51c大模型~合集148
我自己的原文哦~https://blog.51cto.com/whaosoft/14029691Oral工作再升级!上海AI Lab联合复旦、港中文推出支持更长视频理解的最佳工具本文第一作者魏熙林,复旦大学计算机科学技术学院人工智能方向博士生,研究方向是多模态大模型、高效长上下文;目前在上海人工智能实验室实习,指导 mentor 是臧宇航、王佳琦。一、背景介绍虽然旋转位置编码(RoPE)及其变体因
我自己的原文哦~ https://blog.51cto.com/whaosoft/14029691
#VideoRoPE++
Oral工作再升级!上海AI Lab联合复旦、港中文推出支持更长视频理解的最佳工具
本文第一作者魏熙林,复旦大学计算机科学技术学院人工智能方向博士生,研究方向是多模态大模型、高效长上下文;目前在上海人工智能实验室实习,指导 mentor 是臧宇航、王佳琦。
一、背景介绍
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
VideoRoPE++ 这项工作首先进行了全面分析,确定了将 RoPE 有效应用于视频所需的五个关键特性,而先前的工作并未充分考虑这些特性。
作为分析的一部分,这项工作构建了一个全新的评测基准 ——V-RULER,其中的子任务 “带干扰项的大海捞针(Needle Retrieval under Distractor, NRD)” 表明:当前 RoPE 变体在缺乏合理时间维度建模策略时,容易被周期性干扰项误导,表现不稳定。
基于分析,作者提出了 VideoRoPE++,它具有三维结构,旨在保留时空关系。VideoRoPE 的特点包括低频时间分配以减轻周期性碰撞、对角布局以保持空间对称性,以及可调整的时间间隔以解耦时间和空间索引。
此外,为提升模型在训练范围之外的外推能力,作者团推还提出了外推方案 ——YaRN-V。该方法仅在低频时间轴上进行插值,同时保持空间维度的稳定性与周期性,从而实现在长视频场景下的结构一致性与外推鲁棒性。在长视频检索、视频理解和视频幻觉等各种下游任务中,VideoRoPE++ 始终优于先前的 RoPE 变体。
Paper: https://github.com/Wiselnn570/VideoRoPE/blob/main/VideoRoPE_plus.pdf
Project Page: https://wiselnn570.github.io/VideoRoPE/
Code:https://github.com/Wiselnn570/VideoRoPE/

二、分析

左图:为了展示频率分配的重要性,基于 VIAH(a),作者提出了一个更具挑战性的 benchmark: V-RULER,子任务 Needle Retrieval under Distractors 如(b)所示,其中插入了相似图像作为干扰项。右图:与 M-RoPE 相比,VideoRoPE++ 在检索中更具鲁棒性,并且不容易受到干扰项的影响。

上图:M-RoPE 的时间维度局限于局部信息,导致对角线布局。下图:VideoRoPE++ 有效利用时间维度进行检索。M-RoPE 在定位目标图像上有效,但在多选问题中表现不佳,因为它主要通过垂直位置编码来定位图像,而非时间特征,导致时间维度未能捕捉长距离依赖关系,关注局部信息。相比之下,空间维度则捕捉长距离语义信息,导致 M-RoPE 在频率分配设计上表现较差。
三、VideoRoPE ++ 设计
作者团队提出了 VideoRoPE++,一种视频位置嵌入策略,优先考虑时间建模,通过低频时间分配(LTA)减少振荡并确保鲁棒性。它采用对角线布局(DL)以保持空间对称性,并引入可调时间间隔(ATS)来控制时间间隔,以及提出 YaRN-V 对训练范围以外的位置信息进行外推。VideoRoPE++ 有效地建模了时空信息,从而实现了鲁棒的视频位置表示。
1. 低频时间分配 (LTA):

考虑一个基于 RoPE 的 LLM,头部维度为 128,对应 64 个旋转角度 θn,分布在不同维度上。每个图示中,用平行的蓝色平面表示 cos (θnt) 在 3 维上的表现。
(a)对于 M-RoPE,时间依赖性由前 16 个高频旋转角度建模,导致振荡和位置信息失真。低维度间隔较短,振荡周期性使得远距离位置可能具有相似信息,类似哈希碰撞(如红色平面所示),容易引发干扰,误导模型。
(b)相比之下,VideoRoPE++ 通过最后 16 个旋转角度建模时间依赖性,具有更宽的单调间隔。时间建模不再受振荡影响,显著抑制了干扰项的误导效应。
2. 对角线布局 (DL) :

原始 1D RoPE(Su et al., 2024)未包含空间建模。M-RoPE(Wang et al., 2024b)虽然采用 3D 结构,但引入了不同帧间视觉标记索引的差异。相比之下,VideoRoPE++ 实现了平衡,保留了原始 RoPE 一致的索引增长模式,并引入了空间建模。优点包括:1)保留视觉标记的相对位置,避免文本标记过于接近角落;2)保持原始 RoPE 编码形式,相邻帧的空间位置信息增量与文本标记增量一致。
3. 可调时间间隔 (ATS) :
为了缩放时间索引,作者团队引入缩放因子 δ 来对齐视觉和文本标记之间的时间信息。假设 τ 为标记索引,起始文本(0 ≤ τ < Ts)的时间、水平和垂直索引为原始标记索引 τ。对于视频输入(Ts ≤ τ < Ts + Tv),τ − Ts 表示当前帧相对于视频开始的索引,通过 δ 缩放控制时间间距。对于结束文本(Ts + Tv ≤ τ < Ts + Tv + Te),时间、水平和垂直索引保持不变,形成线性进展。根据可调节的时间间距设计,视频位置编码(VideoRoPE++)中 τ-th 文本标记或(τ, w, h)-th 视觉标记的位置信息(t, x, y)如式(7)所示。

其中,w 和 h 分别表示视觉块在帧中的水平和垂直索引。
4. 基于 YaRN-V 的外推能力

在视频理解任务中,时空维度的差异性对位置编码提出了特殊挑战:空间信息(如纹理与边缘)通常具有局部性和周期性,而时间信息则跨越更长且不确定的范围,依赖更广的上下文建模。为解决这一不对称性,作者提出了 YaRN-V,一种仅沿时间维度进行频率插值的外推方法,同时保持空间维度不变。该选择性设计在保留空间结构的同时,有效提升了长视频建模中的时间泛化能力。YaRN-V 的设计依据于空间与时间维度在频域特性上的本质差异:空间维度处于高频段,训练中已完成一个完整周期,因此模型能自然泛化至未见过的空间位置;而时间维度处于低频段,训练范围内无法覆盖完整周期,因此仅对时间轴插值便可实现有效的长时外推。
四、实验结果
长视频检索任务:
作者团队展示了 VideoRoPE++ 与其他 RoPE 变体在 V-RULER 上的性能。Vanilla RoPE 和 TAD-RoPE 在视觉训练上下文外具备一定外推能力,但超出极限后失效。相比之下,VideoRoPE 和 M-RoPE 在测试上下文内表现优越,且 VideoRoPE 始终优于 M-RoPE,展现出更强鲁棒性。

长视频理解任务:
如表所示,作者团队在三个长视频理解基准上比较了 VideoRoPE++ 与现有 RoPE 变体(Vanilla RoPE、TAD-RoPE 和 M-RoPE)。VideoRoPE++ 在这些基准上优于所有基线方法,展示了其鲁棒性和适应性。在 LongVideoBench、MLVU 和 Video-MME 上,VideoRoPE++ (Qwen2 基座) 在 64k 上下文长度下分别比 M-RoPE 提高了 2.91、4.46 和 1.66 分,突显了其在捕捉长距离依赖关系和处理具有挑战性的视频任务中的卓越能力。

外推任务:

在本次实验中,作者针对超出训练范围的长序列输入,系统评测了多种位置外推方案。在 V-RULER 基准中的 Lengthy Multimodal Stack 任务上,作者提出的方法 YaRN-V 以 81.33 的得分显著领先,较最强基线 YaRN 提升 13.0 分,稳健应对混合模态干扰下的超长位置索引。相比之下,传统位置编码方案已完全失效,而 NTK-Aware(67.66)和 MRoPE++(62.30)等方法虽有一定泛化能力,但整体表现仍有限。
实验结果表明,YaRN-V 能更好支撑视频大模型在长输入场景下的时间对齐,避免位置溢出带来的性能衰退,是多模态长序列理解的理想方案。
五、总结
本文确定了有效位置编码的四个关键标准:2D/3D 结构、频率分配、空间对称性和时间索引缩放。通过 V-NIAH-D 任务,作者展示了先前 RoPE 变体因缺乏适当的时间分配而易受干扰。因此,提出了 VideoRoPE++,采用 3D 结构保持时空一致性,低频时间分配减少振荡,对角布局实现空间对称性,并引入可调节时间间距和外推方案 YaRN-V。VideoRoPE++ 在长视频检索、视频理解和视频幻觉任务中优于其他 RoPE 变体。
#ReMA
Meta-Think ≠ 记套路,多智能体强化学习解锁大模型元思考泛化
本文第一作者为上海交通大学计算机科学四年级博士生万梓煜,主要研究方向为强化学习、基础模型的复杂推理,通讯作者为上海交通大学人工智能学院温颖副教授和上海人工智能实验室胡舒悦老师。团队其他成员包括来自英属哥伦比亚大学的共同第一作者李云想、Mark Schmidt 教授,伦敦大学学院的宋研、杨林易和汪军教授,上海交通大学的温潇雨,王翰竟和张伟楠教授。
引言
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。然而,大模型何时产生 “顿悟(Aha Moment)” 的机理仍未明晰。近期多项研究提出推理模式(reasoning pattern)对于推理能力的重要作用。类似的,本研究认为
大模型复杂推理的能力强弱本质在于元思维能力的强弱。
所谓 “元思维” (meta-thinking),即监控、评估和控制自身的推理过程,以实现更具适应性和有效性的问题解决,是智能体完成长时间复杂任务的必要手段。大语言模型(LLM)虽展现出强大推理能力,但如何实现类似人类更深层次、更有条理的 "元思维" 仍是关键挑战。

上图通过两台机器人求三角形高线的截距的解决样例,直观展示了元思维与推理的分工:推理机器人执行计算,元思维机器人则在关键节点介入进行规划、拆解或纠错。基于这个动机,本研究提出从多智能体的角度建模并解决这个问题并引入强化元思维智能体(Reinforced Meta-thinking Agents, 简称 ReMA)框架,利用多智能体间的交互来建模大模型推理时的元思维和推理步骤,并通过强化学习鼓励整个系统协同思考如何思考,以兼顾探索效率与分布外泛化能力。
论文题目:ReMA: Learning to Meta-think for LLMs withMulti-agent Reinforcement Learning
论文链接:https://arxiv.org/abs/2503.09501
Github 代码链接: https://github.com/ziyuwan/ReMA-public
当前,提升大模型推理能力的研究主要分为两种思路:
一是构造式的方法:通过在结构化的元思维模板上采样与搜索构造数据进行监督微调,但这类方法往往只是让模型记住了这种回答范式,而没有利用模型内在的推理能力进行灵活探索以发现模型本身最适合的元思维模式,因此难以泛化到分布外的问题集上;
二是 Deepseek R1 式的单智能体强化学习(SARL)方法:通过引入高质量退火数据获得具备一定的混合思维能力的基础模型后,直接使用规则奖励函数进行强化学习微调,习得混合元思维和详细推理步骤。但这类方法通常依赖强大的基础模型,对于能力欠缺的基础模型来说在过大的动作空间内无法进行高效探索,且不用说可能导致的可读性差等问题。

图一:ReMA框架与现有大模型复杂推理训练框架对比
针对这些挑战,ReMA 框架采取了一套全新的解决思路,将复杂的推理过程解耦为两个层级化的智能体:
1. 元思维智能体 (Meta-thinking agent)

: 负责产生战略性的监督和计划,进行宏观的思考和指导,并在必要的时刻对当前的推理结果进行反思和修正。
2. 推理智能体 (Reasoning agent)

: 负责根据元思维智能体的指导,执行详细的子任务,如单步推理和具体计算等。
这两个智能体通过具有一致目标的迭代强化学习过程进行探索和协作学习。这种多智能体系统(MAS)的设计,将单智能体强化学习的探索空间分散到多个智能体中,使得每个智能体都能在训练中更结构化、更有效地进行探索。ReMA 通过这种方式来平衡了泛化能力和探索效率之间的权衡。
方法
ReMA 的生成建模
本研究首先给出单轮多智能体元思维推理过程(Multi-Agent Meta-thinking reasoning process,MAMRP)的定义。
在单轮交互场景下,当给定一个任务问题时,元思维智能体会对问题进行宏观分析和必要拆解,产生求解计划,而推理智能体会根据元思维的逐步指令完成任务内容。具体来说,给定问题,元思维智能体首先给出元思维,接着推理智能体给出问题求解,该过程如下所示:

而在多轮交互场景中,元思维智能体给出的元思维可以以一种更加均匀的方式加入到整个思考过程中,元思维智能体可以显式地对求解的过程进行计划、拆解、反思、回溯和修正,其交互历史会不断叠加直至结束。类似的,本研究可以给出多轮 MAMRP 的定义,该过程如下所示:

整个系统的求解过程可以用以下有向图来直观理解:


图二:不同算法框架的训练方式对比
单轮 ReMA 的训练
单轮场景下,考虑两个智能体和 ,团队通过迭代优化的方式最大化两个智能体各自的奖励,从而更新智能体们各自的权重:

其中每个智能体的奖励函数分别考虑了总体回答正确性与各自的格式正确性。对于策略梯度的更新算法,本研究使用目前主流的 GRPO 和 REINFORCE++ 来节省显存和加速训练。
多轮 ReMA 的训练
在扩展到多轮场景下时,为了提升计算效率和系统可扩展性,团队做了如下改变:
(1)首先是通过共享参数的方式降低维护两份模型参数的部署开销,同时简化调度两份模型参数的依赖关系,提高效率。具体来说,本研究使用不同的角色的系统提示词来表示不同智能体的策略


,在优化时同时使用两个智能体的采样数据进行训练,更新一份参数。
(2)其次是针对多轮交互场景的强化学习,不同于本研究将每一轮的完整输出定义为一个动作,通过引入轮次级比率(turn-level ratio)来进行 loss 归一化与剪切, 具体优化目标如下所示:

其中:

通过这样的方式,在多轮训练的过程中,能够消除 token-level loss 对于长度的 bias,另外通过考虑单轮所有 token 的整体裁切,可以一定程度上稳定训练过程。
实验结果
单轮 ReMA 的实验
首先团队在单轮设定上对比了一般 CoT 的 Vanila Reasoning Process (VRP),以及其 RL 训练后的结果 VRP_RL, MRP_RL。团队在多个数学推理基准(如 MATH, GSM8K, AIME24, AMC23 等)和 LLM-as-a-Judge 基准(如 RewardBench, JudgeBench)上对 ReMA 进行了领域内外泛化的广泛评估。在数学问题上,团队使用了 MATH 的训练集(7.5k)进行训练,在 LLM-as-a-Judge 任务上则将 RewardBench 按子类比例划分为了 5k 训练样本和 970 个测试样本进行训练和领域内测试。

表一:单轮ReMA的实验对比
结果显示,在多种骨干预训练模型(如 Llama-3-8B-Instruct, Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct)上,ReMA 在平均性能上一致优于所有基线方法。特别是在分布外数据集上,ReMA 在大多数基准测试中都取得了最佳性能,充分证明了其元思索机制带来的卓越泛化能力。例如,在使用 Llama3-8B-Instruct 模型时,ReMA 在 AMC23 数据集上的性能提升高达 20%。
消融实验
为了证明 ReMA 中多智能体系统的引入对于推理能力的训练有益,团队在单轮设定下分别对二者的强化学习训练机制进行了消融实验。
问题一:元思维是否可以帮助推理智能体进行强化学习训练?

团队分别对比了三种强化学习训练策略,RL from base 采用了基础模型直接进行 RL 训练;RL from SFT 在 RL 训练开始前先用 GPT-4o 的专家数据进行 SFT 作为初始化;RL under Meta-thinking 则在 RL 训练时使用从 GPT-4o 生成的元思维数据 SFT 过后的元思维智能体提供高层指导。
图三展示了训练过程中三种不同难度的测试集上的准确率变化趋势,实验结果证明了元思维对于推理模型的强化学习具有促进作用,尤其是在更困难的任务上具有更好的泛化性。
问题二:LLM 是否能够通过强化学习演化出多样的元思维?

图四:不同规模的元思维智能体的强化学习训练演化过程
接着团队探索了不同规模的元思维智能体的强化学习训练演化过程,团队设计了一个可解释性动作集合。通过让模型输出 JSON 格式的动作(先确定动作类型(DECOMPOSE,REWRITE,EMPTY),再输出相应的内容),以实现对模型输出动作类型的监控。图四展示了三种动作类型对应的问题难度在训练中的变化,实验发现,在小模型上进行训练时(Llama3.2-1B-Instruct),元思维策略会快速收敛到输出简单策略,即 “什么都不做”;而稍大一些的模型(如 Llama3.1-8B-Instruct)则能够学会根据问题难度自适应的选择不同的元思维动作。这个结果也意味着,现在越来越受到关注的自主快慢思考选择的问题,一定程度上可以被 ReMA 有效解决。
多轮 ReMA 的实验

图五:多轮ReMA的实验结果
最后,团队扩展到多轮设定下进行了实验。首先,由于大多数语言模型本身不具备将问题拆解成多轮对话来完成的能力,团队先从 LIMO 数据集中转换了 800 条多轮 MAMRP 的样本作为冷启动数据,接着使用 SFT 后的权重进行强化学习训练。图五左侧展示了在 MATH level 3-5 (8.5k)数据集上的训练曲线和在七个测试集上的平均准确率。团队发现了以下结论:
1. 多轮 ReMA 训练在训练集上可以进一步提升,但是在测试集上的提升不明显。
2. 训练具有不稳定性,并且对超参数很敏感,不同的采样设定(单轮最大 token 数和最大对话轮数)间会有不同的训练趋势。
图五右侧展示了前文中提出的两个改进(共享参数更新和轮次级比率)对于多轮训练的影响,团队采样了一个包含所有问题类型的小数据集以观察算法在其上的收敛速度和样本效率。不同采样设定下的实验结果均表明该方案能够有效提升样本效率。
总结
总的来说,团队尝试了一种新的复杂推理范式,即使用两个层次化的智能体来显式区分推理过程中的元思维,并通过强化学习促使他们协作完成复杂推理任务。团队在单轮与多轮的实验上取得了一定的效果,但是在多轮训练的中还需要进一步解决训练崩溃的问题。这表明目前基于 Deterministic MDP 的训练流程也许并不适用于 Stochastic/Non-stationary MDP,对于这类问题的数据、模型方面还需要有更多的探索。
#Mirage
全球首款AI原生UGC游戏引擎诞生!输入文字秒建GTA世界,试玩体验来了
从此,游戏的未来不单单由专业设计师逐关打造,而是让每一个人都能实时构思、生成并体验游戏世界。
就在今天,全球首个由实时世界模型驱动的 AI 原生游戏引擎问世了!
该游戏引擎名为「Mirage」,由 Dynamics Lab 开发。
该系统专为构建动态、交互式且持续演变的游戏体验而设计,玩家可以通过自然语言、键盘或控制器实时生成并修改整个游戏世界。

从功能定位来看,Mirage 支持多类型的游戏开发。
,时长01:14
目前发布了两款可玩游戏演示,包括都市乱斗(GTA 风格)和海岸漂移(极限竞速地平线风格)。
都市乱斗:https://demo.dynamicslab.ai/chaos
海岸漂移:https://demo.dynamicslab.ai/drift
所有场景都是实时动态生成的,并非预设脚本。我们看到的是一个随着玩家操作实时演变的可交互动态模拟世界。

都市乱斗(GTA 风格)

海岸漂移(极限竞速地平线风格)
xx上手试玩了一下都市乱斗(GTA 风格),打开后界面是下面这样的,左边是控制选项,右边是街景选项。

体验了一小会,我们发现:游戏延迟还比较高,人物前后左右移动的灵敏度有进一步提升的空间。
,时长00:30
团队成员 Zhiting Hu 在 𝕏 上分享了延迟的可能原因,其中最大的延迟来源应该是网络延迟。

Mirage 还支持用户上传初始图片,然后进行游戏,xx用一张公司附近的照片进行了测试,视频如下:
,时长00:47
虽然当前体验效果与心中的预期仍有差距,但 Mirage 代表着 AI 技术的前沿突破。
相较于谷歌的 AI Doom/Genie、Decart 的 AI Minecraft 以及微软的《雷神之锤 II》AI 版等近期成果,Mirage 具备以下三大显著优势:
- 实时 UGC 创作:支持游戏过程中实时通过文本输入生成内容,在基于世界模型的游戏生成领域实现重大突破。
- 影视级画质呈现:超越早期系统的像素块风格,实现照片级真实感视觉效果。
- 持久交互体验:连续交互时长突破十分钟,大幅扩展生成式游戏的可持续体验边界。
评论区的网友对 Mirage 给予了很高的评价与期待。

想要体验的小伙伴,赶紧去,目前服务器可能已经处于崩溃边缘了。

开发团队坚信:随着实时生成技术的持续突破,Mirage 必将重塑游戏产业的未来格局。
,时长00:21
UGC 2.0:生成式游戏的崛起
传统游戏采用预制设计:城市布局固定、任务脚本预设、体验存在终局。而 Mirage 打破了这一边界,让玩家在游戏过程中实时创造全新体验。
通过自然语言指令、键盘输入或控制器操作,玩家可随时生成逃亡巷道、召唤载具或扩展城市天际线。系统将即时响应,将这些用户生成元素无缝融入持续运行的模拟世界 —— 游戏世界不仅是可交互的,更在与玩家共同进化。
Mirage 支持从竞速、角色扮演到平台跳跃的多元游戏类型:
,时长00:15
这就是 UGC 2.0 的革新世界:
- 零门槛创作:仅需文本描述,人人皆可生成专属游戏世界。
- 实时共创演化:玩家在游戏进程中即时创造、演进并重塑游戏内容。
- 无限动态体验:每次体验皆独一无二,永不重复,彻底告别预设脚本。
基于下一代 AI 构建
Mirage 基于前沿的 World Model 研究,采用了基于 Transformer 的大规模自回归扩散模型,能够生成可控的高保真视频游戏序列。据介绍,该技术框架融合了多项关键创新:
基于游戏进行的基础训练
Mirage 建立在强大的训练基础上 —— 目标是理解和生成丰富的游戏体验。这一基础始于从互联网上大规模收集各种游戏数据 —— 这些数据可提供捕捉各种游戏机制和风格所需的广度。
为此,Dynamics Lab 构建了一个专门的数据记录工具,可用于捕捉高质量的人类录制的游戏互动。通过细致的、高保真度的样本,这些精心编排的流程丰富了数据集,从而可以训练模型掌握复杂的玩家行为和游戏情境逻辑。
随后,收集和记录的数据会被输入到一个垂直训练流水线 —— 一种专注于游戏领域的特定训练方法。这使得模型能够深入内化游戏世界规则、系统模式和交互动态。
最终,该模型能够生成连贯、逼真且灵活的游戏内容,进而突破了传统预先编写游戏的限制。
交互式生成与实时控制的结合
通过将帧级提示词处理集成到其核心,Mirage 重新定义了实时交互。这使得玩家能够输入命令或提示 —— 它们会在游戏进行中被即时解释。
支持通过云游戏随时随地畅玩:
- 动态输入系统:Mirage 能以超低延迟处理玩家输入(主要通过键盘和文本),实现近乎即时的响应。
- 实时输出:视觉更新通过一个全双工通信管道传输回浏览器;在这个管道中,输入和输出并行流动,从而消除延迟并确保流畅的交互。
具体技术上,Mirage 基于一个定制版因果 Transformer 模型,并进行了以下增强:
- 专用视觉编码器
- 经过改进的位置编码
- 针对扩展式交互序列优化的结构
Mirage 集中了 LLM 和扩散模型的优势,支持生成连贯、高质量的内容。为了同时保证速度和质量,该团队还在其扩散组件中使用的蒸馏策略。
游戏支持玩家随时使用自然语言重塑环境,从而触发即时世界更新。其具备由 KV cache 驱动的长上下文窗口,因此即使在世界实时演变的情况下,游戏也能保持视觉一致性。
关键功能
- 16 FPS 帧率:以标清 (SD) 分辨率进行实时交互。
- 动态 UGC:玩家可以使用自然语言命令改变世界。
- 扩展型游戏体验:Mirage 可生成分钟级的互动游戏,并保持视觉一致性。
- 云串流:随时随地进行跨平台即时游戏,无需下载。
- 无限重玩性:每次游戏体验都独一无二。
- 多模式控制:接受文本、按键和控制器输入。
团队成员及未来展望
据介绍,Mirage 由一支技术深厚、创意驱动型的 AI 研究员、工程师和设计师团队打造。
团队成员拥有谷歌、英伟达、亚马逊、世嘉、苹果、微软、卡内基梅隆大学及加州大学圣地亚哥分校的深厚背景。
Dynamics Lab 还在博客中分享了他们的「未来之路」:「生成式游戏不仅仅是一项功能,更是一种全新的媒介。Mirage 引领着一个游戏不再需要下载或设计,而是需要被想象、被激发、被体验的未来。」
博客地址:https://blog.dynamicslab.ai/
#LSTKC++
北京大学提出LSTKC++,长短期知识解耦与巩固驱动的终身行人重识别
本文的第一作者为北京大学博士二年级学生徐昆仑,通讯作者为北京大学王选计算机研究所研究员、助理教授周嘉欢。
近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。
该框架引入了长短期知识解耦与动态纠正及融合机制,有效保障了模型在终身学习过程中对新知识的学习和对历史知识的记忆。目前该研究已被 IEEE TPAMI 接收,相关代码已开源。
- 论文标题:Long Short-Term Knowledge Decomposition and Consolidation for Lifelong Person Re-Identification
- 论文链接:https://ieeexplore.ieee.org/abstract/document/11010188/
- 代码链接:https://github.com/zhoujiahuan1991/LSTKC-Plus-Plus
- 接收期刊:T-PAMI(CCF A 类/中科院一区 Top)
- 单位:北京大学王选计算机研究所,华中科技大学人工智能与自动化学院
行人重识别(Person Re-Identification, ReID)技术的目标是在跨摄像头、跨场景等条件下,根据外观信息准确识别行人身份,并在多摄像头监控、智能交通、公共安全与大规模视频检索等应用中具有重要作用。
在实际应用中,行人数据分布常因地点、设备和时间等因素的变化而发生改变,使得新数据和训练数据呈现域差异,导致传统的「单次训练、静态推理」ReID 范式难以适应测试数据的长期动态变化。
这催生了一个更具挑战性的新任务——终身行人重识别(Lifelong Person Re-ID, LReID)。该任务要求模型能够利用新增域的数据进行训练,在学习新域数据知识的同时,保持旧域数据的识别能力。

图 1 研究动机
LReID 的核心挑战是灾难性遗忘问题,即模型在学习新域知识后,对旧域数据的处理性能发生退化。为克服该问题,多数方法采用知识蒸馏策略将旧模型的知识迁移到新模型。然而,这些方法存在两个关键隐患:
- 错误知识迁移:由于数据偏差等因素,旧模型中不可避免地包含一些错误知识。在知识蒸馏过程中,不仅会引发错误知识的累积,还会对新知识的学习产生干扰,造成模型的学习能力受限;
- 知识损失:新旧域之间的分布差异导致部分旧知识无法被新数据激活,使得这些知识无法通过知识蒸馏有效地迁移到新模型中。
为破解上述难题,北京大学王选计算机研究所团队在 T-PAMI 2025 上提出了 LSTKC++ 框架。该框架引入了长短期知识解耦与动态纠正及融合机制,在有效保障新知识学习的同时,增强了旧知识的保留能力。
一、基础框架:LSTKC 长短期知识纠正与巩固
LSTKC 是作者团队在 AAAI 2024 上提出的终身行人重识别框架。LSTKC 引入了「短期-长期模型协同融合」的思想,将终身学习所涉及的模型划分为短期模型和长期模型。前者指利用特定域数据训练得到的模型,后者指积累了所有历史域知识的模型。
在新域数据训练时,LSTKC 引入一个基于知识纠正的短期知识迁移模块(Rectification-based Short-Term Knowledge Transfer, R-STKT)。R-STKT 从长期模型中提取判别性特征,并基于新数据的标注信息识别并纠正其中的错误特征,进而利用知识蒸馏策略将校正后的正确知识迁移到新模型中。
在新域数据训练结束后,LSTKC 引入了基于知识评估的长期知识巩固模块(Estimation-based Long-Term Knowledge Consolidation, E-LTKC),根据长期模型和短期模型生成的特征,估计长期知识与短期知识之间的差异,进而实现长短期知识的自适应融合,实现了新旧知识的权衡。

图 2 LSTKC 模型
二、升级框架:LSTKC++ 长短期知识解耦与巩固
尽管 LSTKC 中基于知识差异的长短期知识融合策略在一定程度上促进了新旧知识权衡,但是由于模型间的知识差异无法直接反映融合模型的实际性能,导致 LSTKC 的模型融合策略难以实现新旧知识的最优权衡。

图 3 LSTKC++ 框架
为解决上述问题,作者在 T-PAMI 版本提出了 LSTKC++,从三个方面进行了方法升级:
- 模型解耦。 将原有的长期旧模型
-

- 解耦为两个部分:一个代表更早期历史知识(前
-

- 个域)的长期模型
-

- 和一个代表最近历史知识(第
-

- 域)的短期旧模型
-

- 。
- 长短期互补知识迁移。 首先,针对长期旧模型和短期旧模型进行互补纠正:根据样本亲和度矩阵(affinity matrix)分别筛选出长期旧模型
-

- 和短期旧模型
-

- 中的正确知识。然后,对于二者均正确的知识进行融合;对于一方正确、另一方错误的知识,仅保留正确知识;对于二者错误的知识,根据新数据标签进行纠正。通过上述互补纠正过程,得到融合了长短期模型的互补知识纠正矩阵。随后,纠正矩阵基于知识蒸馏损失指导新模型学习。
- 基于新数据的知识权衡参数优化。 为了优化 LSTKC 中用于融合长期历史知识和短期历史知识的权衡参数
-

- ,作者将新增的
-

- 域训练数据作为验证集,进而搜索得到最优的长短期历史知识权衡参数
-

- ,用以获得更新的长期旧模型
-

- 。

相比于使用已学习过的数据作为优化基准,新增数据尚未被长期和短期历史模型学习过,避免了过拟合问题,因此对知识权衡性能的评估更为可靠。
- 样本关系引导的长期知识巩固。 为了使模型在学习新域后能够直接利用长期知识和短期知识进行推理,作者引入了更新后的长期历史模型
-

- 与短期模型
-

- 的融合机制。具体地,利用
-

- 和
-

- 提取的样本间相似性矩阵
-

- 和
-

- 计算融合权重:

其中,

为用于测试的模型。
三、实验分析
数据集与实验设置
论文的实验采用两个典型的训练域顺序(Order-1 与 Order-2),包含五个广泛使用的行人重识别数据集(Market1501、DukeMTMC-ReID、CUHK03、MSMT17、CUHK-SYSU)作为训练域。分别评估模型在已学习域(Seen Domains)上的知识巩固能力和在未知域(Unseen Domains)上的泛化能力。评测指标采用行人 ReID 任务的标准指标:平均精度均值(mAP)和 Rank-1 准确率(R@1)。


实验结果
- 综合性能分析: 在两种不同的域顺序设定下,LSTKC++ 的已知域平均性能(Seen-Avg mAP 和 Seen-Avg R@1)相比于 CVPR 2024 方法 DKP 提升 1.5%-3.4%。同时,LSTKC++ 在未知域的整体泛化性能(Unseen-Avg mAP 和 Unseen-Avg R@1)上相比于现有方法提升 1.3%-4%。
- 子域性能分析: 在不同的域顺序设定中,虽然 LSTKC++ 在第一个和最后一个域的性能并非最优,但是其在中间三个域的性能均显著优于现有方法。这是因为部分现有方法对模型施加较强的抗遗忘约束,因而有效保持了初始域的性能,但其对新知识的学习能力大幅受限。其次,部分方法则采用较弱的抗遗忘约束,增强了模型对新知识的学习能力,但其对历史域性能的保持能力受限。与上述方法相比,LSTKC++ 综合考虑了知识遗忘和学习的自适应平衡,因而在中间域呈现明显的性能优势,并在不同域的整体性能上实现稳定提升。
- 计算与存储开销分析: 现有方法(如 PatchKD、AKA、DKP)通常通过引入额外的可学习模块来提升抗遗忘性能,这些模块往往会增加额外的训练时间、模型参数量、存储空间占用和 GPU 显存消耗。与之相比,LSTKC 和 LSTKC++ 仅在特征提取器和身份分类器中包含可学习参数,因此在模型参数量(Params)上具有明显优势。其次,LSTKC 在训练时间(Batch Time)、模型存储(Model Memory)和 GPU 显存消耗(GPU Memory)方面均最为高效。尽管 LSTKC++ 引入了一个额外的旧模型,但由于该旧模型被冻结且不参与梯度计算,其带来的额外开销仅为约 30% 的训练时间和约 818MB(占总显存的~7.4%)的 GPU 显存。总体而言,与最新的 CVPR 2024 方法 DKP 相比,LSTKC++ 在综合性能(TABLE I 和 TABLE II)以及计算和存储效率方面均展现出明显优势。

四、总结与展望
技术创新
本项被 T-PAMI 2025 接收的工作聚焦于终身行人重识别(LReID)任务,面向新知识学习和历史知识遗忘的挑战,提出了以下创新性设计:
- 解耦式知识记忆体系: 提出将终身学习中的知识解耦为长期知识和短期知识,通过长短期知识的针对性处理保障短期新知识学习和促进长期历史知识与短期新知识间的平衡;
- 语义级知识纠错机制: 将知识筛选与纠正机制引入基于知识蒸馏的持续学习,有效克服错误历史知识对新知识学习的干扰;
- 长短期互补知识提炼: 挖掘并融合长短期模型间的互补知识,提升知识蒸馏过程中知识表达的鲁棒性,提升历史知识在新知识学习中的引导作用。
- 遗忘-学习主动权衡: 摒弃固定抗遗忘损失的策略,提出主动搜索最优的新旧知识权衡参数的方法。
应用价值
LSTKC++ 所提出的终身学习机制具备良好的实用性和推广潜力,特别适用于以下典型场景:
- 适应动态开放环境,构建「终身进化」的识别系统。 在实际应用中,摄像头部署环境常常发生变化,例如视角变换、光照变化、图像分辨率波动等,传统静态训练的模型难以持续适应。LSTKC++ 具备长期知识保持与新知识快速整合能力,可持续应对环境迁移,适用于智慧城市、边缘计算终端、无人安防等场景,助力构建「可持续演进」的识别系统。
- 满足隐私保护需求,避免历史样本访问。 在公共安全、交通监控、医疗影像等高度敏感的应用场景中,受限于数据安全与隐私法规,系统通常禁止长期存储历史图像或身份数据。LSTKC++ 在整个持续学习过程中无需访问任何历史样本或缓存数据,具备天然的隐私友好性。
- 高效学习,快速部署。 LSTKC++ 无需保存图像或额外身份原型等,在多轮更新中也不会引入显存负担或冗余参数。同时,相比现有方法(如 DKP),该方法大幅减少了参数规模与显存占用,训练过程高效,可快速完成模型更新,满足资源受限设备上的持续学习需求。
未来展望
LSTKC++ 为无样本持续学习提供了结构化解决方案,未来仍具备多维度的研究与拓展空间:
- 向预训练视觉大模型拓展。 当前终身学习方法多数基于 CNN 架构设计,然而预训练视觉大模型在视觉任务中已展现出强大表达能力。如何将 LSTKC++ 的知识解耦与巩固机制迁移至大模型框架,并结合其先验语义进行持续学习,是一个具有理论深度与实际价值的重要方向。
- 研究多模态感知下的持续学习机制。 现有终身行人重识别研究主要基于可见光图像,尚未充分考虑红外、深度图、文本描述等多模态信息。在传感设备普及的背景下,融合多模态数据以提升持续学习的稳定性、抗干扰能力,将是推动算法实用化的重要路径。
- 推广至通用类别的域增量识别任务。 LSTKC++ 当前聚焦于「跨域+跨身份」的行人检索问题,然而在现实应用中,物品、交通工具、动物等通用类别同样面临动态领域变化现象。将本方法推广至通用类别的域增量学习场景,有望提升大规模视觉系统在开放环境下的适应性与扩展能力。
#NLP先驱、斯坦福教授Manning学术休假
加盟风投公司任合伙人
NLP 领域被引用次数最多的研究者之一、斯坦福人工智能实验室(Stanford AI Lab)前主任克里斯托弗・曼宁(Christopher Manning)已从斯坦福大学休假,加入风险投资公司 AIX Ventures 担任普通合伙人。
来源:https://www.wsj.com/articles/ai-researcher-christopher-manning-takes-leave-from-stanford-for-aix-ventures-0ab3cb4e?st=gLsy7t
此前,曼宁自 2021 年起以兼职投资人身份与 AIX 展开合作,现在将全职投入为公司提供咨询服务。
曼宁本人在 X(前 Twitter)上确认了这一消息,并表示:「我已加入 AIX Ventures,担任普通合伙人,专注于投资深度 AI 领域的初创公司。期待与各位创始人携手攻克 AI 领域的难题,并见证这些创新产品的诞生!」
对于曼宁的加入,AIX Ventures 的创始合伙人 Shaun Johnson 表示:「所有顶尖的 AI 原生工程师都认识 Chris,并且他们都希望与他合作。」
NLP 领域的先驱
曼宁教授是将深度学习应用于 NLP 领域的早期领军人物,在词向量 GloVe 模型、注意力、机器翻译、问题解答、自监督模型预训练、树递归神经网络、机器推理、依存解析、情感分析和总结等方面都有著名的研究。
他还专注于解析、自然语言推理和多语言处理的计算语言学方法,目标是让计算机能够智能地处理、理解和生成人类语言。
曼宁教授在澳大利亚国立大学获得学士学位,1994 年获得斯坦福大学博士学位,1999 年起执教于斯坦福大学。
他是斯坦福大学语言学系和计算机科学系机器学习专业的首任 Thomas M. Siebel 教授、斯坦福人工智能实验室(SAIL)主任以及斯坦福以人为中心人工智能研究所(HAI)副主任。2023 年,曼宁因其在计算机自然语言处理领域发挥的关键作用获得阿姆斯特丹大学荣誉博士学位。
曼宁教授与他人合著了有关 NLP 统计方法(Manning and Schütze 1999 年)和信息检索(Manning, Raghavan, and Schütze, 2008 年)的教科书,以及有关词性和复杂谓词的语言学专著。他的《统计自然语言处理基础》(Foundations of Statistical Natural Language Processing)是该领域的标准著作,也是几代学生的必读书目。他的斯坦福 CS224N 自然语言处理与深度学习在线课程视频也已被数十万人观看。
在二十余年的教学生涯中,曼宁教授曾培养出许多计算机科学领域的优秀人才,其中也有来自中国的陈丹琦、王孟秋等学生。
此前,曼宁教授已入选 ACM Fellow、AAAI Fellow 和 ACL Fellow,也曾担任 ACL 前主席(2015 年)。他的研究曾获得 ACL、Colin、EMNLP 和 CHI 最佳论文奖以及 ACL 时间检验奖。2024 年获得 IEEE 冯诺伊曼奖。作为 NLP 知名学者,曼宁教授始终对领域内的前沿技术趋势保持关注。
2022 年,曼宁教授在美国人文与科学学院(AAAS)期刊的 AI & Society 特刊上发表题为《Human Language Understanding & Reasoning》的文章,探讨了语义、语言理解的本质,并展望了大模型的未来。
「随着 NLP 领域的技术突破,我们或许已在通用人工智能(Artificial general intelligence, AGI)方向上迈出了坚定的一步。」
在 2023 年的大模型浪潮中,曼宁也参与并发表了多项相关研究。
曼宁教授的转型,标志着他将不再仅局限于学术研究,而是更深度地参与到 AI 初创公司的投资与发展中。他的加入将为 AIX Ventures 带来在 NLP 和深度 AI 领域的深厚积淀,同时也将为更多创新 AI 项目提供宝贵的经验和指导。
#实验室10篇论文被ICCV 2025录用
近日,第20届ICCV国际计算机视觉大会(The 20th IEEE/CVF International Conference on Computer Vision (ICCV 2025))公布了论文接收结果,实验室共有10篇论文被ICCV 2025录用,第一作者分别是何佩博士(导师:焦李成教授),吴兆阳博士生(导师:刘芳教授),缑雪健硕士生(导师:刘芳教授),王鑫硕士生(导师:缑水平教授),闵聿宽博士生(导师:邓成教授),朱宜航博士生(导师:邓成教授),慕晨宇硕士生(导师:邓成教授,杨二昆副教授),石光辉博士生(导师:梁雪峰教授),杜瑞琦博士生(导师:唐旭教授)及冯明涛副教授。论文简要介绍如下:
01 论文1
论文题目:Domain-aware Category-level Geometry Learning Segmentation for 3D Point Clouds
论文作者:何佩,李玲玲,焦李成,尚荣华,刘芳,王爽,刘旭,马文萍
作者单位:西安电子科技大学
论文概述:三维场景分割中的域泛化是将模型部署到未知环境的关键挑战。当前的方法通过增强点云的数据分布来缓解领域偏移。然而,模型学习点云中的全局几何模式,忽略了类别级的分布和对齐。本文提出了一个类别级几何学习框架,用于探索领域不变的几何特征,以实现域泛化的三维语义分割。具体而言,提出类别级几何嵌入感知点云特征的细粒度几何属性,构建每个类别的几何属性,并将几何嵌入与语义学习耦合。其次,提出几何一致性学习模拟潜在的三维分布并对齐类别级几何嵌入,使模型关注几何不变信息,从而提高泛化能力。实验结果验证了所提出方法的有效性,与现有的域泛化三维场景分割方法相比,该方法具有竞争力的分割精度。
02 论文2
论文题目:Hierarchical Variational Test-Time Prompt Generation for Zero-Shot Generalization
论文作者:吴兆阳,刘芳,焦李成,李硕,李玲玲,刘旭,陈璞华,马文萍
作者单位:西安电子科技大学
论文概述:现有的如 CLIP 这样的视觉语言模型已经展现出强大的零样本泛化能力,这使得它们能够通过提示学习在各种下游任务中发挥作用。然而,现有的测试时提示调整方法(例如熵最小化)将文本和视觉提示视为固定的可学习参数,限制了它们对未知领域的适应性。为此,我们提出了分层变分测试时提示生成方法,其中文本和视觉提示均通过 Hyper Transformer 在推理时动态生成。这使得模型能够为每种模态生成特定于数据的提示,从而显著提升泛化能力。为了进一步解决模板敏感性和分布偏移问题,我们引入了变分提示生成方法,利用变分推理来减轻不同提示模板和数据增强引入的偏差。此外,我们的分层变分提示生成方法在每一层上都对来自前一层的提示进行条件提示,从而使模型能够捕捉更深层次的上下文依赖关系,并优化提示交互以实现稳健的自适应。在领域泛化基准上进行的大量实验表明,我们的方法明显优于现有的即时学习技术,在保持效率的同时实现了最先进的零样本准确率。
03 论文3
论文题目:Knowledge-Guided Part Segmentation
论文作者:缑雪健,刘芳,焦李成,李硕,李玲玲,王浩,刘旭,陈璞花,马文萍
作者单位:西安电子科技大学
论文概述:在现实世界中,物体及其各个组成部分不仅存在明显的整体差异,还具有复杂而精细的结构关系。如何让计算机像人类一样理解和分割这些细粒度的部件,是计算机视觉领域的重要挑战。传统的语义分割方法大多关注于物体整体的粗粒度信息,能够较好地区分大范围的物体区域,但在需要识别和分割物体内部具体部件时,常常表现出不足。现有方法往往将每个部件视为独立的类别,忽视了部件之间的结构性联系以及与物体整体的关系,导致对复杂结构的理解不够深入,无法满足实际应用中对精细识别的需求。
针对这一问题,我们提出了一种知识引导的部件分割(KPS)新框架。该方法的核心思想是:像人类认知一样,先整体把握物体类别,再深入分析其内部各部件之间的结构关系。具体来说,我们首先利用大语言模型自动抽取物体部件之间的结构知识,并将这些关系构建成知识图谱。然后,通过结构知识引导模块,将知识图谱中的结构信息嵌入到分割模型的特征表达中,从而为部件分割提供结构性指导。同时,我们还设计了粗粒度物体引导模块,用于捕捉和利用物体层面的整体区分特征,进一步增强分割模型对不同物体类别的感知能力。通过将结构性知识与视觉特征有机结合,我们的方法能够更好地理解部件之间的关联和物体的整体特征,在复杂场景下实现更加准确和细致的部件分割。
04 论文4
论文题目:TopicGeo: An Efficient Unified Framework for Geolocation
论文作者:王鑫,王新林,缑水平
作者单位:西安电子科技大学
论文概述:在小尺度的查询图像与大量大尺度的地理参考图像之间建立空间对应关系的视觉地理定位技术已受到广泛关注。现有方法通常采用“先检索再匹配”的分离范式,但该范式存在计算效率低或精度受限的问题。为此,我们提出了一个统一的检索匹配框架TopicGeo,通过三项关键创新实现查询图像与参考图像的直接且精确匹配。首先我们将通过CLIP提示学习和语义蒸馏提取的文本对象语义(称为Topic即主题)嵌入地理定位框架,以消除多时相遥感图像中类内与类间的分布差异,同时提升处理效率。然后基于中心自适应标签分配与离群点剔除机制作为联合“检索-匹配”优化策略,确保了任务一致的特征学习与精确的空间对应关系。我们还引入了多层次的精细匹配流程,以进一步提升匹配的质量和数量。在大规模的合成与真实数据集上的评估表明,TopicGeo在检索召回率和匹配精度方面均具有较好的性能,同时保持了良好的计算效率。
05 论文5
论文题目:Vision-Language Interactive Relation Mining for Open-Vocabulary Scene Graph Generation
论文作者:闵聿宽,杨木李,张瑾皓,王宇宣, 武阿明,邓成
作者单位:西安电子科技大学
论文概述:为了促进场景理解在现实世界中的应用,开放词汇场景图生成(OV-SGG)近年来备受关注,旨在突破训练过程中标注的有限关系类别的限制,并在推理过程中发现那些未知的关系。针对开放词汇场景图生成,一个可行的解决方案是利用包含丰富类别级内容的大规模预训练视觉语言模型(VLM)来捕捉图像与文本之间的精确对应关系。然而,由于VLM缺乏二次关系感知知识,直接使用基础数据集中的类别级对应关系无法充分表征开放世界中的广义关系。因此,设计一个有效的开放词汇关系挖掘框架极具挑战性且意义重大。为此,我们提出了一种基于OV-SGG的视觉语言交互关系挖掘模型(VL-IRM),该模型探索通过多模态交互学习广义关系感知知识。具体来说,首先,为了增强关系文本与视觉内容的泛化能力,我们提出了一个关系生成模型,使文本模态能够探索基于视觉内容的开放式关系。然后,我们利用视觉模态引导关系文本进行空间和语义扩展。该方法成功地将现有VLM应用于场景图生成任务,并适应广泛的关系类别。在多个数据集上的实验表明,我们的方法具有较好的性能和实际应用价值。
06 论文6
论文题目:VGMamba: Attribute-to-Location Clue Reasoning for Quantity-Agnostic 3D Visual Grounding
论文作者:朱宜航,张瑾皓,王宇宣,武阿明,邓成
作者单位:西安电子科技大学
论文概述:作为xx智能的重要方向,三维视觉定位任务近年来广受关注,其旨在识别与给定语言描述相匹配的三维物体。现有大多数方法采用两阶段流程,即先生成候选物体框,然后再根据与语言查询的相关性筛选出目标物体。然而,当查询语义复杂时,仅凭抽象的语言特征难以精准定位对应物体,导致定位性能下降。通常,人类在定位特定物体时,往往会综合利用物体属性和空间位置信息两类线索。受此启发,本文提出一种新颖的属性到位置线索推理机制,以提升三维视觉定位任务的精度。具体来说,我们设计了 VGMamba 网络,其由基于奇异值分解的属性 Mamba、位置 Mamba 以及多模态融合 Mamba 三部分组成。该网络以三维点云场景与语言查询为输入,首先对提取到的特征进行 SVD 分解,然后通过滑动窗口操作捕获物体的属性特征;接着利用位置 Mamba 提取空间位置信息;最后通过多模态 Mamba 实现特征融合,精准定位与查询描述相符的目标物体。在多个公开数据集上的实验证明,我们的方法具有较好的性能和实际应用价值。
07 论文7
论文题目:Meta-Learning Dynamic Center Distance: Hard Sample Mining for Learning with Noisy Labels
论文作者:慕晨宇,瞿依俊,闫杰熹,杨二昆,邓成
作者单位:西安电子科技大学
论文概述:样本选择方法是一种广泛采用的带有噪声标签的学习策略,其中损失较小的样本在训练过程中被有效地视为干净的。然而,这个干净的集合经常被简单的例子所主导,限制了模型对更具挑战性的案例的有意义的暴露,并降低了它的表达能力。为了克服这一限制,我们引入了一种称为动态中心距离(DCD)的新度量,它可以量化样本难度,并提供关键补充损失值的信息。与依赖于预测的方法不同,DCD是在特征空间中作为样本特征和动态更新中心之间的距离计算的,通过提出的元学习框架建立。在捕获基本数据模式的初步半监督训练的基础上,我们结合DCD来进一步细化分类损失,降低分类良好的示例的权重,并战略性地将训练集中在一组稀疏的硬实例上。这种策略防止简单的例子支配分类器,从而导致更健壮的学习。跨多个基准数据集的广泛实验,包括合成和真实世界的噪声设置,以及自然和医学图像,一致地证明了我们的方法的有效性。
08 论文8
论文题目:Learning Separable Fine-Grained Representation via Dendrogram Construction from Coarse Labels for Fine-grained Visual Recognition
论文作者:石光辉,梁雪峰,李文杰,林笑宇
作者单位:西安电子科技大学
论文概述:在生物多样性监测、物种保护等关键领域,细粒度视觉识别(FGVR)对区分高度相似的物种至关重要,但其广泛应用却受限于昂贵且耗时的精细标注。因此,从粗标签中学习细粒度表征以实现FGVR是一项具有挑战性与价值的任务。早期的方法主要关注最小化细粒度类别类内方差,但忽视了细粒度类别之间的可分性,致使FGVR性能受限。后续研究采用自上而下的范式,通过深度聚类增强可分性,但这些方法需要预定义细粒度类别的数量,无法适应类别动态变化的现实场景(如新物种发现)。据此,我们提出一种自下而上的学习范式,通过迭代地合并相似的实例/聚类簇,构建层次化的树状图,从最低级的实例中推断出更高层次的语义,无需预定义类别数量。我们提出了BuCSFR方法,其包含自底向上构建(BuC)模块,该模块基于最小信息损失准则构建树状图;以及可分细粒度表征(SFR)模块,该模块将树状图节点视为伪标签,来确保细粒度表征的可分性。两个模块基于期望最大化(EM)框架,相互促进,协同工作。该方法使模型能自适应动态变化的语义结构(如物种演化),在仅使用粗标签条件下,实现无需先验类别数量的可分离细粒度表征学习,并在五个基准数据集上验证了方法的有效性。
09 论文9
论文题目:Category-Specific Selective Feature Enhancement for Long-Tailed Multi-Label Image Classification
论文作者:杜瑞琦,唐旭,张向荣,马晶晶
作者单位:西安电子科技大学
论文概述:由于现实世界中的多标签数据普遍存在严重的标签不平衡问题,长尾多标签图像分类已成为计算机视觉领域的一个研究热点。传统观点认为,深度神经网络的分类器更容易受到长尾分布的影响,而特征提取的主干网络相对更为稳健。然而,我们从特征学习的角度出发,发现主干网络在应对样本稀缺类别时虽然仍具备较强的区域定位能力,但丧失了相应类别的敏感性。基于这一观察,我们提出了一种用于长尾多标签图像分类的类别特异选择性特征增强模型。该方法首先利用主干网络所保留的定位能力生成标签相关的类激活图;随后,引入一种渐进式注意力增强机制,按从头部类别到中部类别再到尾部类别的顺序逐步增强低置信度类别的响应;最后,基于优化后的类激活图提取判别性视觉特征,并融合语义信息完成分类任务。在两个基准数据集上进行的大量实验证明了我们方法在长尾多标签场景下良好的泛化能力和分类表现。
特征学习分析结果
方法流程图
10 论文10
论文题目:Partially Matching Submap Helps: Uncertainty Modeling and Propagation for Text to Point Cloud Localization
论文作者:冯明涛,梅龙龙,武子杰,罗建桥,田丰豪,冯婕,董伟生,王耀南
作者单位:西安电子科技大学,湖南大学
论文概述:基于任务指令到城市级别的大规模点云跨模态定位是未来人机协作中的关键视觉-语言任务。现有框架通常假设每个指令文本严格对应于区域三维地图的中心区域,这限制了其在真实场景中的适用性。本研究针对现实噪声场景的假设重新定义该任务,通过允许指令文本与区域三维地图形成部分空间匹配对,放宽了一对一对齐的限制。为此,我们在精细位置回归中建模跨模态歧义性,通过引入表征为高斯分布的不确定性分数来缓解困难样本的影响。此外,我们提出不确定性感知相似性度量函数,将不确定性传播至区域三维场景识别阶段,从而提升指令文本与区域三维场景地图的相似性评估质量,该方法不仅能促使模型学习三维场景判别性特征,还能有效处理真实场景部分对齐样本并增强任务协同性。在多个数据集上的实验表明,我们的方法具有较好的性能和实际应用价值。
ICCV是计算机领域的著名国际会议,和CVPR、ECCV统称CV三大顶会(与ECCV轮流召开,两年一次),也是计算机学会推荐的A类会议。数据显示,今年大会共收到了11239份有效投稿,最终录用率为24%。ICCV 2025 将于10月19日至25日在美国夏威夷举行。
#Demystifying Reasoning Dynamics with Mutual Information
重磅发现!大模型的「aha moment」不是装腔作势,内部信息量暴增数倍!
刘勇,中国人民大学,长聘副教授,博士生导师,国家级高层次青年人才。长期从事机器学习基础理论研究,共发表论文 100 余篇,其中以第一作者/通讯作者发表顶级期刊和会议论文近 50 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和顶级会议 ICML、NeurIPS 等。
你肯定见过大模型在解题时「装模作样」地输出:「Hmm…」、「Wait, let me think」、「Therefore…」这些看似「人类化」的思考词。
但一个灵魂拷问始终存在:这些词真的代表模型在「思考」,还是仅仅为了「表演」更像人类而添加的语言装饰?是模型的「顿悟时刻」,还是纯粹的「烟雾弹」?
现在,实锤来了!来自中国人民大学高瓴人工智能学院、上海人工智能实验室、伦敦大学学院(UCL)和大连理工大学的联合研究团队,在最新论文中首次利用信息论这把「手术刀」,精准解剖了大模型内部的推理动态,给出了令人信服的答案:
当这些「思考词」出现的瞬间,模型大脑(隐空间)中关于正确答案的信息量,会突然飙升数倍!
这绝非偶然装饰,而是真正的「信息高峰」与「决策拐点」!更酷的是,基于这一发现,研究者提出了无需额外训练就能显著提升模型推理性能的简单方法,代码已开源!
论文题目:Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning
论文链接:https://arxiv.org/abs/2506.02867
代码链接:https://github.com/ChnQ/MI-Peaks
核心发现一:揭秘大模型推理轨迹中的「信息高峰」现象
研究者们追踪了像 DeepSeek-R1 系列蒸馏模型、QwQ 这类擅长推理的大模型在解题时的「脑电波」(隐空间表征)。他们测量每一步的「脑电波」与最终正确答案的互信息(Mutual Information, MI),并观察这些互信息如何演绎变化。
惊人现象出现了:模型推理并非匀速「爬坡」,而是存在剧烈的「信息脉冲」!在特定步骤,互信息值会突然、显著地飙升,形成显著的「互信息峰值」(MI Peaks)现象。这些峰值点稀疏但关键,如同黑暗推理路径上突然点亮的强光路标!

这意味着什么?直觉上,这些互信息峰值点处的表征,模型大脑中那一刻的状态,蕴含了更多指向正确答案的最关键信息!
进一步地,研究者通过理论分析证明(定理 1 & 2),推理过程中积累的互信息越高,模型最终回答错误概率的上界和下界就越紧,换言之,回答正确的概率就越高!


既然互信息峰值的现象较为普遍地出现在推理模型(LRMs)中,那么非推理模型(non-reasoning LLMs)上也会表现出类似的现象吗?

为了探索这一问题,研究者选取了 DeepSeek-R1-Distill 系列模型和其对应的非推理模型进行实验。如上图橙色线所示,在非推理模型的推理过程中,互信息往往表现出更小的波动,体现出明显更弱的互信息峰值现象,且互信息的数值整体上更小。
这表明在经过推理能力强化训练后,推理模型一方面似乎整体在表征中编码了更多关于正确答案的信息,另一方面催生了互信息峰值现象的出现!
核心发现二:「思考词汇」=「信息高峰」的语言化身
那么,这些互信息峰值点处的表征,到底蕴含着怎样的语义信息?
神奇的是,当研究者把这些「信息高峰」时刻的「脑电波」翻译回人能看懂的语言(解码到词汇空间)时,发现它们最常对应的,恰恰是那些标志性的「思考词」:
- 反思/停顿型:「Hmm」、「Wait」…
- 逻辑/过渡型:「Therefore」、「So」…
- 行动型:「Let」、「First」…

例如,研究者随机摘取了一些模型输出: 「Wait, let me think differently. Let’s denote...,」 「Hmm, so I must have made a mistake somewhere. Let me double-check my calculations. First, ...」
研究团队将这些在互信息峰值点频繁出现、承载关键信息并在语言上推动模型思考的词汇命名为「思考词汇」(thinking tokens)。它们不是可有可无的装饰,而是信息高峰在语言层面的「显灵」,可能在模型推理路径上扮演着关键路标或决策点的角色!
为了证明这些 tokens 的关键性,研究者进行了干预实验,即在模型推理时抑制这些思考词汇的生成。
实锤验证:实验结果显示,抑制思考词汇的生成会显著影响模型在数学推理数据集(如 GSM8K、MATH、AIME24)上的性能;相比之下,随机屏蔽相同数量的其他普通词汇,对性能影响甚微。这表明这些存在于互信息峰值点处的思考词汇,确实对模型有效推理具有至关重要的作用!

启发应用:无需训练,巧用「信息高峰」提升推理性能
理解了「信息高峰」和「思考词汇」的奥秘,研究者提出了两种无需额外训练即可提升现有 LRMs 推理性能的实用方法。
应用一:表征循环(Representation Recycling - RR)

- 启发:既然 MI 峰值点的表征蕴含丰富信息,何不让模型「多咀嚼消化」一下?
- 方法:在模型推理过程中,当检测到生成了思考词汇时,不急于让其立刻输出,而是将其对应的表征重新输入到模型中进行额外一轮计算,让模型充分挖掘利用表征中的丰富信息。
- 效果:在多个数学推理基准(GSM8K、MATH500、AIME24)上,RR 方法一致地提升了 LRMs 的推理性能。例如,在极具挑战性的 AIME24 上,DeepSeek-R1-Distill-LLaMA-8B 的准确率相对提升了 20%!这表明让模型更充分地利用这些高信息量的「顿悟」表征,能有效解锁其推理潜力。
应用二:基于思考词汇的测试时扩展(Thinking Token based Test-time Scaling - TTTS)

- 启发:在推理时如果允许模型生成更多 token(增加计算预算),如何引导模型进行更有效的「深度思考」,而不是漫无目的地延伸?
- 方法:受启发于前人工作,作者在模型完成初始推理输出后,如果还有 token 预算,则强制模型以「思考词汇」开头(如「Therefore」、「So」、「Wait」、「Hmm」等)继续生成后续内容,引导模型在额外计算资源下进行更深入的推理。
- 效果:当 token 预算增加时,TTTS 能持续稳定地提升模型的推理性能。如图所示,在 GSM8K 和 MATH500 数据集上,在相同的 Token 预算下,TTTS 持续优于原始模型。在 AIME24 数据集上,尽管原始模型的性能在早期提升得较快,但当 token 预算达到 4096 后,模型性能就到达了瓶颈期;而 TTTS 引导下的模型,其性能随着 Token 预算的增加而持续提升,并在预算达到 6144 后超越了原始模型。
小结
这项研究首次揭示了 LRMs 推理过程中的动态机制:通过互信息动态追踪,首次清晰观测到 LRMs 推理过程中的互信息峰值(MI Peaks)现象,为理解模型「黑箱」推理提供了创新视角和实证基础。
进一步地,研究者发现这些互信息峰值处的 token 对应的是表达思考、反思等的「思考词汇」(Thinking Tokens),并通过干预实验验证了这些 token 对模型推理性能具有至关重要的影响。
最后,受启发于对上述现象的理解和分析,研究者提出了两种简单有效且无需训练的方法来提升 LRMs 的推理性能,即表征循环(Representation Recycling - RR)和基于思考词汇的测试时扩展(Thinking Token based Test-time Scaling - TTTS)。
研究者希望这篇工作可以为深入理解 LRMs 的推理机制提供新的视角,并进一步提出可行的方案来进一步推升模型的推理能力。
#印度小哥简历90%造假
还身兼数职,干翻硅谷一圈AI创业公司
这回不止奥特曼一个人头大了。
我们知道大模型时代,最稀缺的资源是人才。
本周四,半个硅谷的 CEO 都在讨论一个名为 Soham Parekh 的人才,不过不是因为他 AI 技术出众,而是因为他另一方面的「身怀绝技」。
事情的爆发是在 7 月 2 日,有一个 AI 创业公司 PlayGround 的创始人发推通知大家避雷:

该公司的创始人 Suhail Doshi 此前招募了一位名叫 Soham Parekh 的印度小哥来当工程师,结果发现他工作能力并不如意,还身兼数职,遂决定将其开除。没想到这段一年前的经历只是 Soham Parekh 神奇事迹一个小小的节点。
Soham Parekh 是谁?作为用人单位,Suhail Doshi 贴出了 Soham 提供的简历,一看水平还挺高,佐治亚理工 CS 硕士毕业,曾在不少创业公司工作。
Suhail 估计其中的内容 90% 是假的,而且其中大多数链接都失效了。

另外工作地点也是假的。PlayGround 公司在雇佣 Soham Parekh 以后,曾以为他们在美国招到了人,还给他提供的假地址寄去了笔记本电脑,结果被原路退回。当时招进来工作后,Soham Parekh 也没有完成过什么像样的任务,只是不断用扯谎的方式应付过去。
作为创业公司的负责人,Suhail Doshi 表示自己曾尝试说服这个人,解释多职位兼职的后果,给他一个改过自新的机会,因为有时候人需要改过自新,但显然没用,只能在 Soham Parekh 入职一个星期后把他开了。
一个貌似真人加入一家创业公司,又被退了回去,如果到这里就结束了,可能只是一个平平无奇的简历造假故事,然而 PlayGround 的创始人还表示他还知道有至少六家公司也遭遇过同样的情况。
被坑的创始人展示了几个 Message 截图,里面是其他公司创始人的抱怨:「我们刚刚雇佣了这位 Soham Parekh」,「他正在我们的开发团队里」,「我刚刚邀请他下周来试用」。
这位 Soham Parekh,就好像是一位能够速通所有面试的大神。
PlayGround 的遭遇引来了 AI 圈内各路人的围观,知名 AI 技术博主 Sebastian Raschka 回帖问道:他简历上那么多 GitHub 项目、博客文章和论文都是公开可查的,这怎么造假?

Suhail 只能表示委屈,这些看来都是伪造的。
也有人站出来表示,Soham Parekh 曾经在求职的时候找我做推荐人,我早就觉得他不对劲了。

被坑过的公司显然也不止这几家,很快 Create.xyz 的创始人 Marcus Lowe 在下面回帖表示:我们也曾雇佣过这位 Soham Parekh,离谱的是我们公司要求是到公司上班,于是他在我们公司待了一天,然后就编了一系列谎话说他不能来。
还有雇佣过此人的管理者表示,他在会议上表现得自信且能言善辩,但几乎从未完成过任何工作。其他开发人员常常不得不接手他的任务,才能让项目推进下去。甚至他还做过一些非常过分的行为。
也有 CEO 说:「我昨天还在面试这个人,我麻了。」

Pally.AI 的创始人 Haz Hubble 介绍了自己的避坑经验:「我们曾经给 Soham Parekh 提供了创始工程师职位,但由于他不愿意和我们住在一起,所以我们放弃了。」
难道马斯克在 X 办公室搭帐篷,才是确保招到正确的人的方法?
有围观群众问:如果说 Soham Parekh 一人身兼数职,为啥他在不同的公司入职都要用同一个名字?这不是更容易暴露吗?
但很快又有另一种假设出来了:万一 Soham Parekh 其实是多人合用一个角色呢?

Engineer as a Service,好一个人工扮演的「AI 智能体」。

对于这次事件的围观愈演愈烈,现在已经出现了反向思考的:如果你们公司 CEO 没有收到过 Soham Parekh 的邮件,是不是因为你们名头不够响呢?

随着人们的深挖,越来越多的信息不断浮出水面。Soham Parekh 其人是不是真实存在,科技圈里其实是有一点佐证的。早在 2021 年 6 月,Meta 的博客曾经介绍了他作为开源贡献者的故事。

文章中作者采访了 Soham Parekh,介绍了他作为 WebXR 贡献者,致力于通过美国职业黑客联盟(MLH)的资助使用 WebXR 媒体层创建沉浸式 AR/VR 技术的案例。
还留下了一张不太清晰的照片:

作者感谢了 Soham Parekh 对 Facebook 开源生态系统做出的持续贡献,不知如今看到他的事业发展应该做何感想。
最新的消息是,Soham Parekh 主动联系上来了。

一个「AI 新星」,正在冉冉升起?
参考内容:
https://x.com/Suhail/status/1940287384131969067
https://developers.facebook.com/blog/post/2021/06/01/webxr-contributor-story-soham-parekh/
#OmniGen2
智源新出,开源神器,一键解锁AI绘图「哆啦 A 梦」任意门
2024 年 9 月,智源研究院发布了统一图像生成模型 OmniGen。该模型在单一架构内即可支持多种图像生成任务,包括文本生成图像(Text-to-Image Generation)、图像编辑(Image Editing)和主题驱动图像生成(Subject-driven Image Generation)。用户仅需使用多模态的自然语言指令,便可灵活实现上述功能,无需依赖额外的上下文提示、插件或预处理模块。凭借其功能的高度通用性与架构的高度简洁性,OmniGen 一经发布便获得社区的广泛好评。随后,随着 Gemini 2.0 Flash 和 GPT-4o 等闭源多模态模型的相继发布,构建统一图像生成模型成为当前最受关注的研究与应用方向之一。
在这一背景下,OmniGen 迎来重大技术升级,正式发布 OmniGen2。新一代模型在保持简洁架构的基础上,显著增强了上下文理解能力、指令遵循能力和图像生成质量。同时,OmniGen2 全面继承了其基座多模态大模型在上下文理解与生成方面的能力,同时支持图像和文字生成,进一步打通了多模态技术生态。同时,模型权重、训练代码及训练数据将全面开源,为社区开发者提供优化与扩展的基础。这些特性都将推动统一图像生成模型从构想向现实的转变。
1. 分离式架构 + 双编码器策略
OmniGen2 采取了分离式架构解耦文本和图像,同时采用了 ViT 和 VAE 的双编码器策略。不同于其他工作,ViT 和 VAE 独立作用于 MLLM 和 Diffusion Transformer 中,提高图像一致性的同时保证原有的文字生成能力。

2. 数据生成流程重构
OmniGen2 也在探索解决阻碍领域发展的基础数据和评估方面的难题。相关的开源数据集大多存在固有的质量缺陷,尤其是在图像编辑任务中,图像质量和质量准确度都不高。而对于图片上下文参考生成任务,社区中缺乏相应的大规模多样化的训练数据。这些缺陷极大地导致了开源模型和商业模型之间显著的性能差距。为了解决这个问题,OmniGen2 开发了一个从视频数据和图像数据中生成图像编辑和上下文参考数据的构造流程。

3. 图像生成反思机制
受到大型语言模型自我反思能力的启发,OmniGen2 还探索了将反思能力整合到多模态生成模型中的策略。基于 OmniGen2 的基础模型构建了面对图像生成的反思数据。反思数据由文本和图像的交错序列组成,首先是一个用户指令,接着是多模态模型生成的图像,然后是针对之前生成输出的逐步反思。
每条反思都涉及两个关键方面:
1)对与原始指令相关的缺陷或未满足要求的分析,
2)为解决前一幅图像的局限性而提出的解决方案。

经过训练的模型具备初步的反思能力,未来目标是进一步使用强化学习进行训练。

OmniGen2 发布一周 GitHub 星标突破 2000,X 上相关话题浏览量数十万。

现在科研体验版已开放,可抢先尝试图像编辑、上下文参照的图像生成等特色能力。
科研体验版链接:https://genai.baai.ac.cn
OmniGen2 的玩法简单,只需要输入提示词,就能解锁丰富的图像编辑与生成能力。
1. 基于自然语言指令的图像编辑
OmniGen2 支持基于自然语言指令的图片编辑功能,可实现局部修改操作,包括物体增删、颜色调整、人物表情修改、背景替换等。

2. 多模态上下文参考的图像生成
OmniGen2 可从输入图像中提取指定元素,并基于这些元素生成新图像。例如,将物品 / 人物置于新的场景中。当前 OmniGen2 更擅长保持物体相似度而不是人脸相似度。

3. 文生图
OmniGen2 能够生成任意比例的图片。

OmniGen2 在已有基准上取得了颇具竞争力的结果,包括文生图,图像编辑。然而,对于图片上下文参考生成(in-context generation) 任务,目前还缺乏完善的公共基准来系统地评估和比较不同模型的关键能力。
现有的上下文图像生成基准在捕获实际应用场景方面存在不足。它们不考虑具有多个输入图像的场景,并且受到上下文类型和任务类型的限制。同时,先前的基准使用 CLIP-I 和 DINO 指标来评估上下文生成的图像的质量。这些指标依赖于输入和输出之间的图像级相似性,这使得它们不适用于涉及多个主题的场景,并且缺乏可解释性。
为了解决这一限制,团队引入了 OmniContext 基准,其中包括 8 个任务类别,专门用于评估个人、物体和场景的一致性。数据的构建采用多模态大语言模型初筛和人类专家手工标注相结合的混合方法。

OmniGen2 依托智源研究院自研的大模型训练推理并行框架 FlagScale,开展推理部署优化工作。通过深度重构模型推理链路,并融合 TeaCache 缓存加速策略,实现 32% 的推理效率提升,大幅缩短响应时间并强化服务效能。同时,框架支持一键式跨机多实例弹性部署,有效提升集群资源整体利用率。团队将持续推进软硬协同优化,构建高效推理部署能力体系。
OmniGen2 的模型权重、训练代码及训练数据将全面开源,为开发者提供优化与扩展的新基础,推动统一图像生成模型从构想加速迈向现实。
OmniGen2 相关链接:
- Github: https://github.com/VectorSpaceLab/OmniGen2/
- 论文:https://arxiv.org/abs/2506.18871
- 模型:https://huggingface.co/BAAI/OmniGen2
- 科研体验版链接:https://genai.baai.ac.cn
#AI 编程十字路口
为什么说 Copilot 模式是创业陷阱?
当整个人工智能行业都在为「如何给程序员打造更快的马」而疯狂投入时,一支特立独行的团队选择「直接去造汽车」。
「大模型的发展,更像一场篮球比赛才刚刚打完第一节。所有人都在用第一节的比分去判断整场比赛的胜负,但我们认为,还有第二、三、四节要打。」蔻町智能(AIGCode)创始人兼 CEO 宿文用这样一个比喻,为当前略显拥挤的 AI 编程赛道,提供了一个不同的观察视角。
自 2022 年底 ChatGPT 引爆全球以来,AI 编程被普遍认为是大语言模型最快、最确定能实现严肃商业化(PMF)的一个赛道。从 GitHub Copilot 的成功,到科技大厂和创业公司纷纷推出自己的编程助手,行业似乎已经形成一种共识:AI 是程序员的「副驾驶」,其核心价值在于提升代码编写效率。
然而,宿文和他的蔻町智能,正试图证明这是对终局的误判。在与xx的最近一次访谈中,宿文拆解了他对 AI 编程的三大「非共识」判断。
非共识一:基座模型仍处「婴幼儿期」
网络结构创新是破局关键
在许多人眼中,大模型的基座之战似乎已尘埃落定。后来者尤其是创业公司,只能在应用层寻找机会。宿文对此的看法截然不同:「我们认为大模型技术,或者说基座模型的发展,还处于婴幼儿时期。」
他指出,现有以 Transformer 为基础的模型架构,在学习机制和知识压缩效率上存在根本性问题。「尽管 MoE 通过专家分工解决了部分计算效率问题,但其专家之间是 “扁平” 且缺乏协作的,整体上仍是一个依靠简单路由机制的 “黑盒”。」
蔻町智能从成立第一天起,就选择自研基座模型。他们的破局点,正是在于对模型网络结构的持续迭代和创新。「我们在 MoE 的基础上,继续向后迭代,最终采用了在推荐搜索领域已经非常成熟的 PLE(Progressive Layered Extraction)架构。」
他解释道,从 MoE 到 MMoE,解决的是专家的解耦问题;再到 PLE,则进一步解决了专家解耦后可能产生的冲突和信息损耗问题,实现了对任务共性与个性的精细化提取。

多任务学习(Multi-task Learning)网络结构的演进,从简单的底层共享(Shared-Bottom),发展到通过门控专家网络(MMoE、CGC)与渐进式分层提取(PLE),以实现更精细地分离与融合任务的共性与个性信息。图片来源:Gabriel Moreira@ Medium
宿文表示,网络结构创新使他们的模型在知识压缩和长逻辑链条的理解上,具备了与主流模型不同的潜力。

蔻町智能研发的新模型 AIGCoder 架构图,通过解耦的专家模块(De-coupled Experts)改良传统模型,利用多头专家感知注意力(MHEA)负责动态激活专家,定制化门控(CGC)负责精细整合信息,实现了在不增加计算开销的前提下,通过架构创新应对大模型扩展时遇到的瓶颈。

实验数据显示,无论是单个关键模块(左)还是整合后的完整架构(右),AIGCoder(橙色曲线)的训练效率均比基线模型(蓝色曲线)提升超过 1.3 倍。
非共识二:「避开大厂赛道」是个伪命题
在 AI 领域,创业者常常听到一句劝诫——不要做大厂发展道路上的业务,否则会被轻易碾压。
宿文却认为这是个伪命题。「如果真的是一件大事,为什么大厂会不做?更精准的说法应该是,“避免去摘低垂的果实”。」
「真正的护城河,不在于选择一个大厂看不上的 “缝隙市场”,而是在同一个领域里,解决比大厂更复杂、更深入的问题。」
「现在的许多 Coding 产品用工程化的方式集成各种 API,生成一个前端尚可的 Demo,这就是 “低垂的果实”。蔻町智能的策略,是通过底层技术创新,实现真正的 “All-in-one”。」
这种一体化的思路,也体现在宿文对 Agent 发展的看法上。他表示当前行业习惯性地将技术栈划分为 Infra、基座、OS、Agent 等层次,「这很像是对上一代 PC 互联网和移动互联网的技术架构的简单映射,这样 “刻舟求剑” 式的对新技术做定义意义不大。」
他强调,在新范式下,各个技术环节是深度耦合的。「奔着解决问题的角度,我们就把它一体化地解决。在最终效果没有出来之前,过早分工反而不利于提效。」
蔻町智能把 AI for Coding 划分为 L1 到 L5 五个阶段:
L1:类似低代码平台,目前不是主流;
L2:Copilot 产品,辅助程序员,根据提示生成代码,代表产品有 GitHub Copilot、Cursor;
L3:Autopilot 产品,能端到端地完成编程任务,不需要程序员介入;
L4:多端自动协作,让多个协作用户能直接把软件创意变成某个完整的产品;
L5:能够自动迭代,升级为成熟的软件产品。
宿文表示:「目前大部分 AI Coding 产品集中在 L2 阶段,而 AutoCoder 从一开始就定位在 L3。」
从 L2 到 L3,并非简单的量变。「将编程助手做到极致,并不会自然而然地通向端到端软件生成。」两者需要解决的技术问题、优化的方向,基本上没有大的重合:前者(Copilot)优化的是「写代码效率」,核心是上下文理解与精准补全;后者(Autopilot)解决「不写代码」的问题,核心是对复杂业务逻辑的理解、拆解与长逻辑链条的生成。
此外,L2 需要与 IDE(集成开发环节)深度融合,对大厂俩说有天然优势,对创业公司而言,则可能是一条事倍功半的险路。
非共识三:个性化应用市场即将爆发,
新增需求远超存量替代
坚持 L3 不仅是技术上的选择,也是宿文和他的团队对市场未来的判断。尽管行业普遍认同 AI 编程的终极目标在于赋能每一个人,但在实现路径上,由于 AI 技术瓶颈与普通用户相关知识的缺失,主流看法认为,当下最现实的路径,是先辅助程序员,解决存量市场的效率问题。
宿文则认为这恰恰是一种「战略绕行」,因为 L2 无法自然演进到 L3,所以沿着 L2 走,不仅无法抵达终点,更可能错失真正的蓝海——那个被现有开发模式压抑的、由海量个性化需求构成的增量市场。
「新增的需求远远大于存量的替代。程序员不会消失,但一个全新的、数倍于现有规模的市场会爆发。」
「很像是有了滴滴才有了网约车市场,有了美团才有了外卖市场,」他类比说:「以前人们打车、点外卖的大量潜在需求被高昂的成本和复杂的流程所压抑,一旦有了低成本、高效率的供给方式,市场便会迎来爆发式增长。」
在软件开发领域,对于大量的中小企业、创业者,甚至大企业的业务部门而言,都存在被压抑的需求。宿文举例,一个业务部门想为内部开发一套培训系统,传统模式下,从漫长的需求沟通、高昂的开发投入,到最终交付物偏离预期的风险,整个过程动辄数月,且试错成本极高。
蔻町智能希望将这个流程重塑为:「只要上午能明确定义需求,下午就能看到一个可直接上线部署的产品。」
蔻町智能最新发布的端到端软件生成产品 AutoCoder,定位「全球首款前后端一体化的应用与软件完整生成平台」,能够同时生成高度可用的前端、数据库和后端。例如,用户输入「帮我生成一个科技公司官网」,平台不仅生成用户可见的前台页面,也同步生成供企业员工管理网站内容和用户数据的后台系统。
AutoCoder 的受众不仅包括产品经理、设计师等专业人士(Prosumer),更涵盖了大量非技术背景的个人从业者、小型企业主(如咖啡店、健身房)、初创团队的非技术创始人等。这些人有明确的数字化需求,但被传统开发的高门槛挡在门外。
宿文引用了一个数据:海外一家类似理念的公司,其产品的月度访问量,在短时间内已经达到了发展近 20 年的 GitHub 的十分之一,并且 GitHub 的数据本身并未下滑。这意味着一个新的、增量用户的市场正在被激发。
当然,L3 这条路最直接的质疑就是——端到端生成的软件出了 Bug 怎么办?宿文的回应是:
「与其花费数小时去寻找一个 Bug,为什么不花几分钟重新生成一个正确的版本呢?」随着软件生成的边际成本趋近于零,迭代和试错的自由度将被前所未有地释放。
结语
自研基座模型,选择更难的端到端路径,瞄准被压抑的增量需求——这三个非共识但逻辑自洽的判断,构成了蔻町智能的核心战略和发展路径。
当然,选择一条少有人走的路,必然伴随着质疑和不确定性。正如汽车在诞生之初,远没有马车跑得快,甚至开几公里就散架。蔻町智能的「汽车」能否在性能、稳定性和可靠性上,快速迭代到可以与成熟的「马车体系」相抗衡甚至超越的阶段,仍需时间和市场的检验。
但毫无疑问,这场关于 AI 编程的篮球赛才刚刚开始。一个挑战者已经选择用自己的方式,去打一场完全不同的比赛。从用户的角度,我们也乐于期待一个软件创造权力被彻底平权的未来。
#Prompt不再是AI重点,新热点是Context Engineering
登上热搜!
最近「上下文工程」有多火?Andrej Karpathy 为其打 Call,Phil Schmid 介绍上下文工程的文章成为 Hacker News 榜首,还登上了知乎热搜榜。

之前我们介绍了上下文工程的基本概念,今天我们来聊聊实操。
为什么关注「上下文工程」
我们很容易将 LLM 拟人化——把它们当作能够「思考」、「理解」或「感到困惑」的超级助手。从工程学的角度来看,这是一个根本性的错误。LLM 并不具备信念或意图,它是一个智能的文本生成器。
更准确的看法是:LLM 是一个通用的、不确定的函数。这个函数的工作方式是:你给它一段文本(上下文),它会生成一段新的文本(输出)。

- 通用:意味着它能处理各种任务(如翻译、写代码),无需为每个任务单独编程。
- 不确定:意味着同样的输入,每次可能得到稍有不同的输出。这是它的特点,不是毛病。
- 无状态:意味着它没有记忆。你必须在每次输入时,提供所有相关的背景信息,它才能「记住」对话。
这个视角至关重要,因为它明确了我们的工作重心:我们无法改变模型本身,但可以完全控制输入。所有优化的关键,在于如何构建最有效的输入文本(即上下文),来引导模型生成我们期望的输出。
「提示词工程」一度很火,但它过于强调寻找一句完美的「魔法咒语」。这种方法在真实应用中并不可靠,因为「咒语」可能因模型更新而失效,且实际输入远比单句指令复杂。
一个更精准、更系统的概念是「上下文工程」。

两者的核心区别在于:
- 提示词工程:核心是手动构思一小段神奇的指令,如同念咒。
- 上下文工程:核心是构建一个自动化系统,像设计一条「信息流水线」。该系统负责从数据库、文档等来源自动抓取、整合信息,并将其打包成完整的上下文,再喂给模型。
正如 Andrej Karpathy 所说,LLM 是一种新型的操作系统。我们的任务不是给它下达零散的命令,而是为它准备好运行所需的所有数据和环境。
上下文工程的核心要素
简单说,「上下文工程」就是打造一个「超级输入」的工具箱。我们听到的各种时髦技术(比如 RAG、智能体),都只是这个工具箱里的工具而已。
目标只有一个:把最有效的信息,用最合适的格式,在最恰当的时机,喂给模型。

以下是工具箱里的几种核心要素:
- 指令:下达命令这是最基础的,就是直接告诉模型该做什么。比如命令它「扮演一个专家」,或者给它看几个例子,让它照着学。
- 知识:赋予「记忆」 模型本身没有记忆,所以我们要帮它记住。在聊天机器人里,就是把聊天记录一起发给它。如果记录太长,就做个「摘要」或者只保留最近的对话。
- 工具:
- 检索增强生成 (RAG):给它一本「开卷考试」用的参考书为了防止模型瞎说(产生幻觉),我们可以让系统先从我们自己的知识库(比如公司文档)里查找相关资料,然后把「参考资料」和问题一起交给模型,让它根据事实来回答。
- 智能体:让它自己去「查资料」

这是更高级的玩法。我们不再是提前准备好所有资料,而是让一个聪明的「智能体」自己判断需要什么信息,然后主动使用工具(比如上网搜索、查数据库)去寻找答案,最后再汇总起来解决问题。
总而言之,所有这些技术,无论简单还是复杂,都是在回答这一个问题:「怎样才能给模型打造出最完美的输入内容?」
上下文工程的实践方法论
使用 LLM 更像做科学实验,而不是搞艺术创作。你不能靠猜,必须通过测试来验证。
工程师的核心能力不是写出花哨的提示,而是懂得如何用一套科学流程来持续改进系统。这套流程分两步:
第一步:从后往前规划(定目标 → 拆任务)
从你想要的最终结果出发,反向推导出系统的样子。
- 先想好终点:明确定义你希望 LLM 输出的完美答案是什么样的(内容、格式等)。
- 再倒推需要什么原料:要得到这个完美答案,LLM 的输入(上下文)里必须包含哪些信息?这就定义了你的系统需要准备的「原料包」。
- 最后设计「流水线」:规划出能够自动生产这个「原料包」的系统。
第二步:从前往后构建(搭积木 → 总装)
规划好后,开始动手搭建。关键是:搭好一块,测一块,最后再组装。
- 先测试「数据接口」:确保能稳定地获取原始数据。
- 再测试「搜索功能」:单独测试检索模块,看它找资料找得准不准、全不全。
- 然后测试「打包程序」:检查那个把所有信息(指令、数据)组装成最终输入的程序是否正常工作。
- 最后才进行「总装测试」:当所有零件都确认无误后,再连接起来,对整个系统进行端到端测试。这时,你可以完全专注于评估 LLM 的输出质量,因为你知道它收到的输入肯定是正确的。
核心思想就是:通过这种「先规划、后分步搭建和测试」的严谨流程,我们将使用 LLM 从凭感觉的艺术,变成了有章可循的工程科学。
实践
更具体的实践方法,大家可以参考 Langchain 最新的博客和视频,里面详细介绍了上下文工程当前主流的四大核心方法,并展示了 LangChain 生态中 LangGraph 和 LangSmith 如何助力开发者高效实施上下文工程。

- 博客地址:Context Engineering for Agents
- 视频地址:Context Engineering for Agents (LangChain)
参考链接:
https://ai.intellectronica.net/context-engineering
https://blog.langchain.com/context-engineering-for-agents/
#WorldVLA
首次!世界模型、动作模型融合,全自回归模型来了
岑俊,阿里巴巴达摩院xx智能大模型算法研究员,博士毕业于香港科技大学。研究方向主要是:xx智能 VLA 模型,世界模型。
阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。
论文标题:WorldVLA: Towards Autoregressive Action World Model
论文地址:https://arxiv.org/pdf/2506.21539
代码地址:https://github.com/alibaba-damo-academy/WorldVLA
研究简介
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型的发展成为机器人动作建模研究的重要方向。这类模型通常是在大规模预训练的多模态大语言模型(Multimodal Large Language Models, MLLMs)基础上,添加一个动作输出头或专门的动作模块,以实现对动作的生成。MLLMs 在感知和决策方面表现出色,使得 VLA 模型在多种机器人任务中展现出良好的泛化能力。然而,这些模型存在一个显著的局限性:它们往往缺乏对动作本身的深入理解。在现有方法中,动作只是作为输出结果处理,并未被当作输入进行分析和建模。相比之下,世界模型(World Models)能够基于当前观测与动作预测未来的视觉状态,从而同时理解视觉信息和行为动态。尽管具备这一优势,世界模型却无法直接生成动作输出,这导致其在需要显式动作规划的应用场景中存在功能上的空白。
为了解决 VLA 模型与世界模型各自的局限,我们提出 WorldVLA —— 一种基于自回归机制的统一动作与图像理解与生成模型。如下图所示,WorldVLA 使用三个独立的编码器分别处理图像、文本和动作数据。不同模态的 token 被设计为共享相同的词表,从而使得在同一个语言模型架构下可以统一完成跨模态的理解与生成任务。

其中,世界模型部分通过输入动作来生成对应的视觉表示,从而学习环境中的物理动态规律。这种对动作的解读与物理世界的建模对于动作模型的决策至关重要。与此同时,嵌入在 WorldVLA 中的动作模型也反过来增强了对视觉信息的理解,进一步提升世界模型在图像生成方面的准确性。这种双向增强机制使整个系统在理解和生成图像与动作方面更加鲁棒和全面。
此外,已有研究表明,动作分块(action chunking)和并行解码技术对动作模型的性能有显著影响。然而,我们在实验中发现,在自回归模型中连续生成多个动作时会导致性能下降。主要原因在于,预训练的多模态语言模型主要接触的是图像和文本,而对动作的学习较少,因此在动作生成任务中泛化能力有限。而在自回归模型中,后续动作的生成依赖于前面的预测结果,一旦出现错误,便会随时间不断传播放大。为了解决这一问题,我们提出了一种动作注意力掩码策略(action attention masking strategy),在生成当前动作时选择性地屏蔽掉之前的动作信息。这种方法有效缓解了错误累积的问题,在动作分块生成任务中带来了显著的性能提升。
在 LIBERO 基准测试中,我们的 WorldVLA 相比使用相同主干网络的传统动作模型,在抓取成功率上提升了 4%。相较于传统的世界模型,WorldVLA 在视频生成质量上表现更优,FVD(Fréchet Video Distance)指标降低了 10%。这些结果充分说明,将世界模型与动作模型融合所带来的协同增益,验证了图像与动作统一理解与生成框架的优势。在动作分块生成任务中,传统自回归方式会导致抓取成功率下降 10% 到 50%。但引入我们的注意力掩码策略后,性能下降得到了明显缓解,抓取成功率提升了 4% 到 23%。
研究方法
VLA 模型可以根据图像理解生成动作;世界模型可以根据当前图像和动作生成下一帧图像;WorldVLA 将将两者融合,实现图像与动作的双向理解和生成,如下图所示。

WorldVLA 使用独立的编码器分别处理图像、文本和动作,并让这些模态共享同一个词汇表,从而在单一的大语言模型架构下实现跨模态的统一建模。这种设计不仅提升了动作生成的准确性,也增强了图像预测的质量。WorldVLA 使用 Action Model 数据和 World Model 数据来训练模型。Action Model 是根据图片输入和文本指令输入来输出动作,数据格式如下:

World Model 根据当前帧图片和动作来生成下一帧图片,数据格式如下:

在一次性输出多个 action 时,使用默认的自回归范式会使得效果变差。原因是动作模态并不在原本多模态大模型的预训练中,因此泛化能力较差,这样生成多个动作时就会有误差累积的问题。为了解决这个问题,WorldVLA 提出了一种 attention mask 策略,使得生成动作时只能看见前面的图片而不能看见前面的动作,从而解决动作累计误差问题,如下图所示。

实验结果
在 LIBERO benchmark 上的实验结果如下图所示,在没有预训练的情况下超越了需要预训练的全自回归模型 OpenVLA。

下图为 action model 的消融实验结果。对比 row2 和 row1 以及 row5 和 row4 可以看出,world model 的加入可以给 action model 带来更好的结果。Row3 可以看出,使用默认的 attention mask 会导致某些任务的成功率下降,但是从 row4 看出,我们提出的 attention mask 可以全面大幅提升任务的成功率。

Action Model 可视化 (Text + Image -> Action)
下图可以看出 WorldVLA 可以根据指令完成对应的动作。



World Model 可视化 (Action + Image -> Image)
下图可以看出 WorldVLA 可以根据动作和图片来生成下一帧图片。



#大模型时代如何得到更好的embedding表征?
本文作者通过分析MTEB排行榜前列的工作,总结出当前embedding模型主要特点,包括使用InfoNCE loss或类似损失函数、多任务训练以及基于大模型微调等,为读者提供了embedding技术发展的最新趋势和思路。
世界上本没有「不可能」,存在的「不可能」只是自己视角下的「不可能」。——爱工作的小小酥
LLM如何学习更好的embedding?
以往的训练embedding的模型都是以BERT架构为基础,使用MLM损失训练,得到模型可以在各种下游任务上微调,例如分类。
在大模型时代,我们经常采用语言模型损失建模,以预测下一个token的方式进行训练,这样训练的模型在很多任务上都超过了以前的模型,但这样的模型怎么提取embedding特征,用于其他检索相关任务呢?
最近注意到MTEB排行榜上多了很多基于现有的大模型训练的模型,在此整理一下embedding技术的发展,以备不时之需,但读的时候发现并不是所有论文都使用了LLM。
阅读了排行榜前排的工作,发现现在embedding模型主要有以下特点:
1、使用INfoNCE loss。
在之前训练BERT的时代,如果进行预训练,一般是用MLM任务,可能最近大家评测的很多任务或者大模型RAG的兴起,导致检索任务变得额外重要。下面的损失函数基本是用INfoNCE,个别使用了cosent loss(比较类似INfoNCE,是一个可以用于排序的loss)。
2、多任务训练。
使用INfoNCE loss进行训练的话,需要构建(query,正样本,负样本)三元组。对于检索类的任务,当然很容易构造,而对于分类、聚类的任务,就要想各种办法构造出这种格式,在下面的论文中主要涉及两种方式:
- 将分类、聚类的类别标签作为数据匹配的正样本或者负样本。(这个相对较多)
- 将分类、聚类的同类别其他数据作为正样本,不同类别的其他数据作为负样本。
其次,在多任务训练的时候,经常针对不同任务采取不同的损失函数,或者尽管都采用INfoNCE,对于非检索任务,一般不再采用in batch negative。
3、Matryoshka Representation Learning
俄罗斯套娃表示训练方法,其因为可以同时训练多个维度的向量表示,又不会影响性能的优势,在目前的embedding模型中经常被采用。(而且很多都是最大到1972)
4、多阶段训练
可能借鉴于目前LLM的训练流程,目前很多不使用LLM的embedding模型,也采用了多阶段进行训练,一般是划分为2阶段,先使用低质量文本对训练,然后使用人工标注的检索类数据集训练。
5、困难负样本挖掘
困难负样本挖掘一直是对比学习的重点,在下面的几篇论文中,很多也很强调困难负样本的重要性,但主要方法也比较受限,主要是以下几点:
- 单独训练一个embedding模型,给负样本打分,选择高分数据作为困难负样本(用的较多)
- 动态在训练过程中更换困难负样本,计算方式类似上面
6、使用合成数据
在大模型时代,经常使用LLM造数据,在embedding任务中,大家也是进行各种prompt工程构建检索类数据,主要是分为两阶段构造,先让模型「头脑风暴产生主题」,然后「根据主题生成三元组数据」。
7、文本表示方法
在这个方面和之前差不多,主要有以下几种:
- 使用最后一层特征的 mean pooling
- 使用一个特殊的token。[CLS]或者[EOS]
- 后面接一个attention pooling 层。
Piccolo2
Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
https://arxiv.org/abs/2405.06932
概要
这篇论文核心点主要有:
- 将不同的任务使用「不同的损失函数」进行训练,为检索、排序、分类、聚类配置不同的loss,从而兼顾每一种任务的特点,在各个任务上都可以达到最优的效果。
- 在训练过程中加入Matryoshka Representation Learning,从而训练出动态维度的向量。其中最高维度到1972。
- 使用合成数据训练。
- 负样本挖掘。使用piccolo-base-zh使用相似度排名在50-100的随机15个作为困难负样本。
模型结构依旧是bert,训练完的参数量为300M。
训练方式
(1)Retrieval and Reranking Loss
对于检索和排序任务,采用标准的INfoNCE loss,并使用in batch negative。
(2)Semantic Textual Similarity(STS) and PairClassification Loss
在这种任务中,其label一般不是一个绝对的值,例如相似度分数,如果将这种任务单纯的表示为INfoNCE中的三元组的形式,就丢失了这部分信息,因此,对于这些任务,作者使用了cosent loss。具体原理可参考下面的链接:
CoSENT(一):比Sentence-BERT更有效的句向量方案 - 科学空间|Scientific Spaces
https://kexue.fm/archives/8847
(3)Classification and Clustering Loss
在分类和聚类任务中,没有样本对的概念,而是一个标签。作者对于这种任务,是将其label和数据作为一个正样本pair,当前数据和其他label作为负样本pair,采样标准的INfoNCE loss进行训练,但不再使用in batch negative。
最终的损失函数为上述3个loss相加。
合成数据
为了构造出丰富多样的检索相关的数据,作者分为2个步骤进行,分别为生成话题、根据话题生成样本对。最后生成了200k的数据,下面为整个训练过程中采用的数据量。
Conan-embedding
Conan-embedding: General Text Embedding with More and Better Negative Samples
https://arxiv.org/abs/2408.15710
概述
困难负样本一直是对比学习训练过程中的一个关键点,困难负样本的好坏有时会非常影响模型的性能。现有的挖掘困难负样本的方法基本集中在训练之前,经常使用训练好的embedding模型计算负样本的相似度,将高相似度的负样本筛选出来作为困难负样本。但这样一次性决定困难负样本的方法是最优的吗?模型训练过程中会不会改变负样本的难度?
在这篇论文就是集中在这个问题上研究的,设计了一种在训练过程中挖掘负样本的方法,可以根据模型训练的状态选择合适的困难负样本进行学习。其次,为了进一步扩大负样本的数量,提出了Cross-GPU Batch Balance Loss (CBB)。
在模型结构上,依旧采用bert,使用的是BERT large模型,并且也使用了Matryoshka Representation Learning (MRL) 技术训练动态embedding,最大到1792。
训练方式
第一阶段,使用bge-large-zh-v1.5筛选出高质量数据(阈值高于0.4),这里的数据是常规文本对和合成数据,总共有0.75 billion。采用标准的INfoNCE loss 进行训练,并使用in batch negative。
第二阶段,主要使用检索和 STS (semantic textual similarity)任务数据,并采用不同的损失函数,其中检索使用标准的INfoNCE loss,STS使用CoSENT loss。
动态困难负样本
为了在训练过程中动态的选择困难负样本,作者在每100step进行检查一次,查看当前困难负样本乘以1.15是否小于原始的score并且绝对分数小于0.8,如果存在,则进行更换困难负样本。
对于第 轮,更换的时候,选择 到 之间的负样本,其中 为困难负样本的个数。(不懂为啥这样选??)
Cross-GPU Batch Balance Loss
由于训练过程中针对不同任务采用了不同的损失,在以往的训练过程中,是每一个batch都采样同一来源的数据,但这样训练会导致不稳定性,具体可看下图,cross是合并后的损失。
因此,作者将两种任务合并训练,损失为两者的相加,使用不同的gpu来平衡batch的大小。
GTE
Towards General Text Embeddings with Multi-stage Contrastive Learning
https://arxiv.org/abs/2308.03281
概要
阿里GTE系列模型的第一个版本,和以往训练bert不一样的地方在于:
- 收集大量数据
- 分为两阶段进行训练
- 采用升级版对比学习损失,扩大了负样本
- 更关注检索任务
模型结构依旧采用bert,感觉主要是靠大数据量造就了一个比较好的效果。
模型结构
模型的整体结构没有作出改变,加载预训练的MiniLM、bert分别训练出3种大小的模型,分为small、base、large,不同规模的模型参数如下:
损失函数
均衡采样
在预训练阶段由于混合了多种来源的数据,而不同来源的数据数量存在较大差异,为了缓解这种多种数据源数据严重不均衡的问题,使用了基于原始数据量的采样。具体来说,在每一轮的训练过程中,从每个来源采样的概率为其在所有数据中所占的一个大致比例,具体公式如下:
对于上述公式中的 ,论文中取的是0.5。并且为了不让模型「偷懒」,确保每个batch内都是相同类别的数据(后续的mGTE也沿用了这种采样方法)。
升级版InfoNCE
对于(query, document) 这样的数据对来说,原始的InfoNCE是in batch negative,即每一个query和同batch内的其他document构成负样本。因此,在常规的对比学习任务中,一般是batch越大越好,这样样本见到的负样本会更多,会更有利于模型学习,但batch又收到机器显存的限制。
因此,在这篇论文中,在不增大batch的情况下,为了增大每个样本的负样本数量,作者在原始InfoNCE loss的基础上做了进一步的改进,即不再仅仅使用「单向的负样本」,而是使用了「双向的in batch query」和「document negative」。
操作过程也比较简单,可以想一想对于一个batch内的所有数据来说,一条(query, document) 是不是和其他所有的(query, document) 都可以形成负样本,并且不限于(query, document) 这种格式。
那么,我们就可以在原始(query, document) 的基础上扩展(query, query) 和(document, document) 也构成负样本。
具体可以看一下下面的公式,对于一个包含(query, document) 的batch数据:

改进版的InfoNCE的负样本构成如下:
- 当前query和其他document(原始InfoNCE的负样本)
- 当前query和其他query(新增)
- 其他query和当前document(新增)
- 其他document和当前document(新增)
训练方式
第一阶段 无监督预训练
整篇论文主打多种数据、大批量数据训练,此部分就将各种来源的text pair数据进行了混合,数据量总共为788M,具体比例如下:
第二阶段 监督微调
为了在下游检索任务上得到更好的效果,此部分使用更高质量的人类标注pair数据,并使用其他的检索器抽取困难负样本,包括web search (e.g., MS MARCO),open-domain QA (e.g., NQ), NLI (e.g., SNLI), fact verification (e.g., FEVER), paraphrases (e.g., Quora),总共大约3M pairs。
mGTE
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
https://arxiv.org/abs/2407.19669
概要
从模型的名称mGTE就可以看出,这篇论文主要着重点在「多语言」上,除此之外,论文还着重强调在「长文本」上的优越性。
和以往的BERT系列模型不同,此模型支持8192长度(之前都是512长度),并采用较为复杂的多阶段训练流程,同样和GTE类似,使用了大量的数据,最后不仅训练出召回模型,同时也得到了一个优秀的reranker模型。
由于在此时这个阶段,对于如何学习更好的embedding问题?已经出现了各种各样的技术,而在这篇论文中我们可以看到的主要有可以同时训练出多个维度embedding的Matryoshka Embedding方法(俄罗斯套娃embedding方法)、增强训练效率的unpadding技术、以及扩展长文本的Rotary Position Embedding编码技术。
模型结构
在模型结构上依旧采用常规的BERT结构,在其中加入了很多技巧性的工作。整体而言,如下图所示,总共产生了5个模型。这5个模型由一个复杂的训练流程串联起来,最终使用的主要是检索模型(TRM)和精排模型(reranker)。
虽然训练流程较长,但差异性并不是很大,下面先进行简短的总结一下:
- 2k Text Encoder 和 8k Text Encoder 采用相同的数据和训练方法,只是输入的最大长度及个别训练参数不一样。并且采用以往bert使用的MLM损失进行训练。
- 1k Text Embedder 是向检索任务过度的一个模型,采用常规infoNCE进行训练。
- 8k TRM和8k Reranker采用相同的数据和训练损失,只是加载的基础模型不同(从图中也可以看出),且输入方式不同(毕竟一个双塔一个单塔)。
Text Encoder&Text Embedder
从bert之后,已经出现了很多如何更好的学习embedding的新技术,在这篇论文中主要用到有
- 大模型经常采用的Rotary Position Embedding编码方法可以扩展到训练未见过的长度
- unpadding技术可以更有效的训练
- 为了使用FlashAttention,将bert中的FFN改为gated linear unit (GLU)。
各种技术的原理可以再去查找相关资料,本文不再赘述,下面给出2篇unpadding相关的论文。
A Bidirectional Encoder Optimized for Fast Pretraining
https://mosaicbert.github.io/
https://arxiv.org/pdf/2208.08124
TRM&Reranker
对于检索和排序模型而言,整体的模型结构和上述类似,只不过是输入的方式不同。
在检索模型中,query和document是分别输入,使用CLS token向量作为整体的特征表示。
在精排模型中,query和document是拼接输入,同样使用CLS token向量作为整体的特征表示。
同样的,在微调这个阶段,在上述预训练的基础上,也额外使用了很多embedding的各种技术,包括Matryoshka Embedding方法(俄罗斯套娃embedding方法)、可以增强长文本能力的Sparse Representation loss。
训练方法
Text Encoder
在此部分,主要是为了增强模型对文本的理解能力,以及扩展长文本能力。因此,采用了常规的MLM的损失函数,将mask比例设置为30%,并使用了课程学习的训练方法,将文本长度从2k扩展到8k。
由于这篇论文主打「多语言」,因此在整个训练语料上加入了各种各样语言以及来源的数据,在这一阶段中,总共包括75种语言数据,总token数为1028B。
除此之外,在训练过程中,采用了一个采样的小技巧。为了平衡采样不同语言的数据,以防数据过多的数据被训练更多次,首先计算出每种语言所占的比例,然后采用下述多项式分布的方式进行采样,并且确保一个batch内是同一种来源的数据。
在这一过程中的训练参数如下:
Text Embedder
通过上述MLM损失训练后的模型,可以对文本有较好的语义理解能力,但在检索任务中可能效果没有那么好。而对于目前针对检索任务训练的各种召回和排序模型而言,基本采用对比学习的方式。
因此,为了增强模型在下游检索任务上的效果,作者同样采用对比学习损失做了继续预训练(CPT),损失函数为InfoNCE loss和in batch negative。
训练数据同样包括了各种语言各种来源的数据,主要有英文数据对、中文数据对、多语言、交叉语言指令和翻译数据对,总共2,938.8M pairs。
TRM&Reranker
得到一个适合检索的预训练模型之后,已经可以很好的做检索相关的任务了,但还不是一个reranker模型,无法做到精确排序。因此,在上述模型的基础上,作者进一步筛选高质量的pair数据,使用更贴合这个场景的训练损失,以得到更优的检索和排序模型。
这里的TRM和reranker训练过程大体一致,只是采用的预训练模型不一样,TRM使用1k Text Embedder作为基础模型,reranker使用8k Text Encoder 作为基础模型(官方也尝试使用1k Text Embedder,但无增益)。两者采用的训练数据如下:
真个微调过程中,在标准的infoNCE 损失的基础上,使用Matryoshka Embedding方法(俄罗斯套娃embedding方法)得到动态的embedding维度,使用可Sparse Representation loss进一步增强长文本能力。
(1)Matryoshka Embedding方法
原始的embedding模型中,输出是一个固定维度,例如768,最后使用768这个向量计算一个loss。在推理的时候,同样只能使用768维度的向量,无法压缩到512或者扩展到更高维度(除了重新训练模型)。
Matryoshka Embedding方法即是为了解决这种问题而提出的,这个直译「俄罗斯套娃embedding方法」。意思是将原先的768维度缩小为多个维度,例如[32, 64,128, 256,768],训练的时候每一个维度后面单独使用一个线性分类器进行转换一下,然后分别计算损失,最后所有损失相加得到最终的损失。
Matryoshka Representation Learning
https://arxiv.org/abs/2205.13147
(2)Sparse Representation方法
这个方法来源于BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation(https://arxiv.org/abs/2402.03216)。
在标准的INfoNCE loss的计算过程中,我们需要计算一个query和document的相似度,这里一般采用余弦相似度或者内积,在这个方法中,主要是对这个相似度计算方法进行改变的,具体来说,为每个token计算一个权重
然后计算「每个pair中相同的token的权重乘积和」作为当前pair的相似度,替换掉标准INfoNCE中的相似度计算方式。整个微调过程中的损失为:
其中,前一部分为上述的Sparse Representation loss,第二部分为Matryoshka Embedding 的loss。
NV-Embed
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
https://arxiv.org/abs/2405.17428
概述
LLM学习embedding表示的方法都有什么?
目前很多论文基本将最后一个token的embedding作为整个文本embedding表示,但这种方法由于太依靠最后一个token的表示,容易带来偏差。
因此,在这篇论文中,提出一个Latent Attention Layer对LLM最后的embedding进一步编码,以得到信息融合程度更高的embedding表示。
那模型的其他设置有什么特殊的地方吗?
基本没有了,在训练方式上,和常规模型比较类似,采用2阶段训练方式。loss为和标准的INfoNCE,模型使用Mistral-7B,并使用lora进行训练,设置rank=16,alpha=32。
并且作者强调自己没有使用合成数据。
样本构造方式
对于(query,document)数据对,只在query前面加上指令,document前面不添加。后续也有工作指出推理的时候都可以添加,不会导致不一致。

训练方式
(1)第一阶段
采用公开检索数据,并使用in batch negative进行训练,训练之前使用单独训练的embedding 模型筛选高质量数据。
(2)第二阶段
这一部分采用非检索数据集,主要包括分类和聚类数据集,从MTEB英文训练集中筛选的各种分类数据集。为了将这种数据转为(query,document)数据对,作者按照标签进行归类,将同类别的数据作为正样本,不同类别的样本作为负样本(其他工作是将label作为匹配的数据)。
Improving Text Embeddings with Large Language Models
Improving Text Embeddings with Large Language Models
https://arxiv.org/abs/2401.00368
概要
现有的训练embedding表征的模型常常采用大批量的数据,2阶段方式进行训练。这篇论文不再使用那么复杂的流程,只使用合成数据,并且只有一个阶段训练流程,就达到了有竞争力的效果。
模型配置
和以往的LLM embedding模型差不多,同样使用Mistral-7b进行lora训练,并将lora设置为16。
损失函数依旧采用标注的INfoNCE loss和in batch negative。
最后训练的时候加入一些带标注数据,总共1.8M。
合成数据构造方法
为了构造出具有较强多样性的数据,作者将任务归为2类进行设计prompt,分别为非对称任务和对称任务。但都是使用gpt3.5-Turbo和gpt4进行生成。
(1)非对称任务
非对称任务主要包括短-长匹配、短-短匹配、长-短匹配、长-长匹配。对于这些子任务,分别设计prompt。并将生成数据的流程拆分为2步,先生成task名称,再针对task生成相应的数据。
(2)对称任务
作者将这部分任务分为monolingual semantic textual similarity (STS) 和 bitext retrieval。对于这种任务,直接使用1步生成相应的数据,具体可以看下面的示例。
为了进一步增强数据的多样性,在prompt构造的过程中,随机选择生成的长度和生成的语言,最终构造出500k数据。
GRIT
Generative Representational Instruction Tuning
https://arxiv.org/abs/2402.09906
概要
一个模型可以兼容生成和embedding任务吗?
常规大模型基本是以生成方式进行建模,如果要借用大模型架构构建embedding模型,一般是将生成损失改为INfoNCE,但这样建模的模型就失去了生成能力。
这篇论文就从这个角度出发,不丢弃任何一方,同时使用INfoNCE和生成损失训练模型,让大模型兼顾生成能力和embedding能力。
模型配置
但混合两种任务一起训练会有一个问题,对于embedding任务来说,一般都是采用双向注意力机制,让模型充分学习token之间的语义关系;但对于生成任务来说,一般采用 causal attention,后面的token只能看到前面的token。因此,作者将不同任务的attention矩阵进行了更改,并且embedding任务取最后一层特征的mean pooling作为最后的特征向量,具体的模型结构如下:
使用的基础模型和其他的模型差不多,也是Mistral 7B,同时也训练出了Mixtral 8x7B,都是全量训练(前面有的是lora训练)。
损失函数
对于embedding任务,采用标准的INfoNCE loss,并使用in batch negative。对于生成任务,采用保准的生成损失(预测下一个token),两者加权得到最终的损失。
Reranker
虽然模型没有单独为排序任务训练,但也进行了reranker的评测,借鉴的是另一篇论文:arXiv reCAPTCHA(https://arxiv.org/abs/2304.09542),将召回的结果,拼接到prompt中,借助模型的生成能力进行排序,具体使用的prompt格式如下:
总结
随着大型语言模型(LLM)的发展,模型的通用能力逐渐增强。通常,这些模型通过混合各种任务数据进行训练,并采用多阶段训练策略。
通过阅读上面的论文,发现embedding模型也在朝这个方向发展,开始采用混合多种任务数据的训练方式。然而,由于嵌入模型的特殊性,不同任务通常使用不同的损失函数。并且根据数据的质量或其与下游任务的契合程度,将数据分为两批,进行多阶段训练。
在写这篇文章的时候,突然想到一个问题:知乎文章和视频号是不是很类似,都是选题、调研、整理、归纳的过程。而这整个过程是特别考验一个人的学习能力的,如何快速找到核心点,学明白,然后整理成别人很容易理解的样子?有时候并不是一时半会可以掌握的。
#从Llama-1到Llama-3
万字长文带你梳理Llama开源家族
Llama模型的发布不仅证明了开源模型在全球AI领域的重要性,也为AI的未来发展方向提供了新的视角和动力。通过持续的技术进步和社区驱动的创新,Llama有望继续推动全球AI技术的广泛应用和发展。
引言
在AI领域,大模型的发展正以前所未有的速度推进技术的边界。
北京时间4月19日凌晨,Meta在官网上官宣了Llama-3,作为继Llama-1、Llama-2和Code-Llama之后的第三代模型,Llama-3在多个基准测试中实现了全面领先,性能优于业界同类最先进的模型。
纵观Llama系列模型,从版本1到3,展示了大规模预训练语言模型的演进及其在实际应用中的显著潜力。这些模型不仅在技术上不断刷新纪录,更在商业和学术界产生了深远的影响。因此,对Llama模型不同版本之间的系统对比,不仅可以揭示技术进步的具体细节,也能帮助我们理解这些高级模型如何解决现实世界的复杂问题。
文本将详细梳理Llama开源家族的演进历程,包括:
- Llama进化史(第1节)
- 模型架构(第2节)
- 训练数据(第3节)
- 训练方法(第4节)
- 效果对比(第5节)
- 社区生态(第6节)
- 总结(第7节)
1. Llama进化史
本节将对每个版本的Llama模型进行简要介绍,包括它们发布的时间和主要特点。
1.1 Llama-1 系列
Llama-1 [1]是Meta在2023年2月发布的大语言模型,是当时性能非常出色的开源模型之一,有7B、13B、30B和65B四个参数量版本。Llama-1各个参数量版本都在超过1T token的语料上进行了预训训练,其中,最大的65B参数的模型在2,048张A100 80G GPU上训练了近21天,并在大多数基准测试中超越了具有175B参数的GPT-3。
由于模型开源且性能优异,Llama迅速成为了开源社区中最受欢迎的大模型之一,以Llama为核心的生态圈也由此崛起。我们将在第6节对这一生态进行详细介绍。与此同时,众多研究者将其作为基座模型,进行了继续预训练或者微调,衍生出了众多变体模型(见下图),极大地推动了大模型领域的研究进展。

唯一美中不足的是,因为开源协议问题,Llama-1不可免费商用。
1.2 Llama-2 系列
时隔5个月,Meta在2023年7月发布了免费可商用版本 Llama-2 [2],有7B、13B、34B和70B四个参数量版本,除了34B模型外,其他均已开源。

相比于Llama-1,Llama-2将预训练的语料扩充到了 2T token,同时将模型的上下文长度从2,048翻倍到了4,096,并引入了分组查询注意力机制(grouped-query attention, GQA)等技术。
有了更强大的基座模型Llama-2,Meta通过进一步的有监督微调(Supervised Fine-Tuning, SFT)、基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)等技术对模型进行迭代优化,并发布了面向对话应用的微调系列模型 Llama-2 Chat。
通过“预训练-有监督微调-基于人类反馈的强化学习”这一训练流程,Llama-2 Chat不仅在众多基准测试中取得了更好的模型性能,同时在应用中也更加安全。
随后,得益于Llama-2的优异性能,Meta在2023年8月发布了专注于代码生成的Code-Llama,共有7B、13B、34B和70B四个参数量版本。

1.3 Llama-3
系列2024年4月,Meta正式发布了开源大模型 Llama 3,包括8B和70B两个参数量版本。除此之外,Meta还透露,400B的Llama-3还在训练中。

相比Llama-2,Llama-3支持8K长文本,并采用了一个编码效率更高的tokenizer,词表大小为128K。在预训练数据方面,Llama-3使用了超过15T token的语料,这比Llama 2的7倍还多。
Llama-3在性能上取得了巨大飞跃,并在相同规模的大模型中取得了最优异的性能。
另外,推理、代码生成和指令跟随等能力得到了极大的改进,使Llama 3更加可控。
2. 模型架构
本节将详细描述Llama的模型架构,包括神经网络的大小、层数、注意力机制等。
目前,主流的大语言模型都采用了Transformer[3]架构,它是一个基于多层自注意力(Self-attention)的神经网络模型。
原始的Transformer由编码器(Encoder)和解码器(Decoder)两个部分构成,同时,这两个部分也可以独立使用。
例如基于编码器的BERT [4]模型和基于解码器的GPT [5]模型。
Llama模型与GPT类似,也是采用了基于解码器的架构。在原始Transformer解码器的基础上,Llama进行了如下改动:
- 为了增强训练稳定性,采用前置的RMSNorm [6]作为层归一化方法。
- 为了提高模型性能,采用SwiGLU [7]作为激活函数。
- 为了更好地建模长序列数据,采用RoPE [8]作为位置编码。
- 为了平衡效率和性能,部分模型采用了分组查询注意力机制(Grouped-Query Attention, GQA)[9]。
具体来说,首先将输入的token序列通过词嵌入(word embedding)矩阵转化为词向量序列。然后,词向量序列作为隐藏层状态依次通过𝐿个解码器层,并在最后使用RMSNorm进行归一化。归一化后的隐藏层状态将作为最后的输出。
在每个解码器层中,输入的隐藏层状态首先通过RMSNorm归一化然后被送入注意力模块。注意力模块的输出将和归一化前的隐藏层状态进行残差连接。之后,新的隐藏层状态进行RMSNorm归一化,然后被送入前馈网络层。类似地,前馈网络层的输出同样进行残差连接,作为解码器层的输出。
每个版本的Llama由于其隐藏层的大小、层数的不同,均有不同的变体。接下来,我们将展开看下每个版本的不同变体。
2.1 Llama-1 系列
Llama-1 模型架构,详见MODEL_CARD:
https://github.com/meta-llama/llama/blob/main/MODEL_CARD.md

为了更好地编码数据,Llama-1使用BPE [10]算法进行分词,具体由sentencepiece进行实现。值得注意的是,Llama-1将所有数字分解为单独的数字,并对未知的UTF-8字符回退到字节进行分解。词表大小为32k。
2.2 Llama-2 系列
Llama-2 模型架构,详见MODEL_CARD(同上)

Llama-2使用了和Llama-1相同的模型架构以及tokenizer。与Llama-1不同的是,Llama-2将上下文长长度扩展到了4k,并且34B和70B参数量版本使用了GQA。
2.3 Llama-3 系列
Llama-3 模型架构,详见MODEL_CARD:
https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md

与Llama 2相比,Llama-3将tokenizer由sentencepiece换成了tiktoken,这与GPT4 保持一致。同时,词表大小由32k扩展到了128k。另外,为了提高模型效率,Llama-3 8B和70B都采用了GQA。同时上下文长度也扩展到了8k。
3. 训练数据
本节将对每个版本的训练数据进行简要介绍,包括数据来源、规模和处理方式。
3.1 Llama-1 系列
Llama-1使用了海量无标注数据进行自监督学习,这些预训练数据由多个来源混合而成,且都是公开的数据。各个来源的数据量和采样比例见下表。

- 英语CommonCrawl:Llama-1预处理了2017年至2020年间的五个CommonCrawl数据集。该过程在行级别去重,使用fastText线性分类器进行语言识别以去除非英语页面,并使用n-gram语言模型过滤低质量内容。此外,Llama-1训练了一个线性模型来分类维基百科中用作参考的页面和随机采样的页面,并丢弃了未被分类为参考的页面。
- C4:在探索性实验中,Llama-1观察到使用多样化的预处理CommonCrawl数据集可以提升性能。因此,Llama-1的数据中包括了公开可获得的C4数据集。C4的预处理也包括去重和语言识别步骤:与CCNet的主要区别在于质量过滤,主要依赖于标点符号的存在或网页中的单词和句子数量等启发式规则。
- Github:Llama-1使用Google BigQuery上可公开获取的GitHub数据集。Llama-1仅保留在Apache、BSD和MIT许可下分发的项目。此外,Llama-1还使用基于行长度或字母数字字符比例的启发式规则过滤低质量文件,并用正则表达式移除如页眉等样板内容。最后,Llama-1在文件级别对结果数据集进行去重,匹配精确相同的内容。
- 维基百科:Llama-1添加了2022年6月至8月期间的维基百科数据,涵盖使用拉丁或西里尔文字的20种语言。Llama-1处理数据以移除超链接、评论和其他格式化的样板内容。
- Gutenberg和Books3:Llama-1在训练数据集中包括了两个书籍语料库:Gutenberg项目(包含公共领域的书籍)和ThePile的Books3部分,一个公开可获得的用于训练大型语言模型的数据集。Llama-1在书籍级别进行去重,移除超过90%内容重合的书籍。
- ArXiv :Llama-1处理ArXiv的Latex文件,以增加科学数据到Llama-1的数据集。Llama-1移除了第一节之前的所有内容以及参考文献部分。Llama-1还移除了.tex文件中的注释,并内联扩展了用户编写的定义和宏,以增强论文间的一致性。
- Stack Exchange:Llama-1包括了Stack Exchange的数据转储,这是一个涵盖从计算机科学到化学等多种领域的高质量问题和答案的网站。Llama-1保留了28个最大网站的数据,移除了文本中的HTML标签,并根据得分将答案排序(从最高到最低)。
经过上述处理,Llama-1的整个训练数据集包含大约1.4T token。对于Llama-1的大部分训练数据,每个token在训练期间只使用一次,但维基百科和Books的数据进行了大约两个epoch的训练。
3.2 Llama-2
Llama-2 预训练使用了来自公开可用源的 2T个数据token(未详细指出具体的开源数据)。Llama-2-Chat 还在为此项目创建的27,540个提示-响应对上进行了额外的微调,其表现优于更大但质量较低的第三方数据集。为了实现AI对齐,使用了包含1,418,091个Meta示例和七个较小数据集的组合的人类反馈强化学习(RLHF)。在Meta示例中,平均对话深度为3.9,Anthropic Helpful 和 Anthropic Harmless集合为3.0,包括OpenAI Summarize、StackExchange等在内的其他五个集合的平均对话深度为1.0。微调数据包括公开可用的指令数据集以及超过一百万个新的人类标注示例。
在预训练过程中,Llama-2对数据的安全性进行了全面考量。通过对预训练数据进行分析,Llama-2能够增加透明度,并发现潜在的问题根源,如潜在的偏见。Llama-2采取了一系列措施,包括遵循 Meta 公司的隐私和法律审查流程,排除已知含有大量个人信息的网站的数据。此外,Llama-2未对数据集进行额外的过滤,以使模型在各种任务中更广泛可用,同时避免过度清洗可能导致的意外人口统计消除。对于语言的代表性和毒性的分析,Llama-2使用了相应的工具和数据集,以了解预训练数据的特征,为模型的安全调整提供指导。这一过程确保了我们的模型在安全性方面得到了充分的考虑,并促使我们在部署模型之前进行了重要的安全调整。
Llama 2的预训练主要集中在英语数据上,尽管实验观察表明模型在其他语言方面已有一定的熟练度,但由于非英语语言的预训练数据量有限,其熟练度受到限制(如下图所示)。因此,该模型在非英语语言中的性能仍然脆弱,应谨慎使用(说明多语言能力差:有可能是词表较小导致)。

预训练数据截至到2022年9月,但某些调整数据较新,直到2023年7月。
在Llama2发布的技术报告中有说明:
我们将继续努力微调模型,以提高在其他语言环境下的适用性,并在未来发布更新版本,以解决这一问题。
当前Llama-3 不但扩充了词表大小而且增加了多语言的训练语料。从而完成了在Llama2在技术报告的承诺,而且在当前公布出来的多语言任务中获得了大幅度提升的性能。
3.3 Llama-3 系列
为了更好训练Llama-3,研究人员精心设计了预训练语料库,这些不仅关注数量,还特别强调了质量。LLAMA-3其训练数据量大幅增加,从LLAMA-2的2T Tokens扩展到了15T Tokens,增长了约8倍。其中,代码数据扩充了4倍,显著提升了模型在代码能力和逻辑推理能力方面的表现。
LLAMA-3提供了三种规模的模型版本:小型模型具有8B参数,其性能略优于Mistral 7B和Gemma 7B;中型模型则拥有70B参数,其性能介于ChatGPT 3.5和GPT 4之间;大型模型规模达到400B,目前仍在训练中,旨在成为一个多模态、多语言版本的模型,预期性能应与GPT 4或GPT 4V相当。
值得注意的是,LLAMA-3并没有采用MOE(Mixture of Experts)结构,这种结构主要用于降低训练和推理成本,但在性能上通常无法与同规模的密集型(Dense)模型相比。随着模型规模的扩大,如何降低推理成本将成为一个需要关注的问题。
此外,LLAMA-3的训练数据包括了大量的代码token和超过5%的非英语token,来源于30多种语言。这不仅使得模型在处理英语内容时更加高效,也显著提升了其多语言处理能力,这表明LLAMA-3在全球多语言环境中的适应性和应用潜力。
为确保数据质量,Meta开发了一系列数据过滤pipeline,包括启发式过滤器、NSFW过滤器、语义重复数据删除技术及用于预测数据质量的文本分类器。这些工具的有效性得益于先前版本Llama的表现,特别是在识别高质量数据方面。
此外,Meta通过大量实验评估了在最终预训练数据集中混合不同来源数据的最佳策略,确保Llama-3能在多种场景下展现卓越性能,如日常琐事、STEM 领域、编程和历史知识等。
4. 训练方法
本节将对每个版本的训练方法进行简要介绍,包括预训练、有监督微调和基于人类反馈的强化学习。
4.1 Llama-1系列
Llama-1模型是一个基础的自监督学习模型,它没有经过任何形式的特定任务微调。自监督学习是一种机器学习技术,其中模型通过分析大量未标记的数据来预测其输入数据的某些部分。这种方法允许模型在没有人类标注的数据的情况下自动学习数据的内在结构和复杂性。Llama-1在公布的技术报告中详细描述了使用AdamW优化器的机器学习模型的具体训练配置。AdamW是对Adam优化器的改进,可以更有效地处理权重衰减,从而提高训练的稳定性。β1和β2参数的选择影响训练过程的收敛行为和稳定性。Llama-1描述的余弦学习率调度是一种有效的技术,用于在训练期间调整学习率,通过逐渐减少学习率,在某些情况下可以导致更好的收敛。实施0.1的权重衰减和1.0的梯度裁剪是预防过拟合和确保数值稳定性的标准做法。使用预热步骤是一种策略性方法,旨在训练过程初期稳定训练动态。根据模型大小调整学习率和批量大小是一种优化资源分配和效率的实用方法,有可能提高模型性能。
Llama-1也展示了一系列针对大规模语言模型训练进行的优化措施。通过使用xformers库[12]中的causal multi-head attention(通过不存储注意力权重和不计算由于语言建模任务的因果性质而被屏蔽的key/query.分数来实现的)的高效实现,减少了内存占用和计算时间,显示了在处理大量数据时对效率的关注。此外,采用手动实现反向传播函数代替依赖自动微分系统,以及利用检查点技术保存计算成本高的激活,都是提高训练速度和减少资源消耗的有效策略。通过模型和序列并行性以及优化GPU之间的通信,进一步提升了训练过程的效率。这些优化措施特别适合于训练参数庞大的模型,如650亿参数的模型,能显著减少训练时间,提高整体的运算效率。整体上,这些优化技术体现了在高性能计算领域对资源管理和效率优化的深入考量,对于推动大规模语言模型的发展具有重要意义。
4.2 Llama-2系列
Llama-2模型是在Llama-1的基础上进一步发展的,而Llama-2-Chat模型则是基于Llama-2进行微调的版本。这两个模型保持了固定的4k上下文长度,这与OpenAI的GPT-4在微调过程中可能增加的上下文长度不同。
在Llama-2和Llama-2-Chat的微调中,采用了自回归损失函数,这是一种在生成模型中常见的方法,模型预测下一个token时会考虑到之前的所有token。在训练过程中,用户输入提示的token损失被清零,这意味着模型被训练以忽略这些特定的token,从而更专注于生成回复。
Llama-2-Chat的训练过程如下图所示。整个过程起始于利用公开数据对Llama-2进行预训练。在此之后,通过有监督微调创建了Llama-2-Chat的初始版本。随后,使用基于人类反馈的强化学习(RLHF)方法来迭代地改进模型,具体包括拒绝采样(Rejection Sampling)和近端策略优化(Proximal Policy Optimization, PPO)。在RLHF阶段,人类偏好数据也在并行迭代,以保持奖励模型的更新。

4.3 Llama-3系列
与Llama-2类似,Llama-3系列也有两个模型——预训练模型Llama-3和微调后的模型Llama-3-Instruct。
在预训练阶段,为了有效地利用预训练数据,Llama-3投入了大量精力来扩大预训练。具体而言,通过为下游基准测试制定一系列扩展法则(scaling laws),使得在训练之前就能预测出模型在关键任务上的性能,进而选择最佳的数据组合。
在这一过程中,Llama-3对扩展法则有了一些新的观察。例如,根据DeepMind 团队提出的Chinchilla [11]扩展法则,8B模型的最优训练数据量约为200B token,但实验发现,即使训练了两个数量级的数据后,模型性能仍在继续提高。在多达15T token上进行训练后,8B和70B参数的模型都继续以对数线性的方式提升性能。
为了训练最大的Llama-3模型,Meta结合了三种并行策略:数据并行、模型并行和流水并行。当同时在16K GPU上进行训练时,最高效的策略实现了每个GPU超过400 TFLOPS的计算利用率。最后,模型在两个定制的24K GPU集群上进行了训练。
为了最大限度地延长GPU的正常运行时间,Meta开发了一个先进的新训练堆栈,可以自动检测、处理和维护错误。另外还大大提高了硬件可靠性和无声数据损坏的检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销。这些改进使总的有效训练时间超过95%。综合起来,这些改进使Llama-3的训练效率比Llama-2提高了约三倍。
在微调阶段,Meta对模型的微调方法进行了重大创新,结合了有监督微调(Supervised Fine-Tuning, SFT)、拒绝采样、近似策略优化(Proximal Policy Optimization, PPO)和直接策略优化(Direct Policy Optimization, DPO)。这种综合方法优化了模型在执行复杂的推理和编码任务时的表现。特别是通过偏好排序的训练,Llama-3在处理复杂的逻辑推理问题时能更准确地选择最合适的答案,这对于提高AI在实际应用中的可用性和可靠性至关重要。
5. 效果对比
本节将对比不同版本在众多基准测试中的效果差异。
5.1 Llama-2 vs Llama-1
Meta官方数据显示,Llama-2在众多基准测试中都优于Llama-1和其他开源语言模型。

5.2 Llama-3 vs Llama-2
Meta官方数据显示,在各自参数规模上,Llama-3 8B和70B版本都取得了不错的成绩。8B模型在众多基准测试中均胜过Gemma 7B和Mistral 7B Instruct,而70B模型超越了闭源模型Claude 3 Sonnet,对比谷歌的Gemini Pro 1.5性能也是相当。

同时,在Llama-3的开发过程中,Meta还开发了一个包含1800个提示的高质量人类评估集。评测结果显示,Llama 3不仅大幅超越Llama 2,也战胜了Claude 3 Sonnet、Mistral Medium和GPT-3.5这些知名模型。

Llama-3之所以能够取得如此出色的成绩,离不开它预训练模型的优异性能。在众多基准测试中,8B模型超越了Mistral 7B和Gemma 7B,70B模型则战胜了Gemini Pro 1.0和Mixtral 8x22B。

另外,Meta表示,最大的Llama-3仍在训练中,其参数超过400B,并在多项基准测试中取得了出色的成绩。一旦完成训练,Meta将发表一篇详细的研究论文。

值得注意的是,根据英伟达科学家Jim Fan的整理,Llama3 400B基本逼近Claude-3-Opus和GPT-4-turbo,这将意味着开源社区即将迎来GPT-4级大模型。

6. 社区影响
本节将简要介绍Llama模型对开源社区的影响。
6.1 开放源代码模型的力量
自Meta发布Llama模型以来,它对全球AI社区产生了深远的影响。作为一个开源的大语言模型(LLM),Llama不仅提供了一个强大的技术基础,还推动了全球范围内对AI技术的广泛采用和创新。
Llama模型的开源策略被视为LLM时代的“安卓”,这意味着它提供了一个模块化和可自定义的平台,使研究人员和开发者能够根据自己的需要调整和优化模型。这种开放性极大地降低了进入门槛,使得从小型创业公司到大型企业都能够利用这一技术。四月十九日的Llama 3的发布,一日的下载量已经突破了1.14k,两个8B的模型位列trending第一。

6.2 对全球AI研发的影响
在OpenAI转向更封闭的商业模式后,Llama的发布为全球进行AI项目研发的团队和个人提供了一种可靠的选择。这种开源模型确保了用户不必完全依赖单一的商业API,从而增加了企业的运营安全感和自由度,尤其是在数据安全和成本控制方面。
6.3 技术进步和社区创新
技术上,Llama模型已经展示了与GPT相媲美的性能,这证明了开源社区在推动前沿技术方面的能力。此外,社区通过对模型的不断优化和调整,在不同的垂直领域中开发出适用的解决方案,类似于Stable Diffusion和Midjourney等社区驱动的大模型。
6.4 生态系统和多样性
Llama的应用已经扩展到多种平台和设备,包括移动和边缘设备。这种多样化的应用不仅推动了技术的普及,也加速了新应用的创新。例如,云平台如AWS和Google Cloud的积极参与,证明了Llama模型的广泛适用性和强大功能。
6.5 Llama社区的未来展望
随着Llama模型的持续发展和优化,Meta强调了对多模态AI、安全性和责任以及社区支持的持续关注。这些方向不仅符合当前AI发展的趋势,也为Llama社区的未来提供了明确的路线图。
7. 总结
总之,Llama模型的发布不仅证明了开源模型在全球AI领域的重要性,也为AI的未来发展方向提供了新的视角和动力。通过持续的技术进步和社区驱动的创新,Llama有望继续推动全球AI技术的广泛应用和发展。
参考文献
[1] Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
[2] Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[5] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[6] Zhang B, Sennrich R. Root mean square layer normalization[J]. Advances in Neural Information Processing Systems, 2019, 32.
[7] Shazeer N. Glu variants improve transformer[J]. arXiv preprint arXiv:2002.05202, 2020.
[8] Su J, Ahmed M, Lu Y, et al. Roformer: Enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063.
[9] Ainslie J, Lee-Thorp J, de Jong M, et al. Gqa: Training generalized multi-query transformer models from multi-head checkpoints[J]. arXiv preprint arXiv:2305.13245, 2023.
[10] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units[J]. arXiv preprint arXiv:1508.07909, 2015.
[11] Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
[12] https://github.com/facebookresearch/xformers
#一份假简历领5份硅谷AI工资
印度老哥真是不得了
凭借一份虚假简历同时在硅谷多家AI初创公司兼职!
离谱! 一群AI初创公司竟然集体控诉:
我们被一个印度老哥骗了。
这个名叫Soham Parekh的人,在隐瞒真实情况下进行远程兼职,最多一次打了五份工。
有一说一,这也算是最强打工人了吧(摊手)。
避雷贴一开始发出,还以为只是个人Drama经历分享,没想到一石激起千层浪,竟然有这么多老板都出来吐苦水,说自己上当受骗了。
“他在面试时表现得相当出色,差点就录用他了”、“本来周一来上班来着,好险做了背调,让他只工作了一天”、“亲自合作了两天,他人很好。就是每天他都会找个借口请假半天,说要见律师。”……
大家发现原来他不只造假简历,还有隐瞒签证状态、谎称自己在美国等种种事迹。
虽然老板们错愕,但不妨碍网友们当即开始快乐造梗。 这事儿啊现在也是被大家玩起来了,随便一打开社交平台,就像这样:
哈喽,你是Soham Parekh,即将开始一天的报到。
还借着现在大厂不惜金钱揽人才的操作,要不在座大厂考虑下这位候选人呢?
具体咋回事?我们仔细扒了扒。
硅谷创始人集体控诉
起因是一初创公司创始人Suhail Doshi分享了自己的经历。
他指控一个印度男子以虚假借口同时在3到4家初创公司工作。Soham Parekh曾在他们公司短暂工作,但不到一周就被解雇了。
本来还警告了Soham哥别再撒谎/诈骗别人的,结果一年过去了,他还在继续骗大家。
并且告诫大家:小心点,Soham哥经常出没在YC孵化的公司。
他还附上了简历,上面写着Soham哥本科毕业于孟买大学,硕士毕业于佐治亚理工学院计算机学院。
工作经历也是非常丰富,三年时间辗转了四家公司,但是时间都不重合。
鉴于Soham哥的可信度,这份简历「可能90%都是假的,而且大多数链接都是失效的」。
不过顺着个人网站soham.sh找到了疑似本人的GitHub网页。
Star数最高的一个项目是他做的一个免费开源APP,叫做CheatingDaddy。
顾名思义,就是用来面试/汇报作弊用的。
它通过使用屏幕捕获和音频分析在视频通话、面试、演示和会议期间提供实时的AI帮助。
背后是Google Gemini 2.0 Flash Live提供支持。
如果是真的,倒也很符合这位老哥的人设了。
结果Suhail Doshi这段亲身经历不说还好,一说直接激起千层浪。其他初创公司的创始人也开始吐苦水:我也被骗过!
刚刚帮他报名了参加下周的工作试用。看到这条推文。工作试用取消了。
这个人浪费了我们一个月时间。
他们反馈最多的就是面试时人模人样的,显得非常专业。
有个差点就被骗到的Igor Zalutski小哥说,这个老哥看起来非常敏锐,而且不说废话,幸好周末做了背调,得知他不仅同时做很多工作、还谎报签证状态啥的。
本来这周一就上班来着,最后赶紧解雇了他。
所以Igor Zalutski得出的结论就是千万不要跳过背景调查。
这时候就有网友问了,撇开骗局不谈,YC初创公司需要招聘远程员工吗?
Suhail Doshi解释道,老哥还编造了自己的位置,让我们误以为他在美国,甚至还给他寄了一台笔记本电脑,结果给退回来了。据说是寄给他“妹妹”的。
就在刚刚,Suhail表示老哥已经联系到了他,目前有意坦白,不过担心会因此断送他的职业生涯。
我真的很喜欢我的工作,所以我想真诚地征求您的意见,我是否完全破坏了我的职业生涯?我能做些什么来改善我的状况?我也很乐意坦白。
大家认为,还是坦白比较好。
网友纷纷为小哥造梗
结果万万没想到,让硅谷初创公司们纷纷痛苦面具的Soham Parekh,竟然在网络上一炮而红。
笑疯,这届网友实在太有梗:
YC初创公司们Be like:
颤抖吧HR,以为在和Soham Parekh一个人面试?其实……
真正的全球首个完全自主的AI Agent is coming!(不过上下文窗口非常短)
摊牌了,其实Soham parekh只是新的openAI GPT-5模型的代号。(bushi)
并非个例,可能只是冰山一角
玩梗归玩梗,更多网友发现似乎有点不对劲,好像这还不是个例。
有位网友甚至扒出Reddit上有个r/overemployed社区,里面全是有类似OE(One Employer, Multiple Jobs;一份雇主,多份工作)工作经历的人在分享经验。
原来同时拥有好几份全职工作的情况不仅仅出现在硅谷,还有建筑行业、护理行业,甚至公务员。
当然更多的人OE只是在麦当劳和汉堡王之间。(V我50震怒)
在社区里,他们分享自己是如何找到另一份工作而不被发现,如何和试图找到员工OE证据的领导斗智斗勇,如何在会议重叠时脱身,如何在类似领英的招聘网站上不被标记……
他们表示,老板可以同时拥有多家初创公司,为什么员工就不能呢?
而且OE似乎只是对公司有害,对他们个人而言,却是好处多多。
不仅每个月可以收获更丰厚的薪资,还能将学到的新技能迁移到另一份工作上。
也不用再为被公司辞退发愁,还有另一份工作可以托底。
所以,OE真的完全是错误的吗?还是人们在生活重压下的无奈之举,这值得我们思考。
回到Soham Parekh,网友们也在揣测他是如何一个人完成5份工作的,毕竟同时干2份已经很极限,5份实在太超模。
有人提出一个假设:外包?
早在2012年,美国最强程序员Bob就被公司发现,他将工作外包给程序员,除去外包费,啥也不做,每年躺赚20万美元。
而现在类似的数字游民似乎已经成为了许多个人乃至企业的优先选择。
所以,原来我们找不到的工作都去了这里?
谁说找工作难,老哥表示so easy~
参考链接:
[1]https://x.com/jayendra_ram/status/1940494055563264042
[2]https://x.com/0xJba/status/1940534405111730645
[3]https://www.reddit.com/r/overemployed/
[4]https://x.com/Suhail/status/1940287384131969067/quotes
[5]https://x.com/deedydas/status/1940530770839589271
[6]https://x.com/VCBrags/status/1940493682844881125
#你被哪个后来知道很致命的BUG困扰过一周以上吗?
鼓励一个走迷宫 AI 尽量去那些没见过的场景,结果 AI 找到了一个迷宫里的电视,不用动就能不断地见到新东西 《智能体只想看电视》
模型训练很慢,随便写点 bug 很多天以后才会观察到迹象
我入门强化学习做的项目 NIPS2017-LearningToRunACE,是在虚拟环境训练一个机器人跑步,要在规定时间跑得最远,模型输入就是各个机器人关节的速度位置,障碍物的位置等等,然后输出肌肉的舒张收缩控制量
当年强化学习搭好框架以后,基本上就是要设计奖励或者说学习目标
先写个速度最快的学习目标 -> 学了两天一看,模型学会了跳远然后摔倒,因为蹦出去那一下挺快的摔倒惩罚搞高点 -> 模型学会扎马步
换个惩罚项,模型重心不能低 -> 模型学会了走路,但是膝盖都快反关节了,因为弯膝盖让重心变低
加点左右脚关节状态统计量的对称性约束 -> 模型学会了双腿蹦跶往前一直跳
给阶段性奖励,比如跑了10米就给奖励 -> 学会在一个地方来回过线
后来我又搞了一个 LearningToPaint,希望教 AI 用画笔涂鸦,输入是一张图片,神经网络每一步输出几个笔触的控制量(位置颜色形状等等)
因为输入图像,要用卷积网络处理图像,然后接全连接输出,结果我训了一两个月模型才发现,我卷积网络参数从来就没有更新过,也就是说我在用一个随机参数的神经网络做视觉特征提取器,也训练的还行
我还把画笔接口写错了,一个参数既控制红色也控制画笔半径,导致画的红色总是怪怪的,也凑合用
学习目标设计也很容易坑,比方说设计最大化每一步接近目标的程度 -> 学会画一笔后擦掉,循环刷分
鼓励模型用小笔画,想着让模型关注细节 -> 学会磨洋工刷分
惩罚项加多了就会出现类似于 狼抓不到羊一头撞死 的故事
还有很多实现的坑,在 numpy / torch / GPU 几个地方转来转去能把人搞疯,学会熟练使用 cProfile单个小数 np.round 比 round 慢十几倍完全没想到过
这两年又用强化学习训语言大模型了
让另一个奖励模型给模型打分 -> 尽说谄媚的话(这就是人类反馈!),发明奇怪的咒语骗奖励模型
鼓励模型思考长一些 -> 生成重复字符刷分
加上重复检测 -> 生成越来越高级的车轱辘话,听君一席话,如听一席话
我以为我在训练模型,其实我是在接受模型毒打
神经网络强就强在它非常鲁棒,硬扛 bug 也能迭代
合作做深度学习,你可以在环境、预处理的代码里塞几个 bug,在数据里投毒
让你的小伙伴来调模型,在 AI 像一个智障的时候他就有无限的灵感
最后关头把 bug 删掉获得突飞猛进的效果 《优秀的 AI 来源于艰苦的训练环境》
#对VLA的RL最新进展的梳理~
2025年5月,VLA的RL领域掀起了一股热潮,不仅传统的PPO、GRPO、DPO等算法纷纷被移用到VLA上,而且各种针对VLA特殊性的创新tricks层出不穷。本文将梳理VLA领域RL算法的来龙去脉。
早期探索:iRe-VLA
(Improving Vision-Language-Action Model with Online Reinforcement Learning)
★
https://arxiv.org/pdf/2501.16664arxiv.org/pdf/2501.16664
这篇文章的核心算法是PPO,并且针对在线强化学习不稳定的问题提出了双阶段的训练范式:
- 第0步:用专家数据集进行监督学习;
- 第1步:冻结VLM backbone,进行online RL;
- 第2步:将第0步的数据集与第1步中采样到的成功轨迹混合,进行监督学习;
- 第1步与第2步反复迭代。
具体实现上,此文没有采用已有的VLA模型结构,而是将BLIP-2 3B用于VLM backbone,把它最后的全连接层替换为一个action head,包含一个token learner和一个MLP。训练中采用LoRA以节省显存。实验环境采用Meatworld和Franka Kitchen仿真环境以及real-world panda manipulation。这些任务都被分成三份:在监督学习阶段就进行训练的、在在线RL阶段训练的和不进行训练的未见过的新任务,使得我们可以分别评估算法效果。
最终的实验结果表现不错,消融实验说明阶段2不冻结VLM效果更好。
偏好对齐:GRAPE
(GRAPE: Generalizing Robot Policy via Preference Alignment)
★
https://arxiv.org/abs/2411.19309arxiv.org/abs/2411.19309
GRAPE这篇文章的核心思路是将DPO代表的偏好对齐引入VLA训练,精心针对VLA的特点设计偏好。此文在轨迹level进行偏好对齐,每条轨迹的奖励设计为三部分的和:
- 是否成功奖励(成功是1,失败是0);
- 自我奖励(模型自己生成轨迹的概率大小对数);
- 外部奖励(使用自设的cost函数评估,下面详解流程)
计算轨迹cost首先需要把轨迹输入到一个VLM任务分解器中,把一条轨迹分解为若干阶段。然后再用一个VLM提取每一个阶段中的关键点表示,然后将阶段和关键点表示外加想让cost函数达到的对齐目标同时输入GPT-4o生成cost函数。之后用这些cost函数分别评估轨迹的每一阶段,使用指数衰减聚合给出总的cost,定义为外部奖励
实验上主要在Simpler-Env和LIBERO环境中,使用open-VLA和它的原始检查点、SFT、每一step level的DPO以及Octo的SFT对比,超过了它们的表现。
LOOP:RIPT-VLA
(Interactive Post-Training for Vision-Language-Action Models)
★
https://arxiv.org/pdf/2505.17016arxiv.org/pdf/2505.17016
简单来说LOOP就是RLOO+PPO:在 稀疏奖励 + 长时间序列 + 多任务不平衡 场景中critic模型不好训,就采用留一法(RLOO)估计优势;然后在用PPO的clip算出loss进行优化。因此,在线采样中同一个context需要rollout多次。RIPT-VLA主要是采用LOOP算法的online RL,给出了开源代码。
此外还加了哪些trick呢?
- 动态拒绝机制:如果某个上下文 c 下的所有 K 个 rollouts 的奖励完全一致(都成功或都失败),则跳过这个任务,提升梯度有效性;
- 多任务场景群体采样:在 batch 中,分组采样多个 context,每个 context 对应 K 个 rollouts,相当于:从 multi-task context dataset 中选 B/K 个任务,每个任务采样 K 条轨迹,提高样本多样性,缓解 task imbalance;
- 部分off policy优化:每个 rollout 用多次(N>1):可视作轻度 off-policy,提高样本利用率。
全面对比:rlvla
(What Can RL Bring to VLA Generalization? An Empirical Study)
★
https://arxiv.org/pdf/2505.19789arxiv.org/pdf/2505.19789
这篇文章在VLA上实现了各种RL或类RL算法及一些变种:PPO、GRPO、DPO、PPO-ORZ(不用GAE)、GRPOs(一组采样轨迹从同一初始状态开始)。最终发现PPO表现最好,以其为代表与SFT进行比较,发现优于SFT。具体来说,实验精心设计了in-domain的场景和三种out of domain的场景:vision、semantics、execution,发现RL优于SFT。给出了开源代码。
系统与算法的双重创新:RL4VLA
(VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning)
★
https://arxiv.org/pdf/2505.18719arxiv.org/pdf/2505.18719
这篇文章在算法上主要把自回归的VLA动作生成过程建模为一个多模态多轮对话过程,从而进行PPO训练。为了避免传统的机器人RL训练中稀疏的二元奖励带来的问题,作者决定给训练轨迹中划分一些稠密的伪奖励,来指示当前状态/动作序列片段朝着任务完成的有效进展程度,从而用它们训练一个专门的奖励模型(Robotic Process Reward Model)。具体划分方法是:
- 搜集多样化成功轨迹,按照夹爪开合度的显著变化夹爪分解成一系列子任务,因为夹爪的开闭往往标志着关键步骤的开始或结束(如抓取物体、释放物体);
- 在每个子任务片段内部,进一步识别末端执行器速度接近零的时刻(关键帧),这些时刻通常对应着稳定状态(如物体被抓稳、物体接触到目标表面)或精细动作的完成点(如精确对准、轻微接触),之后给导致这些关键帧动作序列分配一个正的伪奖励。逻辑是:成功到达这些关键帧表明该子任务取得了实质进展;
现在有了细粒度标注的稠密奖励轨迹数据集,训练的Robotic Process Reward Model的方法呼之欲出:最大化在有希望的动作序列上预测其组成Token的对数似然(Log-Likelihood),并且被伪奖励信号加权。最终的奖励信号选用Robotic Process Reward Model和真实动作完成奖励直接相加的和。
此外,本文在训练过程中也加了以下tricks:
自适应课程选择策略 (Curriculum Selection Strategy):
- 目标: 提升样本效率和泛化能力。
- 方法:根据智能体当前在每个任务上的成功率 (),动态调整任务采样概率。公式 使得:
- 成功率接近 50% 的任务获得最高采样优先级,代表智能体能力的 "前沿",学习效率最高。
- 参数 控制探索的程度。
价值网络预热 (Critic Warmup):
- 目标: 解决训练初期价值网络(Critic)估计不准确导致策略更新被误导的问题,提高训练稳定性。
- 方法: 在正式开始策略-价值联合优化(如PPO)之前:
- 使用模仿预训练好的策略收集初始轨迹数据。
- 用这些数据单独训练价值网络(Critic)若干轮次。
- 效果: 让 Critic 在联合训练开始时就能提供相对可靠的价值估计,避免早期训练被错误信号误导。
GPU负载均衡的矢量化环境 (GPU-balanced Vectorized Environments):
- 目标: 高效支持大规模并行环境仿真,解决 GPU 内存瓶颈。
- 方法:
- 将多个环境实例(矢量化环境)分布到不同的训练 GPU 上,每个 GPU 负责管理和交互其子集的环境。
- 使用 all_reduce操作,将所有 GPU 工作进程上的环境状态高效收集汇总,提供给中央推理引擎(用于 VLA 模型推理,生成动作)。
- 效果: 平衡了多个环境渲染和交互带来的 GPU 内存和计算负载,支持更大规模的并行数据收集。
高效基础设施优化 (Infrastructure Optimizations):
- 目标: 最大化内存利用和计算效率,支持大规模 VLA-RL 训练。
- 关键措施:
- 总
G 块 GPU。 - 专用
1 块 GPU 运行推理引擎,使用 vLLM 高效加速 VLA 模型的大批量推理。 - 剩余
G-1块 GPU 运行学习过程(策略、价值网络更新),使用 Ray 进行分布式协调。
- 模型精度: 使用 bfloat16 存储模型参数和计算,显著减少内存占用。
- GPU 专业化分工:
- 推理引擎优化: 在
vLLM 插件中实现 OpenVLA,替换原生 Hugging Face Transformers 生成函数,解决大批量推理时结果错误的问题。 - 分布式训练框架: 使用 PyTorch FSDP (Fully Sharded Data Parallel) 管理分布式训练,有效支持超大模型参数的切分与同步。
启发与思考
- 双阶段训练范式成主流:监督预训练 + 在线RL微调是稳定训练VLA的基础框架(如iRe-VLA、RL4VLA);
- RL算法选择:目前PPO是训练主流,是否可以研究适合于VLA-RL新的RL算法(比如LOOP);
- 稀疏奖励问题需多路径破解:一些解决方案是把轨迹划分成一些子任务分别打分形成稠密奖励,也可以精心设计不同目标对应的cost函数,然而更精准有效的奖励设计仍亟待探索;
- 提升样本有效性:由于VLA采样成本更高,提高学习的有效性更加重要,可以采取类似课程学习的思路增加有效性;
- RL工程问题仍需解决:如何在VLA场景下解决采样效率低、在线采样显存开销大的工程问题还需下功夫破解;如何在非自回归的VLA结构上跑通RL也是一个具有挑战性和实际意义的问题;
#Skywork-Reward-V2
人机协同筛出2600万条数据,七项基准全部SOTA,昆仑万维开源奖励模型再迎新突破
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。
基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
因此,奖励模型对大模型能力来说举足轻重:它既需要能够准确进行评判,又需要足够通用化,覆盖多个知识领域,还需要具备灵活的判断能力,可以处理多种输入,并具备足够的可扩展性。
7 月 4 日,国内 AI 科技公司昆仑万维发布了新一代奖励模型 Skywork-Reward-V2 系列,把这项技术的上限再次提升了一截。
Skywork-Reward-V2 系列共包含 8 个基于不同基座模型和不同大小的奖励模型,参数规模从 6 亿到 80 亿不等,它在七大主流奖励模型评测榜单上全部获得了第一。

Skywork-Reward-V2 系列模型在主流基准上的成绩。
与此同时,该系列模型展现出了广泛的适用性,它在多个能力维度上表现出色,包括对人类偏好的通用对齐、客观正确性、安全性、风格偏差的抵抗能力,以及 best-of-N 扩展能力等。Skywork-Reward-V2 系列模型目前已经开源。
- 技术报告:https://arxiv.org/abs/2507.01352
- HuggingFace 地址:https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
- GitHub 地址:https://github.com/SkyworkAI/Skywork-Reward-V2
其实在去年 9 月,昆仑万维首次开源 Skywork-Reward 系列模型及数据集就获得了 AI 社区的欢迎。过去九个月中,该工作已被开源社区广泛应用于研究与实践,在 Hugging Face 平台上的累计下载量超过 75 万次,并助力多个前沿模型在 RewardBench 等权威评测中取得成绩。

这一次,昆仑万维再次开源的奖励模型,或许会带来更大的关注度。
打造千万级人类偏好数据
想让大模型的输出总是符合人类偏好,并不是一个简单的任务。
由于现实世界任务的复杂性和多样性,奖励模型往往只能作为理想偏好的不完美代理。这种不完美性可能导致模型在针对奖励模型优化时出现过度优化问题 —— 模型可能会过分迎合奖励模型的偏差而偏离真实的人类偏好。
从实际效果来看,当前最先进的开源奖励模型在大多数主流评测基准上表现仍然说不上好。它们经常不能有效捕捉人类偏好中细致而复杂的特征,尤其是在面对多维度、多层次反馈时,其能力尤为有限。此外,许多奖励模型容易在特定的基准任务上表现突出,却难以迁移到新任务或新场景,表现出明显的「过拟合」现象。
尽管已有研究尝试通过优化目标函数、改进模型架构,以及近期兴起的生成式奖励模型(Generative Reward Model)等方法来提升性能,但整体效果仍然十分有限。

左图:31 个顶尖开源奖励模型在 RewardBench 上的能力对比;右图:分数的相关性 —— 可见很多模型在 RewardBench 上性能提升后,在其他 Benchmark 上成绩却「原地踏步」,这可能意味着过拟合现象。
同时,以 OpenAI 的 o 系列模型和 DeepSeek-R1 为代表的模型推动了「可验证奖励强化学习」(Reinforcement Learning with Verifiable Reward, RLVR)方法的发展,通过字符匹配、系统化单元测试或更复杂的多规则匹配机制,来判断模型生成结果是否满足预设要求。虽然此类方法在特定场景中具备较高的可控性与稳定性,但本质上难以捕捉复杂、细致的人类偏好,因此在优化开放式、主观性较强的任务时存在明显局限。
对此,昆仑万维在数据构建和基础模型两大方向上尝试解决问题。
首先,他们构建了迄今为止规模最大的偏好混合数据集 Skywork-SynPref-40M,总计包含 4000 万对偏好样本。其核心创新在于一条「人机协同、两阶段迭代」的数据甄选流水线。

两阶段偏好数据整理流程。
如图所示,这个流程分为两大阶段:
第一阶段,人类引导的小规模高质量偏好构建。此阶段研究人员针对 RLHF 可能存在的「高质量数据缺乏→模型弱→生成数据质量低」恶性循环,独创「金标准锚定质量 + 银标准扩展规模」的双轨机制,一方面利用有限人工精准突破初始瓶颈,另一方面利用模型自身能力实现规模化突破。
具体来说,人工和大模型会分别标注出「黄金」和「白银」偏好数据,奖励模型在白银数据上进行训练,并与黄金数据对比评估其不足之处。接着,系统选择当前奖励模型表现不佳的相似偏好样本进行重新标注,以训练 RM 的下一次迭代,这一过程重复多次。
第二阶段,全自动大规模偏好数据扩展。此阶段不再由人工参与审核,而是让训练完成的奖励模型独挑大梁,通过执行一致性过滤,对数据进行二次筛选。
此时,系统将第一阶段的奖励模型与一个专门基于验证的人类数据训练的「黄金」奖励模型相结合,通过一致性机制来指导数据的选择。由于这一阶段无需人工监督,因此能够扩展到数百万个偏好数据对。
从效果来看,该流程结合了人工验证的质量保证与基于人类偏好的大型语言模型(LLM)的注释,实现了高度可扩展性。
最终,原始的 4000 万样本「瘦身」为 2600 万条精选数据,不仅人工标注负担大大减轻,偏好数据在规模与质量之间也实现了很好的平衡。
突破体量限制:参数差数十倍依然能打
经过人机结合数据训练的 Skywork-Reward-V2 系列模型,实现了超出预期的能力。
相比去年 9 月发布的 Skywork-Reward,工程人员在 Skywork-Reward-V2 系列上基于 Qwen3 和 LLaMA 3 等模型训练了 8 个奖励模型,参数规模覆盖更广。
我们从下表可以看到,在 RewardBench v1/v2、PPE Preference & Correctness、RMB、RM-Bench、JudgeBench 等主流奖励模型评估基准上,Skywork-Reward-V2 均创下最佳纪录。

取得 SOTA 成绩的背后,我们可以提炼出以下几点关键发现:
首先,数据质量与丰富度的提升极大地抵消了参数规模的限制,使得奖励模型在特定任务上可以精炼为小型专家模型。
比如在奖励模型评估基准 RewardBench v2 上,Skywork-Reward-V2 在精准遵循指令方面展现出了卓越能力。即使是最小的 Skywork-Reward-V2-Qwen3-0.6B,其大大拉近了与上一代最强模型 Skywork-Reward-Gemma-2-27B-v0.2 的整体差距,参数规模整整相差了 45 倍。
更进一步,Skywork-Reward-V2-Qwen3-1.7B 的平均性能与当前开源奖励模型的 SOTA ——INF-ORM-Llama3.1-70B 相差不大,某些指标实现超越(如 Precise IF、Math)。最大规模的 Skywork-Reward-V2-Llama-3.1-8B 和 Skywork-Reward-V2-Llama-3.1-8B-40M 通过学习纯偏好表示,胜过了强大的闭源模型(Claude-3.7-Sonnet)以及最新的生成式奖励模型,在所有主流基准测试中实现全面超越,成为当前奖励模型新王。

RewardBench v2 基准测试结果。
跑分拉升意味着数据工程策略的作用越来越大,有针对性、高质量的训练数据能支撑起「小打大」;另外,数据驱动 + 结构优化足以与单纯堆参数正面竞争,精工细作的模型训练范式同样值得考虑。
其次,随着对人类价值的结构性建模能力增强,奖励模型开始从「弱监督评分器」走向「强泛化价值建模器」。
在客观正确性评估基准(JudgeBench)上,Skywork-Reward-V2 整体性能虽弱于 OpenAI o 系列等少数专注于推理与编程的闭源模型,但在知识密集型任务上优于所有其他模型,其中 Skywork-Reward-V2-Llama-3.2-3B 的数学表现达到了 o3-mini (high) 同等水平,Skywork-Reward-V2-Llama-3.1-8B 更是完成超越。

JudgeBench(知识、推理、数学与编程)基准上与顶级 LLM-as-a-Judge 模型(如 GPT-4o)和推理模型(o1、o3 系列)的性能对比。
在另一客观正确性评估基准 PPE Correctness 上, Skywork-Reward-V2 全系 8 个模型在有用性(helpfulness)和无害性(harmlessness)指标上均展现出了强大的 BoN(Best-of-N)能力,超越此前 SOTA 模型 GPT-4o,最高领先达 20 分。

另外,从下面 PPE Correctness 五项高难度任务的 BoN 曲线可以看到,Skywork-Reward-V2 表现出持续正扩展性,均达到 SOTA。

同样在偏见抵抗能力测试(RM-Bench)、复杂指令理解及真实性判断(RewardBench v2)等其他高级能力评估中,Skywork-Reward-V2 取得领先,展现出强大的泛化能力与实用性。

在难度较高、专注评估模型抵抗风格偏差的 RM-Bench 上,Skywork-Reward-V2 取得 SOTA。
最后,在后续多轮迭代训练中,精筛和过滤后的偏好数据能够持续有效地提升奖励模型的整体性能,再次印证 Skywork-SynPref 数据集的规模领先与质量优势,也凸显出「少而精」范式的魔力。
为了验证这一点,工程人员尝试在早期版本的 1600 万条数据子集上进行实验,结果显示(下图),仅使用其中 1.8%(约 29 万条) 的高质量数据训练一个 8B 规模模型,其性能就已超过当前的 70B 级 SOTA 奖励模型。

图左展示了整个数据筛选流程(包含原始数据、过滤后数据、过滤后数据 + 校正偏好对三个阶段)中奖励模型得分的变化趋势;图右展示了 Skywork-Reward-V2-Llama-3.1-8B 奖励模型的初始版本(即 Llama-3.1-8B-BTRM)在最终训练轮次的平均得分。
可以预见,随着奖励模型的能力边界不断扩展,未来其将在多维偏好理解、复杂决策评估以及人类价值对齐中承担更核心的角色。
结语
Skywork-Reward-V2 的一系列实证结果输出了这样一种观点:随着数据集构建本身成为一种建模行为,不仅可以提升当前奖励模型的表现,未来也有可能在 RLHF 中引发更多对「数据驱动对齐」技术的演进。
对奖励模型的训练来说,常规的偏好数据往往非常依赖人工标注,不仅成本很高、效率低,有时还会产生噪声。结合大语言模型的自动化标注方法,让人工验证的标签「指导」AI 进行标注,这样可以兼具人类的准确与 AI 的速度,进而实现大规模的偏好数据生成,为大模型能力的提升奠定了基础。
这次发布 Skywork-Reward-V2 时,昆仑万维表示,未来基于人类 + AI 的数据整理方式,还可以激发出大模型的更多潜力。
除了再次开源奖励模型,2025 年初至今,昆仑万维一定程度上也是业内开源 SOTA 大模型最多的 AI 企业之一,其开源包括:
- 软件工程(Software Engineering, SWE)自主代码智能体基座模型「Skywork-SWE」:在开源 32B 模型规模下实现了业界最强的仓库级代码修复能力;
- 空间智能模型「Matrix-Game」:工业界首个开源的 10B + 空间智能大模型;
- 多模态思维链推理模型 「Skywork-R1V」:成功实现强文本推理能力向视觉模态的迁移;
- 视频生成系列模型:SkyReels-V1,以及今年 4 月发布的迭代版 —— 全球首个使用扩散强迫框架的无限时长电影生成模型 SkyReels-V2;
- 数学代码推理模型「Skywork-OR1」:在同等参数规模下实现了业界领先的推理性能,进一步突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈。

这一系列的开源,势必将加速大模型领域技术迭代的速度。
#Shortcut
10分钟搞定Excel世锦赛难题!首个超越人类Excel Agent,网友:想给它磕一个
这个AI让打工人「磕头」致谢。
前段时间,我们报道了 5 款大模型参加了今年山东高考的事儿,为了弄清楚各大模型在 9 个科目中的具体表现,我们对着测评明细表挨个儿分析,搞得狼狈又崩溃。要是哪个 AI 能一键分析表格,我当场就能给它磕一个。

现在,终于有 AI 来整顿 Excel 表格了!
这款 AI 工具名为 Shortcut,号称是「第一个超越人类的 Excel Agent」。它能够一次性完成大多数 Excel 知识工作任务,甚至在大约 10 分钟内就解决了 Excel 世界锦标赛的复杂案例,准确率超过 80%,这比人类快 10 倍。
(冷知识:Excel 世界锦标赛(MEWC)是由金融建模世界杯(FMWC)团队组织、微软官方支持的全球性电子竞技赛事,参赛者需通过 Excel 解决复杂场景化题目,2024 年决赛以《魔兽世界》为模拟场景,冠军奖金 5000 美元。)
,时长01:59
Shortcut 具有与 Excel 近乎完美的功能兼容性,可以直接编辑、导入和导出文件,它不仅限于基础 Excel 操作,还能处理复杂的金融建模任务,例如:
构建多标签的预估上限表( Pro Forma Cap Table)。
分析 5000 行 CSV 数据,生成图表和仪表板,提供深入见解。
递归解决错误,确保财务模型的准确性。
此外,它还有隐藏功能,比如画尤达大师。
据 fundamental 联合创始人 nico 演示,他只需输入提示词:帮我创作一幅精美的 50x50 像素的尤达图像,放在 B 列,通过阴影处理和色彩运用来展现它的标志性特征。Shortcut 就开始一步步执行任务,先设置像素网格,并将单元格调整为正方形,接着用各种绿色阴影创建尤达的耳朵和基本脸型。
,时长00:07
当然,Shortcut 也有一些局限性,比如在格式化方面比较懒、在长时间多轮对话中表现不佳、处理大型 PDF 时可能遇到上下文限制。

Shortcut 目前处于早期预览阶段,大家可以在 X 上评论以获取邀请码。
- 邀请码获取地址:https://x.com/nicochristie/status/1940440489972649989
- Shortcut 地址:http://tryshortcut.ai
我们试了一下,只要使用谷歌邮箱登录,即使没有邀请码也能获得 3 次免费体验机会。
接下来,我们就奉上一手实测。
一手体验
Shortcut 界面分为两部分,左侧类似于 Excel 表格,右侧是聊天区,输入提示词就能指使它干活。
点击左上侧的「Open Xlsx File」就能上传原始的 excel 文件,当然也可以一键新建、保存文档。
比如,我们上传了 5 款大模型挑战语文高考卷的成绩单,先让它算出各个模型对应的总分,再根据以上表格分析一下每个模型在各个题型中的得分情况。
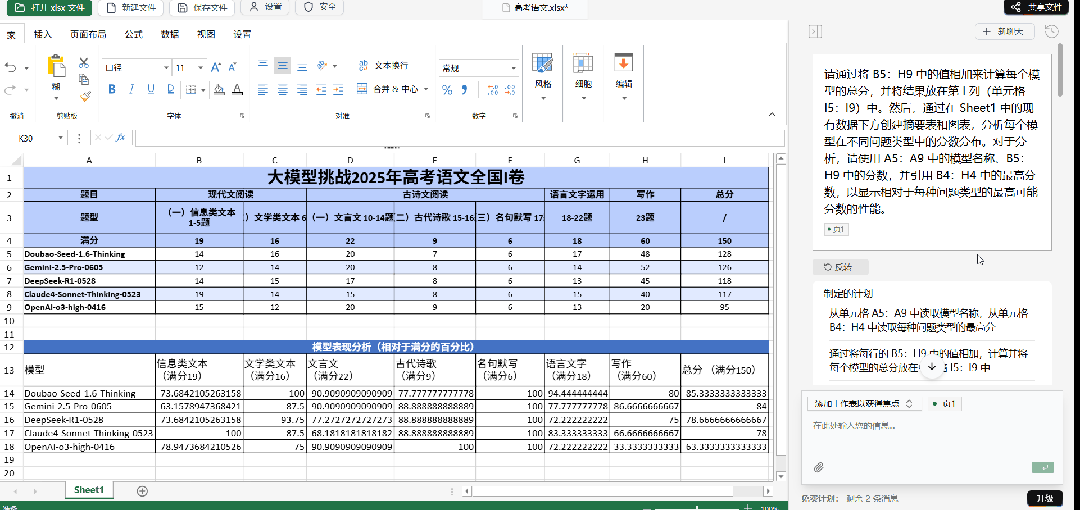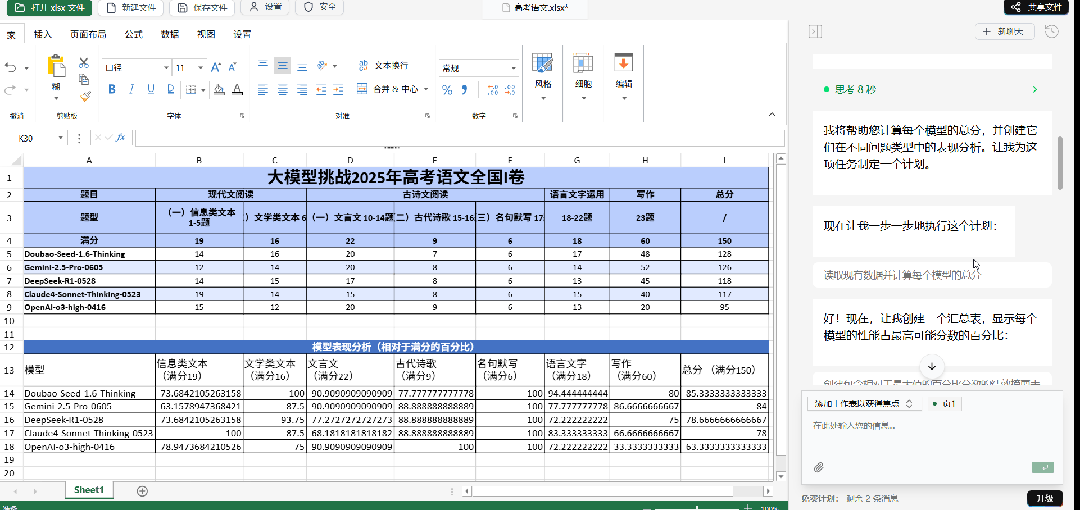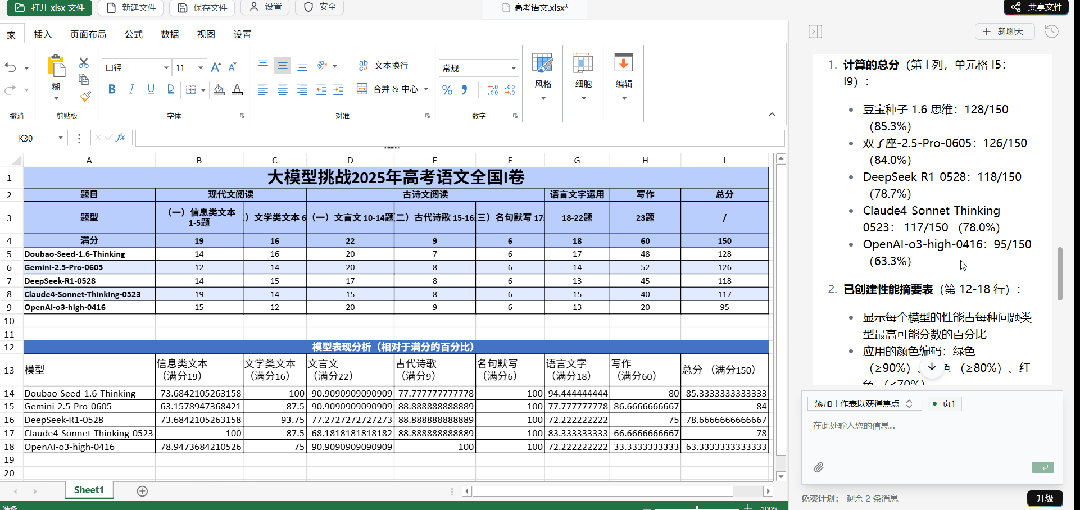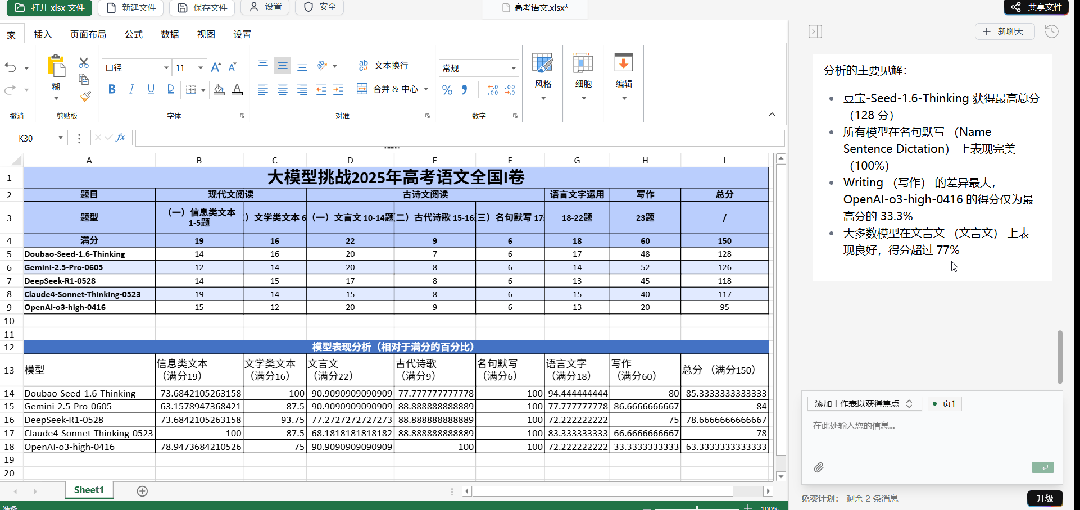
领到任务后,它就开始咔咔思考,并像其他 Agent 一样让我们提供更多信息,比如计算的总分输入到哪一栏、分析得分情况是使用哪种形式等。确认完上述信息后,它就开始制定计划。
以下红框圈出来的部分即是 Shortcut 生成的。我专门核对了一遍,它计算的各个模型总分和相对于满分的百分比全都准确无误。

并且能根据表格准确分析出五大模型在总分、各个题型中的表现情况。

不过,我们对照右侧的任务清单,发现它也漏掉了几项,例如条形图、比较总分的柱状图以及雷达图等,翻遍了各个角落也没找到相应的图表。

难度升级。我们又上传了那个曾把我们搞得焦头烂额的各科评分明细表,让它分析这 5 款大模型在语文学科中第 23 题中的最终得分分别是多少,并形成一个表格。
好家伙,Shortcut 直接罢工:由于早期访问期间需求量大,Shortcut 正在承受压力,我们正在扩大容量,请稍后再试。我们换了几台电脑重新试了几次,还是没有起色。

我们还让它生成一个像素版马里奥图像,输入的提示词:Create a beautiful 50x50 pixel art of Mario, placed in column B, showcasing his iconic features through shadowing and color usage.
Shortcut 还是先要求细化需求,比如要创建哪个版本的马里奥、马里奥的姿势和表情等。

确认完以上细节,它立马就能响应:
来看看经典 8-bit Mario 最终效果,虽然有点抽象,但起码完成了任务。

总体来说,对于一些简单的表格生成、数据处理(比如计算总和、百分比等),Shortcut 可以轻松搞定,但如果投喂给它的表格数据过于复杂,它就很容易「宕机」。
虽然传统 Excel 是一款功能强大的工具,但其复杂性和易出错的特性让打工人痛恨已久,这也就给 Shortcut 等专门处理 Excel 任务的 Agent 巨大的发展空间,不过就目前来看,它们似乎还有较长的路要走。
参考链接:
https://x.com/nicochristie/status/1940440499393106288
#TaskCraft
Agent RL和智能体自我进化的关键一步: TaskCraft实现复杂智能体任务的自动生成
近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。当前如 GAIA 与 BrowserComp 等主流数据集在构建过程中高度依赖人工标注,因而在规模与任务复杂性方面均存在明显限制——BrowserComp 仅涵盖约 1300 个搜索任务,GAIA 则仅提供约 500 条多工具协同任务样本。与基础大模型训练中动辄万级以上的指令数据相比,差距十分显著。
尽管在基础模型阶段,像 self-instruct 这样的自监督方法已经借助大语言模型(LLM)成功构建了大规模的指令型数据,有效提升了模型的通用性和泛化能力,但在智能体(Agent)场景下,这类静态指令数据却难以满足实际需求。原因在于,复杂的智能体任务通常需要模型与环境进行持续的动态交互,同时涉及多工具的协同操作和多步骤推理。而传统的指令数据缺乏这种交互性和操作性,导致其在智能体训练中迁移性差、适用性有限。
为应对上述挑战,OPPO 研究院的研究者提出了 TaskCraft,一个面向智能体任务的自动化生成框架,旨在高效构建具备可扩展难度、多工具协同与可验证执行路径的智能体任务实例。TaskCraft 通过统一的流程化建构机制,摆脱了对人工标注的依赖,能够系统性地产生覆盖多种工具(如 URL、PDF、HTML、Image 等)的复杂任务场景,并支持任务目标的自动验证,确保数据质量与执行闭环。 基于该框架,研究团队构建并开源了一个包含约 41,000 条智能体任务的合成数据集,显著扩展了现有 Agent 数据资源的规模与多样性,为后续通用智能体的训练与评估提供了有力支撑。
论文标题:TaskCraft: Automated Generation of Agentic Tasks
论文地址:https://arxiv.org/abs/2506.10055
Github:https://github.com/OPPO-PersonalAI/TaskCraft
数据集:https://huggingface.co/datasets/PersonalAILab/TaskCraft
数据生成
生成过程主要分为两大部分:第一部分 生成简单且可验证的原子任务;第二部分 通过深度拓展和宽度拓展,不断构建新的原子任务,使复杂性逐步提升。
原子任务的生成

原子结构生成示意图
可以简单理解为,从原始数据中提取核心问题,然后确保问题必须通过特定工具来解决。整个流程包含以下四个关键步骤:
1.收集信息:系统从多种来源(网页、PDF、图片等)提取信息。例如,企业财报、一张统计图或一篇新闻文章。
2.识别关键内容: 利用LLM从这些文档中提取候选结论,比如:2025 年苹果公司总收入为 383.3 亿美元
3.生成问题:LLM需要将这些候选结论转换为工具回答的问题。例如:“在财务报告《Apple 2025 年度报告》中,2025 年的总收入是多少?”(答案:383.3 亿美元)
4.验证任务:每个原子任务被保留必须满足以下两个条件:
- 必须依赖工具才能解答( LLM 无法直接推导答案)。
- 必须经过 Agent 验证,确保能够顺利执行任务。
任务拓展
任务拓展旨在将一个简单任务逐步演化为更具层次和挑战性的复杂任务,使 Agent 必须通过多个步骤才能完成任务。拓展方式主要包括深度拓展与宽度拓展。

深度拓展示意图
其中,深度拓展的目标是为了构建可被拆解为一系列相互依赖的任务。每一步都依赖前一步的结果,从而构建出一条多步推理链。其主要包括以下四步:
1.确认主任务与拓展标识符:拓展标识符一般是具有强特殊性的文本,往往作为获取工具上下文的输入关键字。例如对于任务:“电影《星际穿越》的导演是谁?”(答案:克里斯托弗·诺兰),其中的拓展标识符是:《星际穿越》。
2.执行Agent搜索,构造新的辅助原子任务:Search Agent以拓展标识符为线索执行搜索,并从搜索结果中构造一个新的原子任务,其答案即为该拓展标识符。例如:“哪部美国著名科幻电影是在 2014 年 11 月 7 日上映的?”(答案:《星际穿越》)
3.合并辅助原子任务,更新主任务:将辅助原子任务与原主任务进行融合,构建一个逻辑连贯的复合任务。例如:“2014 年 11 月 7 日上映的美国著名科幻电影,它的导演是谁?“(答案:克里斯托弗·诺兰)
4.验证任务合理性:为了规避对合并问题的整体验证,研究者采用了多种规则对合并后的主任务进行语义验证,包括:超集验证、关系验证、信息泄露验证、替换合理性验证等。
而宽度拓展则是通过选择两个(或多个)结构兼容的原子任务,这些任务应来自同一信息源(如同一篇网页或 PDF),且答案之间不存在因果依赖。使用 LLM 将多个任务的语义合并成一个自然、流畅且具备完整性的新任务。

宽度拓展示意图
通过 Prompt Learning 提升任务生成效率
在 TaskCraft 的任务构建流程中,Prompt 的设计起到了至关重要的作用。研究团队采用了自举式 few-shot 提示优化机制,基于生成的任务数据对提示进行了迭代优化,从而实现了提示模板的自我进化。如表1,实验结果显示,原子任务的生成通过率从初始的 54.9% 提高至 68.1%,同时平均生成时间减少了近 20%。在深度拓展任务中,6 轮任务扩展的成功率由 41% 提升至 51.2%,进一步验证了生成数据在提升任务构建质量与效率方面的显著效果。

表1 Prompt Learning实验结果
对智能体基础模型进行SFT训练
其次,研究团队进一步评估了 TaskCraft 所生成任务数据在提升大模型能力方面的实际效果。以 Qwen2.5-3B 系列为基础,研究者基于三个典型的多跳问答数据集(HotpotQA、Musique 和 Bamboogle)的训练集,生成了约32k条多跳任务以及轨迹,并利用这些生成数据对模型进行监督微调(SFT)。如表2,实验结果表明,经过微调后,Base 模型的平均性能提升了 14%,Instruct 模型提升了 6%,说明 TaskCraft 生成的数据在增强大模型的推理能力与工具调用表现方面具有显著成效。此外,当这些微调模型与强化学习方法 Search-R1 相结合时,模型性能进一步提升,进一步证明 TaskCraft 所生成的任务数据不仅能用于监督学习,也可作为强化学习的优质训练起点。

表2 监督微调效果
此外,你可能会好奇:引入搜索 Agent 是否真的有必要?为此,研究团队设计了一项对比实验,比较了两种任务构建方式的效果:一是直接使用 GPT-4.1 基于某个结论生成任务,另一种则是借助基于 GPT-4.1 的 Search Agent 自动生成任务。结果如表 3 所示,TaskCraft 构建范式在多项指标上表现更优。

表3任务构建范式的有效性分析
相比之下,TaskCraft 生成的任务具有显著更高的通过率,验证时间更短,且工具使用次数更符合“原子任务”的定义(理论最优为:一次输入索引 + 一次目标工具调用)。此外,任务的工具调用次数也更稳定,方差更小,反映出 TaskCraft 在保持原子任务难度的一致性方面具备更强的优势。

原子数据域分布
基于 TaskCraft,研究者构建了一个包含约 41,000 个 agentic 任务的大规模数据集,为 AI 智能体的系统化调优与评估提供了坚实的基础。该数据集覆盖多个工具使用场景,包括网页搜索、PDF 阅读、图像理解等,任务结构层次丰富,难度可控,支持原子级任务和多跳复杂任务。由于所有任务都附带了真实的执行轨迹,不仅可以进行监督式微调(SFT),还能为强化学习(RL)提供高质量的训练数据起点。这使得该数据集可广泛应用于智能体基础模型的能力增强、Agent 推理策略的评估,以及多工具调用环境下的泛化能力测试。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 18
18 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)