
起飞了 ! 使用 DuckDB 的处理11 亿出租车出行数据
如果您想知道为什么我不运行基于 Linux 的桌面作为我的主要工作环境,我仍在使用 Nvidia GTX 1080 GPU,它在 Windows 上有更好的驱动程序支持,并且我时不时地使用 ArcGIS Pro仅原生支持 Windows。SSD 的写入速度为 50-150 MB/s,读取速度通常为 5-10 MB/s,而 CPU 几乎处于空闲状态,为 5-10%。因此,我将在更快的驱动器上运行基准
使用 DuckDB 的处理11 亿出租车出行数据
DuckDB 是一个进程内数据库。它不依赖于自己的服务器,而是用作客户端。客户端可以使用内存中的数据、DuckDB 的内部文件格式、其他软件开发商的数据库服务器以及 AWS S3 等云存储服务。
这种不将 DuckDB 的数据集中在其自己的服务器中的选择,再加上作为单个二进制文件进行分发,使得安装和使用 DuckDB 比建立 Hadoop 集群要简单得多。
该项目并不针对非常大的数据集。尽管如此,它的工效还是足够吸引人的,而且它在很大程度上减少了工程时间,因此是值得考虑解决方法。分析就绪、云优化的 Parquet 文件日益普及,在处理数百 GB 或更大的数据集时,不再需要大量硬件。
DuckDB 主要是 Mark Raasveldt 和 Hannes Mühleisen 的作品。它由一百万行 C++ 代码组成,并作为独立的二进制文件运行。开发非常活跃,自 2018 年开始以来,其 GitHub 存储库的提交数量几乎每年都翻倍。DuckDB 使用 PostgreSQL 的 SQL 解析器、Google 的 RE2 正则表达式引擎和 SQLite 的 shell。
SQLite 支持五种数据类型:NULL、INTEGER、REAL、TEXT 和 BLOB。我总是对此感到沮丧,因为处理 时间类型 需要在每个 SELECT 语句中进行转换,并且无法将字段描述为布尔值意味着分析软件无法自动识别并提供这些字段的特定 UI 控件和可视化。
值得庆幸的是,DuckDB 支持 25 种开箱即用的数据类型,并且可以通过扩展添加更多数据类型。
为 DuckDB 中的每个列段创建一个最小-最大索引。这种索引类型是大多数 OLAP 数据库引擎快速响应聚合查询的方式。 Parquet 和 JSON 扩展在官方版本中提供,并且它们的用法有详细记录。 Parquet 文件支持 Snappy 和 ZStandard 压缩。
DuckDB 的文档组织良好,简洁得令人耳目一新,大多数描述旁边都有examples。
在这篇文章中,我将了解 DuckDB 处理 11 亿次出租车出行基准测试的速度有多快。该数据集由 2009 年至 2015 年间在纽约市进行的 11 亿次出租车行程组成。这是我用来测试 Amazon Athena、BigQuery、BrytlytDB、ClickHouse、Elasticsearch、EMR、Hydrolix、kdb+/q、 MapD / OmniSci / HEAVY.AI、PostgreSQL、Redshift 和 Vertica 的相同数据集。我有一个关于所有这些基准的单页摘要以供比较。

我的工作站
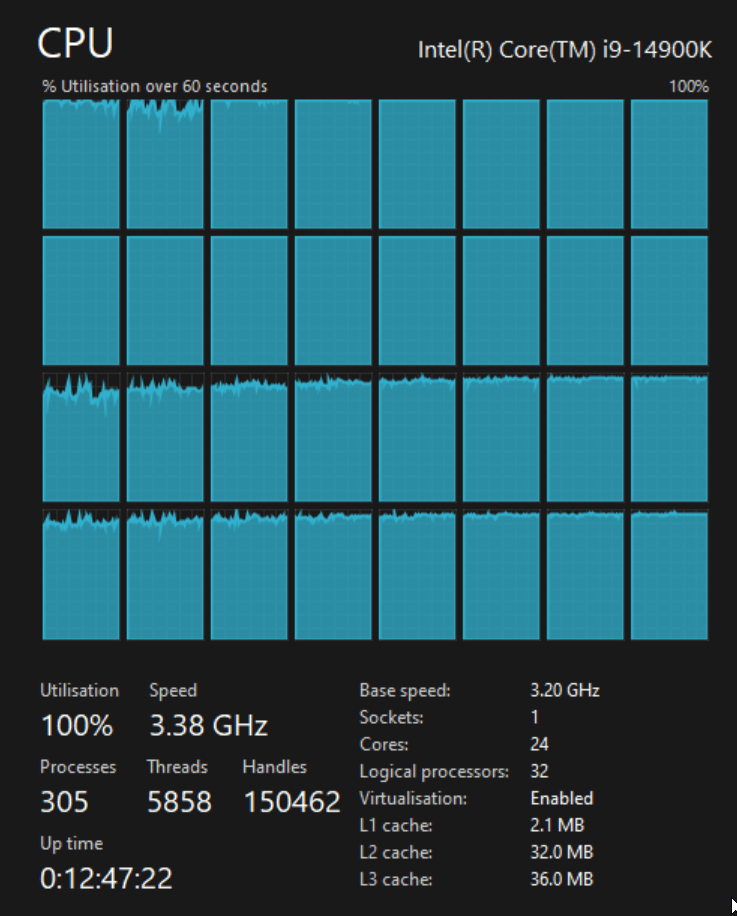
对于此基准测试,我使用 6 GHz Intel Core i9-14900K CPU。它拥有 8 个性能核心和 16 个效率核心,总共 32 个线程和 32 MB 二级缓存。它配有液体冷却器,并安装在宽敞的全尺寸 Cooler Master HAF 700 电脑机箱中。我在 YouTube 上看到过一些视频,人们成功地将 i9-14900K 超频至 9.1 GHz。
该系统配备 48 GB DDR5 RAM,主频为 5,200 MHz,以及第五代 Crucial T700 4 TB NVMe M.2 SSD,读取速度高达 12,400 MB/s。 SSD 上有一个散热器,有助于降低温度。这是我系统的C盘。
还有一个通过 SATA 接口连接的 2 TB SSD,其中包含原始出租车行程数据集。该驱动器的峰值速度约为 5-600 MB/s。这是我系统的D盘。
该系统由 1,200 瓦、完全模块化的 Corsair 电源供电,并安装在华擎 Z790 Pro RS 主板上。
我在 Windows 11 Pro 上通过 Microsoft 的 Ubuntu for Windows 运行 Ubuntu 22 LTS。如果您想知道为什么我不运行基于 Linux 的桌面作为我的主要工作环境,我仍在使用 Nvidia GTX 1080 GPU,它在 Windows 上有更好的驱动程序支持,并且我时不时地使用 ArcGIS Pro仅原生支持 Windows。
启动并运行DuckDB
我将首先安装一些将在本文中使用的依赖项。
$ sudo apt update
$ sudo apt install \
build-essential \
cmake \
pigz \
python3-virtualenv \
zip
然后,我将下载并安装下面的 DuckDB v0.10.0 的官方二进制文件。
$ cd ~
$ wget -c https://github.com/duckdb/duckdb/releases/download/v0.10.0/duckdb_cli-linux-amd64.zip
$ unzip -j duckdb_cli-linux-amd64.zip
$ chmod +x duckdb
$ ~/duckdb
INSTALL parquet;
$ vi ~/.duckdbrc
.timer on
.width 180
LOAD parquet;
将 11 亿次行程数据导入 DuckDB
我将使用的数据集是对纽约市六年来 11 亿次出租车行程生成的数据转储。原始数据集以 56 个 GZIP 压缩的 CSV 文件形式存在,压缩时为 104 GB,解压时需要 500 GB 空间。 Billion Taxi Rides in Redshift博客文章详细介绍了我如何将此数据集放在一起,并更详细地描述了它包含的列。
我将从 SATA 连接的 SSD 上的 /mnt/d/taxi 读取源数据,并在第 5 代 NVMe 驱动器上创建 DuckDB 文件 /mnt/c/taxi/taxi.duckdb 。
$ cd /mnt/d/taxi/
$ vi create.sql
我将提前为数据创建一个表,而不是依赖 DuckDB 的类型推断。这将确保我为每列提供正确的数据类型粒度。
CREATE OR REPLACE TABLE trips (
trip_id BIGINT,
vendor_id VARCHAR,
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR,
rate_code_id BIGINT,
pickup_longitude DOUBLE,
pickup_latitude DOUBLE,
dropoff_longitude DOUBLE,
dropoff_latitude DOUBLE,
passenger_count BIGINT,
trip_distance DOUBLE,
fare_amount DOUBLE,
extra DOUBLE,
mta_tax DOUBLE,
tip_amount DOUBLE,
tolls_amount DOUBLE,
ehail_fee DOUBLE,
improvement_surcharge DOUBLE,
total_amount DOUBLE,
payment_type VARCHAR,
trip_type VARCHAR,
pickup VARCHAR,
dropoff VARCHAR,
cab_type VARCHAR,
precipitation BIGINT,
snow_depth BIGINT,
snowfall BIGINT,
max_temperature BIGINT,
min_temperature BIGINT,
average_wind_speed BIGINT,
pickup_nyct2010_gid BIGINT,
pickup_ctlabel VARCHAR,
pickup_borocode BIGINT,
pickup_boroname VARCHAR,
pickup_ct2010 VARCHAR,
pickup_boroct2010 BIGINT,
pickup_cdeligibil VARCHAR,
pickup_ntacode VARCHAR,
pickup_ntaname VARCHAR,
pickup_puma VARCHAR,
dropoff_nyct2010_gid BIGINT,
dropoff_ctlabel VARCHAR,
dropoff_borocode BIGINT,
dropoff_boroname VARCHAR,
dropoff_ct2010 VARCHAR,
dropoff_boroct2010 VARCHAR,
dropoff_cdeligibil VARCHAR,
dropoff_ntacode VARCHAR,
dropoff_ntaname VARCHAR,
dropoff_puma VARCHAR);
$ ~/duckdb /mnt/c/taxi/taxi.duckdb < create.sql
$ ~/duckdb /mnt/c/taxi/taxi.duckdb
INSERT INTO trips
SELECT *
FROM read_csv('trips_x*.csv.gz');
SATA 驱动器上的读取峰值速度为 60 MB/s,但约为 40 MB/s,写入约为 20 MB/s。 CPU 使用率约为 25%,DuckDB 的 RAM 消耗迅速增长至 22 GB 左右。有一次,我发现我的内存即将耗尽,所以我取消了这项工作。
一次一个 CSV
第二次尝试我将 CSV 导入 DuckDB 的是一次导入一个 CSV 文件。
$ for FILENAME in trips_x*.csv.gz; do
echo $FILENAME
~/duckdb -c "INSERT INTO trips
SELECT *
FROM READ_CSV('$FILENAME');" \
/mnt/c/taxi/taxi.duckdb
done
最初,这效果很好。 SATA 驱动器上的读取峰值速度为 60 MB/s,但约为 40 MB/s,写入约为 20 MB/s。每次导入期间,DuckDB 的 RAM 消耗峰值约为 10 GB。 CPU 使用率最初约为 15-25%,但随着越来越多的 CSV 导入 DuckDB,最终达到 100%。
当 CPU 消耗达到 100% 时,我注意到整体时钟频率下降到 3.5 GHz,然后再次下降到 3.4 GHz,然后恢复到 4 GHz 范围。
下面是 Speccy 大约在同一时间的屏幕截图。
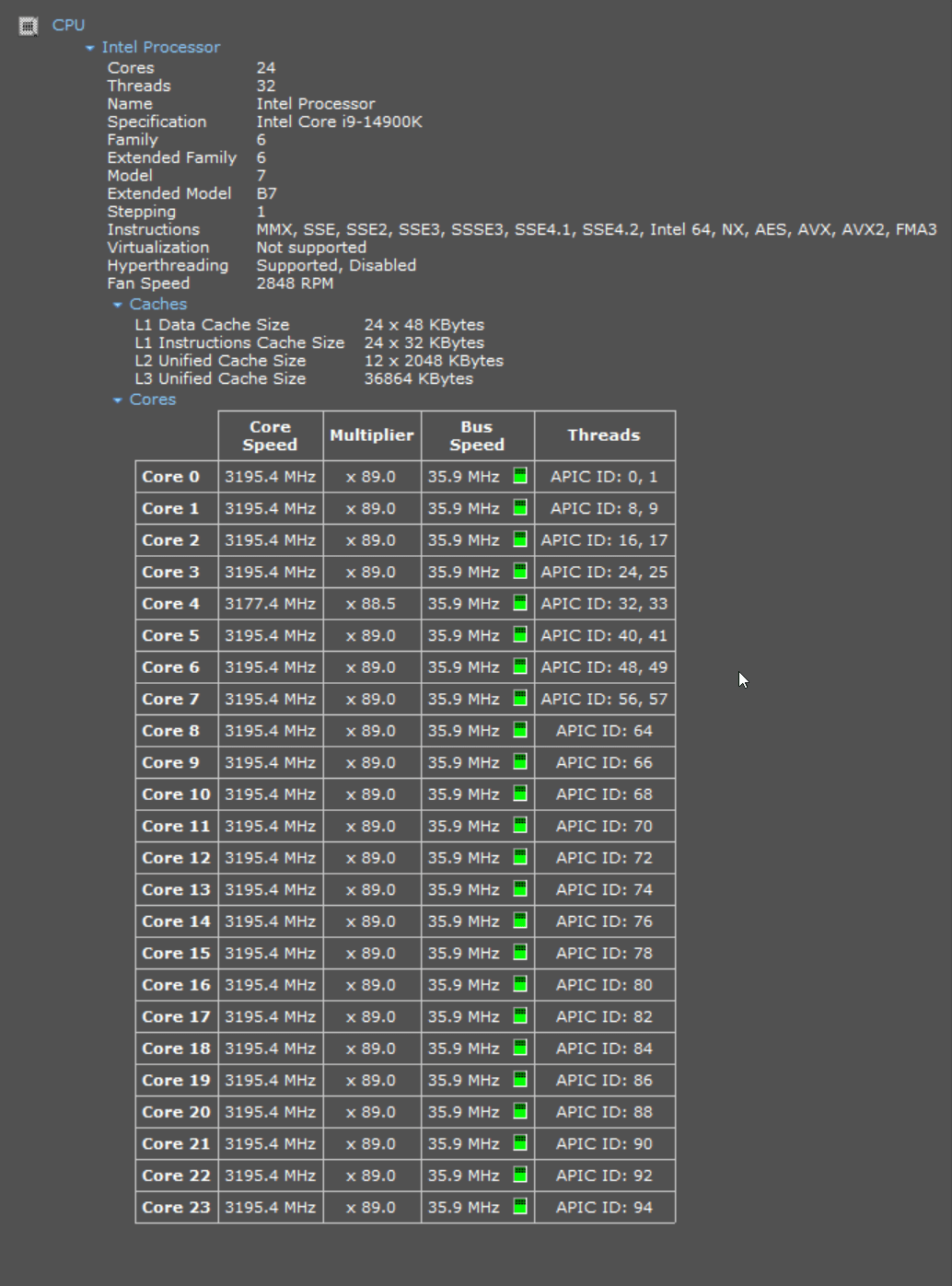
导入进展顺利,直到第 36 个 CSV 文件,但从那时起,进度停止,CPU 处于 100%。此时 DuckDB 文件大约为 70 GB。经过 45 分钟的磁盘活动非常少且 CPU 全速运行后,我取消了该作业。
构建 Parquet Files
我对该数据集进行基准测试的第三次尝试是将每个 CSV 文件转换为 Parquet 文件,然后查询这些文件。
SSD 是消耗品,在使用足够多的情况下,在某些时候可能会出现故障。第五代 SSD 的价格为 616 欧元,而容量为 2 TB 的新型 SATA SSD 的价格约为 100 欧元。因此,我将在更快的驱动器上运行基准测试,但我将在更便宜的驱动器上构建 Parquet 文件。
通常我按经度对数据进行排序,因为这会产生较小的 Parquet 文件,但为了将 RAM 消耗保持在最低限度,我不会为 DuckDB 指定任何特定顺序。
$ for FILENAME in trips_x*.csv.gz; do
echo $FILENAME
OUT=`echo $FILENAME | sed 's/.csv.gz//g'`
touch working.duckdb
rm working.duckdb
~/duckdb working.duckdb < create.sql
~/duckdb -c "INSERT INTO trips
SELECT *
FROM read_csv('$FILENAME');
SET preserve_insertion_order=false;
SET memory_limit='8GB';
COPY(
SELECT *
FROM trips
) TO '$OUT.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);" \
working.duckdb
done
上述 RAM 消耗峰值约为 20 GB。 CSV 的读取速度在 40-120 MB/s 之间,写入峰值在任何时候都在 120 MB/s 左右。在某些操作期间,CPU 消耗几乎没有突破 20%,而在其他部分,所有核心的 CPU 消耗将达到 100% 的峰值。
大多数 GZIP 压缩的 CSV 文件大小为 1.9 GB,生成的 PQ 文件大小约为 1.5 GB。
一份有问题的 CSV
不幸的是,DuckDB 卡在 trips_xbj.csv.gz 上。 CPU 已达到极限,工作 DuckDB 文件大小为 868 MB,而正常情况下会生成约 2 GB。我怀疑 CSV 太大,所以我尝试将其分成几个 500K 行的 CSV 文件。
$ pigz -dc trips_xbj.csv.gz \
| split --lines=500000 \
--filter="pigz > trips_xbj_\$FILE.csv.gz"
$ for FILENAME in trips_xbj_x*.csv.gz; do
echo $FILENAME
OUT=`echo $FILENAME | sed 's/.csv.gz//g'`
touch working.duckdb
rm working.duckdb
~/duckdb working.duckdb < create.sql
~/duckdb -c "INSERT INTO trips
SELECT *
FROM read_csv('$FILENAME');
SET preserve_insertion_order=false;
SET memory_limit='8GB';
COPY(
SELECT *
FROM trips
) TO '$OUT.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);" \
working.duckdb
done
当我运行上面的 DuckDB 最终卡在 trips_xbj_xas.csv.gz 上,症状与以前相同。
编译DuckDB
我决定编译 DuckDB 的主分支,看看它是否可以毫无问题地处理上述 CSV。
$ git clone https://github.com/duckdb/duckdb.git ~/duckdb_source
$ cd ~/duckdb_source
$ mkdir -p build/release
$ cmake \
./CMakeLists.txt \
-DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DEXTENSION_STATIC_BUILD=1 \
-DBUILD_PARQUET_EXTENSION=1 \
-B build/release
$ CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) \
cmake --build build/release
我为这个独特的 DuckDB 构建重新安装了 Parquet 扩展。
$ ~/duckdb_source/build/release/duckdb
INSTALL parquet;
然后,我对有问题的 CSV 重新运行 CSV 到 Parquet 的转换过程。
$ cd /mnt/d/taxi
$ for FILENAME in trips_xbj_xas.csv.gz; do
echo $FILENAME
OUT=`echo $FILENAME | sed 's/.csv.gz//g'`
touch working.duckdb
rm working.duckdb
~/duckdb_source/build/release/duckdb working.duckdb < create.sql
~/duckdb_source/build/release/duckdb \
-c "INSERT INTO trips
SELECT *
FROM read_csv('$FILENAME');
SET preserve_insertion_order=false;
SET memory_limit='8GB';
COPY(
SELECT *
FROM trips
) TO '$OUT.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);" \
working.duckdb
done
我希望自 0.10.0 版本发布以来的过去几周内修复了某种 CSV 解析错误,从而可以解决该问题。相反,我收到了一条在官方二进制版本中没有看到的错误消息。
Conversion Error: CSV Error on Line: 220725
Error when converting column "column20".
Could not convert string "Cash" to 'BIGINT'
file=trips_xbj_xas.csv.gz
delimiter = , (Auto-Detected)
quote = \0 (Auto-Detected)
escape = \0 (Auto-Detected)
new_line = \n (Auto-Detected)
header = false (Auto-Detected)
skip_rows = 0 (Auto-Detected)
date_format = (Auto-Detected)
timestamp_format = (Auto-Detected)
null_padding=0
sample_size=20480
ignore_errors=0
all_varchar=0
列名称从 column00 开始。第 21 个字段是 payment_type ,它是 VARCHAR。我不确定为什么 DuckDB 想要将其转换为 BIGINT。
我删除了 create.sql 中字段之间的可读间距。第一行是 CREATE TABLE 语句,因此第 22 行是第 21 个字段名称和类型。
$ grep -n -B1 -A1 payment create.sql
21- total_amount DOUBLE,
22: payment_type VARCHAR,
23- trip_type VARCHAR,
该字段是 VARCHAR 所以我很困惑为什么 DuckDB 想要将其转换为 BIGINT。
忽略错误
我将使用 ignore_errors=true 再次运行 CSV 到 Parquet 的转换,看看是否可以跳过此记录,并了解是否可以知道此问题的全貌。
$ for FILENAME in trips_xbj_xas.csv.gz; do
echo $FILENAME
OUT=`echo $FILENAME | sed 's/.csv.gz//g'`
touch working.duckdb
rm working.duckdb
~/duckdb_source/build/release/duckdb working.duckdb < create.sql
~/duckdb_source/build/release/duckdb \
-c "INSERT INTO trips
SELECT *
FROM read_csv('$FILENAME',
ignore_errors=true);
SET preserve_insertion_order=false;
SET memory_limit='8GB';
COPY(
SELECT *
FROM trips
) TO '$OUT.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);" \
working.duckdb
done
生成的 Parquet 文件中应该有 500K 记录,但现在还没有达到 280K!。
SELECT COUNT(*)
FROM READ_PARQUET('trips_xbj_xas.pq');
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 279904 │
└──────────────┘
我还发现 trips_xbs.pq 和 trips_xbv.pq 总共也丢失了大约 200 万条记录。
$ for FILENAME in trips_x*.pq; do
echo $FILENAME, `~/duckdb -csv -c "SELECT COUNT(*) FROM READ_PARQUET('$FILENAME')"`
done
...
trips_xbs.pq, .. count_star() 19999999
trips_xbt.pq, .. count_star() 20000000
trips_xbu.pq, .. count_star() 20000000
trips_xbv.pq, .. count_star() 17874858
...
有问题的数据
这是 DuckDB 报出错误的记录部分。
$ gunzip -c trips_xbj_xas.csv.gz \
| head -n220725 \
| tail -n1 \
> unparsable.csv
$ grep -o '.*Cash' unparsable.csv
26948130,CMT,2009-01-10 11:24:50,2009-01-10 11:28:39,,,-73.980964,40.779387999999997,-73.97072,40.784225999999997,1,0.90000000000000002,4.5,0,,0,0,,,4.5,Cash
下面我将使用 DuckDB 读取记录并查看“Cash”值落在哪个字段。
$ ~/duckdb
.mode line
SELECT COLUMNS(c -> c LIKE 'column0%' OR
c LIKE 'column1%' or
c LIKE 'column20')
FROM READ_CSV('unparsable.csv');
column00 = 26948130
column01 = CMT
column02 = 2009-01-10 11:24:50
column03 = 2009-01-10 11:28:39
column04 =
column05 =
column06 = -73.980964
column07 = 40.779388
column08 = -73.97072
column09 = 40.784226
column10 = 1
column11 = 0.9
column12 = 4.5
column13 = 0
column14 =
column15 = 0
column16 = 0
column17 =
column18 =
column19 = 4.5
column20 = Cash
“Cash”值位于第 21 列,因此这看起来不像对齐问题。
CSV 文件可以仅通过逗号分隔符进行解析,因为没有单元格值包含逗号。下面,我将使用行号注释 CSV 数据的前 21 行,作为双重检查,确保“Cash”应出现在第 21 列中。
$ python3
s = '''26948130,CMT,2009-01-10 11:24:50,2009-01-10 11:28:39,,,-73.980964,40.779387999999997,-73.97072,40.784225999999997,1,0.90000000000000002,4.5,0,,0,0,,,4.5,Cash'''
for n, v in enumerate(s.split(','), start=1):
print(n, v)
1 26948130
2 CMT
3 2009-01-10 11:24:50
4 2009-01-10 11:28:39
5
6
7 -73.980964
8 40.779387999999997
9 -73.97072
10 40.784225999999997
11 1
12 0.90000000000000002
13 4.5
14 0
15
16 0
17 0
18
19
20 4.5
21 Cash
使用 ClickHouse 进行转换
我不知道如何及时解决DuckDB的问题。为了解决问题,我将使用 ClickHouse 生成剩余的 Parquet 文件。
$ cd ~
$ curl https://clickhouse.com/ | sh
$ cd /mnt/d/taxi
$ ~/clickhouse local
CREATE TABLE trips (
trip_id INT,
vendor_id VARCHAR(3),
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR(1),
rate_code_id SMALLINT,
pickup_longitude DECIMAL(18,14),
pickup_latitude DECIMAL(18,14),
dropoff_longitude DECIMAL(18,14),
dropoff_latitude DECIMAL(18,14),
passenger_count SMALLINT,
trip_distance DECIMAL(18,6),
fare_amount DECIMAL(18,6),
extra DECIMAL(18,6),
mta_tax DECIMAL(18,6),
tip_amount DECIMAL(18,6),
tolls_amount DECIMAL(18,6),
ehail_fee DECIMAL(18,6),
improvement_surcharge DECIMAL(18,6),
total_amount DECIMAL(18,6),
payment_type VARCHAR(3),
trip_type SMALLINT,
pickup VARCHAR(50),
dropoff VARCHAR(50),
cab_type VARCHAR(6),
precipitation SMALLINT,
snow_depth SMALLINT,
snowfall SMALLINT,
max_temperature SMALLINT,
min_temperature SMALLINT,
average_wind_speed SMALLINT,
pickup_nyct2010_gid SMALLINT,
pickup_ctlabel VARCHAR(10),
pickup_borocode SMALLINT,
pickup_boroname VARCHAR(13),
pickup_ct2010 VARCHAR(6),
pickup_boroct2010 VARCHAR(7),
pickup_cdeligibil VARCHAR(1),
pickup_ntacode VARCHAR(4),
pickup_ntaname VARCHAR(56),
pickup_puma VARCHAR(4),
dropoff_nyct2010_gid SMALLINT,
dropoff_ctlabel VARCHAR(10),
dropoff_borocode SMALLINT,
dropoff_boroname VARCHAR(13),
dropoff_ct2010 VARCHAR(6),
dropoff_boroct2010 VARCHAR(7),
dropoff_cdeligibil VARCHAR(1),
dropoff_ntacode VARCHAR(4),
dropoff_ntaname VARCHAR(56),
dropoff_puma VARCHAR(4)
) ENGINE=Log;
INSERT INTO trips
SELECT *
FROM file('trips_xbj_xas.csv.gz', CSV);
SELECT *
FROM trips
INTO OUTFILE 'trips_xbj_xas.pq'
FORMAT Parquet;
500000 rows in set. Elapsed: 2.427 sec. Processed 500.00 thousand rows, 290.10 MB (205.99 thousand rows/s., 119.51 MB/s.)
Peak memory usage: 418.85 MiB.
我试图让 DuckDB 读取上面的 Parquet 文件,但它无法读取。
$ ~/duckdb
SELECT cab_type,
COUNT(*)
FROM READ_PARQUET('trips_xbj_xas.pq')
GROUP BY cab_type;
Error: Invalid Error: Unsupported compression codec "7". Supported options are uncompressed, gzip, snappy or zstd
检查 ClickHouse 的 Parquet 文件
我一直在研究 Parquet debugging tool。我将用它来检查 ClickHouse 正在使用的压缩方案。
$ git clone https://github.com/marklit/pqview \
~/pqview
$ virtualenv ~/.pqview
$ source ~/.pqview/bin/activate
$ python3 -m pip install \
-r ~/pqview/requirements.txt
$ python3 ~/pqview/main.py \
most-compressed \
trips_xbj_xas.pq \
| grep compression
compression: LZ4
ClickHouse 在去年的某个时候将其默认的 Parquet 压缩方案从 Snappy 更改为 LZ4。 LZ4 很棒,但 DuckDB 不支持它。我将使用 ClickHouse 兼容性设置重建 Parquet 文件,该设置将恢复为使用 Snappy 压缩。
SELECT *
FROM trips
INTO OUTFILE 'trips_xbj_xas.pq'
FORMAT Parquet
SETTINGS compatibility='23.2';
$ python3 ~/pqview/main.py \
most-compressed \
trips_xbj_xas.pq \
| grep compression
compression: SNAPPY
由于 ClickHouse 能够使用 Snappy 生成 Parquet 文件,我还重新处理了 trips_xbs.pq 和 trips_xbv.pq 。我在将它们导入 ClickHouse 时遇到问题, trips_xbv.pq 在 1573 万行点处停止。我必须将它们分成 4 x 5M 行的 CSV 文件才能顺利导入。
ClickHouse 将timestamps转换为 uint64 导出到 Parquet,而不是timestamps。我使用 DuckDB 将这些字段转换回时间戳。
$ ~/duckdb_source/build/release/duckdb working.duckdb
SET preserve_insertion_order=false;
SET memory_limit='8GB';
CREATE OR REPLACE TABLE trips AS
SELECT * EXCLUDE (pickup_datetime, dropoff_datetime),
MAKE_TIMESTAMP(pickup_datetime * 1000000) AS pickup_datetime,
MAKE_TIMESTAMP(dropoff_datetime * 1000000) AS dropoff_datetime,
FROM READ_PARQUET('trips_xbj_xas.pq');
COPY(
SELECT *
FROM trips
) TO 'trips_xbj_xas_ts.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);
CREATE OR REPLACE TABLE trips AS
SELECT * EXCLUDE (pickup_datetime, dropoff_datetime),
MAKE_TIMESTAMP(pickup_datetime * 1000000) AS pickup_datetime,
MAKE_TIMESTAMP(dropoff_datetime * 1000000) AS dropoff_datetime,
FROM READ_PARQUET('trips_xbs.pq');
COPY(
SELECT *
FROM trips
) TO 'trips_xbs_ts.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);
CREATE OR REPLACE TABLE trips AS
SELECT * EXCLUDE (pickup_datetime, dropoff_datetime),
MAKE_TIMESTAMP(pickup_datetime * 1000000) AS pickup_datetime,
MAKE_TIMESTAMP(dropoff_datetime * 1000000) AS dropoff_datetime,
FROM READ_PARQUET('trips_xbv.pq');
COPY(
SELECT *
FROM trips
) TO 'trips_xbv_ts.pq' (FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);
双重检查
在完整的 11 亿出租车出行数据集中,应该有 1,086,709,191 条黄色出租车记录和 26,943,827 条绿色出租车记录。我运行以下命令来检查这些 Parquet 文件是否属于这种情况。 Mark Raasveldt 几天前修复了进度条错误,因此从这里开始我将使用新编译的 DuckDB 版本。
$ ~/duckdb_source/build/release/duckdb
SELECT cab_type,
COUNT(*)
FROM READ_PARQUET('trips_x*.pq')
GROUP BY cab_type;
┌──────────┬──────────────┐
│ cab_type │ count_star() │
│ varchar │ int64 │
├──────────┼──────────────┤
│ yellow │ 1086709191 │
│ green │ 26943827 │
└──────────┴──────────────┘
The Parquet Benchmark
在运行以下基准测试之前,我将 Parquet 文件复制到第五代 SSD 上。以下是我在 Parquet 文件上多次运行每个查询后看到的最快时间。
以下完成时间为 36.942 秒。
SELECT cab_type,
COUNT(*)
FROM READ_PARQUET('trips_x*.pq')
GROUP BY cab_type;
以下完成时间为 51.085 秒。
SELECT passenger_count,
AVG(total_amount)
FROM READ_PARQUET('trips_x*.pq')
GROUP BY passenger_count;
以下完成时间为 60.656 秒。
SELECT passenger_count,
DATE_PART('year', pickup_datetime) AS year,
COUNT(*)
FROM READ_PARQUET('trips_x*.pq')
GROUP BY passenger_count,
year;
以下完成时间为 92.124 秒。
SELECT passenger_count,
DATE_PART('year', pickup_datetime) AS year,
ROUND(trip_distance) AS distance,
COUNT(*)
FROM READ_PARQUET('trips_x*.pq')
GROUP BY passenger_count,
year,
distance
ORDER BY year,
count(*) DESC;
替代方法
在这篇文章首次发布后,Mark Raasveldt 联系我,让我知道 COPY 命令使用 READ_CSV() 的替代方法,并通过此将数据集加载到 DuckDB 的内部格式中方法将更加可靠并产生更快的基准数据。
我从 SATA 连接的 SSD 中删除了原始数据集中不存在的所有 .csv.gz 文件,并确保仅保留 56 个原始文件,以避免记录重复。然后我运行了以下命令。
$ touch working.duckdb
$ rm working.duckdb
$ ~/duckdb_source/build/release/duckdb \
working.duckdb \
< create.sql
$ ~/duckdb_source/build/release/duckdb \
working.duckdb \
-c "COPY trips FROM 'trips*.csv.gz';"
RAM 消耗迅速增长至 22 GB,然后趋于平稳。 SSD 的写入速度为 50-150 MB/s,读取速度通常为 5-10 MB/s,而 CPU 几乎处于空闲状态,为 5-10%。该作业运行了约 3-4 小时,然后达到 91%,然后突然被终止。我不确定为什么会发生这种情况,因为系统上有足够的可用内存。
在大约 3.5 小时内,平均持续写入速度为大约 70 MB/s,这意味着 SSD 将写入大约 860 GB,尽管 DuckDB 文件仅增长到大约 90 GB。鉴于 SSD 可能会磨损,如果您使用自己的硬件,则需要考虑这一点。
我第二次尝试使用 COPY 命令。这次,我一次导入一个文件。这项工作最终在 75 分钟内完成。 RAM 消耗仅在 6 GB 左右达到峰值,CPU 在此期间徘徊在 15-30% 之间。
$ touch working.duckdb
$ rm working.duckdb
$ ~/duckdb_source/build/release/duckdb \
working.duckdb \
< create.sql
$ for FILENAME in trips_*.csv.gz; do
echo `date`, $FILENAME
~/duckdb_source/build/release/duckdb \
-c "COPY trips FROM '$FILENAME';" \
working.duckdb
done
生成的 DuckDB 文件为 113 GB。在将其复制到第五代 SSD 之前,我检查了记录数。
SELECT cab_type,
COUNT(*)
FROM trips
GROUP BY cab_type;
┌──────────┬──────────────┐
│ cab_type │ count_star() │
│ varchar │ int64 │
├──────────┼──────────────┤
│ green │ 26943827 │
│ yellow │ 1086709191 │
└──────────┴──────────────┘
DuckDB 的一个有趣的方面是其各种各样的压缩方案。其中一些,例如Adaptive Lossless Floating-Point Compression (ALP),是 DuckDB 所独有的。任何一个字段都可以有任意数量的这些方案,用于压缩其各自的行组。 DuckDB 自动决定在每行组的基础上使用哪种方案。
下面是 trips 表中每个字段的每个压缩方案的行组计数。
WITH pivot_alias AS (
PIVOT PRAGMA_STORAGE_INFO('trips')
ON compression
USING COUNT(*)
GROUP BY column_name,
column_id
ORDER BY column_id
)
SELECT * EXCLUDE(column_id)
FROM pivot_alias;
┌───────────────────────┬───────┬───────┬────────────┬──────────┬────────────┬───────┬───────┬──────────────┐
│ column_name │ ALP │ ALPRD │ BitPacking │ Constant │ Dictionary │ FSST │ RLE │ Uncompressed │
│ varchar │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │ int64 │
├───────────────────────┼───────┼───────┼────────────┼──────────┼────────────┼───────┼───────┼──────────────┤
│ trip_id │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ vendor_id │ 0 │ 0 │ 0 │ 9426 │ 9425 │ 1 │ 0 │ 0 │
│ pickup_datetime │ 0 │ 0 │ 28218 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ dropoff_datetime │ 0 │ 0 │ 28218 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ store_and_fwd_flag │ 0 │ 0 │ 0 │ 888 │ 9283 │ 143 │ 0 │ 8538 │
│ rate_code_id │ 0 │ 0 │ 439 │ 10965 │ 0 │ 0 │ 7445 │ 3 │
│ pickup_longitude │ 18636 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ pickup_latitude │ 15872 │ 2663 │ 0 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ dropoff_longitude │ 19353 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ dropoff_latitude │ 16789 │ 2663 │ 0 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ passenger_count │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ trip_distance │ 9426 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ fare_amount │ 9426 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ extra │ 9426 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ mta_tax │ 197 │ 0 │ 0 │ 10085 │ 0 │ 0 │ 8180 │ 390 │
│ tip_amount │ 9426 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ tolls_amount │ 5907 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 3519 │ 0 │
│ ehail_fee │ 0 │ 0 │ 0 │ 18852 │ 0 │ 0 │ 0 │ 0 │
│ improvement_surcharge │ 192 │ 0 │ 0 │ 18102 │ 0 │ 0 │ 549 │ 9 │
│ total_amount │ 9427 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ payment_type │ 0 │ 0 │ 0 │ 9426 │ 9425 │ 1 │ 0 │ 0 │
│ trip_type │ 0 │ 0 │ 0 │ 9340 │ 9416 │ 10 │ 0 │ 86 │
│ pickup │ 0 │ 0 │ 0 │ 0 │ 8798 │ 628 │ 0 │ 9426 │
│ dropoff │ 0 │ 0 │ 0 │ 0 │ 8311 │ 1115 │ 0 │ 9426 │
│ cab_type │ 0 │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │
│ precipitation │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ snow_depth │ 0 │ 0 │ 2362 │ 16249 │ 0 │ 0 │ 241 │ 0 │
│ snowfall │ 0 │ 0 │ 2262 │ 15614 │ 0 │ 0 │ 976 │ 0 │
│ max_temperature │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ min_temperature │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ average_wind_speed │ 0 │ 0 │ 9426 │ 9426 │ 0 │ 0 │ 0 │ 0 │
│ pickup_nyct2010_gid │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ pickup_ctlabel │ 0 │ 0 │ 0 │ 0 │ 7685 │ 1741 │ 0 │ 9426 │
│ pickup_borocode │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ pickup_boroname │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ pickup_ct2010 │ 0 │ 0 │ 0 │ 0 │ 9323 │ 187 │ 0 │ 9426 │
│ pickup_boroct2010 │ 0 │ 0 │ 18354 │ 0 │ 0 │ 0 │ 235 │ 9426 │
│ pickup_cdeligibil │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ pickup_ntacode │ 0 │ 0 │ 0 │ 0 │ 9403 │ 40 │ 0 │ 9426 │
│ pickup_ntaname │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ pickup_puma │ 0 │ 0 │ 0 │ 0 │ 9424 │ 3 │ 0 │ 9426 │
│ dropoff_nyct2010_gid │ 0 │ 0 │ 647 │ 0 │ 0 │ 0 │ 8779 │ 9426 │
│ dropoff_ctlabel │ 0 │ 0 │ 0 │ 0 │ 6843 │ 2583 │ 0 │ 9426 │
│ dropoff_borocode │ 0 │ 0 │ 9426 │ 0 │ 0 │ 0 │ 0 │ 9426 │
│ dropoff_boroname │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ dropoff_ct2010 │ 0 │ 0 │ 0 │ 0 │ 9221 │ 369 │ 0 │ 9426 │
│ dropoff_boroct2010 │ 0 │ 0 │ 0 │ 0 │ 9301 │ 247 │ 0 │ 9426 │
│ dropoff_cdeligibil │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ dropoff_ntacode │ 0 │ 0 │ 0 │ 0 │ 9407 │ 31 │ 0 │ 9426 │
│ dropoff_ntaname │ 0 │ 0 │ 0 │ 0 │ 9426 │ 0 │ 0 │ 9426 │
│ dropoff_puma │ 0 │ 0 │ 0 │ 0 │ 9421 │ 8 │ 0 │ 9426 │
├───────────────────────┴───────┴───────┴────────────┴──────────┴────────────┴───────┴───────┴──────────────┤
│ 51 rows 9 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────┘
内部格式基准
以下是我在 DuckDB 表上多次运行每个查询后看到的最快时间。
以下在 0.498 秒内完成。
SELECT cab_type,
COUNT(*)
FROM trips
GROUP BY cab_type;
以下在 0.234 秒内完成。
SELECT passenger_count,
AVG(total_amount)
FROM trips
GROUP BY passenger_count;
以下在 0.734 秒内完成。
SELECT passenger_count,
DATE_PART('year', pickup_datetime) AS year,
COUNT(*)
FROM trips
GROUP BY passenger_count,
year;
以下内容在 1.334 秒内完成。
SELECT passenger_count,
DATE_PART('year', pickup_datetime) AS year,
ROUND(trip_distance) AS distance,
COUNT(*)
FROM trips
GROUP BY passenger_count,
year,
distance
ORDER BY year,
count(*) DESC;
感谢您花时间阅读这篇文章。
原文地址: 1.1Billion Taxi Rides using DuckDB
相关文档:
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)