K8S复习
Kubeadm 的代码设计采用了可组合的模块方式,所以你可以只使用 Kubeadm 的部分功能,比如使用 Kubeadm 帮你生成各个组件的证书,也可以基于 kubeadm 开发专属的集群部署工具,比如通过 Ansible 借助于 Kubeadm 的子功能来定制 Kubernetes 集群的搭建。最为关键的是,Kubeadm 可以向下兼容低一个小版本的 Kubernetes,也就意味着,你可以用
目录
本文原文出自本人自己复习时整理,原文非常系统,建议拜师#yyds干货盘点# 手把手教你玩转 Kubernete 集群搭建(03)_wzlinux的博客-CSDN博客
升级策略知道了这些,我们来看具体的升级策略,一般来说有三类:
本文原文出自本人自己复习时整理,原文非常系统,建议拜师#yyds干货盘点# 手把手教你玩转 Kubernete 集群搭建(03)_wzlinux的博客-CSDN博客
1.docker的优势
在某一段时期内,大家一提到 Docker,就和容器等价起来,认为 Docker 就是容器,容器就是Docker。其实容器是一个相当古老的概念,并不是 Docker发明的,但 Docker 却为其注入了新的灵魂——Docker 镜像
Docker 镜像解决了环境打包的问题,它直接打包了应用运行所需要的整个“操作系统”,而且不会出现任何兼容性问题,它赋予了本地环境和云端环境无差别的能力,这样避免了用户通过“试错”来匹配不同环境之间差异的痛苦过程, 这便是 Docker 的精髓。
2.容器的八大能力
一个容器编排引擎到底需要哪些能力才能解决上述这些棘手的问题
首先容器调度平台可以自动生成容器实例,然后是生成的容器可以相邻或者相隔,帮助提高可用性和性能,还有健康检查、容错、可扩展、网络等功能,它几乎完美地解决了需求与资源的匹配编排问题

3.k8s和docker-swarm和MESOS的区别
Kubernetes 采用了 Pod 和 Label 这样的概念,把容器组合成一个个相互依赖的逻辑单元,相关容器被组合成 Pod 后被共同部署和调度,就形成了服务,这也是 Kuberentes 和其他两个调度管理系统最大的区别。
各个厂商的K8S服务

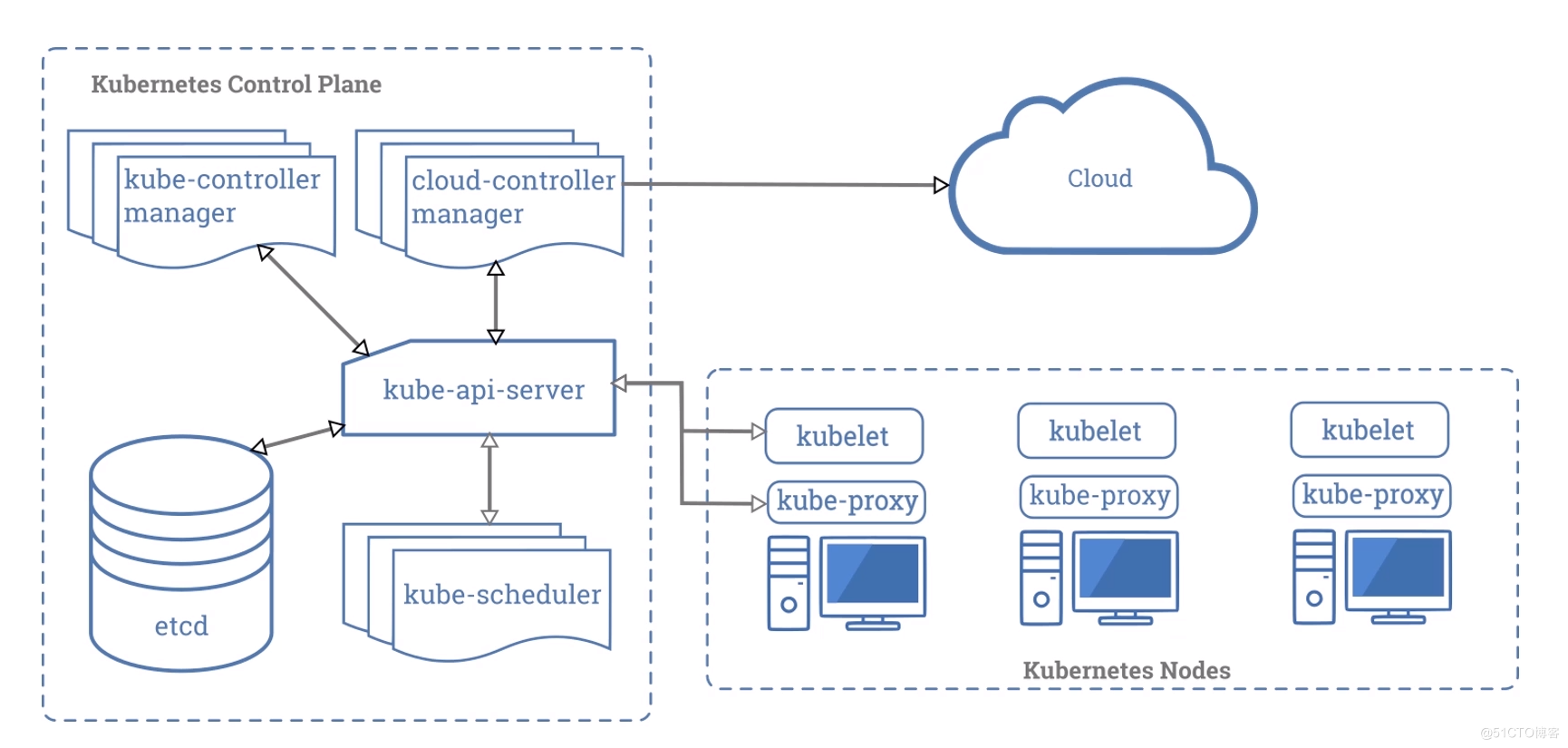
4.K8S的架构

最好为这些 Master 节点选择一些性能好且规格大的物理机或者虚拟机,毕竟控制面堪称 Kubernetes 集群的大脑,要尽力避免这些实例宕机导致集群故障。
同样在 Kubernetes 集群中也采用了分布式存储系统 Etcd,用于保存集群中的所有对象以及状态信息。有的时候,我们会将 Etcd 集群也一起部署到 Master 上。但是在集群节点资源足够的情况下,我个人建议可以考虑将 Etcd 集群单独部署,因为Etcd中的数据可是至关重要的,必须要保证 Etcd 数据的安全
Etcd 采用 Raft 协议实现
5.k8s的组件--MASTER节点
master节点三大件
kube-apiserver、kube-scheduler、kube-controller-manager 这三大组件,我们也称为 Kubernetes 的三大件。
控制节点各个组件的作用
kube-apiserver:它是整个 Kubernetes 集群的“灵魂”,是信息的汇聚中枢,提供了所有内部和外部的 API 请求操作的唯一入口。同时也负责整个集群的认证、授权、访问控制、服务发现等能力
用户可以通过命令行工具 kubectl 和 APIServer 进行交互,从而实现对集群中进行各种资源的增删改查等操作。APIServer 跟 BorgMaster 非常类似,会将所有的改动持久到 Etcd 中,同时也保存着一份内存拷贝。
Kube-Controller-Manager:它负责维护整个 Kubernetes 集群的状态,比如多副本创建、滚动更新等。Kube-controller-manager 并不是一个单一组件,内部包含了一组资源控制器,在启动的时候,会通过 goroutine 拉起多个资源控制器。这些控制器的逻辑仅依赖于当前状态,因为在分布式系统中没办法保证全局状态的同步。
Kube-scheduler:它的工作简单来说就是监听未调度的 Pod,按照预定的调度策略绑定到满足条件的节点上。这个调度器是 Kubernetes 的默认调度器,可插拔,你可以根据需要使用其他的调度器,或者通过目前调度器的扩展功能增加自己的特性进去。
6.NODE节点的组件
容器运行时主要负责容器的镜像管理以及容器创建及运行。大家都知道的 Docker 就是很常用的容器,此外还有 Kata、Frakti等。只要符合 CRI(Container Runtime Interface,容器运行时接口)规范的运行时,都可以在 Kubernetes 中使用。
Kubelet 负责维护 Pod 的生命周期,比如创建和删除 Pod 对应的容器。同时也负责存储和网络的管理。一般会配合 CSI、CNI 插件一起工作。
Kube-Proxy 主要负责 Kubernetes 内部的服务通信,在主机上维护网络规则并提供转发及负载均衡能力。除了上述这些核心组件外,通常我们还会在 Kubernetes 集群中部署一些 Add-on 组件,常见的有:
CoreDNS 负责为整个集群提供 DNS 服务;
Ingress Controller 为服务提供外网接入能力;
Dashboard 提供 GUI 可视化界面;
Fluentd + Elasticsearch 为集群提供日志采集、存储与查询等能力。
Kubernetes 中所有的状态都是采用上报的方式实现的。APIServer 不会主动跟 Kubelet 建立请求链接,所有的容器状态汇报都是由 Kubelet 主动向 APIServer 发起的。
Kubelet 进程就会定时向 APIServer 汇报“心跳”,即汇报自身的状态,包括自身健康状态、负载数据统计等。当一段时间内心跳包没有更新,那么此时 kube-controller-manager 就会将其标记为 NodeLost(失联)
Kubernetes 中各个组件都是以 APIServer 为中心,通过松耦合的方式进行。借助声明式 API,各部件通过 watch 的机制就可以根据各个对象的变化,很快地做出相应的处理操作。
7.集群的搭建
对于一个分布式系统而言,要想达到生产可用,就必须要具备身份认证和权限授权能力。一般来说,各内部组件之间相互通信会采用自签名的 TLS 证书,通过 HTTPS 来加强安全访问。同时,为了能够确定各自的身份和权限,常常借助于 mTLS (mutual TLS,双向 TLS)认证。
搞懂K8S证书
#yyds干货盘点# 手把手教你玩转 Kubernete 集群搭建(03)_wzlinux的博客-CSDN博客
四套证书
我们可以看到,Kubernetes 集群如果要生产可用,就需要签发一些证书,我们具体来看一下都需要哪些证书。
etcd 集群内部各 member 之间需要一对 CA (Certificate Authority)用于签发证书,然后签发出一对 TLS 证书用于内部各 member 之间的数据互访和同步。
同时 etcd 集群需要对外暴露服务,方便 kube-apiserver 可以读写数据,这个时候就需要一对 CA 和 一对 TLS 证书。一般来说,为了方便,我们这里可以使用同一份 CA 证书来签发证书。
kube-apiserver 跟 etcd 集群之间的访问,我们也需要用 etcd 的 CA 证书,单独为 kube-apiserver 签发一对 TLS 证书。
Kubernetes 集群内部其他各组件,包括 kube-controller-manager、kube-scheduler、kubelet、kube-proxy 等,与 kube-apiserver 都需要安全访问,因此我们还需要一对 CA 证书,用于签发各个组件的 TLS 证书。同时 kube-apiserver 有时需要主动向 kubelet 发起连接,那么这里还需要为 kube-apiserver 签发一对 TLS 证书。
可见要搭建一个生产可用的 Kubernetes 集群,到目前为止至少需要签发 2 份 CA 证书,8 份 TLS 证书。而实际上 Kubernetes 还支持很多其他的能力,比如 ServiceAccount、aggregation server 等,因此还需要签发更多的证书
我们应该先设置集群的权限还是先搭建集群呢?而且,在内部各组件接入时该怎么设置权限呢?
其实,在 Kubernetes 中,kube-apiserver 启动时会预设一些权限,用于各内部组件的接入访问。那么各个组件在签发证书时,就需要使用各自预设的 CN(Common Name)来标识自己的身份,比如 kube-scheduler 使用的 CN 是system:kube-scheduer
想要从零开始搭建一套安全性高的集群,其难度远不止如此,我们这里还需额外考虑到,譬如证书的有效期、过期替换、证书签发的密钥类型、签名算法等等问题。
节点资源规划
集群节点资源规划
基本原则:大规格 10 台到 20 台:Worker 数量相对少了,master 的负担最小,调度性能最优
Pull image 的次数减少,减少带宽占用,提高容器调度效率
通过临近路由等手段,提高容器间 loopback 的调用,网络性能最优
Worker 数量的减少,剩余碎片资源少,资源利用率最好
同系列规格的机器,高规格机器没有增加成本(平均每核),反而因为系统盘减少而相对减少成本
Worker 数量的减少,减轻了运维的维护工作量和成本
单机规格增大,驱逐的概率降低(request < limit)
集群搭建的方法
Kubeadm
第三个是 Kubeadm,我想给你重点介绍一下它。这个工具是我平时使用最多,也是最推荐你去使用的。上面介绍的 Kind 和 Minikube 这两个工具主要是用于快速搭建本地的开发测试环境,没办法用来搭建生产集群。
当然 Kubeadm 的能力不止如此,它还有如下这些优势。
-
使用 Kubeadm 可以快速搭建出符合一致性测试认证(Conformance Test)的集群。
Kubeadm 用户体验非常优秀,使用起来非常方便,并且可以用于搭建生产环境,支持搭建高可用集群。 -
Kubeadm 的代码设计采用了可组合的模块方式,所以你可以只使用 Kubeadm 的部分功能,比如使用 Kubeadm 帮你生成各个组件的证书,也可以基于 kubeadm 开发专属的集群部署工具,比如通过 Ansible 借助于 Kubeadm 的子功能来定制 Kubernetes 集群的搭建。你可以通过 Kubeadm init phase kubeadm init phase | Kubernetes和 Kubeadm join phasekubeadm join phase | Kubernetes,去了解更多 Kubeadm 创建集群时内部各个子阶段的功能,并根据需要选择合适的子功能。
-
最为关键的是,Kubeadm 可以向下兼容低一个小版本的 Kubernetes,也就意味着,你可以用 v1.18.x 的 kubeadm 搭建 v1.17.y 版本的 Kubernetes。
-
同时kubeadm 还支持集群平滑升级到高版本,即你可以使用 v1.17.x 版本的 Kubeadm 将 v1.16.y 版本的 Kubernetes 集群升级到 v1.17.z。同理,你可以继续使用高版本的 Kubeadm 将你的集群一点点升到想要的版本上去。
-
这里我给出了一张图,你可以看到,Kubeadm 在设计之初的定位就是只关心集群的 bootstrapping,并不负责物理资源的管理和申请。在集群 bootstrapping 搭建完成后,你可以根据自己的需要,在集群中部署自己的 add-on 组件,比如 CNI 插件、Dashboard 等。

知道了这些,现在我们来详细说一下用 Kubeadm 如何搭建集群。
首先,参照官方文档下载安装 Kubeadm 及依赖的组件。然后运行kubeadm init在 master 节点上搭建出集群的控制面。
kubeadm init --pod-network-cidr=10.244.0.0/16如果你的 master 节点有多块网卡,可以通过参数 apiserver-advertise-address 来指定你想要暴露的服务地址,比如:
$ kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.131.128
运行完成后,会出现下面这些信息告诉你安装成功,以及一些常规指令:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a Pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join <control-plane-host>:<control-plane-port> --token <token> --discovery-token-ca-cert-hash sha256:<hash>我们在 master 节点上拷贝一下 kubeconfig 文件到 kubectl 默认的 kubeconfig 路径下:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config然后直接拷贝前面显示的kubeadm join命令 ,依次在各个 node 节点上运行将其加入集群中即可。
如果想要搭建生产环境,那么你可以参照这份官方文档,去搭建一个高可用的集群,这里就不再赘述了。
除此之外,社区还有一些其他项目可以用来搭建集群,比如 kubespray 和 kops。其中 kubespray是通过一堆 Ansible Playbook 来安装 Kubernetes 集群;而 kops 使用起来就像 kubectl 一样方便,可以帮助你在各大公有云上搭建 Kubernetes 集群。
好的,我们这样就完成了集群搭建,但其实这只是第一步,后续的运维和升级才是“大 Boss”。
升级策略
知道了这些,我们来看具体的升级策略,一般来说有三类:
第二种,每半年升级一次,这样会落后社区 1~2 个小版本。这是我个人比较推荐的做法,等到各个小版本的补丁版本稳定后,再对集群做升级操作,这样比较保险。
集群升级的建议
现在,不少大厂都已经在 Kubernetes 集群中运行着实际的生产业务,而线上的这些业务对可用性的要求通常都非常高,有些场景也异常复杂。因此,即使最微小的集群变更也要非常小心,慎重操作,最好通过“轮转+灰度”的升级策略来逐个集群升级。
这样你就会发现,跟随社区版本频繁地进行升级其实很吃力,尤其集群规模比较大的时候,很多大厂其实也吃不消。这往往需要经过多轮的演练、测试,踩完一些“坑”以后,才敢在生产集群进行升级实操,正如上面所说,升级的版本要落后社区至少 1 到 2 个版本。升级的时候,还需要紧密配合监控大盘一起,及时“止血”,避免大规模的生产故障
在这里,我想给你分享一些集群升级的注意事项。
- 升级前请务必备份所有重要组件及数据,例如 etcd 的数据备份、各组件的启动配置等。关于集群的灾备,我们会放在后面的课程中来讲解。
- 千万不要跨小版本进行升级,比如直接把 Kubernetes 从 v1.16.x 的版本升到 v1.18.x 的版本。因为社区的一些 API 以及行为改动有些只会保留两个大版本,跨版本升级很容易导致集群故障。
- 注意观察容器的状态,避免引发某些有状态业务发生异常。在 v1.16 版本以前,升级的时候,如果 Pod spec 的哈希值已更改,则会引发 Pod 重建。关于 Pod 的一些定义和使用方法,我们会在下一节课中深入学习,这里你只要先了解这些就够了。
- 每次升级之前,切记一定要认真阅读官方的 release note,重点关注中间的 highlight 说明,一般文档中会注明哪些变化会对集群升级产生影响。
- 谨慎使用还在 alpha 阶段的功能。社区迭代的时候,这些 alpha 阶段的功能会随时发生变化,比如启动参数、配置方式、工作模式等等。甚至有些 alpha 阶段的功能会被下线掉。
- 社区推荐的集群升级基本流程:先升级主控制平面节点,再升级其他控制平面节点,最后升级工作节点。
- 这里如果你是使用 Kubeadm 进行集群搭建的,可以参考这份社区官方的 Kubeadm 集群升级指南。Kubeadm 在代码开发阶段中,会有对应的 CI 流水线负责验证集群的稳定升级能力。
- 集群搭建只是第一步,重要的是后续集群的维护工作,比如集群组件宕机、集群版本升级等。所以选择合适的工具很重要,因为这可以很大程度降低升级的风险以及运维难度。最后再强调一下,千万不要跨小版本进行升级,要按小版本依次升上来。
8.POD
1.什么情况下会在一个pod里放多个container?---高耦合
一般来说,在一个 Pod 内运行多个容器,比较适应于以下这些场景。
- 容器之间会发生文件交换等,上面提到的例子就是这样。一个写文件,一个读文件。
- 容器之间需要本地通信,比如通过 localhost 或者本地的 Socket。这种方式有时候可以简化业务的逻辑,因为此时业务就不用关心另外一个服务的地址,直接本地访问就可以了。
- 容器之间需要发生频繁的 RPC 调用,出于性能的考量,将它们放在一个 Pod 内。
- 希望为应用添加其他功能,比如日志收集、监控数据采集、配置中心、路由及熔断等功能。这时候可以考虑利用边车模式(Sidecar Pattern),既不需要改动原始服务本身的逻辑,还能增加一系列的功能。比如 Fluentd 就是利用边车模式注入一个对应 log agent 到 Pod 内,用于日志的收集和转发。 Istio 也是通过在 Pod 内放置一个 Sidecar 容器,来进行无侵入的服务治理。
2. 为什么 Kubernetes 不直接管理容器,而用 Pod 来管理呢?
- 使用一个新的逻辑对象 Pod 来管理容器,可以在不重载容器信息的基础上,添加更多的属性,而且也方便跟容器运行时进行解耦,兼容度高。比如:
- 存活探针(Liveness Probe)可以从应用程序的角度去探测一个进程是否还存活着,在容器出现问题之前,就可以快速检测到问题;
- 容器启动后和终止前可以进行的操作,比如,在容器停止前,可能需要做一些清理工作,或者不能马上结束进程;
- 定义了容器终止后要采取的策略,比如始终重启、正常退出才重启等
2. 为什么要允许一个 Pod 内可以包含多个容器?
- 由于容器实际上是一个“单进程”的模型,这点非常重要。因为如果你在容器里启动多个进程,这将会带来很多麻烦
- 用一个 Pod 管理多个容器,既能够保持容器之间的隔离性,还能保证相关容器的环境一致性。使用粒度更小的容器,不仅可以使应用间的依赖解耦,还便于使用不同技术栈进行开发,同时还可以方便各个开发团队复用,减少重复造轮子。
3.如何声明一个 Pod
在 Kubernetes 中,所有对象都可以通过一个相似的 API 模板来描述,即元数据 (metadata)、规范(spec)和状态(status)。这种方式也是从 Borg 吸取的经验,避免过多的 API 定义设计,不利于统一和对接。Kubernetes 有了这种统一风格的 API 定义,方便了通过 REST 接口进行开发和管理。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)