完整的 Scrapyd 指南 - 部署、调度和运行你的 Scrapy Spiders
作为The Python Scrapy Playbook的一部分发布。
你已经构建了你的爬虫,测试了它的工作原理,现在想要安排它每小时、每天等运行一次,并抓取你需要的数据。但是最好的方法是什么?
Scrapyd是最受欢迎的选项之一。 Scrapyd 由开发 Scrapy 本身的同一开发人员创建,是一种在远程服务器上运行 Scrapy 蜘蛛的工具,因此您无需在本地计算机上运行它们。
在本指南中,我们将介绍:
-
什么是 Scrapyd?
-
如何设置 Scrapyd?
-
部署爬虫到 Scrapyd
-
用 Scrapyd 控制蜘蛛
-
将 Scrapyd 与 ScrapeOps 集成
来自ZWZ100037 ScrapeOps ZWZ100038 ZWZ100036(ZWZ100040实时演示ZWZ100041 ZWZ100039)到ZWZ100043到SCRAPYDWEB]4420004447446 ZWZ100046 RECEDERER。
因此,如果您想根据您的要求选择最好的,请务必查看我们的最佳 Scrapyd 仪表板指南,以便在决定使用哪个选项之前查看每个选项的优缺点.
什么是 Scrapyd?
Scrapyd是允许我们在服务器上部署 Scrapy 蜘蛛并使用 JSON API 远程运行它们的应用程序。 Scrapyd 允许您:
-
运行 Scrapy 作业。
-
暂停和取消 Scrapy 作业。
-
管理 Scrapy 项目/蜘蛛版本。
-
远程访问 Scrapy 日志。
Scrapyd 对于想要一种简单的方法来管理在远程服务器上运行的生产 Scrapy 蜘蛛的开发人员来说是一个很好的选择。
使用 Scrapyd,您可以使用现成的 Scrapyd 管理工具(如ScrapeOps,一种开源替代方案)或构建自己的工具,从一个中心点管理多个服务器。
在这里你可以查看完整的Scrapyd 文档和Github repo。
如何设置 Scrapyd
设置 Scrapyd 既快速又简单。您可以在本地或服务器上运行它。
第一步是安装 Scrapyd:
pip install scrapyd
进入全屏模式 退出全屏模式
然后使用以下命令启动服务器:
scrapyd
进入全屏模式 退出全屏模式
这将启动在http://localhost:6800/上运行的 Scrapyd。您可以在浏览器中打开此网址,您应该会看到以下屏幕:
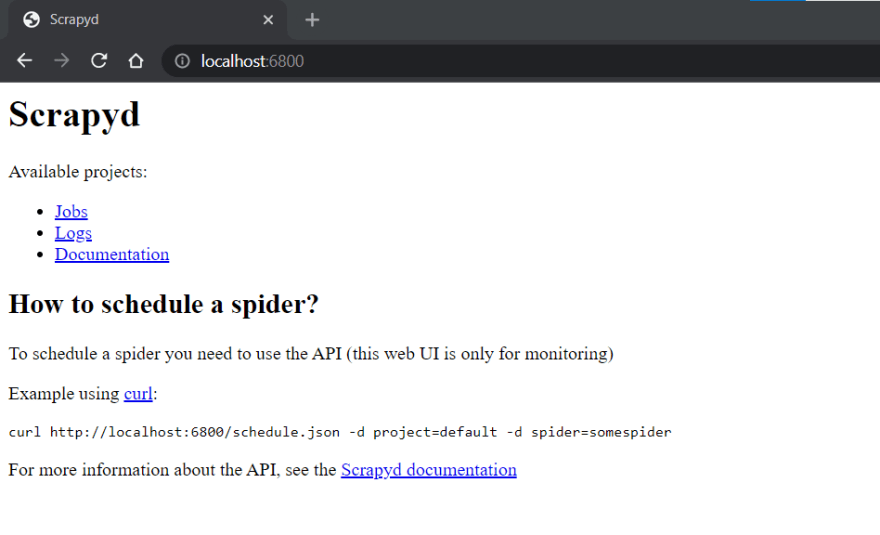
部署蜘蛛到 Scrapyd
要使用 Scrapyd 运行作业,我们首先需要对 Scrapy 项目进行蛋化并将其部署到 Scrapyd 服务器。为此,有一个名为scrapyd-client的易于使用的库使此过程非常简单。
首先让我们安装scrapyd-client
pip install git+https://github.com/scrapy/scrapyd-client.git
进入全屏模式 退出全屏模式
安装后,导航到您要部署的 Scrapy 项目并打开您的scrapyd.cfg文件,该文件应位于您的项目根目录中。您应该会看到类似这样的内容,其中 "demo" 文本被您的 Scrapy 项目名称替换:
## scrapy.cfg
[settings]
default = demo.settings
[deploy]
#url = http://localhost:6800/
project = demo
进入全屏模式 退出全屏模式
这里的scrapyd.cfg配置文件定义了你的 Scrapy 项目应该部署到的端点。为了使我们能够将项目部署到 Scrapyd,如果我们想将其部署到本地运行的 Scrapyd 服务器,我们只需取消注释url值。
## scrapy.cfg
[settings]
default = demo.settings
[deploy]
url = http://localhost:6800/
project = demo
进入全屏模式 退出全屏模式
然后在您的 Scrapy 项目根目录中运行以下命令:
scrapyd-deploy default
进入全屏模式 退出全屏模式
然后,这将使您的 Scrapy 项目蛋化并将其部署到您本地运行的 Scrapyd 服务器。如果成功,您应该在终端中得到这样的结果:
$ scrapyd-deploy default
Packing version 1640086638
Deploying to project "demo" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "DESKTOP-67BR2", "status": "ok", "project": "demo", "version": "1640086638", "spiders": 1}
进入全屏模式 退出全屏模式
现在你的 Scrapy 项目已经部署到你的 Scrapyd 并且可以运行了。
除了:自定义部署端点
上面的示例是最简单的实现,并假设您只是将 Scrapy 项目部署到本地 Scrapyd 服务器。但是,您可以根据需要自定义或添加多个部署端点到scrapyd.cfg文件。
例如,您可以定义本地和生产端点:
## scrapy.cfg
[settings]
default = demo.settings
[deploy:local]
url = http://localhost:6800/
project = demo
[deploy:production]
url = <MY_IP_ADDRESS>
project = demo
进入全屏模式 退出全屏模式
并使用以下命令在本地或生产环境中部署您的 Scrapy 项目:
## Deploy locally
scrapyd-deploy local
## Deploy to production
scrapyd-deploy production
进入全屏模式 退出全屏模式
或者通过指定项目名称来部署特定项目:
scrapyd-deploy <target> -p <project>
进入全屏模式 退出全屏模式
有关这方面的更多信息,请在此处查看scrapyd-client 文档。
用 Scrapyd 控制蜘蛛
Scrapyd 带有一个最小的 Web 界面,可以通过http://localhost:6800/访问,但是,这个界面只是对 Scrapyd 服务器上运行的内容的基本概述,不允许您控制蜘蛛部署到 Scrapyd 服务器。
要使用 Scrapyd 控制您的蜘蛛,您有 3 个选项:
-
Scrapyd JSON API
-
Python-Scrapyd-API 库
-
Scrapyd 仪表板
Scrapyd JSON API
要在您的 Scrapyd 服务器上安排、运行、取消作业,我们需要使用它提供的 JSON API。根据端点,API 支持GET或POSTHTTP 请求。例如:
$ curl http://localhost:6800/daemonstatus.json
{ "status": "ok", "running": "0", "pending": "0", "finished": "0", "node_name": "DESKTOP-67BR2" }
进入全屏模式 退出全屏模式
API 具有以下端点:
端点
描述
daemonstatus.json
检查 Scrapyd 服务器的状态。
addversion.json
向项目添加版本,如果项目不存在则创建项目。
** schedule.json **
安排要运行的作业。
取消.json
取消作业。如果作业处于待处理状态,它将被删除。如果作业正在运行,则作业将被关闭。
listprojects.json
返回上传到 Scrapyd 服务器的项目列表。
listversions.json
返回可用于请求项目的版本列表。
**listspiders.json **
返回可用于请求项目的蜘蛛列表。
listjobs.json
返回所请求项目的待处理、运行和已完成作业的列表。
delversion.json
删除项目版本。如果项目只有一个版本,也删除该项目。
delproject.json
删除项目和所有关联的版本。
完整的 API 规范可以在这里找到。
我们可以使用 Python Requests 或任何其他 HTTP 请求库与这些端点交互,或者我们可以使用python-scrapyd-api一个用于 Scrapyd API 的 Python 包装器。
Python-Scrapyd-API库
python-scrapyd-api围绕 Scrapyd JSON API 提供了一个干净且易于使用的 Python 包装器,可以简化您的代码。
首先,我们需要安装它:
pip install python-scrapyd-api
进入全屏模式 退出全屏模式
然后在我们的代码中,我们需要导入库并将其配置为与我们的 Scrapyd 服务器交互,方法是向其传递 Scrapyd IP 地址。
>>> from scrapyd_api import ScrapydAPI
>>> scrapyd = ScrapydAPI('http://localhost:6800')
进入全屏模式 退出全屏模式
从这里,我们可以使用内置方法与 Scrapyd 服务器交互。
检查守护进程状态
检查 Scrapyd 服务器的状态。
>>> scrapyd.daemon_status()
{u'finished': 0, u'running': 0, u'pending': 0, u'node_name': u'DESKTOP-67BR2'}
进入全屏模式 退出全屏模式
列出所有项目
返回上传到 Scrapyd 服务器的项目列表。
>>> scrapyd.list_projects()
[u'demo', u'quotes_project']
进入全屏模式 退出全屏模式
列出所有蜘蛛
输入项目名称,它将返回可用于所请求项目的蜘蛛列表。
>>> scrapyd.list_spiders('project_name')
[u'raw_spider', u'js_enhanced_spider', u'selenium_spider']
进入全屏模式 退出全屏模式
运行作业
通过指定项目和蜘蛛名称来运行 Scrapy 蜘蛛。
>>> scrapyd.schedule('project_name', 'spider_name')
# Returns the Scrapyd job id.
u'14a6599ef67111e38a0e080027880ca6'
进入全屏模式 退出全屏模式
使用settings参数传递自定义设置。
>>> settings = {'DOWNLOAD_DELAY': 2}
>>> scrapyd.schedule('project_name', 'spider_name', settings=settings)
u'25b6588ef67333e38a0e080027880de7'
进入全屏模式 退出全屏模式
关于 schedule.json API 端点需要注意的一件重要事情。即使端点称为 schedule.json,使用它也只会将作业添加到内部 Scrapy 调度程序队列,该队列将在插槽空闲时运行。
该端点不具有在未来安排作业的功能,因此它在特定时间运行,Scrapyd 会将作业添加到队列中,并在 Scrapy 插槽可用时运行它。
要实际安排作业在未来的特定日期/时间或定期在特定时间运行,那么您将需要最终控制此调度。像ScrapeOps这样的工具会为你做这件事。
取消正在运行的作业
通过发送项目名称和作业_id 取消正在运行的作业。
>>> scrapyd.cancel('project_name', '14a6599ef67111e38a0e080027880ca6')
# Returns the "previous state" of the job before it was cancelled: 'running' or 'pending'.
'running'
进入全屏模式 退出全屏模式
发送后,它将返回作业被取消之前的“先前状态”。您可以通过检查作业状态来验证作业是否实际被取消。
>>> scrapyd.job_status('project_name', '14a6599ef67111e38a0e080027880ca6')
# Returns 'running', 'pending', 'finished' or '' for unknown state.
'finished'
进入全屏模式 退出全屏模式
如需更多功能,请在此处查看 python-scrapyd-api文档。
Scrapyd 仪表板
使用 Scrapyd 的 JSON API 来控制你的蜘蛛是可能的,但是它并不理想,因为你需要在你的终端上创建自定义工作流来监控、管理和运行你的蜘蛛。如果您需要管理分布在多个服务器上的蜘蛛,这本身就可以成为一个主要项目。
其他开发人员遇到了这个问题,对我们来说很幸运,他们决定创建免费和开源的 Scrapyd 仪表板,可以连接到您的 Scrapyd 服务器,这样您就可以从一个仪表板管理所有内容。
有许多不同的 Scrapyd 仪表板和管理工具可用:
-
ScrapeOps(现场演示)
-
ScrapydWeb
-
蜘蛛守护者
如果您想根据您的要求选择最好的,请务必在此处查看我们的最佳 Scrapyd 仪表板指南。
将 Scrapyd 与 ScrapeOps 集成
ScrapeOps是一个免费的网络抓取监控工具,它还有一个 Scrapyd 仪表板,允许您从一个仪表板安排、运行和管理所有抓取工具。
现场演示:ScrapeOps 演示

通过简单的 30 秒安装,ScrapeOps 为您提供了开箱即用的 Web 抓取所需的所有监控、警报、调度和数据验证功能。
与其他 Scrapyd 仪表板不同,ScrapeOps 是一个完整的端到端 Web 抓取监控和管理工具,专用于 Web 抓取,它会自动为您设置所有监视器、健康检查和警报。
特点
设置完成后,ScrapeOps 将:
-
🕵️u200d♂️ 监控 - 自动监控你所有的爬虫。
-
📈 仪表板 - 在仪表板中可视化您的工作数据,以便您查看实时和历史统计数据。
-
💯 数据质量 - 验证每个作业中的字段覆盖率,因此可以立即检测到损坏的解析器。
-
📉 自动健康检查 - 自动检查每个工作的绩效数据与其 7 天移动平均值,看看它是否健康。
-
✔️ 自定义健康检查 - 使用您为其启用的任何自定义健康检查检查每个作业。
-
⏰ 警报 - 如果您的任何工作不健康,请通过电子邮件、Slack 等向您发出警报。
-
📑 报告 - 生成每日(定期)报告,根据您的标准检查所有工作,并让您知道一切是否健康。
集成
将 ScrapeOps 与您的 Scrapyd 服务器集成有两个步骤:
-
安装 ScrapeOps Logger 扩展
-
将 ScrapeOps 连接到您的 Scrapyd 服务器
注意: 您无法将 ScrapeOps 连接到本地运行的 Scrapyd 服务器,并且不提供可连接的公共 IP 地址。
设置完成后,您将能够从一个仪表板安排、运行和管理所有 Scrapyd 服务器。
第1步:安装Scrapy Logger扩展
为了让 ScrapeOps 监控您的爬虫、创建仪表板并触发警报,您需要在每个 Scrapy 项目中安装 ScrapeOps 记录器扩展。
只需安装 Python 包:
pip install scrapeops-scrapy
进入全屏模式 退出全屏模式
并在您的settings.py文件中添加 3 行:
## settings.py
## Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
## Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
## Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
进入全屏模式 退出全屏模式
从那里,您的抓取统计信息将被自动记录并自动发送到您的仪表板。
第 2 步:将 ScrapeOps 连接到您的 Scrapyd 服务器
下一步是向 ScrapeOps 提供 Scrapyd 服务器的连接详细信息,以便您可以从仪表板管理它们。
进入 Scrapyd 服务器详情
在您的仪表板中,转到服务器页面并单击页面顶部的添加 Scrapyd 服务器。
然后在下拉部分中输入您的连接详细信息:
-
服务器名称
-
服务器域名(可选)
-
服务器IP地址
祖兹 100,238 * *
白名单我们的服务器(可选)
根据您保护 Scrapyd 服务器的方式,您可能需要将我们的 IP 地址列入白名单,以便它可以连接到您的 Scrapyd 服务器。有两种方法可以做到这一点:
选项1:自动安装(Ubuntu)
以 root 身份通过 SSH 连接到您的服务器,并在终端中运行以下命令。
wget -O scrapeops_setup.sh "https://assets-scrapeops.nyc3.digitaloceanspaces.com/Bash_Scripts/scrapeops_setup.sh"; bash scrapeops_setup.sh
进入全屏模式 退出全屏模式
此命令将开始为您的服务器提供配置过程,并将配置服务器以便 Scrapyd 可以由 Scrapeops 管理。
选项 2:手动安装
此步骤是可选的,但如果您想使用我们的网站运行/停止/重新运行/安排任何作业,则需要此步骤。如果我们无法通过端口 80 或 443 访问您的服务器,该服务器将被列为只读。
以下步骤应该适用于安装了 UFW 防火墙的基于 Linux/Unix 的服务器。:
第 1 步: 通过 SSH 登录您的服务器
第 2 步: 启用 SSH,这样您就不会被您的服务器阻止
sudo ufw allow ssh
进入全屏模式 退出全屏模式
第 3 步: 允许来自 46.101.44.87 的传入连接
sudo ufw allow from 46.101.44.87 to any port 443,80 proto tcp
进入全屏模式 退出全屏模式
第 4 步: 启用 ufw 并检查防火墙规则是否已实施
sudo ufw enable
sudo ufw status
进入全屏模式 退出全屏模式
第 5 步: 安装 Nginx 并设置反向代理,让来自 scrapeops 的连接到达您的 scrapyd 服务器。
sudo apt-get install nginx -y
进入全屏模式 退出全屏模式
将下面的 proxy_pass & proxy_set_header 代码添加到 nginx 默认配置文件的“位置”块中(默认文件通常在 /etc/nginx/sites-available 中找到)
proxy_pass http://localhost:6800/;
proxy_set_header X-Forwarded-Proto http;
进入全屏模式 退出全屏模式
重新加载你的 nginx 配置
sudo systemctl reload nginx
进入全屏模式 退出全屏模式
完成此操作后,您应该能够从 ScrapeOps 仪表板运行、重新运行、停止、安排此服务器的作业。
更多 Scrapy 教程
这就是如何使用 Scrapyd 运行您的 Scrapy 蜘蛛。如果您想了解有关 Scrapy 的更多信息,请务必查看The Scrapy Playbook。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)