
Delta Compression:diff 算法和 delta 文件格式的实用指南
diff 算法输出两个输入之间的差异集。这些算法是许多常用开发工具的基础。然而,使用上述工具很少需要了解差异算法的内部工作原理。 Git 是一个示例,开发人员无需了解底层 diff 算法就可以读取、提交、提取和合并差异。话虽如此,整个开发人员社区对该主题的了解非常有限。
本文的目的不是详细介绍Ably如何在其分布式发布/订阅消息传递平台上以编程方式实现差异算法,而是分享我们的研究并提供有关差异算法主题的系统知识对 diff/delta/patch 功能的实现者很有用。
快速了解一下上下文
对于像 Tennis Australia 或 HubSpot 这样的 Ably 客户,Message Delta Compression通过仅发送消息的差异来减少传输实时消息所需的带宽。这意味着订阅者只接收自上次更新以来的更改,而不是整个流。发送更少的比特可以提高带宽效率,并为我们的客户降低总体成本和延迟。为了开发这个特性,我们需要实现一个支持二进制编码并且在生成增量时不牺牲延迟的差异算法。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--66rloYUe--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files.ably。 io/ghost/prod/2020/06/delta-savings-1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--66rloYUe--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files.ably。 io/ghost/prod/2020/06/delta-savings-1.png)
差异算法
用途及用途
diff 算法的输出称为 patch 或 delta。增量格式可能是人类可读的(文本)或只有机器可读的(二进制)。人类可读格式通常用于跟踪和协调对人类可读文本(如源代码)的更改。二进制格式通常经过空间优化和使用以节省带宽。它仅将一组更改传输到接收者已经可用的旧版本数据,而不是传输所有新数据。这方面的正式术语是_delta encoding_。
二进制VS文本?
似乎有一个普遍的误解,即差异算法是根据输入类型专门化的。事实是,diff 算法是杂食性的,可以处理任何输入,只要输入可以简单地被视为字节字符串。该字符串可能由英文字母或不透明的二进制数据组成。给定相同字母表中的两个输入字符串,任何差异算法都会生成正确的增量。
处理二进制数据需要不同算法的误解源于常用的差异/合并工具将文本和二进制视为实际上不同。这些工具通常旨在提供人类可读的增量,因此专注于人类可读的输入而不是二进制数据。假设是二进制数据不是人类可读的,因此两个二进制数据输入之间的增量也将不是人类可读的,因此将其呈现为人类可读被认为是太多的努力。在二进制差异的情况下,平等是唯一相关的输出,因此,简单的逐位比较被认为是最快和最合适的解决方案。通过解决方案的效率对算法进行分类导致将输入划分为不同的类型。
另一个增加混淆的方面是差异/合并工具产生的文本差异输出的基于行、基于词和基于字符的分类。被描述为“基于行”的 diff 算法给人的印象是它产生“纯文本”输出,这意味着它只接受文本输入而不接受二进制数据输入。但是,基于行/单词/字符并不是 diff 算法本身的特征;相反,它是在将输入馈送到实际差异算法之前应用于输入的优化。
因为新行和空格作为人类可读文本中的分隔符具有意义,所以 diff 工具可以根据文本中行或单词的哈希值对字符串进行分段。此哈希字符串比原始文本短得多,因此以降低差异粒度为代价节省时间。此外,在某些情况下,基于行的粒度实际上甚至可能增加人类对差异的可读性。
但是,如果已知输入是不透明的二进制数据,则没有有意义的分隔符或人类可读的差异可显示,因此无法应用此优化。因此,能够在人类可读数据成为输入之前对其进行优化的算法很容易被误认为完全无法处理二进制数据。然而,事实仍然存在:除了预处理优化之外,二进制和人类可读的数据都可以被视为字节字符串输入并易于处理。
三代diff算法
应该如何生成差异的概念随着时间的推移而演变。
[![]() ](https://res.cloudinary.com/practicaldev/image/fetch/s--69eZKlHq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files.ably。 io/ghost/prod/2020/06/delta-arrow-1.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--69eZKlHq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files.ably。 io/ghost/prod/2020/06/delta-arrow-1.jpg)
字符串到字符串更正或插入/删除
第一代 diff 算法解决了字符串到字符串的校正问题出现在 60 和 70 年代。两个输入中的每一个都被解释为由某些字母表中的字符组成的字符串。输出是一系列字符编辑,最常见的是插入/删除操作,可应用于其中一个输入以将其转换为另一个输入。这使得这类算法特别适合在人类可读输入上生成人类可读差异,例如由于随着时间的推移进行的实际编辑而产生的相同文本/源代码的不同版本。更有帮助的是,在理论上,而且在实践中,通常有不止一个最小长度的编辑操作序列可以完成工作。可以使用各种启发式方法来选择最接近于实际人工编辑的编辑序列。
Wagner-Fischer 算法奠定了这一代 diff 算法的基础。Myers 算法是最新的改进和生成的事实上的标准,目前用于包括 GNU diff 实用程序在内的多个 diff 工具。
这一代算法通常找到最长公共子序列或最小编辑距离(通常是Levenshtein 距离),并使用这些生成将一个输入转换为所需的编辑序列其他。
块移动或复制/插入
纯块移动
下一代 diff 算法基于上一代看似小的优化。字符编辑升级为字符块编辑。 IE。差异不是将差异表示为对单个字符的操作,而是将差异表示为对字符块的操作。这些操作通常是复制和插入,其中出现在两个输入中的数据块被记录在增量中,就像从一个输入复制到另一个输入一样。其中一个输入所特有的块被记录为插入。这种方法首先由Walter Tichy提出。
基于压缩的块移动
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--mP45hM-u--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files。 ably.io/ghost/prod/2020/06/delta-messages-5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mP45hM-u--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://files。 ably.io/ghost/prod/2020/06/delta-messages-5.png)
Ably 如何使用块移动方法在其发布/订阅消息传递平台中生成增量
最初,块移动方法似乎是一个小的优化。但是,一旦考虑到某些字符块在某些或两个输入中重复的可能性,它就会产生普遍的后果。从复制数据块的角度考虑差异生成,并留意同一块重复多次,这为使用压缩算法生成差异和增量文件打开了大门。
压缩算法就是这样做的:找到最大可能的重复数据块,并将每个连续出现的数据替换为对第一次出现的引用。从不重复的数据块直接复制到输出。因此,实际上,压缩算法是块移动算法。
很明显,如果在 diff 算法的两个输入上都执行压缩算法完成的块移动分析,它将很容易识别两个输入的公共部分。它还将指出哪些数据块是唯一的,即在两个输入中都不同。有了这些数据,就可以直接提出一系列块复制/删除操作,将一个输入转换为另一个输入。
使用压缩算法的主要好处是大大减小了 delta 的大小。一个数据块永远不会在增量中出现多次。它可能会被多次引用,但块的实际数据只会包含在增量中一次。这是与前述方法的主要区别。还应该提到的是,增量大小的减小是以降低人类可读性为代价的。
xDelta、zDelta、Bentley/McIlroy 是这一代差异算法的广泛使用的事实上的标准实现。
最新升级
这将是最新一代的差异算法。它的大多数成员只存在于研究论文中,目前还没有商业实现。它们主要基于块移动方法,但提供了大量的实施优化,这导致声称比上一代速度提高了两位数。
这些优化主要集中在有效地在两个输入中找到匹配的数据块。各种增量散列或类似压缩的技术(例如后缀树)用于实现此目的。
edelta、ddelta、bsdiff 可以分配给这一代的 diff 算法。
当前使用的增量生成算法
这是对专注于高效 delta/patch 文件生成的工具和库的简短概述,在撰写本文时可用。存在不同语言的通用差异算法的各种实现,此处未提及。
尽管我们没有遇到流行工具或库的可能性相对较小,但并未声明完整性。毕竟,流行的东西按定义应该很容易遇到。
Myers 算法 - 人类可读的差异
Myers 算法属于字符串校正系列,并被广泛用于从人类可读输入生成人类可读增量/补丁文件的工具。毫不奇怪,Git Diff 和 GNU Diff 等工具都使用它。
原始 Myers 时间和空间复杂度为 O(ND),其中 N 是两个输入的长度之和,D 是将一个输入转换为另一个输入的最小编辑脚本的大小。显然,当有一些差异时,就像编辑相同的代码/文本文件一样,算法很快。可以并且已经对原始 Myers 算法进行了各种优化,从而改进了高达 O(NlgN + D^2) 的时间和 O(N) 的空间。
宾利-麦克罗伊
Bentley-McIlroy算法属于块移动系列,专注于生成最佳大小的增量/补丁文件。它在不同的平台和语言上有各种实现,因此对于增量大小很重要的场景,它可以被认为是一个事实上的标准。 Google 的Open VCDiff是 Bentley-McIlroy 最突出的用途之一,它能够生成 VCDiff 格式的增量/补丁。
Bentley-McIlroy 算法的时间复杂度为 O(sqrt(N)*N),尽管作者声称平均情况下的线性复杂度。内存复杂度是线性的。
X台达
XDelta(论文的PDF)算法属于块移动家族,专注于 delta 生成的速度。该算法牺牲了增量大小以提高速度。xdeltadelta生成工具是XDelta最突出的用法,它还能够生成VCDiff格式的delta/patch。
XDelta 算法具有线性时间和空间复杂度。
BSDiff
BSDiff算法属于块移动系列,专注于实现最小增量/补丁大小。它还专门针对可执行文件进行了优化。bsdiff 工具是 BSDiff 算法最突出的用法。 bsdiff 工具使用它自己的自定义增量/补丁文件格式。
BSDiff 时间复杂度为 O((n+m)log(n)),其中 n 和 m 是两个输入的大小。它的内存复杂度最大 (17n,9n+m)+O(1)。
增量文件格式
标准是好事。标准的真正好处是通常有很多可供选择。然而,就增量/补丁文件而言,问题更多的是缺乏标准而不是标准的丰富。过多的差异工具和库以自己的自定义格式生成增量/补丁文件,因此只有补丁的生产者才能应用它。
在这种情况下,历史上出现了两种主要的 delta/patch 格式标准化尝试。
Unix .patch
这是 GNU diff 工具生成的一系列 delta/patch 格式,旨在提高人类可读性。 GNU diff 工具已经存在了很长时间,因此这些补丁格式被各种文本处理工具和源代码控制系统广泛接受/使用,无论是否修改。
VCDiff
VCDiff是创建与数据无关和算法无关的增量/补丁格式的最突出尝试,旨在提高应用程序的紧凑性和速度。 VCDiff 在 Google 的SDCH(HTTP 共享字典压缩)工作中获得了相当大的采用。如今,许多 diff 算法实现都能够生成 VCDiff 格式的 delta/patch 文件。大多数流行语言和平台都存在各种成熟状态的 VCDiff delta 应用程序库。
VCDiff 术语消歧 - 补丁格式与算法
在RFC3284中,术语 VCDiff 用于命名 delta/patch 文件格式和 diff 算法。此外,名为 VCDiff 的 diff 算法是专有的。许多研究论文也测试或参考了 VCDiff 算法。虽然该名称的专有差异算法确实存在,但 VCDiff 也是与算法无关的增量/补丁文件格式的名称。 IE。这里的任何算法都可以生成 VCDiff 格式的增量文件。
测试 open-vcdiff 和 xdelta
我们选择 Google open-vcdiff 和 xDelta 算法进行测试,因为它们成熟,使用更先进的块移动方法,生成小尺寸 delta/patch 文件,并且不是基于行的,而是直接应用于不透明的二进制文件。
更重要的是,它们都能够以相对通用和开放的 VCDiff 格式生成 delta/patch 文件。采用开放格式意味着我们可以修复任何错误和/或在必要时实现解码器。作为一家公司,Ably 还提倡开放标准,因此我们尽可能在自己的堆栈中采用它们很重要。
最后但同样重要的是,它们都是开源的,可以构建为库并合并到各种应用程序中。实际上,有多种实现压缩算法的选择,可以在一组很好的语言中使用,用于构建解码器。
这些测试远未完成或具有统计学意义。它们旨在让您真正了解这些算法在该领域的表现。
测试设置
测试是使用撰写本文时(2019 年 6 月)在 GitHub 上找到的算法的最新官方实现完成的。
这两种算法都暴露了大量的调整和设置,比如内存窗口大小,这些都会极大地影响它们的性能。已刻意努力在相同的设置下运行两者,但可能会出现错误。
测试使用xDelta CLI。
测试结果:循环执行3分钟以上的平均时间
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--YZXdUKPA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.us-东 1.amazonaws.com/files.ably.io/newsletter/table1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--YZXdUKPA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.us-东 1.amazonaws.com/files.ably.io/newsletter/table1.png)
以上是哪里:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--EKO0gevl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table2.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--EKO0gevl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table2.png)
Delta尺寸比较
[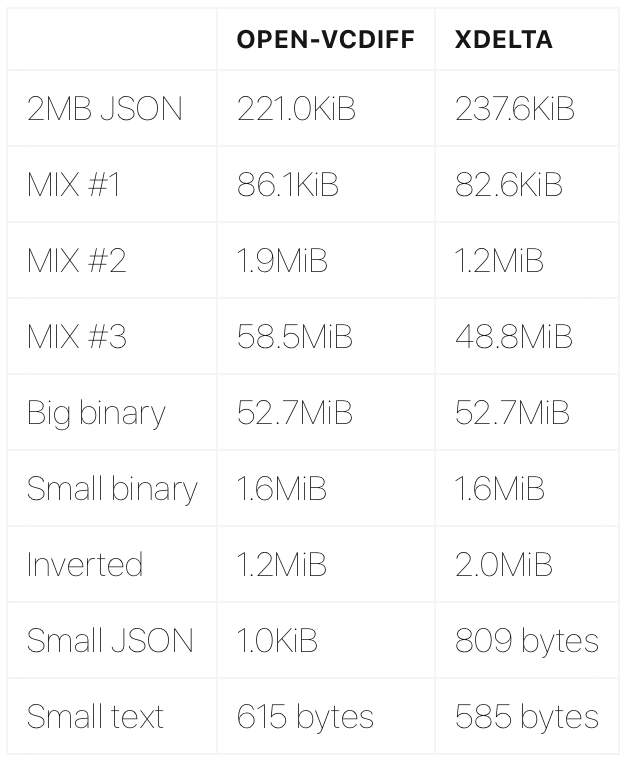 ](https://res.cloudinary.com/practicaldev/image/fetch/s--U3bKfibR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--U3bKfibR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table3.png)
最后,我们在 Ably 选择了 xDelta,主要是因为该算法在 O(n) 复杂度的本机代码中实现了高质量的实现。也就是说,在最坏的情况下,Ably 会丢弃比原始消息更大的增量,但我们不会浪费太多时间来生成此增量。这有助于我们轻松地在通过生成增量节省的带宽和生成所述增量所需的 CPU 成本之间进行权衡。
xDelta 和 VCDIFF 在 Ably
这是美国的中转来源。如果您碰巧在没有公共汽车运行的时间阅读这篇文章 - 例如欧洲的清晨 - 您将看不到任何数据。查看原始帖子以了解此操作。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--JeFFiQeu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JeFFiQeu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://s3.amazonaws。 com/files.ably.io/newsletter/table4.png)
希望这篇文章可以为您节省我研究所有这些信息所花费的时间和精力,并在一个地方为任何希望实现 diff/delta/patch 功能的人提供所需的知识。
关于Abl
Ably 是一个实时消息传递平台。我们每天通过网络、移动和物联网平台向超过 5000 万最终用户提供数十亿条实时消息。
开发人员使用 Ably 通过我们的多协议发布/订阅消息(包括消息delta 压缩)、存在和[推送通知]02220(https://ably.com/push-notifications)101 免费流数据源,在他们的应用程序中构建实时功能(https://ably.com/hub)来自运输和金融等行业,集成将 Ably 扩展到第三方云和 AWS Kinesis 和 RabbitMQ 等系统。
企业和开发人员都选择在 Ably 上进行构建,因为我们提供了唯一一个围绕可靠性四大支柱构建的实时平台:性能、高可用性、可靠性和数据完整性。这使我们的客户能够专注于他们的代码和数据流,同时我们提供无与伦比的服务质量、容错性和可扩展性。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献27131条内容
已为社区贡献27131条内容

所有评论(0)