Python实现一个简单的excel比较工具
最近有小伙伴说需要一个工具来比较两张excel表的差异,直接标注出差异的行。
代码非常简单。为了方便小白使用,我把它打包成一个exe文件,点击执行输出结果。
1.先说一下怎么用,后面是代码
链接:https://pan.baidu.com/s/1oNEeIDOnw1Grw2MOdJrwUQ
提取码:w29l
先到网盘链接,下载文件:
如果不需要源码,直接下载xlsx_比较。 rar就够了。
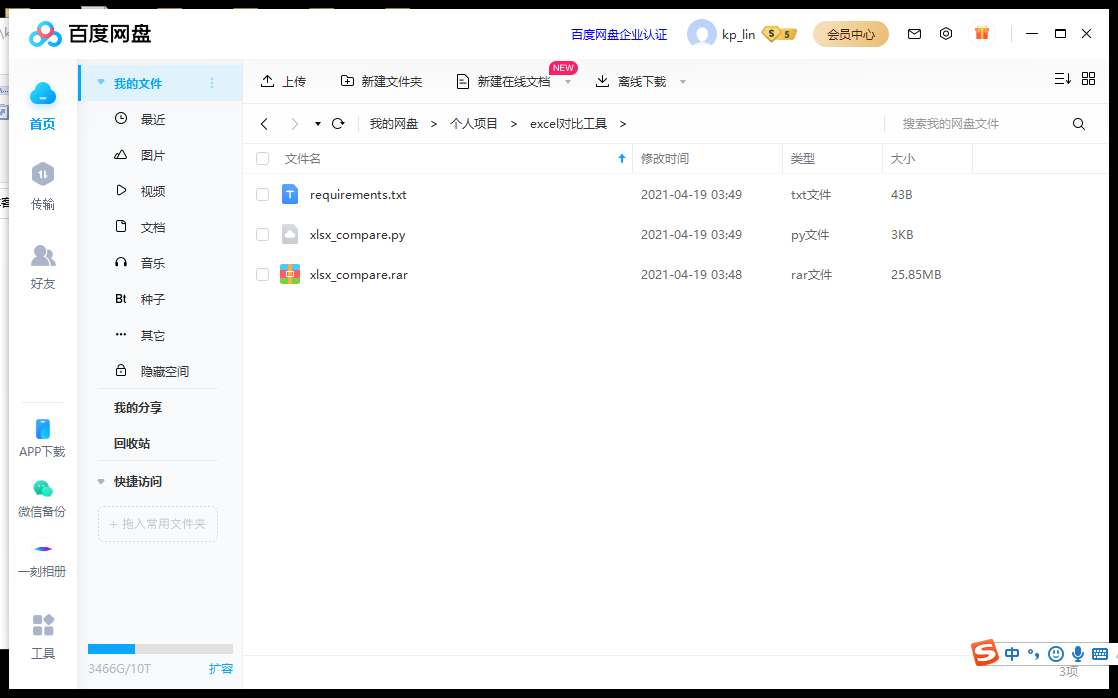
解压后打开:
这里的两个xlsx文件是我用来测试的文件。您可以直接将它们替换为您自己的。他们必须是两个。不要放其他文件。
亮点:你的两个excel文件必须是xlsx格式的文件,比较的内容放在Sheet1中。
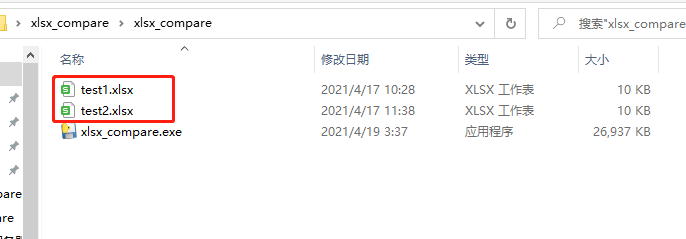
点击exe文件,结果如下:
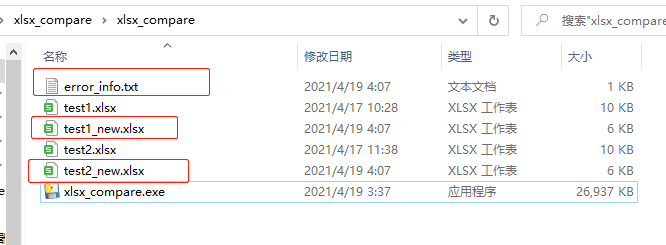
会输出三个文件,第一个error_info.txt表示执行时会写入这个文件中的错误信息。如果运行正常,则写为。

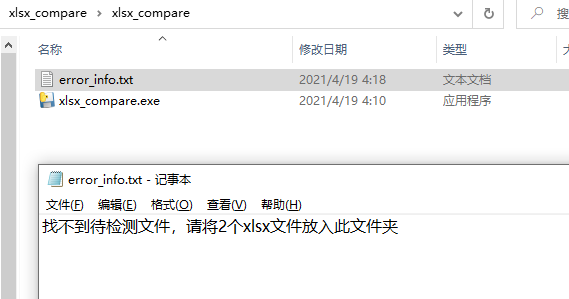
如果出现异常,比如忘记放两个参考文件,error_info.txt是这样的
另外两个新的结局文件是比较结果。打开它们看看。
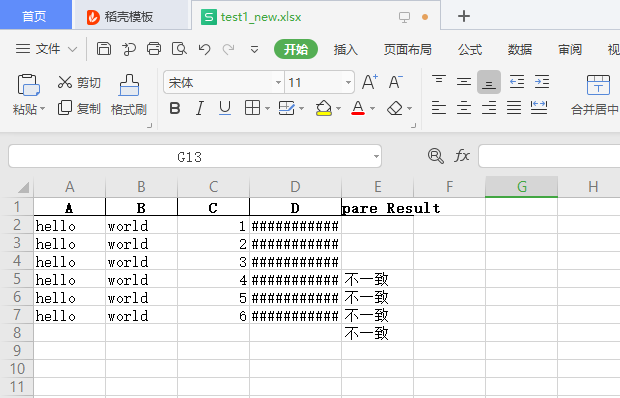
因为D列的长度太长了。
如果在比较中发现任何不一致,将在最后一列用比较结果进行标记
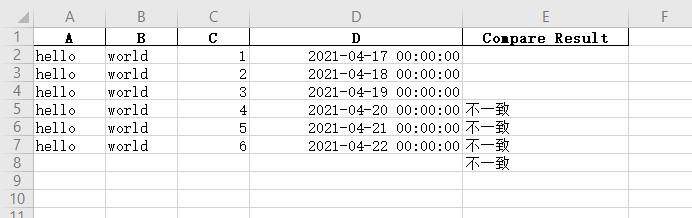
在这种情况下,两个文件的第5、6、7行不一致,第8行是因为test1 Xlsx第8行没有数据,而test2 Xlsx有,所以也标注了。
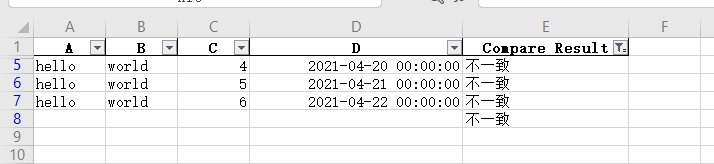
这样我们就可以通过excel过滤器过滤得到两个文件所有不一致的行
2.代码
#!/usr/bin/env python
-*- 编码:utf-8 -*-
日期:2021/4/17
文件名:xlsx_compare
#作者:kplin
将熊猫导入为 pd
导入我们
定义我的_log(信息):
尝试:
with open('error_info.txt', 'w+') as f:
f.write(信息)
f.close()
除了 e 例外:
print('写入错误日志时出现以下错误:\n%s'%e)
定义获取_file():
尝试:
获取当前文件夹下的2个文件
目录\路径 u003d os.getcwd()
文件 u003d os.listdir(dir_path)
ret u003d []
对于我在文件中:
如果 i.endswith('.xlsx') 而不是 i.endswith('_new.xlsx'):
ret.append(i)
如果 i.endswith('.xlsx') 而不是 i.endswith('_new.xlsx') 和 '~$' 在 i 中:
info u003d'请关闭文件%s'%i
我的_log(信息)
返回无
如果 len(ret) u003du003d 0:
info u003d '找不到要检测的文件,请发送2个xlsx放在此文件夹中的文件'
我的_log(信息)
返回无
打印(返回)
返回 ret[0], ret[1]
除了 e 例外:
我的_log(str(e))
定义主(文件 1,文件 2):
尝试:
1.获取原始文件路径和文件名,准备好要生成的新文件名和文件路径
fname1, ext u003d os.path.splitext(os.path.basename(file1))
new_file1 u003d file1.replace(fname1, fname1 + '_new')
fname2, ext u003d os.path.splitext(os.path.basename(file2))
新_file2 u003d file2.replace(fname2, fname2 + '_new')
2. 读取文件
df1 u003d pd.read_excel(file1)
df2 u003d pd.read_excel(file2)
长度 u003d len(df1) 如果 len(df1) >u003d len(df2) 否则 len(df2)
如果两个数据块的行数不一致,补数相同
如果 len(df1) - len(df2) > 0:
获取DF1的列名
d u003d {}
对于 df2.columns 中的 i:
d[i] u003d ['' for x in range(len(df1) - len(df2))]
连接_df u003d pd.DataFrame(d)
df2 u003d pd.concat([df2, concat_df])
如果 len(df2) - len(df1) > 0:
d u003d {}
对于 df1.columns 中的 i:
d[i] u003d ['' for x in range(len(df2) - len(df1))]
连接_df u003d pd.DataFrame(d)
df1 u003d pd.concat([df1, concat_df])
dis_index u003d []
对于我在范围内(len(df1)):
ret u003d df1.iloc[i, :]u003du003ddf2.iloc[i, :]
如果 ret.tolist() 中为 False:
dis_index.append(i)
dis_list u003d ['' for i in range(length)]
对于我在 dis_index 中:
dis_list[i] u003d '非典型性'
df1['比较结果'] u003d dis_list
df2['比较结果'] u003d in\list
df1.to_excel(new_file1, indexu003dFalse)
df2.to_excel(new_file2, indexu003dFalse)
my_log('验证成功。参考文档为:%s%s and %s%s'%(fname1, ext, fname2, ext))
print('验证完成,请检查新文件')
除了 e 例外:
print('发生未知错误,请检查error_info.txt')
我的_log(str(e))
如果 __name__ u003du003d '__main__':
如果没有得到_file():
print('读取文件出错,请检查error_info.txt')
其他:
文件 1,文件 2 u003d 获取_文件()
主要(文件 1,文件 2)
一共有三个功能:
1、my_log函数用于写日志。
2、get_文件功能用于获取当前路径下所有后缀的xlsx文件,将排除_new.xlsx文件,如果当前文件夹中有打开的excel文件,会自动结束操作并提示关闭当前文件夹中打开的excel文件。
3\。 main函数用于处理比较并输出结果:
在这里,pandas 主要用于读取数据并逐行比较。如果不一致,将记录差异的位置。检查完所有行后,在数据块中添加一列Compare Result,标记不同的行,最后写入生成两个新文件。
所有依赖包都在需求 Txt 中:
熊猫 1.1.4
openpyxl 3.0.7
xlrd 1.2.0
可以直接PIP install -R requirements Txt,直接下载安装依赖包。
逻辑很简单,但还没有经过充分的测试。在某些特殊情况下可能会出现其他错误。如果是这样,请给我留言以解释导致错误的原因,并在您有时间时进行改进。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)