
# this is a gdb script
# can be loaded from gdb using
# source my_script.txt (or. gdb or whatever you like)
define pjson
# use the lohmann's builtin dump method, ident 4 and use space separator
printf "%s\n", $arg0.dump(4, ' ', true).c_str()
end
# configure command helper (text displayed when typing 'help pjson' in gdb)
document pjson
Prints a lohmann's JSON C++ variable as a human-readable JSON string
end
在 gdb 中使用它:
(gdb) source my_custom_script.gdb
(gdb) pjson foo
{
"flex" : 0.2,
"awesome_str": "bleh",
"nested": {
"bar": "barz"
}
}
Short path v3.7.0 [EDIT] 2019-onv-06 One 也可以使用新的 to_string() 方法,但我无法通过实时劣质进程使其与 GDB 一起使用。下面的方法仍然有效。
# this is a gdb script
# can be loaded from gdb using
# source my_script.txt (or. gdb or whatever you like)
define pjson
# use the lohmann's builtin dump method, ident 4 and use space separator
printf "%s\n", $arg0.dump(4, ' ', true, json::error_handler_t::strict).c_str()
end
# configure command helper (text displayed when typing 'help pjson' in gdb)
document pjson
Prints a lohmann's JSON C++ variable as a human-readable JSON string
end
April 18th 2020:WORKING FULL PYTHON GDB(带有实时劣质进程和调试符号)
2020 年 4 月 26 日编辑:此处的代码(偏移量)出乎意料,并且不兼容所有平台/JSON 库编译。 github 项目在这个问题上要成熟得多(到目前为止测试了 3 个平台)。 代码原样保留在那里,因为我不会维护 2 个代码库。
版本:
-
https://github.com/nlohmann/json3.7.3版
-
GNU gdb (GDB) 8.3 for GNAT Community 2019 [rev=gdb-8.3-ref-194-g3fc1095] -
用
GPRBUILD/GNAT Community 2019 (20190517) (x86_64-pc-mingw32)搭建的c++项目
以下python代码应在gdb中加载。我使用来自 gdb. 的 .gdbinit 文件
Github 仓库:https://github.com/LoneWanderer-GH/nlohmann-json-gdb
GDB 脚本
随意采用您选择的加载方法(自动或不自动,或 IDE 插件等)
set print pretty
# source stl_parser.gdb # if you like the good work done with those STL containers GDB parsers
source printer.py # the python file is given below
python gdb.printing.register_pretty_printer(gdb.current_objfile(), build_pretty_printer())
Python 脚本
import gdb
import platform
import sys
import traceback
# adapted from https://github.com/hugsy/gef/blob/dev/gef.py
# their rights are theirs
HORIZONTAL_LINE = "_" # u"\u2500"
LEFT_ARROW = "<-" # "\u2190 "
RIGHT_ARROW = "->" # " \u2192 "
DOWN_ARROW = "|" # "\u21b3"
nlohmann_json_type_namespace = \
r"nlohmann::basic_json<std::map, std::vector, std::__cxx11::basic_string<char, std::char_traits<char>, " \
r"std::allocator<char> >, bool, long long, unsigned long long, double, std::allocator, nlohmann::adl_serializer>"
# STD black magic
MAGIC_STD_VECTOR_OFFSET = 16 # win 10 x64 values, beware on your platform
MAGIC_OFFSET_STD_MAP = 32 # win 10 x64 values, beware on your platform
""""""
# GDB black magic
""""""
nlohmann_json_type = gdb.lookup_type(nlohmann_json_type_namespace).pointer()
# for in memory direct jumps. cast to type is still necessary yet to obtain values, but this could be changed by chaning the types to simpler ones ?
std_rb_tree_node_type = gdb.lookup_type("std::_Rb_tree_node_base::_Base_ptr").pointer()
std_rb_tree_size_type = gdb.lookup_type("std::size_t").pointer()
""""""
# nlohmann_json reminder. any interface change should be reflected here
# enum class value_t : std::uint8_t
# {
# null, ///< null value
# object, ///< object (unordered set of name/value pairs)
# array, ///< array (ordered collection of values)
# string, ///< string value
# boolean, ///< boolean value
# number_integer, ///< number value (signed integer)
# number_unsigned, ///< number value (unsigned integer)
# number_float, ///< number value (floating-point)
# discarded ///< discarded by the the parser callback function
# };
""""""
enum_literals_namespace = ["nlohmann::detail::value_t::null",
"nlohmann::detail::value_t::object",
"nlohmann::detail::value_t::array",
"nlohmann::detail::value_t::string",
"nlohmann::detail::value_t::boolean",
"nlohmann::detail::value_t::number_integer",
"nlohmann::detail::value_t::number_unsigned",
"nlohmann::detail::value_t::number_float",
"nlohmann::detail::value_t::discarded"]
enum_literal_namespace_to_literal = dict([(e, e.split("::")[-1]) for e in enum_literals_namespace])
INDENT = 4 # beautiful isn't it ?
def std_stl_item_to_int_address(node):
return int(str(node), 0)
def parse_std_str_from_hexa_address(hexa_str):
# https://stackoverflow.com/questions/6776961/how-to-inspect-stdstring-in-gdb-with-no-source-code
return '"{}"'.format(gdb.parse_and_eval("*(char**){}".format(hexa_str)).string())
class LohmannJSONPrinter(object):
"""Print a nlohmann::json in GDB python
BEWARE :
- Contains shitty string formatting (defining lists and playing with ",".join(...) could be better; ident management is stoneage style)
- Parsing barely tested only with a live inferior process.
- It could possibly work with a core dump + debug symbols. TODO: read that stuff
https://doc.ecoscentric.com/gnutools/doc/gdb/Core-File-Generation.html
- Not idea what happens with no symbols available, lots of fields are retrieved by name and should be changed to offsets if possible
- NO LIB VERSION MANAGEMENT. TODO: determine if there are serious variants in nlohmann data structures that would justify working with strucutres
- PLATFORM DEPENDANT TODO: remove the black magic offsets or handle them in a nicer way
NB: If you are python-kaizer-style-guru, please consider helping or teaching how to improve all that mess
"""
def __init__(self, val, indent_level=0):
self.val = val
self.field_type_full_namespace = None
self.field_type_short = None
self.indent_level = indent_level
self.function_map = {"nlohmann::detail::value_t::null": self.parse_as_leaf,
"nlohmann::detail::value_t::object": self.parse_as_object,
"nlohmann::detail::value_t::array": self.parse_as_array,
"nlohmann::detail::value_t::string": self.parse_as_str,
"nlohmann::detail::value_t::boolean": self.parse_as_leaf,
"nlohmann::detail::value_t::number_integer": self.parse_as_leaf,
"nlohmann::detail::value_t::number_unsigned": self.parse_as_leaf,
"nlohmann::detail::value_t::number_float": self.parse_as_leaf,
"nlohmann::detail::value_t::discarded": self.parse_as_leaf}
def parse_as_object(self):
assert (self.field_type_short == "object")
o = self.val["m_value"][self.field_type_short]
# traversing tree is a an adapted copy pasta from STL gdb parser
# (http://www.yolinux.com/TUTORIALS/src/dbinit_stl_views-1.03.txt and similar links)
# Simple GDB Macros writen by Dan Marinescu (H-PhD) - License GPL
# Inspired by intial work of Tom Malnar,
# Tony Novac (PhD) / Cornell / Stanford,
# Gilad Mishne (PhD) and Many Many Others.
# Contact: dan_c_marinescu@yahoo.com (Subject: STL)
#
# Modified to work with g++ 4.3 by Anders Elton
# Also added _member functions, that instead of printing the entire class in map, prints a member.
node = o["_M_t"]["_M_impl"]["_M_header"]["_M_left"]
# end = o["_M_t"]["_M_impl"]["_M_header"]
tree_size = o["_M_t"]["_M_impl"]["_M_node_count"]
# in memory alternatives:
_M_t = std_stl_item_to_int_address(o.referenced_value().address)
_M_t_M_impl_M_header_M_left = _M_t + 8 + 16 # adding bits
_M_t_M_impl_M_node_count = _M_t + 8 + 16 + 16 # adding bits
node = gdb.Value(long(_M_t_M_impl_M_header_M_left)).cast(std_rb_tree_node_type).referenced_value()
tree_size = gdb.Value(long(_M_t_M_impl_M_node_count)).cast(std_rb_tree_size_type).referenced_value()
i = 0
if tree_size == 0:
return "{}"
else:
s = "{\n"
self.indent_level += 1
while i < tree_size:
# STL GDB scripts write "+1" which in my w10 x64 GDB makes a +32 bits move ...
# may be platform dependant and should be taken with caution
key_address = std_stl_item_to_int_address(node) + MAGIC_OFFSET_STD_MAP
# print(key_object['_M_dataplus']['_M_p'])
k_str = parse_std_str_from_hexa_address(hex(key_address))
# offset = MAGIC_OFFSET_STD_MAP
value_address = key_address + MAGIC_OFFSET_STD_MAP
value_object = gdb.Value(long(value_address)).cast(nlohmann_json_type)
v_str = LohmannJSONPrinter(value_object, self.indent_level + 1).to_string()
k_v_str = "{} : {}".format(k_str, v_str)
end_of_line = "\n" if tree_size <= 1 or i == tree_size else ",\n"
s = s + (" " * (self.indent_level * INDENT)) + k_v_str + end_of_line # ",\n"
if std_stl_item_to_int_address(node["_M_right"]) != 0:
node = node["_M_right"]
while std_stl_item_to_int_address(node["_M_left"]) != 0:
node = node["_M_left"]
else:
tmp_node = node["_M_parent"]
while std_stl_item_to_int_address(node) == std_stl_item_to_int_address(tmp_node["_M_right"]):
node = tmp_node
tmp_node = tmp_node["_M_parent"]
if std_stl_item_to_int_address(node["_M_right"]) != std_stl_item_to_int_address(tmp_node):
node = tmp_node
i += 1
self.indent_level -= 2
s = s + (" " * (self.indent_level * INDENT)) + "}"
return s
def parse_as_str(self):
return parse_std_str_from_hexa_address(str(self.val["m_value"][self.field_type_short]))
def parse_as_leaf(self):
s = "WTFBBQ !"
if self.field_type_short == "null" or self.field_type_short == "discarded":
s = self.field_type_short
elif self.field_type_short == "string":
s = self.parse_as_str()
else:
s = str(self.val["m_value"][self.field_type_short])
return s
def parse_as_array(self):
assert (self.field_type_short == "array")
o = self.val["m_value"][self.field_type_short]
start = o["_M_impl"]["_M_start"]
size = o["_M_impl"]["_M_finish"] - start
# capacity = o["_M_impl"]["_M_end_of_storage"] - start
# size_max = size - 1
i = 0
start_address = std_stl_item_to_int_address(start)
if size == 0:
s = "[]"
else:
self.indent_level += 1
s = "[\n"
while i < size:
# STL GDB scripts write "+1" which in my w10 x64 GDB makes a +16 bits move ...
offset = i * MAGIC_STD_VECTOR_OFFSET
i_address = start_address + offset
value_object = gdb.Value(long(i_address)).cast(nlohmann_json_type)
v_str = LohmannJSONPrinter(value_object, self.indent_level + 1).to_string()
end_of_line = "\n" if size <= 1 or i == size else ",\n"
s = s + (" " * (self.indent_level * INDENT)) + v_str + end_of_line
i += 1
self.indent_level -= 2
s = s + (" " * (self.indent_level * INDENT)) + "]"
return s
def is_leaf(self):
return self.field_type_short != "object" and self.field_type_short != "array"
def parse_as_aggregate(self):
if self.field_type_short == "object":
s = self.parse_as_object()
elif self.field_type_short == "array":
s = self.parse_as_array()
else:
s = "WTFBBQ !"
return s
def parse(self):
# s = "WTFBBQ !"
if self.is_leaf():
s = self.parse_as_leaf()
else:
s = self.parse_as_aggregate()
return s
def to_string(self):
try:
self.field_type_full_namespace = self.val["m_type"]
str_val = str(self.field_type_full_namespace)
if not str_val in enum_literal_namespace_to_literal:
return "TIMMY !"
self.field_type_short = enum_literal_namespace_to_literal[str_val]
return self.function_map[str_val]()
# return self.parse()
except:
show_last_exception()
return "NOT A JSON OBJECT // CORRUPTED ?"
def display_hint(self):
return self.val.type
# adapted from https://github.com/hugsy/gef/blob/dev/gef.py
# inspired by https://stackoverflow.com/questions/44733195/gdb-python-api-getting-the-python-api-of-gdb-to-print-the-offending-line-numbe
def show_last_exception():
"""Display the last Python exception."""
print("")
exc_type, exc_value, exc_traceback = sys.exc_info()
print(" Exception raised ".center(80, HORIZONTAL_LINE))
print("{}: {}".format(exc_type.__name__, exc_value))
print(" Detailed stacktrace ".center(80, HORIZONTAL_LINE))
for (filename, lineno, method, code) in traceback.extract_tb(exc_traceback)[::-1]:
print("""{} File "{}", line {:d}, in {}()""".format(DOWN_ARROW, filename, lineno, method))
print(" {} {}".format(RIGHT_ARROW, code))
print(" Last 10 GDB commands ".center(80, HORIZONTAL_LINE))
gdb.execute("show commands")
print(" Runtime environment ".center(80, HORIZONTAL_LINE))
print("* GDB: {}".format(gdb.VERSION))
print("* Python: {:d}.{:d}.{:d} - {:s}".format(sys.version_info.major, sys.version_info.minor,
sys.version_info.micro, sys.version_info.releaselevel))
print("* OS: {:s} - {:s} ({:s}) on {:s}".format(platform.system(), platform.release(),
platform.architecture()[0],
" ".join(platform.dist())))
print(horizontal_line * 80)
print("")
exit(-6000)
def build_pretty_printer():
pp = gdb.printing.RegexpCollectionPrettyPrinter("nlohmann_json")
pp.add_printer(nlohmann_json_type_namespace, "^{}$".format(nlohmann_json_type_namespace), LohmannJSONPrinter)
return pp
######
# executed at autoload (or to be executed by in GDB)
# gdb.printing.register_pretty_printer(gdb.current_objfile(),build_pretty_printer())
祖兹 100033-
当心:
- 包含糟糕的字符串格式(定义列表并使用 ",".join(...) 可能会更好;身份管理是石器时代的风格)
- 解析几乎没有测试过,只有一个实时的劣质进程。
- 它可能与核心转储 + 调试符号一起使用。 TODO:阅读那些东西
https://doc.ecoscentric.com/gnutools/doc/gdb/Core-File-Generation.html
- 不知道没有可用符号会发生什么,很多字段都是按名称检索的,如果可能的话应该更改为偏移量
- 没有 LIB 版本管理。 TODO:确定 nlohmann 数据结构中是否存在可以证明使用结构的严重变体
- 平台相关 TODO:移除黑魔法偏移或以更好的方式处理它们
注意:如果你是 python-kaizer-style-guru,请考虑帮助或教授如何改善所有这些混乱
一些(轻度测试):
gpr 文件:
project Debug_Printer is
for Source_Dirs use ("src", "include");
for Object_Dir use "obj";
for Main use ("main.cpp");
for Languages use ("C++");
package Naming is
for Spec_Suffix ("c++") use ".hpp";
end Naming;
package Compiler is
for Switches ("c++") use ("-O3", "-Wall", "-Woverloaded-virtual", "-g");
end Compiler;
package Linker is
for Switches ("c++") use ("-g");
end Linker;
end Debug_Printer;
主文件
#include // 我正在使用来自 repo 版本的独立 json.hpp #include
using json = nlohmann::json;
int main() {
json fooz;
fooz = 0.7;
json arr = {3, "25", 0.5};
json one;
one["first"] = "second";
json foo;
foo["flex"] = 0.2;
foo["bool"] = true;
foo["int"] = 5;
foo["float"] = 5.22;
foo["trap "] = "you fell";
foo["awesome_str"] = "bleh";
foo["nested"] = {{"bar", "barz"}};
foo["array"] = { 1, 0, 2 };
std::cout << "fooz" << std::endl;
std::cout << fooz.dump(4) << std::endl << std::endl;
std::cout << "arr" << std::endl;
std::cout << arr.dump(4) << std::endl << std::endl;
std::cout << "one" << std::endl;
std::cout << one.dump(4) << std::endl << std::endl;
std::cout << "foo" << std::endl;
std::cout << foo.dump(4) << std::endl << std::endl;
json mixed_nested;
mixed_nested["Jean"] = fooz;
mixed_nested["Baptiste"] = one;
mixed_nested["Emmanuel"] = arr;
mixed_nested["Zorg"] = foo;
std::cout << "5th element" << std::endl;
std::cout << mixed_nested.dump(4) << std::endl << std::endl;
return 0;
}
输出: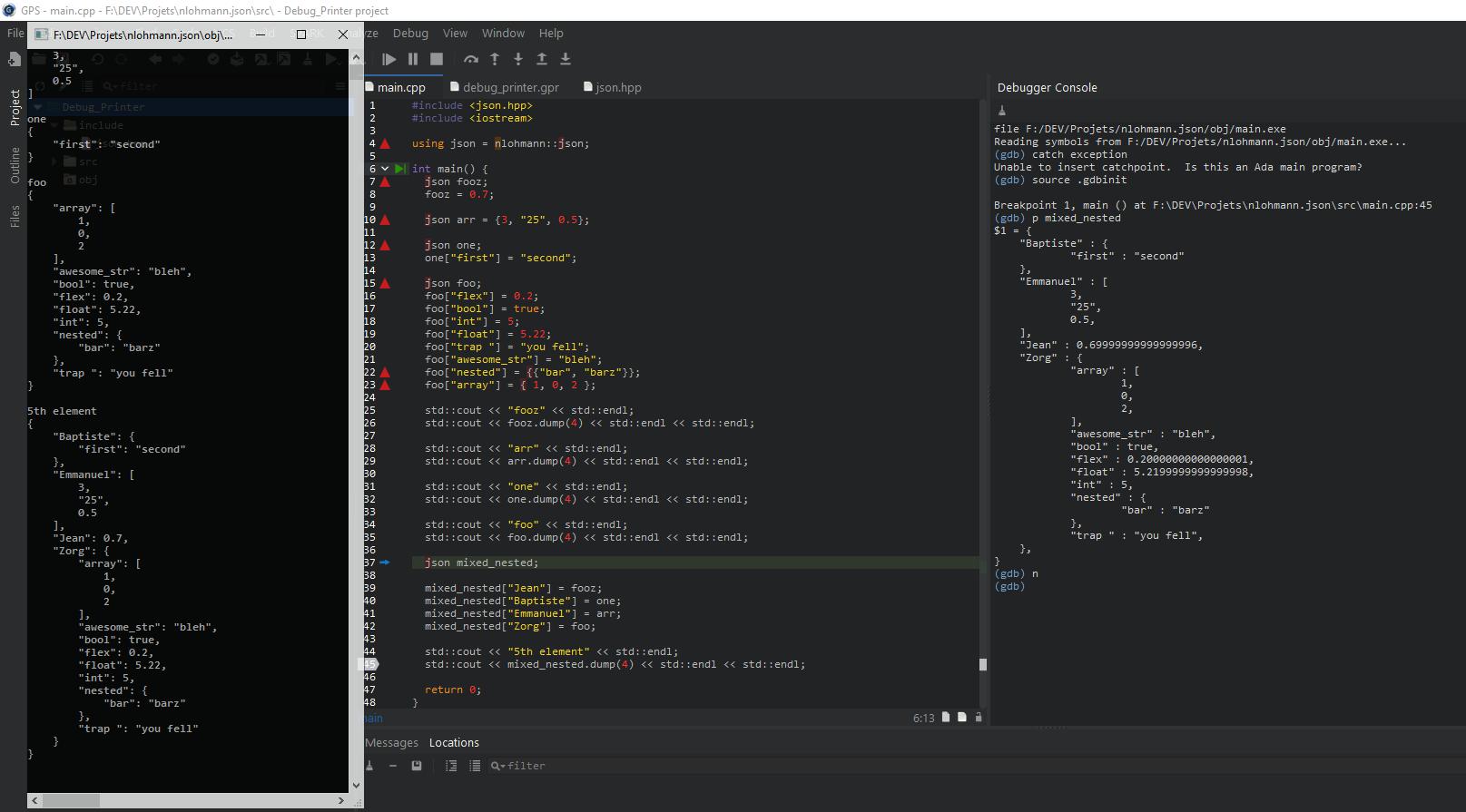
(gdb) source .gdbinit
Breakpoint 1, main () at F:\DEV\Projets\nlohmann.json\src\main.cpp:45
(gdb) p mixed_nested
$1 = {
"Baptiste" : {
"first" : "second"
},
"Emmanuel" : [
3,
"25",
0.5,
],
"Jean" : 0.69999999999999996,
"Zorg" : {
"array" : [
1,
0,
2,
],
"awesome_str" : "bleh",
"bool" : true,
"flex" : 0.20000000000000001,
"float" : 5.2199999999999998,
"int" : 5,
"nested" : {
"bar" : "barz"
},
"trap " : "you fell",
},
}
编辑 2019 年 3 月 24 日:添加 employed russian 给出的精度。
编辑 2020 年 4 月 18 日:在与 python/gdb/stl 苦苦挣扎了一夜之后,我按照 GDB 文档的方式为 python 漂亮的打印机工作了一些东西。请原谅任何错误或误解,我整晚都在这件事上撞了头,现在一切都变得模糊不清了。
编辑 2020-april-18 (2): rb 树节点和 tree_size 可以以更“内存”的方式遍历(见上文)
2020 年 4 月 26 日编辑:添加有关 GDB python 漂亮打印机的警告。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)