Is there a faster way to find the length of the longest string in a Pandas DataFrame than what's shown in the example below?
import numpy as np
import pandas as pd
x = ['ab', 'bcd', 'dfe', 'efghik']
x = np.repeat(x, 1e7)
df = pd.DataFrame(x, columns=['col1'])
print df.col1.map(lambda x: len(x)).max()
# result --> 6
It takes about 10 seconds to run df.col1.map(lambda x: len(x)).max() when timing it with IPython's %timeit.
DSM's suggestion seems to be about the best you're going to get without doing some manual microoptimization:
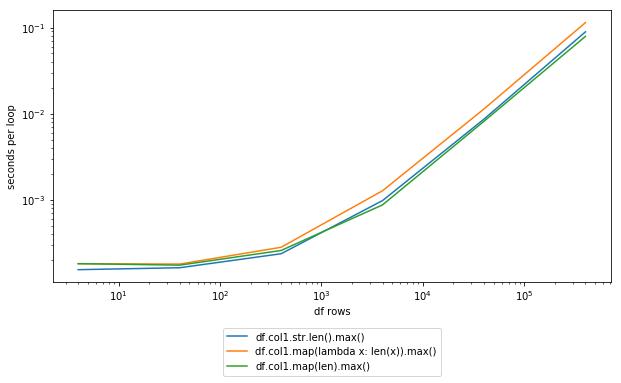
%timeit -n 100 df.col1.str.len().max()
100 loops, best of 3: 11.7 ms per loop
%timeit -n 100 df.col1.map(lambda x: len(x)).max()
100 loops, best of 3: 16.4 ms per loop
%timeit -n 100 df.col1.map(len).max()
100 loops, best of 3: 10.1 ms per loop
Note that explicitly using the str.len() method doesn't seem to be much of an improvement. If you're not familiar with IPython, which is where that very convenient %timeit syntax comes from, I'd definitely suggest giving it a shot for quick testing of things like this.
Update Added screenshot:








 已为社区贡献126450条内容
已为社区贡献126450条内容

所有评论(0)