K8S架构发展历史以及基本概念学习笔记
Google --> 10年容器基础架构Borg 2014开源--> 使用GO重构GO基础学习重构K8SKubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。方便伸缩扩容.........
一、核心介绍
1.1、发展历程
- Infrastructure as a Service:基础设施服务
- PlatForm as a service:平台即服务 -> 下一代Docker
- Software as a service:软件即服务
1.2 、分布式资源管理
1.2.1、Apace MESOS
twitter -> 后来迁移
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核。-> 抽象资源+调度任务。
- 支持数万个节点的大规模场景
- 支持多种应用框架,包括Marathon、Singularity、Aurora等;
- 支持HA(基于ZooKeeper实现)
- 支持Docker、LXC等容器机制进行任务隔离;
- 提供了多个流行语言的API,包括Python、Javaden
- 自带了简洁易用的WebUI,方便用户直接进行操作

Mesos采用了经典的“主-从”架构,其中主节点(管理节点)可以使用Zookeeper来做HA。Mesos master 服务奖运行在主节点上,Mesos slave 服务则需要运行在各个计算任务节点上。负责完成具体任务的应用框架,与Mesos master进行交互,来申请资源。
Mesos有三个基本的组件:管理服务(master)、任务服务(slave)以及应用框架(framework)。
- 管理服务(master):跟大部分分布式系统中类似,主节点起到管理作用,将看到全局的信息,负责不同应用框架之间的资源调度和逻辑控制。应用框架需要注册到管理服务上才能被使用。用户和应用需要通用主节点提供的API来获取集群状态和操作集群资源。
- 任务服务(slave):负责汇报本从节点上的资源状态(空闲资源、运行状态等等)给主节点,并负责隔离本地资源来执行主节点分配的具体任务。隔离机制目前包括各种容器机制,包括LXC、Docker等。
- 应用框架(framework):应用框架是实际干活的,包括连个主要组件:
- 调度器:注册到主机诶单,等待分配资源;
- 执行器:在从节点上执行框架指定的任务(框架也可以使用Mesos自带的执行器,包括shell脚本执行器和Docker执行器)
- 应用框架可以分两种:一种是对资源的需求会扩展(比如Hadoop、Spark等),申请后还可能调整;另一种是对资源的需求将会固定(MPI等),一次申请即可。
调度:
对于一个资源调度框架来说,最核心的就是调度机制,怎么能快速高效地完成对某个应用框架资源的分配,是核心竞争力所在。最理想情况下(大部分时候都无法实现),最好是能猜到应用们的实际需求,实现最大化的资源使用率。Mesos为了实现尽量优化的调度,采取了两层(two-layer)的调度算法
调度的基本思路很简单,master先全局调度一大块资源给某个framework,framework自己在实现内部的细粒度调度,决定那个任务用多少资源。两层调度简化了Mesos master自身的调度过程,通过将复杂的细粒度调度交由framework实现,避免了Mesos master成为性能的瓶颈。
调度过程:调度通过offer发送的方式进行交互。一个offer是一组资源例如<1 CPU ,2GB Mem>>。
基本调度过程如下:
- Slave节点会周期性汇报自己可用的资源给master;某个时候,master收到应用框架发来的资源请求,根据调度策略,计算出来一个资源offer给framework;framework收到offer后可以决定要不要,如果接受的话,返回一个描述,说明自己希望如何使用和分配这些资源来运行某些任务(可以说明只希望使用部分资源,则多出来的会被master收回);
- master则根据framework答复的具体分配情况发送给slave,以使用framework的executor来按照分配的资源策略执行任务。
具体给出一个例子:
某从节点想主节点汇报自己有<4 CPU , 8 GB Mem>的空闲资源,同时,主节点看到某个应用框架请求<3 CPU , 6 GB Mem>,就创建一个offer<slave #1, 4 CPU, 8GB> 把满足的资源发给应用框架。应用框架(的调度器)收到offer后觉得可以接受,就恢复主节点,并告诉主机节点希望运行两个任务:一个占用<1CPU ,2GB Mem>, 一个占用<2 CPU , 4GB Mem>。主节点收到任务信息后分配任务到从节点上运行(实际上是应用框架的执行器来负责执行任务)。任务执行结束后资源可以被释放出来。剩余则资源还尅继续分配给其他应用框架或任务。应用框架在收到offer后,如果offer不满足自己的偏好(例如希望继续使用上次的slave)则可以选择拒绝offer,等待master发送新的offer过来。另外可以通过过滤机制加快资源的分配过程。
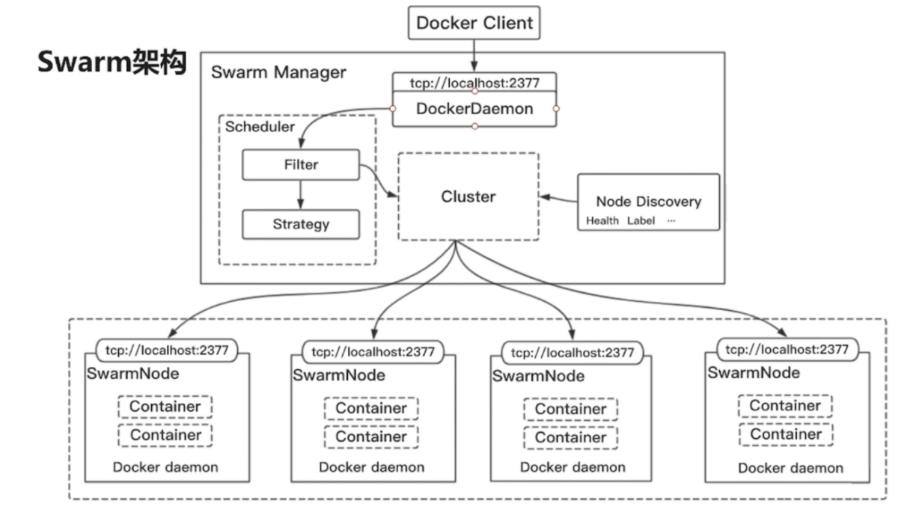
1.2.2、Docker Swarm
Docker Swarm --> 只提供Docker组件
Swarm是Docker公司推出的用来管理docker集群的平台,几乎全部用GO语言来完成的开发的,代码开源在https://github.com/docker/swarm, 它是将一群Docker宿主机变成一个单一的虚拟主机,Swarm使用标准的Docker API接口作为其前端的访问入口,换言之,各种形式的DockerClient都可以直接与其进行通讯,方便用户部署集群主机服务。
Docker Compose 在单一主机上面部署服务
Docker Swarm 多台主机上面管理服务
Swarm deamon只是一个调度器(Scheduler)加路由器(router),Swarm自己不运行容器,它只是接受Docker客户端发来的请求,调度适合的节点来运行容器,这就意味着,即使Swarm由于某些原因挂掉了,集群中的节点也会照常运行,放Swarm重新恢复运行之后,他会收集重建集群信息。

Docker Client使用Swarm对 集群(Cluster)进行调度使用,Swarm是典型的master-slave结构,通过发现服务来选举manager。manager是中心管理节点,各个node上运行agent接受manager的统一管理,集群会自动通过Raft协议分布式选举出manager节点,无需额外的发现服务支持,避免了单点的瓶颈问题,同时也内置了DNS的负载均衡和对外部负载均衡机制的集成支持
- Swarm:集群管理和编排使用的是SwarmKit

- Node:代表集群中的一个实例信息(一个物理机),上面可以部署多个容器

- Service:表示Node中的一个服务信息,承载在一个容器中

- Task:表示一个docker容器中实际执行的命令(分配任务)
1.2.2.2、Swarm 集群模式特性
- 批量创建服务:创建一个overlay的网络,用来保证在不同主机上的容器网络互通的网络模式
- 强大的集群的容错性 && 服务节点的可扩展性:
容器副本中的其中某一个或某几个节点宕机后,cluster会根据自己的服务注册发现机制,以及之前设定的值–replicas n,在集群中剩余的空闲节点上,重新拉起容器副本。整个副本迁移的过程无需人工干预,迁移后原本的集群的load balance依旧好使!不难看出,docker service其实不仅仅是批量启动服务这么简单,而是在集群中定义了一种状态。Cluster会持续检测服务的健康状态。- 复制服务(–replicas n):在一个节点下Node下进行容器的复制操做
- 全局复制服务(–mode=global):将一个容器复制发布到全局的节点中
- 调度机制
由cluster的server端去选择在哪个服务器节点上创建并启动一个容器实例的动作。它是由一个装箱算法和过滤器组合而成。每次通过过滤器(constraint)启动容器的时候,swarm cluster 都会调用调度机制筛选出匹配约束条件的服务器,并在这上面运行容器。
集群创建过程:
1)发现Docker集群中的各个节点,收集节点状态、角色信息,并监视节点状态的变化
2)初始化内部调度(scheduler)模块
3)创建并启动API监听服务模块
1.2.3、Kubernetes
Google --> 10年容器基础架构Borg 2014开源–> 使用GO重构[[GO基础学习]]重构K8S
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。方便伸缩扩容
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来曝露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
-
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
-
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
-
自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来为容器分配资源。
-
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
-
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
-
弹性伸缩
特点:
- 采用GO开发轻量级,消耗资源小
- 开源
- 弹性伸缩
- 内部实现自动负载均衡:采用IPVS -> [[IPVS(IP Virtual Server) && LVS (Linux Virtual Server)]]
1.2.4、区别
- 可伸缩性 && 弹性
- Mesos对于运行着大规模集群的公司来说是最好的选择,在模拟测试中,其最高可以运行5万多个节点
- Kubernetes和Swarm都被限制在1000个节点(大约5万个容器)。同时Mesos在大规模解决方案实践上拥有强大的话语权,如Twitter这样的大公司都在使用。
Swarm:适合中小型系统,在这个范畴它的价值和可扩展性最好
Kubernetes:适合中等规模高度冗余的系统
Mesos:目前最稳定的平台,适合大规模系统
#todo
- 其他区别
二、K8S 组件 && 结构
2.1、核心概念
2.1.1、NODE
Node是Pod真正运行的主机,可以物理机,也可以是虚拟机。为了管理Pod,每个Node节点上至少要运行container runtime(容器运行环境:比如docker或者rkt)、kubelet和kube-proxy服务。
- 地址:包括hostname、外网IP和内网IP
- 条件(Condition):包括OutOfDisk、Ready、MemoryPressure和DiskPressure
- 容量(Capacity):Node上的可用资源,包括CPU、内存和Pod总数
- 基本信息(Info):包括内核版本、容器引擎版本、OS类型等
如果node 被删除,所拥有的pod会自动分流到其他的node,但是存在特殊的无法被分流的pod
2.1.2、POD
- 是一个K8S中的最小的部署单元、管理单元是一组容器的集合
- 一个POD中可以有多个容器Container
- 一个POD之间的容器可以相互通讯,共享网络
- 生命周期是短暂的,服务器重启会丢失
2.1.3、Controller
创建POD进行部署
2.1.4、Service
- 定义一组POD的访问方法
通过Service统一接口进行访问
2.1.5、核心架构

架构举例:

- Master:主节点
- API Server:集群入口RestFul风格,处理到请求,交给ETCD存储
- ControllerManager:处理集群常规后台任务,一个资源对应一个控制器
- Scheduler:节点调度器,选择不同NODE节点进行选择调度
- ETCD:K/V 存储数据,集群相关基本数据
- Node:工作节点
- Kubelet:master 派到一个容器节点管理节点的代理
- Kube-Proxy:网络之间的维护代理,实现负载均和一级网络上代理
实际组件交互例子:

每一个厂都有一个Kubelet代理,负责当前应用启停和销毁,当出现问题的时候由Kubelet进行处理,回报信息给秘书(ApiServer)-> Controller - manager(领导人-决定)
-> 交给决策者进行处理(动态调度进行调度处理)
-> 存储决策文件
-> 分配决策
-> 存储决策文件到档案库ETCD
-> ApiServer进行通知Kubelet进行处理
当应用构建结束之后,应用之间相互调用由Kube-Proxy(门卫)进行统一处理,打通整个服务,门卫之间信息相互同步。
最终实际上整个集群由KubeCtl(程序员命令)进行直接控制,启动开启集群,这个命令实质上也是发送个ApiServer进行实际处理。
2.2、搭建K8S集群
[[K8S集群搭建]]
搭建工具:
- Kubeadmin:K8S部署工具,使用Kubeadm Init、Kubeadm Init
- 二进制包:手动部署每个组件

2.2.1、前置安装
- 一台或者多台系统
- 2G或者更多RAM
- CPU:2C或者更多
- 硬盘30G以上
- 机器间网络互通
- 必须访问外网
- 禁止SWAP分区
- 临时禁止: swapoff -a
- 永久关闭:vim /etc/fstab -> 注释掉最后一行Swap
2.2.2、KubeAdmin
是官方社区推出的快速部署KuberNetes集群工具,可以通过一下两个命令实现快速搭建。
2.2.2.1、操作系统安装
集群分配:
192.168.153.131 k8s_master
192.168.153.129 slave1
192.168.153.130 slave2
192.168.153.128 slave3
root账户密码为:
root : 123456789
- 开启root [[Ubuntu开启Root远程访问]]
- 关闭防火墙 yes
#关闭防火墙
#临时
systemctl stop firewalld
#永久关闭
systemctl disable firewalld
出现如下报错,请使用apt install -y firewalld

-
- 安装:
sudo apt install policycoreutils selinux-utils selinux-basics- 激活:
sudo selinux-activate - 设置启用:
sudo selinux-config-enforcing - 重启系统
- 查看SELinux 状态
- 激活:
- 关闭:
- 打开:
/etc/selinux/config - 设置:
SELINUX=disabled - 重启
- 打开:
- 安装:
-
关闭Swap yes
# 临时
swapoff -a
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
- 方便访问设置名称
#设置主机名称
hostnamectl set-hostname xxxx
- 设置Host地址(只需要在Master中设置)
cat >> /etc/hosts <<EOF
192.168.153.131 k8s_master
192.168.153.129 slave1
192.168.153.130 slave2
192.168.153.128 slave3
EOF
- 设置流量转发 yes
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
- 设置同步时间 yes
apt install ntpdate -y
ntpdate time.windows.com
- 安装Docker
#ubuntu
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
#centos
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
-
Docker 加速 [[镜像加速]]
-
换源 [[Ubuntu 换源]]
-
设置开机自启动
systemctl enable docker && systemctl start docker
- 重启Docker
systemctl restart docker
2.2.2.2、安装K8S
注意版本兼容性问题
2.2.2.2.1、前置安装
所有节点都进行安装
- 安装
kubelet、kubeadm、kubect- 安装证书工具:
sudo apt-get install -y apt-transport-https ca-certificates curl - 安装证书:
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg - 添加K8S软件源:
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list - 更新版:
sudo apt-get update - 安装K8S:apt install kubeadm=1.23.8-00 kubelet=1.23.8-00 kubectl=1.23.8-00
- 开机自启:
systemctl enable kubelet
- 安装证书工具:
2.2.2.2.2、安装部署主节点
- 执行初始化init:
kubeadm init \
--apiserver-advertise-address=(master节点ip) \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.8 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all
成功提示:

Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.153.131:6443 --token 080k86.3w1djwjhxe5q4l4p --discovery-token-ca-cert-hash sha256:8b82312bf868a68919b8de12cbbf7a97be20cd795d816332bcc9f3d81a0838d3
查看主节点工作情况kubeadm get nodes:

2.2.2.2.2、安装部署从节点
-
在从节点中执行命令:
kubeadm join 192.168.153.131:6443 --token 080k86.3w1djwjhxe5q4l4p --discovery-token-ca-cert-hash sha256:8b82312bf868a68919b8de12cbbf7a97be20cd795d816332bcc9f3d81a0838d3成功结果:

-
主节点中查看状态:

注:执行时候出现:

解决方案:执行kubeadm reset恢复设置,之后再次执行上述命令
2.2.2.2.3、安装网络插件
root执行:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
插件可能因为网络原因执行失败,这里附上文件kube-flannel.yml,使用kubectl apply -f进行执行
---
kind: Namespace
apiVersion: v1
metadata:
name: kube-flannel
labels:
pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-flannel
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-flannel
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
#image: flannelcni/flannel-cni-plugin:v1.1.0 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.1.0
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
#image: flannelcni/flannel:v0.18.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.18.1
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
#image: flannelcni/flannel:v0.18.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.18.1
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
查看当前节点pods状态 kubectl get pods -n kube-system:
观察是否ready为全部上线,图例如下:

2.2.2.2.4、查看安装结果
kubectl get nodes

2.2.2.2.5、验证安装
创建一个Nginx集群:
- 执行命令:
kubectl create deployment nginx --image=nginx - 查看状态:
kubectl get pod
等待成为Running则执行下述,开启暴露端口:
kubectl expose deployment nginx --port=80 --type=NodePort

查看状态:
kubectl get pod,svc

查看暴露的端口是,30612,从集群中任意节点都可以访问 -> 测试如下:

2.2.3、二进制包
未做,待更
2.2.4、总述
KubeAdmin:
- 安装虚拟机
- 更新软件源
- 配置运行环境
- 关闭防火墙
- 关闭Swap
- 关闭Selinux
- 设置Ipv4 -> iptables
- 设置host与主机名
- 时间同步
- 所有节点均安装 Docker、KubeAdm、Kubelet、KubeCtl
- 修改Docker镜像源
二进制:
三、核心组件
3.1、KubeCtl
是一个K8s集群的管理工具,实现对集群的基本管理和处理。
语法:kubectl command type name flags
- command:对资源的操做
- create
- get
- describe
- delete
- type:指定资源类型,大小写敏感
- pod
- pods
- node
- …
- name:资源名称。大小写敏感,不加就是全部
示例:kubectl get nodes slave1

kubectl get pod,svc:查看pod运行在线情况

kube get cs:查看健康状态

kubectl --help:命令行工具 (kubectl) | Kubernetes
3.1.1、基础命令

3.1.2、部署和集群管理

3.1.3、故障调试

3.1.4、其他命令

3.2 Yaml文件(资源编排)
- 使用空格做为缩进
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 低版本缩进时不允许使用Tab 键,只允许使用空格
- 使用#标识注释,从这个字符一直到行尾,都会被解释器忽略
3.2.1、KubeCtl create生成Yaml
kubectl create deployment web --image=nginx -o yaml --dry-run
生成文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
3.2.2、kubeCtl get导出Yaml文件
kubectl get deploy nginx -o=yaml > my.yaml
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2022-07-13T08:06:10Z"
generation: 1
labels:
app: nginx
name: nginx
namespace: default
resourceVersion: "4889"
uid: e235528a-958f-4b83-8205-cba3b0f0255d
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2022-07-13T08:07:57Z"
lastUpdateTime: "2022-07-13T08:07:57Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2022-07-13T08:06:10Z"
lastUpdateTime: "2022-07-13T08:07:57Z"
message: ReplicaSet "nginx-8f458dc5b" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
3.3、POD
3.3.1、基本概念
- 是K8S中最小的部署单元
- K8S不会直接处理容器,实际上是管理POD并且一个POD是一组容器的集合。
- 一个POD中的每个容器都共享一个POD网络的命名空间(一个POD中网络共享)
- POD是短暂的,动态的
- 每个POD都包含一个根容器

3.3.2、特点
为什么管理的不是容器?
因为正常处理情况下:
- 容器使用Docker创建的,一个docker对应一个容器、一个单进程并且对应运行一个应用程序。
- docker进程是一个守护进程,一直监听活动。当一个docker中运行多个应用程序的时候不方便管理,一次docker容器中实际上是一个服务一个进程。
- POD是一个多进程的设计,可以同时运行多个应用程序。
- 一个POD多个容器,一个容器运行一个应用程序,因此POD是一个多线程容器。
- 亲密性
- POD存在为了亲密性交互,POD内部进行交互
- 网络之间的交互远程的调用
- 两个应用之间频繁调用。
3.3.3、Pod实现机制
3.3.3.1、共享网络
1. 容器之间相互隔离,通过namespace和group组进行隔离
多个容器在同一个namespace中就可以实现网络共享。
POD在创建过程中首先会创建一个根容器(Pause容器也叫Info容器)当你每创建一个用户业务
容器都会把用户容器加入到Info容器中,也就是变成了处于同一个名称空间,一个mac地址一个IP地址

yaml示例:

3.3.3.2、共享存储
1. 持久化数据类型:
1. 日志数据
2. 业务数据
共享存储由数据卷Volumn构成,通过数据卷进行持久化存储,映射数据/

yaml示例:

3.3.3.3、镜像拉取 imagePullPolicy
1. IfNotPresent:不存在的时候拉取(默认)
2. Always:每次创建POD都会自动重新拉取
3. Never:POD从不主动拉取,必须手动拉取

3.3.3.4、资源限制
Request:调度资源大小
Limit:最大大小
本身实际上是由Docker来限制资源的


3.3.3.5、POD 重启机制 restartPolicy
1. Always:容器终止后自动重启(适用于一般使用容器)
2. OnFailure:容器异常退出,状态码非零重启
3. Never:容器终止从不退出


3.3.3.6、健康检查
原始情况我们检测的是容器是否运行,但是比如Java发生OOM的时候,容器时正常的,但是业务不正常。因此需要从业务层面监控。
1. livenessProbe(存活检查):检查失败就杀掉容器,根据POD 的restartPolicy进行处理
2. readinessProbe(就绪检查):检查失败会从service endpoint中剔除


3.3.3.7、调度策略
3.3.3.7.1、创建POD

- Master 节点:
- create pod -> ApiServer ->存储到etcd
- Scheduler -> 监控ApiServer是否存在新的POD创建,根据ETCD中POD信息,依照自己的调度算法进行调度,将其调度到某一个节点 -> 存储调度信息到ETCD
2.NODE节点: - kubelet -> ApiServer -> 读取ETCD中分配给当前节点的POD信息 -> 通过Docker创建容器 -> 返回状态给ApiServer -> 存储到ETCD中
3.3.3.7.2、POD调度
影响调度的因素:
- POD资源限制:根据request中限制的内存CPU需求找到满足条件的NODE进行调度。

- 节点选择器标签
nodeSelector:节点选择器,下图选择env_role:dev 选择的开发环境

根据设置的分组名称:组名,进行调度
1. 设置分组别名 kubectl label node node1 env_role=dev这里将node1起一个tag(名字随意)为dev标签。

查看node标记的资源标签:kubectl get nodes xxx --show-labels
3. 节点亲和性
nodeAffinity:根据节点标签约束来决定Pod调度放到哪个节点上面,有的话满足条件,不满足也可以正常使用。
1. 硬亲和性(requiredxxx):其中标注的条件必须满足(这里是目前环境中必须满足dev test),不满足就会进入等待。

- 软亲和性(preferref):表示尝试满足,不保证一定可以满足目标设置

weight:权重
key:环境分组Key
operator:支持常见支持符
1. In:里面包含
2. . NotIn:不包含(反亲和性)
3. Exists:存在
4. GT:大于
5. LT:小于
6. DowsNotExists:不存在
nodeSelector和nodeAffinity:POd调度到某些节点上,POd属性,调度时候实现。
- 污点 && 污点容忍
Taint污点:不做普通的资源分配调度,是一个节点属性 实际上是一个特殊分配
场景:- 专用节点
- 特定硬件节点
- 基于污点驱逐(分配到出他以外的节点)
使用污点: - 查看污点
kubectl describe node xxxx | grep Taintmaster默认存在污点- NoSchedule:当前节点一定不被调度
- NoExecute:不会调度,会驱逐当前node中其他pod到其他Node中
- PreferNoSchdule:当前节点尽量不被调度
- 为节点添加污点:
kubectl taint node xxx key=value:污点的三个参数 - 删除污点:
kubectl taint node xxx key:污点值-
污点容忍:
配置之后虽然节点存在污点,但是仍有可能被调度到

key:污点设置的key value:污点设置的value
3.3.3.7.3、彻底删除一个POD
由于每一个POD是由Deployment进行创建管理的,因此执行kubectl delete pod xxx其实无效只是删除了一个POD而已,但是存在容灾控制,因此需要先删除相应的Deployment,之后其管理的POD会自动被删除。
- 查看所有的Deployment:
kubectl get deployment - 删除对应的Deployment:
kubectl delete deployment xxx - 查看对应的POD是否被删除:
kubectl get pods
3.4、Controller
在集群中管理运行容器的对象
3.4.1、POD和Controller的关系
1. POD和Controller之间通过Label标签建立关系Selector

2. POD通过controller实现应用的运维,比如弹性伸缩,滚动升级等
3.4.2、Deployment控制器应用场景
Web服务、微服务
1. 部署无状态应用
2. 管理POD和ReplicaSet(副本)
3. 部署,滚动升级等功能
3.4.4、使用Depoyment控制器部署 – Yaml文件
命令行:kubectl create deployment web --image=nginx --dry-run -o=yaml生成一个yaml并不运行
打开的yaml文件:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector: #控制器绑定POD标签的选择器
matchLabels: #标签
app: web
strategy: {}
template: #POD模板
metadata:
creationTimestamp: null
labels: #POD标签
app: web #值
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
部署yaml文件:kubectl apply -f web.yaml

- 导出一个yaml
kubectl create deployment web --image=镜像名称 --dry-run -o=yaml - 使用命令部署
kubectl apply -f xxx.yaml - 查看状态
kubectl get pods - 对外暴露端口
kubectl expose deployment web --port=pod端口 --type=NodePort --target-port=外部端口 --name=发布名称 -o=yaml > web-port.yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2022-07-18T06:56:05Z"
labels:
app: web
name: web1
namespace: default
resourceVersion: "31313"
uid: 1bc421ea-5ce8-4f54-ab4a-17e7fdfc1e4a
spec:
clusterIP: 10.102.187.245
clusterIPs:
- 10.102.187.245
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- nodePort: 32019
port: 80
protocol: TCP
targetPort: 80
selector:
app: web
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
发布:kubectl apply -f xxx.yaml

3.4.5、部署应用的升级回滚 && 弹性伸缩
先部署一个应用:设置副本和版本
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.14
name: nginx
resources: {}
status: {}
~
执行kubectl apply -f xxxx.yaml进行部署

3.4.5.1、升级
- 执行升级操做:
kubectl set image deployment 应用名称 容器名称=容器名称:版本号
这里对应kubectl set image deployment web nginx=nginx:1.15

升级中:

在这个过程中,实际上副本只设置了2个,但是这里有三个,因为一个个升级,并且在下载启动设置中旧版本继续运行,最后将旧的替换掉


使用命令进行查看升级状态: kubectl rollout status deployment web

3.4.5.2、回滚
回滚版本:
-
查看历史版本:
kubectl rollout history deployment web

-
回到上一个版本:
kubectl rollout undo deployment web


-
回滚到指定版本:
kubectl rollout undo --to-revision=1 deployment web

3.4.5.3、弹性伸缩
kubectl scale deployment web --replicas=10

持续更新,学习中ing…

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)