k8s中工作负载
k8s中工作负载和资源对象
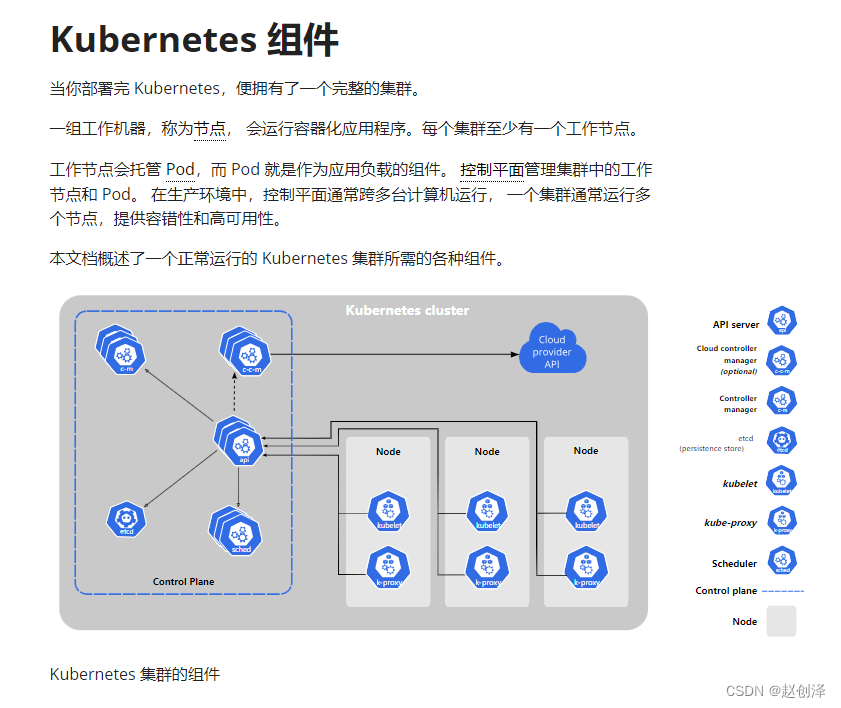
先上图,这是kubernetes官网上的架构图,简单明了。

工作负载(资源对象):
起初还搞不清楚工作负载和资源对象的关系,最后一查才发现工作负载被包含于资源对象,两者的关系是挺微妙。下面详细解释下两者的含义:
工作负载:是一种资源对象,用于定义和管理容器化应用程序的运行方式。提起工作负载,我们脑海中常浮现出的是statefulset、daemonset、deployment、job、cronjob。由于工作负载时被包含于资源对象,那么上述五种类型也是资源对象,同时也是工作负载。
资源对象:指在k8s上创建的资源实例。这个其实很好理解,听我娓娓道来。在k8s中将所有的内容全部抽象为资源,资源实例化后是对象。纳尼,这怎么到面向对象编程了,其实这样的表示只是让我们对资源对象的理解更容易罢了。提到资源对象,那脑子一下把k8s中的都包含了,有pod、replicaset、deployment、service、endpoint、ingress、ingress-control、configmap、pv/pvc等等。
整体介绍下:
- Pod(Pod):容器的最小调度单位,可以包含一个或多个相关容器。
- Service(服务):为一组具有相同标签的 Pod 提供统一访问入口,并提供负载均衡能力。
- Ingress(入口):通过定义规则来管理从外部访问集群内 Service 的流量。
- ConfigMap(配置映射):存储应用程序的配置数据,以键值对的形式提供给容器。
- Secret(密钥):用于存储敏感数据,如密码、令牌等,并将其安全地传递给容器。
- Volume(卷):在容器之间共享和持久化数据的抽象概念。
- Job(作业):用于创建一次性任务,会运行一个或多个 Pod 直到完成指定的工作。
- CronJob(定时作业):根据用户定义的时间表定期运行 Job。
- Namespace(命名空间):用于在集群内部分隔资源,实现多租户的隔离和资源管理。
- ServiceAccount(服务账户):与 Pod 关联的身份验证信息,并授予 Pod 访问其他资源的权限。
详细介绍:
Deployment(部署):用于控制 Pod 的创建、更新和删除,确保应用的稳定运行。
下图就可以立马理解deployment、replicaset(副本集)、pod这个三者的关系。优雅永不过时。

Deployment 一个非常重要的功能就是实现了 Pod 的滚动更新。
StatefulSet(有状态副本集):管理有状态应用程序的创建、更新和删除,确保每个 Pod 都有唯一的网络标识和稳定的持久化存储。可以处理 Pod 的启动顺序,为保留每个 Pod 的状态设置唯一标识。
问题来了,什么是有状态什么是无状态? 直接上硬货。
-
无状态服务(Stateless Service):该服务运行的实例不会在本地存储上持久化需要的数据,并且多个实例对于同一个请求响应的结果是完全一致的。 -
有状态服务(Stateful Service):就和上面的概念是对立的了,该服务运行的实例需要在本地存储持久化数据。
那么,经典面试题就来了。statefulSet和Deployment最大的区别就是:deployment里的pod副本是用的相同的存储,而statsfulet中的pod副本有自己的存储,这是他们最大的区别。
statefulset(有状态服务) 特点:
- 稳定的、唯一的网络标识符 (例如:etcd 配置文件,节点地址发生变化,将无法使用)
- 稳定的、持久化的存储
- 有序的、优雅的部署和缩放(例如:mysql 主从关系,先启动主,再启动从)
- 有序的、优雅的删除和终止
- 有序的、自动滚动更新
DaemonSet(守护进程集):确保集群中的每个节点都运行一个 Pod 实例,用于在整个集群中运行系统级任务。一看daemon那不就是守护进程吗,那肯定是每个节点上都需要有守护进程才可以,说白了就是在每个节点部署一个 Pod副本。上图增加理解:

使用场景:
-
集群存储守护程序:如 glusterd、ceph 要部署在每个节点上以提供持久性存储;
-
节点监控守护进程:如 Prometheus 监控集群,可以在每个节点上运行一个
node-exporter进程来收集监控节点的信息; -
日志收集守护程序:如 fluentd 或 logstash,在每个节点上运行以收集容器的日志
-
节点网络插件:比如 flannel、calico,在每个节点上运行为 Pod 提供网络服务。
这个三个重要的工作负载也是资源对象就介绍到这里。
还有两个负载均衡的资源对象(service和ingress)也需要介绍下,同样非常重要。
Service 是一种抽象的对象,它定义了一组 Pod 的逻辑集合和一个用于访问它们的策略。其实这个概念和微服务非常类似。一个 Serivce 下面包含的 Pod 集合是由 Label Selector 来决定的。
service存在的意义:Service引入主要是解决Pod的动态变化,提供统一访问入口。包含两个方面
- 防止Pod失联,准备找到提供同一个服务的Pod(服务发现)
- 定义一组Pod的访问策略(负载均衡)
service的功能:
- 为pod提供负载均衡(iptables、ipvs)
- 动态感知pod的变化,会把pod ip变化更新到负载均衡

常见的service的类型:
service的类型有:ClusterIP、NodePort、LoadBalancer、ExternalName、externalIPs.
1 ClusterIP: 默认的service服务类型。通过集群内部的IP暴露服务,选择该值。局限是只能够在集群内部进行访问。
2 Nodeport:对外暴露应用。通过node节点的ip和静态端口进行暴露服务。通过请求nodeIP:nodeport可以从集群的外部访问一个NodePort服务。端口的范围:30000-32767。局限是若都对用户暴露ip和端口,多台node该使哪台用户访问呢?
3 LoadBalancer:对外暴露应用,使用公有云。在每个node上启用一个端口来暴露服务。
注意点:LoadBalancer也会自动生成NodePort,而NodePort也会自动生成ClusterIP的。
4 ExternalName:通过返回CNAME和它的值,可以将服务映射到externalName字段的内容。
该类型更多用于服务迁移场景。
5 externalIPs:确保使用哪个 IP 来访问 Kubernetes 集群,使用外部 IP Service 类型,我们可以将Service 绑定到连接集群的 IP。
还有一个新内容Endpointslices:
与之对应的是一个Endpoints(EP)。Endpoints 是 Kubernetes 中的一个资源对象,存储在 etcd中,用来记录一个 Service 对应一组 Pod 的访问地址,一个 Service 只有一个 Endpoints 资源,Endpoints 资源会去观测 Pod 集合,只要服务中的某个 Pod 发生变更,Endpoints 就会进行同步更新。
Endpoints的缺点:kubernetes限制单个Endpoints对象中可以容纳的端口数量。且一个service只有一个Endpoints资源,这意味着她需要为支持相应服务的每个pod存储ip等网络信息。
Endpoints资源的缺陷:若一个端点发生变更,将会导致整个Endpoints资源更新。那么当业务需要进行频繁端点更新时,需要一个巨大的API资源被相互传递,这会影响到kubernetes组件的性能。
于是Endpointslices对象就出现了,提供了一种可扩展和可拓展的替代方案,缓解处理大量网络端点带来的性能问题。
举例介绍:
假设我们有一个 2000 个 Pod 副本的服务,它最终生成的Endpoints 资源对象会很大(比如 1.5MB (etcd 具有最大请求大小限制1.5MB),还会截断成 1000),在生产环境中,如果该服务发生滚动更新或节点迁移,那么 Endpoints 资源将会频繁变更,当该列表中的某个网络端点发生了变化,那么就要将完整的 Endpoint 资源分发给集群中的每个节点。如果我们在一个具有 3000 个节点的大型集群中,这会是个很大的问题,每次更新将跨集群发送 4.5GB 的数据(1.5MB*3000 ,即 Endpoint 大小*节点个数),并且每次端点更新都要发送这么多数据。想象一下,如果进行一次滚动更新,共有 2000 个 Pod 全部被替换,那么传输的数据量将会是TB 级数据。这不进对集群内的网络带宽浪费巨大,而对 Master 的冲击非常大,会影响 Kubernetes 整体的性能。

如果使用了 Endpointslices,假设一个服务后端有 2000 个 Pod,我们可以让每个 Endpointslices 存储 100 个端点,最终将获得 20 个 Endpointslices。添加或删除 Pod 时,只需要更新其中 1 个 Endpointslice 资源即可,这样操作后,可扩展性和网络可伸缩有了很大的提升。
比起在流量高峰时,服务为了承载流量,扩容出大量的 Pod,Endpoints 资源会被频繁更新,两个使用场景的差异就变得非常明显。更重要的是,既然服务的所有 Pod IP 都不需要存储在单个资源中,那么我们也就不必担心 etcd 中存储的对象的大小限制。
Endpoints 和 Endpointslice 两种资源的不同之处:
-
Endpoints 适用场景:
-
有弹性伸缩需求,Pod 数量较少,传递资源不会造成大量网络流量和额外处理。
-
无弹性伸缩需求,Pod 数量不会太多。哪怕 Pod 数量是固定,但是总是要滚动更新或者出现故障的。
-
-
Endpointslice 适用场景:
-
有弹性需求,且 Pod 数量较多(几百上千)。
-
Pod 数量很多(几百上千),因为 Endpoints 网络端点最大数量限制为 1000,所以超过 1000 的 Pod 必须得用 Endpointslice。
-
另一种负载均衡的资源对象是ingress:
Ingress:用来暴露服务给外部用户。是从 Kuberenets 集群外部访问集群的一个入口。将外部的请求转发到集群内不同的 Service 上,然后再加上一个域名规则定义,路由信息的刷新依靠 Ingress Controller 来提供。

Ingress公布了从集群外部开到集群内部服务的HTTP和HTTPS路由的规则集合,而具体实现流量路由则是由Ingress Controller负责。ingress的命名空间是从svc中获取,不需要自定义命名空间。

ingress就是为了弥补nodeport的不足而产生的:
NodePort存在的不足:
• 一个端口只能一个服务使用,端口需提前规划;
• 只支持4层负载均衡;
• 注意:我们知道,NodePort它是要到我们节点上的ClusterIp,然后通过ClusterIp去帮我们做一下负载,其实它的调用链是多了一层。ingress主要是实现了一个7层的负载均衡,ingress也支持一些4层的负载均衡; ingress controller虽然也支持4层的,但工作中如果有4层需求,也是直接使用service就好了。
基于端口是一种分流的方式,不可能一个端口分2个流量,除非这个程序内部是基于7层的,可以在协议层进行一些分流;而我们的svc是4层的,包括iptables、ipvs都是基于4层进行转发的,user -> nginx upstream ->代理多个web服务器。
注明出处: 明心静性 | 彦

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)