
使用 VS Code 调试 Python 代码时将变量保存为 JSON 文件
是 Python 标准库json模块中用于将 Python 对象以 JSON 格式写入到文件中的核心函数。参数名含义obj要写入的 Python 对象(如字典、列表等)fp打开的文件对象(必须是文本模式)indent设置缩进空格数,使 JSON 更易读(如indent=4是否只输出 ASCII 字符。默认True(非 ASCII 会被转义),设为False可输出中文sort_keys是否按 key
使用 VS Code 调试 Python 代码时将变量保存为 JSON 文件
在日常 Python 开发中,我们经常需要调试变量的值,特别是调试复杂对象、字典、列表或自定义类实例。在 Visual Studio Code(VS Code)中调试 Python 程序时,将变量实时保存为 JSON 文件不仅有助于持久化调试数据,还可以便于后续分析或复现问题。
本文将介绍如何在 VS Code 调试过程中,将不同类型的变量(包括字典、列表、类对象等)保存为 JSON 文件,并提供实践建议与注意事项。
目录
1 为什么要将变量保存为 JSON?
- 调试数据持久化:便于后续重现某一时刻程序状态;
- 辅助分析:使用其他工具(如 Pandas、Jupyter Notebook)进行进一步分析;
- 跨系统传递:JSON 是一种轻量通用的数据交换格式,便于与其他服务或语言交互。
- 直观了解变量内容:一些大型项目中变量的数据结构往往很复杂,VS Code 的变量监视页面不能够清晰的展示变量内容。
2 环境准备
- VS Code 最新版本
json标准库(Python 自带)
3 调试中保存变量为 JSON 的基本方法
3.1 json.dump 简介
json.dump() 是 Python 标准库 json 模块中用于将 Python 对象以 JSON 格式写入到文件中的核心函数。
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)
常用参数说明:
| 参数名 | 含义 |
|---|---|
obj |
要写入的 Python 对象(如字典、列表等) |
fp |
打开的文件对象(必须是文本模式) |
indent |
设置缩进空格数,使 JSON 更易读(如 indent=4) |
ensure_ascii |
是否只输出 ASCII 字符。默认 True(非 ASCII 会被转义),设为 False 可输出中文 |
sort_keys |
是否按 key 排序输出(适合调试) |
separators |
控制分隔符(默认是 (',', ': ')),设为 (',', ':') 可生成更紧凑的 JSON |
default |
当遇到无法序列化的对象时,调用该函数处理(如转字符串) |
3.1.1 基本用法(带缩进)
import json
data = {
"name": "张三",
"age": 25,
"skills": ["Python", "机器学习"]
}
with open("user.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
输出内容(保持中文不转义,排版清晰):
{
"name": "张三",
"age": 25,
"skills": [
"Python",
"机器学习"
]
}
3.1.2 精简格式输出(用于机器读取或压缩传输)
import json
with open("compact.json", "w", encoding="utf-8") as f:
json.dump(data, f, separators=(",", ":"), ensure_ascii=False)
输出内容:
{"name":"张三","age":25,"skills":["Python","机器学习"]}
3.1.3 排序键 + 自定义处理不可序列化对象
import datetime
data = {
"name": "Alice",
"timestamp": datetime.datetime.now()
}
# 自定义序列化函数
def json_default(obj):
if isinstance(obj, datetime.datetime):
return obj.isoformat()
raise TypeError("Type not serializable")
with open("time.json", "w") as f:
json.dump(data, f, default=json_default, indent=4)
输出内容:
{
"name": "Alice",
"timestamp": "2025-06-12T14:33:45.123456"
}
3.2 使用 json.dump 保存基础类型(dict、list、tuple 等)
Python 的 json 模块可以直接序列化常见的基础数据结构,如 dict、list、str、int、float 和 bool。但需要注意,tuple 会自动转为 list 进行序列化。
以下是一些典型结构的示例:
3.2.1 保存列表(List)
import json
data_list = ["apple", "banana", "cherry"]
with open("list.json", "w") as f:
json.dump(data_list, f, indent=4)
输出内容(list.json):
[
"apple",
"banana",
"cherry"
]
3.2.2 保存字典(Dict)
import json
data_dict = {
"name": "Alice",
"age": 28,
"is_admin": False
}
with open("dict.json", "w") as f:
json.dump(data_dict, f, indent=4)
输出内容(dict.json):
{
"name": "Alice",
"age": 28,
"is_admin": false
}
3.2.3 保存元组(Tuple)
import json
data_tuple = ("x", "y", "z")
with open("tuple.json", "w") as f:
json.dump(data_tuple, f, indent=4)
输出内容(注意元组变成了列表):
[
"x",
"y",
"z"
]
3.2.4 列表嵌套字典(List of Dict)
import json
data_list_of_dicts = [
{"id": 1, "value": "foo"},
{"id": 2, "value": "bar"}
]
with open("list_of_dicts.json", "w") as f:
json.dump(data_list_of_dicts, f, indent=4)
输出内容:
[
{
"id": 1,
"value": "foo"
},
{
"id": 2,
"value": "bar"
}
]
3.2.5 列表嵌套元组(List of Tuple)
import json
data_list_of_tuples = [
(1, 2),
(3, 4),
(5, 6)
]
with open("list_of_tuples.json", "w") as f:
json.dump(data_list_of_tuples, f)
输出内容(元组被转换成了列表):
[[1, 2], [3, 4], [5, 6]]
3.2.6 字典嵌套列表与字典
import json
nested_structure = {
"title": "Nested Example",
"items": [
{"type": "fruit", "name": "apple"},
{"type": "fruit", "name": "banana"},
{"type": "vegetable", "name": "carrot"}
]
}
with open("nested.json", "w") as f:
json.dump(nested_structure, f, indent=4)
输出内容:
{
"title": "Nested Example",
"items": [
{
"type": "fruit",
"name": "apple"
},
{
"type": "fruit",
"name": "banana"
},
{
"type": "vegetable",
"name": "carrot"
}
]
}
注意事项:
- Python 的
tuple会被自动转为 JSON 的array(即 list),JSON 本身不区分list和tuple; - 不能直接保存
set类型,需要手动转换为list; json.dump会自动处理嵌套结构,只要其内部元素都可序列化。
3.3 保存自定义类对象
3.3.1 普通类的对象
- 大多数普通类的对象,可以通过
. __dict__属性获取其实例属性字典,再用json.dump写入。
什么是实例属性字典(__dict__)?
在 Python 中,每个普通类的对象都有一个 __dict__ 属性,它是一个字典,用来存储这个对象的所有实例变量(属性)及其当前值。
通俗理解:
obj.__dict__就是“对象的属性 + 值”构成的字典表示,方便查看和操作。
示例:
class User:
def __init__(self, name, age):
self.name = name
self.age = age
user = User("Bob", 25)
# 将对象转为字典后保存
with open("user.json", "w") as f:
json.dump(user.__dict__, f, indent=4)
输出:
{
"name": "Bob",
"age": 25
}
这个字典就可以直接用于 JSON 序列化(使用 json.dump(p.__dict__, f)),从而保存对象的状态。
3.3.2 @dataclass`类的对象
@dataclass类的对象要先转换为标准字典再进行写入
从 Python 3.7 开始,可以使用 @dataclass 装饰器更方便地定义“数据类”。这种类天然适合用于数据结构的存储和序列化处理。针对 @dataclass 修饰的类对象保存为 JSON 的写法,推荐使用 dataclasses.asdict() 方法来转换为标准字典,然后再用 json.dump() 写入。
from dataclasses import dataclass, asdict
import json
@dataclass
class User:
name: str
age: int
skills: list
user = User(name="Alice", age=30, skills=["Python", "Data Science"])
with open("user.json", "w", encoding="utf-8") as f:
json.dump(asdict(user), f, indent=4, ensure_ascii=False) # 使用 `asdict()` 转换为字典
输出内容:
{
"name": "Alice",
"age": 30,
"skills": [
"Python",
"Data Science"
]
}
4 在 VS Code 中调试时保存变量
你可以使用以下几种方式保存变量到 JSON:
4.1 在断点处添加临时代码
直接在打断点的下一行或希望保存变量的位置插入保存代码。
如图所示,用此种方式即可将传入函数_agenerate()的message参数保存为json文件。
4.2 在调试控制台中手动执行保存命令
暂停后,在 VS Code 的调试控制台直接输入: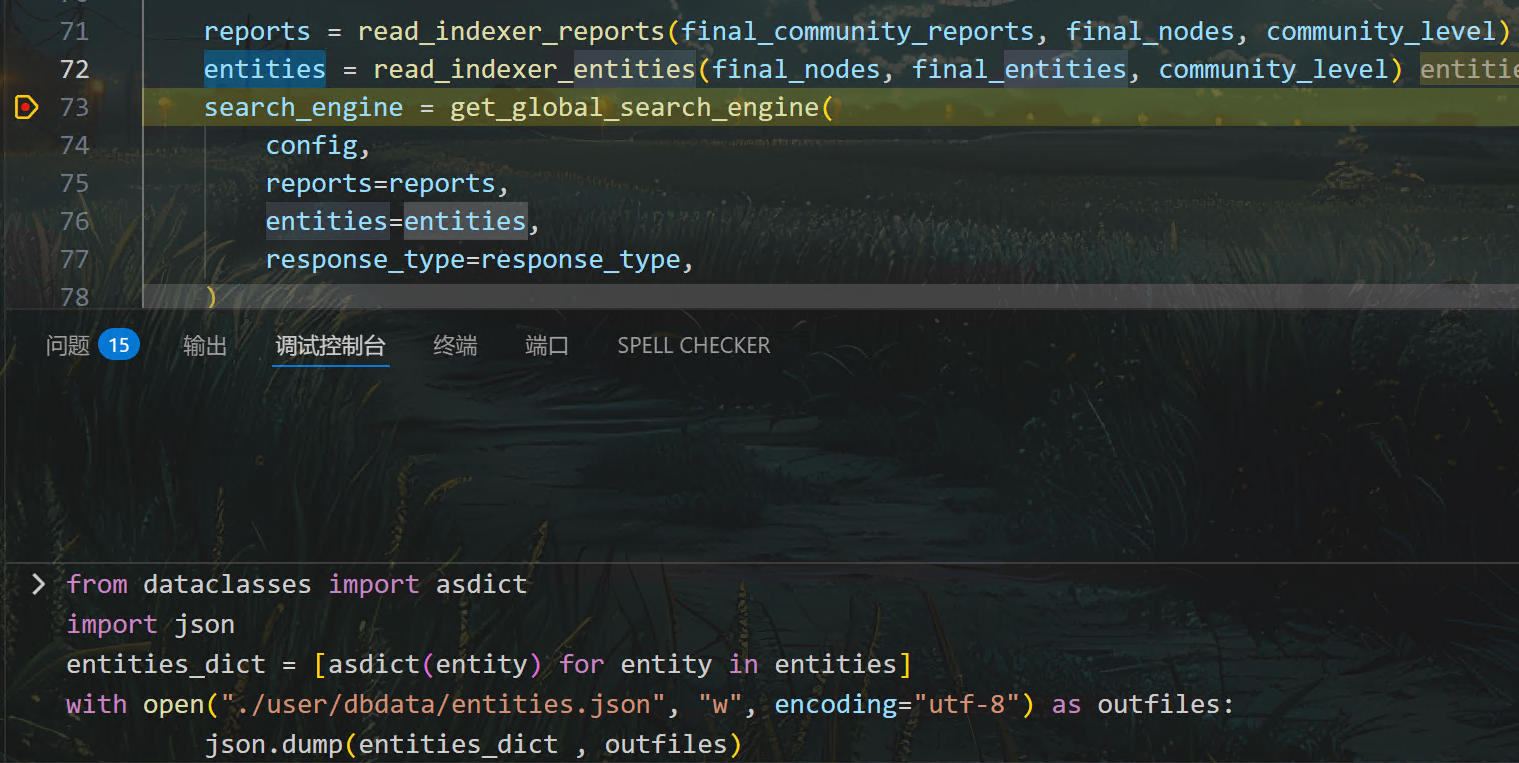
如图所示,此种方法更为灵活,真正实现了“停到哪存到哪”,适合一次性导出。图中的entities变量是由@dataclass类的实例组成的列表,结合“数据类”和列表的处理方式,要先遍历列表内的全部“数据类”的实例,先将其转换为字典,得到字典列表entities_dict,后面就可以按照列表的方式进行保存。
4.3 封装成调试辅助函数
def save_json(var, filename="debug.json"):
import json
with open(filename, "w") as f:
json.dump(var, f, indent=4)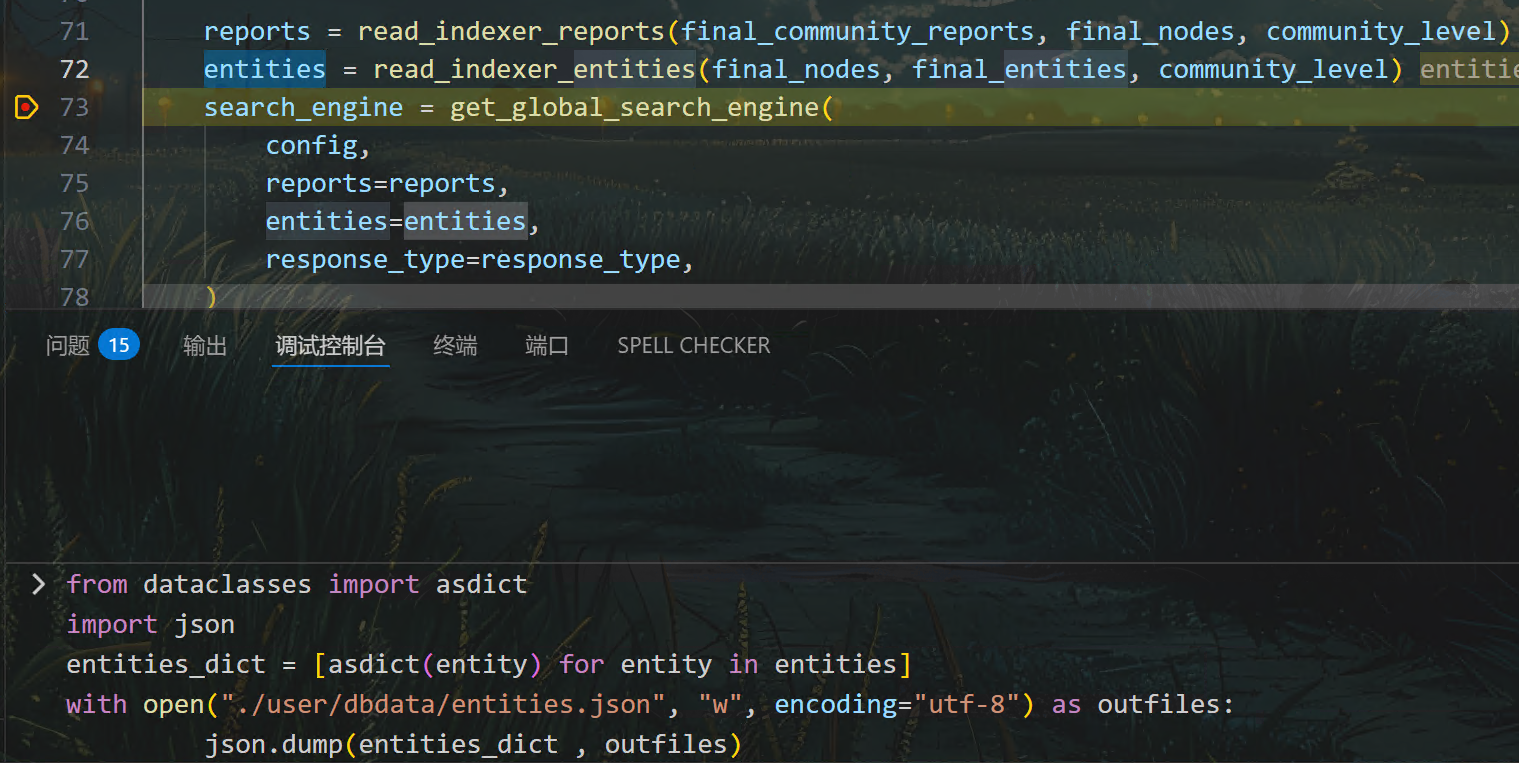

# 调试时调用
save_json(my_data)
可在任意函数中调用,也便于日后复用。
5 注意事项
- 确保对象可序列化:Python 的
json模块不能序列化所有对象(如函数、文件句柄、NumPy 数组等); - 路径问题:文件路径默认是相对当前工作目录(
os.getcwd()),可以使用绝对路径以避免误保存; - 格式化美观:加上
indent=4便于阅读 JSON 文件。
6 总结
在 VS Code 中调试 Python 代码时,灵活地将变量保存为 JSON 文件,可以极大提升调试效率和数据可追溯性。无论是调试字典、列表,还是自定义对象,都有对应的工具和技巧可用。调试不仅是查看变量值,更是系统性地管理程序状态的过程。

更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)