How to Scrape Stock Market Data in Python [Practical Guide, Plus Code]dependencieslist of URLsstarting our CSV filelooping through our list
本文最初发表于ScraperAPI
无论您是跟踪投资组合的投资者,还是寻求更有效地保持最新状态的投资公司,创建脚本来抓取股市数据都可以节省您的时间和精力。
在本教程中,我们将构建一个脚本来跟踪多个股票价格,将它们组织成一个易于阅读的 CSV 文件,只需按一下按钮即可自行更新,并在几秒钟内收集数百个数据点。
用请求和美丽的汤构建股市刮板
在本练习中,我们将抓取investing.com 以提取Microsoft、可口可乐和耐克的最新股票价格,并将其存储在CSV 文件中。我们还将向您展示如何使用 ScraperAPI 保护您的机器人免受反抓取机制和技术的阻止。
注意:即使没有 ScraperAPI,该脚本也可以抓取股票市场数据,但对于以后扩展您的项目至关重要。
尽管我们将引导您完成该过程的每一步,但事先了解 Beautiful Soup 库是有帮助的。如果您对这个库完全陌生,请查看我们为初学者准备的精美汤教程。它包含提示和技巧,并涵盖了您需要了解的基本知识以刮取几乎任何东西。
有了这个,让我们跳到代码中,这样你就可以学习如何抓取股市数据。
1\。设置我们的项目
首先,我们将创建一个名为“scraper-stock-project”的文件夹,然后从 VScode 中打开它(您可以使用任何您喜欢的文本编辑器)。接下来,我们将打开一个新终端并为此项目安装两个主要依赖项:
pip3 安装 bs4
pip3 安装请求
之后,我们将创建一个名为“stockData-scraper.py”的新文件并将我们的依赖项导入其中。
导入请求
从 bs4 导入 BeautifulSoup
使用 Requests,我们将能够发送 HTTP 请求以下载 HTML 文件,然后将其传递给 BeautifulSoup 进行解析。所以让我们通过向耐克的股票页面发送请求来测试它:
网址u003d'https://www.investing.com/equities/nike'
page u003d requests.get(url)
打印(page.status_code)
通过打印页面变量的状态码(这是我们的请求),我们可以确定是否可以抓取页面。我们正在寻找的代码是 200,这意味着它是一个成功的请求。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--P2kZmu3---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/i2z18uufiopgr280zf6f.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--P2kZmu3---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/i2z18uufiopgr280zf6f.png)
成功!在继续之前,我们将存储在 page 中的响应传递给 Beautiful Soup 进行解析:
汤 u003d BeautifulSoup(page.text, 'html.parser')
你可以使用任何你想要的解析器,但我们使用 html.parser 因为它是我们喜欢的。
相关资源:什么是 Web Scraping 中的数据解析? [里面的代码片段]
2\。检查网站的 HTML 结构 (Investing.com)
在开始抓取之前,让我们在浏览器中打开https://www.investing.com/equities/nike以更加熟悉该网站。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--TssEdoid--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/wlonf4czvwyn6n3lq7n2.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--TssEdoid--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/wlonf4czvwyn6n3lq7n2.png)
正如您在上面的屏幕截图中看到的那样,该页面显示了公司名称、股票代码、价格和价格变化。至此,我们要回答三个问题:
数据是用 JavaScript 注入的吗?
我们可以使用什么属性来选择元素?
这些属性在所有页面中是否一致?
检查 JavaScript
有几种方法可以验证某个脚本是否正在注入一条数据,但最简单的方法是右键单击“查看页面源”。
[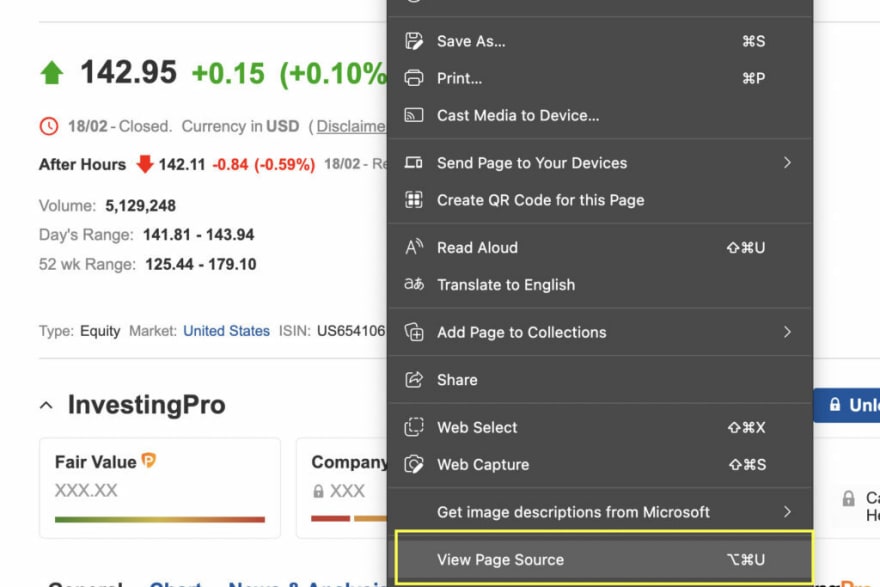 ](https://res.cloudinary.com/practicaldev/image/fetch/s--jyw1kfRG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jvyh1ux7mwpev1jzls7j.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--jyw1kfRG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jvyh1ux7mwpev1jzls7j.jpg)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--PsA7hLDI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/fhllwtf8sfsz80g660k3.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--PsA7hLDI--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/fhllwtf8sfsz80g660k3.jpg)
看起来没有任何 JavaScript 可能会干扰我们的爬虫。接下来,我们将对其余信息执行相同的操作。我们没有发现任何其他我们可以使用的 JavaScript。
注意:检查 JavaScript 很重要,因为请求不能执行 JavaScript 或与网站交互,所以如果信息在脚本后面,我们将不得不使用其他工具来提取它,比如 Selenium。
选择 CSS 选择器
现在让我们检查网站的 HTML 以确定我们可以用来选择元素的属性。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--w0ewmN32--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/14dv6lzz7wxi5fw4hxmm.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--w0ewmN32--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/14dv6lzz7wxi5fw4hxmm.png)
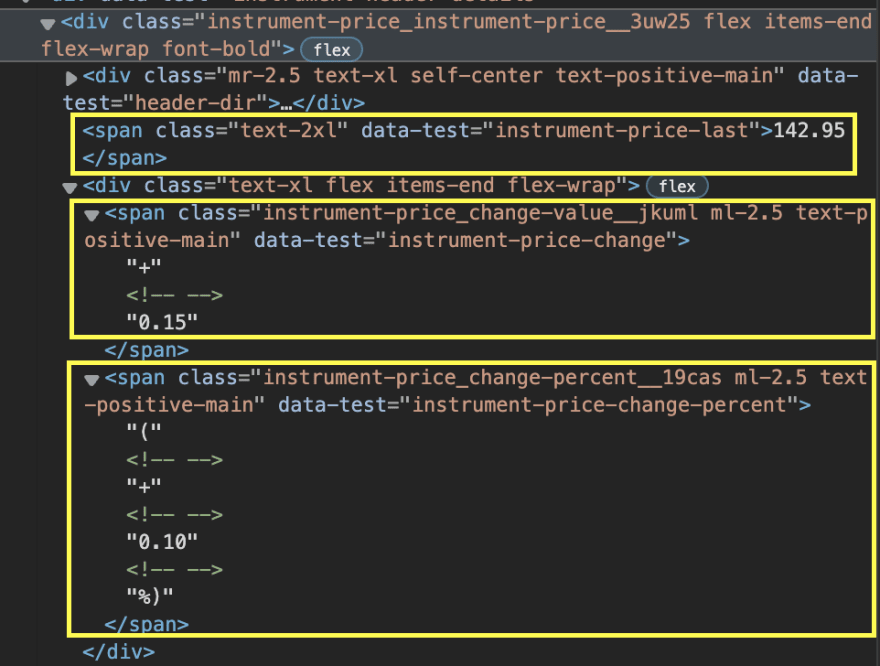
提取公司名称和股票代码将是一件轻而易举的事。我们只需要使用类‘text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2’来定位H1标签。
但是,价格、价格变化和百分比变化被分成不同的跨度。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--HRfXyTKQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/9a3b6n4vg20uy42mxmab.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HRfXyTKQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/9a3b6n4vg20uy42mxmab.png)
更重要的是,根据变化是正还是负,元素的类会发生变化,所以即使我们使用它们的类属性选择每个跨度,仍然会有它不起作用的实例。
好消息是,我们有一个小窍门可以把它弄出来。因为 Beautiful Soup 返回一个解析树,我们现在可以导航树并选择我们想要的元素,即使我们没有确切的 CSS 类。
在这种情况下,我们要做的是在层次结构中向上并找到一个我们可以利用的父 div。然后我们可以使用 find_all(‘span’) 来制作包含 span 标签的所有元素的列表——我们知道我们的目标数据使用它。而且因为它是一个列表,我们现在可以轻松地浏览它并选择我们需要的那些。
所以这是我们的目标:
company u003d soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [0].文本
change u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [2].文本
现在进行测试运行:
print('加载中:', url)
打印(公司,价格,变化)
结果如下:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--hHUlp37V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/cms3fxmu16y8qvvmk2jt.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--hHUlp37V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/cms3fxmu16y8qvvmk2jt.png)
3\。刮掉多只股票
现在我们的解析器正在工作,让我们扩大规模并抓取几只股票。毕竟,只跟踪一个股票数据的脚本可能不会很有用。
我们可以通过创建 URL 列表并遍历它们以输出数据,使我们的爬虫解析和爬取多个页面。
网址 u003d [
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
]
对于网址中的网址:
page u003d requests.get(url)
汤 u003d BeautifulSoup(page.text, 'html.parser')
company u003d soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [0].文本
change u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [2].文本
print('加载中:', url)
打印(公司,价格,变化)
这是运行后的结果:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_CCOd8hq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/ag4iy8jdcpxs23j5jiwb.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_CCOd8hq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/ag4iy8jdcpxs23j5jiwb.png)
太棒了,它适用于所有领域!
我们可以继续向列表中添加越来越多的页面,但最终,我们会遇到一个很大的障碍:反抓取技术。
4\。集成 ScraperAPI 以处理 IP 轮换和验证码
并非每个网站都喜欢被抓取,这是有充分理由的。在抓取网站时,我们需要记住我们正在向它发送流量,如果我们不小心,我们可能会限制网站对真实访问者的带宽,甚至会增加所有者的托管成本。也就是说,只要我们尊重网络抓取最佳实践,我们的项目就不会有任何问题,也不会导致我们正在抓取的网站出现任何问题。
然而,企业很难区分道德爬虫和那些会破坏他们网站的爬虫。因此,大多数服务器将配备不同的系统,例如
浏览器行为分析
验证码
监控一段时间内来自某个IP地址的请求数
这些措施旨在识别机器人,并在数天、数周甚至永远阻止它们访问网站。
我们不需要单独处理所有这些场景,而是只需添加两行代码,让我们的请求通过 ScraperAPI 的服务器并为我们自动完成所有操作。
首先,让我们创建一个免费的 ScraperAPI 帐户来访问我们的 API 密钥和我们项目的 5000 个免费 API 积分。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--rgCe10vU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/d51st6d1j1wjonhbqfl3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--rgCe10vU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/d51st6d1j1wjonhbqfl3.png)
现在我们准备在循环中添加一个新的 params 变量来存储我们的键和目标 URL,并使用 urlencode 来构造我们将用来在 page 变量中发送请求的 URL。
参数 u003d {'api_key': '51e43be283e4db2a5afb62660xxxxxxx', 'url': url}
page u003d requests.get('http://api.scraperapi.com/', paramsu003durlencode(params))
哦!我们不能忘记将我们的新依赖添加到文件的顶部:
从 urllib.parse 导入 urlencode
现在每个请求都将通过 ScraperAPI 发送,它会在每个请求后自动轮换我们的 IP,处理 CAPCHA,并使用机器学习和统计分析来设置最佳标头以确保成功。
快速提示:ScraperAPI 还允许我们通过在 params 变量中设置 ‘render’: true 作为参数来抓取动态站点。 ScraperAPI 将在发回响应之前呈现页面。
5\。将数据存储在 CSV 文件中
Tos 将您的数据撕成一个易于使用的 CSV 文件,只需在 URL 列表和循环之间添加以下三行:
文件 u003d open('stockprices.csv', 'w')
writer u003d csv.writer(文件)
writer.writerow(['公司', '价格', '变化'])u003d
这将创建一个新的 CSV 文件并将其传递给我们的 writer(在 writer 变量中设置)以添加第一行和我们的标题。
必须将其添加到循环之外,否则它将在抓取每一页后重写文件,基本上会擦除以前的数据并给我们一个 CSV 文件,其中仅包含列表中最后一个 URL 中的数据。
此外,我们需要在循环中添加另一行来写入抓取的数据:
writer.writerow([company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')])
还有一个在循环之外关闭文件:
文件.close()
6\。完成的代码:股市数据脚本
你成功了!您现在可以将此脚本与您自己的 API 密钥一起使用,并添加任意数量的股票:
依赖关系
导入请求
从 bs4 导入 BeautifulSoup
导入 csv
从 urllib.parse 导入 urlencode
网址列表
网址 u003d [
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
]
开始我们的 CSV 文件
文件 u003d open('stockprices.csv', 'w')
writer u003d csv.writer(文件)
writer.writerow(['公司', '价格', '变化'])
循环遍历我们的列表
对于网址中的网址:
#通过 ScraperAPI 发送我们的请求
参数 u003d {'api_key': '51e43be283e4db2a5afb62660fc6ee44', 'url': url}
page u003d requests.get('http://api.scraperapi.com/', paramsu003durlencode(params))
#我们的解析器
汤 u003d BeautifulSoup(page.text, 'html.parser')
company u003d soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [0].文本
change u003d soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')\ [2].文本
#printing 以获得一些视觉反馈
print('加载中:', url)
打印(公司,价格,变化)
#将数据写入我们的CSV文件
writer.writerow([company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')])
文件.close()
总结:运行股市数据刮板时的注意事项
你需要记住,股票市场并不总是开放的。例如,如果你从纽约证券交易所抓取数据,它会在美国东部标准时间周五下午 5 点关闭,周一上午 9:30 开市。所以在周末运行你的刮刀是没有意义的。它也在下午 4 点关闭,这样您之后就不会看到价格的任何变化。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_bFYNNHd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/vcbfluomhzj0rkiyazq5.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_bFYNNHd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/vcbfluomhzj0rkiyazq5.jpg)
要记住的另一个变量是您需要多久更新一次数据。证券交易所最波动的时间是开盘和收盘时间。因此,在上午 9 点 30 分、上午 11 点和下午 4 点 30 分运行您的脚本可能就足以了解股票的收盘情况。周一的开盘对于监控也是至关重要的,因为在此期间发生了许多交易。
与外汇等其他市场不同,股市通常不会出现太多疯狂的波动。也就是说,新闻和商业决策通常会严重影响股价——以 Meta 股票崩盘或 GameStop 股价上涨为例——因此阅读与你正在抓取的股票相关的新闻至关重要。
我们希望本教程可以帮助您构建自己的股市数据抓取工具,或者至少为您指明正确的方向。在未来的教程中,我们将在这个项目的基础上创建一个实时股票数据抓取工具来监控您的股票,敬请期待!

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)