为什么不能反转带有标志表情符号的字符串?

您认为以下 Python 代码的输出是什么?
>>> flag = "🇺🇸"
>>> reversed_flag = flag[::-1]
>>> print(reversed_flag)
进入全屏模式 退出全屏模式
像这样的问题让我想立即打开一个 Python REPL 并尝试代码,因为我_认为_我知道答案是什么,但我对这个答案不是很有信心。
这是我第一次看到这个问题时的想法:
-
flag字符串包含单个字符。 -
[::-1]切片反转flag字符串。 -
单个字符的字符串反转与原字符串相同。
-
因此,
reversed_flag必须是"🇺🇸"。
这是一个完美的有效参数。但结论是真的吗?看一看:
>>> flag = "🇺🇸"
>>> reversed_flag = flag[::-1]
>>> print(reversed_flag)
🇸🇺
进入全屏模式 退出全屏模式
这里到底发生了什么?
"🇺🇸"真的包含单个字符吗?
当一个有效论证的结论为假时,它的前提之一_也必须_为假。让我们从顶部开始:
flag字符串包含一个字符。
是这样吗?你怎么知道一个字符串有多少个字符?
在 Python 中,您可以使用内置的len()函数来获取字符串中的字符总数:
>>> len("🇺🇸")
2
进入全屏模式 退出全屏模式
哦。
这很奇怪。您只能在字符串"🇺🇸"(即美国国旗)中_看到_单个_thing_,但2的长度与flag[::-1]的结果相近。由于"🇺🇸"的反面是"🇸🇺",这似乎暗示了"🇺🇸" == "🇺 🇸"。
如何判断字符串中有哪些字符?
有几种不同的方法可以使用 Python 查看字符串中的所有真实字符:
>>> # Convert a string to a list
>>> list("🇺🇸")
['🇺', '🇸']
>>> # Loop over each character and print
>>> for character in "🇺🇸":
... print(character)
...
🇺
🇸
进入全屏模式 退出全屏模式
美国国旗表情符号并不是唯一有两个字符的国旗表情符号:
>>> list("🇿🇼") # Zimbabwe
['🇿', '🇼']
>>> list("🇳🇴") # Norway
['🇳', '🇴']
>>> list("🇨🇺") # Cuba
['🇨', '🇺']
>>> # What do you notice?
进入全屏模式 退出全屏模式
然后是苏格兰国旗:
>>> list("🏴")
['🏴', '\U000e0067', '\U000e0062', '\U000e0073', '\U000e0063',
'\U000e0074', '\U000e007f']
进入全屏模式 退出全屏模式
好的,关于 _ 的全部内容是什么?
💪🏻 挑战: 你能找到任何看起来像单个字符但实际上包含两个或多个字符的非表情符号字符串吗?
这些示例令人不安的是,它们暗示您无法仅通过查看屏幕来判断字符串中的字符。
或者,也许更深入地说,它让你质疑你对字符一词的理解。
到底什么是字符?
计算机科学中的 character 一词可能会令人困惑。它往往与单词 symbol 混为一谈,公平地说,它是单词字符的同义词,因为它用于英语白话。
事实上,当我搜索character computer science时,我得到的第一个结果是一个指向Technopedia 文章的链接,该文章将一个字符定义为:
“[A] 信息的显示单位,相当于一个字母或符号。”
— 技术百科,“字符(Char)”
该定义似乎不正确,尤其是鉴于美国国旗示例表明单个符号可能由至少两个字符组成。
我得到的第二个谷歌结果是维基百科。在 that 文章中,字符的定义更自由一些:
”[A] 字符是一个信息单元,大致对应于 grapheme,类似字形的单元或符号,例如在自然语言的书面形式的字母表或音节表中。
— 维基百科,“字符(计算)”
嗯...在定义中使用“大致”这个词会使定义感觉,容我说,non-definitive。
但维基百科的文章继续解释说,字符一词在历史上一直被用来“表示特定数量的连续位”。
然后,关于具有一个符号的字符串如何包含两个或多个字符的问题的重要线索:
“当今最普遍认为一个字符指的是 8 位(一个字节)...... 所有 [symbols] 都可以用一个或多个 UTF-8 的 8 位代码单元来表示。”
— 维基百科,“字符(计算)”
好的!也许事情开始变得更有意义了。一个字符是_一个字节的信息_代表一个文本单元。我们在字符串中看到的符号可以由多个 8 位(1 字节)_UTF-8 代码单元_组成。
Characters 与_symbols 不同。_ 现在一个符号可以由多个字符组成似乎是合理的,就像标志表情符号一样。
但什么是 UTF-8 代码单元?
在 Wikipedia 关于字符的文章再往下一点,有一个名为 Encoding 的部分解释了:
“计算机和通信设备使用字符编码来表示字符,该编码将每个字符分配给某物——通常是由数字序列表示的整数——可以通过网络存储或传输。常用编码的两个例子是 ASCII 和 Unicode 的 UTF-8 编码。”
— 维基百科,“字符(计算)”
还有一次提到了 UTF-8!但现在我需要知道什么是字符编码。
究竟什么是字符编码?
根据维基百科,字符编码将每个字符分配给一个数字。这意味着什么?
这不是说你可以将每个字符与一个数字配对吗?因此,您可以将英文字母表中的每个大写字母与 0 到 25 之间的整数配对。

您可以在 Python 中使用元组来表示这种配对:
>>> pairs = [(0, "A"), (1, "B"), (2, "C"), ..., (25, "Z")]
>>> # I'm omitting several pairs here -----^^^
进入全屏模式 退出全屏模式
停下来问问自己:“我可以在不明确写出每一对的情况下创建一个像上面那样的元组列表吗?”
一种方法是使用Python 的enumerate()函数。enumerate()接受一个名为 iterable 的参数并返回一个元组,该元组包含一个默认为 0 的计数以及通过迭代 iterable 获得的值。
下面来看看enumerate()的实际应用:
>>> letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
>>> enumerated_letters = list(enumerate(letters))
>>> enumerated_letters
[(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'), (6, 'G'),
(7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'), (13, 'N'),
(14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'), (19, 'T'), (20, 'U'),
(21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'), (25, 'Z')]
进入全屏模式 退出全屏模式
还有一种更简单的方法可以制作所有字母。
Python 的string模块有一个名为ascii_uppercase的变量,它指向一个包含英文字母表中所有大写字母的字符串:
>>> import string
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> enumerated_letters = list(enumerate(string.ascii_uppercase))
>>> enumerated_letters
[(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'), (6, 'G'),
(7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'), (13, 'N'),
(14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'), (19, 'T'),
(20, 'U'), (21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'), (25, 'Z')]
进入全屏模式 退出全屏模式
好的,所以我们将字符与整数相关联。这意味着我们有一个字符编码!
但是,你如何使用它?
要将字符串”PYTHON”编码为整数序列,您需要一种方法来查找与每个字符关联的整数。但是,在元组列表中查找内容很困难。它也确实效率低下。 (为什么?)
字典很适合查资料。如果我们将enumerated_letters转换为字典,我们可以快速查找与整数相关的字母:
>>> int_to_char = dict(enumerated_letters)
>>> # Get the character paired with 1
>>> int_to_char[1]
'B'
>>> # Get the character paired with 15
>>> int_to_char[15]
'P'
进入全屏模式 退出全屏模式
但是,要对字符串”PYTHON”进行编码,您需要能够查找与字符关联的整数。你需要int_to_char.的反面
如何交换 Python 字典中的键和值?
一种方法是使用reversed()函数从int_to_char字典中反转键值对:
>>> # int_to_char.items() is a "list" of key-value pairs
>>> int_to_char.items()
dict_items([(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D'), (4, 'E'), (5, 'F'),
(6, 'G'), (7, 'H'), (8, 'I'), (9, 'J'), (10, 'K'), (11, 'L'), (12, 'M'),
(13, 'N'), (14, 'O'), (15, 'P'), (16, 'Q'), (17, 'R'), (18, 'S'),
(19, 'T'), (20, 'U'), (21, 'V'), (22, 'W'), (23, 'X'), (24, 'Y'),
(25, 'Z')])
>>> # The reversed() function can reverse a tuple
>>> pair = (0, "A")
>>> tuple(reversed(pair))
('A', 0)
进入全屏模式 退出全屏模式
您可以编写一个生成器表达式来反转int_to_char.items()中的所有对并使用该生成器表达式来填充字典:
>>> char_to_int = dict(reversed(pair) for pair in int_to_char.items())
>>> # Reverse the pair-^^^^^^^^^^^^^^
>>> # For every key-value pair--------^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
>>> # Get the integer associated with B
>>> char_to_int["B"]
1
>>> # Get the integer associated with P
>>> char_to_int["P"]
15
进入全屏模式 退出全屏模式
最好将每个字母与一个唯一的整数配对。否则,这种字典反转就行不通了。 (为什么?)
现在您可以使用char_to_int字典和列表理解将字符串编码为整数列表:
>>> [char_to_int[char] for char in "PYTHON"]
[15, 24, 19, 7, 14, 13]
进入全屏模式 退出全屏模式
您可以使用 Python 的字符串.join()方法在生成器表达式中使用int_to_char将整数列表转换为大写字符字符串:
>>> "".join(int_to_char[num] for num in [7, 4, 11, 11, 14])
'HELLO'
进入全屏模式 退出全屏模式
但是,有一个问题。
您的编码无法处理带有标点符号、小写字母和空格之类的字符串:
>>> [char_to_int[char] for char in "monty python!"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <listcomp>
KeyError: 'm'
>>> # ^^^^^^^-----char_to_int has no "m" key
进入全屏模式 退出全屏模式
解决此问题的一种方法是使用包含您需要的所有小写字母、标点符号和空白字符的字符串来创建编码。
但是,在 Python 中,几乎总是有更好的方法。 Python 的string模块包含一个名为printable的变量,它为您提供一个包含一大堆可打印字符的字符串:
>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
进入全屏模式 退出全屏模式
如果您从头开始制作自己的字符串,您会包含所有这些字符吗?
现在您可以制作新的字典来对string.printable中的字符进行编码和解码:
>>> int_to_printable = dict(enumerate(string.printable))
>>> printable_to_int = dict(reversed(item) for item in int_to_printable.items())
进入全屏模式 退出全屏模式
您可以使用这些字典对更复杂的字符串进行编码和解码:
>>> # Encode the string "monty python!"
>>> encoded_string = [printable_to_int[char] for char in "monty python!"]
>>> encoded_string
[22, 24, 23, 29, 34, 94, 25, 34, 29, 17, 24, 23, 62]
>>> # Decode the encoded string
>>> decoded_string = "".join(int_to_printable[num] for num in encoded_string)
>>> decoded_string
'monty python!'
进入全屏模式 退出全屏模式
您现在已经制作了两种不同的字符编码!他们_真的_是不同的。看看当你使用两种编码解码相同的整数列表时会发生什么:
>>> encoded_string = [15, 24, 19, 7, 14, 13]
>>> # Decode using int_to_char (string.ascii_uppercase)
>>> "".join(int_to_char[num] for num in encoded_string)
'PYTHON'
>>> # Decode using int_to_printable(string.printable)
>>> "".join(int_to_printable[num] for num in encoded_string)
'foj7ed'
进入全屏模式 退出全屏模式
差远了!
所以,现在我们知道了一些关于字符编码的事情:
-
字符编码将字符与唯一整数配对。
-
某些字符编码排除了包含在其他字符编码中的字符。
-
两种不同的字符编码可能会将相同的整数解码为两个不同的字符串。
这与 UTF-8 有什么关系?
什么是 UTF-8?
维基百科关于字符的文章提到了两种不同的字符编码:
“常用编码的两个示例是 ASCII 和 Unicode 的 UTF-8 编码。”
— 维基百科,“字符(计算)”
好的,所以 ASCII 和 UTF-8 是特定类型的字符编码。
根据关于 ASCII 的维基百科文章:
ASCII 是万维网上最常见的字符编码,直到 2007 年 12 月 UTF-8 编码超过它; UTF-8 向后兼容 ASCII。
— 维基百科,“ASCII”
UTF-8 不仅仅是网络的主要字符编码。它也是 Linux 和 macOS 操作系统的主要字符编码,甚至是 Python 代码](https://docs.python.org/3/howto/unicode.html#python-s-unicode-support)的[默认值。
事实上,您可以看到 UTF-8 如何使用 Python 字符串对象上的.encode()方法将字符编码为整数。但是.encode()不返回整数列表。相反,encode()返回一个bytes对象:
>>> encoded_string = "PYTHON".encode()
>>> # The encoded string *looks* like a string still,
>>> # but notice the b in front of the first quote
>>> encoded_string
b'PYTHON'
>>> # b stands for bytes, which is the type of
>>> # object returned by .encode()
>>> type(encoded_string)
<class 'bytes'>
进入全屏模式 退出全屏模式
Python 文档将bytes对象描述为“0 <= x < 256范围内的不可变整数序列”。考虑到encoded_string对象显示字符串“PYTHON”中的字符而不是一堆整数,这似乎有点奇怪。
但是让我们接受这一点,看看我们是否能以某种方式梳理出整数。
Python 文档说bytes是一个“序列”,而Python 的词汇表将序列定义为“[a]n 可迭代,它支持使用整数索引进行有效的元素访问”。
因此,听起来您可以像索引 Pythonlist对象一样索引bytes对象。让我们试一试:
>>> encoded_string[0]
80
进入全屏模式 退出全屏模式
啊哈!
将encoded_string转换为列表时会发生什么?
>>> list(encoded_string)
[80, 89, 84, 72, 79, 78]
进入全屏模式 退出全屏模式
答对了。看起来 UTF-8 将字母”P”分配给整数80,”Y”分配给整数89,”T”分配给整数84,等等。
让我们看看当我们使用 UTF-8 对字符串”🇺🇸”进行编码时会发生什么:
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
进入全屏模式 退出全屏模式
嗯。您是否期望”🇺🇸”被编码为八个整数?
”🇺🇸”由两个字符组成,分别是“🇺”和”🇸"。让我们看看这些是如何编码的:
>>> list("🇺".encode())
[240, 159, 135, 186]
>>> list("🇸".encode())
[240, 159, 135, 184]
进入全屏模式 退出全屏模式
好的,现在事情变得更有意义了。“🇺”和”🇸"都被编码为四个整数,“🇺”对应的四个整数出现在”🇺🇸”对应的整数列表的第一位,而”🇸"对应的四个整数出现在第二位。
不过,这提出了一个问题。
为什么 UTF-8 将某些字符编码为四个整数,而将其他字符编码为一个整数?
字符“🇺”在 UTF-8 中被编码为四个整数的序列,而字符”P”被编码为单个整数。这是为什么?
Wikipedia 的 UTF-8 文章顶部有一个提示:
UTF-8 能够使用一到四个一字节(8 位)代码单元对 Unicode 中的所有 1,112,064 个有效字符代码点进行编码。具有较低数值的代码点往往更频繁地出现,使用较少的字节进行编码。
— 维基百科,“UTF-8”
好的,这听起来像是 UTF-8 不是将字符编码为整数,而是编码为 Unicode 代码点。每个代码单元显然可以是一到四个字节。
我们现在需要回答几个问题:
1.什么是字节?
- 什么是 Unicode 码位?
字节这个词已经浮动了很多,所以让我们继续给它一个正确的定义。
bit 是最小的信息单位。一个位有两种状态,开或关,通常分别用整数0和1表示。 byte 是八位的序列。
您可以将字节解释为整数,方法是将它们的组成位视为用二进制表示法表达的数字。
二进制符号在您第一次看到时可能看起来很奇特。不过,这很像您用来书写数字的常用十进制表示。不同的是,每个数字只能是 0 或 1,并且数字中每个位的值是 2 的幂,而不是 10 的幂:

由于一个字节包含八位,因此您可以用单个字节表示的最大数字是二进制的11111111或十进制的255。
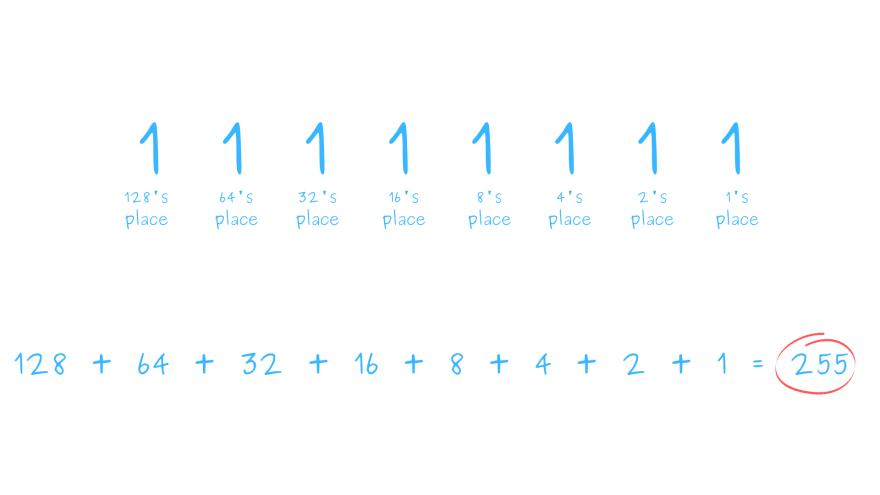
每个字符使用一个字节的字符编码最多可以编码 255 个字符,因为最大 8 位整数是255。
255 个字符可能足以用英语对所有内容进行编码。尽管如此,它仍然无法处理全球书面和电子通信中使用的所有字符和符号。
所以你会怎么做?允许将字符编码为多个字节似乎是一个合理的解决方案,而这正是 UTF-8 所做的。
UTF-8 是 _Unicode 转换格式 — 8 位_的首字母缩写词。又是 Unicode 这个词。
根据 Unicode 网站:
“Unicode 为每个字符提供了一个唯一的编号,无论是什么平台,无论是什么程序,无论是什么语言。”
— Unicode 网站,“什么是 Unicode?”
Unicode 非常庞大。 Unicode 的目标是为所有书面语言提供通用表示。每个字符都被分配给一个代码点——一个带有一些额外组织的“整数”的花哨词——总共有 1,112,064 个可能的代码点。
但是,Unicode 代码点的实际编码方式取决于。 UTF-8 只是一种实现 Unicode 标准的字符编码。它将代码点分成一到四个 8 位整数的组。
Unicode 还有其他编码。 UTF-16 将 Unicode 代码点划分为一个或两个 16 位数字,是 Microsoft Windows](https://docs.microsoft.com/en-us/windows/win32/intl/unicode)使用的[默认编码。 UTF-32 可以将每个 Unicode 代码点编码为单个 21 位整数。
但是等等,UTF-8 使用一到四个字节将符号编码为代码点。好的,那么......为什么🇺🇸符号被编码为八个字节?
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
>>> # There are eight integers in the list, a total of eight bytes!
进入全屏模式 退出全屏模式
请记住,美国国旗表情符号由两个字符组成:🇺 和 🇸。这些字符被称为区域指标符号。 Unicode 标准中有 26 个区域指示符代表 A-Z 英文字母。它们用于编码ISO 3166-1 两个字母的国家代码。
以下是 Wikipedia 对区域指标符号的评价:
这些在 2010 年 10 月被定义为 Unicode 6.0 对表情符号的支持的一部分,作为为每个国家标志编码单独字符的替代方法。尽管它们可以显示为罗马字母,但实现可以选择以其他方式显示它们,例如使用国旗。 TheUnicode FAQ表示应该使用这种机制,并且国旗的符号不会直接编码。
— 维基百科,“区域指示符号”
换句话说,🇺🇸 符号——实际上,any 国家国旗的符号——不被 Unicode 直接支持。操作系统、网络浏览器和其他使用数字文本的地方,可以_选择_到_渲染_对区域指标作为标志。
让我们盘点一下我们目前所知道的:
-
符号字符串通过字符编码(通常为 UTF-8)转换为整数序列。
-
一些字符被 UTF-8 编码为单个 8 位整数,而其他字符则需要两个、三个或四个 8 位整数。
-
一些符号,例如标志表情符号,不是由 Unicode 直接编码的。相反,它们是 Unicode 字符序列的呈现,并且可能会或可能不会被每个平台支持。
那么,当你反转一个字符串时,会反转什么?您是反转编码中的整个整数序列,还是反转代码点的顺序,还是其他不同的东西?
你实际上如何反转字符串?
你能想出一种方法来通过代码实验而不是试图查找答案来回答这个问题吗?
您之前看到 UTF-8 将字符串”PYTHON”编码为六个整数的序列:
>>> list("PYTHON".encode())
[80, 89, 84, 72, 79, 78]
进入全屏模式 退出全屏模式
如果对字符串”PYTHON”的反转进行编码会发生什么?
>>> list("PYTHON"[::-1].encode())
[78, 79, 72, 84, 89, 80]
进入全屏模式 退出全屏模式
在这种情况下,列表中整数的顺序被颠倒了。但是其他符号呢?
之前,您看到“🇺"符号被编码为四个整数的序列。当你编码它的反转时会发生什么?
>>> list("🇺".encode())
[240, 159, 135, 186]
>>> list("🇺"[::-1].encode())
[240, 159, 135, 186]
进入全屏模式 退出全屏模式
嗯。两个列表中整数的顺序是一样的!
让我们尝试用美国国旗反转字符串:
>>> list("🇺🇸".encode())
[240, 159, 135, 186, 240, 159, 135, 184]
>>> # ^^^^^^^^^^^^^^---Code point for 🇺
>>> # ^^^^^^^^^^^^^^^^^^---Code point for 🇸
>>> # The code points get swapped!
>>> list("🇺🇸"[::-1].encode())
[240, 159, 135, 184, 240, 159, 135, 186]
>>> # ^^^^^^^^^^^^^^---Code point for 🇸
>>> # ^^^^^^^^^^^^^^^^^^---Code point for 🇺
进入全屏模式 退出全屏模式
整数的顺序没有颠倒!相反,代表🇺和🇸的Unicode代码点的四个整数组被交换。每个代码点中整数的顺序保持不变。
这一切意味着什么?
这篇文章的标题是骗人的!您_可以_ 反转带有标志表情符号的字符串。但是由多个码位组成的反转符号可能会产生令人惊讶的结果。特别是如果您以前从未听说过字符编码和代码点之类的东西。
为什么这很重要?
从这项调查中可以吸取一些重要的教训。
首先,如果您不知道使用哪种字符编码对某些文本进行编码,则无法保证解码后的文本准确地代表原始文本。
其次,虽然 UTF-8 被广泛采用,但仍有许多系统使用不同的字符编码。从文件中读取文本时请记住这一点,尤其是在从不同操作系统共享或跨越国际边界时。明确并始终指出正在使用哪种编码对文本进行编码或解码。
例如,Python 的open()函数有一个encoding参数指定在读取或将文本写入文件时使用的字符编码。好好利用它。
你从这里去哪里?
我们已经涵盖了很多领域,但仍有很多问题没有得到解答。因此,写下您仍然有的一些问题,并使用您在本文中看到的调查技术来尝试回答它们。
💡 这篇文章的灵感来自Will McGugan在 Twitter 上提出的问题。查看 Will 的线程了解一大堆字符编码的疯狂。
以下是您可能想探讨的一些问题:
-
当你将
”🏴”转换为一个列表时,你最终会得到一堆以”\U”开头的字符串。这些字符串是什么,它们代表什么? -
”🏴”的 UTF-8 编码包含高达 28 个字节的信息。 🏴udb40udc67udb40udc62udb40udc73udb40udc63udb40udc74udb40udc7f与🇺🇸有何不同?还有哪些其他标志被编码为 28 字节? -
是否有任何标志表情符号被编码为单个代码点?
-
很多平台都支持彩色表情,比如可以用不同肤色渲染的竖起大拇指表情。不同颜色的相同符号如何编码?
-
如何检查包含表情符号的字符串是否为回文?
谢谢阅读!保持好奇!
加入我的免费每周通讯“对代码好奇”每周五在您的收件箱中获取引起好奇心的内容。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)