debian11使用kubeasz部署高可用k8s集群
kubeasz使用二进制安装,使用ansible-playbook实现自动化部署。kubeasz可以一键安装,也可以分步部署,本文使用一键安装。安装过程如下,会创建2个本地的容器,kubeasz和local_registry。kubeasz容器运行ezctl用于搭建集群,local_registry容器是一个本地的镜像仓库。ezdown脚本会先下载相关镜像,再将镜像存放到local_registr
GitHub项目地址
https://github.com/easzlab/kubeasz
简介
kubeasz使用二进制安装,使用ansible-playbook实现自动化部署。
kubeasz可以一键安装,也可以分步部署,本文使用一键安装。
安装过程如下,会创建2个本地的容器,kubeasz和local_registry。kubeasz容器运行ezctl用于搭建集群,local_registry容器是一个本地的镜像仓库。ezdown脚本会先下载相关镜像,再将镜像存放到local_registry。
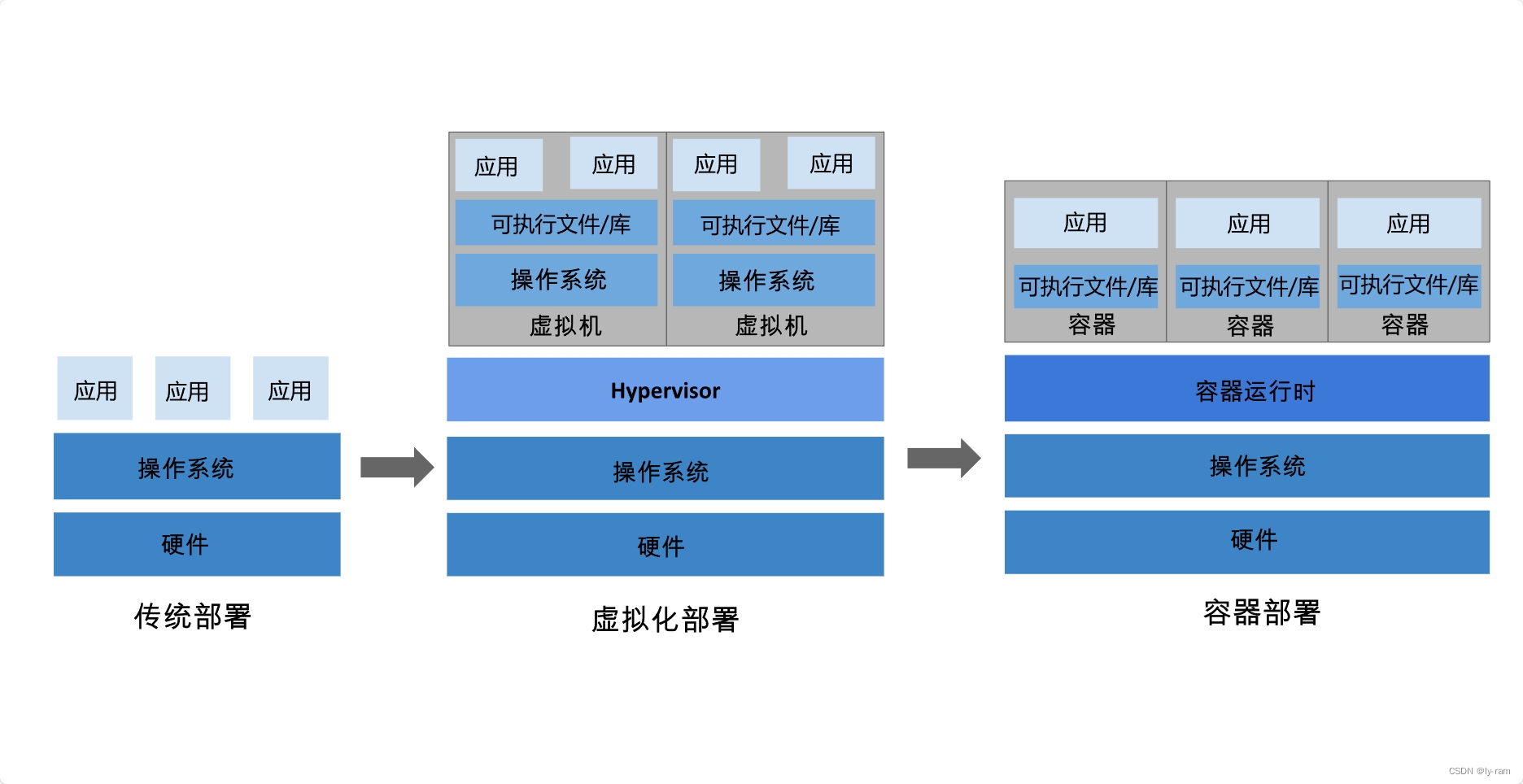
容器部署与传统部署方式的区别

k8s集群组件

集群规划
节点如下所示
| ip | 主机名 | 角色 |
|---|---|---|
| 192.168.122.11 | m01 | 运行ansible/ezctl命令,master和etcd节点 |
| 192.168.122.12 | m02 | master和etcd节点 |
| 192.168.122.13 | m03 | master和etcd节点 |
| 192.168.122.101 | n01 | node节点 |
| 192.168.122.102 | n02 | node节点 |
| 192.168.122.103 | n03 | node节点 |
注意:etcd集群需要1,3,5,…奇数个节点,一般复用master节点,如果拆开,master节点只需要2个。
推荐的机器配置:
- master节点:4c/8g内存/50g硬盘
- worker节点:建议8c/32g内存/200g硬盘以上
在 kubeasz 2x 版本,多节点高可用集群安装可以使用2种方式
- 1.先规划准备,预先配置节点信息,直接安装多节点高可用集群
- 2.先部署单节点集群,然后通过扩容成高可用集群
组件版本
| 组件 | 版本 |
|---|---|
| kubeasz | 3.6.2 |
| kubernetes | 1.26.8 |
| etcd | 3.5.9 |
| calico | 3.24.6 |
准备工作
确保每个节点上 MAC 地址和 product_uuid 的唯一性
- 你可以使用命令
ip link或ifconfig -a来获取网络接口的 MAC 地址 - 可以使用
sudo cat /sys/class/dmi/id/product_uuid命令对 product_uuid 校验
如果使用KVM虚拟机,machine-id很有可能相同,需要手动修改
cat /etc/machine-id
rm -rf /etc/machine-id && dbus-uuidgen --ensure=/etc/machine-id && cat /etc/machine-id
更新apt源
echo 'deb http://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main
deb-src http://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye main
deb http://security.debian.org/debian-security bullseye-security main
deb-src http://security.debian.org/debian-security bullseye-security main
deb http://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main
deb-src http://mirrors.tuna.tsinghua.edu.cn/debian/ bullseye-updates main' > /etc/apt/sources.list
apt -y update
修改时区
timedatectl
timedatectl set-timezone Asia/Shanghai
修改主机名
hostnamectl set-hostname $hostname
其他改动
ezdown脚本会调整系统参数、关闭swap分区、修改hosts文件、加载必要模块,因此,很多配置不需要调整。
#!/bin/bash
# 更新系统
apt update
apt-get upgrade -y
# 设置别名
cat >> /etc/profile << EOF
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
EOF
source /etc/profile
# 安装常用工具
apt install -y iptables net-tools vim wget lsof unzip zip tree lrzsz psmisc sysstat
# 关闭交换分区 取消分区挂载
swapoff -a
sed -i '/ swap / s/^/# /g' /etc/fstab
# 命令自动补全
apt install -y bash-completion
部署步骤
以下示例创建一个6节点的多主高可用集群,文档中命令默认都需要root权限运行。
1.准备ssh免密登陆
debian11系统,需要先允许密码登录root用户(密钥传输完成后,可以继续禁用密码登录root)
vim /etc/ssh/sshd_config
# Authentication:
#LoginGraceTime 2m
#PermitRootLogin prohibit-password
PermitRootLogin yes
配置部署节点ssh免密登陆所有节点,只需在部署节点执行
#$IP为所有节点地址包括自身,按照提示输入yes 和root密码
ssh-keygen
ssh-copy-id $IP
#验证
ssh $IP
2.在部署节点编排k8s安装
- 下载项目源码、二进制及离线镜像
下载工具脚本ezdown,kubeasz版本选择3.6.2
# 国内环境
export release=3.6.2
wget https://ghproxy.com/https://github.com/easzlab/kubeasz/releases/download/${release}/ezdown
chmod +x ./ezdown
下载kubeasz代码、二进制、默认容器镜像(更多关于ezdown的参数,运行 ./ezdown 查看)
# 国内环境
./ezdown -D -k v1.26.8
【可选】下载额外容器镜像(cilium,flannel,prometheus等)
脚本默认使用calico。根据实际需要选择,集群节点少(几十个)可以选择flannel,节点多,选择cilium性能更好。
本文额外安装prometheus组件。
./ezdown -X prometheus
【可选】下载离线系统包 (适用于无法使用yum/apt仓库情形)
./ezdown -P debian_11
上述脚本运行成功后,所有文件(kubeasz代码、二进制、离线镜像)均已整理好放入目录/etc/kubeasz
- 创建集群配置实例
# 容器化运行kubeasz
./ezdown -S
# 创建新集群 k8s-01
docker exec -it kubeasz ezctl new k8s-01
2021-01-19 10:48:23 DEBUG generate custom cluster files in /etc/kubeasz/clusters/k8s-01
2021-01-19 10:48:23 DEBUG set version of common plugins
2021-01-19 10:48:23 DEBUG cluster k8s-01: files successfully created.
2021-01-19 10:48:23 INFO next steps 1: to config '/etc/kubeasz/clusters/k8s-01/hosts'
2021-01-19 10:48:23 INFO next steps 2: to config '/etc/kubeasz/clusters/k8s-01/config.yml'
- 配置hosts和config.yml文件
/etc/kubeasz/clusters/k8s-01/hosts
主要修改ip地址。k8s_nodename最好和主机名对应上。
网络插件默认使用calico,可以修改为其他插件(flannel, kube-router, cilium, kube-ovn),但是需要提前下载(使用 ./ezdown -X)。
kube-proxy模式默认使用ipvs,可以调整为iptables。
本文使用的k8s集群版本是1.26.8,容器运行时只能使用containerd,不支持docker。
若有私有镜像仓库或者有其他外部负载均衡器,根据需要修改配置文件。
# 'etcd' cluster should have odd member(s) (1,3,5,...)
[etcd]
192.168.122.11
192.168.122.12
192.168.122.13
# master node(s), set unique 'k8s_nodename' for each node
# CAUTION: 'k8s_nodename' must consist of lower case alphanumeric characters, '-' or '.',
# and must start and end with an alphanumeric character
[kube_master]
192.168.122.11 k8s_nodename='m01'
192.168.122.12 k8s_nodename='m02'
192.168.122.13 k8s_nodename='m03'
# work node(s), set unique 'k8s_nodename' for each node
# CAUTION: 'k8s_nodename' must consist of lower case alphanumeric characters, '-' or '.',
# and must start and end with an alphanumeric character
[kube_node]
192.168.122.101 k8s_nodename='n01'
192.168.122.102 k8s_nodename='n02'
192.168.122.103 k8s_nodename='n03'
# [optional] harbor server, a private docker registry
# 'NEW_INSTALL': 'true' to install a harbor server; 'false' to integrate with existed one
[harbor]
#192.168.1.8 NEW_INSTALL=false
# [optional] loadbalance for accessing k8s from outside
[ex_lb]
#192.168.122.11 LB_ROLE=master EX_APISERVER_VIP=192.168.122.100 EX_APISERVER_PORT=8443
#192.168.122.12 LB_ROLE=backup EX_APISERVER_VIP=192.168.122.100 EX_APISERVER_PORT=8443
# [optional] ntp server for the cluster
[chrony]
#192.168.122.11
[all:vars]
# --------- Main Variables ---------------
# Secure port for apiservers
SECURE_PORT="6443"
# Cluster container-runtime supported: docker, containerd
# if k8s version >= 1.24, docker is not supported
CONTAINER_RUNTIME="containerd"
# Network plugins supported: calico, flannel, kube-router, cilium, kube-ovn
CLUSTER_NETWORK="calico"
# Service proxy mode of kube-proxy: 'iptables' or 'ipvs'
PROXY_MODE="ipvs"
# K8S Service CIDR, not overlap with node(host) networking
SERVICE_CIDR="10.68.0.0/16"
# Cluster CIDR (Pod CIDR), not overlap with node(host) networking
CLUSTER_CIDR="172.20.0.0/16"
# NodePort Range
NODE_PORT_RANGE="30000-32767"
# Cluster DNS Domain
CLUSTER_DNS_DOMAIN="cluster.local"
# -------- Additional Variables (don't change the default value right now) ---
# Binaries Directory
bin_dir="/opt/kube/bin"
# Deploy Directory (kubeasz workspace)
base_dir="/etc/kubeasz"
# Directory for a specific cluster
cluster_dir="{{ base_dir }}/clusters/k8s-01"
# CA and other components cert/key Directory
ca_dir="/etc/kubernetes/ssl"
# Default 'k8s_nodename' is empty
k8s_nodename=''
# Default python interpreter
ansible_python_interpreter=/usr/bin/python3
/etc/kubeasz/clusters/k8s-01/config.yml
修改K8S_VER为1.26.8,prom_install为yes,其他的不做改动。
5.开始安装
#建议使用alias命令查看。~/.bashrc 文件应该包含:alias dk='docker exec -it kubeasz'
source ~/.bashrc
alias
# 一键安装,等价于执行docker exec -it kubeasz ezctl setup k8s-01 all
dk ezctl setup k8s-01 all
等待一段时间后,会安装完成。
6.验证
在m01节点运行
su -
kubectl get nodes
kubectl get pods -A
kubectl top nodes
kubectl top pods -A
#修改config文件,将config文件复制到另外2台master节点
sed -i s/192.168.122.11/127.0.0.1/ /root/.kube/config
scp /root/.kube/config root@ip2:/root/.kube/
scp /root/.kube/config root@ip3:/root/.kube/
systemctl status kube-apiserver kube-controller-manager kube-scheduler
#验证etcd
export NODE_IPS="ip1 ip2 ip3"
for ip in ${NODE_IPS}; do
ETCDCTL_API=3 etcdctl \
--endpoints=https://${ip}:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem \
endpoint health; done
for ip in ${NODE_IPS}; do
ETCDCTL_API=3 etcdctl \
--endpoints=https://${ip}:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem \
--write-out=table endpoint status; done
#验证calico
calicoctl node status
netstat -antlp|grep ESTABLISHED|grep 179
部分组件解释
kubernetes集群本身的高可用(api等组件),通过kube-lb(nginx)实现,不需要额外的负载均衡器。etcd3个节点,少一个,集群可以继续运行,少2个集群会崩溃。kube-lb的配置文件如下。
cat /etc/kube-lb/conf/kube-lb.conf
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 192.168.122.11:6443 max_fails=2 fail_timeout=3s;
server 192.168.122.12:6443 max_fails=2 fail_timeout=3s;
server 192.168.122.13:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
集群搭建完成后,会自动安装dashboard,由于前面额外选择了prometheus,因此会自动安装prometheus以及grafana。
使用kubeasz部署的工具,yml文件在/etc/kubeasz/clusters/k8s-01/yml/
tree /etc/kubeasz/clusters/k8s-01/yml/
/etc/kubeasz/clusters/k8s-01/yml/
├── calico.yaml
├── coredns.yaml
├── dashboard
│ ├── admin-user-sa-rbac.yaml
│ ├── kubernetes-dashboard.yaml
│ └── read-user-sa-rbac.yaml
├── metrics-server.yaml
├── nodelocaldns.yaml
└── prom-values.yaml
1 directory, 8 files
dashboard
使用 https://NodeIP:NodePort 方式访问 dashboard,支持两种登录方式:Kubeconfig、令牌(Token)
使用kubectl get svc -A查看service,能看到端口。
示例
root@m01:~# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 14m
kube-system dashboard-metrics-scraper ClusterIP 10.68.118.71 <none> 8000/TCP 12m
kube-system kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 12m
kube-system kube-dns-upstream ClusterIP 10.68.135.83 <none> 53/UDP,53/TCP 12m
kube-system kubernetes-dashboard NodePort 10.68.161.167 <none> 443:30380/TCP 12m
kube-system metrics-server ClusterIP 10.68.82.10 <none> 443/TCP 12m
kube-system node-local-dns ClusterIP None <none> 9253/TCP 12m
kube-system prometheus-kube-prometheus-coredns ClusterIP None <none> 9153/TCP 11m
kube-system prometheus-kube-prometheus-kube-controller-manager ClusterIP None <none> 10257/TCP 11m
kube-system prometheus-kube-prometheus-kube-etcd ClusterIP None <none> 2379/TCP 11m
kube-system prometheus-kube-prometheus-kube-proxy ClusterIP None <none> 10249/TCP 11m
kube-system prometheus-kube-prometheus-kube-scheduler ClusterIP None <none> 10259/TCP 11m
kube-system prometheus-kube-prometheus-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 11m
monitor alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 11m
monitor prometheus-grafana NodePort 10.68.40.146 <none> 80:30903/TCP 11m
monitor prometheus-kube-prometheus-alertmanager NodePort 10.68.111.134 <none> 9093:30902/TCP 11m
monitor prometheus-kube-prometheus-operator NodePort 10.68.107.29 <none> 443:30900/TCP 11m
monitor prometheus-kube-prometheus-prometheus NodePort 10.68.51.15 <none> 9090:30901/TCP 11m
monitor prometheus-kube-state-metrics ClusterIP 10.68.31.89 <none> 8080/TCP 11m
monitor prometheus-operated ClusterIP None <none> 9090/TCP 11m
monitor prometheus-prometheus-node-exporter ClusterIP 10.68.220.164 <none> 9100/TCP 11m
注意:使用chrome浏览器访问 https://NodeIP:NodePort 可能提示安全风险无法访问,可以换firefox浏览器设置安全例外,继续访问。
- Token令牌方式登录(admin)
选择 Token 方式登录,复制下面输出的admin token 字段到输入框
# 获取 Bearer Token,找到输出中 ‘token:’ 开头的后面部分
kubectl describe -n kube-system secrets admin-user
- Token令牌方式登录(只读)
选择 Token 方式登录,复制下面输出的read token 字段到输入框
# 获取 Bearer Token,找到输出中 ‘token:’ 开头的后面部分
kubectl describe -n kube-system secrets dashboard-read-user
- Kubeconfig登录(admin)
Admin kubeconfig文件默认位置:/root/.kube/config,该文件中默认没有token字段,使用Kubeconfig方式登录,还需要将token追加到该文件中,完整的文件格式如下:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdxxxxxxxxxxxxxx
server: https://192.168.122.1:6443
name: cluster1
contexts:
- context:
cluster: cluster1
user: admin
name: context-cluster1
current-context: context-cluster1
kind: Config
preferences: {}
users:
- name: admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDRxxxxxxxxxxx
client-key-data: LS0tLS1CRUdJTxxxxxxxxxxxxxx
token: eyJhbGcixxxxxxxxxxxxxxxx
- Kubeconfig登录(只读)
首先创建只读权限 kubeconfig文件,然后类似追加只读token到该文件,略。
Prometheus
kubeasz部署Prometheus,使用helm chart方式部署,使用的charts地址:
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
- 访问prometheus的web界面:
http://$NodeIP:30901 - 访问alertmanager的web界面:
http://$NodeIP:30902 - 访问grafana的web界面:
http://$NodeIP:30903(默认用户密码 admin:Admin1234!)

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)