时间序列工具库学习Darts模块——多个时间序列、预训练模型和协变量的概念和使用
1.实验目的
本笔记本用于以下目的:
-
在多个时间序列上训练单个模型
-
预训练模型用于获取训练期间未见的任何时间序列的预测
-
使用协变量训练和使用模型
2.指南库
# 如果在本地工作,则修复 python 路径
从实用程序导入修复_pythonpath_if_working_locally
修复_ pythonpath_ if_ working\locally()
将熊猫导入为 pd
将 numpy 导入为 np
进口火炬
导入 matplotlib.pyplot 作为 plt
从 darts.models 导入 NBEATSModel
从 darts.models 导入 *
从飞镖导入 TimeSeries
从 darts.utils.timeseries_generation 导入 (
高斯_timeseries,
线性_timeseries,
正弦_timeseries,
)
从 darts.models 导入 (
RNN模型,
TCN型号,
变压器模型,
NBEATS模型,
BlockRNN模型,
)
从 darts.metrics 导入 mape、smape
从 darts.dataprocessing.transformers 导入 Scaler
从 darts.utils.timeseries_generation 导入 datetime_attribute_timeseries
从 darts.datasets 导入 AirPassengersDataset、MonthlyMilkDataset
%load_ext 自动重载
%自动重载 2
%matplotlib 内联
将熊猫导入为 pd
将 numpy 导入为 np
导入 matplotlib.pyplot 作为 plt
从飞镖导入 TimeSeries
从 darts.datasets 导入 AirPassengersDataset、MonthlyMilkDataset
可重复性
火炬手册_seed(1)
np.random.seed(1)
3.读取数据
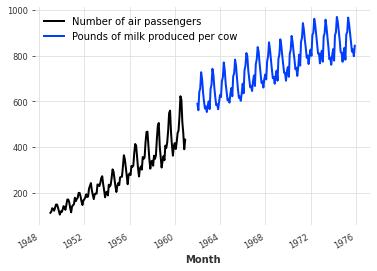
首先阅读两个时间序列——一个包含每月航空公司乘客的数量,另一个包含每月每头奶牛的产奶量。这些时间序列彼此之间没有太大的关系,但它们都有明显的年周期性和上升趋势的月频率,并且(完全巧合)它们包含可比数量级的值。
series\air u003d 航空旅客数据集().load()
series\milk u003d 每月牛奶数据集().load()
series_air.plot(labelu003d"航空旅客人数")
series_milk.plot(labelu003d"每头奶牛生产的牛奶磅数")
plt.legend()
4.预处理
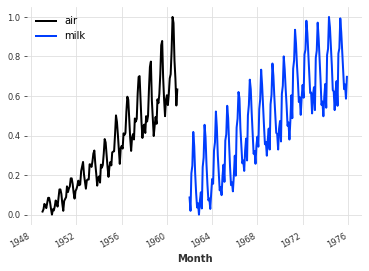
一般来说,神经网络往往在标准化/标准化数据上工作得更好。在这里,Scaler 类将用于标准化 0 到 1 之间的时间序列:
从 darts.dataprocessing.transformers 导入 Scaler
定标器_air,定标器_milk u003d 定标器(),定标器()
系列_air_scaled u003d 缩放器_air.fit_transform(series_air)
系列_milk_scaled u003d 缩放器_milk.fit_transform(series_milk)
系列_air_scaled.plot(标签u003d“空气”)
系列_milk_scaled.plot(labelu003d"milk")
plt.legend()
5.拆分数据集[训练集、验证集]
保留这两个系列的最后 36 个月作为验证:
火车_air, val_air u003d series_air_scaled[:-36], series_air_scaled[-36:]
火车_milk, val_milk u003d series_milk_scaled[:-36], series_milk_scaled[-36:]
6.全局预测模型
Darts 包含许多预测模型,但并非所有模型都可以在多个时间序列上进行训练。支持多系列训练的模型称为全局模型。目前有五种全球模式:
-
BlockRNN模型
-
RNN模型
-
时间卷积网络(TCN)
-
N-Beats 模型
-
变压器模型
将区分两个时间序列:
-
目标时间序列是我们有兴趣预测的时间序列(给定它的历史)
-
协变量时间序列是可能有助于预测目标序列的时间序列,但它们对预测不感兴趣。有时称为外部数据。
进一步区分协变量序列,取决于他们是否可以提前知道:
-
过去的协变量表示其过去值在预测时已知的时间序列。这些通常是必须测量或观察的事情。
-
未来协变量表示其未来值在预测时间范围内已知的时间序列。例如,这些可以代表已知的未来假期或天气预报。
有些模型只使用过去的协变量,有些只使用未来的协变量,有些模型可能同时使用两者。
-
BlockRNNModel、TCNModel、NBEATSModel和transformer模型都使用了past_covariates。
-
RNNModel 使用 future_covariates。
上面列出的所有全局模型都支持多个训练序列。此外,它们都支持多变量序列。这意味着它们可以在多维时间序列中无缝使用;目标系列可以包含一个(通常是这种情况)或多个维度。多维度的时间序列其实只是一个规则的时间序列,其中每个时间戳的值是一个向量而不是一个标量。
例如,过去支持_协变量的四种模型遵循“块”架构。它们包含一个神经网络,将时间序列块作为未来时间序列的输入和输出(预测)块。输入维度是目标序列的维度(分量),加上所有协变量的分量数 - 堆叠在一起。输出维度是目标序列的维度:
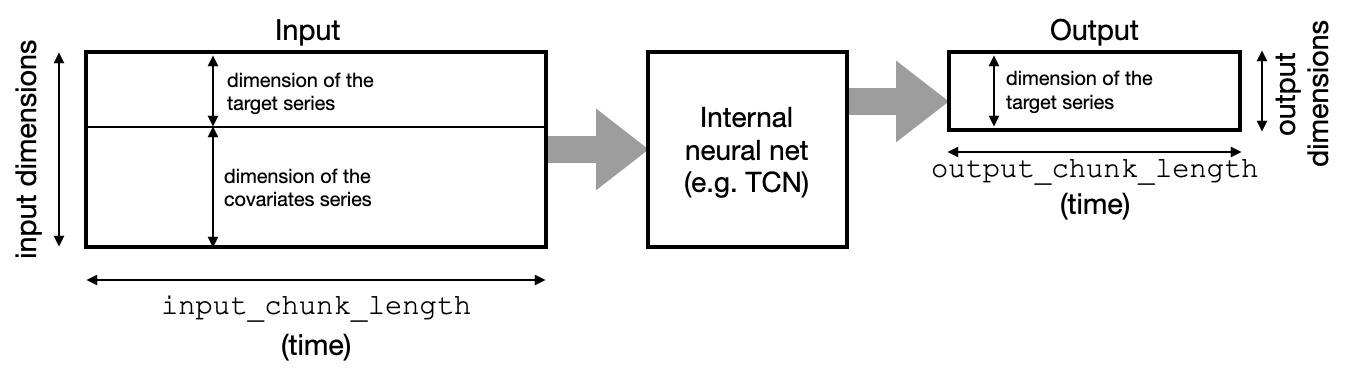
RNNModel 以循环方式以不同的方式工作(这就是它们支持未来协变量的原因)。好消息是,作为用户,我们无需过多担心不同的模型类型和输入/输出维度。维度由模型根据训练数据自动推断,对过去或未来协变量的支持由过去_ Covariables 或future_ covariables 参数简单处理。
在构建模型时,仍然需要指定两个重要参数:
-
input_chunk_length:这是模型回溯窗口的长度;因此,模型会读取之前的 input_chunk_length 点来计算每个输出。
-
output_chunk_length:这是内部模型生成的输出(预测)的长度。但是,**“外”飞镖模型**(例如NBEATSModel、TCNModel等)的predict()方法可以在更长的时间范围内调用。在这些情况下,如果输出超出_块_如果在长度范围内调用predict(),内部模型将被重复调用,以自回归的方式依赖于自己之前的输出。如果使用过去的_协变量,这需要提前足够长的时间知道这些协变量。
7.训练预测单变量
建立一个回溯窗口为 24 个点(输入_chunk_lengthu003d24)的 N-BEATS 模型并预测接下来的 12 个点(输出_chunk_lengthu003d12)。选择这些值,以便模型在过去两年中每次都生成连续预测。
该模型可以像任何其他飞镖预测模型一样使用,并且适用于单个时间序列:
模型_air u003d NBEATSModel(
输入_chunk_lengthu003d24,输出_chunk_lengthu003d12,n_epochsu003d200,随机_stateu003d0
)
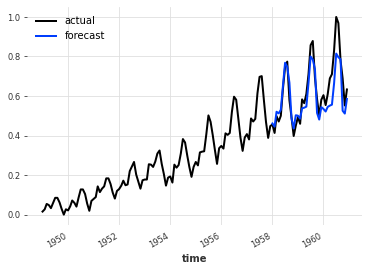
模型_air.fit(火车_air,详细u003d真)

与其他飞镖预测模型一样,可以通过调用 predict() 来获得预测。注意接下来调用的window是36的predict(),比模型内部输出的_chunk_长度为12的horizon要长一些。这在这里不是问题 - 如上所述,在这种情况下,内部模型将被简单地称为自回归输出。在这种情况下,它将被调用 3 次,以便三个 12 点输出形成最终的 36 点预测——但所有这些都是在幕后透明地完成的。
pred u003d 模型_air.predict(nu003d36)
系列_air_scaled.plot(标签u003d“实际”)
pred.plot(labelu003d"预测")
plt.legend()
print("MAPE u003d {:.2f}%".format(mape(series_air_scaled, pred)))
(1).训练过程[后台训练过程]
调用模型_空气。 fit() 时会发生什么?
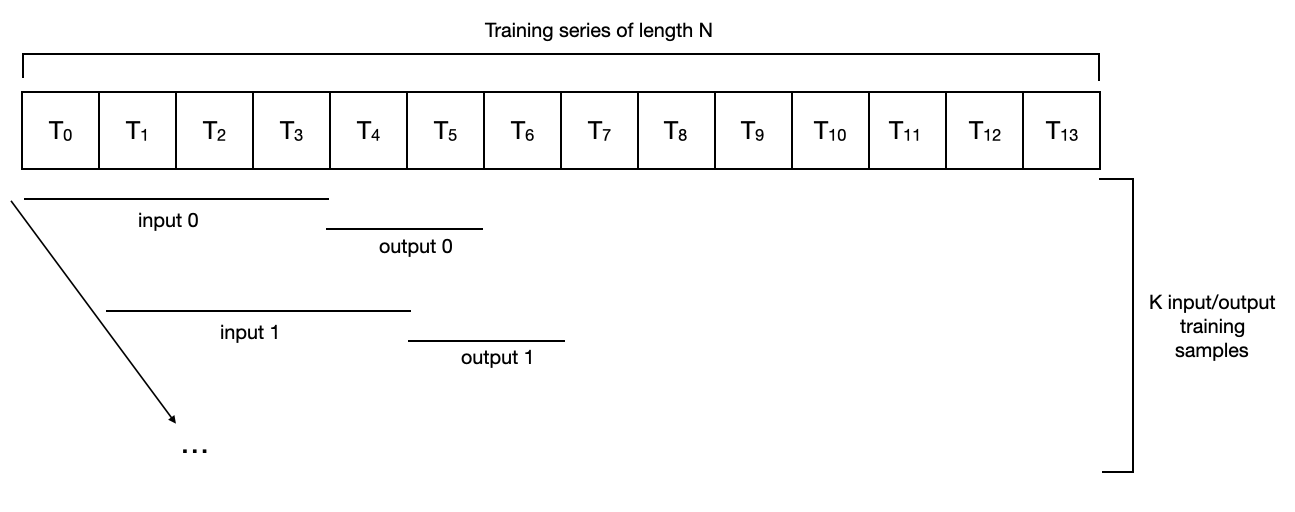
为了训练内部神经网络,dart 首先从提供的时间序列(在本例中为 series_air_scaled)创建一个输入/输出样本数据集。有几种方法可以做到这一点,dart 在 dart utils 中。数据包包含几个不同的数据集实现。
默认情况下,NBEATSModel 实例化一个飞镖工具。数据。 Pastcovariatessequentialdataset,它只构造序列中存在的所有连续输入/输出子序列对(input_chunk_length 和 output_chunk_length)。
对于一个长度为 14 的序列,输入_chunk_lengthu003d4,输出_chunk_lengthu003d2,它看起来像这样:
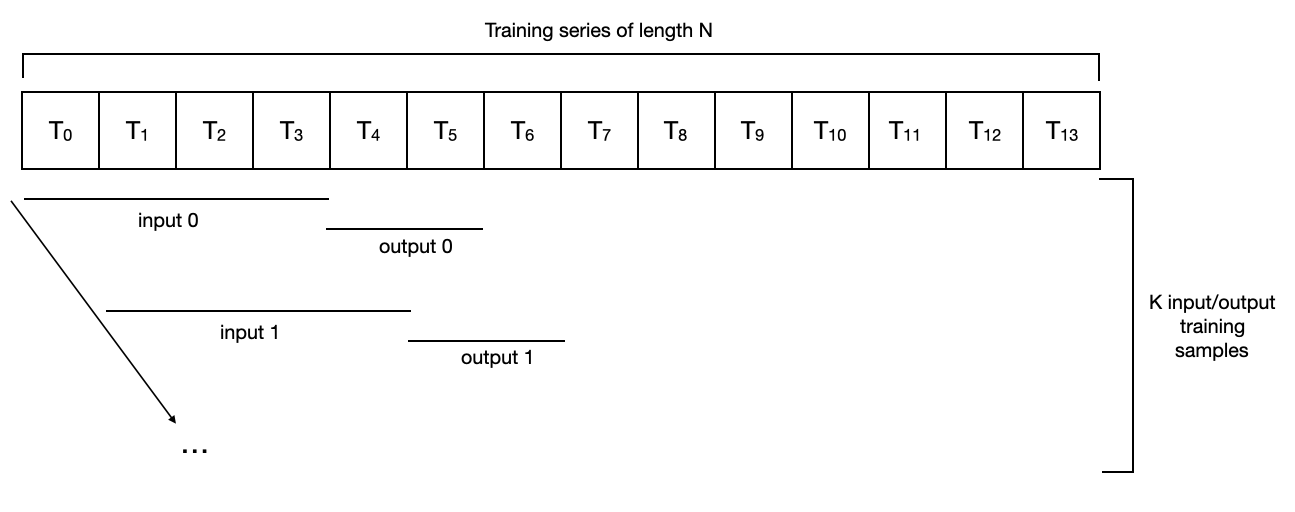
对于这样一个数据集,一系列长度为N的数据集得到N-输入_块_长度-输出_块_长度+1个样本的训练集。在上面的例子中,我们有Nu003d14,输入_chunk_lengthu003d4,输出_chunk_lengthu003d2,所以用于训练的样本数是Ku003d9。在这种情况下,训练阶段包括一个完整的遍历所有样本(可能是几个小批量)。
注意默认情况下,不同的模型很容易使用不同的数据集。例如,飞镖工具。数据。 Horizonbaseddataset 受到 N-BEATS 论文的启发,生成“接近”系列结尾的样本,甚至可能忽略系列的开头。
如果需要控制如何从实例生成训练样本,可以通过继承抽象类 TimeSeries 来实现自己的训练数据集。飞镖。实用程序。数据。 trainingdatasetdarts 数据集继承自 torch Dataset,这意味着很容易实现一个不会一次将所有数据加载到内存中的惰性版本。一旦有了自己的数据集实例,就可以直接调用 fit_from_Dataset() 方法,所有全局预测模型都支持该方法。
8.在多个时间序列(多变量)上训练模型
所有这些机器都可以与多个时间序列无缝使用。下面是一个顺序数据集。如何找到长度为 N 和 M_ chunk_ Length u003d 4 和 output_chunk_lengthu003d2 的两个序列输入

笔记:
-
不同的系列不需要相同的长度,甚至不需要共享相同的时间戳。
-
实际上,它们甚至不需要具有相同的频率。
-
训练数据集中的样本总数将是每个系列中包含的所有训练样本的并集;因此,训练期现在将涵盖所有系列的所有样本。
(1).训练空中交通数据集和牛奶数据序列
另一个模型示例适用于两个时间序列(航空乘客和牛奶生产)。由于使用两个(大致)相同长度的系列会使训练数据集的大小翻倍,因此我们将使用一半的 epoch 数量:
火车_air, val_air u003d series_air_scaled[:-36], series_air_scaled[-36:]
火车_milk, val_milk u003d series_milk_scaled[:-36], series_milk_scaled[-36:]
模型_air_milk u003d NBEATSModel(
输入_chunk_lengthu003d24,输出_chunk_lengthu003d12,n_epochsu003d100,随机_stateu003d0
)
在两个(或更多)序列上拟合模型就像在 fit() 函数的参数中给出序列列表(而不是单个序列)一样简单:
模型_air_milk.fit([train_air, train_milk], 详细u003dTrue)

(2).训练后生成预测
在计算预测时指定预测未来的时间序列很重要:以前没有这样的约束。当仅在一个系列上拟合模型时,模型将在内部记住该系列。如果在没有 series 参数的情况下调用 predict(),它将返回训练序列的(唯一)预测。一旦模型应用于多个系列,这将不再起作用 - 在这种情况下,系列参数对于 predict() 成为必需的。
假设您想预测空中交通的未来。在这个例子中,为predict()函数指定了series u003d train_air,目的是预测train_air后的内容:
pred u003d 模型_air_milk.predict(nu003d36, seriesu003dtrain_air)
系列_air_scaled.plot(标签u003d“实际”)
pred.plot(labelu003d"预测")
plt.legend()
print("MAPE u003d {:.2f}%".format(mape(series_air_scaled, pred)))
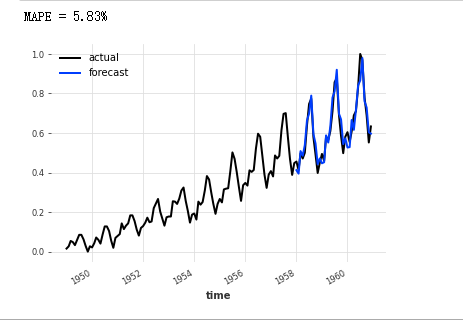
(3).牛奶消费量真的有助于预测空中交通吗?
在模型的这个特定示例中,情况似乎就是这样(至少在 MAPE 错误方面)。但如果你仔细想想,这并不奇怪。空中交通具有年度季节性和上升趋势。牛奶系列也表现出这两个特征,在这种情况下,它可能有助于模型捕捉它们。
请注意,这指向了对预测模型进行预训练的可能性;一劳永逸地训练模型,然后用它们来预测不在训练集中的序列,可以预测一个或多个变量的未来。使用该模型,您可以真正预测任何其他系列的未来值,甚至是那些在训练期间从未见过的值。
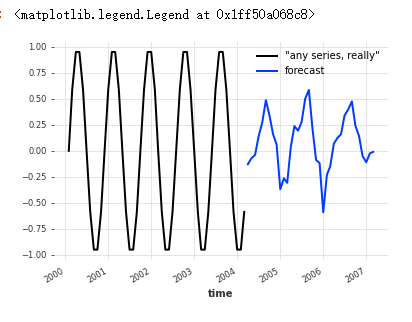
例如,假设你想预测一些任意正弦波序列的未来:[使用训练好的模型预测多个变量的未来]
这个预测不好(sin甚至没有每年的季节性),但你可以理解。
任何_series u003d 正弦_timeseries(长度u003d50,频率u003d“M”)
pred u003d model_air_milk.predict(nu003d36, seriesu003dany_series)
any_series.plot(labelu003d'"任何系列,真的"')
pred.plot(labelu003d"预测")
plt.legend()
与 fit() 函数支持的类似,您还可以在参数中为 predict() 函数提供序列列表,在这种情况下,它将返回预测序列列表。例如,一次可以得到空中交通和牛奶序列的预测,这两个序列分别对应train_air和train_牛奶后的预测:
pred_list u003d 模型_air_milk.predict(nu003d36, seriesu003d[train_air, train_milk])
对于系列,zip 中的标签(pred_list,[“航空乘客”,“牛奶生产”]):
series.plot(labelu003df"预测 {label}")
plt.legend()
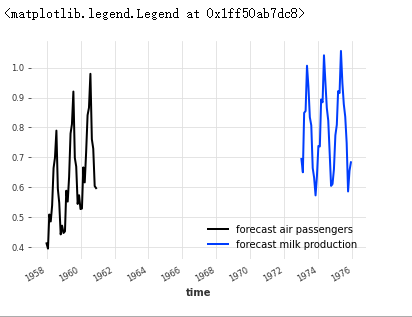
9.协变量序列
到目前为止,已经使用的模型仅使用目标序列的历史来预测其未来。但是,如上所述,全局 dart 模型也支持使用协变量时间序列。这些是“外部数据”的时间序列,可能对预测不感兴趣,但仍希望用作模型的输入,因为它们可能包含有价值的信息。
(1) 构造协变量
看一个空气和牛奶系列的简单例子。在这个例子中,我们将尝试使用年和月作为协变量:
# 构建年月系列:
air_year u003d datetime\attribute\timeseries(series_air\scaled, attributeu003d"year")
air_month u003d datetime_attribute_timeseries(series_air_scaled, attributeu003d"month")
牛奶_year u003d datetime\attribute\timeseries(series_milk\scaled, attributeu003d"year")
牛奶_month u003d datetime_attribute_timeseries(series_milk_scaled, attributeu003d"month")
将年月叠加得到二维(年月)序列:
air_covariates u003d air_year.stack(air_month)
牛奶_covariates u003d 牛奶_year.stack(milk_month)
在 0 和 1 之间缩放:
缩放器_dt_air u003d 缩放器()
空气_ 协变量 u003d 缩放器_ft_air.fit_transform(空气\协变量)
缩放器_dt_milk u003d 缩放器()
牛奶_ 协变量 u003d 缩放器_ft_milk.fit_transform(牛奶_ 协变量)
分割训练/验证集:
空气\火车\协变量,空气_val\协变量 u003d 空气\协变量[:-36],空气_covariates[-36:]
牛奶_train_covariates,牛奶_val_covariates u003d (
牛奶_协变量[:-36],
牛奶_协变量[-36:],
)
绘制协变量:
plt.figure()
空气_covariates.plot()
plt.title("空中交通协变量(年月)")
plt.figure()
牛奶_covariates.plot()
plt.title("牛奶生产协变量(年月)")
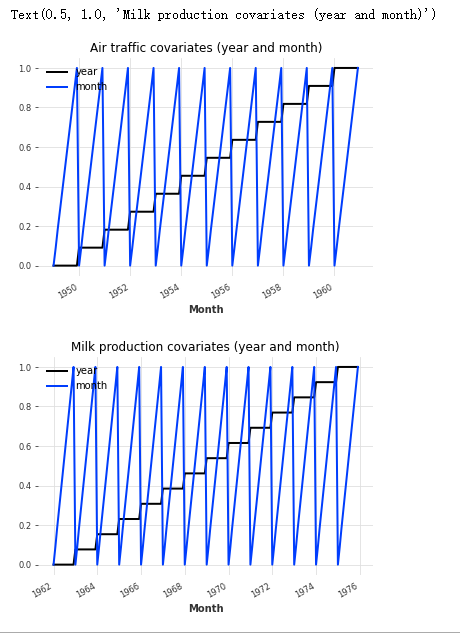
很好,所以对于每个目标序列(空气和牛奶),我们构建了一个具有相同时间线并包含年和月的协变量序列。
请注意,这里的协变量序列是多变量时间序列:它们包含两个维度 - 一个代表年份,另一个代表月份。
(2) 训练[协变+特征,目标数据]
建立一个blockrnmodel训练:
模型_cov u003d BlockRNNModel(
模型u003d"LSTM",
输入_chunk_lengthu003d24,
输出_chunk_lengthu003d12,
n_epochsu003d300,
随机_stateu003d0,
)
现在,要使用协变量训练模型,只需将协变量(以匹配目标序列的列表的形式)作为未来_将协变量参数提供给 fit() 函数。参数名称为future_Covariables,以提醒模型这些协变量的未来值可以用于预测。
模型_cov.fit(
系列u003d[火车_air, train_milk],
过去\covariatesu003d[air\train\covariates, milk_train\covariates],
详细u003d真,
)
! zoz100078](https://programming.vip/images/doc/7822b1487c7fa82a5f9d74fa1aeb20ef.jpg)
(3) 使用协变量预测未来[无需输入未来的真实值]
同样,要获得预测,您现在只需为 predict() 函数_ Covariables 参数指定未来。
pred_cov u003d 模型_cov.predict(nu003d36, seriesu003dtrain_air, past_covariatesu003dair_covariates)
系列_air_scaled.plot(标签u003d“实际”)
pred_cov.plot(标签u003d“预测”)
plt.legend()

注意这里调用了predict(),它的预测范围n大于训练模型中使用的输出_块_长度。这是可以实现的,因为即使 BlockRNNModel 使用过去的协变量,在这种情况下,这些协变量也知道未来。因此,dart 可以通过自回归计算和预测未来的 n 个时间步长。
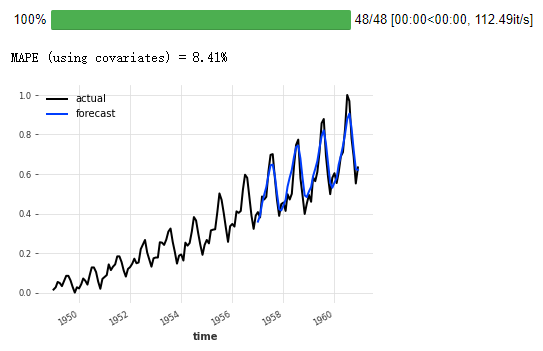
(4) 使用协变量进行回测
协变量可用于对模型进行回测。例如,要评估 12 个月的运行精度,从 75% 的空气系列开始:
回测_cov u003d 模型_cov.historical_forecasts(
系列_air_scaled,
过去\协变量u003d空气\协变量,
开始u003d0.6,
预测_horizonu003d12,
步幅u003d1,
重新训练u003d假,
详细u003d真,
)
系列_air_scaled.plot(标签u003d“实际”)
回测_cov.plot(标签u003d“预测”)
plt.legend()
print("MAPE (使用协变量) u003d {:.2f}%".format(mape(series_air_scaled, backtest_cov)))

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)