面对大规模 K8s 集群,如何先于用户发现问题?,源码+原理+手写框架
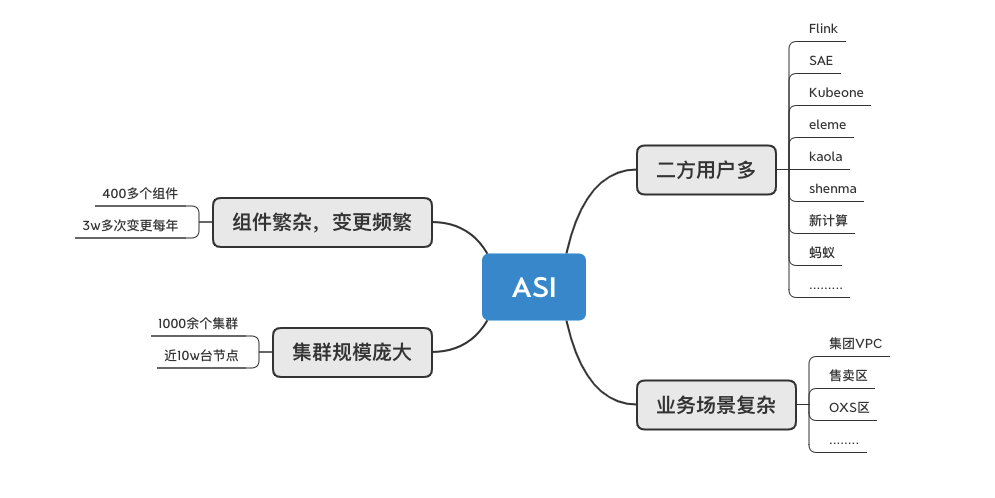
从组件维度看,我们目前有几百个组件,每年有几万次的组件变更。频繁的组件变更如何在稳定性和效率之间取得权衡,怎样让变更时更稳定,怎样让灰度更确信,从而降低爆炸半径?从集群维度看,目前有上千个集群和海量节点,碰到的集群/节点问题较多,监控链路覆盖比较繁复,怎样让集群运行时更加可信?从二方用户和业务场景看,我们支持了大量的集团二方用户,同时业务场景也非常复杂,怎样保证各有特色的业务场景都能得到一致的细心
-
从组件维度看,我们目前有几百个组件,每年有几万次的组件变更。频繁的组件变更如何在稳定性和效率之间取得权衡,怎样让变更时更稳定,怎样让灰度更确信,从而降低爆炸半径?
-
从集群维度看,目前有上千个集群和海量节点,碰到的集群/节点问题较多,监控链路覆盖比较繁复,怎样让集群运行时更加可信?
-
从二方用户和业务场景看,我们支持了大量的集团二方用户,同时业务场景也非常复杂,怎样保证各有特色的业务场景都能得到一致的细心关照?

基于长期的集群管理经验,我们有如下预设:
- 数据监控作为正向链路,无法无死角覆盖所有场景。即使链路中各个节点的监控数据正常,也不能 100% 保证链路可用。
-
集群状态每时每刻都在变化,各个组件也在不停地更新升级,同时链路上的每个系统也在不停的变更,监控数据的覆盖永远是正向的追赶,只能逼近 100% 全覆盖而无法完全达到。
-
即使整个集群链路中所有组件/节点的监控数据都正常,也不能保证集群链路 100% 可用。就如同业务系统一样,看上去都是可用的,没有问题暴露。但只有通过全链路压测实际探测过整个链路后,才能得到实际可用的结论。
-
你要正向证明一个东西可用,需要举证无数的例子。而如果要反向证明不可用,一个反例就够了。数据监控链路只能逼近全覆盖,而无法保证真正全覆盖。
- 大规模场景下,数据无法达到 100% 的完全一致性。
- 当集群规模足够大时,数据的一致性问题将会愈加显现。比如全局风控组件是否全集群链路覆盖?相关流控配置是否全集群链路推平?pod 主容器时区是否与上层一致?集群客户端节点证书是否有即将过期?等等问题,一旦疏忽,将有可能酿成严重的故障。
只有弥补上述两类风险点,才能有底气真正做到先于用户发现问题。我们解决上述两类风险的思路分别是:
- 黑盒探测
- 所谓黑盒探测,既模拟广义上的用户行为,探测链路是否正常。
- 定向巡检
- 所谓巡检,既检查集群异常指标,找到已有或可能将存在的风险点。
基于以上思路,我们设计并实现了 KubeProbe 探测/巡检中心,用于弥补复杂系统的正向监控的不足,帮助我们更好、更快地发现系统风险和线上问题。
=======================================================================
1)黑盒探测
不知道你是否也经历过一条链路上各个系统监控数据都正常,但是实际链路流程就是跑不通。或者因为系统变化快,监控覆盖不到 100% 的场景总是会有遗漏,导致影响到了用户却没有报警,对用户没有实质影响却报警频发从而疲于奔命。
如果一个系统开发者自己都不使用自己的系统,那么怎么可能先于用户发现系统问题呢?所以要先于用户发现系统问题,首先我们自己就得先成为用户,而且一定是使用最多,了解最深,无时无刻不在使用和感知系统状况的用户。
所谓黑盒探测,就是让自己成为自己的用户,模拟广义"用户"的行为去对集群/组件/链路等待待测对象做探测。注意,这里的"用户"并不仅仅是狭义上使用系统的同学,而是广义用户。比如,etcd 的"用户"是 APIServer,而 ASI 的"用户"可能是某个通过 APIServer 操作集群的同学,也可能是 Normandy 发起的发布/扩容/缩容操作。

我们希望 KubeProbe 能在 变更时(监听到集群状态发生变化/组件变更/组件发布/系统升级等等事件)/运行时(周期,高频)/故障恢复时(手动),通过周期/事件触发/手动触发,执行各种不同类型的黑盒探测,第一时间感知组件/集群/链路的可用性。
以 etcd 集群的可用性来举例,我们可以实现一个探测用例,逻辑是对 etcd 做 create/get/delete/txn 等等操作,并记录每个操作的成功率/消耗时间,当成功率低于 100% 或消耗时间超过容忍阈值后,触发报警。我们将周期高频运行这个 etcd 的探测用例,同时对于 etcd 集群的任何变更都会发出一个事件 event 触发这个 etcd 探测立即运行,这样就能尽量确保第一时间发现 etcd 可用性故障了。同时,当 etcd 集群因为某些原因不可用了,我们也可以通过手动触发等其他方式做探活,也能第一时间得到是否恢复的信息。
2)定向巡检
在大规模集集群/系统场景下,数据一致性是一定会面临的难题。数据不一致,将导致一些隐患,可能会在未来引发某些确定性的故障。
相比于黑盒探测面对的未知故障场景,定向巡检的目标是对集群的已知风险点做扫描。

我们希望 KubeProbe 能够定期对整个集群/链路做定向的巡检,找出这些数据不一致的点,判断数据不一致是否可能引发风险,从而能够防患于未然,治未病。
比如 etcd 冷热备多集群覆盖不全,可能导致集群遇到故障无法快速恢复。那么我们就定期对 etcd 的冷热备覆盖情况做定向巡检,找出没有覆盖推平的集群,并告警。比如 集群风控系统没有全集群链路覆盖,限流配置没有全集群链路推平,可能导致某些故障场景引发集群全面崩溃,我们定期对风控配置全网扫描,判断是否可能导致故障,找出这些隐藏的已知风险点并告警。
=======================================================================
1)基本架构
KubeProbe 的基本实现架构大致如下图,KubeProbe 中心端配置集群/集群组与巡检/探测用例/用例集之间的关联关系,负责对集群做具体某次探测实例下发。某个具体的巡检/探测用例下发到具体某个集群将使用用例的镜像创建一个 pod,这个 pod 里会执行若干巡检/探测逻辑,当执行完成后会回调中心端回写本次巡检/探测结果。其具体结果在中心端统一展示/告警,并提供给其他消费者消费(如支持 ASIOps 平台的发布阻断)。

2)高频架构
除了上述的基本架构之外,我们对于高频探测用例(既探测周期短,触发频率需要非常频繁,甚至保持无缝探测的场景)设计了一套集群内的分布式常驻探测架构,该架构通过集群内的 ProbeOperator 组件 watch 自定义对象 probeConfig 的变化,在集群内创建一个常驻的探测 pod,将持续无间断的运行探测逻辑,实现接近无缝的持续探测,并将结果通过去噪/令牌桶限流等处理后,上报中心端,共给其他消费者消费。

所有的探测/巡检用例都使用统一的 git 仓库管理,由我们提供一个统一的 client 库,client 库最核心提供的方法主要有两个。
KPclient “gitlab.alibaba-inc.com/{sigma-inf}/{kubeProbe}/client”
// 报告成功
// 此方法会向KubeProbe报告本次巡检结果为成功
KPclient.ReportSuccess()
os.Exit(0)
// 报告失败
// 报告方法会向KubeProbe报告本次巡检结果为失败,并且失败信息为 我失败啦
KPclient.ReportFailure([]string{“我失败啦!”})
os.Exit(1)
我们可以通过提供好的 Makefile 将这个用例打包成镜像,录入 KubeProbe 中心端就可以对集群做配置和下发了。将具体巡检/探测逻辑和 KubeProbe 中心管控端解耦,可以灵活而又简便的让更多的二方用户接入自己的特殊巡检/探测逻辑。
目前已经使用的探测/巡检用例包括:
-
通用探测:模拟 pod / deployment / statefulset 生命周期探测集群整条管控链路。
-
etcd 黑盒探测:模拟 etcd 的基本操作,探测元集群中各 etcd 状态。
-
金丝雀探测(感谢质量技术同学的大力支持):模拟用户使用 ASI 的部署场景,实现金丝雀应用的全链路模拟发布/扩容/缩容。
-
Virtual cluster 探测:探测 vc 虚拟集群的管控链路状态。
-
联邦链路探测:探测联邦控制器相关链路的状态。
-
节点通用探测:在集群每个节点上模拟调度一个探测 pod,探测节点侧链路状态。
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

Ending
Tip:由于文章篇幅有限制,下面还有20个关于MySQL的问题,我都复盘整理成一份pdf文档了,后面的内容我就把剩下的问题的目录展示给大家看一下
如果觉得有帮助不妨【转发+点赞+关注】支持我,后续会为大家带来更多的技术类文章以及学习类文章!(阿里对MySQL底层实现以及索引实现问的很多)


吃透后这份pdf,你同样可以跟面试官侃侃而谈MySQL。其实像阿里p7岗位的需求也没那么难(但也不简单),扎实的Java基础+无短板知识面+对某几个开源技术有深度学习+阅读过源码+算法刷题,这一套下来p7岗差不多没什么问题,还是希望大家都能拿到高薪offer吧。
文章!**(阿里对MySQL底层实现以及索引实现问的很多)
[外链图片转存中…(img-FTfj8sTD-1711199395313)]
[外链图片转存中…(img-EvmMAGKu-1711199395314)]
吃透后这份pdf,你同样可以跟面试官侃侃而谈MySQL。其实像阿里p7岗位的需求也没那么难(但也不简单),扎实的Java基础+无短板知识面+对某几个开源技术有深度学习+阅读过源码+算法刷题,这一套下来p7岗差不多没什么问题,还是希望大家都能拿到高薪offer吧。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)