ELK+kafka日志系统
input配置:指定kafka集群个节点地址,指定topics,该topics就是在k8s集群中daemonset yml文件中引用的topics变量,指定编码为jsonoutput配置:通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemons
·
原文出处
如有侵权,私信删除!!!
一、资源规划
| 服务名 | 所在服务器 |
|---|---|
| kafka1—2.13-2.4.1 | 192.168.76.10 |
| kafka2—2.13-2.4.1 | 192.168.76.11 |
| kafka3—2.13-2.4.1 | 192.168.76.12 |
| zookeeper1—3.6.3 | 192.168.76.10 |
| zookeeper2—3.6.3 | 192.168.76.11 |
| zookeeper3—3.6.3 | 192.168.76.12 |
| elasticsearch1—7.12.1 | 192.168.76.10 |
| elasticsearch2—7.12.1 | 192.168.76.11 |
| elasticsearch3—7.12.1 | 192.168.76.12 |
| kibana—7.12.1 | 192.168.76.13 |
| logstash—7.12.1 | 192.168.76.14 |
| JDK—11.0.21 | ------ |
二、JDK-11
# 官网下载JDK11的安装包,并上传到服务器解压/home/java
tar -zxvf jdk-11.0.21_linux-x64_bin.tar.gz
# 编辑文件并加入以下内容
vim /etc.profile
# JAVA_11
export PATH=/home/java/jdk-11.0.21/bin:$PATH
# 使环境变量生效
source /etc/profile
java -version
java version "11.0.21" 2023-10-17 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.21+9-LTS-193)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.21+9-LTS-193, mixed mode)
三、kafka
# 以下操作在3个节点执行
# zookeeper集群
mkdir /apps
cd /apps
wget https://downloads.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
# 三个zookeeper节点执行:解压安装包并做软链接
tar xvf apache-zookeeper-3.6.3-bin.tar.gz
ln -sv /apps/apache-zookeeper-3.6.3-bin /apps/zookeeper
# zookeeper配置
cd /apps/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=192.168.76.10:2888:3888
server.2=192.168.76.11:2888:3888
server.3=192.168.76.12:2888:3888
# 创建数据目录
mkdir -p /data/zookeeper
# 配置zookeeper节点id(注意,zookeeper集群每个节点的id都不一样)
在zookeeper1节点192.168.76.10上执行:
echo 1 > /data/zookeeper/myid
在zookeeper2节点192.168.76.11上执行:
echo 2 > /data/zookeeper/myid
在zookeeper3节点192.168.76.12上执行:
echo 3 > /data/zookeeper/myid
# 运行zookeeper集群.
# 注意:zookeeper配置的初始化时间为10*2000ms,即20s,因此三个节点服务拉起时间不能超过20s,超过20s将会集群初始化失败查看集群各节点角色
/apps/zookeeper/bin/zkServer.sh start
/apps/zookeeper/bin/zkServer.sh status #当前集群zookeeper2为leader角色。
# kafka集群
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.13-2.4.1.tgz
tar xvf kafka_2.13-2.4.1.tgz
ln -sv /apps/kafka_2.13-2.4.1 /apps/kafka
# 修改kafka配置文件
# kafka1节点192.168.76.10配置
cd /apps/kafka/config
vim server.properties
broker.id=10 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.10:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs
# kafka2节点192.168.76.11配置
cd /apps/kafka/config
vim server.properties
broker.id=11 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.11:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs
# kafka3节点192.168.76.12配置
cd /apps/kafka/config
vim server.properties
broker.id=12 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://192.168.76.12:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=192.168.76.10:2181,192.168.76.11:2181,192.168.76.12:2181 #指定zk地址和端口
# 创建日志目录
mkdir -p /data/kafka-logs
# 启动kafka
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
# 验证端口是否起来
netstat -antp | grep 9092
tcp 0 0 192.168.76.10:9092 0.0.0.0:* LISTEN 69836/java
四、elasticsearch
# 以下操作在3个节点执行
cd /apps
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
rpm -ivh elasticsearch-7.12.1-x86_64.rpm
# 修改配置文件并启动服务
# elasticsearch01节点192.168.76.10上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: master-10 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.10 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
# elasticsearch02节点192.168.76.11上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: node1-11 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.11 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
# elasticsearch03节点192.168.76.12上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-yaya #指定集群名称,三个节点集群名称配置一样
node.name: node2-12 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 192.168.76.12 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["192.168.76.10", "192.168.76.11","192.168.76.12"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
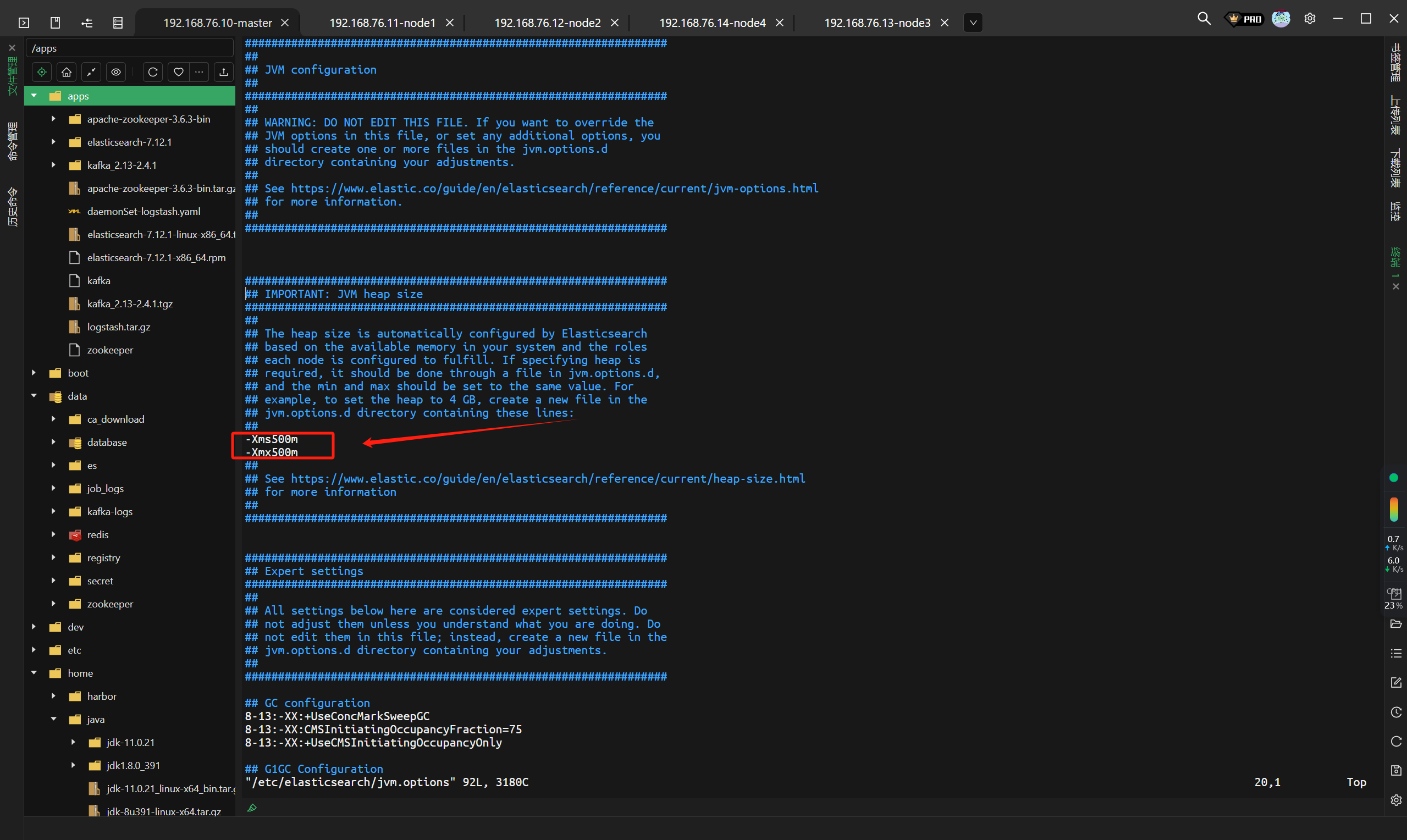
# 如果es起不来的话,可能是资源不够,修改如下文件并重启就可以了
vim /etc/elasticsearch/jvm.options

五、kibana
# 下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
rpm -ivh kibana-7.12.1-x86_64.rpm
vim /etc/kibana/kibana.yml
server.port: 5601 #kibana监听端口
server.host: "192.168.76.13" #kibana地址
elasticsearch.hosts: ["http://192.168.76.10:9200"] #elasticsearch的地址和端口
i18n.locale: "zh-CN" #修改kibana页面显示语言为中文
# 启动
systemctl start kibana
netstat -antp | grep 5601
访问:http://192.168.76.13:5601/
六、logstash
# 构建镜像
vim logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ] #关闭xpack功能,该功能收费,如果不关闭将无法正常使用logstash
# 准备logstash日志收集的配置,通过配置input日志输入和output输出来匹配收集的容器日志
vim app1.conf
input {
file {
path => "/var/lib/docker/containers/*/*-json.log"
start_position => "beginning"
type => "jsonfile-daemonset-applog"
}
file {
path => "/var/log/*.log "
start_position => "beginning"
type => "jsonfile-daemonset-syslog"
}
}
output {
if [type] == "jsonfile-daemonset-applog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "jsonfile-daemonset-syslog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
#codec => "${CODEC}" #系统日志不是json格式
}}
}
# Dockerfile
vim Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD app1.conf /usr/share/logstash/pipeline/logstash.conf
# 构建镜像
docker build -t harbor.magedu.local/baseimages/logstash:v7.12.1-json-file-log-v4 .
# 准备镜像,所有节点
docker save -o logstash.tar.gz logstash:v7.12.1-json-file-log-v4
docker load -i logstash.tar.gz
scp logstash.sh
#
vim daemonSet-logstash.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-elasticsearch
namespace: log-collection
labels:
k8s-app: logstash-logging
spec:
selector:
matchLabels:
name: logstash-elasticsearch
template:
metadata:
labels:
name: logstash-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: logstash-elasticsearch
image: logstash:v7.12.1-json-file-log-v4 #使用自构建的镜像
env: #设置环境变量,便于在Dockerfile中引用这些变量
- name: "KAFKA_SERVER"
value: "192.168.76.10:9092,192.168.76.11:9092,192.168.76.12:9092"
- name: "TOPIC_ID"
value: "jsonfile-log-topic"
- name: "CODEC"
value: "json"
volumeMounts:
- name: varlog
mountPath: /var/log #指定宿主机系统日志在容器内的挂载路径
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers #指定容器存储在宿主机上日志目录在容器内的挂载路径
readOnly: false
terminationGracePeriodSeconds: 30
volumes: #设置挂载,将宿主机系统日志路径和容器存储宿主机的日志路径挂载到logstash容器中,便于logstash收集日志
- name: varlog
hostPath: #使用hostPath类型的存储卷
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
# 创建nomespace
kubectl create ns log-collection
kubectl apply -f daemonSet-logstash.yaml
# 查看pod是否运行
kubectl get po -n log-collection
NAME READY STATUS RESTARTS AGE
logstash-elasticsearch-6m8j2 1/1 Running 1 19h
logstash-elasticsearch-7n7ls 1/1 Running 1 19h
logstash-elasticsearch-9ns25 1/1 Running 1 19h
logstash-elasticsearch-csmvc 1/1 Running 1 19h
logstash-elasticsearch-vscv4 1/1 Running 1 19h

宿主机安装logstash消费kafka集群日志
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-x86_64.rpm
rpm -ivh logstash-7.12.1-x86_64.rpm
# 编辑配置文件
vim /etc/logstash/conf.d/daemonset-log-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.76.10:9092,192.168.76.11:9092,192.168.76.12:9092" # kafka三个节点地址
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
if [type] == "jsonfile-daemonset-applog" {
elasticsearch {
hosts => ["192.168.76.10:9200","192.168.76.11:9200"] # es地址,写两个就好
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" {
elasticsearch {
hosts => ["192.168.76.10:9200","192.168.76.11:9200"] # es地址,写两个就好
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
# 启动查看有无报错
systemctl start logstash
配置参数说明:
input配置:指定kafka集群个节点地址,指定topics,该topics就是在k8s集群中daemonset yml文件中引用的topics变量,指定编码为json
output配置:通过type过来日志,将过滤的日志发送给elasticsearch,hosts指定elasticsearch集群各节点地址,index指定索引,用日期进行区分。这里分别过滤容器日志jsonfile-daemonset-applog和系统日志jsonfile-daemonset-syslog
hosts:指定elasticsearch集群各节点地址
index:指定索引格式
七、配置kibana







此插件可利用科学上网的方法,到Google应用商店搜索elasticsearch自行下载


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)