
pandas Python数据分析库和SQL教我取平均分
对于主要使用数据工作的 Python 开发人员来说,很难不发现自己不断地沉浸在 SQL 和 Python 的开源数据库 pandas 中。尽管这些工具使操作和转换数据变得非常容易——有时就像一行代码一样简洁——但分析人员仍然必须始终了解他们的数据以及他们的代码的含义。即使计算像汇总统计这样简单的东西也容易出现严重错误。 在本文中,我们来看看算术平均值。尽管传统上讲授的是一维数据,但为多维数据计算它
对于主要使用数据工作的 Python 开发人员来说,很难不发现自己不断地沉浸在 SQL 和 Python 的开源数据库 pandas 中。尽管这些工具使操作和转换数据变得非常容易——有时就像一行代码一样简洁——但分析人员仍然必须始终了解他们的数据以及他们的代码的含义。即使计算像汇总统计这样简单的东西也容易出现严重错误。
在本文中,我们来看看算术平均值。尽管传统上讲授的是一维数据,但为多维数据计算它需要一个根本不同的过程。事实上,计算算术平均值就好像你的数据是一维的一样会产生严重错误的数字,有时会偏离预期的数量级。对我来说,这是一次令人羞愧的经历:即使是算术平均值也同样值得进行双重和三重检查,而不是任何其他计算。
很少有统计计算能与最基本的计算的简单性和解释力相媲美:百分比、总和和平均值,最重要的是。因此,它们无处不在,从探索性数据分析到数据仪表板和管理报告。但其中之一,即算术平均值,却异常有问题。尽管传统上讲授的是一维数据,但为多维数据计算它需要一个根本不同的过程。事实上,计算算术平均值就好像你的数据是一维的一样会产生严重错误的数字,有时会偏离预期的数量级。对我来说,这是一次令人羞愧的经历:即使是算术平均值也同样值得进行双重和三重检查,而不是任何其他计算。
回归基础
算术平均值定义为:
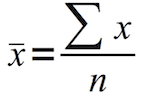
图片来源:
开源网站
或者:
SUM(all observations) / COUNT(number of observations)
我们可以通过一个简单的苹果采摘示例看到这一点:
苹果
姓名
num_apples
凯蒂
4
艾伦
8
约翰
10
苔丝
8
杰西卡
5
什么构成了这里的观察?一个人,由单个列(名称)定义,也称为维度或属性。
使用上面的公式,我们可以计算算术平均值:
SUM(4 + 8 + 10 + 8 + 5) / 5 = 7
在 SQL 中,我们会这样写:
SELECT AVG(num_apples) FROM apples
我们刚刚计算了什么? “每个人采摘的苹果的平均数量”(每个人代表一次观察)。
增加复杂度:二维数据
苹果
日期
姓名
num_apples
2017-09-24
凯蒂
4
2017-09-24
艾伦
8
2017-09-24
约翰
10
2017-09-24
苔丝
8
2017-09-26
凯蒂
5
在此示例中,我们将 Jessica 替换为 Katie,但日期不同。
现在表中的每个观察都_不仅仅是_(名称)。凯蒂出现了两次,但在不同的观察中,因为凯蒂在两个不同的日子采摘了苹果。相反,每个观察都由两个维度组成:(日期,名称)。
我们可以问和以前一样的问题:“一个人平均采摘的苹果数量是多少?”
我们应该期待一个数字,就像以前一样。我们是否应该期望平均值等于 7,就像我们之前得到的那样?
回到我们的公式:
图片来源:
开源网站
或者:
zoz100077
更多 Python 资源
-
什么是IDE?
-
备忘单:适用于初学者的 Python 3.7
-
顶级 Python GUI 框架
-
下载:7 个必不可少的 PyPI 库
-
红帽开发者
-
最新Python内容
因此,尽管分子(采摘的苹果数量)保持不变,但分母(人数)从 5 变为 4。凯蒂在不同的日子里摘了两次苹果,所以我们不会重复计算她。
这里发生了什么? 在表格级别定义的观察单位与我们分析的观察单位不同。
对于我们的分析问题,我们不是在询问每个人采摘苹果的天数。我们只是询问每个人平均采摘的苹果数量,我们最终应该得到“平均采摘 7 个苹果”或“平均采摘 10 个苹果”之类的答案。如果凯蒂碰巧比其他人采摘苹果的天数更多,那应该真的会提高平均水平。在任何苹果采摘者的随机样本中,我们可能会发现像凯蒂这样的人比其他人更频繁地采摘苹果,这推高了人们采摘苹果的平均数量。
那么我们如何在 SQL 中编写它呢?这将_不_工作:
SELECT AVG(num_apples) FROM apples
这将给我们与以前相同的答案:7。
我们要做的是将数据折叠到我们关心的分析级别。我们不是在询问 date-person 采摘的苹果的平均数量,这是之前的查询会给我们的。我们询问的是普通人采摘的苹果数量。我们分析的观察级别是人(姓名),而不是日期人(日期,姓名)。
所以我们的查询看起来像这样:
从(
选择名称,SUM(num_apples) AS num_apples
从苹果
按名称分组
) 作为吨
害怕。
内部查询为我们提供了这个结果集:
苹果
姓名
num_apples
凯蒂
9
艾伦
8
约翰
10
苔丝
8
现在,这就是我们想要取平均值的东西!外部查询然后执行此操作:
SUM(4 + 8 + 10 + 8 + 5) / 4 = 8.75
那么我们在这里学到了什么? 我们的分析问题要求我们将数据的维度减少到小于表格定义的维度。 表格定义了对二维(日期、姓名)的观察,但我们的分析问题要求对一维进行观察(姓名)。
这种通过_collapsing_改变的维度导致分母中观察量的变化,这改变了我们的平均值。
重申一下显而易见的事实:如果我们不对原始数据执行这种折叠操作,我们计算的第一个平均值将是错误的。
为什么会发生这种情况,更普遍的是?
当数据存储在数据库中时,必须指定粒度级别。换句话说,“什么构成了个人观察?”
你可以想象一个表存储这样的数据:
销售
日期
产品_已售出
2017-09-21
21
2017-09-22
28
2017-09-24
19
2017-09-25
21
2017-09-26
19
2017-09-27
18
但是您也可以想象一个存储相同数据但粒度更细的表,如下所示:
销售
日期
产品分类
产品_已售出
2017-09-21
T 恤
16
2017-09-21
夹克
2
2017-09-21
帽子
3
2017-09-22
T 恤
23
2017-09-22
帽子
5
2017-09-24
T 恤
10
2017-09-24
夹克
3
2017-09-24
帽子
6
2017-09-25
T 恤
21
2017-09-26
T 恤
14
2017-09-26
帽子
5
2017-09-27
T 恤
14
2017-09-27
夹克
4
在表级别定义的观察单元称为主键。所有数据库表都需要主键,并应用每个观察必须是唯一的约束。毕竟,如果一个观察出现两次但不是唯一的,它应该只是一个观察。
它通常遵循如下语法:
创建表销售 (
日期 DATE NOT NULL 默认 '0000-00-00',
product_category VARCHAR(40) NOT NULL default '',
产品\销售IN
主键(日期,产品_category)<------
)
请注意,我们选择记录数据的粒度级别实际上是表定义的一部分。主键定义了我们数据中的“单一观察”。在我们开始存储任何数据之前,它是必需的。
现在,仅仅因为我们在那个粒度级别_记录_数据并不意味着我们需要在那个粒度级别_分析_它。我们需要分析数据的粒度级别始终取决于我们试图回答的问题类型。
这里的关键点是主键在_表级别_定义观察,这可能包含一个或两个或 20 个维度。但是我们的_分析_可能不会如此细致地定义观察结果(例如,我们可能只关心每天的销售额),因此我们必须折叠数据并重新定义观察结果以进行分析。
形式化模式
所以我们知道,对于我们提出的任何分析问题,我们都需要重新定义构成单个观察的内容,而与主键恰好是什么无关。如果我们只取平均值而不破坏我们的数据,我们最终会在分母中得到太多的观察结果(即主键定义的数量),因此_平均值太低_。
回顾一下,使用与上面相同的数据:
销售
日期
产品分类
产品_已售出
2017-09-21
T 恤
16
2017-09-21
夹克
2
2017-09-21
帽子
3
2017-09-22
T 恤
23
2017-09-22
帽子
5
2017-09-24
T 恤
10
2017-09-24
夹克
3
2017-09-24
帽子
6
2017-09-25
T 恤
21
2017-09-26
T 恤
14
2017-09-26
帽子
5
2017-09-27
T 恤
14
2017-09-27
夹克
4
“平均每天销售的产品数量是多少?”
嗯,这个数据集中有六天,一共卖出了 126 件产品。 平均每天售出 21 种产品。
它不是 9.7,这是您从这个查询中得到的:
SELECT AVG(products_sold) FROM sales
我们需要像这样折叠数据:
选择平均(数量)从(
选择日期,SUM(products_sold) AS 数量
从销售
按日期分组
) 作为吨
给我们 21。我们可以在这里感受到大小:9.7 一点也不接近 21。
注释上面的查询:
选择平均(数量)从(
选择日期,SUM(products_sold) AS 数量
从销售
按日期分组 // [折叠键]
) 作为吨
在这里,我将折叠键定义为“与我们的分析相关的观察单位”。它与主键无关——它忽略了我们不关心的任何列,例如 (product_category)。折叠键说:“我们只想处理这个级别的粒度,所以通过将其全部加起来来卷起下面的任何粒度。”
在这种情况下,我们将_用于我们的分析_的观察单位明确定义为(日期),它将构成分母中的行数。如果我们不这样做,谁知道有多少观察(行)会滑入分母? (答案:无论我们在主键级别看到多少。)
不幸的是,崩溃的钥匙并不是故事的结局。
如果我们想要组的平均值怎么办?比如,“按类别销售的平均产品数量是多少?”
与组合作
“按类别销售的平均产品数量是多少?”
似乎是一个无害的问题。会出什么问题?
选择产品_category, AVG(产品_sold)
从销售
按产品分组_category
没有什么。这确实有效。这是正确的答案。我们得到:
销售
产品分类
平均(产品_sold)
T 恤
12.83
夹克
3
帽子
4.75
夹克的健全性检查:我们卖夹克的时间是 3 天,我们总共卖 4 + 3 + 2 u003d 9,所以平均是 3。
我立刻在想:“三个_什么_?”答案:“平均卖出三件夹克。”问题:“平均 what?”答:“我们平均一天卖出三件夹克。”
好的,现在我们看到我们最初的问题不够精确——它没有提到天数!
这是我们真正回答的问题:“对于每个产品类别,平均每天售出的产品数量是多少?”
平均问题的剖析,英文
由于任何 SQL 查询的最终目标都是对用简单英语提出的问题进行直接的、声明性的翻译,因此我们首先需要理解问题的英语部分。
让我们分解一下:“对于每个产品类别,平均每天销售的产品数量是多少?”
分为三个部分:
-
Groups: 我们想要每个产品类别的平均值(product_category)
-
**观察:**我们的分母应该是天数(日期)
-
**Measurement:**分子是我们求和的测量变量(products_sold)
对于每个组,我们需要一个平均值,即_每天_销售的产品总数除以_该组中的天数_。
我们的目标是将这些英文组件直接翻译成 SQL。
从英文到SQL
以下是一些交易数据:
交易
日期
产品
状态
购买者
数量
2016-12-23
真空
纽约
布赖恩·金
1
2016-12-23
订书机
这
布莱恩·金
3
2016-12-23
打印机墨水
纽约
布赖恩·金
2
2016-12-23
订书机
这
特雷弗·坎贝尔
1
2016-12-23
真空
嘛
劳伦米尔斯
1
2016-12-23
打印机墨水
嘛
约翰·史密斯
5
2016-12-24
真空
嘛
劳伦米尔斯
1
2016-12-24
键盘
纽约
布赖恩·金
2
2016-12-25
键盘
嘛
汤姆·刘易斯
4
2016-12-26
订书机
这
约翰·多伊
1
“对于每个州和产品,平均每天销售的产品数量是多少?”
选择状态、产品、AVG(数量)
FROM 交易
GROUP BY 状态、产品
这给了我们:
交易
状态
产品
平均(数量)
纽约
真空
1
这
订书机
1.66
纽约
打印机墨水
2
纽约
键盘
2
嘛
真空
1
嘛
打印机墨水
5
嘛
键盘
4
对(NY,订书机)进行健全性检查,我们应该在 2 天(2017-12-23 和 2017-12-26)内总共得到 3 + 1 + 1 u003d 5,给我们 2.5...
唉,SQL 结果给了我们 1.66。 查询一定是错误的。
这是正确的查询:
选择状态、产品、AVG(数量) FROM (
选择状态、产品、日期、总和(数量)作为数量
FROM 交易
GROUP BY 状态、产品、日期
) 作为吨
GROUP BY 状态、产品
给我们:
交易
状态
产品
平均(数量)
纽约
真空
1
这
订书机
2.5
纽约
打印机墨水
2
纽约
键盘
2
嘛
真空
1
嘛
打印机墨水
5
嘛
键盘
4
平均问题的剖析,在 SQL 中
我们确定英语平均问题包含三个部分,如果我们不尊重这一点,我们就会错误地计算平均值。我们也知道英文的组件应该翻译成SQL的组件。
他们来了:
选择状态,产品,
平均(数量)//[测量变量]
从 (
选择状态、产品、日期、总和(数量)作为数量
FROM 交易
GROUP BY 状态、产品、日期 // [COLLAPSING KEY]
) 作为吨
GROUP BY 状态,产品 // [GROUPING KEY]
-- [观察键] u003d [折叠键] - [分组键]
-- (date) u003d (state, product, date) - (state, product)
这与上面的查询相同,只是带有注释。
请注意,在我们的英语问题中,折叠键_不是_——这就像伪造主键,但用于我们的分析,而不是使用表中定义的主键。
另请注意,在 SQL 翻译中,观察键是隐式的,而不是显式的。 观察键等于折叠键(即,只是我们分析所需的维度,仅此而已)减去分组键(我们分组的维度)。剩下的就是观察键,或者为我们的分析定义观察的东西。
我是第一个承认_我们的平均问题中最重要的部分——即定义观察的内容——在 SQL 中甚至没有明确表示是多么令人困惑的人。它是隐含的。我称之为采用多维平均值的陷阱。
外卖如下:
-
折叠键定义了我们将在分析中使用的维度。表的主键中的其他所有内容都将被“汇总”。我们在内部查询**的 **GROUP BY 中定义折叠键。
-
grouping 键是我们想要对数据进行分组的维度(即“针对每个组”)。这是在外部查询的GROUP BY中定义的。
-
折叠键 - 分组键 u003d 观察键。
-
如果不定义折叠键,则隐式使用表的主键作为折叠键。
-
如果不做任何分组,折叠键等于观察键
例如,如果您的表的主键是 (date, product, state, purchaser) 并且您想对每个州 (group:状态),您_必须解决折叠键_(即内部 SQL 查询中的内容)。
我们不想隐式使用主键,所以我们将使用折叠键。什么折叠键?折叠键将是 (observation key: purchaser) + (grouping key: state) u003d (purchaser, state)。这在我们内部查询的 GROUP BY 中,(state) 单独在外部查询的 GROUP BY 中,并且隐含的观察键是 (purchaser)。
最后,请注意如果我们_不_使用折叠键会发生什么。主键是(日期、产品、状态、购买者),我们的分组键是(状态)。如果我们根本不使用任何子查询,我们将得到一个答案,它将观察定义为 (date, product, state, purchaser) - (state) u003d (date, product, purchaser)。这将决定我们在每组中看到多少观察,这会影响我们平均值的分母。 这是错的。
收尾
我从这一切中学到的一件事是,从分析的角度来看,永远不要相信主键。它定义了记录数据的粒度(即构成观察的内容),但这可能不是您分析所需要的。如果您没有_明确_意识到这种差异将如何影响您的计算,那么您的计算很可能是不正确的。因为无论您是否意识到,主键都会影响您的分母。
因此,如果您不能信任主键,最安全的做法是**始终折叠数据。**如果您不进行任何分组,那么您的折叠键明确等于您的观察键。如果您正在进行分组,那么您的折叠键是您的观察键和分组键的总和。但有一点是肯定的:如果您没有折叠数据,那么您就是在隐式信任主键。
我学到的第二件事是,与 SQL 完全无关,问一个关于平均值的问题并不总是直观的。"按证券计算的平均股价是多少?"是一个模棱两可的问题,即使是简单的英语!这是每只证券的每日平均股价,还是每天每只证券的平均股价?
业务问题不会以数据库逻辑或程序代码的形式出现。相反,它们是使用_自然语言_制定的,并且必须翻译成_数据语言_。作为一名数据分析师,您必须澄清:“我们到底取了什么平均值?”在这里,从折叠、分组和观察键的角度进行思考是有帮助的,尤其是在概念化有多少观察进入您的分母。
这个问题并不局限于 SQL,而是任何关系数据的存储,例如pandas.DataFrames或 R 数据表。如果你和我一样,你会仔细研究你的旧代码 grepping 来获取平均值,然后想知道,“我到底在这里取了什么平均值?”
本文最初发布于alexpetralia.com并经许可转载。
要了解更多信息,请参加 Alex Petralia 的演讲,[分析数据:在PyCon Cleveland 2018上,pandas 和 SQL 教我如何取平均](https://us.pycon.org/2018/schedule/presentation/84/).

学AI,认准AI Studio!GPU算力,限时免费领,邀请好友解锁更多惊喜福利 >>>
更多推荐

 0
0 0
0- 0



 已为社区贡献126483条内容
已为社区贡献126483条内容

所有评论(0)