想要优化 K8S 集群管理?Cluster API 帮你忙 | K8S Internals 系列第 5 期
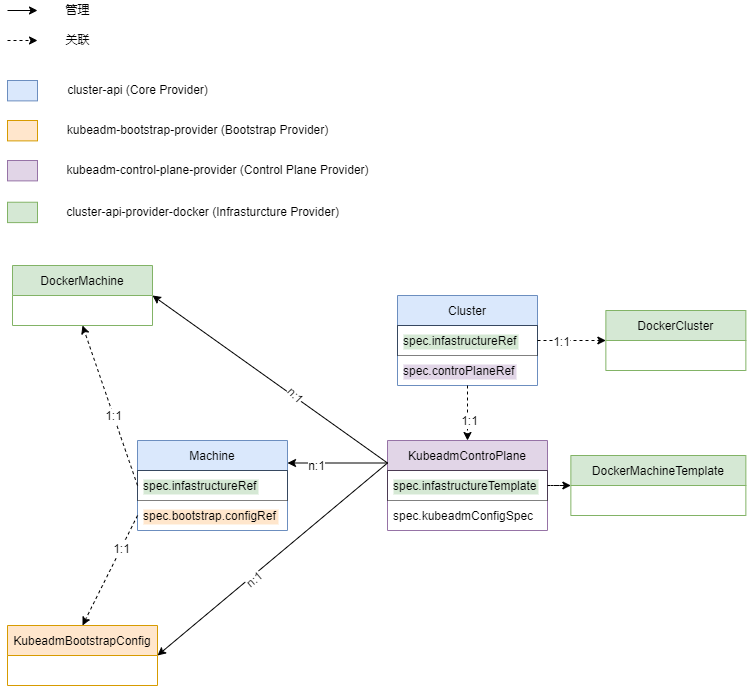
我们以(bootstrap-provider)以及(Infrastructure Provider)组件,资源版本 v1beta1 为例,梳理一下 Cluster API 的自定义资源关系图。在 Cluster API 中对于工作集群的控制平面节点和工作节点的控制是独立分开的,由此对应的资源关系又可划分为控制平面节点机器关系和工作节点机器关系。控制平面节点机器关系图对于,工作集群控制平面节点由资源
K8S Internals 系列第五期
容器编排之争在 Kubernetes 一统天下局面形成后,K8S 成为了云原生时代的新一代操作系统。K8S 让一切变得简单了,但自身逐渐变得越来越复杂。【K8S Internals 系列专栏】围绕 K8S 生态的诸多方面,将由博云容器云研发团队定期分享有关调度、安全、网络、性能、存储、应用场景等热点话题。希望大家在享受 K8S 带来的高效便利的同时,又可以如庖丁解牛般领略其内核运行机制的魅力。
本文将结合 CNCF 社区中面向多集群管理的 Cluster API 项目,来和大家谈谈 K8S 集群的管理方式。
1. 为什么选择 Cluster API?
Kubernetes 已经成为云原生容器平台的事实标准,越来越多不同行业的企事业单位开始将业务从传统的物理机、虚拟机迁移过来。利用 Kubernetes 让应用管理变得既快又稳,同时降低成本。
在这个过程中,一个企业内部建设了数量不少的 K8S 集群,这些集群的部署方式、版本、配置参数、业务部署都不尽相同。可以说,在 K8S 带来便捷高效的同时,如何管理这些 K8S 集群也成为了不可忽略的问题,例如:如何安装部署 Kubernetes 集群、如何管理多个 Kubernetes 集群、异构集群如何管理、集群如何升级扩容、集群的配置参数如何规范的变更?一系列灵魂发问成了不少企业的痛楚。
结合 CNCF 社区中面向多集群管理的 Cluster API 项目,我们来和大家谈谈社区的解决方案。
Cluster API 由 Kubernetes 特别兴趣小组 Cluster Lifecycle 发起,旨在提供 K8S 即服务能力。用 Kubernetes 的能力管理 Kubernetes,用 Kubernetes 的方式提供 Kubernetes 集群生命周期管理,并且支持管理集群相关的基础设施(虚拟机、网络、负载均衡器、VPC 等)。通过以上种种方式,让 K8S 基础设施的生命周期管理也变得非常云原生化。
看到这里,熟悉 Kubernetes 的小伙伴们肯定心想:用 cluster API 项目,是不是只用提交一个 yaml 就好了?没错就是这样。Cluster API 提供了声明式的集群管理方式。那么对比之前集群的部署方式又有什么区别呢?以使用 Kubernetes 的官方部署工具 kubeadm 为例,请看下图。

使用或部署过 Kubernetes 集群的小伙伴们知道,Kubernetes 集群依赖于几个组件协同工作才能正常运行,对这些组件的部署往往吓退了很多人,kubeadm 的出现很大程度减轻了这一痛楚,并且对集群重复部署的问题也给出了一个很好的答案。不过正如上图所示,几乎每一步都需要人工手动操作,部署人员辗转多台服务器之间重复着相同的操作。同时面对日益增长的集群环境,kubeadm 并没有解决如何对自己已部署的集群进行管理。除此之外还包括以下问题:
-
如何针对异构集群一致地配置机器、负载均衡器、VPC 等?
-
如何自动化管理集群生命周期,包括升级和集群删除?
-
如何扩展并管理任意数量的集群?
Cluster API 给出了答案,通过申明式的构建具有 Kubernetes 风格的 API,完成诸如集群自动创建、配置和管理等功能。同时支持您使用不同的基础设施提供商以及引导程序提供商来构建管理您的集群。
2. Cluster API 架构

(图源 Cluster API 官方网站)
-
Management Cluster
Cluster API 工作的集群,该集群往往通过 kind 等工具生成,在该集群上运行着一个或多个基础设施提供程序,并保存着 Cluster API 相关的 CRD 资源。是负责管理工作集群生命周期的集群。
-
Target Cluster
工作集群,由管理集群创建并管理其生命周期。
-
Infrastructure provider
基础设施提供商,工作集群基础设施的实际提供者(如 AWS、Azure 和 Google 等),由各大厂商实现,但需要遵循 Cluster API 的规范去实现相应的接口和逻辑。
-
Control plane provider
控制平面提供者,负责 Target Cluster 控制平面的节点生成,Cluster API 默认使用 kubeadm 引导控制平面。对于不同厂商可实现适配自己的控制平面引导程序。
-
Bootstrap Provider
引导程序提供者,负责集群证书生成,初始化控制平面,并控制其他节点(控制平面和工作节点)加入集群。Cluster API 默认使用基于 kubeadm 的引导程序。对于不同厂商可实现适配自己的节点引导程序。
-
Custom Resources
自定义资源,Cluster API 提供并依赖于几个自定义资源:Machine、MachineDeployment、MachineSet、Cluster。作为厂商,在实现自己的 provider 时应当遵循这些自定义资源规范。
3. Cluster API 资源介绍
我们以kubeadm-control-plane-provider(Control plane provider)、kubeadm-bootstrap-provider(bootstrap-provider)以及cluster-api-provider-docker(Infrastructure Provider)组件,资源版本 v1beta1 为例,梳理一下 Cluster API 的自定义资源关系图。
在 Cluster API 中对于工作集群的控制平面节点和工作节点的控制是独立分开的,由此对应的资源关系又可划分为控制平面节点机器关系和工作节点机器关系。
控制平面节点机器关系图
对于kubeadm-control-plane-provider,工作集群控制平面节点由KubeadmControlplane资源控制。该资源直接控制了一组Machine资源,每一个Machine资源又分别关联了一个DockerMachine和KubeadmBootstrapConfig资源。对于使用者来说实际工作集群中的一个控制平面节点都在管理集群中以一个Machine资源的形式存在,KubeadmControlplane则是整个工作集群控制平面节点的体现。即每个实际的控制平面节点及其对应的引导配置都在管理集群中以资源的形式存在,管理集群通过控制这些资源,最终由基础设施提供者(如 cluster-api-provider-docker)作用到实际的节点或基础设施之上。

工作节点机器关系图
相比于控制平面节点机器的关系图,工作节点机器的关系图更为复杂。这是因为 Cluster API 对于工作节点机器的管理使用了类似 Kubernetes 中Deployment的MachineDeployment,由MachineDeployment管理一组MachineSet,再由MachineSet管理一组Machine。和控制平面节点机器关系中所述一致,每个实际的控工作节点及其对应的引导配置都在管理集群中以资源的形式存在,管理集群通过控制这些资源,最终由基础设施提供者(如 cluster-api-provider-docker)作用到实际的节点或基础设施之上。

资源介绍
下面我们对涉及到的具体资源做一些简单介绍。
-
Cluster
Cluster 资源是整个工作集群在管理集群中以资源形式的存在。在对工作集群生命周期过程中,尤其是在工作集群部署阶段中,兼具部署状态收集的功能。通过查看 Cluster 资源状态便可掌控整个工作集群部署状态。同时在其资源字段中对整个工作集群的集群网络进行了配置。
关键字段展示:
spec.ClusterNetwork
type ClusterNetwork struct {
// APIServerPort specifies the port the API Server should bind to.
// Defaults to 6443.
// +optional
APIServerPort *int32 `json:"apiServerPort,omitempty"`
// The network ranges from which service VIPs are allocated.
// +optional
Services *NetworkRanges `json:"services,omitempty"`
// The network ranges from which Pod networks are allocated.
// +optional
Pods *NetworkRanges `json:"pods,omitempty"`
// Domain name for services.
// +optional
ServiceDomain string `json:"serviceDomain,omitempty"`
}
-
MachineDeployment
MachineDeployment 的工作方式与 Kubernetes Deployment 类似。MachineDeployment 通过对 2 个 MachineSet(旧的和新的)进行更改来协调对 Machine Spec 的更改。
关键字段展示:
spec.ClusterName
// ClusterName is the name of the Cluster this object belongs to.
// +kubebuilder:validation:MinLength=1
ClusterName string `json:"clusterName"`spec.Replicas
Replicas 就像 Kubernetes Deployment 那样定义期望的 Pod 副本数定义期望的 Machine 数量。
// Number of desired machines. Defaults to 1.
// This is a pointer to distinguish between explicit zero and not specified.
// +optional
// +kubebuilder:default=1
Replicas *int32 `json:"replicas,omitempty"`spec.Selector
匹配具有对应 lable 的 Machine。
// Label selector for machines. Existing MachineSets whose machines are
// selected by this will be the ones affected by this deployment.
// It must match the machine template's labels.
Selector metav1.LabelSelector `json:"selector"`spec.Template
创建 Machine 的模板,此处不展示,请继续向下看 Machine 资源介绍。
spec.Strategy
Machine 更新策略,默认为滚动更新(RollingUpdate),可选策略 RollingUpdate;OnDelete。
type MachineDeploymentStrategy struct {
// Type of deployment.
// Default is RollingUpdate.
// +kubebuilder:validation:Enum=RollingUpdate;OnDelete
// +optional
Type MachineDeploymentStrategyType `json:"type,omitempty"`
// Rolling update config params. Present only if
// MachineDeploymentStrategyType = RollingUpdate.
// +optional
RollingUpdate *MachineRollingUpdateDeployment `json:"rollingUpdate,omitempty"`
}-
MachineSet
MachineSet 的目的是维护在任何给定时间运行的一组稳定的 Machine。但并不是直接独立使用,而是与 MachineDeployment 一起工作,由 Machine Deployments 来协调其状态。
关键字段展示:
spec.ClusterName
// ClusterName is the name of the Cluster this object belongs to.
// +kubebuilder:validation:MinLength=1
ClusterName string `json:"clusterName"`spec.Replicas
// Replicas is the number of desired replicas.
// This is a pointer to distinguish between explicit zero and unspecified.
// Defaults to 1.
// +optional
// +kubebuilder:default=1
Replicas *int32 `json:"replicas,omitempty"`sepc.DeletePolicy
当缩减节点时删除节点的策略,默认为随机(Random),可选 Random;Newest;Oldest。
// DeletePolicy defines the policy used to identify nodes to delete when downscaling.
// Defaults to "Random". Valid values are "Random, "Newest", "Oldest"
// +kubebuilder:validation:Enum=Random;Newest;Oldest
// +optional
DeletePolicy string `json:"deletePolicy,omitempty"`spec.Selector
// Selector is a label query over machines that should match the replica count.
// Label keys and values that must match in order to be controlled by this MachineSet.
// It must match the machine template's labels.
// More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors
Selector metav1.LabelSelector `json:"selector"`spec.Template
创建 Machine 的模板,此处不展示,请继续向下看 Machine 资源介绍。
-
Machine
Machine 是具体工作集群中具体节点在管理集群以资源形式的存在,当一个 Machine 被删除或创建,对应的工作集群的节点也会随之被删除或创建。如果 Machine 资源的字段被修改,那么控制器将会创建新的 Machine 对旧的 Machine 进行替换。
关键字段展示:
spec.ClusterName
// ClusterName is the name of the Cluster this object belongs to.
// +kubebuilder:validation:MinLength=1
ClusterName string `json:"clusterName"`spec.Bootstrap
关联的引导程序资源,对于 kubeadm-bootstrap-provider,关联的是 kubeadmBootstrapConfig。其中 DataSecretName 将会被存储 Bootstrap data 的 secret 的 name 填充。
// Bootstrap encapsulates fields to configure the Machine’s bootstrapping mechanism.
type Bootstrap struct {
// ConfigRef is a reference to a bootstrap provider-specific resource
// that holds configuration details. The reference is optional to
// allow users/operators to specify Bootstrap.DataSecretName without
// the need of a controller.
// +optional
ConfigRef *corev1.ObjectReference `json:"configRef,omitempty"`
// DataSecretName is the name of the secret that stores the bootstrap data script.
// If nil, the Machine should remain in the Pending state.
// +optional
DataSecretName *string `json:"dataSecretName,omitempty"`
}spec.InfrastructureRef
关联基础设施提供程序,Machine 所有字段定义以及引导工作都由基础设施提供者实现
// InfrastructureRef is a required reference to a custom resource
// offered by an infrastructure provider.
InfrastructureRef corev1.ObjectReference `json:"infrastructureRef"`spec.Version
Vesion 定义了对应工作集群节点上所需要安装的 Kubernetes 版本
// Version defines the desired Kubernetes version.
// This field is meant to be optionally used by bootstrap providers.
// +optional
Version *string `json:"version,omitempty"`spec.ProviderID
此字段与此 Machine 对应的工作集群 node 对象上的 ProviderID 一致,通过此字段匹配工作集群 node 对象,并通过工作集群的 API Server 对 node 对象进行访问以及控制。
// ProviderID is the identification ID of the machine provided by the provider.
// This field must match the provider ID as seen on the node object corresponding to this machine.
// This field is required by higher level consumers of cluster-api. Example use case is cluster autoscaler
// with cluster-api as provider. Clean-up logic in the autoscaler compares machines to nodes to find out
// machines at provider which could not get registered as Kubernetes nodes. With cluster-api as a
// generic out-of-tree provider for autoscaler, this field is required by autoscaler to be
// able to have a provider view of the list of machines. Another list of nodes is queried from the k8s apiserver
// and then a comparison is done to find out unregistered machines and are marked for delete.
// This field will be set by the actuators and consumed by higher level entities like autoscaler that will
// be interfacing with cluster-api as generic provider.
// +optional
ProviderID *string `json:"providerID,omitempty"`4. 结束语
Cluster API 是一个十分优秀的项目,从工作集群的部署到伸缩、删除和升级都有非常好的体验(提交 yaml 然后等待 Cluster API 完成工作)。无论您是在何种基础设施上搭建集群,都能在社区找到合适您的 provider。又或许您想自建 provider 适配,只需遵循 Cluster API 的 provider 规范便可快速编写出您的定制程序。
下一篇,我们将带您深入了解 Cluster API 的运行原理。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)