用 Python 和机器学习检测假新闻
技术的进步减少了我们对从日报获取最新消息的依赖。 Youtube 和 Twitter 等热门网站为我们获取最新消息提供了便利。但是,来自这些网站的消息的可信度如何?
假新闻模仿真实的头条新闻,并被故意传播以进行恶作剧并在人群中传播宣传。营销人员还将其用作点击诱饵,以吸引他们网站的浏览者。
为了解决各个网站上新闻的可信度问题,我们将开发一个假新闻检测模型。机器学习算法将帮助我们实现这一目标。我们专门使用被动攻击算法。
工作流程
下图显示了创建模型的不同阶段,包括将文本数据转换为数字数据、训练模型和测试模型。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--E5zJtXP4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/e7j1vrohmovwi7x8yfyd.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--E5zJtXP4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/e7j1vrohmovwi7x8yfyd.png)
1\。导入模块
第一步是导入运行我们的项目所需的库。使用的库是 numpy、pandas、sklearn 和 seaborn。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
进入全屏模式 退出全屏模式
2\。加载数据
接下来,我们将新闻 csv 文件中的数据读入 Pandas DataFrame。这是使用pd.read('filename.csv')函数完成的。确保 csv 文件与 Python 代码位于同一文件夹中。
.shape函数用于输出数据集的大小。
.head()函数输出数据集中的前五条记录。
news_data=pd.read_csv("news.csv")
news_data.shape
news_data.head()
进入全屏模式 退出全屏模式
(6335, 4)
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--3e-_mrzh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/63d5bumh32muclv5xvwl.PNG)
](https://res.cloudinary.com/practicaldev/image/fetch/s--3e-_mrzh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/63d5bumh32muclv5xvwl.PNG)
3\。数据预处理
我们需要检查数据中的空条目。isnull()函数为我们执行此操作,并在.sum()函数的帮助下为我们提供了空条目的总数
news_data.isnull().sum()
进入全屏模式 退出全屏模式
Unnamed: 0 0
title 0
text 0
label 0
dtype: int64
进入全屏模式 退出全屏模式
然后我们提取标签列,因为那是带有真实或虚假标签的列。
labels=news_data.label
进入全屏模式 退出全屏模式
4\。拆分数据集以训练和测试数据
这是机器学习中最重要的一步。我们的模型使用训练数据集进行训练,并使用测试数据集进行测试。 Scikit learn 中的 train_test_split 函数将帮助我们拆分数据。分割将是训练集的 80% 数据和测试集的剩余 20% 数据。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(news_data['text'], labels, test_size=0.2, random_state=7)
进入全屏模式 退出全屏模式
5\。初始化 TF-IDF 矢量化器
TF-IDF 表示词频 - 逆文档频率。
TfidfVectorizer()是 Scikit learn 中的一个函数,用于将文本数组转换为 TF-IDF 矩阵。
- 词频 - 一个词在文本中出现的次数除以文档中的总词数。
[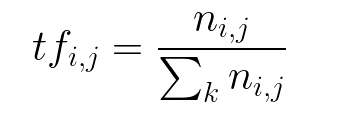 ](https://res.cloudinary.com/practicaldev/image/fetch/s--3HJVfgfK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/y26h78x9rugbkhb9go9p.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--3HJVfgfK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/y26h78x9rugbkhb9go9p.png)
- 逆文档频率 - 它衡量一个术语在整个数据中的重要性。它由语料库中所有文档中稀有词的权重决定。
[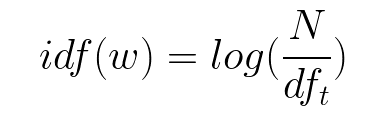 ](https://res.cloudinary.com/practicaldev/image/fetch/s--xRwxW0cu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/27xukxexofb5nme7r72m.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--xRwxW0cu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/27xukxexofb5nme7r72m.png)
N 是文档数,df 是包含单词 w 的文档数。
TF-IDF Vectorizer 公式:
[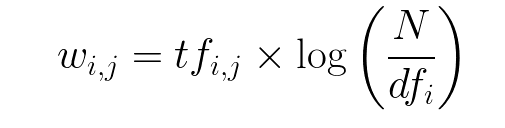 ](https://res.cloudinary.com/practicaldev/image/fetch/s--hDenp1_O--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/uploads/articles/myy9zutysxiuxfx41wgt.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--hDenp1_O--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/uploads/articles/myy9zutysxiuxfx41wgt.png)
tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=1.0)
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
tfidf_test=tfidf_vectorizer.transform(x_test)
进入全屏模式 退出全屏模式
使用英语中的停用词和最大文档频率 1.0 初始化 TfidfVectorizer。
在训练集上拟合和变换向量器,在测试集上变换向量器。
6\。使用训练集训练模型
让我们使用 Passive-Aggressive 算法训练假新闻检测模型,并检查训练模型的准确度得分。
Passive-Aggressive 算法是一种在线学习算法,用于涉及大量数据并且由于其大小而在计算上无法训练整个数据集的情况。该算法对正确的预测保持被动,并对不正确的预测做出积极响应。
初始化一个被动-积极分类器
pac=PassiveAggressiveClassifier(max_iter=20)
pac.fit(tfidf_train,y_train)
进入全屏模式 退出全屏模式
7\。测试训练好的模型
我们使用 20% 的测试数据通过准确度得分和混淆矩阵来测试我们训练的模型的效率。
检查准确度分数
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print("Accuracy: ",round(score*100,2),"%")
进入全屏模式 退出全屏模式
Accuracy: 93.45 %
进入全屏模式 退出全屏模式
经过训练的算法产生 93.45 % 的准确率
8\。构建混淆矩阵
混淆矩阵是分类模型在测试数据上性能的二维数组,将预测的类别标签与真实标签进行比较。二元分类包括;真阳性、真阴性、假阳性和假阴性。
该矩阵可以从 Scikit learn 计算如下:
from sklearn.metrics import confusion_matrix
cf_matrix = confusion_matrix(y_test,y_pred)
print(cf_matrix)
进入全屏模式 退出全屏模式
[[573 42]
[ 38 614]]
进入全屏模式 退出全屏模式
我们有 573 个真阳性、38 个真阴性、42 个假阳性和 614 个假阴性。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)