基于kubeasz部署高可用k8s集群
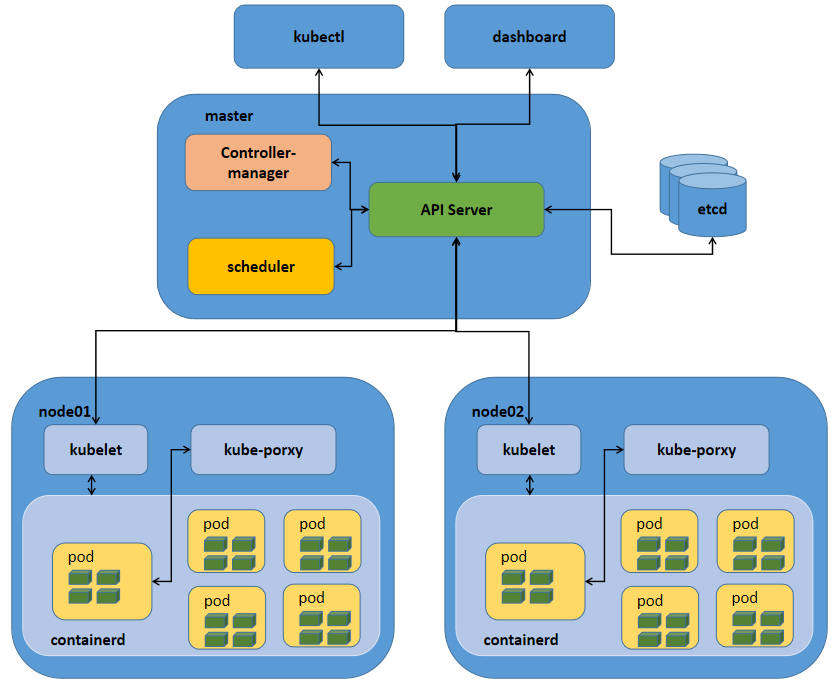
在部署高可用k8s之前,我们先来说一说单master架构和多master架构,以及多master架构中各组件工作逻辑 k8s单master架构 提示:这种单master节点的架构,通常只用于测试环境,生产环境绝对不允许;这是因为k8s集群master的节点是单点,一旦master节点宕机,将导致整个集群不可用;其次单master节点apiServer是性能瓶颈;从上图我们就可以看到,maste
在部署高可用k8s之前,我们先来说一说单master架构和多master架构,以及多master架构中各组件工作逻辑
k8s单master架构

提示:这种单master节点的架构,通常只用于测试环境,生产环境绝对不允许;这是因为k8s集群master的节点是单点,一旦master节点宕机,将导致整个集群不可用;其次单master节点apiServer是性能瓶颈;从上图我们就可以看到,master节点所有组件和node节点中的kubelet和客户端kubectl、dashboard都会连接apiserver,同时apiserver还要负责往etcd中更新或读取数据,对客户端的请求做认证、准入控制等;很显然apiserver此时是非常忙碌的,极易成为整个K8S集群的瓶颈;所以不推荐在生产环境中使用单master架构;
k8s多master架构

提示:k8s高可用主要是对master节点组件高可用;其中apiserver高可用的逻辑就是通过启用多个实例来对apiserver做高可用;apiserver从某种角度讲它应该是一个有状态服务,但为了降低apiserver的复杂性,apiserver将数据存储到etcd中,从而使得apiserver从有状态服务变成了一个无状态服务;所以高可用apiserver我们只需要启用多个实例通过一个负载均衡器来反向代理多个apiserver,客户端和node的节点的kubelet通过负载均衡器来连接apiserver即可;对于controller-manager、scheduler这两个组件来说,高可用的逻辑也是启用多个实例来实现的,不同与apiserver,这两个组件由于工作逻辑的独特性,一个k8s集群中有且只有一个controller-manager和scheduler在工作,所以启动多个实例它们必须工作在主备模式,即一个active,多个backup的模式;它们通过分布式锁的方式实现内部选举,决定谁来工作,最终抢到分布式锁(k8s集群endpoint)的controller-manager、scheduler成为active状态代表集群controller-manager、scheduler组件工作,抢到锁的controller-manager和scheduler会周期性的向apiserver通告自己的心跳信息,以维护自己active状态,避免其他controller-manager、scheduler进行抢占;其他controller-manager、scheduler收到活动的controller-manager、scheduler的心跳信息后自动切换为backup状态;一旦在规定时间备用controller-manager、scheduler没有收到活动的controller-manager、scheduler的心跳,此时就会触发选举,重复上述过程;
服务器规划

基础环境部署
重新生成machine-id
| 1 2 3 4 5 |
|
提示:如果你的环境是通过某一个虚拟机基于快照克隆出来的虚拟机,很有可能对应machine-id一样,可以通过上述命令将对应虚拟机的machine-id修改成不一样;注意上述命令不能再crt中同时对多个虚拟机执行,同时对多个虚拟机执行,生成的machine-id是一样的;
内核参数优化
| 1 2 3 4 5 6 7 8 9 10 |
|
系统资源限制
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
内核模块挂载
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
禁用SWAP
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
提示:以上操作建议在每个节点都做一下,然后把所有节点都重启;
1、基于keepalived及haproxy部署高可用负载均衡
下载安装keepalived和haproxy
| 1 2 |
|
在ha01上创建/etc/keepalived/keepalived.conf
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
将配置文件复制给ha02
| 1 2 3 |
|
在ha02上编辑/etc/keepalived/keepalived.conf

提示:ha02上主要修改优先级和声明角色状态,如上图所示;
在ha02上启动keepalived并设置开机启动
| 1 2 3 4 5 |
|
验证:在ha02上查看对应vip是否存在?

在ha01启动keepalived并设置为开机启动,看看对应vip是否会漂移至ha01呢?

提示:可以看到在ha01上启动keepalived以后,对应vip就漂移到ha01上了;这是因为ha01上的keepalived的优先级要比ha02高;
测试:停止ha01上的keepalived,看看vip是否会漂移至ha02上呢?

提示:能够看到在ha01停止keepalived以后,对应vip会自动漂移至ha02;
验证:用集群其他主机ping vip看看对应是否能够ping通呢?
| 1 2 3 4 5 6 7 8 9 |
|
提示:能够用集群其他主机ping vip说明vip是可用的,至此keepalived配置好了;
配置haproxy
编辑/etc/haproxy/haproxy.cfg
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
把上述配置复制给ha02
| 1 2 3 |
|
在ha01上启动haproxy,并将haproxy设置为开机启动
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
提示:上面报错是因为默认情况下内核不允许监听本机不存在的socket,我们需要修改内核参数允许本机监听不存在的socket;
修改内核参数
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
验证:重启haproxy 看看是能够正常监听6443?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
提示:可用看到修改内核参数以后,重启haproxy对应vip的6443就在本地监听了;对应ha02也需要修改内核参数,然后将haproxy启动并设置为开机启动;
重启ha02上面的haproxy并设置为开机启动
| 1 2 3 4 5 6 7 8 9 10 |
|
提示:现在不管vip在那个节点,对应请求都会根据vip迁移而随之迁移;至此基于keepalived及haproxy部署高可用负载均衡器就部署完成;
2、部署https harbor服务提供镜像的分发
在harbor服务器上配置docker-ce的源
| 1 |
|
在harbor服务器上安装docker和docker-compose
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
验证docker版本
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
下载docker-compose二进制文件
| 1 |
|
给docker-compose二进制文件加上可执行权限,并验证docker-compose的版本
| 1 2 3 4 5 6 7 8 9 10 11 |
|
下载harbor离线安装包
| 1 |
|
创建存放harbor离线安装包目录,并将离线安装包解压于对应目录
| 1 2 3 4 5 6 7 8 |
|
创建存放证书的目录certs
| 1 2 3 4 5 6 |
|
上传证书
| 1 2 3 4 5 6 7 8 9 10 |
|
复制harbor配置模板为harbor.yaml
| 1 2 3 4 5 6 7 8 |
|
编辑harbor.yaml文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
|
提示:上述配置文件修改了hostname,这个主要用来指定证书中站点域名,这个必须和证书签发时指定的域名一样;其次是证书和私钥的路径以及harbor默认登录密码;
根据配置文件中指定路径来创建存放harbor的数据目录
| 1 2 3 4 |
|
提示:为了避免数据丢失建议这个目录是挂载网络文件系统,如nfs;
执行harbor部署
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 |
|
域名解析,将证书签发时的域名指向harbor服务器

验证:通过windows的浏览器访问harbor.ik8s.cc,看看对应harbor是否能够正常访问到?

使用我配置的密码登录harbor,看看是否可用正常登录?

创建项目是否可用正常创建?

提示:可用看到我们在web网页上能够成功创建项目;
扩展:给harbor提供service文件,实现开机自动启动
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
加载harbor.service重启harbor并设置harbor开机自启动
| 1 2 3 4 5 6 |
|
3、测试基于nerdctl可以登录https harbor并能实现进行分发
nerdctl登录harbor
| 1 2 3 4 5 6 7 8 9 10 |
|
提示:这里也需要做域名解析;
测试从node02本地向harbor上传镜像
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
验证:在web网页上看我们上传的nginx:v1镜像是否在仓库里?

测试从harbor仓库下载镜像到本地
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
通过上述测试,可以看到我们部署的harbor仓库能够实现上传和下载images;至此基于商用公司的免费证书搭建https harbor仓库就完成了;
4、基于kubeasz部署高可用kubernetes集群
部署节点部署环境初始化
本次我们使用kubeasz项目来部署二进制高可用k8s集群;项目地址:GitHub - easzlab/kubeasz: 使用Ansible脚本安装K8S集群,介绍组件交互原理,方便直接,不受国内网络环境影响;该项目使用ansible-playbook实现自动化,提供一件安装脚本,也可以分步骤执行安装各组件;所以部署节点首先要安装好ansible,其次该项目使用docker下载部署k8s过程中的各种镜像以及二进制,所以部署节点docker也需要安装好,当然如果你的部署节点没有安装docker,它也会自动帮你安装;
部署节点配置docker源
| 1 |
|
部署节点安装ansible、docker
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
部署节点安装sshpass命令⽤于同步公钥到各k8s服务器
| 1 |
|
部署节点生成密钥对
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
编写分发公钥脚本
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
执行脚本分发ssh公钥至master、node、etcd节点实现免密钥登录
| 1 |
|
验证:在deploy节点,ssh连接k8s集群任意主机,看看是否能够正常免密登录?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
提示:能够正常免密登录对应主机,表示上述脚本实现免密登录没有问题;
下载kubeasz项目安装脚本
| 1 2 3 |
|
编辑ezdown

提示:编辑ezdown脚本主要是定义安装下载组件的版本,根据自己环境来定制对应版本就好;
给脚本添加执行权限
| 1 2 3 4 |
|
执行脚本,下载kubeasz项目及组件
| 1 |
|
提示:执行ezdown脚本它会下载一些镜像和二进制工具等,并将下载的二进制工具和kubeasz项目存放在/etc/kubeasz/目录中;
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
查看ezctl工具的使用帮助
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
使用ezctl工具生成配置文件和hosts文件
| 1 2 3 4 5 6 7 8 9 |
|
编辑ansible hosts配置文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
|
提示:上述hosts配置文件主要用来指定etcd节点、master节点、node节点、vip、运行时、网络组件类型、service IP与pod IP范围等配置信息。
编辑cluster config.yml文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 |
|
提示:上述配置文件主要定义了CA和证书的过期时长、kubeconfig配置参数、k8s集群版本、etcd数据存放目录、运行时参数、masster证书名称、node节点pod网段子网掩码长度、kubelet根目录、node节点最大pod数量、网络插件相关参数配置以及集群插件安装相关配置;

提示:这里需要注意一点,虽然我们没有自动安装coredns,但是这两个变量需要设置下,如果ENABLE_LOCAL_DNS_CACHE的值是true,下面的LOCAL_DNS_CACHE就写成对应coredns服务的IP地址;如果ENABLE_LOCAL_DNS_CACHE的值是false,后面的LOCAL_DNS_CACHE是谁的IP地址就无所谓了;
编辑系统基础初始化主机配置

提示:注释掉上述ex_lb和chrony表示这两个主机我们自己定义,不需要通过kubeasz来帮我们初始化;即系统初始化,只针对master、node、etcd这三类节点来做;
准备CA和基础环境初始化
| 1 |
|

提示:执行上述命令,反馈failed都是0,表示指定节点的初始化环境准备就绪,接下来我们就可以进行第二步部署etcd节点;
部署etcd集群
| 1 |
|

提示:这里报错说/usr/bin/python没有找到,导致不能获取到/etc/kubeasz/clusters/k8s-cluster01/ssl/etcd-csr.json信息;
解决办法,在部署节点上将/usr/bin/python3软连接至/usr/bin/python;
| 1 2 3 |
|
再次执行上述部署步骤

验证etcd集群是否正常?
| 1 2 3 4 5 6 |
|
提示:能够看到上面的健康状态成功,表示etcd集群服务正常;
部署容器运行时containerd
验证基础容器镜像
| 1 2 3 |
|
下载基础镜像到本地,然后更换标签,上传至harbor之上
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
配置harbor镜像仓库域名解析-公司有DNS服务器进⾏域名解析

提示:编辑/etc/kubeasz/roles/containerd/tasks/main.yml文件在block配置段里面任意找个地方将其上述任务加上即可;
编辑/etc/kubeasz/roles/containerd/templates/config.toml.j2⾃定义containerd配置⽂件模板;

提示:这个参数在ubuntu2204上一定要改成true;否者会出现k8spod不断重启的现象;一般和kubelet保持一致;

提示:这里可以根据自己的环境来配置相应的镜像加速地址;
私有https/http镜像仓库配置下载认证

提示:如果你的镜像仓库是一个私有(不是公开的仓库,即下载镜像需要用户名和密码的仓库)https/http仓库,添加上述配置containerd在下载对应仓库中的镜像,会拿这里配置的用户名密码去下载镜像;
配置nerdctl客户端

提示:编辑/etc/kubeasz/roles/containerd/tasks/main.yml文件加上nerdctl配置相关任务;
在部署节点准备nerdctl工具二进制文件和依赖文件、配置文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
提示:准备好nerdctl相关文件以后,对应就可以执行部署容器运行时containerd的任务;
执⾏部署容器运行时containerd
| 1 |
|

验证:在node节点或master节点验证containerd的版本信息,以及nerdctl的版本信息

提示:在master节点或node节点能够查看到containerd和nerdctl的版本信息,说明容器运行时containerd部署完成;
测试:在master节点使用nerdctl 下载镜像,看看是否可以正常下载?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
测试:在master节点登录harbor仓库
| 1 2 3 4 5 6 7 8 9 10 |
|
测试:在master节点上向harbor上传镜像是否正常呢?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
测试:在node节点上登录harbor,下载刚才上传的ubuntu:22.04镜像,看看是否可以正常下载?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
提示:能够在master或node节点上正常使用nerdctl上传镜像到harbor,从harbor下载镜像到本地,说明我们部署的容器运行时containerd就没有问题了;接下就可以部署k8s master节点;
部署k8s master节点
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 |
|
提示:上述kubeasz项目,部署master节点的任务,主要做了下载master节点所需的二进制组件,分发配置文件,证书密钥等文件、service文件,最后启动服务;如果我们需要自定义任务,可以修改上述文件来实现;
执行部署master节点
| 1 |
|

在部署节点验证master节点是否可用获取到node信息?
| 1 2 3 4 5 |
|
提示:能够使用kubectl命令获取到节点信息,表示master部署成功;
部署k8s node节点
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
|
提示:上述是部署node节点任务,主要做了分发二进制文件,配置文件,配置kubelet、kubeproxy,启动服务;

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
提示:这里说一下kubeasz部署master和node节点时,都会执行kube-lb这个role;这个role就是一个nginx,主要作用是反向代理master apiserver,即访问本地127.0.0.1:6443,对应访问会被反向代理至后端多个master apiserver,即便是在master本地也会代理;这样做的主要原因是分担外部负载均衡器的压力同时实现多master高可用;
如master上的kube-lb的配置文件

执行部署node节点
| 1 |
|

验证:在部署节点获取node信息,看看是否能够正常获取到?
| 1 2 3 4 5 6 7 |
|
提示:能够通过kubectl获取到node信息,就表示对应master和node部署完成,至少master节点和node节点该有的组件都正常工作;至此k8s集群master节点和node节点的部署就完成了,接下部署calico网络插件;
部署网络组件calico
部署calico组件配置

提示:我们可以根据自己的环境修改calico部署配置;
查看calico所需镜像

验证部署节点本地镜像
| 1 2 3 4 5 6 7 8 |
|
修改calico镜像标签为本地harbor地址
| 1 2 3 4 5 6 7 8 9 |
|
上传calico所需镜像至本地harbor仓库
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
提示:这样做的目的可以有效提高去外网下载calico镜像的时间;
验证:在harborweb页面查看对应镜像是否上传至harbor仓库?

修改配置yaml文件中的镜像地址为本地harbor仓库地址
| 1 2 3 4 5 6 |
|
执行部署calico网络插件
| 1 |
|

验证:calico pod是否正常运行?
| 1 2 3 4 5 6 7 8 |
|
master上验证calico
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
node节点上验证calico
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
提示:能够在master节点和node节点通过calicoctl 命令查询到其他节点信息,说明calico插件就部署好了;
验证pod通信
复制部署节点上/root/.kube/config文件至master节点
| 1 2 3 |
|
提示:这一步不是必须的,如果你要在master节点使用kubectl命令来管理集群,就把配置文件复制过去;
修改/root/.kube/config文件中apiserver地址为外部负载均衡地址

测试kubectl命令是否正常可用?

提示:如果能够正常执行kubectl命令,说明外部负载均衡器没有问题;
创建测试pod
| 1 2 3 4 5 6 7 |
|
查看pod IP网络地址
| 1 2 3 4 5 6 |
|
进入任意测试pod,ping其他两个pod,看看是否能够正常ping通?是否可以正常访问互联网?

提示:可以看到pod和pod之间可以正常跨主机通信,也可以正常访问到外网,这里需要注意,现在集群还没有部署coredns,所以这里直接ping www.baidu.com是无法正常解析的;
集群节点伸缩管理
添加node节点
| 1 |
|

提示:删除node节点使用 ezctl del-node k8s-cluster01 <ip>;
验证节点信息
| 1 2 3 4 5 6 7 8 |
|
添加master节点
| 1 |
|

提示:删除master节点使用 ezctl del-master k8s-cluster01 <ip>;
验证节点信息
| 1 2 3 4 5 6 7 8 9 |
|
验证calico状态
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
验证node节点路由
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
升级集群(建议跨小本号升级,如果跨大版本号升级请充分测试没有问题再升级)
升级前需提前下载好用于更新的master 组件二进制、node节点组件二进制以及客户端二进制

复制二进制文件至/etc/kubeasz/bin/
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
验证/etc/kubeasz/bin/各组件是否是我们想要升级版本
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
执行升级集群操作
| 1 |
|

验证节点版本信息
| 1 2 3 4 5 6 7 8 9 |
|
提示:上面我们使用的是kubeasz来更行k8s集群master和node;我们也可以手动更新;
手动更新
方法1:将⼆进制⽂件同步到其它路径,修改service⽂件加载新版本⼆进制,即⽤新版本替换旧版本;
方法2:关闭源服务、替换⼆进制⽂件然后启动服务,即直接替换旧版本;
将coredns及dashboard部署至kubernetes集群
部署k8s内部域名解析服务coredns
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 |
|
查看coredns 所需镜像
| 1 2 3 |
|
部署节点下载镜像,修改标签,上传至harbor仓库
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
修改部署清单镜像地址为harbor仓库地址
| 1 2 3 |
|
应用coredns部署清单
| 1 2 3 4 5 6 7 8 |
|
验证coredns pods是否正常运行?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
验证:创建测试pod,看看对应pod是否可用正常解析域名?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
提示:可用看到部署coredns以后,现在容器里就可以正常解析域名;
部署官方dashboard
下载官方dashboard部署清单
| 1 |
|
查看清单所需镜像
| 1 2 3 4 5 |
|
下载所需镜像,重新打上本地harbor仓库地址的标签并上传至本地harbor仓库
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
|
修改部署文件中镜像地址为harbor仓库对应镜像地址
| 1 2 3 4 |
|
应用dashboard部署清单
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
验证:查看pods是否正常运行?

查看dashboard 服务地址

创建admin用户和secret密钥
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
获取token
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
登录dashboard


设置token登录保持时间

再次应用部署清单
| 1 |
|
基于Kubeconfig⽂件登录
制作Kubeconfig⽂件
| 1 2 |
|
提示:在kubeconfig文件中加上token信息即可;如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
提示:将上述文件导出即可使用kubeconfig文件来登录dashboard;
验证使用kubeconfig文件登录dashboard


部署第三方dashboard kuboard
为kuboard准备存放数据的目录,安装nfs-server
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
部署kuboard
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 |
|
应用部署清单
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
访问kuboard

提示:默认用户名和密码是admin/Kuboard123

导入集群
添加集群的方式有两种,一种是agent,一种是kubeconfig;agent这种方式需要在k8s上额外运行一个pod来作为agent;
agent方式导入集群


提示:把上述命令在k8s集群上执行下就好;
kubeconfig方式导入集群


提示:需要将制作好的kubeconfig文件内容直接粘贴进来即可;

返回首页查看集群列表

提示:kuboard它可用管理多个集群;
选择使用集群的身份

查看集群概要信息

好了,第三方dashboard kuboard就部署好了,后面我们管理k8s集群就可用在kuboard上面点点;如果需要卸载kuboard ,只需要在k8s上将部署清单delete一下即可;kubectl delete -f kuboard-all-in-one.yaml;
部署第三方dashboard kubesphere
提前准备存储类相关部署清单
授权清单
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
|
存储类清单
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
NFS提供者清单
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
在NFS上准备数据目录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
应用上述授权、存储类、NFS提供者清单
| 1 2 3 4 5 6 7 8 9 10 |
|
验证:查看对应pod是否正常运行?

验证存储类是否正常创建

编辑cluster-configuration.yaml,启用插件
启用logging

提示:除了在部署前修改cluster-configuration.yaml文件来启用各种插件,也可以在部署后使用admin用户登录控制台,在平台管理,选集权管理,定制资源定义,在搜索栏里输入clusterconfiguration,点击搜索结果查看详细页面;在自定义资源中,点击kk-installer右侧编辑YAML;
应用kubesphere-installer.yaml安装清单
| 1 2 3 4 5 6 7 8 |
|
应用cluster-configuration.yaml集群配置清单
| 1 2 3 |
|
查看安装过程⽇志信息
| 1 |
|
验证:查看pods是否正常运行
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
查看kubesphere 控制台服务端口

访问kubesphere 控制台

修改密码



ok,基于第三方dashboard kubesphere部署完毕;

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)