51c大模型~合集131
该算法超越了目前广泛使用的 GRPO 等方法,定义了一个更广泛的算法设计空间,能将 PRIME、DAPO 等方法的优点融合入算法框架中,无需蒸馏超大参数规模模型,便实现了轻中量级(7B/32B)模型推理能力的再提升。值得一提的是,研究人员观察到,在基于 InternBootcamp 的多任务混合训练过程中,出现了强化学习的 “涌现时刻”:在单一任务中,无法成功推理得到奖励的模型,通过多个任务混合的
我自己的原文哦~ https://blog.51cto.com/whaosoft/13941618
#InternBootcamp
通专融合,思维链还透明,上海AI Lab为新一代大模型打了个样
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。这一趋势在国内也得到印证。
刚刚,上海 AI Lab 宣布创造性构建了 “加速训练营”(InternBootcamp),通过对评价建模,与大模型进行交互并提供反馈,从而使大模型持续进化,获得解决复杂推理任务的能力。
通过上述方法以及一系列通专融合底层技术架构创新,书生・思客(InternThinker)实现在奥赛级数学、科学对象理解与推理、算法编程、棋类游戏、智力谜题等多个专业任务同步学习演进,并在多任务混合强化学习过程中出现智能 “涌现时刻”。
随着 InternThinker 专业推理能力升级,它成为我国首个既具备围棋专业水平,又能展示透明思维链的大模型。在实验室科研人员的布局和着子中,蕴含数千年智慧的围棋成为了科学探索的 “试应手”。
思维链透明,自然语言点评“神之一手”
围棋作为一项具有四千多年历史的智力竞技项目,因其独特的复杂性和对人类智能的深刻体现,可作为衡量人工智能专业能力最具代表性的任务之一。2016 年 AlphaGO 一战成名,随后,AI 在棋力、效率、通用性等方面均有显著提升,但其具体推理过程仍为 “黑盒”,即便能输出胜率评估和落子概率,亦无法用人类语言解释 “为什么某一步更好”。典型表现为:AI 有时会下出违背人类直觉的 “天外飞仙” 棋步,事后被证明有效,但当时难以解释。
本次升级后的 InternThinker,在围棋任务上不仅具备较强的专业水平,在大模型中率先实现打破思维 “黑盒”,运用自然语言就对弈过程进行讲解。目前 InternThinker 已开启公测,所有用户均可以随时随地与之对弈(公测链接:https://internlm-chat.intern-ai.org.cn/)。
用户在与 InternThinker 对弈的过程中,大模型化身为循循善诱的 “教练”,它能全面地分析当前局面形势,对不同的落子点进行判断和对比,并给出明确的结果,让用户了解每一步棋背后的推理过程和决策依据,从而帮助用户更好地理解和学习围棋。
李世石在与 AlphaGO 交战的第四盘 78 手下在 L11,被称为 “神之一手”,直接扭转局势赢下一局。在研究人员对这一名局的复现中,InternThinker 评价这步棋 “相当刁钻…… 这步棋完美解决 L11 的威胁,重新确立中央控制权,为后续进攻埋下伏笔。” 随后它给出了落子在 L10 的应对策略。

InternThinker 应对李世石 “神之一手”
InternThinker 还具备多样化的 “语言” 风格,极具 “活人感”。比如,当用户下了一步好棋,它会加油鼓励:“这步棋相当有力,可以说是‘以攻代守’的好手”;也会冒出毒舌锐评:“可以说是‘不是棋’的选择”。

InternThinker 多样化的语言风格
在棋力方面,InternThinker 未来仍有提升空间。新生代世界围棋冠军王星昊九段在与其对弈后评价道:“能解说思考过程的 AI 还是第一次见,感觉它分析得非常好;从布局看棋力可能在职业 3-5 段之间。”
InternBootcamp:“体验” 即学习,探索大模型推理能力提升新范式
InternThinker 强大的推理能力及在围棋任务上的突破,得益于其创新的训练环境。针对复杂的逻辑推理任务,如何准确地获得过程和结果反馈尤为关键,为此,研究人员搭建了大规模、标准化、可扩展的可交互验证环境 InternBootcamp—— 这相当于为模型创造了一个 “加速训练营”,使其可以高效习得专业技能,快速 “成长”。

InternBootCamp 与大模型交互流程
基于代码智能体自动化构造,InternBootCamp 包含超 1000 个验证环境,覆盖广泛的复杂逻辑推理任务,能有效帮助大模型领域研究者基于强化学习开展探索。InternBootcamp 可以批量化、规范化生成难度可控的推理任务,如奥赛级数学、科学对象理解与推理、算法编程、棋类游戏、智力谜题等,并与大模型进行交互和提供反馈。通过不同专业知识大规模构造和混合训练,使大模型跳出基于数据标注获取问题和答案的繁琐模式,同时避免传统奖励模型的欺骗,从而实现大模型推理能力提升的新范式。
除围棋外,在其他任务中 InternThinker 也有不俗表现。通过对多种任务的混合强化学习,InternThinker 在包括数十个任务的测试集上的平均能力超过 o3-mini、DeepSeek-R1 以及 Claude-3.7-Sonnet 等国内外主流推理模型。

InternThinker 在包括数十个任务的测试集上的平均能力超过 o3-mini、DeepSeek-R1 以及 Claude-3.7-Sonnet 等国内外主流推理模型。
甚至在一些任务中性能表现远超当前其他推理大模型。


InternBootcamp 已开源,欢迎接入任务,开展更多有价值的探索:https://github.com/InternLM/InternBootcamp
多任务混合强化学习:迎来 “涌现时刻”
值得一提的是,研究人员观察到,在基于 InternBootcamp 的多任务混合训练过程中,出现了强化学习的 “涌现时刻”:在单一任务中,无法成功推理得到奖励的模型,通过多个任务混合的强化学习,能够在训练过程中成功得到奖励,实现领域外专业任务的有效强化学习训练。
除了单独训练 Tapa、Unicoder25 任务外,研究人员额外选择了几十种任务进行混合训练。如下图所示:单一训练 Tapa 等任务并不能成功获得任务的正向反馈;而混合训练各类 InternBootcamp 任务达一定步数后,InternThinker 融合学习了这些推理任务的思考方式,建立起了不同任务间的关联,从而成功获取了 Tapa 这类任务的正向反馈,实现对该任务的有效学习。
这意味着,随着 InternBootcamp 任务的数量增加、质量提升和难度加大,大模型有望迎来能力的 “升华”,高效解决更多、更难、更具实用性的推理任务,在助力大模型推理能力泛化的同时,加速推动科学发现。


Unicode25 任务和 Tapa 任务 "涌现时刻",其中浅色表示峰值、深色表示均值
通专融合底层技术突破
上述进展得益于近期上海 AI Lab 在通专融合路线的底层技术和架构方面的一系列创新突破。
从大模型发展历程来看,主要分化为专业性和通用泛化性两大路线。上海 AI Lab 率先提出通专融合技术路线(https://arxiv.org/abs/2407.08642),着力解决大模型高度专业化与通用泛化性相互制约的发展困境。这一路径的关键在于同步提升深度推理与专业泛化能力,使模型不仅在广泛的复杂任务上表现出色,还能在特定领域中达到专业水平。
上海 AI Lab 进一步提出通过相互依赖的基础模型层、 融合协同层和探索进化层 “三层” 技术路径, 可打造 “通用泛化性”“高度专业性”“任务可持续性” 三者兼得的通用人工智能。

通专融合 AGI 实现路径
第一层为基础模型层,旨在构建通用泛化基础能力和高密度监督的专业能力。上海 AI Lab 团队近期提出全新的 “记忆体 + 解码器” 大模型架构 Memory Decoder,并实现两个组成部分通过不同的预训练任务分别进行训练。区别于将所有信息全都编码进 decoder 的现有 Transformer 经典大模型架构,该架构实现了通专融合中 “知识与推理可分离与自组合” 的新一代大模型。其中,记忆体承担 “专” 的功能,负责对不同领域知识的可靠记忆;解码器承担 “通” 的功能,负责通用的语言组织和逻辑;记忆体可经过一次训练后应用于不同基模型。
第二层为融合协同层,通过多路线协同构建比肩人类专家的通专融合能力。团队近期的突破包括:
设计强化学习算法 PRIME(https://arxiv.org/abs/2502.01456),结合高密度监督信号,有效强化了智能体专精能力的提升效率,为通用群体智能发展铺平了道路。可实现更快速的收敛,同时获取比现有方法高出 7% 的性能提升。在 AIME、MATH 等竞赛难度数学题上,仅用少量开源数据,便可使得 7B 模型的数学能力显著超越 OpenAI 的 GPT-4o。
推出以多任务强化学习为核心的后训练技术框架 MoR,聚焦实现多任务的强化学习。针对不同类型任务(例如数学解答和证明、科学问答、推理解谜、主观对话等)进行了算法探索和初步集成验证,实现了多任务强化学习的混合训练。
构建基于结果奖励的强化学习新范式 OREAL(https://arxiv.org/abs/2502.06781),着力解决大模型当前面临的 “稀疏奖励困境、局部正确陷阱和规模依赖魔咒” 三大困局。该算法超越了目前广泛使用的 GRPO 等方法,定义了一个更广泛的算法设计空间,能将 PRIME、DAPO 等方法的优点融合入算法框架中,无需蒸馏超大参数规模模型,便实现了轻中量级(7B/32B)模型推理能力的再提升。
第三层为探索进化层,通过自主探索与反馈修正实现 AI 自我进化闭环。团队近期的突破包括:
测试时强化学习(TTRL)框架(https://arxiv.org/abs/2504.16084),有效探索人工智能自主进化的可能路径。TTRL 能在没有准确标签的情况下进行奖励估计,驱动模型朝着正确的方向学习,有力支持了在减少人工标注依赖方面的潜力,进一步推动强化学习向大规模、无监督方向的持续扩展。
构建分子逆合成新方法 Retro-R1,基于大模型 + 智能体 + 长推理 + 强化学习的范式,在多步逆合成问题上展现出了更精准的合成路径规划能力。Retro-R1 在不使用任何 SFT 数据仅使用 1 万条强化学习数据通过 200 步训练的情况下就实现了大模型在逆合成推理能力的升级,并在不同领域数据中展现出了出色的泛化能力。
据悉,未来上海 AI Lab 将系统推进通专融合技术路线的发展与探索,将通专融合的新能力、新进展持续通过 InternBootcamp 对外开放,加速以新一代通专融合基座模型的方式解决具体科学发现中的关键问题,同时牵引打造垂直领域示范应用案例,为科学发现与产业创新提供关键驱动力。
....
#Maia 200问世
刚刚,微软全新一代自研AI芯片Maia 200问世
一觉醒来,我们看到了微软自研 AI 芯片的最新进展。
微软原定于 2025 年发布的下一代 AI 芯片 Maia 200,终于在今天问世!

微软 CEO Satya Nadella
根据微软官方介绍,Maia 200 作为一款强大的 AI 推理加速器,旨在显著改善 AI token 生成的经济性。
Maia 200 基于台积电的 3 纳米工艺打造,配备原生 FP8/FP4 张量核心、重新设计的内存系统,拥有 216GB HBM3e 内存、7TB/s 带宽以及 272MB 片上 SRAM,并配有数据传输引擎,从而能够保证大规模模型高效、快速地进行数据流动。
这些使得 Maia 200 成为任何超级计算平台中表现最强的第一方硅片,其 FP4 性能是第三代 Amazon Trainium 的三倍,FP8 性能超越了谷歌第七代 TPU。
与此同时,Maia 200 还是微软迄今为止最高效的推理系统,每美元性能比该公司当前集群中的最新一代硬件提升了 30%。

Maia 200 是微软异构 AI 基础设施的重要组成部分,将为包括 OpenAI 最新 GPT-5.2 在内的多个大模型提供支持,为 Microsoft Foundry 和 Microsoft 365 Copilot 带来更高的性价比优势。
微软超级智能团队将利用 Maia 200 进行合成数据生成和强化学习,以提升下一代自研模型的性能。在合成数据流水线应用场景中,Maia 200 的独特设计有助于加速高质量、特定领域数据的生成与筛选,从而为后续的模型训练提供更及时、更具针对性的信号。
Maia 200 已部署在爱荷华州德梅因附近的美国中部数据中心区域,接下来将部署在亚利桑那州菲尼克斯附近的美国西部 3 区域,未来还将扩展至更多地区。
Maia 200 与 Azure 实现了无缝集成。目前,微软正在开放 Maia SDK 的预览,该 SDK 提供了一整套用于构建和优化 Maia 200 模型的工具,涵盖了 PyTorch 集成、Triton 编译器、优化内核库以及对 Maia 底层编程语言的访问权限。这既能让开发者在需要时进行精细化控制,又能实现模型在不同异构硬件加速器之间的轻松迁移。
对于微软这波突如其来的「秀肌肉」,社区反响热烈。
有网友送出点赞,并强调了微软在基础设施层面的统治力。

也有人关心上面是否能安装最近爆火的 Clawdbot。

也不乏灵魂拷问/调侃。

专为 AI 推理打造
Maia 200 芯片采用台积电最先进的 3 纳米工艺制造,单颗芯片包含超过 1400 亿个晶体管。它专门针对大规模 AI 工作负载进行了定制,同时兼顾了极高的能效比。因此,无论是在性能还是成本效益方面,Maia 200 均表现卓越。
Maia 200 专为使用低精度计算的最新模型设计,在 750W 的 SoC 热设计功耗(TDP)范围内,单颗芯片可以提供超过 10 PetaFLOPS 的 FP4 性能和超过 5 PetaFLOPS 的 FP8 性能。
从实际应用来看,Maia 200 可以轻松运行当今规模最大的模型,并为未来更庞大的模型预留了充足的性能空间。

关键在于,算力(FLOPS)并非提升 AI 速度的唯一因素,数据的传输效率同样至关重要。Maia 200 通过重新设计的内存子系统解决了这一瓶颈。
该子系统以窄精度数据类型为核心,配备了专门的 DMA 引擎、片上 SRAM 和专用的片上网络(NoC)总线,用于实现高带宽数据移动,从而提升了 Token 吞吐量。

优化的 AI 系统
在系统层面,Maia 200 引入了一种基于标准以太网的新型两层 Scale-up 网络设计。通过定制的传输层和紧密集成的网卡(NIC),它在不依赖私有协议矩阵的情况下,实现了高性能、高可靠性和显著的成本优势。
每个加速器可以提供:
- 2.8 TB/s 的双向专用 Scale-up 带宽;
- 在包含多达 6,144 个加速器的集群中,实现可预测的高性能集合通信。
这种架构为密集型推理集群提供了可扩展的性能,同时降低了功耗和 Azure 全球机架的整体拥有成本(TCO)。
在每个托架(tray)内,四个 Maia 加速器通过直接的非交换链路全连接,使高带宽通信保持在本地,实现最佳推理效率。机架内和机架间的联网均采用相同的 Maia AI 传输协议,通过最少的网络跳数实现跨节点、机柜和集群的无缝扩展。
这种统一的架构简化了编程,提高了工作负载的灵活性,减少了闲置容量,并在云端规模下保持了性能与成本效率的一致性。

云原生开发模式
Microsoft 芯片开发计划的一个核心原则,是在最终芯片就绪之前,尽可能地验证整个端到端系统。
针对 Maia 200,一套复杂的预芯片环境从架构设计之初便发挥了引导作用,能够高保真地模拟大语言模型的计算与通信模式。正是通过这种早期的协同开发环境,微软得以在首颗芯片生产出来之前,就将芯片、网络与系统软件视为统一整体进行深度优化。
为了确保 Maia 200 能够在数据中心实现快速且无缝的部署,微软从设计阶段就同步开展了对后端网络及第二代闭环液冷换热单元等复杂系统组件的早期验证。通过与 Azure 控制平面的原生集成,该系统在芯片和机架层面实现了安全性、遥测、诊断及管理能力的全面覆盖,从而显著提升了生产级关键 AI 负载的可靠性与运行时间。
得益于这些投入,在首批封装件送达后的几天内,AI 模型便已在 Maia 200 芯片上成功运行。从首颗芯片到首个数据中心机架部署的时间缩短了一半以上,优于同类 AI 基础设施项目。这种从芯片到软件再到数据中心的端到端方法,直接转化为更高的利用率、更短的投产时间,以及在云规模下每美元性能和每瓦特性能的持续提升。

大规模 AI 时代才刚刚开启,基础设施将决定创新的边界。微软表示,Maia AI 加速器计划是跨代发展的。
在向全球基础设施部署 Maia 200 的同时,微软已经在设计未来几代产品,并期待每一代都能不断树立新标杆,为最重要的 AI 工作负载提供更卓越的性能和效率。
官方博客:
https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
....
#A Practical Survey of Actionable Mechanistic
大模型哪里出问题、怎么修,这篇可解释性综述一次讲清
过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。
正是在这一背景下,来自香港大学、复旦大学、慕尼黑大学、曼切斯特大学、腾讯等机构的研究团队联合发布了 “可实践的机制可解释性”(Actionable Mechanistic Interpretability)综述。文章通过 "Locate, Steer, and Improve" 的三阶段范式,系统梳理了如何将 MI 从 “显微镜” 转化为 “手术刀”,为大模型的对齐、能力增强和效率提升提供了一套具体的方法论。

- 论文标题:Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
- 论文链接:https://arxiv.org/abs/2601.14004
- 项目主页:https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey
从 “显微镜” 到 “手术刀” 的范式转移
尽管大语言模型(LLM)近年来在多种任务上展现出了强大的能力,但其内部的运作机制依然在很大程度上不透明,常被视为一个 “黑盒”。围绕如何理解这一黑盒,机制可解释性(Mechanistic Interpretability, MI)逐渐发展为一个重要研究方向。
然而,现有的 MI 研究大多仍停留在 “观察” 层面:例如哪些神经元编码了特定实体、哪些注意力头参与了指代消解、哪些计算电路实现了算术或逻辑功能。但一个更关键的问题仍有待回答 —— 这些机制层面的发现,如何真正转化为模型行为和性能的实际改进?
正是基于这一问题,研究团队撰写了这篇以实践为导向的系统性综述。不同于传统综述侧重于回答 “模型内部有什么”,本文将关注点转向 “可以对模型做什么”,并围绕 "定位->操控->提升" 这一闭环,系统梳理了机制可解释性如何走向可实践的模型改造路径。

1. Locate:像医生一样精准 “定位” 病灶
干预的前提是准确的诊断。文章首先构建了一套系统的可解释对象(Interpretable Objects)定义与分类体系,为后续的机制分析奠定了基础。
- 微观层面:从传统的神经元(Neuron) 到近年来广泛使用的稀疏自编码器特征(SAE Feature)。
- 宏观层面:涵盖注意力头(Attention Heads)、残差流 (Residual Stream) 等组件。
- 诊断工具:梳理了包括因果归因(Causal Attribution)、探针(Probing)、梯度检测(Gradient Detection) 等主流定位技术。

2. Steer:面向干预的 “手术” 手段
当关键对象被定位出来之后,对其进行干预便成为可能。这也标志着机制可解释性从 “观察” 迈向 “可实践” 的关键一步。文章将现有的干预手段归纳为三大类:
- 幅度操控(Amplitude Manipulation):对目标对象进行置零/缩放/替换(ablation, scaling, patching)等操作,实现 “开关式” 或 “强度式” 控制。
- 靶向优化(Targeted Optimization):利用定位到的关键组件进行参数级的微调(如仅微调特定的 Attention Heads),比全量微调更高效、副作用更小。
- 向量运算(Vector Arithmetic):在激活空间中加入/移除任务向量或特征向量,实现推理时引导模型行为。

3. Improve:MI 赋能的三大应用场景
Application 章节中将其划分为三大类别,并逐一呈现了 MI 在这三个维度上的实质性提升:
- 对齐(Alignment):通过定位与有约束的干预,减少有害行为、降低幻觉或提升遵循指令的稳定性。
- 能力(Capability):把机理层面的 “功能模块”转化为具体的能力增强路径(例如更稳的推理、记忆或语言生成)。
- 效率(Efficiency):探索更灵活的干预与压缩手段,为高效训练,推理加速与部署成本提供新抓手。

【Paper List 指南】
对相似领域的可解释性工作,研究团队将分散的研究成果做成了 “可检索的图表”:每篇论文都用统一标签标出它在研究什么、怎么找到关键位置、以及如何进一步用来引导模型行为,以便将不同研究路线的代表性工作进行直观对照,快速定位与自身需求最契合的的关键论文。





(左右滑动查看更多论文)
【结语】
本综述通过 "Locate-Steer-Improve" 的框架,首次系统地勾勒出了 MI 从分析走向具体干预的路线图。
展望未来,作者团队认为 MI 的核心挑战与机遇在于打破 “各自为战” 的局面 —— 需要建立标准化的评估基准(Standardized Evaluation),验证干预手段的泛化性;同时推动 MI 向自动化(Automated MI)演进,最终实现让 AI 自主发现并修复内部错误的愿景。
期待这篇综述能为社区提供一份详实的 “指南”,推动大模型从不可解释的黑盒,真正走向透明、可控、可信的未来。
....
#亿万富豪本豪,复出只因退休太空虚
Clawdbot作者~
火爆全网的Clawdbot,作者竟然是个亿万富翁?!
本来以为又是个辍学的AI创业者,结果上网一查,这哥们早在十五年前就创过业,今年估计已经四十岁了。
而且第一次创业就直接起飞。
2011年创业,2021年套现退出,狠狠捞了1亿欧元 (约8.3亿人民币)。
照理说,财富自由后的剧本应该是:白天挥杆高尔夫,晚上红酒配龙虾。
你猜怎么着?
仅仅过了四年清闲日子,这哥们就就坐不住了,手痒得不行,又开始全职写代码,进军AI创业。
一年不到,就搞出了Clawdbot。
一个7x24小时的开源AI助理,会主动出击,像私人秘书一样向用户汇报。
Agent能干的都能干,可以能填表格、发邮件、控制浏览器……
「真·贾维斯」。
全网刷屏的现象级AI产品,顺手帮库克给Mac mini冲了波业绩。
网友高呼:绝对的GOAT。
接下来就一起看看,Clawdbot作者,「贾维斯」之父的传奇人生。
上半场:独自创业的iOS工程师
大佬叫Peter Steinberger (下面就叫他彼得吧),奥地利人,本科毕业于维也纳科技大学,修读计算机与信息科学。
事实上,还在上学的彼得就已经是一名资深的iOS开发者。读书期间,他就为多个知名iOS项目提供过技术咨询和一对一培训。
甚至,母校的第一门Mac/iOS开发课程,都是在彼得的参与推动下开设的。
2010年,彼得靠这门手艺,接到了个即将改变他人生的订单。
客户想做一个基于PDF格式的杂志类App,彼得花了八周时间,为他们完整开发了一个iOS版本。
起初,他并没把这当成什么大事。
但没过多久,一位同事突然问他:「我能不能也用这套引擎?」
彼得一激灵,发现这事不简单。
那时第一代iPad刚发布不久,应用程序正在把越来越多的体验转移到数字世界,而纸质文档,很可能就是最早被重构的对象之一。
而一旦文档电子化,就得额外添加电子签名、文档查看、编辑、批注、协作等功能。
企业想自己做这些,面临很高的技术门槛。
于是,2011年,彼得启动了一个Solo项目——PSPDFKit。
名字也很直白:P来自Peter;PDF指PDF文件;Kit代表SDK工具包。
项目推进得异常快。彼得几乎在一天之内就搭了一个带网店的网站,在推特上发了条消息。第一周就卖出了好几份授权。
不过,那时他并没打算全职创业。
事实上,彼得已经接受了一份硅谷的程序员工作。只是去美国的工作签证审批得异常慢,足足要等九个月。
但也正是这九个月,给了他一段意外的「空窗期」。他没再接其他兼职,把全部时间都用来打磨PSPDFKit。
谁能想到,这个副业的进展有点过于顺利了……
几乎从第一天起就开始盈利。等彼得真正入职硅谷公司时,PSPDFKit带来的收入,已经超过了他的工资。
四个月后,彼得又回到了家乡,彻底All in PSPDFKit,开始正式扩充团队,并引入了两位联合创始人。
事实证明,他的确踩中了风口:
文档处理工具,哪怕只是像「预览云端文件」这样的功能,在当时都非常难做。却又是企业不得不做的东西。
现在,PSPDFKit把这套底座打好了,企业只需付一笔订阅费,就能直接接入SDK和API使用。
彼得的生意自然便是一路高歌猛进。
到2021年,PSPDFKit几乎已经成为文档处理领域的事实标准。客户包括Apple、Adobe、汉莎航空、Dropbox、迪士尼等知名企业,间接服务覆盖150个国家,触达近10亿消费者。
而彼得的人生,也在这一年迎来了拐点。
2021年10月,著名机构Insight Partners宣布投资PSPDFKit。彼得选择在这一节点套现退出,出售了大部分股份,交易金额约为1亿欧元。
彼得的下半场
但故事,这才刚刚开始……
实现财富自由的彼得,感到前所未有的空虚。
当卖掉我在PSPDFKit的股份时,我心如刀绞。
PSPDFKit是彼得13年的心血。可他实在太累了,必须得停一停了,而Insight Partners的出现提供了宝贵的机会。
退休后,彼得尽情狂欢、享乐,还搬去了另一个国家生活。
但这一切,只让他觉得自己是一副行尸走肉。
为了填补内心的空虚,他尝试了各种心理治疗,甚至还接触了死藤水——一种源自南美的传统致幻饮品。
这样的日子,一晃就是四年。
直到某一天,彼得突然意识到:换城市、换国家,都无法带来真正的幸福;人生的意义,可能永远也找不到了。
因为真正的意义——
需要我自己去创造。
一天,彼得久违地冒出了一个新点子,坐到电脑前开始动手写代码。
那一刻我意识到,自己的火花又回来了。
他恍然大悟,原来将想法付诸实践,写代码,一直是他人生中最快乐的事情。
于是,2025年6月,彼得在自己的博客上宣布复出。
领英上,他的最新身份是Amantus Machina的创始人,致力于研发下一代超个性化AI Agent。
半年后,Clawbot火爆全网,成为2026年第一个真正意义上的病毒级AI产品。
前阵子听播客时,Lovart的创始人提到一个观点:
移动互联网时代,头部效应太强,上一代很多优秀的创业者,还没来得及完全施展拳脚,窗口就已经关上了。
不少人都憋着鼓劲。
而现在,技术正在撕开一个前所未有的巨大窗口。AI横空出世,终于有了一个把所有产品都重做一遍的机会。
对上一代的许多创业者而言,这简直就像是一张迟到多年的入场券。
同样也是彼得的心中所想:
我们回来了……是时候大干一场了。
参考链接:
[1]https://steipete.me/
[2]https://brutkasten.com/artikel/pspdfkit-wiener-startup
[3]https://techcrunch.com/2021/10/01/pspdfkit-raises-116m-its-first-outside-money-now-nearly-1b-people-use-apps-powered-by-its-collaboration-signing-and-markup-tools/
....
#RAE 走向文生图
高维语义 latent 如何让扩散模型更稳、更好学
NYU谢赛宁团队将RAE从ImageNet拓展至文生图:冻结SigLIP-2高维语义编码器,训练轻量Decoder,在0.5B–9.8B DiT上收敛速度比FLUX-VAE快4.6倍,微调256轮无过拟合;统一理解与生成于同一latent空间,支持LLM直接在语义空间做Test-time scaling选优,为原生多模态统一模型开辟新路径。
NYU 谢赛宁团队最近的工作提出 RAE:用一个语义信息丰富的,预训练好的 Encoder。训一个用于生成任务的,作为辅助的 Decoder。RAE 相比于 VAE 的特点之一是 latent space 的维度特别高,且 latent space 包含着丰富的语义信息。
RAE 在实验上,在 ImageNet 上做了生成任务的验证。
如今原版作者团队沿着 RAE 的道路继续探索,在文生图 (text-to-image, T2I) 任务也取得了突破。本文继续解读。
作者首先顺延 RAE 的做法,冻结预训练的 Encoder (这里是 SigLIP-2)。然后,缩放 Decoder,并在网络数据,合成数据和文本渲染数据上训练。作者发现:缩放总体而言提升了生成质量,但是目标数据的组成对于特定的域很重要。
然后,作者测试了 RAE 为 ImageNet 设计的 design choices:
- 宽的 DDT head
- 维度相关的 noise scheduling
- 噪声增强的 Decoder
在 scaling 之后,作者发现 2 依然重要,但是 1 和 3 的作用就很小了。
作者把 RAE 与 FLUX VAE 在不同规模的 Diffusion Transformer 上进行了对比,参数量从 0.5B 到 9.8B。结果显示在预训练阶段 RAE 在不同规模的模型中一致性地超过了 VAE。在高质量数据微调阶段,VAE 在 64 epochs 出现了灾难性过拟合。但是,RAE 在 256 epochs 时保持稳定,取得更好的表现。
在所有实验中,基于 RAE 的扩散模型表现出了更快的收敛速度以及更好的生成质量。此外,理解生成能够在一个共享的 latent representation space 中进行,这点也为统一模型的设计带来了新的可能。

图1:RAE 在大规模文生图训练中比 VAE 收敛更快。图示是 GenEval (4.0×) 和 DPG-Bench (4.6×)
下面是对本文的详细介绍。
01 原班人马,RAE 扩展到文生图任务
论文名称:Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
论文地址:https://arxiv.org/pdf/2601.16208
项目主页:https://rae-dit.github.io/scale-rae/
1 Scale-RAE 论文解读:
1.1 Scale-RAE 做了什么事?
关于文生图模型,一般是通过 VAE 把输入从像素空间压缩到一个 latent space 进行的。
与此同时,表征学习的进步依赖于自监督学习范式,文本监督范式等等。表征学习模型提取出来的表征,相比于 VAE 来讲,其 latent 的维度较高,且具有更加丰富的语义信息。
高维度的 latent 表征曾普遍被认为不适合生成式建模。Representation Autoencoder (RAE) 冻结预训练的 Encoder,基于这个高维度的 latent 训练了一个轻量的 Decoder。这个 Decoder 的功能就是根据高维度的 latent 完成重建像素。有了它,我们就可以在这个 semantic latent space 中训练 Diffusion 模型。RAE 也是在 ImageNet 上验证了在这个 semantic latent space 中进行 diffusion,相比基于 VAE 的 diffusion 可以实现更加高效的训练。
但是,ImageNet 代表了一种极简场景:
- 固定的分辨率
- 精心选择的图像内容
- class-conditional 的图像生成任务
RAE 能不能适配形式更加自由的文生图任务?特点:
- 视觉多样性更高
- 开放词表 + 任意的关系组合的复杂画面
- 更大的模型和计算
在这样的场景下,高维度的 latent 是否还能胜任。本文就是探索 RAE 能否在 T2I 的场景下成功做 scaling。配置:
- RAE 冻结 Encoder:SigLIP-2
- T2I 框架:MetaQuery (利用了预训练的 LLM)
Scale-RAE 这个工作主要探索了两大部分。
其一,探索更多数据下的 Decoder 训练。
结论:
- 把数据从 ImageNet 扩展到网络数据以及合成数据,只对 ImageNet 产生微小的帮助。更多样化的自然图像 (比如 YFCC) 帮助更多。
- 文本的重建不能缺少 text-specific 数据。加一些文本渲染数据对于文本重建帮助很大。
其二,探索 RAE 的 design choices 在大规模文生图任务中的重要性。
结论:在 RAE 的 design choices 中,
- 维度相关的 noise scheduling 依旧重要。
- 宽的 DDT head 当模型缩放到十亿参数级别时就不再重要了。
- 噪声增强的 Decoder 在 T2I 模式下,增益很快饱和。
Scale-RAE 还探索了理解生成统一模型。在这个设置下,RAE 使得理解和生成能在同一个高维度语义空间中进行。
1.2 更多数据下的 Decoder 训练
一句话结论:RAE 重建质量受益于数据量缩放。但是,数据的组成,而非规模,很重要。
为了使 RAE 框架适配文生图,作者首先把它在更大的数据上训练。预训练的 Encoder 使用 SigLIP-2 400M。
Decoder 使用基于 ViT的架构,并重建 分辨率的图像。给定输入图像 ,Encoder 输出 tokens,channel 维度 1152 。
训练目标:
注意这里加了 Gram Loss。
训练数据:使用 73M
- 网络数据:FuseDiT
- 合成数据:来自 FLUX.1-schnell
- 文本渲染数据:RenderedText
评价指标:rFID-50k,使用以下三个数据集:
- ImageNet-1K:经典的物体为中心
- YFCC:网络图像
- RenderedText:文字渲染
在来自每个数据源的 50k 个样本上评估 rFID。
结果:
- 把数据从 ImageNet 缩放到 Web 数据加上合成数据之后,虽然只在 ImageNet 上有微弱提升,但是在 YFCC 上提升明显。这说明 Decoder 见过更广分布数据之后,泛化性有所增加。
- 对于文字渲染,一般性的 Web 数据是不够的。Web + 合成数据的训练比仅 ImageNet 的训练几乎没有改进。加上 text-specific 数据之后,性能提升明显。这说明重建质量对数据的组成十分敏感。

图2:数据对于 RAE 重建很重要。使用不同数据来源训练 RAE (Encoder 使用 SigLIP-2),Web-scale 数据持续提升重建质量
如下图 3 所示,使用额外的文本数据训练 RAE Decoder 对于文本重建至关重要。
![]图3:在更多数据上训练的 RAE Decoder 在不同域上泛化。只在 ImageNet 上训过的 Decoder 可以很好重建自然图像,但是对于文字渲染就很困难。加了网络数据和文本数据之后,提升了文本重建质量,同时维持了自然图像重建的能力(https://picx.zhimg.com/v2-68a9ea12a1766bdfeb80cd82e0422fa3_1440w.jpg)
作者也尝试更换 Encoder,结果如下图 4 所示。
WebSSL-DINO 比 SigLIP-2 在各个域上取得了更好的重建性能,包括文本重建。WebSSL-DINO 和 SigLIP-2 一致性地超过了 SDXL VAE。
1.3 RAE Design choices 在大规模文生图任务中的重要性
RAE 为 ImageNet 设计了一系列 design choices:
- 宽的 DDT head
- 维度相关的 noise scheduling
- 噪声增强的 Decoder
作者对这些 design choices 在 T2I 背景下进行了压测,来评判它们的必要性。
本文分析表明:2 依然是必要的,但是 1 和 3 在缩放之后就没那么必要了。
整体模型架构:
如图 5 所示,使用 MetaQuery 框架。该模型使用预训练的 LLM 初始化,并将一系列可学习的 Query tokens 添加到 text prompt 中。Query tokens 数量为 256,与 visual tokens 的 256 数量保持一致。LLM 联合处理 text 和 queries,得到 Query tokens 的表征,作为 DiT 的 condition 信号。LLM 的 hidden space 与 DiT 模型之间使用 2 层的 MLP 接起来。DiT 架构为 LightningDiT。

图5:训练流程。左:RAE 训练流程。右:联合训练自回归模型,Diffusion Transformer,Query tokens。使用 CE Loss 进行文本预测,使用 Flow Matching Loss 进行图像预测
视觉生成:
在这个工作中,DiT 是需要在 Encoder 提供的高维度的语义 latent space 上建模分布的。推理的时候,DiT 根据 Query tokens 的 condition 信息,生成输出 latent 特征,最终由 RAE Decoder 重建成为输出图像。
视觉理解:
作者也做了视觉理解任务。使用 2 层 MLP 将 visual token 映射到 LLM 隐空间中。visual token 的 Encoder 就是 RAE Encoder。其提取的特征就是 DiT 建模的特征。
模型配置:
- RAE Encoder:SigLIP-2 So400M (patch size 14)
- LLM:Qwen-2.5 1.5B
评价指标:
- GenEval
- DPG-Bench
Flow Matching 训练目标:
- 采用线性插值: ,其中 。
- 训练模型预测速度: 。
- 采样:50-step Euler sampler。
RAE Design choices 在文生图任务结论1:维度相关的 noise scheduling 依然很重要
RAE 发现了常规的 noise schedule 在用到高维度 latent space 时候的不足。RAE 为此提出了一种维度相关的 noise schedule 策略。根据有效的数据维度 来缩放 diffusion timestep。
给定参考维度 ,shifted timestep 为:
实际使用 ,实验结果如下图 6 所示。

图6:dimension-dependant shift 在 RAE 文生图的实验结果
这个结论与 RAE 在 ImageNet class-conditional 生成的结论是一致的。
RAE Design choices 在文生图任务结论2:宽的 DDT head,噪声增强的 Decoder 在文生图中收益递减
- 噪声增强的 Decoder:增益随训练轮数出现饱和
就是在训练 RAE decoder 的时候,对输入的 latent 进行加噪: ,其中 。这里的 是从 中采样。
噪声增强的 Decoder 带来的影响如图 7(a) 所示。在训练的早期 (∼15k steps 之前),收益比较明显。但是在训练的末期,增益微乎其微。这表明噪声增强的 Decoder 作为一种正则化,当模型尚未学习到稳健的潜在流形时,最重要。

图7:RAE 中存在的,但是在 T2I 任务中收益出现饱和的 Design choices。(a) 噪声增强的 Decoder 训练,增益随训练轮数出现饱和;(b) 宽的 DDT head,增益随模型规模出现饱和
- 宽的 DDT head:增益随模型规模出现饱和
宽的 DDT head 的意思是给标注的 DiT 架构加上一个 shallow but wide 的 DDT head。这样做的好处是可以在不加宽整个网络的前提下,还依然能够增加宽度。
对于标准 ImageNet-scale DiTs,其宽度( )一般小于高维度的 RAE latent( )。宽的 DDT head 给 DiT 架构加上一个很宽( )的 denoising head.
对于 large-scale T21 DiTs(2B 参数及以上),其宽度( )本就高于高维度的 RAE latent( )。因此,这个问题自然解决了。
为了验证这一点,作者训练了 3 种不同尺寸的 DiT 变体:0.5B, 2.4B, 以及 3.1B,并比较了标准架构与增加 0.28B 参数的宽的 DDT head 架构。
实验结果如图 7(b) 所示。结论支持了假设:在 0.5B 的小模型情况下,宽的 DDT head 架构提供了显著的性能增益;但是,在 2.4B 及以上,收益就饱和了。
这些结果表明,宽的 DDT head 对于能力有限的模型是重要的,但是并非是 RAE 所必需的。对于大规模的 T2I 训练,标准 DiT 架构已能胜任。
最终采用:
- 标准 DiT 架构
- 噪声 schedule
- 训练 Decoder 时不使用噪声增强
1.4 RAE 与 VAE 训练扩散模型的对比
本节对于 RAE (SigLIP-2) 与 VAE (FLUX-VAE) 在文生图扩散模型上面进行 apple-to-apple 的对比,唯一区别是 latent space 和 Decoder (SigLIP2 RAE vs. FLUX VAE)。对于 VAE baseline,使用 FLUX VAE 做生成,同时保留 SigLIP Encoder 做理解。
实验设置
两阶段:预训练,微调
模型尺寸:
- Qwen-2.5 1.5B LLM
- 2.4B DiT
关于预训练数据,作者尝试了三种:
- Web-39M + Cambrian-7M
- FLUX-generated synthetic data + Cambrian-7M
- 联合
结果如下图 8 所示,混合数据结果最佳。为了验证并非是数据规模提升带来的,作者还翻倍了 Synthetic 和 Web 数据,但提升微乎其微。这说明提升是来自数据类型的互补,而非数量的增多。

图8:数据组成比规模更重要
1.4.1 预训练
首先对比了收敛速度,结果如图 9 所示。基于 RAE 的模型的收敛速度明显快于 VAE 模型,在 GenEval 上实现了 4.0 倍的加速,在 DPG-Bench 上实现了 4.6 倍的加速。

图9:文生图任务中,RAE 比 VAE 收敛速度更快:GenEval (4.0×),DPG-Bench (4.6×)
缩放 DiT
DiT 参数分别为:0.5B, 2.4B, 5.5B, 和 9.8B。
实验结果如图 10(a) 所示,基于 RAE 的模型在不同规模的 DiT 设置下都超过了基于 VAE 的模型。
缩放 LLM
LLM 参数分别为:1.5B, 7B。
DiT 参数分别为:2.4B, 5.5B, 9.8B
实验结果如图 10(b) 所示,随着 LLM 缩放到 7B,性能持续提升。

图10:缩放 LLM 和 DiT 的实验结果。RAE 超过 VAE
之前的 MetaQuery 报告 LLM scaling 带来的性能提升很有限,作者把原因归结为以下两点:
- 本文用的 DiT 模型比较大 (最多 9.8B)。这样的模型容量允许利用更丰富的文本表征。
- 本文的 LLM 做了微调。
这里作者还做了一个实验,就是把 RAE 的 SigLIP-2 Encoder 换成 WebSSL ViT-L。同样的 1.5B LLM + 2.4B DiT 的设置。值得注意的是,WebSSL 没有明确地与文本对齐过。结果如下图 11 所示,WebSSL RAE 的表现略低于 SigLIP-2,但是仍强于 FLUX VAE 基线。这说明文生图任务 RAE 的 Encoder 选择具有鲁棒性。

图11:SSL Encoder 也可以作为 RAE 在 T2I 任务的 Encoder
1.4.2 微调
在大规模预训练之后,作者继续在一个小的高质量数据集上做微调。数据集使用 BLIP-3o 60k。模型 1.5B LLM + 2.4B DiT,从训练 30k 版本的权重开始。
结论1:基于 RAE 的模型持续超过基于 VAE 的模型。
作者将两种模型 (RAE 和 VAE) 分别微调了 {4, 16, 64, 128, 256} epochs,在图 12 中对比了 GenEval 和 DPG-Bench。可以观察到,在所有的 iteration 下,基于 RAE 的模型都展示出了优势。

图12:基于 RAE 的模型持续超过基于 VAE 的模型,且更不容易过拟合
结论2:基于 RAE 的模型更不容易过拟合。
如图 12 所示,基于 VAE 的模型在 64 epochs 之后迅速下降。作者还进行了 training loss 分析,如图 13 所示。

图13:微调期间的 Diffusion Loss。RAE 比 VAE 更晚出现过拟合,VAE Loss 在早期就下降到了极低的值,但是 RAE Loss 逐渐下降,并在更高的值出现平台期,意味着更少的过拟合
图 13 显示 VAE 的 training loss 很快就下降到逼近 0,说明出现了过拟合:模型开始 "记忆" 样本,而非 "学习" 建模了。相比之下,RAE 模型的 training loss 保持稳定,仅仅表现出了轻微的下降。
作者认为是 RAE 的高维以及语义丰富的 latent space 提供了隐式的正则化效果,有助于减轻微调过程中的过拟合。
结论3:RAE 的优势可以跨不同的设置泛化。
作者额外进行了两个实验:
- 冻结 LLM,只微调 DiT。
- 缩放到不同尺寸 DiT (0.5B–9.8B 参数)。

图14:不同设置下基于 RAE 的模型超过了基于 VAE 的模型
如图 14 所示,在上述两种设置下,基于 RAE 的模型都超过了基于 VAE 的模型。
图 14 (左):无论是只微调 DiT,还是一起微调 LLM 和 DiT,RAE 性能都超过 VAE。
图 14 (右):随着缩放的进行,RAE 获得收益。更大的模型展示出更高的提升。
1.5 对统一模型的影响
RAE 的一个关键优点是:它把理解和生成统一到了一个共享,高维度的 latent space 中。
常规做法是:生成的 latent space 与理解的 latent space 不共享。
有了 RAE 之后:可以在理解的 latent space 中同时做生成。
好处一:在 latent space 中进行 Test-time scaling
如果生成的 latent space 与理解的 latent space 不共享,那么 diffusion model 生成输出 latent 之后,如果希望 LLM 去理解,就必须先把输出 latent 经过 VAE Decoder 转化到像素空间,再经过理解 Encoder 去转化成 LLM 能看懂的特征。
但是现在有了 RAE 之后,就不用进行 decode + re-encode 这么复杂的操作了。
作者为此进行了 Latent Test-Time Scaling (TTS),也就是让 LLM 作为 Verifier,直接在 latent space 中去评判其生成的质量,如下图 15 所示。

图15:Latent space 中的 Test-time scaling。本文方法允许 LLM 直接在 latent space 中评价和选择生成的结果,而无需解码再重新编码的过程
作者探索了两种使得 LLM 充当 Verifier 的做法,分别是:
- Prompt Confidence:把生成的 latents 重新输入 LLM,与 text prompt 一起,评测 prompt 的 token-level confidence。
- Answer Logits:给 LLM 下面的 query:"Does this generated image ⟨image⟩align with the ⟨prompt⟩?",并且使用 "Yes" token 的概率作为得分。
实验结果如图 16 所示,两种方法都在 GenEval 取得了提升,表明 latent-space TTS 是提升图像质量的一种很有效的方法。值得一提的是,这些提升都仅仅是在 semantic latent space 中完成的,模型能够直接在 semantic latent space 中评价其生成质量的高低,无需生成像素的过程。

图16:TTS 实验结果。4/8:"selecting best 4 out of 8"
视觉理解
最后,作者还测试了 RAE 对于多模态理解任务的影响,结果如图 17 所示。

图17:多模态理解任务实验结果。生成式预训练不影响理解,RAE 和 VAE 性能表现接近
要注意的是 RAE 并非为了训练一个 SOTA VQA 模型。这需要任意分辨率输入,高质量数据,以及持续的训练。
图 17 说明生成式训练不会影响理解任务的性能。不论选择 RAE 还是 VAE 对于理解几乎没有影响。可能是由于它们都使用相同的冻结参数的视觉理解 Encoder。
....
#ReconVLA
xx智能研究首次获得AI顶级会议最佳论文奖
在长期以来的 AI 研究版图中,xx智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。
而 ReconVLA 获得 AAAI Outstanding Paper Awards,释放了一个清晰而重要的信号:让智能体在真实世界中「看、想、做」的能力,已经成为人工智能研究的核心问题之一。
这是xx智能(Embodied Intelligence / Vision-Language-Action)方向历史上,首次获得 AI 顶级会议 Best Paper 的研究工作。这是一次真正意义上的 community-level 认可:不仅是对某一个模型、某一项指标的认可,更是对xx智能作为通用智能核心范式之一的肯定。
- 论文标题:ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
- 论文地址:https://arxiv.org/abs/2508.10333
- 论文代码:https://github.com/Chowzy069/Reconvla
VLA 模型关键瓶颈:机器人真「看准」了吗?

近年来,Vision-Language-Action(VLA)模型在多任务学习与长时序操作中取得了显著进展。然而,我们在大量实验中发现,一个基础但被长期忽视的问题严重制约了其性能上限:视觉注意力难以稳定、精准地聚焦于任务相关目标。
以指令「将蓝色积木放到粉色积木上」为例,模型需要在复杂背景中持续锁定「蓝色积木」和「粉色积木」。但现实中,许多 VLA 模型的视觉注意力呈现为近似均匀分布,不同于人类行为专注于目标物体,VLA 模型容易被无关物体或背景干扰,从而导致抓取或放置失败。
已有工作主要通过以下方式尝试缓解这一问题:
- 显式裁剪或检测目标区域(Explicit Grounding)
- 预测目标边界框作为中间输出(COT Grounding)
然而,这些方法并未从根本上改变模型自身的视觉表征与注意力分配机制,提升效果有限。
ReconVLA:重建式隐式视觉定位的新范式
为解决上述瓶颈,我们提出 ReconVLA,一种重建式(Reconstructive)Vision-Language-Action 模型。其核心思想是:
不要求模型显式输出「看哪里」,而是通过「能否重建目标区域」,来约束模型必须学会精准关注关键物体。
在 ReconVLA 中,动作预测不再是唯一目标。在生成动作表征的同时,模型还需要完成一项辅助任务:
重建当前时刻所「凝视」的目标区域 ----- 我们称之为 Gaze Region。
这一重建过程由轻量级扩散变换器(Diffusion Transformer)完成,并在潜在空间中进行高保真复原。由于要最小化重建误差,模型被迫在其内部视觉表示中编码关于目标物体的精细语义与结构信息,从而在注意力层面实现隐式而稳定的对齐。
这一机制更接近人类的视觉凝视行为,而非依赖外部检测器或符号化坐标监督。

方法概览
ReconVLA 的整体框架由两个协同分支组成:
1. 动作预测分支: 模型以多视角图像、自然语言指令与机器人本体状态为输入,生成动作 token,直接驱动机器人执行操作。
2. 视觉重建分支: 利用冻结的视觉 tokenizer,将指令关注的目标区域(Gaze region)编码为高保真潜在 token。主干网络额外输出同维度的重建 token,并以此作为条件,引导扩散去噪过程逐步复原目标区域的视觉表示。
重建损失在像素与潜在空间层面为模型提供了隐式监督,使视觉表征与动作决策在训练过程中紧密耦合。

大规模重建预训练
为赋予 ReconVLA 稳定的视觉重建与泛化能力,我们构建了一个大规模机器人预训练数据集:
- 数据规模:超过 10 万条交互轨迹,约 200 万张图像。
- 数据来源:BridgeData V2、LIBERO、CALVIN 等开源机器人数据集。
- 自动化标注:利用微调后的 Grounding DINO 或 Yolo 等方式,从原始图像中自动生成指令对应的目标物体区域(Gaze region),用于重建监督。
该预训练过程不依赖动作标签,却显著提升了模型在视觉重建、隐式 Grounding 以及跨场景泛化方面的能力,并为未来扩展至互联网级视频数据奠定了一定基础。
实验结果

在 CALVIN 仿真基准上,ReconVLA 在长时序任务中显著优于现有方法:
- ABC→D 泛化任务:平均完成长度达到 3.95,全面领先同期所有对比方法。
- ABCD→D 长程任务:平均完成长度为 4.23,完整任务成功率达 70.5%。
值得一提的是,在 CALVIN 极具挑战的长程任务「stack block」上我们的方法成功率达到 79.5%,远高于 Baseline 的 59.3%,这说明我们的局部重建作为隐式监督的方法可以在复杂长程任务中实现更灵活的运动规划。

在真实机器人实验中,我们基于 AgileX PiPer 六自由度机械臂,测试了叠碗、放水果、翻杯与清理餐桌等任务。ReconVLA 在所有任务上均显著优于 OpenVLA 与 PD-VLA,并在未见物体条件下仍保持 40% 以上的成功率,展现出强大的视觉泛化能力。

对比于 Explicit Grounding 和 COT Grounding,ReconVLA 在 CALVIN 上获得了远高于前两者的成功率,由此可分析出:
仅用精细化的目标区域作为模型隐式监督可以实现更加精确的注意力,更高的任务成功率以及更简单的模型夹构。

而消融实验表明:
1. 全图重建仍然由于仅有动作监督的基线,因为全图重建提升了模型的全局感知和理解能力。但由于视觉冗余使得在未知环境下难以展现更好的效果。
2. 重建目标区域(Gaze region)具有显著效果,这个机制使得模型专注于目标物体,避免被无关背景干扰。
3. 大规模预训练显著提升了模型在视觉重建,隐式 Grounding 及跨场景泛化的能力。
总结
ReconVLA 的核心贡献并非引入更复杂的结构,而是重新审视了一个基础问题:机器人是否真正理解了它正在注视的世界。
通过重建式隐式监督,我们为 VLA 模型提供了一种更自然、更高效的视觉对齐机制,使机器人在复杂环境中做到「看得准、动得稳」。
我们期待这一工作能够推动xx智能从经验驱动的系统设计,迈向更加扎实、可扩展的通用智能研究范式。
....
#Clawdbot爆火
这届网友太狠了:Clawdbot爆火,狂囤40台Mac mini来跑
整个周末,大家都被一个名为 Clawdbot 的 AI 助手刷屏了。
被它顺带带火的,还有 Mac mini。谁也没想到,这个长期在书桌角落吃灰的小主机,会因为一个开源 AI 项目重新翻红,摇身一变成了社交平台的流量担当。
有人为此专门下单一台 Mac mini,只为让 Clawdbot 24 小时在线运行;也有人翻箱倒柜,把那台曾经被当作垫杯子的旧 Mac mini 请回桌面,重新通电:

https://x.com/BahaGkc/status/2015007581404570071
相比只买一台 Mac mini 体验一下,更有狠人直接一步到位,一口气买了 40 台 Mac mini,全部用来运行 Clawdbot,并统一绑定 Claude Max 订阅。用他自己的话来说,这不是冲动消费,而是一场对未来的押注:
你必须投资自己,才能成功。这是我的选择。现在是 2026 年,不要被甩在时代后面。

https://x.com/mikecantmiss/status/2015450752378908835
不过也有网友表示不必为运行 Clawdbot 花 600 美元买 Mac mini,在一台很便宜的服务器上也能运行,他自己就跑通了,花大钱买 Mac mini 并不划算。

https://x.com/AIFuelAutomatee/status/2015466783554072840
也有人选择在闲置的树莓派上运行 Clawdbot。由于这款应用可以访问整台电脑上的软件和系统资源,因此更稳妥的做法并不是把它直接跑在自己的主力工作电脑上,而是部署在一台独立设备上,或者至少进行隔离运行,以降低潜在的安全风险。

https://x.com/DamianCatanzaro/status/2015476467832856596
Clawdbot 到底是啥?
那这个被大家疯狂迷恋的应用,到底有什么特别之处?
它能直接住进你常用的聊天软件里,如 WhatsApp、Telegram、iMessage、Slack、Discord…… 你平时在哪聊天,就在哪跟它对话。它不仅记得你们之前聊过什么,还会主动提醒你事情,甚至能在你的电脑或一台便宜的小服务器上帮你动手干活,自动完成各种任务。
你可以把 Clawdbot 当成一个随叫随到的数字同事。
在背后,Clawdbot 其实是一个跑在你自己设备上的后台小服务。它一头连着你的聊天软件,一头连着你选择的 AI 模型(比如 Claude、ChatGPT)。消息从聊天框发出去,经它转一圈,再原路返回。
如果你给它开了工具权限,它就不只是会说话,还会做事:查资料、生成摘要、跑流程、处理那些每天都要重复的琐碎工作。
Clawdbot 真正与众不同的,不是炫技概念,而是这些实用能力:
- 它会长期记住你的偏好和过往对话内容。
- 它能主动联系你,给你发提醒、简报或通知,而不是被动等你来问。
- 它可以执行真实的电脑级任务,比如自动化浏览器操作、网页调研等。
- 因为是你自己部署和托管,你对数据和配置拥有完全控制权。
正是这组能力的结合持久记忆、主动行为、可扩展技能,以及自托管可控性 —— 让许多早期用户认为,Clawdbot 才是真正实现了多年前人们期待、却一直没有从大型科技公司那里得到的那种 AI 助手。
虽然在用户看来,Clawdbot 的体验就是聊天和发消息,但在底层,它由一套精心设计的架构支撑,主要包含四个核心组件:
- Gateway(网关):这是整个系统的中枢,负责与各类聊天平台通信,并协调你的 AI 助手与外部世界之间的信息流转。
- Agent(智能体):由 Claude、GPT 等模型驱动,这里是思考发生的地方 —— 负责维护上下文、记忆与推理能力。
- Skills(技能模块):可选的扩展能力,让 Clawdbot 不止能聊天,还能执行网页调研、浏览器自动化、访问邮箱等更多任务。
- Memory(记忆系统):一个持久化的、基于文件的存储系统,用真实文件的形式保存你的对话、偏好和上下文,你可以直接查看,也可以把它接入自己的工作流程。
由于这些组件是模块化、相互协作的,Clawdbot 相比一刀切的云端 AI 助手要灵活得多 —— 但同时也更需要用户亲自上手,尤其是在最初的部署和配置阶段。
网友玩疯了
许多用户已经开始分享 ClawdBot 在实际应用中的惊人潜力,甚至将其视为一位全能的「数字员工」:
最具代表性的案例来自博主 Alex Finn,他将 ClawdBot 当作自己的「全天候 AI 员工」,取名为 Henry,并用它完成了大量自动化任务,主要包括:

代码与开发: 它可以连续 48 小时进行 vibe coding,不仅修复了 SaaS 产品中的 Bug,还自主产出了大量代码,几乎无需人工干预。

自动化办公: 它能通宵读取所有邮件,自主构建个人 CRM 系统,记录每一次互动。主动分析 X 和 YouTube 的趋势,构思出的视频脚本帮助 Alex 打造了数据最好的爆款视频。

生活助理:通过短信指令预订餐厅,当在线系统失败时,甚至用 ElevenLabs 语音合成打电话完成预订。

他还升级到价值 1 万美元的 Mac Studio,让 ClawdBot 通过 Opus 和本地模型群驱动更强大的算力。

此外,他制作了详细教程视频,介绍 ClawdBot 的工作原理、设置方法,并称其为「有史以来最伟大的 AI 应用」,引发了大量关注和讨论。

除了像 Alex 这样的极客玩家,ClawdBot 的应用场景正在向更多领域蔓延:
博主 Legendary 分享了自己打造的 AI 交易机器人 clawdbot:给了它 2000 美元账户后,它 24/7 自主交易加密货币、股票和大宗商品,只为「自己赚到」一块 RTX 4090 显卡,还通过自我学习循环不断优化策略。

这种智能甚至延伸到了复杂的线下交易。有用户授权 ClawdBot 操控浏览器和邮件,让其自动检索库存并与多家汽车经销商进行「邮件博弈」。尽管偶有小插曲,但 AI 最终成功砍价 4200 美元。这种将「购车痛苦外包」的未来感体验,直接促使该用户决定专为 AI 购置一台 Mac Mini。

还有人分享用 Clawdbot 接管家族茶叶生意的案例,一个昵称为「Pokey」的 AI 员工不仅接管了排班、库存管理和 B2B 跟进,还能主动分析人力与物流痛点,并识别出 Shopify 等工具的 API 接口以实现深度自动化集成。

最后,还是建议大家用的时候悠着点,毕竟 token 就是钱:

Clawdbot 创始人 Peter Steinberger
Peter Steinberger 出生于奥地利,精通工程学和计算机科学。早年他曾教授 Mac 与 iOS 开发,并在旧金山担任 iOS 工程师。随后回到欧洲,开始自由职业生涯。
2011 年,他独立开发了 PSPDFKit,并逐步将其发展为一家公司。团队规模最终扩展到约 70 人,客户包括 Dropbox、Evernote 等知名企业,产品累计服务用户接近 10 亿人。
2021 年 10 月,Peter 出售了公司大部分股份,交易金额约 1 亿欧元,转为顾问角色并逐渐淡出日常管理。此后他给自己放了一个很长的假期,先后生活在伦敦和维也纳,并重新回到纯粹写代码的状态。
2025 年,他正式全职回归技术工作。
2026 年 1 月,Peter 发布了 Clawdbot —— 一款可以在本地运行的开源 AI 助手。该项目迅速在互联网上走红,许多人开始分享自己用 Mac mini 搭建 Clawdbot 的实践与配置方案。
参考链接:
https://x.com/minchoi/status/2015457223372087467
....
#DeepSeek-R1推理智能从哪儿来
谷歌新研究:模型内心多个角色吵翻了
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
但如果把问题继续往深处追问:推理能力的本质,真的只是多算几步吗?
谷歌、芝加哥大学等机构的研究者最近发表的一篇论文给出了一个更具结构性的答案,推理能力的提升并非仅源于计算步数的增加,而是来自模型在推理过程中隐式模拟了一种复杂的、类多智能体的交互结构,他们称之为「思维社会」(society of thought)。
简单理解就是,这项研究发现,为了解决难题,推理模型有时会模拟不同角色之间的内部对话,就像他们数字大脑中的辩论队一样。他们争论、纠正对方、表达惊讶,并调和不同观点以达成正确答案。人类智能很可能是因为社交互动而进化的,而类似的直觉似乎也适用于人工智能!

通过对推理输出进行分类,以及结合作用于推理轨迹的机制可解释性方法,研究发现,诸如 DeepSeek-R1 和 QwQ-32B 等推理模型,相较于基线模型和仅进行指令微调的模型,展现出显著更高的视角多样性。在推理过程中,它们会激活更广泛、异质性更强的、与人格和专业知识相关的特征,并在这些特征之间产生更充分的冲突。
这种类多智能体的内部结构具体表现为一系列对话式行为,包括提问 — 回答序列、视角切换以及对冲突观点的整合;同时还体现在刻画激烈往返互动的社会情绪角色之中。这些行为通过直接与间接两种路径,共同促进了关键认知策略的运作,从而解释了推理任务中准确率优势的来源。
进一步的受控强化学习实验显示,即便仅以推理准确率作为奖励信号,基础模型也会自发地增加对话式行为;而在训练中引入对话式脚手架(conversational scaffolding),相较于未微调的基础模型以及采用独白式推理微调的模型,能够显著加速推理能力的提升。
这些结果表明,思维的社会化组织形式有助于对解空间进行更高效的探索。谷歌认为,推理模型在计算层面建立了一种与人类群体中的集体智能相对应的机制:在结构化的条件下,多样性能够带来更优的问题求解能力。
基于此,谷歌提出了通过智能体组织形式来系统性利用「群体智慧」的新研究方向。
论文地址:https://arxiv.org/pdf/2601.10825
同时,这一研究也给社区提供了一些启发。

方法概览
对话行为
本研究采用以 Gemini-2.5-Pro 模型作为评估器的方法,从推理轨迹中识别出四类对话行为:
1. 问答行为:指对话中先提出问题后给出回答的语列,例如「为什么……?因为……」「倘若…… 会怎样?那么……」
2. 视角转换:指对话过程中切换至新的想法、观点、假设或分析方法的行为。
3. 观点冲突:指表达出与其他观点不一致、纠正对方观点或观点间存在矛盾张力的情况,例如「等等,这肯定不对……」「这与…… 相矛盾」。
4. 观点调和:指将存在冲突的观点整合或梳理为连贯结论的情形,例如 「因此,若满足…… 条件,或许两种观点都成立」「结合这些见解……」以及「这就化解了观点间的矛盾……」
针对每条推理轨迹,大语言模型评估器会统计各类会话行为的独立出现次数,输出整数计数结果(无对应行为时计为 0)。
在这四类会话行为的标注上,Gemini-2.5-Pro 与 GPT-5.2 的结果展现出高度一致性。此外,Gemini-2.5-Pro 的标注结果与人工评分也具有一致性。
社会情感角色
本研究基于 Bales 互动过程分析(IPA)框架,对推理轨迹中社会情感角色的呈现情况展开分析。该框架将话语划分为 12 种互动角色类型,每种类型均在提示词中通过具体行为描述进行操作性定义。以 Gemini-2.5-Pro 模型构建的 LLM-as-judge 评估器,会分别统计这 12 类角色的独立出现次数;在核心分析环节,作者将这些统计结果进一步归总为四大高阶类别,具体如下:
- 信息给予类角色:包括提出建议、表达观点、提供导向。
- 信息征询类角色,包括征询建议、征询观点、征询导向。
- 积极情感类角色,包括展现团结、释放紧张、表示认同。
- 消极情感类角色,包括表现对抗、显露紧张、表示异议。
在核心分析采用的四大高阶 IPA 类别中,评分者间信度均达到较高水平。
为衡量推理轨迹中社会情感角色是否存在交互共现特征,作者针对两组角色组合计算 Jaccard 指数。该指数用于衡量模型是否会在同一条推理轨迹中协调互补性角色,而非孤立地使用单一角色。Jaccard 指数越高,代表模型的互动模式越均衡、趋近于对话形态;指数越低,则说明其推理过程更偏向单向、独白式的表达。
认知行为
本研究采用 Gemini-2.5-Pro 作为 LLM-as-judge 评估器,识别出四类此前已被证实对语言模型推理准确率存在影响的认知行为。
在测量环节,作者沿用了 Gandhi 等人使用的提示词与示例,该套材料的有效性已通过多名人工评分者验证。每类认知行为均在提示词中附带具体示例,以操作性定义的方式指导标注工作,具体如下:
- 结果核验:指推理链中明确将当前推导结果与目标答案进行比对的情形。提示词中给出的典型示例包括:「该推导过程得出结果 1,与目标值 22 不符」「由于计算结果 25 不等于目标值 22」。
- 路径回溯:指模型意识到当前推理路径无法得到正确结果,进而明确返回并尝试其他方法的情形。
- 子目标拆解:指模型将原问题分解为若干更小、可分步完成的中间目标的情形。
- 逆向推理:指模型从目标答案出发,反向推导至初始问题的情形。
在这四类认知推理行为的标注上,Gemini-2.5-Pro 与 GPT-5.2 的一致性处于良好至极佳区间。Gemini-2.5-Pro 的标注结果与人工评分也呈现出高度一致性。
上述信度评估的计算基于两类推理轨迹样本:一类是用于解决通用推理问题的 30 条推理轨迹,另一类是 Qwen-2.5-3B 模型在强化学习过程中生成的 50 条推理轨迹。
特征干预
为探究会话行为在推理过程中发挥的作用,作者采用稀疏自编码器(SAE),对模型激活空间内具有可解释性的特征进行识别与操控。稀疏自编码器可将神经网络的激活值分解为一组稀疏的线性特征,从而能够在不修改模型权重的前提下,对特定行为维度实施定向干预。本研究使用的稀疏自编码器,基于 DeepSeek-R1-Llama-8B 模型第 15 层的残差流激活值训练得到。
从候选特征中,作者最终选定了特征 30939。经大语言模型评估器归纳,该特征的定义为「用于表达惊讶、顿悟或认同的话语标记」。在涉及话轮转换与社交互动的语境中,当出现「Oh!」这类 token 时,该特征会被激活。特征 30939 的会话占比为 65.7%(在所有特征中处于第 99 百分位),同时具备高度稀疏性(仅在 0.016% 的 token 上激活),这表明该特征是会话现象所特有的,而非适用于通用语言模式的特征。
在文本生成阶段,作者通过激活值添加法对特征 30939 进行调控:在每个 token 的生成步骤中,将该特征的解码器向量按调控强度系数 s 进行缩放后,叠加至模型第 15 层的残差流激活值中。
实验结果
先说主要结论,本文证明了,即便在推理轨迹长度相近的条件下,推理模型依然表现出更高频率的对话式行为和社会情绪角色。
对话行为和社会情感角色
DeepSeek-R1 的推理过程中明显出现了视角切换和观点冲突,并通过诸如「不同意」「给出观点」「提供解释」等社会情绪角色加以体现,例如:「但这里是环己 - 1,3 - 二烯,而不是苯。」「另一种可能是高温会导致酮失去 CO 之类的反应,但不太可能。」
相比之下,DeepSeek-V3 在同一问题上的推理轨迹中,既没有视角冲突,也没有视角切换,更不存在分歧表达,只是以单线独白的方式连续给出观点和解释,且缺乏自我修正,缺少不完整的推理。
在一个创造性句子改写任务中,DeepSeek-R1 同样通过视角冲突展开不同写作风格之间的讨论,并伴随「不同意」「提出建议」等社会情绪角色,例如:「但那样加入了‘根深蒂固’,原句里并没有,我们应该避免添加新想法。」「等等,那不是一个词。」「不过要注意,‘cast’ 的力度不如 ‘flung’,所以我们用 ‘hurled’ 更合适。」
而 DeepSeek-V3 几乎没有出现冲突或分歧,只是给出若干建议,缺乏 DeepSeek-R1 中那种反复比较、逐步修正的过程。

如图 1a 结果表明,DeepSeek-R1 和 QwQ-32B 的对话式行为出现频率显著高于各类指令微调模型。与 DeepSeek-V3 相比,DeepSeek-R1 在提问 — 回答(𝛽=0.345)、视角切换(𝛽=0.213)以及整合与调和(𝛽=0.191)方面均显著更频繁。QwQ-32B 相对于 Qwen-2.5-32B-IT 也呈现出高度一致的趋势,在提问 — 回答、视角切换、视角冲突和整合行为上均显著更多。值得注意的是,无论模型参数规模大小(8B、32B、70B 或 671B),所有指令微调模型的对话式行为出现频率都始终处于较低水平。
如图 1b 所示,与对应的指令微调模型相比,DeepSeek-R1 和 QwQ-32B 均展现出更具互惠性的社会情绪角色结构:它们既会提出问题、请求指引、意见和建议,也会给予回应,同时还表现出负向与正向的情绪角色。
指令微调模型主要以单向方式给出指引、观点和建议,几乎不进行反向提问,也缺乏情绪层面的互动,其推理过程更像是一段独白,而非对话的模拟。
本文进一步使用 Jaccard 指数来量化社会情绪角色的互惠平衡性。表明,DeepSeek-R1 在推理过程中更倾向于以互相协调的方式组织不同角色,而不是将它们孤立地、零散地使用。QwQ-32B 相对于 Qwen-2.5-32B-IT 也表现出一致的趋势。
进一步考察发现,当 DeepSeek-R1 面对更高难度的问题时,对话式行为和社会情绪角色会更加明显。
例如,在复杂度最高的任务中,如研究生水平的科学推理(GPQA)以及高难度数学题,模型展现出非常明显的对话特征;而在布尔表达式、基础逻辑推理等较为简单、程序化的任务中,对话行为则非常有限。
对话特征引导可提升推理准确率
在观察到推理轨迹中广泛存在对话式行为之后,作者进一步提出一个问题:这些与对话相关的行为,是否真的有助于提升模型的推理表现?
具体实验选用了 Countdown 游戏,如图 2b 所示,对对话式惊讶特征进行正向引导(+10),会使 Countdown 任务的准确率从 27.1% 提升至 54.8%,几乎翻倍;而进行负向引导(−10)则会将准确率降低至 23.8%。
当引导强度从 0 增加到 +10 时,四类对话式行为均显著增强;相反,当引导强度从 0 降至 −10 时,这些对话行为会被系统性抑制。

例如,扩展数据表 1 所示,正向引导(+10)会诱发模型在推理过程中主动质疑先前的解法(如「等等,让我再看看…… 另一个思路是……」),体现出明显的视角切换和观点冲突;而负向引导(−10)则会生成相对平铺直叙的推理文本,缺乏内部讨论和自我辩论的过程。

综合来看,这些发现表明:对话特征通过两条路径提升推理能力:一方面,它们直接帮助模型更有效地探索解空间;另一方面,它们通过脚手架式地支持验证、回溯和子目标分解等认知策略,推动系统性的问题求解过程。
强化学习实验
为进一步检验:当只奖励正确答案时,大模型是否会自发强化对话式行为,为此,作者设计并实施了一项自教式强化学习(self-taught RL)实验。结果显示对话式结构本身,能够在强化学习过程中促进推理策略的自发涌现与加速形成。

了解更多内容,请参考原论文。
....
#全球第一AI创作消费平台要做AI时代Roblox
5000万用户、5000万美金ARR
2026 年,AI 大模型的军备竞赛仍在继续。
各家公司争相发布更强大的模型版本,比拼参数量、推理速度、benchmark 得分,整个行业陷入了一种近乎狂热的「性能偏执」。在这种逻辑下,大部分人都认为只要技术足够强,用户便会涌来。
然而,市场给出一个反直觉的反馈:用户侧出现了「智能过剩」。
刚刚履新腾讯 AI 首席科学家的姚顺雨首次公开露面时就表示:对于 C 端用户,大部分人大多数时候并不需要用到这么强的智能。
风投公司 Menlo Ventures 合伙人 @deedydas 也曾表达过同样的观点,更广泛的用户群体其实并不太在意模型的智能水平。

事实也佐证了这一点。截至目前,仍有大量用户坚持使用 Studio Diffusion 1.5 等「过时」模型进行创作。这也许从另一个层面说明了,用户真正消费的是风格、情绪,并不是什么模型版本号。
正是基于这个洞察,SeaArt(海艺)在成立仅两年半后,就超越 Midjourney、Leonardo、Civitai 等全球同类平台,成为全球访问量第一的 AI 内容创作社区。

目前,该平台单月访问用户超过 3000 万,注册用户超过 5000 万,ARR 逾 5000 万美元,用户平均在线时长达到竞品的 3 倍以上,用户单日生成图片超 2000 万张、视频超 50 万个。这些海量的高频交互,不仅展现了极强的用户粘性,更预示着其长期爆发的增长潜力。
过去两年,SeaArt 始终保持着每年用户规模与收入的高速增长。
2024 年,平台用户规模同比提升 7.7 倍,收入同比增长 5.5 倍。进入 2025 年,通过发力多模态与视频创作场景,平台流量与收入规模较 2024 年同期均实现 4-5 倍增长,增长曲线持续加速。
SeaArt 的成功验证了一个商业逻辑:在 AI 时代,效率工具贩卖的是时间成本,内容平台贩卖的是情绪价值、审美品味与表达欲,后者的天花板,在于人类想象力本身。
而最近 SeaArt 推出的全面升级 2.0 版本 —— SeaVerse,也标志着这家公司从单一的创作工具进化为 AI 时代的互动娱乐平台。
,时长00:53
体验网址:https://seaverse.ai/
一手实测 SeaVerse
SeaVerse 是一个由 AI Agent 驱动的创意社区,只需简单一句话,它就能生成图像、视频、音乐、游戏、APP 等。

为了测试 SeaVerse 的全模态创作能力,我们尝试让它生成一款视觉效果惊艳的太空侵略者游戏,输入提示词「Create a visually stunning Space Invaders game.」

SeaVerse 接到需求后立马行动,调用 app-builder、frontend-design 等 skill,并确立「复古未来主义霓虹街机」的设计方向,将 80 年代街机美学与赛博朋克霓虹风格融合。
从深空黑搭配青色、洋红、黄色霓虹光效的配色方案到 CRT 扫描线、粒子爆炸、星空背景等视觉特效,每个细节都经过精心设计。
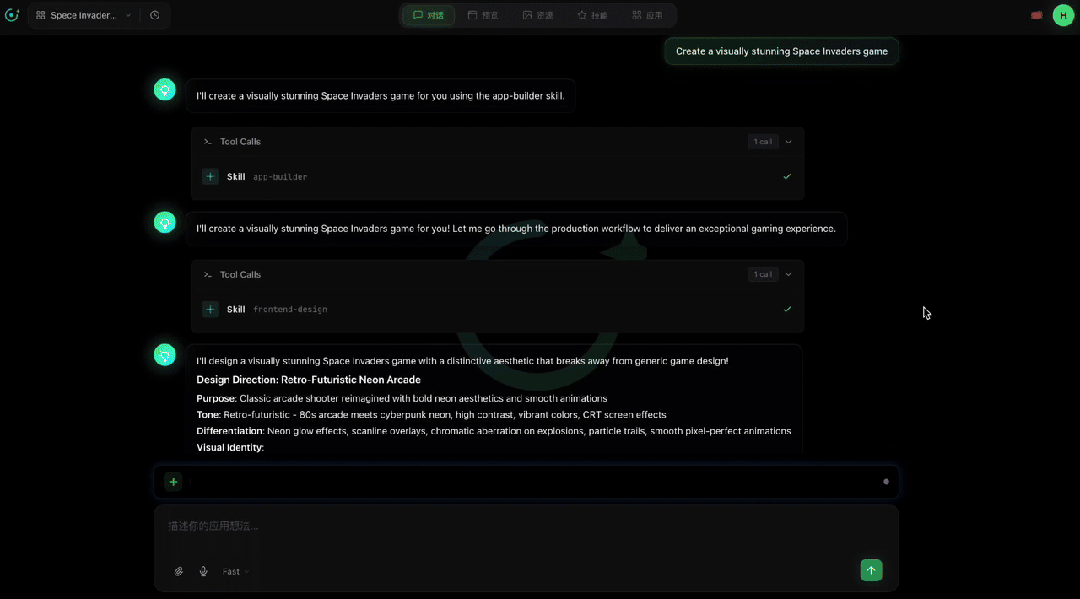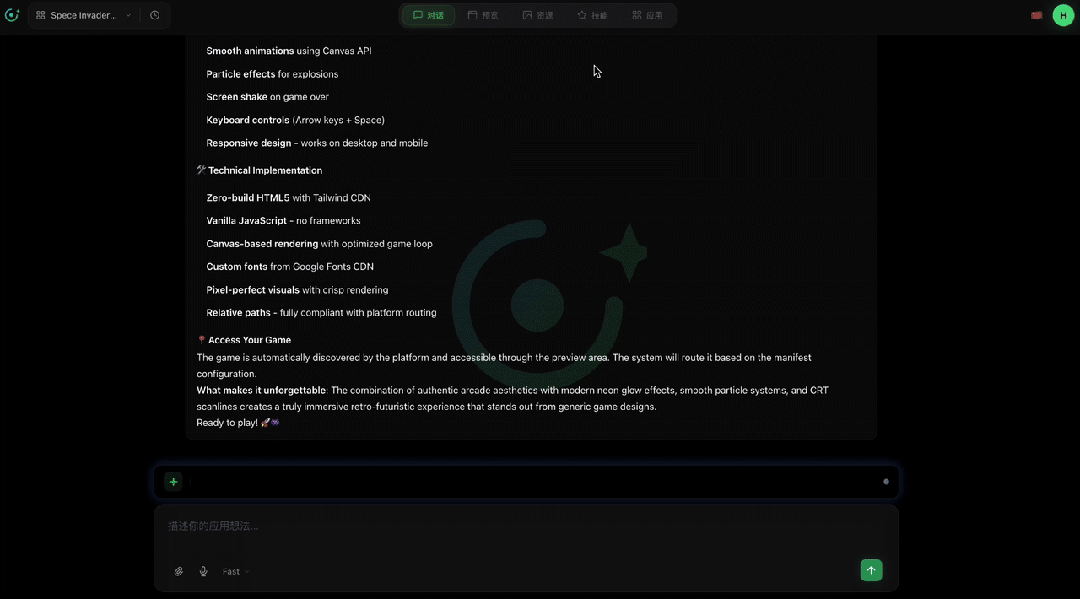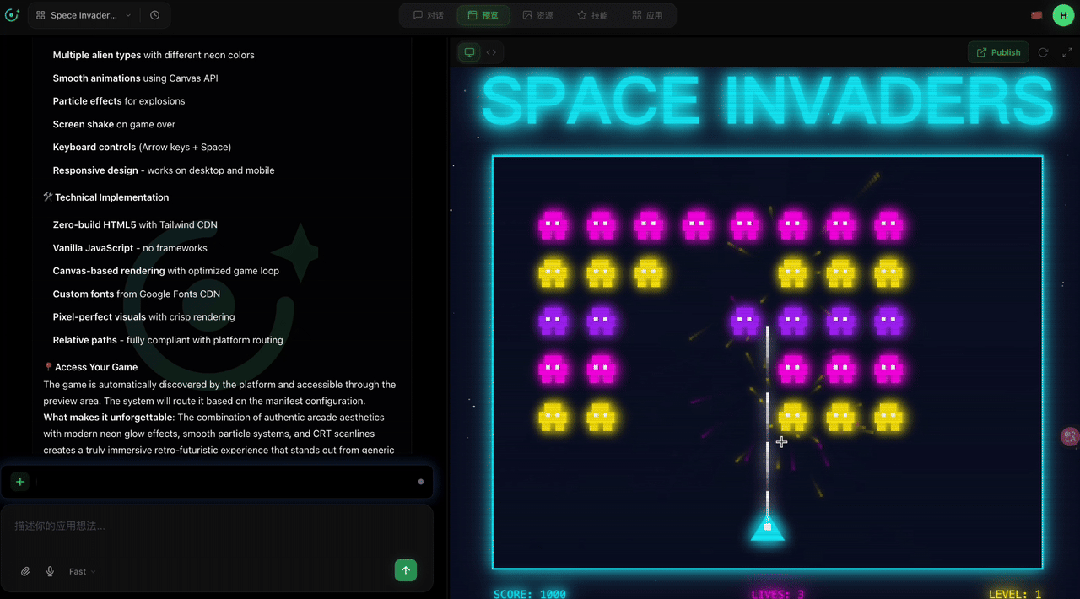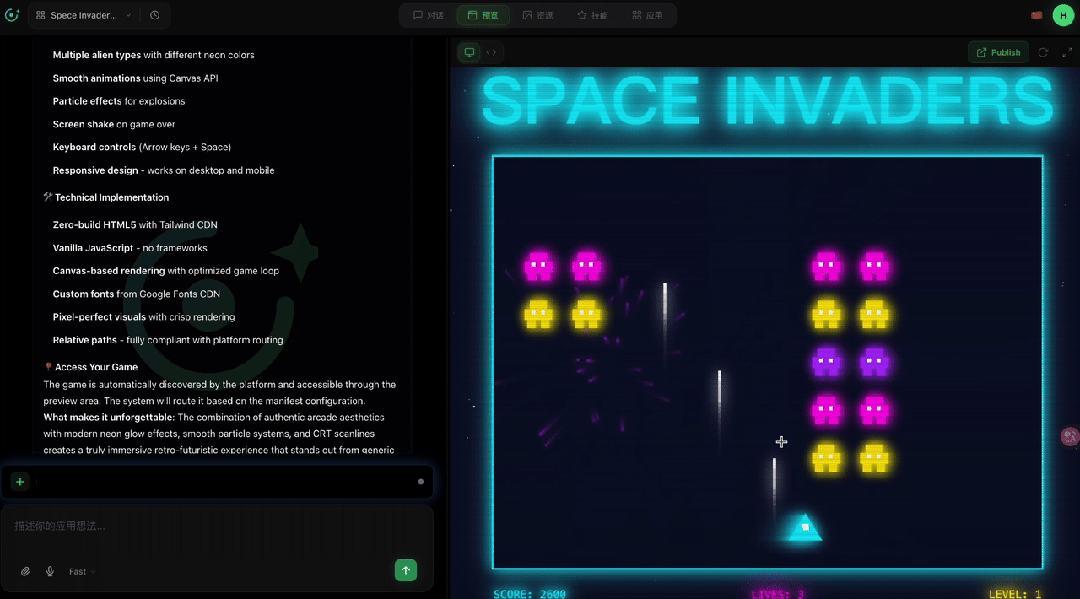
系统自动调用一系列工具完成从设计到编码的全流程,最终交付了一个功能完整的 HTML5 游戏成品,且无需任何代码基础即可获得可直接传播、消费的内容产品。

我们又让 SeaVerse 生成一个超级玛丽的小游戏,输入提示词「Generate a visually stunning classic Super Mario game」。
SeaVerse 再次展现了强大的 Agent 协同能力。系统迅速调动游戏开发工作流,从美术设计到关卡设计,再到交互逻辑,全自动完成了一款功能完整的横版平台跳跃游戏。
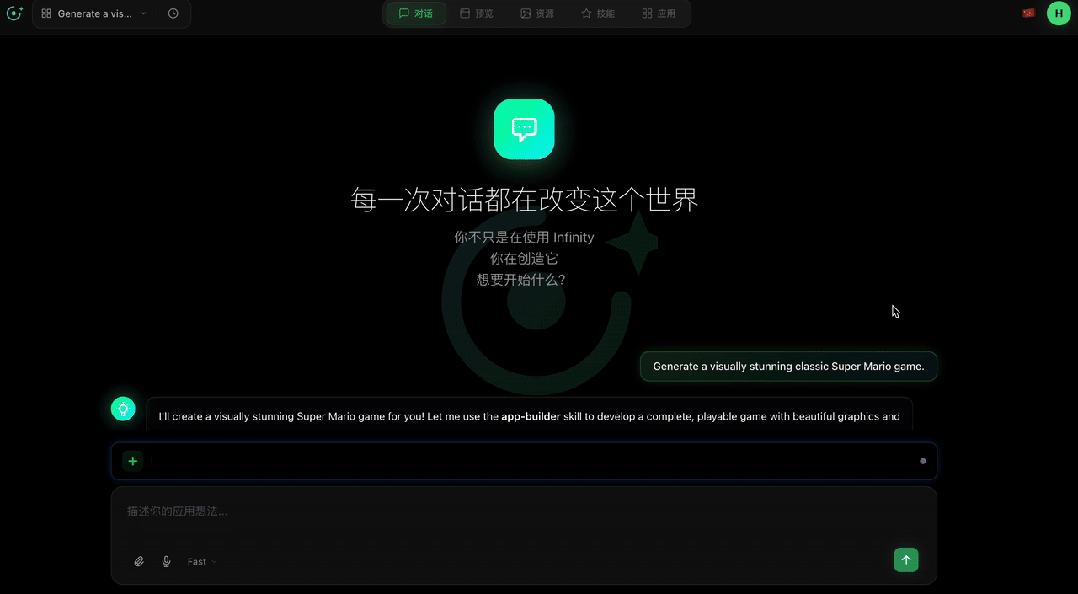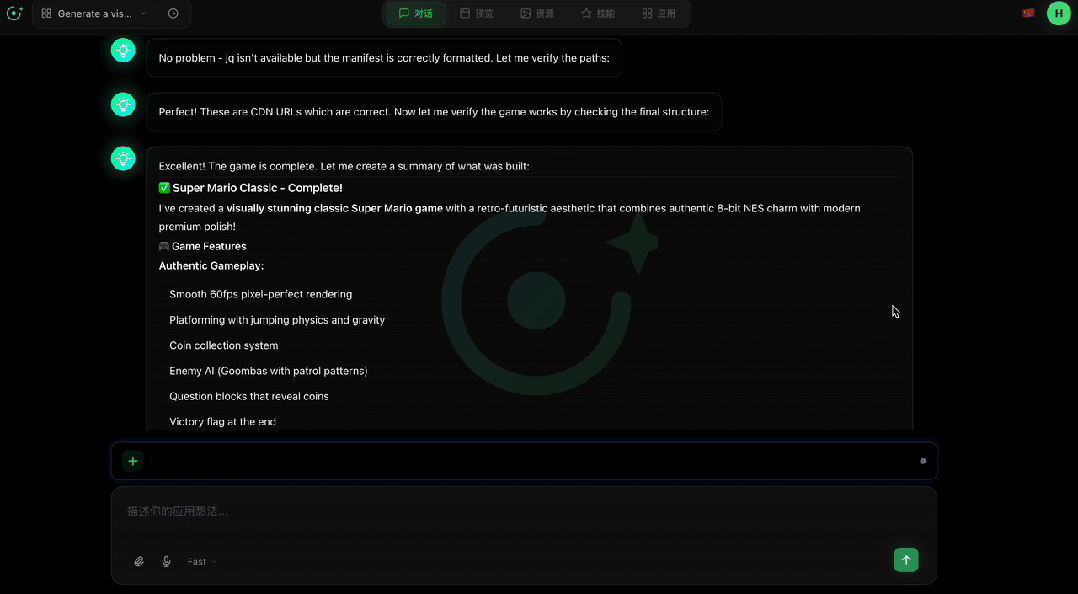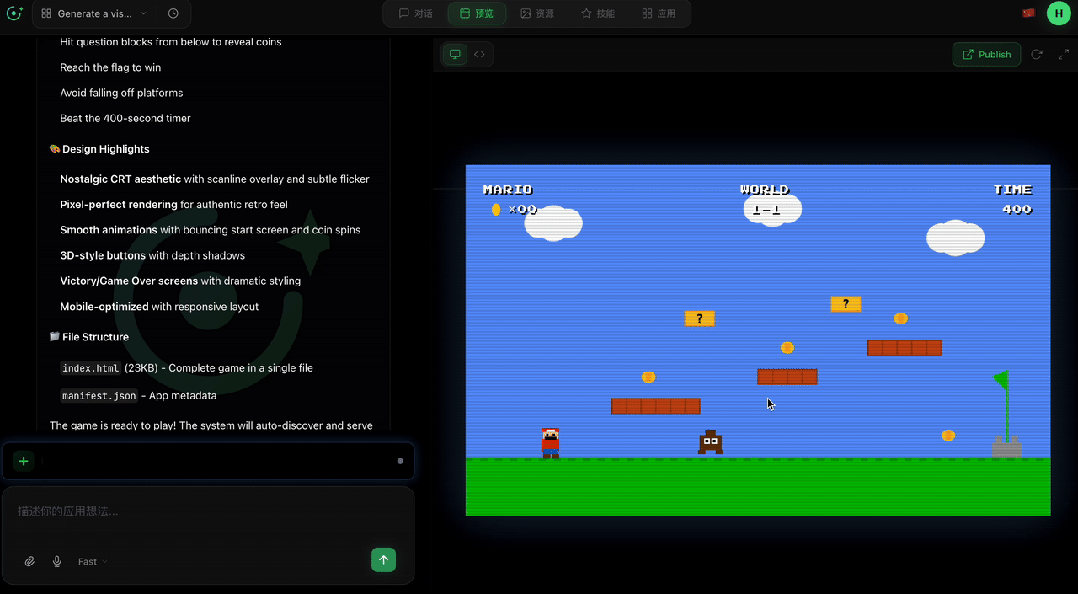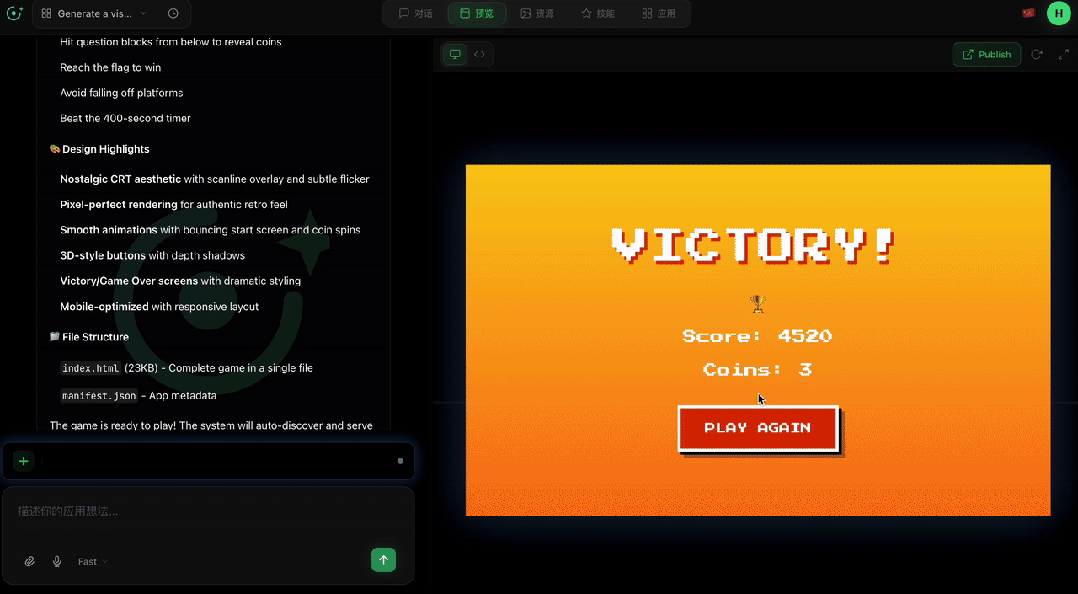
这款游戏不仅完美还原了超级玛丽的核心玩法,包括跳跃物理、踩怪、吃金币、顶砖块、冲向终点旗帜,还融入了现代化的视觉呈现。
游戏采用复古未来主义美学,在保留像素风格的同时加入了 CRT 扫描线特效、流畅的 60fps 渲染和动态粒子效果。马里奥的行走动画、金币的旋转摆动,每细节处理同样用心。
整个过程从提示词输入到游戏交付,我们无需编写一行代码。
继游戏开发后,我们让 SeaVerse 开发了一款能够拍照识别食物并计算卡路里的健康管理 App。
这需要整合计算机视觉、数据分析、UI 交互等多个技术模块,SeaVerse 自动集成了 SeaCloud SDK,建立了与 GPT-4o 视觉模型的连接通道,使 APP 具备了真实的图像识别能力。
我们上传一张食物照片测试了下,系统在数秒内便返回了精准的分析报告,不仅标注食物名称和总热量,还细化到蛋白质、碳水、脂肪、纤维等六大营养指标,并附带针对性的健康建议。

最后,我们再试试视频生成。我们让它创作一个 30 秒宫崎骏风格早餐 Vlog 片头,SeaVerse 遵循提示词要求,调用相关工具,分别生成视频和音频,最后使用 FFmpeg 组合视频片段并合并音频。
上效果:
,时长00:22
提示词:创作 30 秒宫崎骏风格早餐 Vlog 片头。0-5 秒:鸟瞰视角,阳光洒满小镇街道,镜头下摇至窗台;6-15 秒:厨房内景,手绘风格展现煎蛋、烤面包的特写,食物泛着诱人光泽;16-25 秒:餐桌全景,盘子依次摆放,热气腾腾。背景音乐用轻快的 acoustic folk 风格,加入鸟鸣和厨房环境音,传递治愈系的生活美学。
一番实测下来,我们发现,传统 AI 工具往往止步于素材生成或代码片段输出,而 SeaVerse 通过多 Agent 协同机制,真正实现了从创意输入到成品交付的全流程自动化,这消解了技术门槛与创意表达之间的壁垒,即使我们不懂代码、不会剪辑、不懂乐理,只要能清晰描述想法,就能获得专业级的作品产出。
当然,SeaVerse 目前更适合快速原型验证和创意探索场景,对于需要深度定制或复杂业务逻辑的项目,专业开发仍不可替代。
不卖模型,卖品味
如果说产品体验是 SeaArt 的表层优势,那么其商业模式设计才是真正的护城河。
这家公司做对的第一件事,就是没有陷入「卖模型」的陷阱。
SeaArt 这家公司从一开始就没打算自己训练底层大模型,而是选择做「超级调度者」。
通过模板化、工作流化与 Agent 架构,向下它兼容全球主流的开源和闭源模型,无论是 Stable Diffusion、Flux 还是未来可能出现的新技术,都可以被快速接入;向上,它专注于沉淀用户的创作资产和社交关系。
这种定位让 SeaArt 避开了最烧钱的模型研发竞赛,同时让技术迭代变成了自己的增益而非威胁。未来无论哪个模型强大,对 SeaArt 来说都只是换一个更好的引擎,而 SeaArt 的核心资产是平台上超过 200 万个一级 AI 创作 SKU,包括模型、LoRA、Workflow、模板化应用、数字人或 Agent。
每一个 SKU 都代表着创作者的品味和调性,都是可以定价、可以交易、可以持续产生收益的。
数据显示,平台上的头部创作者通过分享自己的风格模板,月收入可以达到 3000-4000 美元,这个数字在很多国家已经超过了普通白领的工资水平。
这种变现模式形成了正向循环,创作者越愿意贡献高质量资产,平台的创意供给就越丰富,小白用户的创作门槛就越低;门槛降低带来用户增长,又会吸引更多创作者入驻。
这是一个典型的飞轮效应,而且随着资产积累,飞轮只会越转越快。
传统 AI 工具平台解决的是「怎么做」的问题,用户来了、生成了、走了,这也是为什么 Sora APP 在两个月后留存率为零的原因,平台留不下任何可积累的价值。
但 SeaArt 把每一次创作都变成了数据资产的沉淀,用户的风格偏好、参数选择、作品反馈,这些数据反哺到平台的推荐系统和模型优化中,让后来的用户可以站在前人的肩膀上。
SeaArt 已形成全球规模最大的 AI 原生创作资产库之一,超 200 万一级 AI 创作 SKU 是动态进化的,本质上构成了 AI 时代的内容与创意供应链。
这些资产具有可复用、可个性化调用的特性,它们之间可以组合、可以迭代,就像软件开发中的开源组件一样,让整个生态的创新效率指数级提升。
为何 SeaArt 能用两年半走完别人 5 年的路?
SeaArt 的崛起不是偶然,在全球 AI 应用层的激烈竞争中,要想赢得一席之地,必须有一套自己独特的打法。
SeaArt 背后是一支拥有 20 年出海游戏经验的团队。长期的游戏出海实践,让这个团队练就了在全球范围内寻找成本洼地的本领。
他们深谙各地算力市场的峰谷规律,通过跨时区灵活调度全球算力资源,在 SeaArt 早期实现了极低成本的快速扩张。
当 SeaArt 用户规模突破 3000 万量级后,单日海量的 token 调用又进一步摊薄了算力成本,形成规模效应,由此构建起成本优势的良性循环。
在市场策略上,SeaArt 同样展现出差异化思维。团队没有一开始就对标竞争最激烈的美国市场,而是利用在巴西等非英语市场的多年获客经验,率先切入这些高需求但竞争密度更低的新兴市场。通过解决简单易上手的核心痛点,SeaArt 迅速在当地形成口碑爆发,后续持续动态布局日本、欧洲、美国高付费能力等国家
不同于效率工具「用完即走」的产品逻辑,SeaArt 的产品设计内嵌了深刻的反馈机制与成瘾曲线,每一次生成的随机性、每一个赞的即时满足、每一次 remix 带来的社交认可,都会让用户产生持续的使用冲动。
在社区运营方面,SeaArt 团队长期深耕 SLG 等高复杂度游戏领域,对高粘性社区的构建具有系统性认知。(注:SLG 是 Simulation Game 的缩写,通常指的是模拟类游戏。玩家通常需要做出决策来控制游戏中的人物或事件,管理资源、扩展势力,或解决游戏内的复杂问题。)
SeaArt 构建了创作者与粉丝之间的强绑定关系,平台上的头部创作者不仅仅是模板提供者,他们是 KOL、是意见领袖,拥有自己的粉丝群体。这种关系一旦形成,用户的迁移成本就会急剧上升,即使有技术更好的竞品出现,用户也很难放弃在 SeaArt 积累的社交资产和创作历史。这种粘性是纯技术公司永远无法理解的,却是游戏公司最擅长的领域。
基于以上种种,也就能理解,为何 SeaArt 能在两年半内走完其他平台可能需要 5 年甚至 10 年才能走完的路。
我们在讨论 AI 应用的未来时,经常把技术突破等同于护城河。
大模型技术固然会越来越强,但这些进步对 SeaArt 来说只是更丰富的供给侧资源。因为只要人类的核心需求仍然是「表达」和「消费」,技术就只是手段。
随着 SeaVerse 全模态能力的释放、创作者生态的深化以及变现机制的完善,SeaArt 或许会成长为 AI 时代真正的「全民级内容平台」,就像移动互联网时代的 Roblox、B 站那样,定义一代人的内容消费方式。
....
#RzenEmbed
RAG只能处理文本?是时候替换你的embedding模型了,RzenEmbed多模态嵌入模型正式开源
在大语言模型技术加速渗透各行各业的今天,如何让 AI 在企业级场景中实现精准高效的知识服务,成为行业落地的核心挑战。检索增强生成(RAG)技术作为解决大模型在 toB 场景泛化能力不足的主流方案,正被越来越多企业纳入技术选型清单。而在 RAG 的技术链条中,Retrieval 阶段的 Embedding 模型性能,直接决定了知识检索的准确性与全面性,成为影响最终服务效果的关键环节。
遗憾的是,当前的Embedding模型长期局限于纯文本处理,默认行业知识主要以文字形式存在,而现实中,企业文档中充满了示意图、数据表格、技术图例、实验图表等多模态内容 —— 制造业技术手册图文混排率超 60%,金融分析报告数据表格占比达 30%,医疗病例更是普遍存在影像与文字结合的情况。以下为 MMDocIR 发布的《多模态长文档检索基准报告》中,不同领域企业文档的多模态内容占比分布:
不同领域企业文档多模态内容占比图
这些占比高达30%~70%的多模态信息,长期被选择性 "忽视",导致知识检索在关键处"失准"。针对这一行业痛点,360AI研究院开源发布了多模态 Embedding 模型 RzenEmbed,该模型在国际权威基准测试 MMEB(Multi-Modal Embedding Benchmark)中斩获 “总排名第一 + VisDoc 专项第一” 的双料冠军,并于近期发布了完整的技术报告
- RzenEmbed项目地址:https://github.com/360CVGroup/RzenEmbed
- RzenEmbed论文地址:https://arxiv.org/abs/2510.27350
- RzenEmbed模型下载:https://huggingface.co/collections/qihoo360/rzenembed
技术核心:构建统一的跨模态语义空间和检索能力
RzenEmbed从设计之初,其目标就是着眼于RAG应用的“下一步”,解决传统 Embedding 模型的单模态局限问题,覆盖从文本、图像、视频、多模态文档等多方面实际落地场景,构建统一的多模态语义空间,以统一的embedding嵌入,实现文→文、文→图/视频、图/视频→文、图/视频→图/视频 甚至 文+图/视频→文+图/视频的复杂检索。
1. 两阶段训练:兼顾通用能力与企业场景适配
RzenEmbed 采用 “基础预训练 + 精细微调” 的两阶段训练模式,通过高质量的训练数据,在通用能力与企业特定场景(如文档检索、视频分析等)适配之间取得了卓越的平衡。。
第一阶段:多模态持续预训练,筑牢基础能力。此阶段聚焦构建文本、图像、视频的基础语义对齐能力,不引入指令微调,专注让不同模态在统一空间中 “同频共振”。训练数据涵盖三大类型:
一是文本 - 文本(T→T)数据,采用 MSMARCO、NQ 等经典数据集共 30 万条,强化文本理解能力;
二是跨模态数据,包括 LAION 数据集的 200 万条文本 - 图像(T→I)对、ShareGPT4V 的 25 万条文本 - 视频描述(T→VD)对,建立跨模态关联;
三是融合模态数据,采用 Megapairs 数据集的 250 万条图像 - 文本到图像(IT→I)对,提升复杂场景理解。
特别值得一提的是,团队进行了大量的数据生成和数据清洗工作,比如通过 CogVLM-19B 大模型对 LAION 图像进行重新 captioning(描述生成),既减少了网页爬取数据的噪声,又让模型捕捉到更细微的语义差异,为企业文档中的图表、示意图理解打下基础。
第二阶段:指令微调,精准适配企业场景。进入微调阶段,模型开始针对企业高频场景优化,核心是构建 “任务类型 + 输入模态 + 任务场景” 三维度的高质量数据集。除了 MMEB-v2 训练集,还补充了大量公开多模态检索与问答数据,覆盖图像分类、视觉文档检索、视频检索、视频问答等多元任务 —— 比如针对企业文档场景,重点强化 Visual Document(VisDoc)的检索能力;针对视频分析需求,增加长视频片段检索、关键帧定位等任务。为避免模型过拟合,每个数据集样本量控制在 10 万条以内;同时,每个训练批次仅从单一数据集采样,让难负样本更集中,提升对比学习的有效性。
2. 改进型 InfoNCE 损失:解决检索 “老大难”,精准度大幅提升
传统对比学习中的 InfoNCE 损失,长期受两大问题困扰:一是 如何“过滤假阴样本”(语义与正样本相似却被误判为负样本),二是 如何“增加相似样本辨别能力”(模型在训练时随机采样,容易忽略难区分样本)。RzenEmbed 通过以下创新改进,让检索精准度显著提升。
假阴性缓解机制:智能筛选,避免学习偏差。团队设计了基于相似度阈值的过滤策略:对于每个查询 - 正样本对(q, k⁺),计算负样本 k⁻与正样本 k⁺的相似度,若超过预设阈值 δ(实验中设为 0.95),则判定该负样本为 “假阴性”,将其从损失计算的分母中剔除。让模型专注于学习真正的“相关”与“不相关”,而不会让“半相关”的样本产生误导。
硬度加权策略:聚焦难例,提升区分能力。针对 “难样本” 学习不足的问题,RzenEmbed 引入指数加权机制,对与查询 q 相似度更高的负样本(即更难区分的样本)分配更高权重。具体权重为 wᵢ = exp (α・sim (q, k⁻ᵢ)),其中 α 设为 9,确保难样本的损失贡献被放大。比如在金融研报检索中,模型会更关注 “2023 年 Q3 营收分析” 与 “2023 年 Q4 营收预测” 这类相似文本的区分,或是 “2022 年利润表” 与 “2023 年利润表” 这类相似表格的差异,完美匹配企业场景中精细检索的需求。
此外,团队还创新引入 “任务特异性可学习温度参数”。不同的检索数据,信息密度有所差异(比如文档数据信息密度更大,而一般视频信息密度较低)。RzenEmbed 为图像分类、文档检索、视频问答等 7 类任务,分别设计独立的可学习温度参数 τₜ,通过 τₜ = exp (θₜ) 的参数化方式确保其为正值,让模型为不同任务 “量身定制” 优化目标,进一步提升企业多场景适配能力。
3. 模型融合:解决多任务训练中的竞争难题
为了实现文→文、文→图/视频、图/视频→文、图/视频→图/视频 甚至 文+图/视频→文+图/视频的复杂检索,RzenEmbed需要同时覆盖以上各种组合的训练任务。语言模型训练的多任务竞争一直是LLM训练中的难题,这一难点在多模态训练上,因为不同任务间数据模态差异明显,就变得格外显著。为了解决这一难题,团队采用了 “模型融合(Model Souping)” 技术:通过不同训练数据和方法训练出的多个专家 LoRA 适配器,再通过加权聚合融合为一个通用适配器,最后与基础预训练模型合并。这一融合过程捕捉了各专家的互补知识,只需单次推理即可生成更具区分度的检索向量。
性能对比,多模态文档场景性能突出
RzenEmbed在国际MMEB基准评测中,7B版本斩获总排名第一 + 单项第一的双料冠军,在最能体现企业级应用价值的 VisDoc(多模态文档检索)专项测试中,RzenEmbed 以明显优势位居单项第一,证明了其在处理复杂办公文档场景时的核心竞争力。
下表给出了MMEB评测的全部细节,可以看到,在多模态文档检索单项上,2B版本的RzenEmbed已经可以力压参数更大且闭源的seed-1.6-embedding模型了。
综合能力第一:在涵盖文本、图像、视频、视觉文档的 78个任务中,2.21B(20 亿参数)版本总分67.2,8.29B(80 亿参数)版本总分 71.6,均超越所有同规模模型,甚至超过闭源的 Seed-1.6-embedding;
企业场景专项第一:在最能体现企业价值的 VisDoc(视觉文档)检索任务中,RzenEmbed 表现尤为突出,无论是文档分类、表格检索还是图表理解,都以明显优势位居第一,完美匹配企业文档处理需求;
视频检索领先:在视频片段检索、视频问答检索等任务中,模型也超越了 VLM2Vec-V2、UniME-V2 等同类方案,为企业视频培训材料、会议录像检索提供了强大支持。
产业落地:多行业赋能,不仅仅是技术进步的“下一步”
RzenEmbed的推出,不仅仅是技术突破意义上的“下一步”,更是AI在企业场景落地的 “更进一步”。在RzenEmbed的加持下,多模态RAG技术可以有效识别并召回以往被视为难题的复杂表格、流程图等“非结构化”内容:
Q: when GLM-10B can be accessed?
A:
Q: get the info. about human evaluation's math score of GPT-4 vs. Qwen-14B-Chat
A:
目前,RzenEmbed通过权重开源和SaaS服务(360AI研究院官网 https://research.360.cn)两种方式对外开放,未来将在多行业释放价值:
制造业:助力技术手册管理,工程师通过一张零件示意图,即可快速检索到对应的安装说明、维修流程,大幅提升工作效率;
金融业:实现研报智能分析,分析师输入 “2024 年新能源行业利润率”,模型可精准定位相关数据表格、趋势图表,减少信息筛选时间;
医疗行业:辅助病例知识挖掘,医生上传一张影像图,即可检索到相似病例的诊断报告、治疗方案,为临床决策提供参考。
从技术突破到产业落地,RzenEmbed 正以多模态能力为核心,推动企业级知识检索升级到“全维度” 智能融合的“下一步”。未来,360AI研究院还将持续优化模型,让多模态技术推动 AI 在办公场景的深度落地。
....
#WildDoc
让GPT-4o准确率大降,这个文档理解新基准揭秘大模型短板
本文的共同第一作者为字节跳动算法工程师王安澜和廖蕾,本文的通讯作者为字节跳动算法工程师唐景群。
在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
- 脱离真实场景:现实中文档多为手机 / 相机拍摄的纸质文件或屏幕截图,面临光照不均、物理扭曲(褶皱 / 弯曲)、拍摄视角多变、模糊 / 阴影、对焦不准等复杂干扰;
- 无法评估鲁棒性:现有基准未模拟真实环境的复杂性和多样性,导致模型在实际应用中表现存疑;

这些缺陷引出了一个关键疑问:当前 MLLMs 模型距离在自然环境中实现全面且鲁棒的文档理解能力到底还有多远?
为了揭开这个谜底,字节跳动 OCR 团队联合华中科技大学打造了 WildDoc—— 首个真实世界场景文档理解的基准数据集。
WildDoc 选取了 3 个常用的具有代表性的文档场景作为基准(Document/Chart/Table), 包含超过 12,000 张手动拍摄的图片,覆盖了环境、光照、视角、扭曲和拍摄效果等五个影响真实世界文档理解效果的因素,且可与现有的电子基准数据集表现进行对比。
为了严格评估模型的鲁棒性,WildDoc 构建了一致性评估指标(Consistency Score)。实验发现主流 MLLMs 在 WildDoc 上性能显著下降,揭示了现有模型在真实场景文档理解的性能瓶颈,并为技术改进提供可验证的方向。本工作不仅填补了真实场景基准的空白,更推动文档理解研究向「实用化、泛化性」迈出关键一步。
- 论文链接:https://arxiv.org/abs/2505.11015
- 项目主页:https://bytedance.github.io/WildDoc/
- Github:https://github.com/bytedance/WildDoc
WildDoc 数据构造与组成
WildDoc 数据包含超 1.2 万张手动采集的真实文档图像,模拟自然环境中的复杂挑战,并引入一致性分数指标,量化评估模型在跨场景下的鲁棒性。WildDoc 目前已开源全部 12K + 图像与 48K + 问答对,其构造过程如下:
1、数据采集:
- 场景多样化:在自然环境(如户外、室内不同光照条件)中手动拍摄文档,确保覆盖环境、光照、视角等多维度干扰因素。
- 基准对齐:复用现有基准的电子文档,通过物理打印后拍摄,保证与传统基准的可比性。
2、多条件拍摄:
- 对同一文档进行四次拍摄,每次改变环境参数(如光照强度、拍摄角度、纸张扭曲程度),获取各种不同效果的对比样本。
3、标注与验证:
- 对图像中的文本、布局等关键信息以及对于问题的可回答性进行人工验证,确保准确性。
- 通过一致性分数计算,评估模型在不同条件下的稳定性,辅助筛选高质量数据。

实验结果
研究团队对众多具有代表性的 MLLMs 进行了测试,包括通用 MLLMs(如 Qwen2.5-VL、InternVL2.5)、专注文档理解的 MLLMs(如 Monkey、TextHarmony)和领先的闭源 MLLMs(如 GPT4o、Doubao-1.5-pro)。实验结果揭示了当前多模态大模型在真实场景下的诸多不足。

首先,现有 MLLMs 在 WildDoc 上的性能相比传统文档基准(如 DocVQA)测试大幅下降。例如,GPT-4o 平均准确率下降 35.3,ChartQA 子集下降达 56.4;开源模型 Qwen2.5-VL-72B 平均准确率 70.6,为开源最佳,但仍低于原始基准约 15%。目前最优的闭源模型为 Doubao-1.5-pro 表现最优(平均准确率 73.7%),但其一致性分数仅 55.0,这也意味着它在一半多的情况下都不能在不同条件下保持准确回答。这表明,当前 MLLMs 模型在面对真实场景的变化时,缺乏足够的稳定性和适应性。
实验结果揭示了在真实世界文档理解中 MLLMs 模型的表现,有以下几点发现:
- 物理扭曲最具挑战性:皱纹、褶皱、弯曲等物理变形导致模型性能下降最显著(如 GPT-4o 下降 34.1-34.7),远超光照(-25.9)或视角(-26.2)变化的影响。
- 非正面视角与图像质量:非正面拍摄(如倾斜视角)因文本形变和模糊导致性能下降(Qwen2.5-VL-72B 下降 17.6),但屏幕捕获图像因数据增强算法成熟,性能下降较小(-8.3 至 - 9.1)。
- 语言模型规模影响有限:大参数量模型(如 72B 参数的 Qwen2.5-VL)在 WildDoc 上表现略优,但未完全克服真实场景挑战,表明模型架构需针对性优化。



另外,一些模型在原始基准测试上表现差异不大,甚至已经接近饱和,但在 WildDoc 上却出现了显著的性能差异。这说明传统基准测试已经难以区分模型的真实能力,而 WildDoc 则能更敏锐地捕捉到模型在真实场景下的不足。
未来之路:如何让 MLLMs 更好地理解真实世界的文档?
面对这些挑战,研究团队提出了几点改进策略,为未来的研究指明了方向。
- 一是数据增强。通过更多的增强技术来模拟真实世界的条件,如变化的光照、阴影等,让模型在训练中接触到更多样化的场景,从而提高其适应能力。
- 二是鲁棒特征学习。让模型学会提取对真实世界变化不敏感的特征,这样即使文档图像发生了一些变化,模型也能准确理解其内容。
- 三是真实数据引入。收集更多的真实世界文档图像,丰富训练数据集,让模型在更多的「实战」中积累经验,提升性能。
WildDoc 数据集有效揭示了 MLLMs 在真实文档理解中的不足,为后续研究提供了关键基准和优化方向,更推动文档理解研究向「实用化、泛化性」迈出关键一步。
....
#对于算法少量内存胜过大量时间
50年僵局打破!MIT最新证明
相信大家都曾有过这样的经历:运行某个程序时,电脑突然卡住,轻则恢复文件,重则重新创建;或者手机频繁弹出「内存不足」的警告,让我们不得不忍痛删除珍贵的照片或应用。
这些日常的烦恼,其实都指向了计算世界中两个至关重要的基本要素:时间和空间。
时间和空间(也称为内存)是计算中最基本的两种资源:任何算法在执行时都需要一定的时间,并在运行过程中占用一定的空间以存储数据。
以往已知的某些任务的算法,其所需的空间大致与运行时间成正比,研究人员长期以来普遍认为这一点无法改进。
MIT 的理论计算机科学家 Ryan Williams 的最新研究建立了一种数学程序,能够将任意算法 —— 无论其具体执行何种任务 —— 转化为一种占用空间显著更少的形式, 证明少量计算内存(空间)在理论上比大量计算时间更有价值,这颠覆了计算机科学家近 50 年来的认知。
论文标题: Simulating Time With Square-Root Space
论文地址:https://arxiv.org/pdf/2502.17779
更重要的是,这一结果不仅揭示了在特定空间约束下可执行的计算范围,还间接证明了在有限时间内无法完成的计算类型。虽然后者早已预期它成立,但一直缺乏严格的证明方法。
50 年的探索与瓶颈
Juris Hartmanis
1965 年, Juris Hartmanis 和 Richard Stearns 两人合作发表了两篇开创性论文,首次对「时间」(Time)和「空间」(Space)这两个概念建立了严格的数学定义。
- 论文地址:https://doi.org/10.1090/S0002-9947-1965-0170805-7
这些定义为研究人员提供了一种共同的语言,使他们能够比较这两类资源,并据此将问题划分为不同的复杂性类别(complexity classes)。
其中一个最重要的复杂性类别 P 类,粗略地说,P 类包含所有能够在合理时间内求解的问题。与之对应的一个空间复杂度类别被称为 PSPACE 类 。
这两个类别之间的关系是复杂性理论中的核心问题之一。
所有属于 P 类的问题也都属于 PSPACE 类,这是因为快速算法在运行时通常没有足够的时间使用大量计算机内存空间。反之亦然,即所有 PSPACE 类问题也都能通过快速算法求解,则两个类别将完全等价:计算时间与计算空间在能力上将无本质差异。
然而,复杂性理论研究者普遍认为,PSPACE 类的规模要大得多,其中包含许多不属于 P 类的问题。换言之,他们相信,从计算能力角度来看,空间是一种远比时间更为强大的资源。这种信念源于这样一个事实:算法可以反复使用同一小块内存,而时间却无法重复利用 —— 一旦过去,就无法重来。
然而,复杂性理论家不满足于这种直觉推理:他们需要严谨的数学证明。要证明 PSPACE 类确实严格大于 P 类,研究人员必须能够展示存在某些 PSPACE 内的问题,其本质上不可能被快速算法求解。
1975 年,John Hopcroft、Wolfgang Paul 和 Leslie Valiant 设计了一个通用的「模拟程序」,证明了任何在特定时间内完成的任务,都可以在略少于该时间的空间内完成。这是连接时间和空间的第一个重要步骤,表明空间至少比时间略强。
然而,随后研究进展停滞,复杂性理论学者开始怀疑,他们或许已经碰到了一个根本性的障碍。
问题正出在 Hopcroft、Paul 和 Valiant 所提出的模拟方法的「通用性」特征上。虽然许多问题确实可以在远小于其时间预算的空间内求解,但一些问题从直觉上来看,似乎需要几乎与时间等量的空间。如果这种情况确实存在,那么更高效地节省空间的通用模拟将无从谈起。
不久之后,Paul 与另外两位研究者一道证明了这一点:更高效的通用模拟确实是不可能的,只要采纳一个看似理所当然的前提 —— 不同的数据块在任何时刻不能同时占用同一块内存空间。
Paul 的研究结果表明,若要真正解决 P 与 PSPACE 的关系问题(P versus PSPACE problem),就必须彻底放弃以模拟(simulation)为中心的研究路径,转而寻找一种全新的理论方法。问题在于,当时没人能提出可行的替代方案。
这个研究难题因此陷入僵局,整整持续了五十年 —— 直到 Williams 的工作最终打破了这一僵持局面。
打破僵局
Williams 的新研究源于对另一个计算中内存使用问题的突破性进展:哪些问题可以在极其有限的空间下被解决?
2010 年,复杂性理论先驱 Stephen Cook 与他的合作者设计出一道被称为树评估问题(tree evaluation problem)的新任务,并证明:任何算法若受制于低于某一特定阈值的空间预算,都无法解决这个问题。
然而,这项证明中存在一个漏洞。其推理依赖于 Paul 等人数十年前提出的直觉性假设:算法不能将新数据存入已经被占用的内存空间。
此后超过十年的时间里,复杂性理论研究者一直在尝试弥合这一漏洞。直到 2023 年,Stephen Cook 的儿子 James Cook 与研究者 Ian Mertz 推翻了这一假设。他们设计出一种全新的算法,能够以远低于此前认为的空间开销,解决树评估问题。这一结果使得原有下界证明完全失效。
Cook(左) 与 Mertz(右)
原先 Stephen Cook 的证明假设中,信息位(bit)被视作类似「石子」(pebbles),必须被存放在算法内存中的不同位置。而事实证明,数据的存储方式远比这更为灵活。
Williams 的革命性飞跃
Cook 与 Mertz 提出的算法引起了众多研究者的兴趣,但起初尚不清楚它是否适用于树评估问题(tree evaluation problem)之外的其他场景。
Ryan Williams
2024 年春季,Ryan Williams 任教的一门课中,一组学生将 Cook 和 Mertz 的论文作为期末项目进行展示。学生们的热情激发了他的兴趣,使他决定深入研究这项工作。
一旦着手,他便迅速捕捉到一个关键想法:他意识到,Cook 与 Mertz 提出的方法实质上是一个通用的空间压缩工具。他想到:为何不利用这一工具,设计一种全新的通用模拟机制(universal simulation),以更优的形式链接时间与空间复杂度?就像当年 Hopcroft、Paul 和 Valiant 所构筑的模型,只不过性能更强。
那项经典成果提供了一种方式,可以将任意具有给定时间预算(time budget)的算法,转化为一个空间预算略小的新算法。Williams 则认识到,倘若基于「柔性石子」(squishy pebbles)建立模拟技术,转化后的新算法所需空间将更大幅度降低 —— 大致等于最初时间预算的平方根。
这种新型节省空间的算法运算速度会显著下降,因此不太可能有实际应用。但从理论角度来看,其意义堪称革命性突破。
Williams 的模拟方法从一个已有的概念 ——「块规整图灵机模拟」 (block-respecting Turing machine simulation) 出发并进行了推广。其基本思路是将整个计算过程(假设总共 t 个计算步骤)分解为 t/b 个连续的「计算块」(computation blocks),每个块包含 b 个计算步骤。
这些「计算块」的输入 / 输出状态(或称为「配置」)之间存在依赖关系,可以形成一个「计算图」 (computation graph)。
Williams 的关键步骤是将这个图灵机在 t 步内的计算问题 —— 特别是判断其最终状态或输出 —— 规约 (reduce) 成一个「树评估问题」 (Tree Evaluation Problem, TEP) 的实例。
这个构造出来的树评估问题实例具有特定的参数:树的高度 h 大致为 t/b(即计算块的数量),每个节点传递的信息的位长度为 b,树的扇入度(每个节点有多少子节点)为 d(一个取决于图灵机本身的小常数)。
重要的是,这棵「树」是「隐式定义」的,意味着不需要在内存中实际构建出整棵树,而是有一套规则可以随时确定树的任何部分应该是什么样子。
对于这个构造出来的「树评估问题」实例,Williams 应用了由 Cook 和 Mertz 提出的算法来求解,Cook-Mertz 算法解决这类树评估问题的空间复杂度大致是 d^(h/2) * poly (b, h) (其中 d 是扇入度,h 是树高,b 是位长)。
Williams 接着分析了总的空间复杂度,并通过精心选择「计算块」的大小 b 来进行优化。当参数 b 被设定为大约 √t (总计算时间 t 的平方根) 时,前面提到的树高 h (约为 t/b) 就变成了大约 √t。
代入 Cook-Mertz 算法的空间复杂度公式(特别是 d^(h/2) 这一项),并综合其他因素(如 log t 因子,来源于对指针、计数器等的记录),最终推导出总的模拟空间复杂度为 O (√t log t)。
参考链接:
https://www.quantamagazine.org/for-algorithms-a-little-memory-outweighs-a-lot-of-time-20250521/
https://arxiv.org/pdf/2502.17779
....
#Visual Planning
只用图像也能思考,强化学习造就推理模型新范式!复杂场景规划能力Max
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。

常见的 MLLM 结构。
这种模式要求模型首先将视觉信息「翻译」或「映射」为文本描述或内部的文本化 token,然后再利用大型语言模型的文本推理能力进行处理。
这个转换过程不可避免地可能导致视觉信息中固有的丰富细节、空间关系和动态特征的丢失或削弱,形成了所谓的「模态鸿沟 (modality gap) 」。这种鸿沟不仅限制了模型对视觉世界的精细感知,也影响了其在复杂视觉场景中进行有效规划的能力。
例如,模型虽然能够识别图像中的物体并描述它们之间一些相对简单的空间关系,但在追求极致的定位精度,或需要深入理解和预测物体间高度复杂、动态或隐含的交互逻辑(而非仅仅识别表面现象)时,其表现仍可能因视觉信息在文本化过程中的细节损失而受到限制。

来自剑桥、伦敦大学学院、谷歌的研究团队认为:语言不一定始终是进行推理最自然或最有效的模态,尤其是在涉及空间与几何信息的任务场景中。

基于此动因,研究团队提出了一种全新的推理与规划范式 —— 视觉规划(Visual Planning)。该范式完全基于视觉表示进行规划,完全独立于文本模态。
论文标题:Visual Planning: Let’s Think Only with Images
论文地址:https://arxiv.org/pdf/2505.11409
代码仓库:https://github.com/yix8/VisualPlanning
在这一框架下,规划通过一系列图像按步编码视觉域内的推理过程,类似于人类通过草图或想象视觉图景来计划未来行为的方式。

推理范式的对比。传统方法(上方与中间两行)倾向于生成冗长且不准确的文本规划,而视觉规划范式(下方一行)则直接预测下一步的视觉状态,形成完全基于图像的状态轨迹,过程无需语言中介。
为支持该方法,研究团队提出了一个创新性的强化学习框架 —— 基于强化学习的视觉规划(Visual Planning via Reinforcement Learning, VPRL)。该框架以 GRPO(群体相对策略优化)为核心优化方法,用于在训练后提升大规模视觉模型的规划能力。
在多个典型的视觉导航任务中,包括 FROZENLAKE、MAZE 和 MINIBEHAVIOR,该方法实现了显著的性能提升。实验结果表明,相较于在纯文本空间内进行推理的其他所有规划变体,研究团队提出的纯视觉规划范式在效果上具备更强优势。
以下是动态示例:
冰湖(FrozenLake): 这是一个具有随机性的网格世界(gridworld)环境,智能体需从指定起点出发,安全到达目标位置,期间必须避免掉入「冰洞」。

迷宫 Maze: 智能体获得一个初始图像,该图展示了迷宫的布局。其任务是在迷宫中从起点(绿色标记)出发,最终到达终点(红色旗帜所在位置)。
微行为(MiniBehaviour): 智能体首先需要从起点移动至打印机所在的位置并「拾取」它,之后应将打印机运送至桌子处并「放下」。

这项研究不仅证明视觉规划是一种可行的替代方案,更揭示了它在需要直觉式图像推理任务中的巨大潜力,为图像感知与推理领域开辟了崭新方向。
强化学习驱动的视觉规划
视觉规划范式
以往的大多数视觉推理基准任务,通常通过将视觉信息映射到文本领域来求解,例如转换为物体名称、属性或关系等标注标签,在此基础上进行几步语言推理。
然而,一旦视觉内容被转换为文本表示,该任务便退化为纯语言推理问题,此时语言模型即可完成推理,而无需在过程中再引入视觉模态的信息。
研究团队提出的视觉规划范式本质上与上述方法不同。它在纯视觉模态下进行规划。研究团队形式化地定义视觉规划为:在给定初始图像 v₀ 的前提下,生成中间图像序列 T = (ˆv₁, ..., ˆvₙ),其中每个 ˆvᵢ 表示一个视觉状态,共同构成一个视觉规划轨迹。具体而言,记 π_θ 为一个参数化的生成视觉模型。该视觉规划轨迹以自回归方式生成,每一个中间视觉状态 ˆvᵢ 都在给定初始状态和此前生成状态的条件下进行采样:

大规模视觉模型中的强化学习
强化学习(RL)在优化自回归模型方面表现出显著优势,其通过序列级奖励信号进行训练,突破了传统 token 级监督信号的限制。在自回归图像生成任务中,图像被表示为视觉 token 的序列。
受 RL 在语言推理任务中成功应用的启发,研究团队引入了一个基于 RL 的训练框架,用于支持大模型下的视觉规划,并采用了 GRPO 方法。该方法利用视觉状态之间的转换信息来计算奖励,同时验证生成策略是否满足环境约束条件。
为训练一种能生成有效动作、并在 RL 阶段保持探索多样性的策略模型,研究团队提出了一种创新性的两阶段强化学习框架:
Stage 1:策略初始化。在该阶段,研究团队采用监督学习,通过在环境中的随机游走(random walk)生成的轨迹来初始化视觉生成模型 π_θ。目标是生成有效的视觉状态序列,并在「模拟」环境中保持充足的探索性。在训练过程中,每条轨迹由一个视觉状态序列 (v₀, ..., vₙ) 构成。对每条轨迹而言,研究团队提取 n−1 对图像样本 (v≤ᵢ, vᵢ₊₁),其中 v≤ᵢ 表示前缀序列 (v₀, ..., vᵢ)。随后,在给定输入前缀的情况下,模型会接触到来自 K 条有效轨迹的下一状态候选集 {vᵢ₊₁^(j)}_{j=1}^K。这些候选状态共享相同的前缀,为防止模型过拟合某一特定转换,同时鼓励生成过程的随机性,研究团队在每个训练步骤中随机采样一个候选状态 vᵢ₊₁^(ℓ) 作为监督目标,通过最小化视觉微调损失函数(VPFT)来优化模型:


所提 VPRL 框架概览。图中展示了该框架在视觉导航任务中的应用,利用自回归式大规模视觉模型进行图像生成。其中使用了 GRPO 对视觉策略模型进行训练,并引入进度奖励函数以鼓励推进性的动作并惩罚非法行为,从而实现与目标一致的视觉规划。
总体而言,该阶段主要作为接下来的强化学习阶段的热启动过程,旨在提升生成图像的连贯性和整体规划质量。
Stage 2:面向视觉规划的强化学习。在第一阶段初始化后,模型拥有较强的探索能力,这对强化学习至关重要,可确保模型覆盖多种状态转移路径,避免陷入次优策略。在第二阶段中,模型通过模拟未来状态(即潜在动作的后果),依据生成结果获得奖励反馈,从而逐步引导学习出有效的视觉规划策略。
具体而言,给定当前输入前缀 v≤ᵢ,旧版本模型 π_θ^old 会采样出 G 个候选中间状态 {ˆvᵢ₊₁^(1), ..., ˆvᵢ₊₁^(G)}。每个候选状态代表了时间步 i 上智能体采取某一行动 a^(k) 后,模拟产生的下一视觉状态。研究团队使用基于规则的解析函数将状态对 (vᵢ, ˆvᵢ₊₁^(k)) 映射为离散动作,以便进行结构化解释。
随后,研究团队设计了一个复合奖励函数 r (vᵢ, ˆvᵢ₊₁^(k)) 来对每个候选状态进行打分,该奖励衡量候选状态是否代表了对目标状态的有效推进(即是否有用)。
不同于传统强化学习中依赖学习一个价值函数评估器(critic),GRPO 通过候选组内的相对比较来计算优势值,从而提供易于解释、计算更加高效的训练信号。此时每个候选的相对优势 A^(k) 的计算方式为:

为引导模型产生更优的候选响应,并强化高优势行为的倾向,研究团队根据以下目标函数更新策略:

其中,D 指代前缀分布,ρ^(k) = π_θ(ˆvᵢ₊₁^(k) | v≤ᵢ) / π_θ^old (ˆvᵢ₊₁^(k) | v≤ᵢ) 表示重要性采样比值。
奖励设计。与离散操作或文本 token 不同,视觉输出往往是高维稀疏信息,难以被直接分解为可解释的单元。在研究团队的视觉规划框架下,核心挑战在于如何判断一个生成的视觉状态能否准确表达对应的规划动作。因此,奖励设计聚焦于在考虑环境约束下,对朝向目标状态的推进进行评估。
为解释由状态 vᵢ 到候选状态 ˆvᵢ₊ₜ^(k) 所隐含的动作计划,研究团队定义一个状态 - 动作解析函数 P: V × V → A ∪ E,其中 A 表示有效动作集合,E 表示非法状态转移集合(例如违反物理约束的动作)。

该过程可借助独立的图像分割组件或基于规则的脚本完成,从像素层级数据中解析出可解释的动作单元。
一旦动作被识别,研究团队引入「进度图」(progress map)D (v) ∈ ℕ,表示从某一可视状态 v 到达目标状态所需的剩余步骤数或努力度。通过比较当前状态与生成状态在进度图上的相对变化,研究团队将动作集合 A ∪ E 划分为三类:

据此,研究团队提出进度奖励函数 r (vᵢ, ˆvᵢ₊₁^(k)):

r =αₒₚₜ, 若为推进有效动作(optimal)r =αₙₒₚₜ, 若为无推进的动作(non-optimal) r =αᵢₙᵥ, 若为非法动作(invalid)
在实验中,研究团队设置 αₒₚₜ = 1,αₙₒₚₜ = 0,αᵢₙᵥ = −5,从而鼓励推进行为,惩罚不可行的状态转移。
系统变体
除提出的 VPRL 主干框架外,为全面评估监督方式(语言 vs. 图像)与优化方法(监督微调 vs. 强化学习)对性能的影响,研究团队提出了若干系统变体作为对比基线:
视觉微调规划(VPFT)。研究团队提出「视觉微调规划」(Visual Planning via Fine-Tuning, VPFT)作为本框架的简化版本,其训练结构与第 2.2 节中的阶段一一致,但使用最优规划轨迹代替随机轨迹。对于每个环境,研究团队采样一条最小步骤的最优轨迹 (v₀^opt, v₁^opt, ..., vₙ^opt),该轨迹从初始状态 v₀^opt = v₀ 通向目标状态。在每一步,模型根据当前前缀 v≤ᵢ^opt 学习预测下一个状态 vᵢ₊₁^opt。训练目标与公式(2)相同,以最优轨迹作为监督信号。
基于语言的监督微调(SFT)。在该对比方法中,规划任务被构建于语言模态中。与生成图像形式的中间状态不同,模型需生成动作序列的文本描述。形式上,给定输入视觉状态 v 及任务描述文本提示 p,模型被训练以输出一个动作序列 t = (t₁, ..., t_L),其中每个 token tᵢ ∈ V_text 表示一个动作。模型输入为提示词 token 与视觉 token 的拼接,目标为对应的文字动作序列。研究团队采用此前在自回归模型中常用的监督微调方法,通过最小化交叉熵损失来学习动作预测:

视觉规划的实验表现如何?
该团队基于一些代表性任务检验了视觉规划这一新范式的实际表现。
具体来说,为了对比视觉规划与基于语言的规划,该团队实验了三种视觉导航环境:FROZENLAKE、MAZE 和 MINIBEHAVIOR。所有这些环境都可以在两种模态下求解,这样一来便能更加轻松地对比两种策略。
模型方面,该团队选择的是完全在视觉数据上训练的模型 —— 这些模型在预训练过程中未接触过任何文本数据。
具体来说,他们选择了大型视觉模型 LVM-3B 作为骨干网络,并使用了 VPFT 和 VPRL 方法。与此同时,相对比的文本模型包括不同设置的 Qwen 2.5-VL-Instruct 以及 Gemini 2.0 Flash (gemini-2.0-flash-002) 和先进思维模型 Gemini 2.5 Pro (gemini-2.5-pro-preview-03-25)。
评估指标则采用了精确匹配 (EM) 和进度率 (PR) 两种。
那么,视觉规划的表现如何呢?
视觉规划胜过文本规划
如下表 1 所示,视觉规划器(VPFT 和 VPRL)在所有任务上均取得了最高分,优于所有使用语言推理的基线模型。

在相同的通过微调的监督训练方法下,VPFT 在精确匹配 (EM) 指标上平均比基于语言的 SFT 高出 22% 以上,而 VPRL 的优势还更大。在进度率 (PR) 方面也观察到了类似的趋势。
这些结果表明,视觉规划范式在以视觉为中心的任务中优势明显,因为语言驱动的方法可能与任务结构不太契合。纯推理模型(无论是大型闭源系统还是小型开源 MLLM)。如果不针对特定任务进行调优,在完成这些规划任务时都会遇到困难。即使是先进的思维模型 Gemini 2.5 Pro,在更复杂的 MAZE 和 MINIBEHAVIOR 任务中,EM 和 PR 也几乎低于 50%,这表明当前前沿的语言模型还难以应对这些挑战,尽管这些任务对人类来说是直观的。
强化学习能带来增益
两阶段强化学习方法 VPRL 带来了最高的整体性能,超越了其它变体。在第二阶段之后,该模型在更简单的 FROZENLAKE 任务上实现了近乎完美的规划(91.6% EM,93.2% PR),并在 MAZE 和 MINIBEHAVIOR 任务上保持了强劲的性能。在所有任务上的性能都比 VPFT 高 20% 以上。
正如预期,该团队的强化学习训练的第一阶段(强制输出格式,但不教授规划行为)获得了近乎随机的性能(例如,在 FROZENLAKE 数据集上实现了 11% 的 EM)。在使用新提出的奖励方案进行第二阶段的全面优化后,规划器达到了最佳性能。这一提升凸显了强化学习相对于 SFT 的一个关键优势:VPRL 允许模型自由探索各种动作并从其结果中学习,而 VPFT 则依赖于模仿,并且倾向于拟合训练分布。通过奖励驱动式更新来鼓励利用(exploitation),VPRL 学会了捕捉潜在的规则和模式,从而实现了更强大的规划性能。
下图展示了一个可视化的对比示例。

随着复杂度提升能保持稳健性
该团队发现,在研究不同方法在不同任务难度(更大的网格通常更难)下的表现时,强化学习依然能保持优势。

如图 5 所示,当在 FROZENLAKE 环境中,随着网格尺寸从 3×3 增加到 6×6,Gemini 2.5 Pro 的 EM 分数从 98.0% 骤降至了 38.8%。相比之下,新提出的视觉规划器不仅在所有网格尺寸下都保持了更高的准确度,而且性能曲线也更加平坦。同样,VPRL 也表现得比 VPFT 更稳定,在 3×3 网格上 EM 分数保持在 97.6%,在 6×6 网格上也仍能达到 82.4%,这表明 VPRL 的稳健性相当好。
....
#PC-Agent-E
312条轨迹激发241%性能!上交大与SII开源电脑智能体,超越 Claude 3.7
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。
业界普遍认为,需要海量的轨迹数据或复杂的强化学习才能实现电脑智能体的水平突破——这可能意味着大量的人工轨迹标注,以及大规模虚拟机环境的构建,以支撑智能体的学习与优化。
然而,来自上海交通大学和 SII 的最新研究却给出了一个非共识答案:仅需 312 条人类标注轨迹,使用 Claude 3.7 Sonnet 合成更丰富的动作决策,就能激发模型 241% 的性能,甚至超越 Claude 3.7 Sonnet extended thinking 模式,成为 Windows 系统上开源电脑智能体的新一代 SOTA。
论文标题:Efficient Agent Training for Computer Use
论文地址:https://arxiv.org/abs/2505.13909
代码地址:https://github.com/GAIR-NLP/PC-Agent-E
模型地址:https://huggingface.co/henryhe0123/PC-Agent-E
数据地址:https://huggingface.co/datasets/henryhe0123/PC-Agent-E
这一发现传递出一个关键信号:当前大模型已经具备了使用电脑完成任务的基础能力,其性能瓶颈主要在于长程推理(long-horizon planning)能力的激发,而这一能力使用极少量高质量轨迹即可显著提升。
,时长00:25
,时长00:24
PC Agent-E:如何用极少量轨迹训练出强大的电脑智能体?
数据从哪来?人类提供原始操作轨迹
与以往依赖大规模人工标注或复杂自动化合成的方式不同,团队的方法只需 312 条真实的人类操作轨迹。这些轨迹由团队开发的工具 PC Tracker 收集而来,仅由两位作者花一天时间操作自己的电脑,就完成了原始轨迹数据的收集。每条轨迹包含任务描述、屏幕截图以及键盘鼠标操作,并确保了数据的正确性。

312 条轨迹在不同软件上的分布
思维链补全:让「动作」有「思考」的支撑
人类执行每一个动作,往往都有一定的理由或「思考过程」。但在收集的原始轨迹数据中,这部分「思维链」是缺失的。于是,团队对人类动作进行了「思维链补全」(Thought Completion),为每一个动作步骤添加了背后的思考逻辑(符合于 ReAct 范式)。此时的数据已足以用于智能体训练,但团队并未止步于此——接下来的关键一步,进一步大幅提升了轨迹质量。
轨迹增强:让 AI 帮你「脑洞大开」
接下来,团队提出了一个关键创新点:轨迹增强(Trajectory Boost),这正是使用极少轨迹让模型超越 Claude 3.7 Sonnet(thinking)的关键。
其核心观察为:每个电脑任务其实可以通过多种路径完成。也就是说,除了人类采取的动作以外,轨迹中的每一步其实都有多个「合理的动作决策」。为了捕捉这种轨迹内在的多样性,团队利用前沿模型 Claude 3.7 Sonnet,为轨迹的每一步合成更多的动作决策。团队注意到,轨迹中每一步记录的数据,作为「环境快照(environment snapshot)」,已足以为人类或智能体提供决策信息。于是,团队将这些快照提供给 Claude 3.7 Sonnet,采样多个包含思考过程的动作决策。这一过程极大丰富了轨迹数据的多样性。

思维链补全与轨迹增强
模型训练:少量数据也能训出强大模型
最终,团队在开源模型 Qwen2.5-VL-72B 的基础上进行训练,得到 PC Agent-E 智能体。作为一款原生智能体模型(native agent model),PC Agent-E 无需依赖复杂的工作流设计,即可实现端到端的任务执行。令人惊喜的是,在仅使用 312 条人工标注轨迹的情况下,模型性能便达到了训练前的 241%,展现出极高的样本效率。
团队在 WindowsAgentArena-V2 上进行评测——这是对原始 WindowsAgentArena 存在问题进行改进后的新版本。实验结果显示,PC Agent-E 的表现甚至超过了 Claude 3.7 Sonnet 的「extended thinking」模式,而用于数据合成的 Claude 3.7 Sonnet 并未启用这一模式。这标志着 PC Agent-E 成为当前 Windows 系统上开源电脑智能体的新一代 SOTA!与此同时,PC Agent-E 在 OSWorld 上也表现出不俗的跨平台泛化性能。

不同电脑智能体在 WindowsAgentArena-V2 上的评估结果
轨迹增强方法的有力验证
论文的关键创新之一——轨迹增强方法在人类轨迹的每一步补充了 9 个合成动作决策。为了进一步验证该方法的效果,团队调整训练时使用的合成动作数量,并观察其对模型性能的影响。
如图所示,随着合成动作数量的增加,模型性能显著提升,并展现出良好的拓展趋势。相比仅使用人类轨迹训练(性能提升仅 15%),PC Agent-E 在引入合成动作后实现了高达 141% 的性能飞跃,充分证明了轨迹增强方法对智能体能力突破的关键作用。

模型能力随训练数据中动作决策的扩展倍数的变化
结论与展望
实验结果有力证明了一个关键观点:少量高质量轨迹,就足以激发智能体强大的长程推理(long-horizon planning)能力。无需海量人类标注,就能训练出当前最优(SOTA)的电脑智能体。
目前,即使是最前沿的电脑智能体,其能力与人类相比仍有明显差距。在这种情况下,在预训练和监督微调阶段引入一定的人类认知,仍然是为后续强化学习打下坚实基础的必要步骤。
团队方法提供了一种新的思路:在人类标注轨迹注定有限的情况下,可以通过提高轨迹质量来实现高效的性能提升。这不仅降低了数据需求,也为未来构建更智能、更自主的数字代理铺平了道路。PC Agent-E 只是一个开始。通往真正能理解并自如操作数字世界的智能代理之路,仍在继续。
....
#Office三件套被卷死
惊了,我的电脑在自动打工!花不到1块钱雇个「AI超人」
国产智能体,这次真封神了。
过去这段时间,「智能体」简直杀疯了。
无论是初创公司还是互联网大厂,主流 AI 玩家们都开始围着它转,说它是大模型的下一站也毫不夸张。
作为人工智能的一种高级实现,智能体比大模型更具实体化、自主性、交互性,已经进化成「会思考、动手强、能串联一切工具的全能战士」。
就在 5 月 22 日,这条 AI 赛道迎来了一个足以傲视群雄的「巨无霸」产品,其背后站着的正是一家国产大模型厂商 —— 昆仑万维。
这家位居国内大模型第一梯队的选手,面向全球正式发布了天工超级智能体(Skywork Super Agents)(下文简称 Skywork),直接卷出了新高度!

与 Manus、OpenAI deep research、Genspark 等其他智能体相比,Skywork 有三大必杀技:「场景全、能力强与框架开源。」
首先是「全」,Skywork 远不是一两个小工具拼凑出来的智能体,而是系统打包了 5 个专家级 AI Agent,可以一键生成专业文档、数据表格、PPT、播客、网页五件套,称得上是内容创作者眼中的黄金搭子。
更炸裂的是,Skywork 还提供了 1 个通用 AI Agent,可以一站式地输出音乐、MV、宣传片、绘本、有声书等多模态内容。

其次是「智商」爆表,跑分成绩给了我们很大惊喜。
Skywork 在多个 AI Agent 基准测试榜单中登顶,比如在 GAIA(最困难、最全面的智能体基准测试)中,面对从初级到高级、从易到难的不同任务(Level 1 到 Level 3),它全面超越了 Manus、OpenAI deep research。

这还没完,Skywork 在 SimpleQA(评测智能体回答事实性问题准确性的基准测试)中的得分(94.5)同样超越了 OpenAI 以及当前 SOTA,解决大模型「胡言乱语」更给力了。

最后是让开发者沸腾的 —— 全球首个开源的 deep research agent 框架,这意味着每个人都可以参与到智能体的定义中来了。
同时,直接开放三大 MCP 接口,供开发者调用文档生成、数据分析、PPT 演示文档三大能力,形成以智能体为核心的「AI 操作系统」,成为开发者们的新基建。
框架开源地址:https://github.com/SkyworkAI/DeepResearchAgent
MCP 地址:https://mcp.so/server/skywork-super-agents/Skywork-ai
还有一点特别值得称道,Skywork 不搞现在 AI 圈讨厌的饥饿营销那套,不排队、不抢码、不内测申请,上线即可用。性价比还贼高,单个通用任务成本仅需 0.96 元。
今日,昆仑万维重磅宣布天工超级智能体(Skywork Super Agents)APP 正式上线,这也是全球首款基于 AI Agent 架构的 Office 智能体手机 App。
看起来,想要体验智能体的小伙伴终于有了一个实力更强、价格又便宜的选择。
,时长01:59
第一手实测:智能体界的「全能型选手」
从 OpenAI 的 deep research 到 Manus、Genspark 等专精型 Agent,市面上的产品在功能上可以说大同小异,而「谁真正能落地、谁真正好用」成为普通用户最关心的问题。
接下来,我们就搞个一手实测,看看 Skywork 这个「新秀」的实力究竟如何。

- 全球官网:https://skywork.ai
- 中国官网:https://tiangong.cn
多场景写作
最近 AI 率检测的问题频频登上各大平台的热搜榜。有大学生发帖称,熬秃了头写的毕业论文 AI 率被判了 80%,测试一番后发现朱自清的《荷塘月色》AI 率竟超 60%。为了去 AI 味儿,学生们绞尽脑汁,要么疯狂改标点,要么短句改长句……
对此,我们让 Skywork 生成一份适用于 B 站 3 分钟科技短视频的脚本, 吐槽一下当前 AI 技术的发展带来的魔幻现实。

[ 上下滑动查看更多 ]
不得不说,Skywork 设计的「UP 主台词」很有 B 站特色,如「屏幕前的各位『肝帝们』」、「亿点点变化」、「以前是怕抄袭,现在是怕被 AI」 等语句非常贴合年轻受众,既有梗又有深度。而且它还在合适的位置穿插着柱状图、专家观点的引用,更增强了脚本的传达力与可信度。
可视化数据分析
Skywork 的表格模式类似于 Microsoft Excel 和 Google Sheets,输入主题、需求或者上传原始数据后,它就能智能分析并生成表格、图标等。
我们输入指令:「生成一份图灵奖 2015-2024 年的获奖统计」。
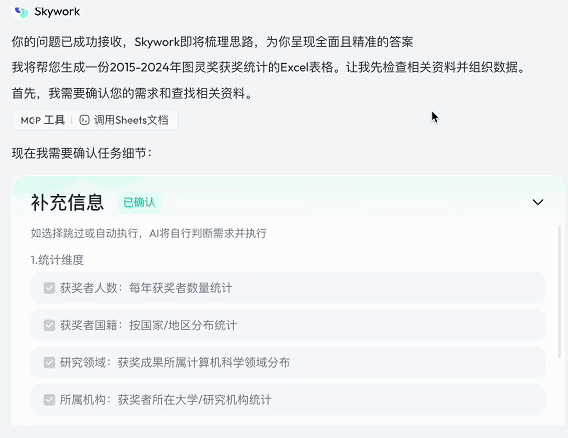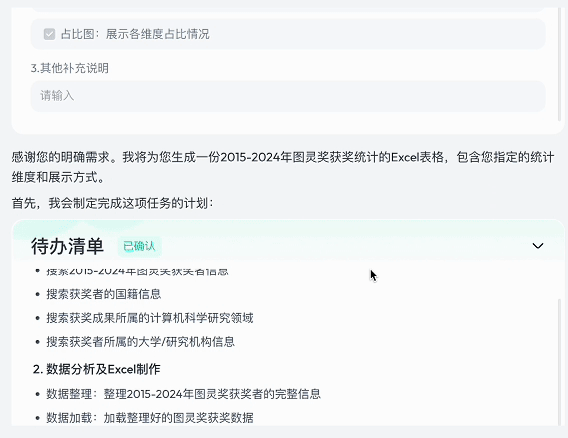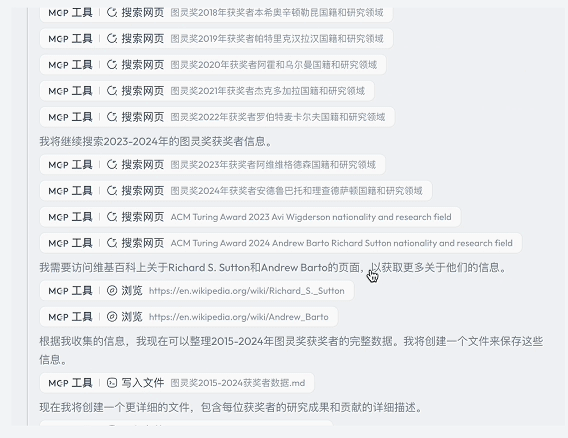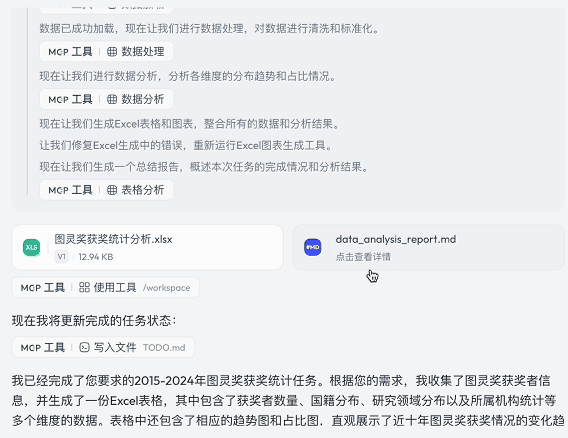
Skywork 并不急于执行,而是通过与用户交互确认任务细节,包括统计维度(如获奖人数、国籍、研究领域、所属机构)和展示方式(如表格、趋势图、占比图等)。这种前置的任务拆解能力,使得整个分析过程具有极高的准确性和可控性。
紧接着,它会自动生成待办清单,调用各种 MCP 工具依次执行任务,整个过程无需用户参与。
Skywork 准确完成了数据整理和分析任务,最终生成四个结构完整、信息翔实的 sheet。在可视化呈现方面,它生成的饼图、柱状图和折线图不仅美观,还极具数据表达力。




[ 上下滑动查看更多 ]
精美 PPT
打工人最怕三件事:加班没有加班费、老板突然 @你、顺便做个 PPT。别的顺便是顺手,这个「顺便」是要命:字体怎么调都不对,图表怎么看都很土,辛辛苦苦熬夜干到凌晨三点,结果老板瞅了一眼:「感觉不太对,你再打磨下」。
现在,Skywork 给每个被 PPT 逼疯的打工人开了张救命的「药方」。只要一句简单的 Prompt:制作《日本镰仓的旅游攻略》PPT,它立马就能生成一份结构清晰、颜值在线的 PPT。

[ 上下滑动查看更多 ]
从最终生成效果来看,该 PPT 不仅有实用信息点,还配了高质量的场景图、路线图和日程表,我们完全可以直接拿来用。
创意网页
今年 2 月份,Andrej Karpathy 提出了 Vibe Coding(氛围编程)的概念,码农们不用逐行写代码,只要用自然语言描述目标功能,专用大模型即可生成对应代码。
Skywork 目前也能实现这一功能,输入需求就能快速生成可溯源、可编辑、可应用的高质量多模态 html 成果。举个例子,我们让它「生成一个开心消消乐的网页小游戏」,几分钟后它啪地甩来一个水果卡通风的成品。

这个网页小游戏不仅界面设计的好看,更重要的是,它真实可玩。在规定的一分钟内,玩家让三个或以上相同的水果图标连成一条直线即可消除,并且它还能根据得分情况增加等级。
智能音频播客
去年谷歌 NotebookLM 曾掀起一股 AI 播客热潮,仅需一个链接或文档,几分钟就能转成接地气的男女对谈。当时,不少 AI 圈的大咖为它「站台」,甚至连「死对头」OpenAI CEO Altman 都认为它很酷。

Skywork 这次上线的播客模式与之有异曲同工之妙。我们输入 Prompt:《面纱》读书对谈播客,它随即就去找资料写稿「录制」,然后一键生成音频播客。
《面纱》读书对谈播客,6分钟
AI 男女主播吐字清晰,语音语调自然真实,语气词、说话的气口都把握得相当到位。从内容来看,他俩也不是照本宣科,而是在真正读懂了小说后,针对播客这一媒介形式进行的自我创作。

与谷歌 NotebookLM 不同的是,如果我们对成品有任何调整需求,可以直接在聊天框里提,Skywork 随时修改。比如,我们让播客增加一部分,介绍小说中的男主沃尔特・费恩是个怎样的人,Skywork 立马在原有播客基础上更新了相应的内容。

音乐与视频生成
此前,昆仑万维发布了全球首个音乐推理大模型 Mureka O1,不输 Suno 的惊艳效果让所有人看到了其在音乐生成领域的深厚造诣。
Skywork 的音乐实力同样不俗,比如「生成一段适合清晨独自散步时听的轻音乐」,它以钢琴为主旋律,整体节奏舒缓匀称,给人一种在晨光中漫步的惬意感觉。
音乐生成,1分钟
视频生成也不在话下,比如「城市天台夜晚,一群会发光的小鸟从霓虹灯上起飞,汇聚成一个漂浮的时间钟表」,这种复杂 Prompt 的目标场景都能 hold 住,你就说赞不赞吧?!
,时长00:08
Skywork 还能生成带背景音乐的视频,如下「generate a video with music: a man raps to the camera」。下一步的升级方向可能就是直接生成指定对白、语气的音画同步视频了,就像谷歌 Veo 3 所能做到的那样。
,时长00:08
这一波实测下来,我们切身的感受是:强,太强了!
无论是生成内容的丰富性、专业性、准确性,还是界面设计的美观程度和布局的合理性,Skywork 都展现出了一个「全能型」智能体该有的样子,甩开了现有竞品。
人无我有,打造差异化竞争优势
在体验过程中,我们发现,Skywork 在任务协同、多模态生成、结果可信度和个人知识库上,具备了真正的「差异化实力」,克服了 Manus、OpenAI deep research 等竞品的痛点,实现了「人无我有」的后发优势。
超能 Office 三件套 —— 高效内容创作与生产力输出
当代打工人,谁没被文档、表格和 PPT 这工作「三件套」逼疯过?
如今,Skywork 把文档、表格、PPT 这三大办公工具整合在了一起,生成的内容不仅更详细、更条理,还能做出各种清晰好看的图表,甚至还能插入 Youtube 视频。


[ 上下滑动查看更多 ]
当然,如果你想对生成的内容进一步细化调整,Skywork 提供了在线编辑功能,通过「编辑」按钮直接在界面上修改文字、调整结构,像使用在线协作工具一样自然流畅。

导出格式也非常灵活,包括 PPTX、PDF、HTML、Google Slides 等多种格式,满足我们在决策讨论、版本迭代、二次创作中的不同需求。

生成酷炫内容 —— 多模态内容融合
在日常创作中,我们往往需要在文字、图片、音频、视频等多个工具之间来回切换,才能把一个想法完整呈现。
Skywork 在通用对话任务上打破传统 Agent 任务执行的边界,接入网页搜索、思考分析、图片生成、图片理解、语音生成、音乐生成、视频生成等十余个 MCP,让创作者无需奔波于不同平台,就能一键生成宣传片、MV、有声书、绘本等多种形式的内容。
比如我们仅用一个 Prompt,就让它混搭出一个小猫的旅行 vlog,不仅准确生成出各大地标,还让小猫在每一个场景中自然入镜,整个过程无需人工干预。
,时长00:35
提示词:帮我生成一个小猫的旅行 vlog,内容分别是小猫到法国埃菲尔铁塔、美国自由女神像、中国长城、澳大利亚悉尼歌剧院、埃及金字塔、印度泰姬陵、日本富士山等地旅游并与这些著名景点自拍合照,配乐轻松欢快。
这种「Agent+MCP 多工具融合」的架构,有望引领下一代内容生产的范式革命。
信源可追溯 —— 向可验证内容创作演进
在如今这个内容泛滥的时代,信息可靠性反倒成了稀缺资源。大模型虽然擅长高效生成,但它们一本正经地胡说八道早就不是什么新闻。
Skywork 试图解决的正是这个痛点。它生成的每一段文字、每一张图片都不是凭空捏造,而是能清晰追溯到具体出处。输出文本可以关联原文段落,图片也能标注出溯源网页或知识库来源,甚至还附上完整的信源列表。

这种将信息溯源融入创作流程,让用户在生成内容的同时随时验证,大大降低了大模型「满嘴跑火车」的风险,真正让每一次产出都有据可查。
个人知识库 —— 打造私有化智能内容循环
如今,市面上的智能体普遍存在的一大痛点在于:素材零散、成果不可持续,缺乏系统性积累机制。
为了解决这些挑战,Skywork 上线了个人知识库。我们可以上传 pdf、doc、ppt、xls 等多种格式的文件,也可以上传录音、url 和 youtube 视频播放地址。每个知识库支持上传最多 50 个文档,并可根据不同主题创建多个知识库,实现清晰有序的知识管理。
更重要的是,Skywork 不只是一个信息存储工具,更是一个智能创作引擎。基于知识库内容,我们可以一键生成 多模态内容,它们又能反向存入知识库,形成「素材 - 创作 - 再积累」的正向循环,打造真正可生长的个人知识系统。

以上这些差异化功能,构成了 Skywork 的核心竞争力,使之成为真正「有用、敢用、好用」且更具性价比的 AI 智能打工人。
从信息发现到结构化内容输出
全链路流程被打通
为了实现通用化、性能更强的智能体,Skywork 在底层技术上祭出了多项自研,打造全链路智能内容引擎,从深度搜索到高效生成,一站式解决复杂任务。
首先自研一个 deep research 模型,通过依托「深度思考 + 推理」的信息检索,不仅查得更广与更准,还能更快找到高质量源信息;强化学习能力的加持又进一步增强模型面向各种搜索任务的泛化性,性能上全面对标 OpenAI 竞品。
接下来是一套自研的 agent workflow 框架,在高效完成传递信息、拆解任务之外,还能灵活调用基座大模型,使智能体能力得以延伸。效果也非常显著,在开源的 deep research 排行榜上拿下了 SOTA 成绩。
此外还自研一个生成物模型,实现高质量数据的生成、收集和训练,使生成内容更丰富、更真实且可读性更强;配合自研的在线编辑系统,无缝兼容常见办公软件,实现一站式内容生成与修改,并能一键导出成稿,效率与友好性绝对是拉满了。
最后,面对特别复杂的任务也有诀窍 —— 「化整为零、各个击破」,即将复杂任务拆分为多个小任务,每个小任务单独进行深度研究、互不干扰,有效突破了模型上下文长度的限制,支持超复杂任务协同解决。
正是技术上的一系列突破,Skywork 才有了如今敢于叫板一切对手的实力。
Office 的下一次革命来了?
自大模型技术爆发以来,人们一直在寻找应用的突破方向,最先开启自动化革命的恰恰是写代码本身。
现在,很多人都知道自然语言驱动的编程工具 Cursor,它正在吸引越来越多的程序员。人们写代码的方式已经发生了变化:先让 AI 写一个 readme 列出项目设计思路、功能逻辑,然后再让 AI 一步一步地实现就可以了。
Cursor 也让编程门槛降到了一个前所未有的低点,号称让非程序员也能参与开发。只要你能描述清楚需求,Cursor 就能帮你生成专业级的代码。
同样地,超级智能体带来的能力,就像是 Office 版本的 Cursor。无论是制作文档、表格、PPT,还是生成网页或播客,它都可以根据你提出的需求快速进行生成,节省你大量的工作时间。
随着智能体成为 AI 产业界的核心关键词,它已过了秀概念的阶段,并开始了从技术展示向场景落地、从工具层向系统层的过渡。此次,Skywork 的推出不仅印证了中国 AI 企业在智能体领域具备了与国际对手抗衡乃至超越的实力,而且预示了接下来在该 AI 方向上「技术 + 场景 + 生态」全面交锋的趋势。
对于昆仑万维来说,这是一次具有战略意义的突破。在未来更大的应用前景铺开之前,它用一款全栈自研的超级智能体为自己在市场上赢得了先机。从上手体验来看,这款产品已经越过了实用化的门槛。
或许过不了多久,大量的工作就会由智能体接手,这何尝不是办公全家桶的一次进化?你只需要提出需求,投喂文件资料,确认好细节后,坐等 AI 交作业!
....
#微软副总裁X上「开课」,连更关于RL的一切
LLM从业者必读
别人都在用 X 发帖子,分享新鲜事物,微软副总裁 Nando de Freitas 却有自己的想法:他要在 X 上「开课」,发布一些关于人工智能教育的帖子。该系列会从 LLM 的强化学习开始,然后逐步讲解扩散、流匹配,以及看看这些技术接下来会如何发展。

话说回来,Freitas 有这个想法时还是 4 月 24 日,到今天为止,他已经更新了多篇帖子,每篇都干货满满。
由于涉及的内容需要费点脑细胞来思考,在更新了几篇后,Freitas 抱怨道:「随着数学知识的增多,自己 X 上的读者人数正在下降。」

或许,太硬核的东西,浏览量确实不会太高。
不过,遗憾归遗憾,这些帖子对于那些想学习 RL、从事大模型的人非常有帮助。
Freitas 也表示,他会不断更新内容,感兴趣的读者可以随时关注。
接下来,我们看看最近几篇帖子内容。
无监督学习、监督学习、强化学习终极定论尚未形成
监督学习对应于最基础的模仿形式:简单的行为复制。它通过最大似然估计,将世界状态(如文本问题)映射到行动(如文本答案)。我们将这种映射关系称为策略。监督学习需要高质量的专家数据,学生只是机械地模仿教师行为,因此需要教师本身必须足够优秀。教师仅示范操作方式,并不进行评分反馈。
另外,目前存在一些非常强大的监督学习方法,它们在通用性极强的专家指导下进行下一步预测(关联学习)和重构学习。这正是大语言模型预训练的核心原理,也是扩散模型、流匹配和自编码器在多模态感知与生成中运作的基础。从本质上看,预测下一个 bit 的过程实则是一种自由能(熵)最小化的过程,简而言之:在趋于无序的世界中创造有序。这正是细胞和生命运作的基本原理 —— 埃尔温・薛定谔和保罗・纳斯各自撰写的同名著作《生命是什么》对此有深入阐述。既然生命遵循这样的规律,那么智能系统采用类似机制运作也就不足为奇了。
另一方面,强化学习 (RL) 则侧重于选择性模仿(selective imitation),这对于优化特定任务的性能非常有效。RL 可以从智能体或其他智能体先前生成的大量次优经验数据中进行训练。RL 可以利用价值函数或其他工具(通过奖励学习)来识别和选择有用的信号。这种选择过程使模型能够利用大量廉价的次优数据进行学习,并最终超越最优秀的老师。
也就是说,在 RL 中,智能体可以识别哪些数据对学习有用,哪些数据应该忽略。
就像我们不会模仿父母的每一个行为,而是选择模仿部分,以及哪些部分应该忽略。
RL 的核心在于自我提高。智能体会生成数据,因此,他们可以从自身数据(成功和错误)以及来自其他智能体的混合数据中学习。
当我们使用奖励信号构建选择机制(例如,对数据进行排序并只挑选最佳的那一半)时,智能体就可以开始从自身数据中学习并自我提升,这种方式非常强大。
此外,智能体会利用其获得的知识来决定在环境中采取哪些行动,从而获得介入性因果知识。
在《An Invitation to Imitation 》一书中,CMU 教授 Drew Bagnell 探讨了一种名为 Dagger 的强化学习替代方案,其中智能体采取行动,老师来纠正学生。
对于智能体来说,从自身行动和自身经验中学习至关重要,这样它才能学会保持鲁棒性。
例如,如果智能体使用专业驾驶员提供的数据学习驾驶,有一天发现自己偏离了道路(这种情况即使是完美的老师也从未发生过),那么学生将不知所措。为了让学生学会回到道路上,它需要老师在那时提供建议。
一项重要的研究启示在于:生成模型对强化学习的作用与任何强化学习算法创新一样重要。这或许存在争议,但我认为过去十年间强化学习的进步,本质上是生成模型发展的结果。从算法演进来看(下文将详细展开),当前 AI 界普遍采用的基础算法思想 —— 如期望最大化算法(EM 算法)和策略梯度 —— 实际上已存在超过 50 年。真正的变革力量来自强化学习基础设施的规模扩张。
希望读者能通过本文认识到:关于无监督学习、监督学习与强化学习的终极定论尚未形成。虽然我质疑这种分类法的有效性,但在未来的教学实践中仍将沿用该框架以辅助知识传递。
分布式强化学习系统
智能体是一种能够感知环境、自主采取行动从而实现目标,并可能通过强化学习或教学来提升自身性能的实体。

智能体可以是一个多模态神经网络,它通过与环境的交互,为用户提供个性化目标。智能体观测得越多,就越容易为用户定制个性化的学习方案。
基于工业级大语言模型(LLM)的强化学习(RL),可能涉及数百万次并行交互,使用数十亿参数的模型,甚至需要调动整个数据中心 —— 成本极其高昂!
如何构建能在如此庞大尺度下高效运行的强化学习系统,绝非易事。
根据文章《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》、《acme: A library of reinforcement learning》,现代分布式强化学习系统可以分为两个部分:Actors 和 Learners。
每个 actor 通过使用称为策略的网络生成动作来与环境交互。actor 还从环境中收集奖励和观测结果。收集到的数据被添加到一个公共记忆中。
Learner 从记忆中采样数据并使用它来更新策略网络。更新网络后,需要将权重检查点发送给每个 actor。在设计此类系统时,测量每个操作的持续时间、每个通信链路的带宽等非常重要。这需要精确的工程设计以及全面的测量和消融。

在语言中,actors 是聊天机器人,环境是人。每次聊天的数据随后被发送到重放内存进行学习。通常,learner 可能比 actors 需要更多的存储空间和计算资源,因为 learner 需要跟踪梯度和大规模统计数据。
此外,了解 actors 的推理成本、通信成本和学习成本也至关重要。
另一方面,若数据采集速度不足,learner 可能需要重复利用历史经验来更新策略 —— 这正是 off-policy 场景的核心特征。此时必须解决一个关键问题:陈旧数据导致的偏差修正。在前面推文中的驾驶示例表明,过度依赖 off-policy 数据可能引发严重后果!
值得庆幸的是,研究者已提出多种解决方案:
重要性加权(Importance Weights):对历史数据赋予不同权重以修正分布偏差;
近端策略优化(PPO):通过剪裁机制控制策略更新幅度;
DeepSeek-R1 论文提出的加权方案:动态调整新旧数据贡献度。
当系统仅依赖大型历史经验库进行策略学习时,便进入离线强化学习(Off-line RL)或批量强化学习(Batch RL)范式。相较于监督学习,其优势在于继承了前文讨论的生成 - 选择机制;但相比在线强化学习,又因缺失环境实时交互而存在局限。
不过,离线强化学习在以下关键场景中具有不可替代价值:
- 高成本交互(如机器人物理训练);
- 高风险环境(如自动驾驶事故数据学习)。
用于后训练 LLM 的 RL
目前看来,RL 有多种形式。


其中一种是单步(one-step )RL 问题(上图左上角)。在这里,给定一个提示,模型会生成一个动作并得到一个评估。
这个动作可以是文本答案、CoT 推理序列、语音或任何其他行为信号,即任何 Token 序列。
评估通常是一个单一的结果奖励,例如答案是否正确。
与单步对应的是多步(multi-step)RL 问题,这种情况大多存在于与聊天机器人对话中,用户是环境,聊天机器人是智能体。
在用户不提供任何输入的情况下,智能体会思考下一步做什么,这是一个单步强化学习问题。这在我们的图中(左上角)清晰可见,因为这三个动作可以轻松地合并为一个动作,而不会破坏决策图的结构。
然而,规划整个对话以最终实现目标,在此期间用户和聊天智能体都会变化,这是一个多步强化学习问题(我们的图中,左下角)。
在这种设置下,智能体可以使用工具(例如 Web 浏览器、编译器等)来建模聊天机器人,从而收集信息。
当强化学习涉及多步时,可能每一步都会对结果有影响。就像当一个人获得奖励时,他并不知道是众多决策中的哪一个导致了奖励。这种现象人们称之为信用分配问题。
由于多步问题,强化学习通常是组合型的,而且维度非常高。在这些情况下,我们必须解决跨维度推理问题。
简而言之,强化学习真的很难,解的方差可能非常大。虽然研究人员发明了一系列概念来控制方差,但代价是引入了偏差,其中包括价值函数。这些概念在多步决策问题中很有用,但对于单步强化学习来说并非总是必需的。虽然其中一些想法在电脑游戏中很有效,但在 LLM 中却行不通。
在控制领域,普遍存在这些问题,如 T 步决策、二次奖励函数。这些被称为线性二次高斯控制器或调节器,构成了最普遍的控制类型之一 —— 模型预测控制 (MPC) 的基础。
然而,盲目地将为电脑游戏或控制开发的强化学习方法的理论和软件引入语言模型领域是危险的。
为了实现工具使用和多步辅助,我们需要为 LLM 提供多步强化学习。然而,要实现像 DeepSeek-R1 或测试时强化学习 TTRL 这样的方法,需要先解决单步强化学习问题,因为这个问题稍微简单一些。
所有 RL 智能体都能够自我学习和自我改进。如果设计得当,它们可以构建质量不断提升的数据集,从而生成更好的策略。RL 智能体的这一特性对于性能和安全性都至关重要。
可能存在一些更难的强化学习案例。比如有时决策范围是未知的或无限的,时间步长可能是连续的,也可能是中断驱动的,动作和观测可以是离散的、也可以是连续的,这些都增加了推理的复杂性。
出于教学原因,明天我们将首先介绍最简单的案例:单步强化学习。
单步强化学习与策略梯度
包括 DeepSeek-R1 在内的许多团队,当他们声称在进行 RL 时,会最大化单步目标函数,如下所示:

这些数学符号代表了以下概念:

也就是说,我们正在针对所有的数据字符串 (a,o) 对 LLM 进行微调。在处理文本时,通常使用积分符号来表示非常庞大的离散求和。
因此,如果我们有一个包含 N 对观测值和动作 (o, a) 的数据集,那么在实际操作中,我们会按如下方式评估目标函数:

环境(用户)也会为我们提供观测值(提示或指令 o)。所以不需要知道分布 P (o)。由于不知道最优动作(大语言模型生成的内容,也就是动作 a),将对这些动作进行积分。这是在概率中处理未知量的标准方法。我们对所有可能的值按照出现的概率进行加权求和。在这种情况下,动作的概率就是大语言模型所生成的结果。大语言模型是一个概率模型。
这种在对大语言模型的权重进行最大化的同时对其输出进行求和的方法,被称为最大期望效用,这也是博弈论中理性主体所采取的做法。通过最大化期望效用(奖励的另一种说法),人们可以收敛到纳什均衡。在统计学中,人们把这个过程称为边缘化,而当它还涉及到对某个量进行最大化时,它就被称为实验设计。
总之,在单步强化学习中,我们通过调整大语言模型的策略来最大化期望回报 R,也就是说,对于目前大多数的大语言模型而言(见上一篇文章),在单次结果中进行奖励 R=r (a,o)。
策略梯度:就是人们所说的 on policy RL 或 Reinforce 算法。这种方法被称为 on-policy,是因为生成样本(动作)的策略(大语言模型)与正在被学习的策略是同一个。
当生成样本的成本低于学习成本时,这种方法是有意义的。也就是说,当 learner 可以按需轻松获取新样本时适用。
但对于成本高昂的游戏模拟引擎而言并非如此,在这类场景中,必须引入缓冲区和回放记忆来缓存数据。随着数据变得陈旧,就需要使用 off-policy 方法。
那如何计算单步损失的梯度,答案是只需沿着梯度方向更新参数即可。
从理论上讲,策略梯度可以使用微积分按如下方式得到它:

策略梯度常用技巧
前文重点介绍了策略梯度算法,不过大家还会使用一些技巧来提高性能。
现在,我们从一个常用的技巧开始,即从奖励中减去奖励的均值。得到的表达式被称为优势(advantage)。这项技术本身被称为基线减法(baseline subtraction)。
在策略梯度中,如果我们从奖励 r 中减去其均值,然后用下面的奖励来替代原来的奖励:

这样做并没有改变最大值的位置,但降低了方差。
此外,当奖励是二元的,而我们又需要一个更连续、渐进的反馈信号时,这种方法格外有用。
下面是证明过程:

KL 散度
KL 散度是一种用于衡量两个分布之间「距离」的方法,从数学角度来说,KL 散度定义如下:

如果在强化学习的损失函数中加入 KL 散度项,本质上是在鼓励后训练(post-training)过程中学习到的 LLM 策略保持接近监督微调(SFT)阶段的策略。
如果我们根据最新的策略 p(a|o) 采样 N 个动作,我们可以再次使用蒙特卡罗方法来近似计算 KL 散度:

此外,John Schulman 有一篇很棒的关于如何高效近似 KL 散度的博客。他提出了以下替代方法:

采样、PPO 以及 GRPO 的重要性
在强化学习系统中,有时会有多个 actors 来收集数据并将数据添加到记忆系统中。然后,learner 从这个记忆中提取样本进行学习。
在这种异步设置中,有些样本会变得过时。生成样本的机制(actors)与更新参数的机制(learner)不同,因此这种方法被称为 off-policy。
重要性采样(Importance Sampling, IS)提供了一种校正 off-policy 样本偏差的解决方案,其核心操作如下:
我们通过在单步目标函数的被积项中乘以并除以旧策略 π_old (a|o) 实现修正。系统将基于该旧策略采取动作,但实际学习的却是新策略 —— 这正是 off-policy 学习的本质特征。数学表达上,通过引入行为策略进行乘除变换后,单步强化学习目标函数转化为:

如果我们观察到一个提示 o^i ,并从行为策略中采样出一个动作 a^i,可以再次用以下蒙特卡罗近似来替代积分,这种近似被称为 IS 估计:

分布的比率被称为重要性权重:

这个权重可能会增大并导致不稳定性,尤其是因为我们计算这个比率所涉及的所有字符串的空间是非常高维的。
PPO:为了防范高方差和不稳定性,我们必须巧妙地截断(裁剪)重要性权重。让我们再次来考虑一下我们的 off-policy 目标:

近端策略优化(PPO)修改了这个目标函数,对那些使 w (theta) 偏离 1 的策略变化进行惩罚,具体如下:

PPO 的内容远不止这些,所以我鼓励大家都去读一读这篇有影响力的论文《Proximal Policy Optimization Algorithms》。
DeepSeek-R1 将裁剪后的重要性采样、基线减法以及与参考策略的 KL(相对熵)接近度相结合,以此来训练其推理模型。(PPO 也做了所有这些事情,但方式略有不同。)
现在我们已经介绍了 DeepSeek 强化学习算法(GRPO)的所有要素,所以接下来就只是把它们整合起来的问题了。
当然,真正的挑战在于解决实现过程中基础设施和数据方面的问题。

为了得到第一个蒙特卡罗估计值,我们使用来自行为策略 pi_old 的样本 a^i ,但是如果我们想要保持估计的无偏性,对于第二项(即 KL 散度项)的蒙特卡罗估计应该使用来自 pi_theta 的样本 a^i ,而不是来自 pi_old 的样本。
正如在之前的文章中所提到的,我们已经从奖励中减去了平均基线值:

但与 DeepSeek-R1 不同的是,我们没有除以标准差。这一点值得通过实证来检验。
注意:在这个版本中,我们针对每个观测值采样一个动作。也可以针对每个观测值采样多个动作来减少方差。DeepSeek-R1 基本上就是这么做的,其梯度更新包含了针对单个问题的多个动作样本。这种技术在随机近似中被称为公共随机数。
如果你对 PPO 和 GRPO 的这些公式感到熟悉了,那么你现在几乎已经了解了如今所有公司在 LLM 中使用的强化学习(RL)所需的全部理论知识。
接下来,Freitas 想从单步强化学习拓展到多步强化学习,从而进行更深入的研究。感兴趣的小伙伴,可以随时关注 Freitas 动态。
参考链接
https://x.com/NandoDF/status/1919728246821634205
https://x.com/NandoDF/status/1918324866979184874
https://x.com/NandoDF/status/1917865356829618645
https://x.com/NandoDF/status/1917575545673417069
https://x.com/NandoDF/status/1917270302666678614
https://x.com/NandoDF/status/1916835195992277281
https://x.com/NandoDF/status/1915548697548464359
https://x.com/NandoDF/status/1915351835105169534
....
#Scaling Under-Resourced TTS
高感情语音技术:逻辑智能小语种TTS破局之道
该工作由北京深度逻辑智能科技有限公司×宁波东方理工EIT-NLP实验室联合完成。
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。
然而,这一繁荣几乎局限于英语、普通话等资源充沛的大语种;全球一千多种小语种由于语料稀缺、文字无空格或多音调等复杂语言学特性,在数据收集、文本前端处理和声学建模上都面临巨大挑战,导致高质量 TTS 迟迟无法落地。破解「小语种困境」既是学术前沿课题,也是实现数字包容与多语文化传播的关键。
面对这一挑战,逻辑智能团队提出了一种针对低资源语言 TTS 的解决方案并应用于泰语 TTS 合成,该工作已经被 ACL 2025 Industry track 正式接收!
- 论文标题:Scaling Under-Resourced TTS: A Data-Optimized Framework with Advanced Acoustic Modeling for Thai
- 论文地址:https://arxiv.org/abs/2504.07858
- 效果试听:https://luoji.cn/static/thai/demo.html
这项工作提出了一种数据优化驱动的声学建模框架的创新方案,通过从语音、文本、音素、语法等多个维度构建系统化的泰语数据集,并结合先进的声学建模技术,成功实现了在有限资源下的高质量 TTS 合成效果。
此外,该框架还具备 zero-shot 声音克隆的能力,展示了优异的跨场景适用性,为行业提供了一种在数据稀少环境下高效构建小语种 TTS 系统的有效范式,对推动全球小语种 TTS 技术的落地与普及具有重要的启示和借鉴意义。
数据优化驱动的声学建模框架方案
该工作遵循数据驱动模型能力的整体思路:
- 首先从源头切入,系统化采集并标注跨领域语音、文本与语言学信息,构建覆盖广、颗粒度细的多维泰语语料库;
- 随后通过 LLM 增强的停顿预测、词切分与混合式 G2P,将原始文本稳健转换为结构化的「音素-声调」序列;
- 最后在此精炼输入之上,引入声调感知的 Phoneme-Tone BERT 与多源特征驱动的 GAN 解码器,实现高保真、低延迟的语音合成,并支持零样本声音克隆。
整套框架以数据质量为核心抓手、以模块化设计保障可扩展性,为解决小语种 TTS「数据稀缺 + 语言复杂」双重瓶颈提供了一条可复制、可落地的工程化路径。

泰语专项数据集构建
该工作构建了一套专为低资源泰语 TTS 设计的多维数据集,涵盖语音、文本和注释三大类:
- 语音数据——500 小时来自新闻、社媒、播客等多领域语料,外加 40 小时金融、医疗、教育、法律等垂直领域语料,兼顾通用合成与专业术语发音;
- 文本数据——100 万句句子语料用于训练 Phoneme-Tone BERT 提升上下文韵律建模,10 万词词表用于训练分词器,解决泰语无空格书写难题;
- 注释数据——1.5 万句停顿标注确保精准断句,4 万词音素-声调标注强化 G2P 与五声调建模。该数据集既保证了规模,又注重多域覆盖和细粒度语言监督,为在资源稀缺环境下实现工业级泰语 TTS 与零样本声音克隆奠定了坚实基础。

先进的预处理流程
该工作设计了一套强大的预处理流程。预处理流水线最大的亮点在于「三步一体、逐层解耦」地化解泰语文本的无标点、无空格、声调复杂三重难题:
- 首先通过 SFT 微调的 Typhoon2 LLM,对 1.5 万句人工标注语料学习停顿规律,在原始文本中智能插入停顿标签以更好地建模口语韵律;
- 随后在扩充至 10 万词的分词词典支撑下,改进版 pythainlp Tokenizer 将连续书写的泰文字流精准切分,为领域专有词提供稳健支持;
- 最后利用 4 万词的音素-声调注释库,结合规则+Transformer 混合式 G2P,把每个词映射成带五声调标记的 IPA 音素序列。
该流水线不仅输出结构化的「音素-声调」序列,大幅降低后续声学模型学习难度,也为其他低资源音调语言提供了可复用的文本前端范式。

卓越的 TTS 模型架构
该工作的 TTS 模型集成了「多源特征 × 声调感知 × 零样本克隆」的组合设计:
- 首先利用多语种预训练模型提取时长、音高、能量等强鲁棒特征,并以风格编码器压缩说话人/情感信息,为后续零样本克隆奠定基础;
- 其次,通过 Phoneme-Tone BERT 在音素序列中显式融入五声调,精准捕捉泰语语义-韵律关联;
- 最后以 GAN 解码器直接从音素与预测特征合成波形,联合时域、频域与感知损失实现高保真、低延迟合成。
整体采取「先独立训练预测器,再与解码器联合微调」的策略,兼顾稳定性与音质,使模型达到 SOTA 表现并支持零样本声音克隆。

实验效果
- 预处理链路有效性:消融实验表明,停顿预测、分词优化和 G2P 优化缺一不可;当分别移除这三项时,系统的 WER 从 6.3% 依次升至 6.5%、10.2% 与 22.5%,自然度评分 NMOS 从 4.4 下降到 3.8、3.9 与 3.0,尤其 G2P 的影响最大,证明精确声调与音素映射是泰语 TTS 的质量瓶颈。
- 通用与行业场景综合表现:在公开基准 TSync2 和金融、医疗、教育、法律四大真实业务脚本上,模型始终保持最低 WER 与最高 NMOS,不仅超越开源系统,也优于 Google TTS、Microsoft TTS 等商业方案;特别是在专业术语发音与语速控制上,用户反馈显示本系统误读率更低、韵律更自然,验证了该框架对多场景的强鲁棒性与可落地性。
- 零样本声音克隆能力:在仅提供几秒参考音的条件下,模型即可生成目标说话人高保真语音,取得 SIM 0.91 和 SMOS 4.5,显著超过 OpenVoice 的 0.85 与 4.0;嵌入可视化进一步展示了对说话人 timbre 的准确聚类,表明「声调感知 + 多源特征」设计能够在低资源环境下实现工业级的声音克隆体验。




....
.
#Veo3
实测惊艳全球的!音画同步无敌,贵是有原因的
好莱坞要完蛋了。
「你大爷永远是你大爷」这句话的含金量还在上升。
上周谷歌举办了一场开发者大会,祭出一堆好东西,其中最让人震撼的就是 Veo3。
该模型具备强大的文本和图像转视频能力,并首次实现了视频与音频的同步生成。
换句话说,视频画面和环境音效、背景音乐、人物对白终于可以一锅出了,而且口型还能对得上。
,时长00:08
不少网友心甘情愿为其氪金,并在社交平台放出了诸多 Veo3 生成的视频,我看完后的第一反应就是刘晓艳「附体」:
没演技的流量明星们,回家吧。
咱不说别的,当初看《演员请就位》第一期的时候,就被这群选手们的烂演技炸得脑瓜子嗡嗡的。
杨子为了演出西门庆的放荡,不是对着于佩尔夸赞「龙睛凤眼,唇红齿白」,就是追着章子怡「死锤烂打」:

刘梓晨版的九妖之王相柳,来一个导师他就「死」一次,演个倒地都一股子喜感:

再对比下 Veo3 生成的「演技」。一位美国士兵在战火纷飞的战场上踉跄行走,表情木然,双眼空洞,突然他停下脚步,在泥泞中跪下,低声呢喃:「为什么我还活着?」
瞅瞅这细微的小表情,这流畅的肢体动作,这充满绝望的台词,你觉得流量明星们赶得上吗?
,时长00:08
Prompt:Handheld medium shot tracking an American soldier walking through a ruined Normandy battlefield at dusk. Heavy rain falls. The camera moves backward, facing him directly. His muddy face is blank, eyes hollow. Explosions flash behind him. He stops, kneels in the mud, and whispers: ‘Why am I still here?’ A slow, somber orchestral score swells.
这个 Veo3 生成的车展视频,也逼真的让人分不清现实还是虚拟。
,时长01:11
还有下面这个 ASMR 视频,也是出自 Veo3 之手。整个过程该博主就用了一句提示词:asmr creator typing on a noisy keyboard and then looking up and blowing into the microphone as she talks。
,时长00:08
更离谱的是,X 网友 Hashem Al-Ghaili 拿 Veo3 探讨了一个非常魔幻的哲学问题:如果 AI 生成的角色不相信自己是 AI 生成的,会发生什么?
Veo 3 生成的视频在视觉和音频上都达到了极高的逼真度,角色动作、表情、口型同步以及环境音效足够以假乱真。
,时长01:29
虽然我们不是尊贵的 Ultra 会员,但前段时间谷歌突然卡 bug,普通用户只需登录 Google 个人账户,且 IP 为美国,就可以免费领取 Google One 会员到 2026 年底,我们正好薅到了羊毛。今天一试发现有了这个会员也可以在 Gemini 官网和 Flow 中使用 Veo3。
接下来,我们就亲自实测一波,看看它是否真的有两把刷子。(温馨提示:以下实测均一次生成,无抽卡。)
Gemini:https://gemini.google.com/
Flow:https://labs.google/flow/about
一手实测
Gemini 官网已更新换代,下方聊天框中除了 Deep Research 和 Canvas 功能外,又新增了 Video 按钮,我们只需输入提示词即可生成 Veo3 视频。

值得注意的是,谷歌官网显示,Google AI Pro 用户可使用主要的 Flow 功能和每月 100 次生成,而 Google AI Ultra 用户则获得最高的使用限制以及 Veo 3 的早期访问权限。

刚开始,我们本想用 Veo3 生成「泰勒・斯威夫特唱 rap」的视频,但尝试几次它总是「罢工」。

扒了下 Gemini 的政策指南,发现它拒绝生成会在现实世界中造成伤害和冒犯的内容,例如儿童安全威胁、危险活动、暴力血腥、露骨色情内容或者拿现实中的名人整活。
那我们就先来个脱口秀。
提示词:一个脱口秀演员在台上说了一个笑话,内容是「别整天说自己是单身狗,狗在你这个年纪,早 die 了」,观众爆笑。
,时长00:08
视频中,脱口秀演员讲笑话的节奏感掌握得很好,观众的反应也很真实、自然,这不比春晚的尬相声好多了?
说到做假新闻,Veo3 更是一绝。
提示词:A news anchor with a serious tone reporting an obviously fake news story about aliens landing in New York City, complete with stock footage overlays, dramatic music, and animated graphics behind them — newsroom background, 16:9 aspect ratio.
,时长00:08
AI 主播坐在演播室,操着一口纯正的美式播音腔一本正经地胡说八道,就是眼神稍微凶狠了些。
Veo3 多少有点刻板印象,比如让它生成一个唱 rap 的歌手,它大概率输出的是黑人。
提示词:A male singer in a cozy recording studio singing into a microphone with headphones on, surrounded by acoustic panels and warm lighting — close-up on emotional facial expressions, intimate mood.
,时长00:08
但不管怎样,这视频生成效果确实没得说,无论是歌手的深情演唱,还是歌曲旋律,都真实得没边了。
最让编辑部看傻了的,是这个 Veo3 生成的游戏直播视频。
提示词:Streamer-style Minecraft gameplay footage with a facecam overlay in the corner, showing a male gamer reacting excitedly while battling mobs in a cave — Twitch stream layout, live chat visible, dynamic lighting.
,时长00:08
角落里的主播,占据屏幕大部分的《我的世界》动态游戏画面,还有观众聊天框,简直就是 Twitch 直播标配。
尤其是游戏主播的反应,瞪大双眼,嘴里喊着「Oh my god」,太真实了!不过唯一的瑕疵就是观众实时聊天框静止不动。
我们再回到这次 Veo 3 强调的「音画同步」上来,让它生成一段简单的对白。
尽管字幕慢了一拍,但 Veo3 这口型对得太丝滑了。
,时长00:08
翻车合集
Veo3 的生成效果确实惊艳,但也有翻车的时候。
比如曾让一众视频生成模型「闹笑话」的体操类视频,Veo3 还是搞不定。
提示词:一位体操运动员在明亮的体操房内,身着鲜艳的体操服,在高低杠上优雅地旋转、跳跃、翻腾,动作行云流水,镜头从不同角度捕捉她的精彩表现,背景音乐是激昂的交响乐,旁白详细讲解着她的动作技巧和训练历程。

这个视频乍一看挺像那么回事,但你一帧帧拎出来瞅,好多邪门的细节:在单杠上旋转时要骨折的胳膊、原地跳跃时 360 度旋转的手臂……

提示词:体操馆内,一位气质儒雅的女体操运动员,身着浅粉色体操服,正在高低杠上比赛。她稳稳地抓住高杠,开始一系列复杂的动作,如后摆上、换杠、空翻抓杠等,动作衔接行云流水,展现出高超的技巧和优雅的姿态。镜头切换多样,包括正面、侧面和俯视角度,记录下她在高低杠上的每一个优美弧度,同时捕捉到她在完成动作后的轻松微笑和对观众的挥手致意。
眼尖的小伙伴应该发现了视频的诡异之处,在旋转过程中,运动员的的身体从「正面」丝滑变成了「背面」,不禁幻视之前的波士顿动力 Atlas 翻跟头。

提示词:一位身穿红色 23 号球衣的高大篮球运动员,肌肉线条分明,正站在篮球场三分线外,阳光从场馆高窗洒下,照亮他专注的面庞和紧握篮球的双手。他深吸一口气,做出标准的投篮姿势,双脚微微分开,膝盖微屈,右手托球,左手轻扶球侧,手腕轻抖,将球高高抛向空中,篮球在空中划出一道优美的弧线,最终投入篮筐,镜头跟随篮球的轨迹,捕捉篮筐、篮板和观众席的反应,背景是热闹的篮球馆,观众们或站或坐,欢呼雀跃。

这个视频画面错乱到已无力吐槽,擦着自家篮筐往对手篮筐里投篮,这操作乔丹看了也得沉默,看来 AI 也不太懂篮球。

提示词:在一个宁静的海底峡谷中,阳光温柔地洒下。一群美人鱼正与她们的海洋朋友们亲密互动。一个红发美人鱼轻轻抚摸着一只海龟布满纹路的脖颈,另一位金发美人鱼则与一群顽皮的海豚分享着发光的海藻。她们的歌声在水中回荡,充满了爱与和谐,吸引了各种各样的海洋生物前来倾听,包括优雅的海马、好奇的章鱼和色彩斑斓的热带鱼。她们的脸上洋溢着纯真快乐的笑容,形成一幅温馨动人的画面。

这画面,这质感,是不是很像小时候的劣质拼贴广告?
另外,谷歌官方还贴心地整理了一份提示词指南,帮助大家更好生成自己想要的画面。
https://cloud.google.com/vertex-ai/generative-ai/docs/video/video-gen-prompt-guide?hl=zh-cn
以下是基于这份文档整理的实用提示词编写结构与优化方法:
1. 核心场景描述
首先明确视频的主要场景和主题,清晰传达视频的核心内容。例如:
「一个现代化的城市咖啡馆内部,阳光透过大窗户照射进来,照亮了木质桌椅和绿色植物。」
2. 视觉细节描述
补充颜色、材质、光线、氛围等视觉细节。例如:
「咖啡馆装饰着工业风格的金属吊灯,墙上挂有抽象画作。两位顾客坐在窗边的高脚凳上,面前摆放着冒着热气的咖啡杯,杯中拉花清晰可见。」
3. 运动和镜头指令
描述镜头运动、拍摄角度和视角变化。例如:
「镜头从咖啡馆门口缓慢推进,然后平滑地向右平移,展示整个空间,最后停留在窗边的顾客身上,进行特写拍摄。」
4. 音频和音效描述
Veo 3 支持音频生成,可在提示词中指定背景音乐、环境音、对话等。例如:
「背景中可以听到轻柔的爵士乐,咖啡机的嗡嗡声,以及顾客低声交谈的声音。女顾客说道:" 这是我喝过的最好的拿铁。」
5. 风格与技术参数
补充期望的色调、风格、帧率、分辨率等。例如:
「整体氛围温暖而放松,色调以暖棕色和淡绿色为主,拍摄风格类似电影《爱在黎明破晓前》的质感和光线处理。以电影 24fps、浅景深拍摄,确保高清画质,保持自然的色彩饱和度。」
[ 上下滑动查看更多 ]
理论结束,我们来实践一下。根据上述提示词结构,让 Veo3 复刻《肖申克的救赎》中的名场面!

提示词:在一片阴郁的夜幕下,一条通向自由的下水道出口位于树林边缘的土壤中,泥泞湿滑。安迪・杜佛兰(着囚服,浑身污泥)从出口中奋力爬出,全身沾满污水与污泥。他踉跄爬起,走到空旷草地中央,天空忽然下起滂沱大雨。闪电划过夜空,在雨中泛出银白的光。 安迪仰望天空,张开双臂,头仰向天,任雨水冲刷全身,脸上显露出一种崩溃后的解脱与重生的神情。 镜头从安迪背后缓慢升起,采用低机位仰拍逐渐转为鸟瞰俯拍,随着雨水从空中泼洒而下,镜头旋转轻微环绕他,营造出史诗感和敬畏感。地面泥泞中留下的是他艰难爬行的痕迹。 背景音中雷声轰鸣,雨声密集而真实,伴随着低沉的管弦乐情绪逐渐上扬,烘托出破茧成蝶般的胜利与自由感。 整个画面以冷蓝色调为主,突出夜雨肃穆庄严的氛围。光影处理上以闪电和月光微弱照亮安迪湿漉漉的身影和表情,手臂上的水珠闪动微光。 画面风格类似电影《肖申克的救赎》原片,注重写实布光与戏剧化构图,帧率 24fps,使用电影级浅景深虚化周围景物,强调人物的孤独与灵魂的觉醒。 特写镜头捕捉雨水从他脸颊缓缓滑落,他的双眼微闭,嘴角略微颤动,传递出不可言说的复杂情感。
对比原版,质量还是有待提升,但内容相对完整。
测试过程中还发现,英文提示词会比中文提示词效果好一点。

总体来说,Veo3 的音画同步非常惊艳,在生成场景单一、动作简单的画面时效果很真实,但涉及到多种场景转换和复杂的交互时,就略显乏力了。
从 GPT-4o、即梦那些以假乱真的图像,到可灵、Veo 3 让人惊叹的视频效果,科技的进步让人目不暇接,甚至有点喘不过气。
面对这一切,简单地唱衰或叫好没有意义,我们更期待的是, 这些强大的技术能够实实在在地为我们每个人的生活增添一些便利,或者解决一些我们真正头疼的问题。 毕竟,科技的真谛不是让人类跪着喊「牛 X」,而是让我们能躺着喊「舒服了」。
参考链接:
https://x.com/HashemGhaili/status/1925616536791760987
https://x.com/MayorKingAI/status/1926046987884908848
https://x.com/laszlogaal_/status/1925094336200573225
https://x.com/venturetwins/status/1925046014689608146
....
#Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
与Gemini Diffusion共振!首个扩散式「发散思维链」来了
近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。不同于始终单向推理、线性生成的传统思维链(CoT),扩散式「发散思维链」允许模型以任意顺序非线性生成,且在生成过程中无需严格遵从语法结构和可读性要求,能够鼓励模型以更加发散、创造性的方法开展推理。
扩散式「发散思维链」目前已成功应用于两种具有代表性的扩散语言模型中。在连续时间扩散语言模型中,该方法可以直接优化由模型输出的得分函数所确定的策略分布;而在离散时间扩散语言模型中,团队将预测不同掩码 Token 的顺序当作模型决策的一部分,并基于 Plackett-Luce 模型设计去掩码策略。据此,团队成功训练有序掩码生成扩散语言模型(Large Language Diffusion with Ordered Unmasking, LLaDOU)。实验表明,仅用公开数据集和 16 张 H800,经扩散式「发散思维链」增强后的模型即可在数学推理和代码生成任务上超越现有扩散语言模型。
扩散式「发散思维链」对基础大模型的训练与推理给出了重要启示:传统的自回归思维链语言模型通过线性预测下一个 token 生成答案并非唯一的选择范式。团队的研究揭示了通过优化 token 生成的顺序进行非线性语言生成是发散式思维的重要特点,对于在生成过程中逐步构建从早期概念要素的形成、到最终连接成具有完整想法和语法结构的回答起到了关键作用。
相关研究成果已于 5 月 15 日公开。团队注意在此后谷歌发布了 Gemini Diffusion 语言模型,因而期待强化「发散思维链」可以应用到更多的扩散语言模型上成为标准训练过程的一部分。
论文标题:Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
arXiv 地址:https://arxiv.org/abs/2505.10446
GitHub 地址:https://github.com/maple-research-lab/LLaDOU
背景
近期,大型语言模型的推理能力引发了学术界的高度关注。一般而言,「推理」通常是指模型在生成最终应答前所经历的系统性思考过程。当前主流的大型语言模型普遍采用分步拆解问题的方法,构建一种具有因果顺序的线性思维链条,形成所谓的「思维链」推理范式。
值得注意的是,人类认知过程中的思维构建机制与此存在本质差异。在构思阶段,人类思维往往呈现非线性的发散特征,能够突破既有语言框架的约束,通过非线性、跳跃性的方式自发生成概念原型、词汇单元及初始设想。随着认知加工的持续深化,这些离散的思维片段经历系统性整合与结构化重组,最终形成逻辑连贯的完整表达体系。认知科学领域将此类思维模式定义为「发散思维」(Lateral Thinking),显著区别于传统思维链所采用的线性推理模式。
为模拟这一思考过程,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式 「发散思维链」这一概念。如图所示,模型的思考过程从一段不包含任何信息的掩码序列开始,在思考过程中,模型会逐步生成推理所需要的关键信息,将掩码转换为具有实际语义内涵的文字内容,如数字和计算过程。最终,在整个扩散去噪流程结束后,模型将生成具有连贯语义内涵且包含正确答案的文字回复。通过仅基于结果的强化学习训练,团队鼓励模型探索多样化的、创造性的和非线性的思维路径,最终得出正确的答案。

扩散式「发散思维链」
为了建模真实文本数据的分布,扩散语言模型构建了一个从 t=0 到 t=T 的离散扩散过程,描述了在 t=0 处的一个未知的真实数据分布 p_data,是如何逐步演化为 t=T 时的一个已知的先验分布 p_prior。而生成一段文本则通过反转这一扩散过程来实现:首先从先验分布 p_prior 中采样 x_0,然后在一系列去噪时间 t_0:N 迭代去噪。在每一个去噪步骤 n 中,模型 θ 会估计时间 t_n 对应的扩散分布

,并从中采样一个中间结果 x_n。随着 n 的增加,扩散时间 t_n 逐渐减小,直到 t_N=0 时得到最终生成结果 x_N。

在这一过程中,为了得到最终的输出 x_N,模型天然需要生成一系列中间结果 x_1:N-1。这一过程与「思维链」(Chain-of-Thought, CoT)技术相似。然而,与 CoT 采用线性因果推理不同,扩散过程中的模型能够在思考过程中自由地生成任何有助于达到正确答案的中间内容,更符合发散思维的概念 —— 即通过间接、具有探索性的方法解决问题。正因如此,团队将由去噪过程中所有的中间结果组成的序列称为扩散式「发散思维链」(Diffusion Chain of Lateral Thoughts, DCoLT),并通过强化学习算法优化模型的这些中间扩散「推理」过程。
团队采用基于最终结果监督的强化学习方法:如果一条思维链推导出的最终答案 x_N 正确,就会予以激励。具体而言,团队生成整个思维链 x_1:N 的过程视为一个多步动作序列进行优化。在第 n 步时,扩散模型会在所有可能的结果上定义一个输出分布

,即是模型用于采样 x_n 的策略分布。奖励信号 r 可以简单地通过验证最终生成结果的正确性得到。值得注意的是,团队不会对推理过程的中间步骤设置任何显式监督,从而鼓励模型探索多样化、非线性的推理策略。
在下图中,团队以 GRPO 为例详细阐述了算法训练框架。类似地,其他强化学习算法也可应用于所提出的框架中。

连续时间扩散语言模型:DCoLT 强化的 SEDD
首先团队考虑以 SEDD 为代表的连续时间扩散语言模型。这类模型通过如下线性常微分方程描述该演化过程。

其中,

表示扩散过程中的瞬时转移率矩阵,不妨首先考虑单个 token 的简单情形

。为了生成样本,这一扩散过程存在一个对应的反向过程,其中包括一个反向转移率矩阵

。

通过欧拉法数值求解,可以计算每一步的转移概率,进而得到用于多步生成的迭代公式。此处团队将

简化为 x_n 以避免标记过于冗余。

在经典的离散扩散模型 SEDD 模型中,SEDD 模型通过预测

,来表示各个 token 的转移概率。因此,团队可以将公式中的

替换为模型估计的

,从而确定转移概率。
扩展到整个序列时,其转移概率可以看作所有 token 转移概率的累乘,即可通过以下公式计算 DCoLT 生成过程中每一步动作对应的采样概率。

离散时间扩散语言模型:DCoLT 强化的 LLaDA
一些扩散语言模型直接在离散的时间步上执行多步生成过程。对于这些模型,需要为每个离散步骤定义其输出策略分布。在这其中,考虑最为常见的掩码扩散语言模型。
以 LLaDA 模型为例:生成过程从一个完全掩码序列开始,逐步去除掩码直至生成最终文本。在每个生成步骤中,模型接收一个带有掩码的序列作为输入,将其中部分掩码预测为有实际含义的文本内容。在整个生成过程进行时,掩码的数量会逐渐减少,直到模型最终输出完整的生成序列。
据此,团队基于 LLaDA 设计了一种有序掩码生成扩散语言模型,LLaDOU。他们将模型在每一步的动作拆解为两部分:首先,确定本步中需要去除的掩码集合,记为

;其次,为这一部分中的每一个掩码预测新的值,以获得新的序列

。
要确定为哪些掩码 token 执行去掩码操作,我们可以用一个得分函数对所有掩码 token 排序。为此,团队设计了一个「去掩码策略模块」(Unmask Policy Module,UPM),该模块在当前扩散步骤 n 下,为第 i 个掩码字符预测一个得分值

。基于这些得分,团队采用 Plackett–Luce 模型定义了一个策略,从中采样一个由 K 个掩码字符的列表

。
具体而言,团队首先根据预测的得分构建一个多项分布,随后以无放回的方式依次采样出 K 个掩码 token,这样,得分较高的 token 有更大的可能性被首先取出,从而使序列中的掩码得分值更倾向满足非递增排序关系,即:

。
令

表示第 n 步之后仍然保持掩码的 token 集合,即满足:

。那么,采样得到某个特定的去掩码列表

的概率可由下式计算所得。

具体而言,在第 n 步去噪过程中,UPM 会取 LLaDA 中最后一层的输出特征作为模块输入,为每一个 token i 预测一个得分

。UPM 仅包含一层 transformer,因此对模型计算量影响很小。此外,考虑到当前的去噪步数 n 和每个 token 的掩码状态同样也对去掩码策略十分重要,团队将这些信息作为自适应归一化层编码在 UPM 模块中。为简单起见,团队将经 DCoLT 训练后,包含 UPM 的整个扩散语言模型记为 LLaDOU(LLaDA with Ordered Unmasking)。整体模型结构如下图所示:

而去掩码的 token 集合

一经确定,模型就会根据词汇表上的输出分布预测它们相应的 token 值,此即第二阶段动作。在给定

以及

的情况下,生成的

概率为:

综上,从

到

的完整策略由这两部分乘积共同决定:

从以上推导可以看出,某种意义上,LLaDOU 模型和基于 next token 预测的自回归(auto-regressive) 语言模型并没有本质区别。两者都是在给定了 prompt 和 context 作为前缀后,去预测后续的 token。区别仅在于,自回归模型要求预测的是紧邻的下一个 token;而 LLaDOU 模型允许通过一个 UPM 模块,从所有可能的后续位置,选择一个或多个 token 进行预测。后者相对于前者更加灵活,可以根据当前生成的结果,打破语言自左到右的自然顺序,在中间步骤,跳跃式地选择合适的 token 进行生成。当然,最终生成的完整结果,仍然满足各种语言语法结构的要求。
在同一时期,业界也推出了一些其他面向 diffusion model 的强化训练方法,如 d1 和 MMaDA。这些方法首先采样得到生成结果以及对应的奖励值,然后对生成结果或问题部分再次进行随机掩码处理,以估算每个 token 的生成概率,用于强化训练。这种情况下,实际采样生成的中间过程和计算概率时的再掩码过程并不一致,可能导致所强化的再掩码采样过程并不是模型真正的采样过程。不同于这些方法,团队直接基于采样过程中每一步所选中的 unmask token 计算概率,据此进行强化训练,保持训练和采样过程一致。同时,更重要的是,团队注意到每步如何选择要 unmask 的 token 也是扩散语言模型采样的关键步骤。基于此,本方法将 unmask token 生成的顺序也作为强化学习所优化策略的一部分,进一步提升扩散语言模型采样的性能。
实验结果
团队基于两个具有代表性的扩散语言模型 ——SEDD 和 LLaDA 开展实验进行验证。
首先,团队基于 SEDD 模型,在数独解题和数学推理两个任务上与其他方法展开了公平对比。DCoLT 取得了比 CoT 和 DoT 更好的实验结果。比如在 GSM8K-Aug 数据集上,同样是使用 SEDD 模型,DCoLT 取得了 57.0% 准确率,超越了 DoT,即使后者使用的训练数据中带有逐步骤的详细 CoT 标注。

而后,团队在 LLaDA 8B 权重的基础上训练 LLaDOU 模型,充分验证了这一思考技术在数学推理和代码生成任务上的能力。结果显示,该技术显著提升了模型对复杂数学逻辑问题的推理准确率,和生成代码的测试通过率。在相关的评测基准上,LLaDOU 超越了其他扩散语言模型,取得了最好的性能。

在下图中,团队用不同颜色展示了同一回答中不同 token 的先后生成顺序 —— 越浅的颜色代表 token 在更早的步数生成。可以看出,整个推理过程倾向于首先生成关键数字和计算符号,然后填充其他相关的文本内容,逐渐满足语法约束。

在这里,团队也以视频形式展示了 LLaDOU 在解决数学问题的完整生成过程。
,时长00:13
总结
这篇文章介绍了由西湖大学 MAPLE 实验室提出的一种全新的大模型推理范式,扩散式「发散思维链」。该框架将反向扩散过程中的中间结果看作模型的推理过程,并将模型最终输出结果的正确性作为奖励开展强化学习训练,大幅提升了大模型的推理能力,在数学推理、代码生成等任务上取得了超越其他扩散语言模型的性能。扩散式「发散思维链」这一理论打破了大模型推理过程的固有范式,为复杂推理问题提供了创新性的方法解决方案,值得我们进一步挖掘。
....
#Token-Shuffle
自回归文生图首次冲上2K分辨率!Token-Shuffle:具有竞争力的生成性能,不输扩散模型
首词将 AR 文生图推到 2048 × 2048 的分辨率,并具有令人印象深刻的生成性能。在 GenAI-benchmark 中,本文 2.7B 模型在硬提示上实现了 0.77 的分数,比 AR 模型 LlamaGen 高出 0.18,扩散模型 LDM 高出 0.15。
通过减少 token 来实现高分辨率自回归图像生成。
本文研究的是自回归 (AR) 图像生成问题。AR 模型普遍被认为不如 Diffusion 更具竞争力。一个主要的限制因素是 AR 模型需要大量的 image token,限制了训练和推理效率,以及图像分辨率。
本文为了把训练的分辨率拉上去,从架构的角度入手,提出了 Token-Shuffle,来减少 Transformer 中 image token 的数量。本文的关键 insight 是 MLLM 视觉词汇表存在维度冗余,其中来自 vision encoder 的低维视觉代码直接映射到高维语言词汇表。
Token-Shuffle 的做法是:沿着 dimension 的维度合并局部 token,减少 token 数量。Token-Unshuffle 的做法是对称的。
与文本提示联合训练,本文模型无需额外的预训练 text encoder,并使 MLLM 能够以 next-token prediction 的范式支持高分辨率图像生成,且同时保持高效的训练和推理。本文第一次将 AR 文生图推到 2048 × 2048 的分辨率,并具有令人印象深刻的生成性能。在 GenAI-benchmark 中,本文 2.7B 模型在硬提示上实现了 0.77 的分数,比 AR 模型 LlamaGen 高出 0.18,扩散模型 LDM 高出 0.15。

图1:本文的 2.7B AR 模型使用 token-shuffle 生成的高分辨率图像
1 Token-Shuffle:自回归高分辨率图像生成
论文名称:Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
论文地址:
https://arxiv.org/pdf/2504.17789
项目主页:
https://ma-xu.github.io/token-shuffle/
1.1 Token-Shuffle 研究背景
LLM 通过自回归地预测序列中的 next-token 在自然语言处理领域取得了成功。最近,一些工作尝试把 LLM 拓展到图像生成领域,像 Llamagen,Chameleon,Emu 等等。
那么自回归图像生成,一般有两种策略:无非是使用连续的视觉 token,还是离散的视觉 token。Kaiming 的 Fluid 指出,连续 token 可以提供更优越的图像质量,且需要更少的 token,提供了显著的计算效率。相比之下,离散 token 通常会产生较低的视觉质量,并且 token 数相对于图像分辨率呈现出二次方增加。但是,离散 token 与 LLM 更兼容。另一方面,连续 token 需要对 LLM pipeline 进行修改,包括使用额外的损失函数 (比如 MAR 的 Diffusion Loss)。此外,没有很强有力的证据表明连续 token 的范式对 MLLM 文本生成的影响比较小,也就意味着连续 token 的范式也可能会影响文本生成。因此,EMU3 和 Chameleon 等大规模、真实世界的 MLLM 在实践中主要采用离散视觉 token。
像 LlamaGen,Chameleon,和 EMU3 这样的工作的 image tokenizer,就使用 vector quantization 的技术把图片转化为离散 tokens,以允许自回归 Transformer 以类似于生成语言的方式生成图像。这个方法面临的限制之一是生成图片的分辨率。不像语言通常需要几十个到几百个 token,图像需要更多的 token (例如,4K 个 token 来生成 1024×1024 分辨率的图像)。由于 Transformer 的二次计算复杂度,这种巨大的 token 数量要求使得训练和推理成本高得令人望而却步。因此,大多数 MLLM 仅限于生成低分辨率或中等分辨率的图像,就很难去挖掘高分辨率图像的好处,比如细节,保真度等等。
虽然支持长上下文生成的高效 LLM 已经有许多工作 (这些工作也有利于高分辨率图像生成),但通常涉及到架构修改,忽略了现成的 LLM,或者干脆是针对语言生成进行优化,而不是利用图像的独特属性。因此,需要为 MLLM 开发使用离散视觉 token 做高分辨率生成的方法。
1.2 Token-Shuffle 做法
首先将视觉 token 集成到 LLM 词汇表中。常见的做法是将视觉标记器码本与原始 LLM 词汇表拼接起来,形成一个新的多模态词汇表。虽然很简单,但这种方法忽略了维度的内在差异。例如,在 VQGAN 中,codebook 向量的维度相对比较低,比如 256。这种低维已被证明足以区分向量,并已被证明可以提高码本的使用和重建质量。但是,直接将视觉 tokenizer 的 codebook 附加到 LLM 词汇表中会导致向量维度急剧增加,达到 3072 或 4096 甚至更高。这种急剧增加不可避免地为添加的视觉词汇引入了无效的维度冗余。
Token-Shuffle 就是受此启发,为 MLLM 设计的即插即用操作。Token-Shuffle 显著减少用于视觉 token 的数量,提高高分辨率图像生成的效率。Token-Shuffle 的灵感来自于图像超分技术中的 Pixel-Shuffle,沿通道维度融合视觉 token。

图2:Token-Shuffle Pipeline:减少 MLLM 中视觉 token 数量的即插即用操作
Token-Shuffle 的思想就是在一个 local window 内部做 token 的处理或者生成。这种方法大大减少了视觉 token 的数量,同时保持高质量的生成。当窗口大小设置为 2 时,可以节约大概 75% 的 token。传统视觉编码器所依赖的激进压缩比,而 Token-Shuffle 是利用了视觉 token 的维度冗余来保留细粒度信息。
Token-Shuffle 第一次将自回归图像生成的边界推到 2048×2048 的分辨率,并使其能够超越,同时仍然享受高效的训练和推理。使用 2.7B Llama 模型,Token-Shuffle 在 GenEval 上实现了 0.62 的 overall score,在 GenAI-bench 上实现了 0.77 的 VQAScore,明显优于相关的自回归模型,甚至超过了扩散模型。
1.3 图像生成的局限性
为了使 LLM 能够进行图像合成,作者将离散的视觉 token 合并到模型的词汇表中。利用 LlamaGen 的预训练 VQGAN 模型。它将输入分辨率下采样 16 倍。VQGAN codebook 包含 16,384 个 token,这些 token 与 Llama 的原始词汇表拼接。特殊的 token 比如 <|start_of_image|> 和 <|end_of_image|> 被用来封装离散视觉 token 序列。在训练期间,所有 token (包括视觉和文本) 都用于计算损失。
虽然很多模型,比如 Llamagen,已经证明了离散视觉 token 在 MLLM 中的图像生成的能力,但一个不可避免的问题是高分辨率图像的视觉 token 数量令人望而却步。为了生成分辨率为 1024×1024 的高分辨率图像,如果使用下采样 16 倍的 tokenizer,总共需要 (1024/16) × (1024/16) = 4096 个视觉 token。与语言语料库相比,这样的许多视觉标记使得训练非常缓慢,推理效率非常低。这也将在很大程度上限制生成的图像质量和美学。如果我们进一步将分辨率提高到 2048×2048,它将对应于 16K 个视觉 token,这在 next-token prediction 的范式下对于高效训练和推理不切实际。
原则上,增加视觉 token 的数量可以产生更详细、美观的图像,分辨率更高。但也会带来令人望而却步的计算和通信负担。之前的方法总是面临权衡:持久地增加训练和推理成本,或者牺牲图像分辨率和质量。解决这一困境对该领域特别有价值,因为人们一直都在寻找可以 balance 生成效率和保真度的方法。
1.4 视觉维度冗余
如上文所述,赋予大型语言模型 (LLM) 具有图像生成能力的常见策略是将视觉 codebook token 附加到语言词汇表中。虽然概念上简单,但此方法会导致视觉 token 的 embedding 维度显著增加。
作者认为:这种将离散视觉 token 直接合并到 LLM 词汇表中的常用方法引入了固有的维度冗余。为了研究这一点,作者使用维度为 3072 的 2.7B Llama 的 MLLM 进行了一个简单的研究。对于视觉词汇表,引入了两个 Linear 来线性减小和扩展 embedding 维度。这样一来,视觉词汇表的 rank 就被限制为 ,其中 是压缩率。作者对于具有不同 值的模型,训练了 55 K iterations。

图3:视觉词汇维度冗余。左:两个 MLP 将视觉 token 的 rank 降低了 r 倍。右图:不同 r 值的预训练损失 (log-scaled perplexity),即使降维显著,性能影响很小
图 3 显示出视觉词汇存在相当大的冗余,因为可以将维度压缩多达 8 倍,而不会显著地影响生成质量。当使用更大的压缩率时,可以观察到损失会轻微增加。
1.5 Token-Shuffle 具体操作
受视觉词汇表中维度冗余的启发,Token-Shuffle 这个即插即用操作可以减少 Transformer 中的视觉 token 数,提高计算效率并实现高分辨率图像生成。
Token-Shuffle 操作
Token-Shuffle 并不是去减少视觉词汇的维度冗余,而是利用这种冗余来减少视觉 token 数量以提高效率。具体来说就是把空间中局部的视觉 token 去 shuffle 为单个 token,然后将融合的视觉 token 和文本 token 一起输入到 Transformer。使用一个 MLP 层来压缩视觉 token 的维度,确保融合的 token 与原始 token 具有相同的维度,确保融合的 token 与原始 token 具有相同的维度。假设 代表局部 shuffle window size,Token-Shuffle 将 token 数减少了 倍,显著减轻了 Transformer 架构的计算量。
Token-Unshuffle 操作
Token-Unshuffle 是为了恢复原始的视觉 token,将融合的 token 分解为局部视觉 token,并使用额外的 MLP 层来恢复原始维度。
还在两个操作中引入了残差 MLP 块。整个 Token-Shuffle pipeline 如图 2 所示。
本质上,不会在推理过程中或训练期间减少 token 的数量,而是在 Transformer 计算期间减少 token 的数量。
图 4 说明了 Token-Shuffle 方法的效率。此外,Token-Shuffle 不是严格遵守 next-token prediction 范式,而是预测下一个 fused token,允许在单个步骤中输出一组局部视觉 token,这就可以显著提高效率并使高分辨率图像生成对于 AR 模型是可行的。

图4:Token-Shuffle 可以二次方地提高效率。对于 shuffle window size s = 2,在训练 FLOP 和 token 数量上实现了大约 4 倍的减少。考虑到在推理过程中使用 KV-cache,推理时间大致与 token 数成线性关系
实现细节
1.对于 Transformer 输入,首先通过 MLP 层,将维度从 映射到 ,将视觉词汇表的维度压缩 倍,其中, 表示 Transformer 维度。
2.接下来,局部 视觉 token 被 shuffle 为单个 token,将每张图像的 token 总数从 减少到 ,同时保持整体维度。
3.为了增强视觉特征融合,添加了 个 MLP Block。
4.对于 Transformer 输出,Unshuffle 操作将每个输出视觉 token 扩展为 个 token。
5.然后是一个 MLP 层将维度从 恢复为 。
6.为了细化特征提取,使用额外的 MLP Block。
为了简单起见,Token-Shuffle 和 Token-Unshuffle 都使用了 个 MLP 层,其中每个 MLP Block 由 2 个具有 GELU 激活的线性投影组成。
1.6 实验设置
使用 2.7B Llama 模型进行了所有实验,Llama 模型的维度为 3072,由 20 个自回归 Transformer Block 组成。遵循 Emu,在 licensed dataset 上训练。为了训练 2048×2048 的高分辨率图像,排除了分辨率小于 1024×1024 的图像。模型是用预训练的 2.7B Llama checkpoint 初始化的,并以 2e−4 的学习率开始训练。所有图像 caption 都由 Llama3 重写,以生成长提示,其被证明有助于更好的生成。
分 3 个阶段对模型进行预训练,从低分辨率到高分辨率图像生成。
使用 512×512 分辨率的图片训练模型,不使用 Token-Shuffle 操作,因为在这个阶段视觉 token 的数量并不多。这个阶段在大约 50B token 上训练,使用 4K 的序列长度、512 的 global batch size 训练总共 211K steps。
将图像分辨率增加到 1024×1024,并引入 Token-Shuffle 操作来减少视觉 token 的数量,以提高计算效率。这个阶段,扩展到 2 TB 训练 token。
将图像分辨率增加到 2048×2048,在 300 B tokens 上训练。
与对较低分辨率的训练不同,作者观察到处理更高分辨率的 (例如 2048×2048) 总是导致训练不稳定,损失和梯度值意外增加。为了解决这个问题,使用 z-loss,它稳定了对非常高分辨率图像生成的训练。
作者在 1,500 个高美学质量的图片上,以 4e-6 的学习率微调不同阶段的模型。默认情况下,可视化和评估是基于分辨率为 1024×1024 上微调的结果,Token-Shuffle window size 为 2,除非另有说明。
1.7 实验结果
虽然 FID 或 CLIPScore 通常用于 class-conditioned 图像生成任务的评估,但众所周知,这些指标对于文生图是不合理的。
本文考虑了两个 Benchmark:GenEval 和 GenAI-Bench。GenAI-Bench 使用 VQAScore 作为自动评估指标,其微调一个视觉问答 (VQA) 模型以生成 text-image alignment score。由于训练字幕是类似于 LlamaGen 的长字幕,因此报告了基于 Llama3-rewritten prompt 的结果,用于字幕长度一致性。
图 5 的结果突出了 Token-Shuffle 的强大性能。与其他自回归模型相比,Token-Shuffle 在 "basic" prompts 上的总体得分为 0.14,在 "hard" prompts 上比 LlamaGen 高出 0.18。与基于强扩散的基线相比,Token-Shuffle 在 "hard" prompts 上的总体得分上超过了 DALL-E 3 0.7。

图5:GenAI-Bench 上图像生成的 VQAScore 评估
图 6 报告了 GenEval 详细的评估结果。实验结果表明,Token-Shuffle 是一种纯 AR 模型,能够呈现很 promising 的生成质量。

图6:GenEval 结果
人类评估结果
自动评估指标提供了公正的评估,但可能并不总完全捕捉人类的偏好。为此,作者还对 GenAI-bench 提示集进行了大规模的人工评估,将我们的模型与 LlamaGen、Lumina-mGPT 和 LDM 进行了比较,分别作为 AR 模型、 MLLM 和 Diffusion 的代表性方法。对于人工评估,主要关注 3 个关键指标:
- 文本对齐:评估图像反映文本提示的准确性。
- 视觉缺陷:检查逻辑一致性以避免不完整身体或四肢等问题。
- 视觉外观:用于评估图像的美学质量。
结果如图 7 所示。本文模型在所有评估方面始终优于基于 AR 的模型 LlamaGen 和 Lumina-mGPT。这表明 Token-Shuffle 有效地保留了美学细节,并在足够的训练下遵守文本,即使在很大程度上降低了 token 数量以提高效率。与 LDM 相比,证明了基于 AR 的 MLLM 相对于扩散模型可以获得相当或优越的生成结果 (在视觉外观和文本对齐方面)。然而,观察到 Token-Shuffle 在视觉缺陷方面的表现略逊于 LDM,与 Fluid 的观察结果一致。

图7:人类评估结果。Token-Shuffle 与 LlamaGen (无文本的基于 AR 的模型)、Lumina-mGPT (带有文本的基于 AR 的模型) 和 LDM (基于扩散的模型) 的对比。对比 3 个方面:图文对齐,视觉缺陷,视觉外观
视觉效果展示
作者将 Token-Shuffle 在视觉上与其他模型进行比较,包括两个基于扩散的模型,LDM 和 Pixart-LCM,和一个自回归模型 LlamaGen。
结果如图 8 所示。虽然所有模型都表现出良好的生成结果,但 Token-Shuffle 似乎更接近于文本。一个可能的原因是 Token-Shuffle 在统一的 MLLM 风格的模型中联合训练文本和图像。与 AR 模型 LlamaGen 相比,Token-Shuffle 以相同的推理成本实现了更高的分辨率,从而提高了视觉质量和文本对齐。与基于扩散的模型相比,Token-Shuffle 作为基于 AR 的模型,展示了具有竞争力的生成性能,同时也支持高分辨率输出。

图8:与扩散模型和 AR 模型的视觉效果对比
....
#用GRPO微调模型:从算法实现到训练~
本期笔者将用强化学习算法GRPO对模型进行微调,这里假定大家已经能够实现LoRA模型的微调,我们GRPO算法修改的参数也是Lora参数。本期依旧会介绍解释基本流程,虽然不会事无巨细,但会将GRPO算法主要技术实现讲清楚。如果对于LoRA微调不了解的可以参考笔者之前的一篇博客小白避坑指南:https://zhuanlan.zhihu.com/p/30203601820。
基本流程
本期笔者通过已经进行过LoRA微调后的模型,再对其通过deepspeed进行分布式强化学习微调优化。接下来简述基本流程:
- 1 加载LoRA微调后模型
- 2 加载数据集
- 3 编写环境奖励函数代码
- 4 编写GRPO微调代码
- 5 记录微调时间和GPU显存的占用率。
跟之前一期一样,笔者的环境是:
- 1 操作系统:Linux Ubuntu 22.04
- 2 GPU:两块A100 80G
基础知识
Deepspeed
DeepSpeed 是由微软研究院开发的开源深度学习优化库,专为大规模模型训练与推理设计,支持 PyTorch 和 TensorFlow 等框架。它通过一系列底层优化技术,解决了分布式训练中的内存效率、计算速度、通信开销等核心问题,让训练万亿参数模型成为可能,同时降低硬件门槛和训练成本。简单来说,我们利用它可以完成分布式训练加速。GRPO
群体相对策略优化 (GRPO) 是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估者(critics, 评论家)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。加载模型
在加载模型之前,我们需要先初始化一下Deepspeed的分布式环境。
# 初始化分布式环境
if args.local_rank != -1:
deepspeed.init_distributed(dist_backend='nccl')
torch.cuda.set_device(args.local_rank)
logger.info(f"分布式训练初始化成功: rank={args.local_rank}, world_size={torch.distributed.get_world_size()}")然后定义一个GRPOTrainer类来加载分词器和基础模型,并在基础模型之上加载LoRA权重。
self.tokenizer = AutoTokenizer.from_pretrained(self.base_model_path)
model_kwargs = {
'torch_dtype': torch.float16 if cuda_available else torch.float32,
'use_cache': False # 训练时禁用KV缓存以节省显存
}
self.model = AutoModelForCausalLM.from_pretrained(
self.base_model_path,
**model_kwargs
)
self.model = PeftModel.from_pretrained(
self.model,
self.lora_model_path
)至此模型加载完毕,不过Lora加载的模型参数默认是不可训练的,我们需要手动将其设置为可训练。如果是lora参数,我们将它的requires_grad属性设置为True。
注意:我们修改的参数仅仅是LoRA参数,其他参数还是冻结的。
trainable_params = []
for name, param in self.model.named_parameters():
if'lora'in name.lower():
param.requires_grad = True
trainable_params.append(param)当然,还需要用Deepspeed进行封装模型,保证分布式训练。
ds_args = {
"model": self.model,
"model_parameters": trainable_params,
"config": ds_config
}
model_engine, optimizer, _, _ = deepspeed.initialize(**ds_args)
self.model = model_engine
self.optimizer = optimizer加载数据集
这里的数据集预处理代码就不展示了,笔者简单提取一部分数据集进行展示,主要包含源代码source_code和参考测试代码test_code两个属性。
# 处理数据
train_data = []
if"data"in json_data:
logger.info(f"从数据文件中找到{len(json_data['data'])}个样本")
for item in json_data["data"]:
source_code = item.get("source_code", "")
test_code = item.get("test_code", "")
if not source_code:
continue
prompt = f"请为以下Java类生成单元测试用例: ```java {source_code} ```生成的测试用例:"
train_data.append({
"prompt": prompt,
"source_code": source_code,
"reference_test": test_code
})
else:
logger.warning("未找到'data'字段,使用加载的完整数据")
train_data = json_data编写环境代码
这里我们需要对每个生成的测试用例进行评估,返回其奖励。奖励的设置是通过不同的测试实现的,包含覆盖率测试、变异分析以及可读性测试。接下来简单介绍一下:
- 静态覆盖率变异实现方法:估算测试对源代码的覆盖程度
- 1 提取源代码中的方法名称
- 2 检查测试代码是否调用这些方法
- 3 计算被测试覆盖的方法比例
- 4 加入对断言数量的考量,每5个断言最多增加0.2的覆盖率分数
- 静态变异分析: 发现代码的缺陷
- 1 统计断言语句的数量和密度
- 2 检查边界条件测试(如null检查、等值比较、边界值测试等)
- 3 根据断言分数和边界条件检查综合评分
- 可读性分数:评估测试代码的清晰度和可维护性
- 1 分析代码长度(过短过长都不好)
- 2 评估注释密度和质量
- 3 检查命名规范
- 4 检查是否包含断言
我们对其设置不同的奖励权重,分别为0.4,0.3以及0.3,最后得出总奖励进行返回。
class TestGenerationEnvironment:
"""测试生成环境,用于评估生成的测试用例质量"""
def __init__(self, jacoco_path: str = None, pit_path: str = None):
self.coverage_weight = 0.4
self.mutation_weight = 0.3
self.readability_weight = 0.3
# 创建临时工作目录
self.temp_dir = tempfile.mkdtemp(prefix="test_eval_")
logger.info(f"创建临时工作目录: {self.temp_dir}")
def evaluate_test(self,
generated_test: str,
source_code: str,
reference_test: str = None) -> Tuple[float, Dict]:
"""评估生成的测试用例质量"""
logger.info("开始评估测试质量")
try:
# 静态覆盖率分析
coverage_score = self._static_coverage_analysis(generated_test, source_code)
logger.info(f"覆盖率评分: {coverage_score:.4f}")
# 静态变异分析
mutation_score = self._static_mutation_analysis(generated_test, source_code)
logger.info(f"变异测试评分: {mutation_score:.4f}")
# 计算可读性分数
readability_score = self._calculate_readability(generated_test)
logger.info(f"可读性评分: {readability_score:.4f}")
# 如果有参考测试,计算与参考测试的相似度
similarity_score = 0.0
if reference_test:
similarity_score = self._calculate_similarity(generated_test, reference_test)
logger.info(f"相似度评分: {similarity_score:.4f}")
# 计算总分
total_score = (
self.coverage_weight * coverage_score +
self.mutation_weight * mutation_score +
self.readability_weight * readability_score
)
logger.info(f"测试质量总评分: {total_score:.4f}")
# 返回总分和详细指标
return total_score, {
"coverage_score": coverage_score,
"mutation_score": mutation_score,
"readability_score": readability_score,
"similarity_score": similarity_score
}
except Exception as e:
logger.error(f"测试评估过程中出现未捕获的错误: {str(e)}")
# 返回默认评分
return 0.65, {
"coverage_score": 0.6,
"mutation_score": 0.6,
"readability_score": 0.8,
"similarity_score": 0.0,
"error": str(e)
}编写GRPO训练代码
接下来主要是GRPO训练代码,由于训练代码过长,笔者仅仅会将其中关键技术实现单独进行讲解。
优势函数计算
对于一个prompt,我们生成num_samples个样本,分别计算其奖励,计算平均奖励作为基准值(替代价值函数),然后减去平均奖励,我们就能得到每个样本的优势函数,然后对其进行标准化。
这个方式也是GRPO的一个重要创新,通过这个方法,替代了价值函数,大大降低了显存。
# 生成测试样本
try:
generated_tests = self.generate_test(prompt, num_samples=num_samples)
logger.info(f"生成{len(generated_tests)}个测试样本完成")
except Exception as e:
logger.error(f"生成测试样本失败: {str(e)}")
return {"loss": 0, "mean_reward": 0, "mean_kl_div": 0, "num_samples": 0}
# 计算奖励
try:
rewards, metrics_list = self.compute_rewards(generated_tests, source_code, reference_test)
logger.info(f"计算样本奖励完成,平均奖励: {rewards.mean().item():.4f}")
except Exception as e:
logger.error(f"计算奖励失败: {str(e)}")
return {"loss": 0, "mean_reward": 0, "mean_kl_div": 0, "num_samples": 0}
# 计算平均奖励作为基准值(替代价值函数)
value = rewards.mean()
# 计算优势函数: 优势 = 奖励 - 价值
advantages = rewards - value
# 标准化优势,减少方差
if len(advantages) > 1 and advantages.std() > 0:
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)计算序列的对数概率
在介绍重要性采样之前,我们需要先计算一下序列的对数概率,只有这样,我们才能对不同的模型进行差异性比较。通过将输入传入模型中,我们对输出进行对数化,最终得到整个序列的对数概率。
def compute_logprobs(self, model, inputs, attention_mask=None):
"""计算序列的对数概率"""
# 准备模型输入
model_inputs = {"input_ids": input_ids}
model_inputs["attention_mask"] = attention_mask
if attention_mask is None:
attention_mask = inputs.get("attention_mask", None)
# 前向传播
with torch.set_grad_enabled(model.training):
try:
outputs = model.module(**model_inputs)
logits = outputs.logits
# 计算对数概率
logits = logits[:, :-1, :] # 去掉最后一个token的预测
labels = input_ids[:, 1:] # 去掉第一个token
attention_mask = attention_mask[:, 1:]
# 计算log softmax
log_probs = F.log_softmax(logits, dim=-1)
# 获取实际token的对数概率
token_log_probs = torch.gather(
log_probs, 2, labels.unsqueeze(-1)
).squeeze(-1)
# 应用注意力掩码
token_log_probs = token_log_probs * attention_mask
# 返回序列总对数概率
return token_log_probs.sum(dim=1)
except Exception as e:
logger.error(f"计算对数概率时发生错误: {str(e)}")
# 返回一个占位符值
return torch.tensor([0.0], device=model_device, requires_grad=model.training)重要性采样机制和比率剪裁
重要性采样是一种统计技术,它允许我们使用一个分布(称为提议分布)的样本来估计另一个分布(目标分布)的期望值。这意味着我们可以使用旧策略生成的样本来训练和更新当前策略。
首先我们计算当前策略与旧策略之间的概率比率,取两者对数概率的差值再对其进行指数化。然后将这个比率现在在一个范围内,防止过大的更新步长导致训练不稳定,最后计算优化目标,取两者的最小值。简单来讲,重要性采样就是放大常选择动作的正向贡献以及负向贡献,缩小不常选择动作的贡献。代码如下:
# 计算当前策略的对数概率
current_log_prob = self.compute_logprobs(self.model, inputs)
# 计算旧策略的对数概率
with torch.no_grad():
old_log_prob = self.compute_logprobs(self.old_model, inputs)
# 计算重要性采样比率
ratio = torch.exp(current_log_prob - old_log_prob.detach())
# 比率剪裁
clipped_ratio = torch.clamp(ratio, 1 - self.cliprange, 1 + self.cliprange)
policy_loss = -torch.min(ratio * advantage, clipped_ratio * advantage).mean()KL散度约束
为了防止模型策略变化过大,GRPO引入KL散度约束,这里我们需要一直不变的参考模型作为基准,每次用它进行约束模型策略的变化。实际的计算其实很简单,我们将其对数概率相减就能得到KL散度。
def calculate_kl_divergence(self, model_inputs):
"""计算当前策略与参考策略之间的KL散度"""
# 计算参考模型的对数概率
with torch.no_grad():
if self.ref_model is None:
# 如果参考模型不可用,使用当前模型的复制
ref_log_probs = self.compute_logprobs(self.model, model_inputs).detach()
else:
# 确保参考模型在评估模式并在正确的设备上
self.ref_model.eval()
ref_log_probs = self.compute_logprobs(self.ref_model, model_inputs)
# 计算当前模型的对数概率(保留梯度)
current_log_probs = self.compute_logprobs(self.model, model_inputs)
# 确保两个张量在同一设备上
if current_log_probs.device != ref_log_probs.device:
ref_log_probs = ref_log_probs.to(current_log_probs.device)
# KL散度计算
kl = current_log_probs - ref_log_probs.detach()
kl_mean = kl.mean()
return kl_mean更新模型参数
最后我们将策略损失和KL散度约束相加组成损失函数,对其进行反向传播更新模型参数即可。并且更新旧策略。
# 总损失
loss = policy_loss + self.beta * kl_div
# 反向传播
try:
self.model.backward(loss)
self.model.step()
except RuntimeError as e:
logger.error(f"反向传播错误: {str(e)}")
continue
# 累加统计信息
total_loss += loss.item()
total_reward += reward.item()
total_kl_div += kl_div.item()
total_samples += 1
# 更新旧策略
if total_samples > 0:
logger.info("更新旧策略")
self.create_old_model_copy()训练模型
由于笔者已经配置好了deepspeed的配置文件,所以命令行命令可以特别简单。
deepspeed --num_gpus=2 train_grpo.py --zs=1本期笔者微调的模型是qwen-7B的模型,不过微调的显存消耗特别大。
训练过程:
总结
本期主要介绍了GRPO中核心的一些技术实现,不过由于篇幅原因,代码中删除了很多基础的配置以及一些异常处理过程。
....
#Mistral成最大赢家
两岁的Llama,最初的14位作者已跑了11个!
他们都是 Meta 的顶尖人才。
Meta 开源 Llama 模型家族帮助该公司制定了 AI 战略,某种程度上也改变了全世界的大模型格局。然而,令人意想不到的是,短短几年,Llama 的初创者们大多已经转投他处。
在 2023 年发表的那篇具有里程碑意义的论文《 LLaMA: Open and Efficient Foundation Language Models 》中,Llama 被推向世界,当时论文共有 14 位作者。
论文地址:https://arxiv.org/pdf/2302.13971
本周有媒体盘点发现,仅过去两年的时间,已经有 11 位作者离开,剩下的 3 位分别是 :研究科学家 Hugo Touvron、研究工程师 Xavier Martinet 和技术项目负责人 Faisal Azhar。
Meta 的人才流失让 Mistral 受益最多。Mistral 是一家总部位于法国巴黎的 AI 初创公司,由前 Meta 研究员 Guillaume Lample 和 Timothée Lacroix(Llama 的两位核心架构师, 也是 LLaMA 的创始成员)共同创立。他们构建的开源模型,直接与 Meta 的旗舰 AI 项目竞争。
随着时间推移,这些人才的流失引发了人们对 Meta 能否留住顶尖 AI 人才的质疑,尤其是在其面临新一轮内外部压力之际。据《华尔街日报》报道,由于内部对其性能和领导力的担忧,该公司正在推迟其史上最大规模的 AI 模型 Behemoth 的发布。Meta 的最新版本 Llama 4 并未受到开发者的热烈欢迎,许多开发者现在将目光转向 DeepSeek 和 Qwen 等发展更快的开源竞争对手,以寻求尖端功能。
Meta 创始人兼 CEO 马克・扎克伯格(左)在 2025 年 LlamaCon 大会上与微软董事长兼 CEO 萨蒂亚・纳德拉交谈。
Meta 内部的研究团队也经历了一次人事变动。领导公司 FAIR 团队八年的 Joelle Pineau 上个月宣布卸任。
Joelle Pineau
她的继任者是 Robert Fergus,Fergus 曾于 2014 年与他人共同创立了 FAIR,之后离开加入谷歌 DeepMind ,在谷歌工作了五年,本月才重返 Meta。
Robert Fergus
随着越来越多人才的相继离职,以及竞争对手在开源创新领域的步伐加快,Meta 现在面临着如何在失去最初团队的情况下捍卫其早期领先地位的挑战。
Meta 首席产品官 Chris Cox 在 2025 年 LlamaCon 大会上发表演讲。
两年前,Meta 引领开源潮流,两年后,这种领先优势已然消退。
尽管 Meta 在人工智能领域投入了数十亿美元,但仍然缺乏专门的推理模型,即专门用于处理需要多步思考、解决问题或调用外部工具完成复杂命令任务的模型。随着谷歌和 OpenAI 等其他公司在其最新模型中优先考虑这些功能,这种差距变得更加明显。
Meta 11 位离职作者的平均任职时间超过五年,这表明他们并非短期聘用,而是深度参与 Meta 人工智能工作的研究人员。一些人早在 2023 年 1 月就离开了;其他人则一直留守到 Llama 3 周期结束,还有一些人在今年才离开。他们的离职标志着这支曾帮助 Meta 将其人工智能声誉建立在开放模型团队的悄然瓦解。
下面我们盘点一下这些离职人员的最终去向。
Naman Goyal
Naman Goyal 现在是 Thinking Machines Lab 技术人员。Thinking Machines Lab 是由 OpenAI 前首席技术官(CTO)Mira Murati 于 2025 年 2 月创立的 AI 公司。
Goyal 于 2018 年加入 Meta,今年 3 月离职,在 Meta 任职时间长达六年多。

在 Meta 工作期间,他参与了 Llama、Llama 2、Llama 3 等多项研究。在 Google Scholar 上,他的总引用量超过 11 万。

Baptiste Rozière
Baptiste Rozière 现在是 Mistral AI 的一名 AI 科学家,领导代码生成团队,现在正致力于研究 Codestral 模型,该模型可在单块 RTX 4090 显卡或配备 32GB RAM 的 Mac 上运行,是本地部署和设备端使用的理想之选。
在加入 Mistral AI 之前,Rozière 在 Meta 工作了 5 年之久,他于 2019 年加入 Meta,2024 年选择离开。

在 Meta 工作期间,他是代码生成团队的一名研究科学家,致力于研究大语言模型,尤其关注代码应用。Baptiste 为 Llama 做出了非常多的贡献,并主导研发了 Code Llama。

Aurélien Rodriguez
Aurélien Rodriguez 现在是明星创企 Cohere 的基础模型训练负责人。在 Cohere 工作期间, 参与研发了 Command-A,当时,该模型可与闭源和开放权重模型 GPT-4o 和 DeepSeek-v3 相竞争,同时更轻、更快。
他于 2022 年加入 Meta,期间参与了 llama、Llama 2、Llama 3 的研究,两年后 Rodriguez 选择离职。

Eric Hambro
Eric Hambro 现为 Anthropic 技术成员(Member of Technical Staff)。
他于 2020 年 9 月加入 Meta,担任研究工程师,并于 2023 年 11 月离职。在 Meta 工作时长 3 年 3 个月,期间参与 Llama 的基础设施与评估工作以及工具使用和智能体的微调研究、在开放式环境中使用互联网数据集进行离线强化学习的研究、以及顶会论文和开源库的贡献。

在 Google Scholar 上,他的论文总引用量超过了 1.8 万。
Timothée Lacroix
Timothée Lacroix 现为 Mistral AI 联合创始人兼 CTO。
他从 2015 年 5 月加入 Meta,并于 2023 年 6 月离职。在 Meta 工作时长 8 年 2 个月。
此后,他加入了 Mistral AI。

在 Google Scholar 上,他的论文总引用量超过了 2 万。

Marie-Anne Lachaux
Marie-Anne Lachaux 现为 Mistral AI 创始成员以及 AI 研究工程师。
她于 2018 年 7 月加入 Meta,先后担任 FAIR AI 研究工程师、Meta GenAI AI 研究工程师,曾经参与 Llama 和 Llama 2 的研发以及定理证明、代码生成、预训练 + 代码混淆、编程语言的无监督转换等项目。她在 2023 年 6 月离职,在 Meta 工作时长 5 年。
她于 2023 年 7 月加入 Mistral AI。

在 Google Scholar 上,她的论文总引用量超过了 3.5 万。

Thibaut Lavril
Thibaut Lavril 现为 Mistral AI 的 AI 研究工程师。
他于 2019 年 2 月加入 FAIR,担任 AI 研究工程师,参与 Llama 和 Llama 2 的开发以及定理证明、Open Catalyst Project(与 CMU 合作,利用 AI 将量子力学模拟加速 1000 倍,从而发现存储可再生能源所需的更高效和可扩展的新型电催化剂)。2023 年 6 月离职,在 Meta 工作时长 4 年 5 个月。

在 Google Scholar 上,他有两篇论文引用量超过了 15000,分别是 Llama 和 Llama 2,总引用量超过了 4 万。

Armand Joulin
Armand Joulin 现为 Google DeepMind 杰出科学家。
他于 2014 年 10 月加入 Meta,担任研究主任,并于 2023 年 5 月离职。在 Meta 工作时长 8 年 8 个月。

在 Google Scholar 上,他的论文引用量有 4 篇超过了 6000,总引用量超过了 9 万。

Gautier Izacard
Gautier Izacard 现为 Microsoft AI 技术成员(Member of Technical Staff)。
他曾于 2019 年 5 月到 8 月在 FAIR 实习,并于 2020 年 2 月到 2023 年 3 月就职于 Meta,此后离职。在 Meta 工作时长 3 年 2 个月。2024 年 3 月,他加入 Microsoft AI。

在 Google Scholar 上,他的论文总引用量超过了 2 万。

Edouard Grave
Edouard Grave 现为法国人工智能实验室 Kyutai 的研究科学家。
他从 2016 年 1 月开始,先后在 Meta 担任博士后研究员、研究科学家,2023 年 2 月离职。在 Meta 工作时长 7 年 2 个月。2023 年 11 月,他加入 Kyutai。

在 Google Scholar 上,他有四篇论文引用量超过了 6000,总引用量超过了 6 万。

Guillaume Lample
Guillaume Lample 现在担任 Mistral AI 联合创始人兼首席科学家。
他自 2014 年开始便在 Meta 实习,并从 2020 年 1 月到 2023 年担任 FAIR 研究科学家,此后离职。在 Meta 工作时长 6 年 5 个月。他于 2023 年 5 月加入 Mistral AI。

在 Google Scholar 上,他有三篇论文引用量超过 5000,总引用量超过 4 万。

参考链接:https://www.businessinsider.com/meta-llama-ai-talent-mistral-2025-5
....
#LLaDA-V
舍弃自回归!国内团队打造纯扩散多模态大模型LLaDA-V,理解任务新SOTA
本文介绍的工作由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。游泽彬和聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。该研究基于团队前期发布的、首个性能比肩 LLaMA 3 的 8B 扩散大语言模型 LLaDA。
此次,团队将 LLaDA 拓展至多模态领域,推出了 LLaDA-V—— 集成了视觉指令微调的纯扩散多模态大语言模型(MLLM)。这项工作标志着对当前以自回归为主流的多模态方法的一次重要突破,展示了扩散模型在多模态理解领域的巨大潜力。
近年来,多模态大语言模型(MLLMs)在处理图像、音频、视频等多种输入模态方面取得了显著进展。然而,现有的大多数方法依赖自回归模型。虽然有研究尝试将扩散模型引入 MLLMs,但往往采用混合架构(自回归 + 扩散)或者受限于语言建模能力,导致性能不佳。
继 LLaDA 成功证明扩散模型在纯语言任务上能与自回归模型(如 LLaMA3-8B)竞争后,一个关键问题随之而来:扩散语言模型能否在多模态任务中也达到与自回归模型相当的性能?LLaDA-V 正是对这一问题的有力回答。
研究团队将 LLaDA 作为语言基座,通过引入视觉编码器(SigLIP 2)和 MLP 连接器,将视觉特征投影到语言嵌入空间,实现了有效的多模态对齐。LLaDA-V 在训练和采样阶段均采用离散扩散机制,摆脱了自回归范式。
论文标题:LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
论文链接:https://arxiv.org/abs/2505.16933
项目地址:https://ml-gsai.github.io/LLaDA-V-demo/
代码仓库:https://github.com/ML-GSAI/LLaDA-V
团队预计近期开源训练推理代码以及 LLaDA-V 权重。
性能亮点
数据可扩展性强,多项基准表现优异
大规模的实验评估揭示了 LLaDA-V 的多个引人注目的特性:
1. 卓越的数据可扩展性与竞争力。团队将 LLaDA-V 与使用 LLaMA3-8B 作为语言基座、但其他部分完全相同的自回归基线 LLaMA3-V 进行了对比。
结果显示,LLaDA-V 展现出更强的数据可扩展性,特别是在多学科知识(如 MMMU)基准上。令人印象深刻的是,尽管 LLaDA-8B 在纯文本任务上略逊于 LLaMA3-8B,但 LLaDA-V 在 11 个 多模态任务中超越了 LLaMA3-V。这表明扩散架构在多模态任务上面具备一定的优势。


2. 纯扩散与混合架构中的 SOTA:与现有的混合自回归 - 扩散模型(如 MetaMorph, Show-o)和纯扩散模型相比,LLaDA-V 在多模态理解任务上达到了当前最佳(SOTA)性能。这证明了基于强大语言扩散模型的 MLLM 架构的有效性。

3. 缩小与顶尖自回归 MLLM 的差距:尽管 LLaDA 的语言能力明显弱于 Qwen2-7B,但 LLaDA-V 在某些基准(如 MMStar)上显著缩小了与强大的 Qwen2-VL 的性能差距,达到了相当的水平(60.1 vs. 60.7)。这进一步印证了扩散模型在多模态领域的潜力。
下图是 LLaDA-V 同用户进行交流的场景。

LLaDA-V 准确描述出了一幅宁静而富有层次感的瑞士阿尔卑斯山景:一条绿色小路蜿蜒延伸,一位行人沿路行走,远处是山谷中的白色教堂和被薄雾环绕的巍峨群山,蓝天白云为画面增添了宁静氛围,整体构图清晰,意境优美。
核心方法
LLaDA-V 的核心在于将视觉指令微调框架与 LLaDA 的掩码扩散机制相结合。下图展示了 LLaDA-V 的训练和推理过程:

架构: 采用经典的「视觉编码器 + MLP 投影器 + 语言模型」架构。视觉编码器(SigLIP 2)提取图像特征,MLP 投影器将其映射到 LLaDA 的嵌入空间。LLaDA 语言塔则负责处理融合后的多模态输入并生成回复。特别地,LLaDA-V 采用了双向注意力机制,允许模型在预测时全面理解对话上下文,这在消融实验中被证明略优于对话因果注意力机制。
训练目标: LLaDA-V 扩展了 LLaDA 的训练目标,以支持多轮多模态对话。其核心思想是在训练时保持图像特征和用户提示(Prompt),仅对模型的回复(Response)进行随机掩码,训练目标仅对被掩码部分计算交叉熵损失。

推理过程: LLaDA-V 的生成过程并非自回归式的逐词预测,而是通过扩散模型的反向去噪过程。从一个完全被掩码的回复开始,模型在多个步骤中迭代地预测被掩码的词元,逐步恢复出完整的回复。研究采用了 LLaDA 的低置信度重掩码策略,优先保留高置信度的预测,提升了生成质量。
总结与展望
LLaDA-V 成功地将视觉指令微调与掩码扩散模型相结合,证明了扩散模型不仅能在语言任务上与自回归模型一较高下,在多模态理解领域同样展现出强大的竞争力和独特的优势,尤其是在数据可扩展性方面。
这项工作不仅为 MLLM 的发展开辟了一条新的技术路径,也挑战了多模态智能必须依赖自回归模型的传统观念。随着语言扩散模型的不断发展,我们有理由相信,基于扩散的 MLLM 将在未来扮演更重要的角色,进一步推动多模态 AI 的边界。
....
#火山引擎xLLM如何一张卡榨出两张的性能
传统云还在「卖铁」,下一代云已在「炼钢」
大模型越来越聪明,企业却似乎越来越焦虑了。
模型性能突飞猛进,从写文案到搭智能体(Agent),AI 掌握的技能也越来越多。但一到真正上线部署,问题就来了:为什么推理成本越来越高?算力投入越来越多?效果却不成正比?
现如今,推理大模型已经具备服务复杂业务场景的实力。但是,要想让它们在工作时有足够快的速度,企业往往不得不大力堆卡(GPU),从而满足 TPOT(平均输出一个 Token 的时间)和 TPS(每秒 Token 数)等指标。也就是说,在迈过了模型性能的门槛之后,企业却发现大模型落地还有另一个高耸的门槛:推理效率。
为了响应这一需求,云厂商不约而同地把目光投向了「卖铁」,也就是上更多、更新但也更贵的卡。但它们的客户面临的问题真的是「卡不够多不够强」吗?
火山引擎给出的答案是:不是卡不够多,也不是卡不够强,而是没「炼」好。
这家已经高举「AI 云原生」旗帜的云服务平台已经在「炼钢」这个方向上走出了自己的道路,其推出的 xLLM 大语言模型推理框架具有堪称极致的性能,能低时延、高吞吐地支持大规模部署:用同样的 GPU 卡,计算成本仅为开源框架的二分之一。
数据说话
同样的卡,跑出两倍性能
火山引擎 xLLM 框架的表现究竟如何?这里我们来看看使用 DeepSeek-R1 模型,在 Hopper 架构单卡显存 141G 和 96G 机型上,xLLM 与性能最好的开源推理框架的性能对比。在社区力量的推动下,这两款主流的开源框架已经针对 DeepSeek-R1 进行了很多优化。
而就算与这两大高效率的开源推理框架对比,xLLM 依然展现出了显著的优势。
这里来看在两组 TPOT < 50ms 的典型流量特征上的测试结果。

Token 输入 3500: 输出 1500 时,xLLM 与两款主流开源框架在 Hopper 96G/141G 上的输出单卡每秒吞吐 TPS

Token 输入 2500: 输出 1500 时,各框架单卡 TPS 对比
从中我们可以得出几个明显结论。
首先,在这两种典型流量特征上,xLLM 的表现都明显优于业内最好的开源方案。具体来说,在输入 3500 : 输出 1500 时,使用 xLLM 推理引擎可让输出单卡 TPS 达到 SGLang 0.4.5 的 2.05 倍;而在输入 2500 : 输出 1500 时,xLLM 更是可以达到 SGLang 0.4.5 的 2.28 倍以上。
不仅如此,xLLM 在 Hopper 96G 机型上的表现也超过了开源框架在显存更大的 Hopper 141G 机型上的表现。而如果达到相同的单卡输出 TPS,前者的成本比后者低约 89%。
另外,还能明显注意到,在上面的两个典型场景中,xLLM 在 Hopper 96G 和 141G 上的输出单卡每秒吞吐 TPS 表现相差不大,比如在输入 3500 : 输出 1500 流量特征时,xLLM 在这两种 GPU 上的表现均在 190 TPS 左右。综合而言,在火山引擎上使用 xLLM + Hopper 96G 方案会更有性价比。
而在极限情况下,xLLM 的优势还能更加明显。以 2500: 1500 的输入输出为例,火山引擎 xLLM 版 DeepSeek 推理的单机总吞吐可达 6233 TPS,输出吞吐可达 2337 TPS,达到最好开源框架的吞吐量的十倍!而在相同的吞吐水平下(1800 TPS),火山引擎 xLLM 的平均 TPOT 为 30 ms,最好开源框架的 TPOT 为 83 ms——xLLM 比开源框架低 64%。而在限定 TPOT < 30 ms 的 SLO 时,火山引擎 xLLM 版的平均单机输出吞吐能达到 1867 TPS,比最好开源框架高 500 %。
从这些数据中可以看出,xLLM 在性能与效率两方面均具显著优势,能够帮助企业以更低的成本获得更高的推理能力,尤其在大规模部署场景中效果尤为突出。
压榨出全部算力
xLLM 框架是如何做到的?
在迈过模型性能门槛后,企业级大模型推理面临的下一道「推理效率」门槛包含多重挑战:
复杂推理场景:不同企业和业务有着各自不同的推理需求,而有的非常复杂,可能涉及多种异构数据和处理流程;同时部署架构也开始向分布式多角色演进,例如对于纯文本模型分离出了 Prefill / Decode 两个角色,对于多模态模型还有非文本数据的 Encoder 角色。
超长上下文:随着场景和流程越发复杂,有的业务已经需要 128K 级别的 KV 缓存存取,这对带宽和延迟都提出严苛考验;另外在 KV Cache 的分级和治理上也需要有更强的管理和操纵能力。
推理侧模型并行化:模型并行方式上,推理侧除最基本的 TP(张量并行)外,也开始扩展 PP(管道并行) 、SP(序列并行)、EP(专家并行)等并行方式。
推理潮汐:业务流量时高时低,静态部署往往要么会浪费资源,要么影响性能。
异构算力:随着国内云厂商普遍开始混合使用各种异构卡 —— 在大模型推理的各阶段充分利用不同异构芯片可以带来优势,各种芯片组合会带来调度和兼容性难题。
为了解决这些挑战以及相关需求,主流的云厂商都在努力探索和研发,而 xLLM 已经率先将一些关键创新做到了生产级可用,造就了一套集深度算子优化、存算分离、弹性异构、PD 分离、训推一体等特性于一体的整体解决方案,从而可实现对不同机型的算力的极致压榨,进而大幅降低推理吞吐成本。
可以说,xLLM 就是火山引擎面向 AI 云原生时代打造的推理引擎。下面我们就来看看 xLLM 为此集成了哪些关键创新。
首先最核心的是 P/D 角色分离架构。由于 Prefill 与 Decode 两阶段的计算特性差异(Prefill 为计算密集型,Decode 为访存密集型),因此角色分离后,可以对不同角色分别配置更优的批处理策略和并行方式,使得各角色可以做到算力独立优化。
而角色分离架构需要在不同角色的 GPU 间传递 KV Cache 缓存数据,为此,火山引擎为 xLLM 配置了高性能 KV Cache 传输能力。xLLM 使用了 veTurboRPC 通信库,这是一个高吞吐量、低延迟的点对点通信库,支持与硬件和网络无关的加速通信。借助 veTurboRPC,无论是通过 NVLink (C2C 或 NVSwitch) 、InfiniBand、RoCE 还是以太网,xLLM 都可以在角色间高速传输数据。
此外,xLLM 还利用了 Pin Memory、UserSpace Network、GPUDirect RDMA 等技术,能够跨节点,跨 GPU 和内存层次结构(包括存储)高效移动缓存数据。
xLLM 也支持异构计算组合。xLLM 可部署不同角色到不同卡型的 GPU 上,组合出最佳成本和推理性能,从而更充分发挥各类 GPU 在计算、带宽和显存上的差异优势。相比之下,目前开源框架领域依旧停留在同种 GPU 卡型间的角色组合上。
池化部署也是 xLLM 的核心能力之一,即能以资源池的形式部署不同角色 —— 角色间可根据负载水平、缓存请求性等动态地将用户请求路由到某个实例。这种根据流量特征扩缩对应角色的池化部署能力可使每个角色都能保持较高的资源使用率。
相比之下,当前的开源框架的分角色部署能力通常是固定配比,比如「1 台 Prefill 实例 + 1 台 Decode 实例」组合共同伺服推理请求。但线上流量特征并不会保持不变,固定配比组合的推理实例无法高效利用 GPU 资源,以一种流量特征决定的 PD 组合,无法适应多变的流量特征。而 xLLM 可以更好地满足动态的实际业务需求。
另外,火山引擎还为 xLLM 配备了多级 KV Cache 存储能力。
首先,xLLM 使用计算节点本地 DRAM 内存作为二级缓存,从 GPU 设备显存上卸载 KV Cache。如此可在保证卡上具有足够显存用于高批量处理的前提下,保证缓存命中以减少提示词的重计算。
在此之外,xLLM 还可搭配弹性极速缓存 EIC 作为分布式缓存空间 ——EIC(Elastic Instant Cache)是火山引擎为大模型等场景提供的高速 KV Cache 服务,可通过以存代算、GDR 零拷贝等方式大幅降低推理 GPU 资源消耗,优化推理时延。具体来说,通过 xLLM 的智能迁移策略,可将频繁访问的 KV Cache 数据优先放置在 GPU 显存及内存中,而访问较少的数据则移动到 EIC,从而在过度缓存 (可能会导致查找延迟) 和不足缓存 (导致漏查和 KV 缓存重新计算) 之间取得平衡。
这些创新让 xLLM 具备低时延、高吞吐与出色稳定性,能够支撑 DeepSeek V3/R1 等千亿参数级超大模型的大规模部署,已成为当前最具竞争力的大模型推理框架之一。
更宏观地看,xLLM 正是火山引擎「AI 云原生」大战略的一部分,即以 AI 负载为中心的基础架构新范式。这是火山引擎从去年 12 月开始在国内最早提出并实践的概念,也被火山引擎总裁谭待定义为「下一个十年的云计算新范式」。

图源:2024 冬季火山引擎 FORCE 原动力大会上火山引擎总裁谭待的演讲
事实上,xLLM 也被集成到了火山引擎上个月推出的 AI 云原生推理套件 ServingKit 中。该套件提供了涵盖大模型推理部署加速、推理性能优化和运维可观测的推理服务全生命周期优化方案,且可灵活集成到客户自有推理系统和业务系统中。
更具体而言,ServingKit 能在 2 分钟内完成 DeepSeek-R1-671B(满血版)模型的下载和预热,13 秒完成模型显存加载。与此同时,ServingKit 也适配了 xLLM 之外的多个主流推理框架(比如 SGLang、vLLM、Dynamo 等),并在社区工作的基础上进行 GPU 算子优化和并行策略调优。比如,针对 DeepSeek 推理,ServingKit 在开源推理引擎 SGLang 上进一步优化,通过 PD 分离和 EP 并行的解决方案,减少了单张 GPU 上的显存占用,打破了 GPU 显存限制,提升了模型吞吐性能。同时可配合 APIG 实现智能流量调度、VKE 实现 PD 分离部署和弹性伸缩。对比社区推理方案,TPS 可提升 2.4 倍。ServingKit 还配备了强大的运维可观测能力,可实现推理服务的全链路观测和问题定位。
与其使用更多卡
不如用好每张卡
在算力紧张、成本敏感的今天,企业对 AI 推理基础设施的判断标准正在悄然变化 —— 从「谁的卡多、谁的卡新」,转向「谁能把卡用得更值」。
在 xLLM 框架的优化下,可以使用各种异构算力,在不增加任何硬件成本的情况下跑出数倍的吞吐性能。这意味着,通过采用供应充足的异构算力、极致全栈工程框架和创新算法的垂直优化方案,xLLM 能让用户获得领先的业务性能,同时还能降低成本。
以 Hopper 96G 为例,它既具备大模型推理所需的高显存、高带宽,又能在 xLLM 框架下充分释放潜能。并且火山引擎已经在多个客户场景中验证了「xLLM+Hopper 96G」的组合 —— 不仅在性能上具备优势,更在性价比上跑赢其它主流方案。
我们相信,真正面向未来的 AI 基础设施,不是「多卖铁」,而是「巧炼钢」:把每一段链路都压到最优路径,把每一个环节的性能都压榨用满。对云厂商来说,在智能应用大爆发的 AI 云原生时代,比拼的也将不再是「铁的厚度」,而是「炼钢的火候」。如果你想亲自试一试这套「炼钢术」,只需登录火山引擎机器学习平台 veMLP,即可轻松开资源,复现前文中的所有测试!
值得关注的,还有将于 6 月 11-12 日举办的「2025 春季 FORCE 原动力大会」,火山引擎将展示更多关于「炼钢」能力的落地实践及其在 AI 云原生方向的最新动态。
报名地址:https://www.volcengine.com/contact/force-2506
....
#One RL to See Them All?
一个强化学习统一视觉-语言任务!
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。
近日,国内初创公司 MiniMax 提出了 V-Triune,一个视觉三重统一强化学习系统,它能使 VLM 在单一的训练流程中同时学习视觉推理和感知任务。
- 论文标题:One RL to See Them All
- 论文地址:https://arxiv.org/pdf/2505.18129
- 代码地址:https://github.com/MiniMax-AI
V-Triune 包含三个互补的组件:样本级数据格式化 (Sample-Level Data Formatting)(用以统一多样化的任务输入)、验证器级奖励计算 (Verifier-Level Reward Computation)(通过专门的验证器提供定制化奖励)以及数据源级指标监控 (Source-Level Metric Monitoring)(用以诊断数据源层面的问题)。
MiniMax 进一步引入了一种新颖的动态 IoU 奖励,它为 V-Triune 处理的感知任务提供自适应、渐进且明确的反馈。该方法在现成的 RL 训练框架内实现,并使用了开源的 7B 和 32B 骨干模型。由此产生的模型,MiniMax 称之为 Orsta (One RL to See Them All),在推理和感知任务上均展现出持续的性能提升。
这种广泛的能力很大程度上得益于其在多样化数据集上的训练,该数据集围绕四种代表性的视觉推理任务(数学、谜题、图表和科学)和四种视觉感知任务(目标定位、检测、计数和光学字符识别 (OCR))构建。
最终,Orsta 在 MEGA-Bench Core 基准测试中取得了显著的进步,其不同的 7B 和 32B 模型变体性能提升范围从 +2.1 到惊人的 +14.1,并且这种性能优势还扩展到了广泛的下游任务中。这些结果凸显了 MiniMax 新提出的统一 RL 方法应用于 VLM 的有效性和可扩展性。
V-Triune:视觉三重统一强化学习系统
V-Triune 的主要目标是使用单一、统一的训练流程,在视觉推理和感知任务上联合训练视觉-语言模型 (VLM),如图 2 所示。

该系统建立在三个核心且相互关联的部分之上,旨在协同处理这些多样化的任务。接下来将详细解释这三个核心组件,并介绍 MiniMax 新颖的动态 IoU 奖励机制。
样本级数据格式化
MiniMax 是如何格式化数据以支持跨感知和推理任务的统一训练的呢?
一个主要挑战是,不同任务可能需要不同类型的奖励、组件和加权策略。例如,像数学、谜题和光学字符识别 (OCR) 这样的任务,其奖励是基于文本答案的正确性来计算的,而检测和定位任务则依赖于空间度量,如 IoU 和边界框格式。
在传统的 RL 设置中,奖励计算通常在任务级别定义。虽然这允许外部实现模块化的奖励函数,但在需要细粒度控制时限制了灵活性。
许多多模态任务可能包含需要不同奖励策略的异构样本。例如,OCR 数据可能同时包含纯文本行和复杂表格,每种都需要不同的评估规则。
同样,检测样本在对象数量、标注完整性或视觉难度方面可能存在显著差异,这表明需要对奖励行为进行样本级的调整。
为了支持这种灵活性,MiniMax 直接在样本级别定义奖励配置。每个样本指定要计算的奖励类型、它们的相对权重以及要使用的关联验证器 (verifier)。这允许在训练期间进行动态奖励路由和细粒度加权,而无需修改核心训练逻辑。
它还可以通过简单调整元数据来支持课程学习 (curriculum learning) 或数据消融策略,使系统更具可扩展性和可维护性。

如图 3 所示,MiniMax 使用 Hugging Face datasets 实现他们的数据模式,它作为所有数据源的统一接口。
通过在单个样本级别定义 reward_model(包括奖励类型、像 accuracy_ratio /format_ratio 这样的权重)和 verifier(验证器)规范,实现了对奖励计算的细粒度控制。这使得能够灵活且可扩展地处理各种多模态任务。
总之,样本级格式化设计能够将多样化的数据集无缝集成到统一的训练流程中,同时允许高度灵活和可扩展的奖励控制。
验证器级奖励计算
与使用固定奖励函数的方法不同,MiniMax 实现了一个独立的、异步的奖励服务器来生成 RL 信号,以取代固定的奖励函数。 该系统基于 FastAPI 的异步客户端-服务器架构(图 4) 。

这种将奖励计算与主训练循环解耦的设计,带来了模块化、可扩展性、灵活性和高吞吐量等关键优势,尤其便于独立扩展和分布式处理。
奖励计算在「验证器级」进行:服务器将请求路由到用户定义的验证器,它们根据模型输出和真实标签计算任务奖励。MiniMax 主要使用两种:
- MathVerifyVerifier:通过评估答案正确性来处理推理、OCR 和计数任务。
- DetectionVerifier: 处理检测、定位任务,并支持动态 IoU 奖励。
这种验证器级架构极大地增强了系统的灵活性和模块化,使得添加新任务或更新奖励逻辑变得简单,且无需修改核心训练流程。
数据源级指标监控
在处理多任务、多源训练时,传统的聚合或单任务指标往往因为缺乏可追溯性以及无法反映各数据源的内在差异,而不足以深入理解模型动态或进行有效诊断。因此,MiniMax 采纳了数据源级指标监控 (Source-Level Metric Monitoring) 策略。
该方法的核心是为每个训练批次,按数据源分别记录关键性能指标。这种精细化的追踪方式具有显著优势:它不仅能帮助我们快速识别出表现不佳或存在问题的数据源,还能支持有针对性的调试,并有助于揭示不同数据源在学习过程中的相互作用与影响。
考虑到强化学习训练过程可能存在的不稳定性,这种细粒度的监控对于验证模型的稳定性和行为模式尤为重要,能够提供比许多标准 RL 基础设施更深入的洞察力。
具体来说,监控的关键指标包括:
- 各源奖励值:用以追踪不同数据集对模型训练的贡献及稳定性。
- 感知任务 IoU/mAP:按来源记录详细的 IoU 值(在多个阈值下)和 mAP 分数,以获得对模型在检测、定位等任务上收敛情况的细粒度见解。
- 响应长度与截断率:通过分析输出长度来判断模型是否存在生成内容过于冗长或坍塌 (collapsed generation) 的问题。
- 反思率 (Reflection Ratio):通过追踪特定反思词汇的出现频率及其与答案正确性的关联,来诊断模型的 “思考” 模式,例如是倾向于过度思考 (overthinking) 还是浅层响应 (superficial responses)。所有这些指标都按数据源持续记录。
动态 IoU 奖励
在目标检测和视觉定位任务中,MiniMax 选择 IoU 作为核心奖励机制,而非直接使用 mAP。实验表明,尽管 mAP 是评估标准,但基于阈值的 IoU 奖励能在达到相当性能的同时,提供更易于解释和控制的反馈信号(如图 5a 所示),这对于指导 RL 训练过程至关重要。

然而,设定一个固定的 IoU 阈值面临着两难境地。一方面,过于宽松的阈值(例如 𝜖 = 0.5 )虽然容易达成,但对于 VLM 的 RL 训练来说可能过于模糊,无法有效区分预测质量的细微差异,甚至可能因奖励模糊性导致模型在训练后期性能下降。
另一方面,采用非常严格的阈值(例如 𝜖 = 0.99 )虽然能确保预测与真实标签高度一致,增强感知与推理信号的统一性,并可能提升训练稳定性,但其严苛性会在训练初期引发冷启动 (cold-start) 问题 —— 大多数早期的、不完美的预测会获得 0 奖励,使得模型难以学习(如图 5b 所示)。
为了克服这一挑战,MiniMax 设计了动态 IoU 奖励策略。该策略借鉴了课程学习的思想,通过在训练过程中动态调整 IoU 阈值。
ϵ 来平衡学习效率和最终精度。具体做法是:在训练的初始 10% 步骤中使用相对宽松的 0.85 阈值,以便模型快速入门;在接下来的 15% 步骤中提升至 0.95;最后,在训练的剩余阶段采用 0.99 的严格阈值,以追求最高的定位精度(如图 6 所示)。这种渐进式的方法旨在平稳地引导模型学习,避免冷启动,同时确保最终的高性能。

训练方法
V-Triune 支持可扩展的数据、任务、验证器和指标系统。不过,早期实验表明,联合训练可能会导致不稳定,具体包括评估性能下降、梯度范数突然飙升、熵波动较大、响应长度突然增加,尤其是在输出错误的情况下。
为了解决训练不稳定性和可扩展性问题,MiniMax 进行了有针对性的调整,包括冻结 ViT 以防止梯度爆炸、过滤虚假图像 token、随机化 CoT 提示词以及解耦评估以在大规模训练期间管理内存。
禁用 ViT 训练
在初始实验中,MiniMax 的做法是通过联合优化 ViT 和 LLM 进行全参数训练。然而,无论超参数设置如何,检测性能在数十步之后都会持续下降。日志分析表明梯度范数异常大且出现峰值(通常 >1),这表明不稳定源于 ViT。对此分析,MiniMax 还进行了实验验证。

如图 7a 所示,联合训练会导致性能下降,而仅 LLM 训练则能维持稳定的提升。仅 ViT 训练的提升甚微,这表明强化学习的优势主要源于更新 LLM。图 7b 则表明,ViT 训练产生的梯度范数显著提高 —— 比仅 LLM 训练高出 10 倍以上。
逐层分析(图 7c)证实了这一点:LLM 梯度在各层之间保持稳定,而 ViT 梯度在反向传播过程中会放大 —— 第一层的范数比最后一层高 5 到 10 倍。这种梯度爆炸会破坏训练的稳定性,并损害视觉性能。
因此,MiniMax 选择在后续实验中冻结 ViT 的参数。
虽然这种不稳定性背后的根本原因仍未得到研究解释,但 MiniMax 提供了两个关键见解。
一、强化学习不仅激活了视觉 - 语言模型 (VLM) 的功能,还会强制模态对齐。当 ViT 和 LLM 联合训练时,视觉表征(即对齐目标)会不断变化,导致不稳定,类似于机器学习中的概念漂移(concept drift)问题。这种动态目标会导致优化不稳定,并可能导致模型崩溃。类似于 GAN 的交替训练(冻结一个组件的同时更新另一个组件)也许是一种解决方案。
二、ViT 的对比预训练可能会限制其在强化学习中的适用性,因为它会鼓励使用静态的实例级特征,而不是强化学习任务所需的动态因果表示。为了缓解这种不匹配,可以在强化学习期间引入辅助自监督目标,以帮助 ViT 适应不断变化的任务需求。
缓解虚假图像特殊 token
为了实现准确的优势估计,查询和生成响应的 logit 向量都会重新计算,因为推理引擎返回的 logit 向量可能不精确。在前向传递过程中,图像占位符(图 8 中红色框,出现在 “vision_end” token 之前)将被 ViT 和适配器模块提取的视觉特征替换。然而,模型可能会错误地生成缺少相应特征的特殊 token(图 8 中蓝色框),例如图像或视频占位符 —— 尤其是在 RL-zero 设置下。

为了确保输入特征对齐并保持训练稳定性,在重新计算之前,会应用一个过滤步骤,将所有此类特殊 token 从 rollout 序列中移除。
CoT 提示词池
在视觉数学任务训练的早期阶段,尽管 CoT 提示词传达的含义相同,但其差异可能会影响模型性能,影响准确度和响应长度等指标。为了减少这种差异,MiniMax 构建了一个 CoT 提示词池,其中包含 10 个「让 MiniMax 一步一步思考」的备选方案和 10 个「将答案放入 \boxed {}」的备选方案。
在训练期间,MiniMax 会从每组中随机选择一个句子并附加到指令中。此策略可以减轻提示词引起的差异,并会专门应用于使用 MathVerifyVerifier 验证的样本。
系统内存管理
V-Trinue 基于 Verl 实现,Verl 是一个单控制器训练框架,它可以接近主节点上的系统内存极限,尤其是在处理大规模视觉数据集时。
为了实现有效的 OOD 性能监控,MiniMax 会定期引入在线测试集基准测试。
为了减轻由此产生的系统开销,MiniMax 的做法是将测试阶段与主训练循环和批处理基准分离,从而绕过默认的 vLLM 数据处理。
实验表现如何?
MiniMax 自然也进行了实验验证。模型方面,他们采用了 Qwen2.5-VL-7B-Instruct 和 Qwen2.5-VL-32B-Instruct 作为基础模型。
V-Triune 的实现则基于 verl。MiniMax 启用原生 FSDP 进行训练,并使用 vLLM 进行生成。所有实验均在 64 块 NVIDIA H20 GPU 上完成。
此外,他们也进行了数据的整编,其中包括许多不同任务的数据集和两个过滤阶段:基于规则过滤以及基于难度过滤。最终,他们得到了一个包含 2.06 万感知样本和 2.71 万推理样本的语料库。

有关训练细节和评估基准的更多详细描述请参阅原论文,下面来重点看看主要实验结果。
MEGA-Bench
表 1 给出了 Orsta 与其骨干模型以及领先的通用 / 推理增强型 VLM 的全面比较。

可以看到,在 7B 和 32B 规模上,Orsta 均表现出了持续的提升:Orsta-7B 在 MEGA-Bench Core 上达到 38.31 (+3.2),Orsta-32B 达到 45.78 (+2.1)。
对于具有丰富训练数据的领域(数学、感知、规划和科学),MiniMax 的方法 V-Triune 为性能带来了显著提升。这表明其在推理和感知任务中均具有强大的泛化能力。相比之下,由于稀疏监督,编程和指标相关任务的提升有限,这凸显了新提出的统一强化学习训练方法的目标可扩展性。
图 11 展示了三个 Orsta 变体(7B、32B-0321、32B-0326)在在线策略和离线策略强化学习下的 MEGA-Bench 性能轨迹。

可以看到,所有变体均表现出稳定的改进,在线策略训练通常优于离线策略训练。7B 模型表现出更平滑、更显著的增益,而 32B 模型的进展则更慢或更不稳定 —— 表明规模更大时,优化难度也更大。
Qwen2.5-VL-0321 在感知和输出格式方面存在已知的问题,但在推理任务中表现可靠,这已得到 MiniMax 的评估和 VL-Rethinker 研究的证实。这些问题在后续的 0326 版本中得到了解决。MiniMax 认为 0321 版本是一个很不错的基线,具有核心知识能力。
如图 12 所示,Orsta-32B-0321 表明强化学习作为一种对齐机制,而不是引入新的能力,主要会增强现有模型的优势。在数学、感知、科学和规划等领域,性能提升最为显著,而在编程等领域外任务中则提升有限,这凸显了以对齐为重的强化学习的影响。

总而言之,MiniMax 的结果表明,强化学习能够在统一的框架内有效增强视觉推理和感知能力。强化学习在 MEGA-Bench Core 的 440 个不同任务上实现了持续的性能提升,表明其可以作为通用的对齐策略,能够释放预训练视觉-语言模型的潜力。
常见下游任务
表 2 给出了在常见视觉推理和感知任务上各模型的表现。

可以看到,在 7B 规模下 Orsta 的性能比其骨干模型高出 4%,在 32B-0326 规模下的性能比其骨干模型高出 1%。
在以数学为中心的 MathVista 基准上,Orsta 在所有模型规模上都实现了超过 5% 的性能提升。这些结果与 MEGA-Bench 数学任务上观察到的提升一致,进一步证明了 Orsta 在提升推理能力方面的优势。
视觉感知能力上,Orsta 在各个基准上均有提升。
在 COCO 检测任务上,Orsta-7B 取得了显著提升(单目标检测 +7.81 mAP 和 +12.17 mAP@50;多目标检测 +3.77 mAP 和 +5.48 mAP@50),在更简单的场景中提升尤为显著。Orsta-32B-0321 亦提升明显,并解决了先前的感知问题,而 Orsta-32B-0326 在两个子集上均实现了 +3% 的 mAP 提升。
在 OVDEval 测试上,Orsta-7B 和 32B 分别提升了 +5.3 和 +3.5 mAP,验证了动态 IoU 奖励的有效性。在 GUI 和 OCR 任务(ScreenSpotPro、OCRBench)上,Orsta-7B 和 32B 分别实现了 +5.3 和 +3.5 的 mAP 提升。在 CountBench 上的提升最为显著,Orsta-7B 的表现优于 32B SFT 模型,而 Orsta-32B 则创下了新的最高水平。
总体而言,V-Triune 对对齐程度较低的基础模型 (0321) 的感知改进比对已完成训练的模型 (0326) 的感知改进更大。
MiniMax 也进行了训练指标分析和消融研究,进一步验证了新方法的优势,详见原论文。
....
#Visual-ARFT(Visual Agentic Reinforcement Fine-Tuning)
让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力
在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
尽管开源研究社区在纯文本的智能体能力方面(比如函数调用和工具集成)已取得显著进展,但涉及图像理解与操作的多模态智能体能力及其对应的评估体系仍处于起步阶段。
因此,上海交大、上海 AI Lab、港中文、武汉大学的研究团队最新推出的多模态智能体训练方法 Visual-ARFT(Visual Agentic Reinforcement Fine-Tuning),专为赋予视觉语言模型(LVLMs)以「工具智能体」能力而设计。
并且,Visual-ARFT 项目已全面开源(包含训练、评测代码,数据和模型)。如果你对多模态模型、强化学习、视觉语言理解感兴趣,不妨一起来探索更多可能性吧!
论文标题:Visual Agentic Reinforcement Fine-Tuning
arXiv 地址: https://arxiv.org/pdf/2505.14246
代码地址: https://github.com/Liuziyu77/Visual-RFT/tree/main/Visual-ARFT
Visual-ARFT 让模型不仅能看图、能理解,还能「动脑推理、动手操作」,主要包括以下三个方面的核心能力:
- 模型能够自动调用搜索引擎查资料或者编写并执行 Python 代码处理图像;
- 面对复杂任务,能够自主拆解问题、规划步骤、调用合适工具完成任务;
- 支持多步推理、多模态输入,具备强大的跨模态泛化能力!
如图 1 所示,本文的方法编写并执行 Python 代码以精准读取图像中特定区域的文本(上图),或者通过互联网搜索回答多模态多跳问题(下图)。

图 1. 视觉智能体强化微调(Visual Agentic Reinforcement Fine-Tuning,简称 Visual-ARFT)在执行复杂的多模态推理任务中展现出显著优势,例如:(上图)编写并执行 Python 代码以精准读取图像中特定区域的文本,以及(下图)通过互联网搜索回答多跳问题。
同时,为了评估模型的工具调用和多模态推理能力,团队构建了智能体评测基准 MAT-Bench (Multimodal Agentic Tool Bench)。测试结果显示,Visual-ARFT 在多个子任务中全面超越 GPT-4o,通过调用工具 ——「写代码 + 查资料」,展现出了完成复杂多模态视觉任务的强大潜力。
方法概览
Visual-ARFT 基于强化微调的训练策略,使用 GRPO 的算法来更新模型权重。团队针对多模态智能体完成任务的流程,对 LVLM 的多步工具调用和问题回答设计了 rule-based verifiable reward。通过简单高效的 reward 设计,驱动模型自主探索工具的使用方法和思考模式。
团队在训练中使用几十到最多 1.2k 的训练数据,通过少量数据实现了对模型的多模态智能体能力的训练。

图 2. Visual-ARFT 框图。主要针对 Agentic Search 和 Agentic Coding 两类任务的多步推理和工具调用能力进行优化。
Visual-ARFT 针对以下两类高难度任务场景进行强化训练:
- Agentic Search:模型面对多模态的多跳复杂问题,先对视觉信息进行分析和推理,然后能够主动进行任务分解、规划信息检索路径,通过调用搜索引擎获取外部知识并整合作答。
- Agentic Coding:模型面对模糊、旋转、曝光过强等复杂图像,能主动生成 Python 代码完成图像修复,或剪裁图像,提取关键区域,并据此完成视觉问答。
在这一过程中,模型并非简单输出结果,而是具备完整的推理结构:
每一步都以 <think> 思考引导、<search> 检索信息、<code> 编写程序、<answer> 给出结论,真正形成可解释的多模态认知路径。
MAT 基准
团队发布了全新的多模态智能体评测基准:MAT(Multimodal Agentic Tool Bench),专门评估多模态工具调用能力:
- MAT-Search:包含 150 道多跳视觉问答任务,人工标注 + 搜索推理;
- MAT-Coding:包含 200 道复杂图像问答任务。模型可以直接作答或通过调用代码工具处理图像,辅助作答。
这一基准填补了当前开源模型在「多模态智能体以及工具调用」方面的评估空白。

图 3. MAT 数据标注过程。MAT-Search 采用人工标注方法构建多模态多跳推理 VQA 数据,MAT-Coding 采用自动化流程构造针对 Agentic Coding 任务的 VQA 数据。
Visual-ARFT 实验结果
团队基于 Qwen2.5-VL 模型在 MAT 上对本文方法进行了测试。结果显示,无论在 MAT-Search 还是在 MAT-Coding 上,本文方法都较 baseline 有了显著的提升,并击败了 GPT-4o 模型。
相较于 baseline 模型直接推理的方式,本文方法通过让 LVLM 学会推理与调用工具,在解决复杂的多模态任务时,更加的得心应手。此外,团队观察到 OpenAI-o3 模型在一众开源闭源中取得了遥遥领先的性能,尤其是在 MAT-Coding 上,凭借其多模态推理和工具调用能力,断层式超越了 GPT-4o 模型。

表 1. MAT 测试结果。 Visual-ARFT 相较 baseline 取得了显著性能提升,击败 GPT-4o。开闭源模型距离 OpenAI-o3 模型存在较大性能差距。
为了测试本文方法的泛化能力,团队选取了 4 个 Out of Domain 的传统 MultihopQA Benchmark 来测试他们的模型,包括 2wikimlutihopQA,HotpotQA,MuSiQue 和 Bamboogle。
结果显示基于 Visual-ARFT 的 Qwen2.5-VL 模型虽然仅仅使用几十条数据进行训练,但是模型获得在这些多跳推理数据集上展现出了显著的性能提升,并击败了其他基于强化学习的方法。

表 2. 传统 MultihopQA 测试结果。团队在 Out of Domain 的多个 multihopQA 上测试了本文方法,展现出 Visual-ARFT 的强大泛化能力。
....
#Large Language Model Psychometrics
北大团队发布首篇大语言模型心理测量学系统综述:评估、验证、增强
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。
论文标题:Large Language Model Psychometrics: A Systematic Review of Evaluation, Validation, and Enhancement
论文链接:https://arxiv.org/abs/2505.08245
项目主页:https://llm-psychometrics.com
资源仓库:https://github.com/valuebyte-ai/Awesome-LLM-Psychometrics
背景
大语言模型(LLMs)的出现,推动了人工智能技术的快速发展。它们在自然语言理解和生成等方面表现出较强的通用能力,并已广泛应用于聊天机器人、智能搜索、医疗、教育、科研等多个领域。AI 正逐步成为社会基础设施的重要组成部分。
与此同时,如何科学、严谨地评估这些能力不断提升的 AI 系统,成为亟需解决的问题。 LLM 评估面临的挑战包括但不限于:
- LLMs 展现出的「心智」特征(如性格、价值观、认知偏差等)超出了传统评测的覆盖范围;
- 模型的快速迭代和训练数据的持续更新,使得静态基准测试难以长期适用;
- LLMs 对提示和上下文高度敏感,评估结果易受细微变化影响,难以保证结果的稳定性和有效性;
- 随着 AI 与人类交互的日益深入,单纯依赖任务分数的评估方式已难以满足「以人为本」的需求;
- AI 逐步应用于多模态和智能体系统,对评估方法的广度和深度提出了更高要求。
这些挑战与心理测量学长期关注的核心问题高度契合:如何科学量化和理解复杂、抽象的心理特质(如知识、技能、性格、价值观等)。心理测量学通过将这些特质转化为可量化的数据,为教育、医疗、商业和治理等领域的决策提供支持。
将心理测量学的理论、工具和原则引入大语言模型的评估,为系统理解和提升 AI「心智」能力提供了新的方法路径,并推动了「LLM 心理测量学(LLM Psychometrics)」这一交叉领域的发展。这一方向有助于更全面、科学地认识和界定人工智能的能力边界。
主要内容
这篇综述论文首次系统梳理了 LLM 心理测量学的研究进展,结构如下图所示。

心理测量和 LLM 基准的差异与评估原则的革新

图:心理测量学和 AI 基准的对比
在大语言模型的评估领域,传统 AI 基准测试和心理测量学看似都依赖测试项目和分数来衡量能力,但两者的内核却截然不同。
传统 AI 评测更注重模型在具体任务上的表现和排名,强调测试的广度和难度,往往依赖大规模数据集和简单的准确率指标,结果多局限于特定场景,难以反映模型的深层能力。
而心理测量学则以「构念」为核心,追求对心理特质的深入理解,强调测试项目的科学设计和解释力,采用如项目反应理论(IRT)等先进统计方法,力求让测试结果既可靠又具备预测力,能够揭示个体在多样认知任务中的表现规律。 正是基于这种理念的转变,研究者们提出了三大创新方向。
首先,使用「构念导向」的评估思路,不再满足于表层分数,而是深入挖掘影响模型表现的潜在变量。
其次,研究者们引入心理测量学的严谨方法,提出证据中心基准设计等新范式,结合心理测量学辅助工具,规避数据污染,提升测试的科学性和可解释性。
最后,研究者们将项目反应理论应用于 AI 评测,实现了动态校准项目难度、智能调整权重、自动生成不同难度的新测试项目,并探索了 AI 与人类反应分布的一致性,使得不同 AI 系统间、AI 与人类之间的比较更加科学和公平。
这一系列革新,正推动 AI 评估从「分数导向」走向「科学解码」,为理解和提升大语言模型的「心智」能力打开了全新视角。
测量构念的扩展
LLM 展现出类人的心理构念,这些构念对模型行为产生深远影响,包括人格构念(性格,价值观,道德观,态度与观点)、能力构念(启发式偏差,心智理论,情绪智能,社交智能,心理语言学能力,学习认知能力)。该综述系统梳理了针对这些心理构念的评估工作,综述了相关理论、工具和主要结论。

测量方法
LLM 心理测量学的方法体系为 LLM「心智」能力的系统评估奠定了基础,主要包括测试形式、数据来源、提示策略、输出评分和推理参数五个方面。
测试形式分为结构化(如选择题、量表评分,便于自动化和客观评估,但生态效度有限)和非结构化(如开放对话、智能体模拟,更贴近真实应用,能捕捉复杂行为,但标准化和评分难度较高)。
数据与任务来源既有标准心理学量表,也有人工定制项目以贴合实际应用,还有 AI 生成的合成项目,便于大规模多样化测试。提示策略涵盖角色扮演(模拟不同身份特征)、性能增强(如思维链、情感提示提升能力)、以及提示扰动和对抗攻击(测试模型稳定性)。
输出与评分分为封闭式(结构化输出,基于概率或预设标准)和开放式(基于规则、模型或人工评分),后者更具挑战性。推理参数(如解码方式)也会影响评估结果,需结合确定性与随机性设置,全面揭示模型特性。

测量验证
与传统 AI 基准测试不同,LLM 心理测量学强调理论基础、标准化和可重复性,需建立严格的验证体系以确保测试的可靠性、效度和公平性。
本文系统梳理了三个关键方面:
首先,可靠性关注测试结果的稳定性,包括重测信度、平行形式信度和评分者信度;当前测试的信度面临挑战,如 LLM 在提示扰动中表现出不稳定性。
其次,效度评估测试是否准确测量目标构念,涉及内容效度、构念效度和校标效度等,主要挑战包含数据污染、LLM 与人类在心理构念的内部表征上存在差异,评估结果向真实场景的可迁移性等。
最后,文章归纳了近期研究提出的标准和建议,为 LLM 心理测量学建立科学方法论基础。

基于心理测量学的增强方法
心理测量学不仅为 LLM 评估提供理论基础,也为模型开发和能力提升开辟了新路径。当前,心理测量学主要在特质调控、安全对齐和认知增强三大方向增强 LLM。
特质调控方面,通过结构化心理量表提示、推理干预和参数微调等方法,LLM 能够模拟和调节多样的人格特质,广泛应用于个性化对话、角色扮演和人口模拟。
安全对齐方面,研究揭示了模型心理特质与安全性、价值观对齐的密切关系,借助价值观理论、道德基础理论和强化学习等手段,推动模型更好地契合人类期望与伦理标准。
认知增强方面,心理学启发的提示策略、角色扮演及偏好优化等方法,有效提升了 LLM 的推理、共情和沟通能力。
整体来看,心理测量学为 LLM 的安全性、可靠性和人性化发展提供了坚实支撑,推动 AI 迈向更高水平的智能与社会价值。
未来展望
该综述总结了 LLM 心理测量学的发展趋势、挑战与未来方向。当前,LLM 在人格测量及其验证上取得初步成果,但能力测试的信效度验证和广泛测试的真实场景泛化仍待加强。传统人类构念难以直接迁移,需发展适用于 LLM 的新理论和测量工具。
研究还需区分模型表现出的特质(perceived traits)与对齐特质(aligned traits),关注评估主观性。模型拟人化方式、统计分析方式及多语言、多轮交互、多模态和智能体环境等新维度带来挑战。项目反应理论(IRT)为高效评估和模型区分提供新思路。
未来还应推动心理测量在模型增强和训练数据优化等方面的应用。 AI 发展已进入「下半场」,评估的重要性与挑战性日益凸显。LLM 心理测量学为评估人类水平 AI 提供了重要范式,有助于推动 AI 向更安全、可靠、普惠的方向发展。
....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 37
37 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)