PyDP:一个 Python 差分隐私库
外形图
1️⃣差分隐私试图解决什么问题?
2️⃣为什么匿名化还不够?
3️⃣PyDP示例演练
差分隐私试图解决什么问题?
差异隐私旨在解决_在学习有关人群的有用信息时对个人一无所知_的悖论。从本质上讲,它描述了数据持有者或策展人对数据主体做出的以下承诺:
“无论有哪些其他研究、数据集或信息来源可用,允许您的数据用于任何研究或分析,您都不会受到不利或其他影响。” – Cynthia Dwork 在_差分隐私的算法基础_中。
差分隐私确保作为对查询的响应的_任何_序列输出“基本上”同样可能发生,而与任何个人记录的存在或不存在无关。
考虑下图,其中两个数据库Database#1和Database#2仅相差一条记录,例如您的数据。如果在这两种不同设置下查询数据库获得的结果几乎相同或分布相似,那么它们本质上对对手来说是无法区分的。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--JJXPrCfD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/sg7q97kdm7wv601erl1i.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JJXPrCfD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/sg7q97kdm7wv601erl1i.jpg)
差分私有数据库机制图解(图片来源)
数学上,
Pr[M(d)∈S]≤exp(ε)Pr[M(d′)∈S] Pr[M(d)∈S]≤exp(ε)Pr[M(d )∈S] Pr[M(d)∈S]≤exp(ε)Pr[M(d′)∈S]
其中,d和d’是两个数据子集,它们因单个训练示例而不同。
-
M(d)是训练子集d的训练算法的输出,M(d’)是训练子集d’的训练算法的输出。 -
在这两种情况下,这些输出属于特定集合
S的概率应该是任意接近的。上述等式应该适用于所有子集d和d’。
Ɛ 的值越小,隐私保障越强。
成员推理攻击 (MIA) 尝试通过查询模型来确定机器学习模型的训练数据中是否存在记录。从上面的讨论中,由于无法推断个人数据记录的包含或排除,差异隐私确保了对此类攻击的保护。
因此,差分私有数据库机制可以使机密数据广泛用于准确的数据分析。
为什么匿名化还不够?
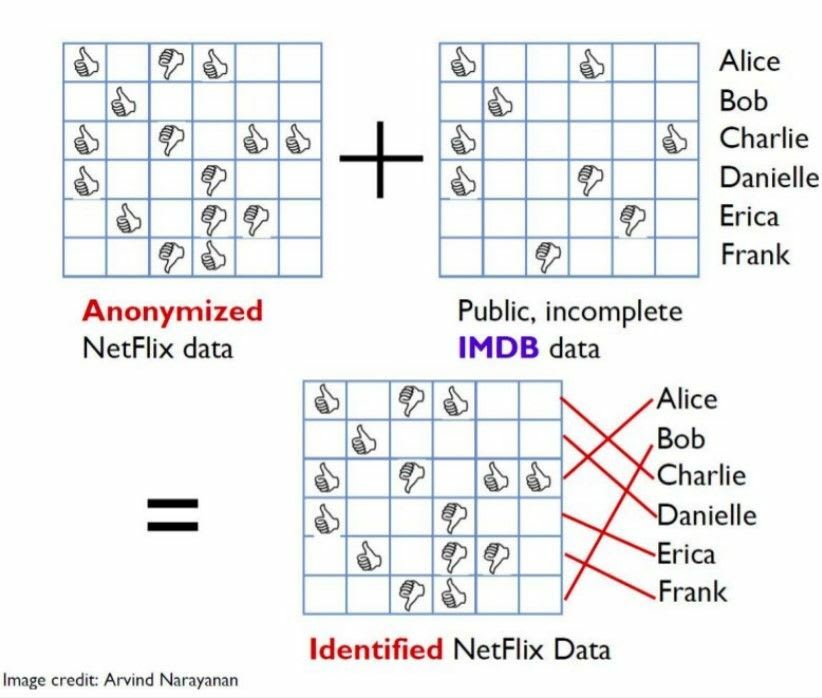
Netflix 奖是一项针对电影推荐最佳协同过滤算法的公开竞赛。
发布的数据集是匿名的,除了为比赛分配的数字外,没有用户或电影被识别。 Netflix 将此类匿名电影记录作为比赛的训练数据发布。
然而,有几个用户可以通过与非匿名和公开可用的互联网电影数据库 (IMDb) 的链接来识别。
德克萨斯大学奥斯汀分校的研究人员 Arvind Narayanan 和 Vitaly Shmatikov 在他们的工作_Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset)_中介绍了他们的研究。
因此,这种_链接攻击_可用于将“anonymized”记录与不同数据集中的非匿名记录进行匹配。
-
差分隐私旨在消除这种链接攻击。
-
由于差分隐私是数据访问机制的属性,它与对手可用的辅助信息的存在与否无关。
因此,访问 IMDb 将不再允许对历史在 Netflix 训练集中的人进行链接攻击,而不是对不在训练集中的人进行攻击。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--VPeqPC6t--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/wsq7l8rotc04r5k0vpem.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--VPeqPC6t--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/wsq7l8rotc04r5k0vpem.jpg)
Netflix 奖竞赛中用户的去匿名化(图片来源:Arvind Narayanan)
PyDP 示例演练
PyDP 是 OpenMined 的 Python 包装器,用于 Google 的差异隐私项目。该库提供了一组 ε-差分私有算法,可用于生成包含私有或潜在敏感信息的数字数据集的聚合统计信息。
安装 PyDP
!pip install python-dp # installing PyDP
进入全屏模式 退出全屏模式
必要进口
import pydp as dp # by convention our package is to be imported as dp (dp for Differential Privacy!)
from pydp.algorithms.laplacian import BoundedSum, BoundedMean, Count, Max
import pandas as pd
import statistics
import numpy as np
import matplotlib.pyplot as plt
进入全屏模式 退出全屏模式
获取所有需要的数据!
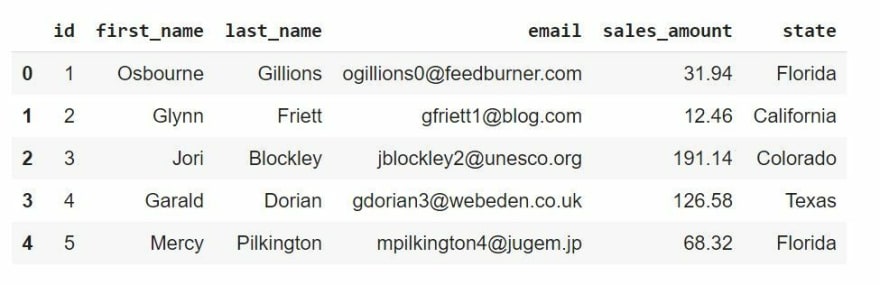
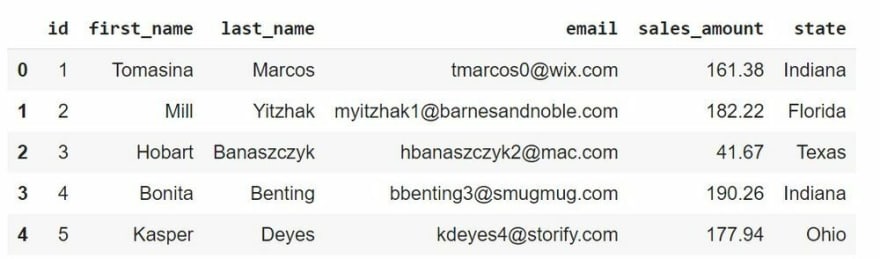
这里使用的数据集包含 5000 条记录,并存储在 5 个文件中,每个文件包含 1000 条记录。
更具体地说,该数据集包含详细信息,例如姓名、客户的电子邮件地址和他们购买商品的金额,以及他们来自美国的哪个州。
让我们获取所有记录,将它们读入 pandas DataFrames 并查看每个 DataFrames 的头部。
url1 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/01.csv'
df1 = pd.read_csv(url1,sep=",", engine = "python")
print(df1.head())
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--OuzYwD4w--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/ozr7zs2pjhejc17dllm4.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--OuzYwD4w--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/ozr7zs2pjhejc17dllm4.jpg)
url2 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/02.csv'
df2 = pd.read_csv(url2,sep=",", engine = "python")
print(df2.head())
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--KyYCa1rj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/fqns91ihdlyyh6gjxr20.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--KyYCa1rj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/fqns91ihdlyyh6gjxr20.jpg)
url3 ='https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/03.csv'
df3 = pd.read_csv(url3,sep=",", engine = "python")
df3.head()
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s---OQFeh9v---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/4q65q3a9rbl4xs4tzvdy.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s---OQFeh9v---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/4q65q3a9rbl4xs4tzvdy.jpg)
url4 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/04.csv'
df4 = pd.read_csv(url4,sep=",", engine = "python")
print(df4.head())
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--M_ce07Cs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/m8fvbjzk9z8h9cwlsn00.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--M_ce07Cs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/m8fvbjzk9z8h9cwlsn00.jpg)
url5 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/05.csv'
df5 = pd.read_csv(url5,sep=",", engine = "python")
print(df5.head())
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--ZcXPtyvG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/em91nefqovyos1h5i4lp.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ZcXPtyvG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/em91nefqovyos1h5i4lp.jpg)
现在我们已经从所有 5 个文件中获取了记录,让我们将所有 DataFrame 连接到一个大 DataFrame 中,这构成了我们的原始数据集。请注意,我们的数据集有 5000 行(记录)和 6 列。
combined_df_temp = [df1, df2, df3, df4, df5]
original_dataset = pd.concat(combined_df_temp)
print(original_dataset.shape)
# Result
# (5000,6)
进入全屏模式 退出全屏模式
创建并行数据库
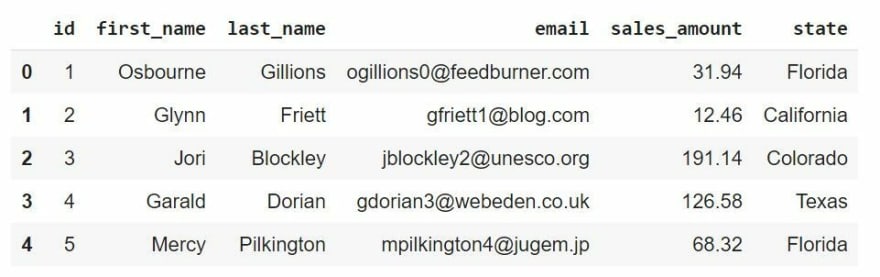
现在让我们创建一个仅相差一条记录的并行数据库,例如 Osbourne 的记录,并将其命名为 redact_dataset。然后,我们检查两个 DataFrame 的头部以验证 Osbourne 的记录是否已被删除。
redact_dataset = original_dataset.copy()
redact_dataset = redact_dataset[1:]
print(original_dataset.head())
print(redact_dataset.head())
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--x7oaauvA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/dcmrfdm81w3pxuegxs1g.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--x7oaauvA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/dcmrfdm81w3pxuegxs1g.jpg)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--iUsrQiHu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/7zrzj5ohpslcjle7icjl.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--iUsrQiHu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/7zrzj5ohpslcjle7icjl.jpg)
在这一点上,让我们问自己以下问题。
我们在附近商店花费的金额是私人信息还是敏感信息?好吧,它可能看起来并不那么敏感!但是,如果相同的信息可以用来识别我们呢?
在我们的示例中,假设我们删除了所有个人信息,例如姓名和电子邮件地址。鉴于可以访问商店的销售记录,销售额本身是否不足以推断 Osbourne 的身份?是的!
为此,我们将原始数据集中sales_amount列和redact_dataset中的所有条目相加。这两个总和之间的差正好给了我们 Osbourne 花费的金额,并如下面的代码片段所示进行验证。
这是一个简单的示例,即使在删除个人身份信息之后,成员资格推断也是成功的。
sum_original_dataset = round(sum(original_dataset['sales_amount'].to_list()), 2)
sum_redact_dataset = round(sum(redact_dataset['sales_amount'].to_list()), 2)
sales_amount_Osbourne = round((sum_original_dataset - sum_redact_dataset), 2)
assert sales_amount_Osbourne == original_dataset.iloc[0, 4]
进入全屏模式 退出全屏模式
差分私有和
现在,我们将说明差分私有求和代替简单求和如何有助于_使成员推断攻击不成功_。
对于上面的示例,我们假设客户应该在商店至少花费 5 美元,并且每次购买不超过 250 美元。
然后,我们继续在原始数据集和并行数据集上计算差异私人总和,这些数据集相差一条记录,如下面的代码片段所示。
dp_sum_original_dataset = BoundedSum(epsilon= 1.5, lower_bound = 5, upper_bound = 250, dtype ='float')
dp_sum_og = dp_sum_original_dataset.quick_result(original_dataset['sales_amount'].to_list())
dp_sum_og = round(dp_sum_og, 2)
print(dp_sum_og)
# Output dp_sum_og
# 636723.61
dp_redact_dataset = BoundedSum(epsilon= 1.5, lower_bound = 5, upper_bound = 250, dtype ='float')
dp_redact_dataset.add_entries(redact_dataset['sales_amount'].to_list())
dp_sum_redact=round(dp_redact_dataset.result(), 2)
print(dp_sum_redact)
# Output dp_sum_redact
# 636659.17
进入全屏模式 退出全屏模式
让我们继续总结一些观察结果。
-
现在我们已经计算了原始数据集和第二个数据集上的差分私有和,很容易验证_差分私有和不等于非差分私有设置下的总和_。
-
此外,差额不再等于 Osbourne 花费的金额,这表明无论访问任何其他客户记录如何,会员攻击现在都不会成功。
-
有趣的是,差分私有总和值仍然具有可比性,并且差别不大。
因此,在我们的简单示例中,我们成功地确保了差异隐私!
print(f"Sum of sales_value in the orignal dataset: {sum_original_dataset}")
print(f"Sum of sales_value in the orignal dataset with DP: {dp_sum_og}")
assert dp_sum_og != sum_original_dataset
# Output
Sum of sales_value in the orignal dataset: 636594.59
Sum of sales_value in the orignal dataset with DP: 636723.61
print(f"Sum of sales_value in the second dataset: {sum_redact_dataset}")
print(f"Sum of sales_value in the second dataset with DP: {dp_sum_redact}")
assert dp_sum_redact != sum_redact_dataset
# Output
Sum of sales_value in the second dataset: 636562.65
Sum of sales_value in the second dataset with DP: 636659.17
print(f"Difference in Sum with DP: {round(dp_sum_og - dp_sum_redact, 2)}")
print(f"Actual Difference in Sum: {sales_amount_Osbourne}")
assert round(dp_sum_og - dp_sum_redact, 2) != sales_amount_Osbourne
# Output
Difference in sum using DP: 64.44
Actual Value: 31.94
进入全屏模式 退出全屏模式
希望这篇介绍性文章有助于理解差异隐私背后的直觉和防止成员推断攻击。我们将在后续的博客文章中查看更多示例。😊
参考文献
[1] Cynthia Dwork 的差分隐私的算法基础。
[2] Chinmay Shah 在 OpenMined 隐私大会上的 PyDP 教程

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)