我在 Kubernetes 上的 Spark 之旅......在 Python 中 (2/3)
在之前的文章中,我们看到了如何使用 Spark Operator 启动 Spark 应用程序。在本文中,我们将看到如何使用 spark-submit 来做同样的事情。让我们首先解释在工作节点上部署驱动程序的两种方式之间的区别。
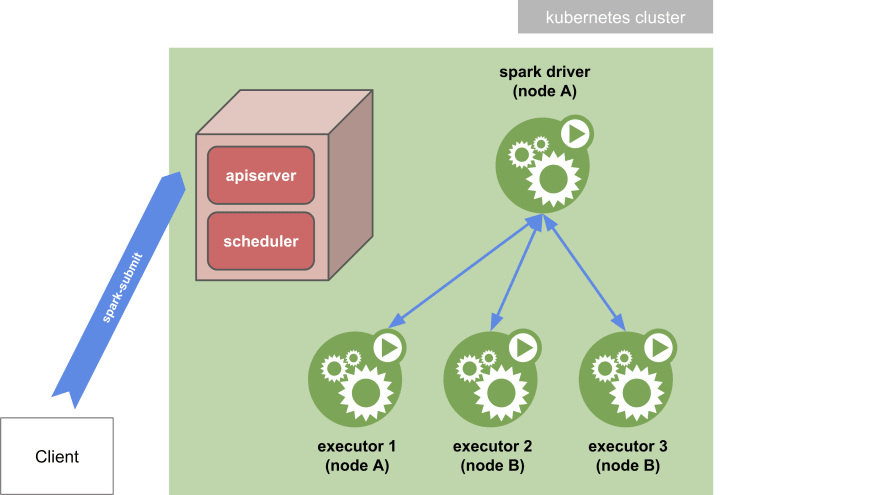
客户端与集群模式
Spark-提交集群模式
在_集群模式_中,您的应用程序是从远离工作机器的机器提交的(例如,在您的笔记本电脑上本地)。您需要在这台机器上安装 Spark 发行版才能实际运行spark-submit脚本。
在这种模式下,一旦提交了应用程序,脚本就会正常退出。然后驱动程序被分离并可以在 kubernetes 集群中独立运行。您可以使用kubectl logs命令打印驱动程序 pod 的日志以查看应用程序的输出。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--pwYVds8m--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/5fm50tip9stkxemr7jpf.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--pwYVds8m--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/5fm50tip9stkxemr7jpf.png)
可以使用身份验证kubectl代理与 Kubernetes API 进行通信。
本地代理可以通过以下方式启动:
kubectl proxy &
进入全屏模式 退出全屏模式
如果本地代理在 localhost:8001 上运行,则通过将--master k8s://http://127.0.0.1:8001指定为spark-submit的参数,可以通过spark-submit访问远程 Kubernetes 集群。
客户端模式下的Spark-submit
在 client 模式 中,spark-submit命令直接与其参数一起传递给驱动程序 pod 中的 Spark 容器。将deploy-mode选项设置为client,驱动程序直接在spark-submit进程中启动,该进程充当集群的客户端。应用程序的输入和输出附加到 pod 的日志中。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--jgPOkVvv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/lnqt2jv1t0pnshvxiy5p.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--jgPOkVvv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/lnqt2jv1t0pnshvxiy5p.png)
谁做什么?
使用“本地”Spark,我们将以客户端模式执行 Spark 应用程序,以免依赖于本地 Spark 分发。具体来说,用户用kubectl创建一个driver pod资源,然后driver pod会在内部以client模式运行spark-submit来运行驱动程序。
使用 Spark Operator,SparkApplication应将.spec.deployMode设置为cluster,因为当前未实现client。在幕后,其行为与原生 Spark 完全相同:操作员的控制器因此嵌入了一个 Spark 分发,该分发扮演着 Spark 调度器的角色;驱动程序 pod 是从控制器生成的......然后在内部以客户端模式运行spark-submit以运行驱动程序。但这对最终用户来说是全局透明的。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--CSAOU0tH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/i8bwquafdakm4ea310ha.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--CSAOU0tH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/i8bwquafdakm4ea310ha.png)
有关SparkApplications如何运行的其他详细信息,请参阅设计文档。
驱动器吊舱
对于原生 Spark,主要资源是驱动程序 pod。
要像 Spark Operator 一样运行 Pi 示例程序,必须使用以下 YAML 文件中的数据创建驱动程序 pod:
pyspark-pi-driver-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app-name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver
namespace: ${NAMESPACE}
spec:
containers:
- name: pyspark-pi
image: eu.gcr.io/yippee-spark-k8s/spark-py:3.0.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5678
name: headless-svc
- containerPort: 4040
name: web-ui
resources:
requests:
memory: 512Mi
cpu: 1
limits:
cpu: 1200m
env:
# Overriding configuration directory
- name: SPARK_CONF_DIR
value: /spark-conf
- name: SPARK_HOME
value: /opt/spark
# Configure all key-value pairs in ConfigMap as container environment variables
envFrom:
- configMapRef:
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
args:
- $(SPARK_HOME)/bin/spark-submit
- /opt/spark/examples/src/main/python/pi.py
- "10"
volumeMounts:
- name: spark-config
mountPath: /spark-conf
readOnly: true
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: In
values: [${DRIVER_NODE_AFFINITIES}]
priorityClassName: ${PRIORITY_CLASS_NAME}
restartPolicy: OnFailure
schedulerName: volcano
serviceAccountName: ${SERVICE_ACCOUNT_NAME}
volumes:
# Add the executor pod template in read-only volume, for the driver to read
- name: spark-config
configMap:
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
items:
- key: spark-defaults.conf
path: spark-defaults.conf
- key: spark-env.sh
path: spark-env.sh
- key: executor-pod-template.yaml
path: executor-pod-template.yaml
进入全屏模式 退出全屏模式
暂时不要关注变量占位符,即使您可以想象它们可以用来做什么。
如您所见,驱动程序 pod 依赖于其他 Kubernetes 资源。我们将详细介绍它们中的每一个。
火花配置
我们使用ConfigMap将 Spark 配置数据与驱动程序 pod 定义分开设置。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
namespace: ${NAMESPACE}
data:
# Comma-separated list of .zip, .egg, or .py files dependencies for Python apps.
# spark.submit.pyFiles can be used instead in spark-defaults.conf below.
# PYTHONPATH: ...
spark-env.sh: |
#!/usr/bin/env bash
export DUMMY=dummy
echo "Here we are, ${DUMMY}!"
spark-defaults.conf: |
spark.master k8s://https://kubernetes.default
spark.submit.deployMode client
spark.executor.instances 2
spark.executor.cores 1
spark.executor.memory 512m
spark.kubernetes.executor.container.image eu.gcr.io/yippee-spark-k8s/spark-py:3.0.1
spark.kubernetes.container.image.pullPolicy IfNotPresent
spark.kubernetes.namespace spark-jobs
# Must match the mount path of the ConfigMap volume in driver pod
spark.kubernetes.executor.podTemplateFile /spark-conf/executor-pod-template.yaml
spark.kubernetes.pyspark.pythonVersion 2
spark.kubernetes.driver.pod.name spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver
spark.driver.host spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver-svc
spark.driver.port 5678
# Config params for use with an ingress to expose the Web UI
spark.ui.proxyBase /spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
# spark.ui.proxyRedirectUri http://<load balancer static IP address>
executor-pod-template.yaml: |
apiVersion: v1
kind: Pod
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: executor
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: In
values: [${EXECUTOR_NODE_AFFINITIES}]
priorityClassName: ${PRIORITY_CLASS_NAME}
schedulerName: volcano
进入全屏模式 退出全屏模式
Executor Pod 模板
我们使用ConfigMap中的模板文件来定义 executor pod 配置。模板通常用于配置无法通过 Spark 属性或环境变量以其他方式配置的 Spark pod。因此,模板文件大多包含与 Kubernetes 级别的部署相关的细粒度配置:这里是节点亲和性和优先级类名称。
为了使 spark-submit 进程可以访问 pod 模板文件,我们必须在驱动程序 pod 中设置 Spark 属性spark.kubernetes.executor.podTemplateFile及其本地路径名。为此,该文件将在创建时自动挂载到驱动程序 pod 中的卷上。
Executor Pod 垃圾回收
我们还必须将 executor 的spark.kubernetes.driver.pod.name设置为驱动程序 pod 的名称。设置此属性后,Spark 调度程序将使用ownerReference部署执行程序 pod,这反过来将确保一旦从集群中删除驱动程序 pod,也将删除应用程序的所有执行程序 pod。
客户端模式网络
在客户端模式下,驱动程序在 pod 内运行。 Spark 执行器必须能够通过 Kubernetes 网络连接到 Spark 驱动程序。为此,我们使用无头服务来允许驱动程序 pod 可以通过稳定的主机名从执行程序路由。在部署无头服务时,我们通过为驱动程序 pod 分配一个(足够)唯一的标签并在无头服务的label selector中使用该标签来确保服务将仅匹配驱动程序 pod 而不会匹配其他 pod。然后,我们可以通过spark.driver.host将驱动程序的主机名与服务名称和 spark 驱动程序的端口传递给执行程序spark.driver.port。
spark-driver-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver-svc
namespace: spark-jobs
spec:
clusterIP: None
ports:
- name: 5678-5678
port: 5678
protocol: TCP
targetPort: 5678
selector:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
type: ClusterIP
进入全屏模式 退出全屏模式
火花用户界面
入口
Spark UI 可以通过创建一个ClusterIP类型的服务来访问,该服务从驱动程序 pod 中公开 UI:
spark-ui-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-svc
namespace: spark-jobs
spec:
ports:
- name: spark-driver-ui-port
port: 4040
protocol: TCP
targetPort: 4040
selector:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
type: ClusterIP
进入全屏模式 退出全屏模式
仅使用此服务,UI 只能从集群内部访问。然后我们必须创建一个Ingress以在集群外部公开 UI。为了让 Ingress 资源正常工作,集群必须有一个入口控制器
跑步。您可以选择最适合您的集群的入口控制器实现。
Traefik和Nginx是非常受欢迎的选择。下面的入口是为 Nginx 配置的:
spark-ui-ingress.yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-ingress
namespace: spark-jobs
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/proxy-redirect-from: "http://$host/"
nginx.ingress.kubernetes.io/proxy-redirect-to: "http://$host/spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}/"
spec:
rules:
- http:
paths:
- path: /spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}(/|$)(.*)
backend:
serviceName: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-svc
servicePort: 4040
进入全屏模式 退出全屏模式
Ingress 由与集群中同时运行的驱动程序 pod 一样多的服务支持。然后,每个 UI 都必须在 Ingress 中使用唯一的path进行寻址。有问题的路径直接来自 Spark 应用程序的名称,具有唯一的 ID。
该接口始终在http://<driver-pod-ip>:4040处可用(从集群内部),因为每个驱动程序 pod 都分配有一个唯一的 IP,并且 pod 主机中只有一个SparkContext运行(否则,UI 将绑定到以 4040 开头的连续端口:4041 , 4042 等)。
因此,在本机上,同一主机上可能在给定时间可用的不同 UI 仅通过分配的端口号来区分。 UI 是按照这个原则设计的,所有的 HTTP 操作都相对于 URL 中的相同根路径执行,即.../。
因此,要通过 Ingress 有效访问 UI,我们必须使用备用根路径(在 Ingress 中配置的路径)设置 HTTP 重定向。为了顺利工作,UI 本身必须通过将spark.ui.proxyBase设置为此根路径来了解此重定向......就是这样!
火花运算符
Operator 支持为 Spark Web UI 创建可选的 Ingress。这可以通过设置ingress-url-format命令行标志来打开。ingress-url-format应该是类似{{$appName}}.{ingress_suffix}/{{$appNamespace}}/{{$appName}}的模板。{ingress_suffix}应该由用户替换以指示集群的 Ingress url,并且操作员会将{{$appName}}和{{$appNamespace}}替换为适当的值。请注意,Ingress 支持需要正确设置集群的 Ingress url 路由。例如如果ingress-url-format是{{$appName}}.ingress.cluster.com,则要求任何*.ingress.cluster.com都应该路由到 K8s 集群上的 Ingress 控制器。
使用ingress-url-format命令行标志安装 Spark Operator 的示例:
./helm install spark-operator incubator/sparkoperator --namespace spark-operator --set enableWebhook=true --set enableBatchScheduler=true --set ingressUrlFormat="\{\{\$appName\}\}.ingress.cluster.com"
进入全屏模式 退出全屏模式
请注意,大括号必须被转义。
未来工作
在我的实验过程中,我无法启用 Spark Operator Ingress,只是因为需要 DNS 名称。相反,与原生 Spark 相同的 Ingress 被“嫁接”到SparkApplication,并使用基于路径的路由。
Spark Operator 提出的操作,基于主机名通配符(例如*.ingress.cluster.com)的路由,仍然很有趣,因为它可以克服上述 HTTP 重定向问题。
使用主机名通配符,因此没有 HTTP 重定向,UI 服务可以切换到NodePort类型(NodePort 服务在每个节点的 IP 上的静态端口上公开服务)并且仍然与 Ingress 兼容。
因此,可以通过配置了外部 URL 的 Ingress 和位于http://<node-ip>:<service-port>的NodePort服务在集群外部访问 UI。NodePort类型的服务在私有云中仍然是相关的。
对象名称和标签
我们使用app-name标签对与单个 Spark 应用程序相关的所有 Kubernetes 资源进行语义分组。
在我们的例子中,这个标签提供了唯一性,我们不希望多个 Spark 应用程序为这个标签携带相同的值(至少在 namespace-time 所考虑的范围内)。
对于给定的 Spark 应用程序,所有对象名称都从app-name派生。我们只需添加一个后缀,该后缀也限定了对象的类型:驱动程序 pod 为-driver,驱动程序服务为-driver-svc,Spark UI 服务为-ui-svc,-ui-ingress用于 Spark UI 入口,-cm用于 ConfigMap。
我们还在 pod 级别设置了标签spark-role,以区分驱动程序和执行程序。
这种命名和标注与 Spark Operator 一致。因此,无论是使用 Spark Operator 还是使用 spark-submit 启动,都可以以相同的方式处理和过滤 Spark 应用程序。 👍
部署
我们现在已经设法模仿了使用 Spark Operator 获得的相同行为,这是我们在 Kubernetes 中部署的内容:
[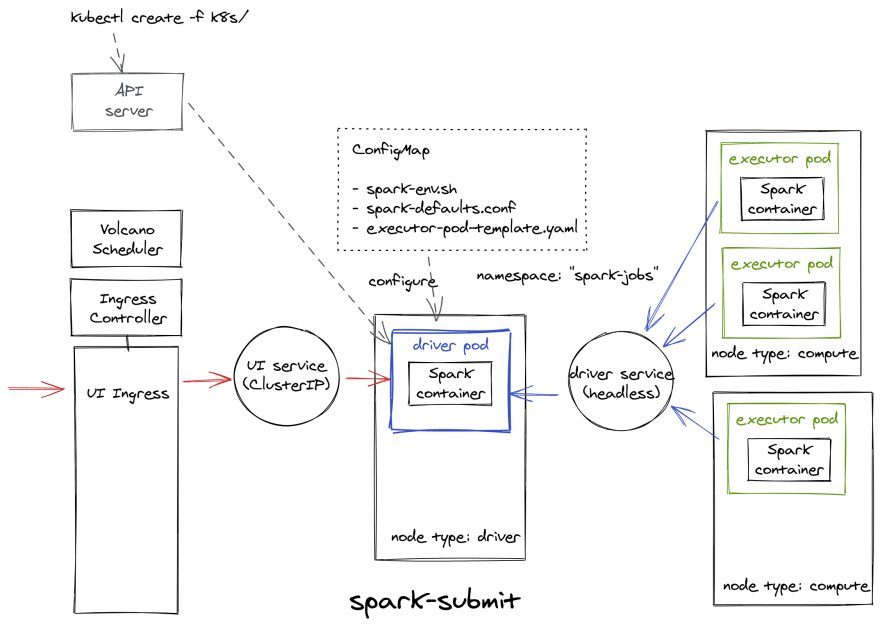 ](https://res.cloudinary.com/practicaldev/image/fetch/s--RKlsmiwj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/63lp45g1c8bh3tf9rprx.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RKlsmiwj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/63lp45g1c8bh3tf9rprx.png)
现在我们已经为 spark-submit 定义了所有的 Kubernetes 资源,我们将着手编写一些 Python 代码来编排所有这些。本系列第三篇也是最后一篇文章见。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献4375条内容
已为社区贡献4375条内容

所有评论(0)