
计算机毕业设计之基于Hadoop租房数据分析系统设计与实现
本文设计并实现了一个基于Hadoop的租房数据分析系统,该系统整合了HDFS、Hive、HBase等大数据组件,构建了完整的数据采集、清洗、分析和可视化流程。系统采用K-Means聚类算法挖掘房屋特征与价格关系,提供房源预测功能,并通过可视化大屏直观展示市场趋势。系统实现了租房数据的增删改查、批量导入导出等管理功能,利用HBase确保海量数据的高效存储与访问。实验表明,该系统能有效处理大规模租房数
摘要
基于Hadoop的租房数据分析系统设计与实现,旨在利用大数据技术和机器学习算法,为租房市场提供全面、深入的数据分析解决方案。系统采用Hadoop生态中的HDFS、MapReduce、Hive、HBase等组件,实现了海量租房数据的高效存储、处理和分析。通过多种数据采集渠道,系统全面收集房源信息、租客偏好、市场动态等数据,并经过数据清洗模块处理,确保数据质量。引入的K-Means聚类分析算法能够深入挖掘数据模式,例如根据房屋面积和价格预测社区名称,为用户提供有价值的洞察。系统还提供了可视化大屏展示,将复杂的数据以直观的图表形式呈现,帮助用户快速理解市场状况,做出明智的决策。租房信息管理功能则通过增删改查、导入导出等操作,实现了对租房数据的灵活管理,满足了用户对数据的高效利用需求。
该系统在技术实现上充分展现了Hadoop生态在处理大规模数据方面的优势。HDFS的高可靠、可扩展存储,MapReduce和Spark的分布式计算,以及Hive和HBase的数据仓库和实时随机读写能力,共同确保了系统应对海量租房数据挑战的能力。K-Means算法的应用体现了机器学习在数据分析中的价值,通过聚类分析揭示数据内在联系,为预测和决策提供依据。可视化技术的运用降低了用户的使用门槛,提升了系统的易用性。租房信息管理功能的实现则体现了对用户需求的关注,提高了工作效率。未来,该系统可进一步优化和扩展,引入更先进的算法、增强可视化效果、支持更多数据源,以适应不断发展的租房市场。
功能性需求
明确项目目标和需求,确定重点功能和特点要求。制定项目计划和时间表,包括开发、测试和上线时间的计划。确定技术选型,包括Hadoop、k-means算法、hive和Djnago、Vue等技术,以及相应的工具和平台[6]。
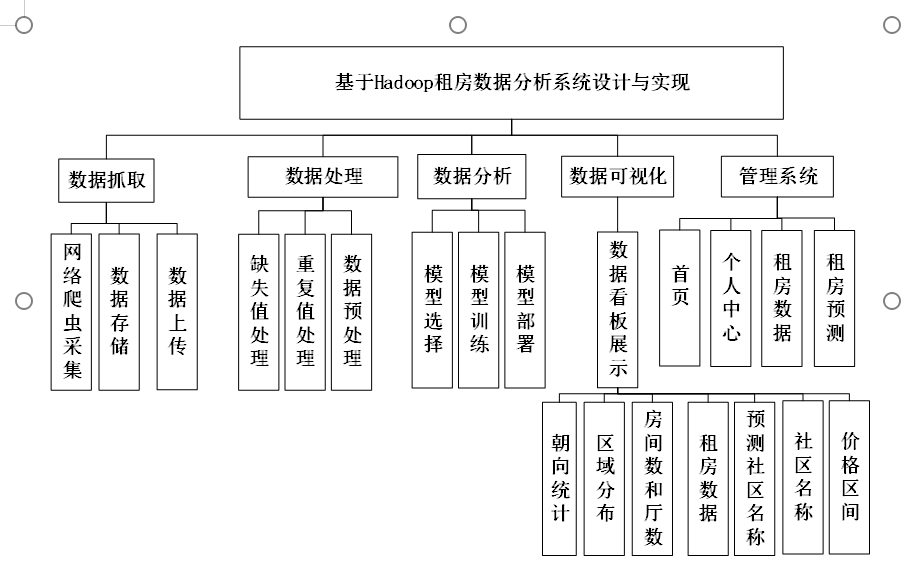
基于Hadoop的租房数据分析系统通过多个功能模块协同工作,实现对海量租房数据的采集、处理、分析和可视化展示。首先,数据抓取模块负责从网络爬虫采集数据并进行存储和上传;数据处理模块则对缺失值进行修复,去除重复数据,并对数据进行预处理以适应后续分析需求。
在数据分析阶段,系统采用模型选择、模型训练和模型部署等步骤来构建预测模型,从而为用户提供精准的租房价格预测服务。此外,数据可视化模块将分析结果以直观的形式展现出来,包括首页展示的数据看板以及个人中心中的各种图表和信息。
管理系统作为整个系统的核心组成部分之一,提供了丰富的管理功能,如租房数据管理和租房预测管理等。这些功能的实现使得系统能够高效地处理和分析大量租房数据,帮助用户更好地了解市场动态和趋势,做出更明智的决策。
用户管理
租房管理
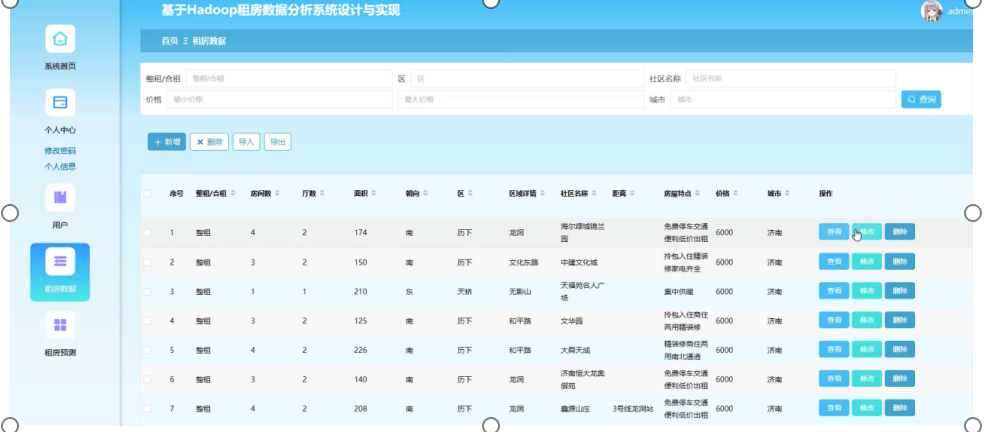
基于Hadoop的租房数据分析系统中的租房信息管理功能,通过一系列精细化的操作实现了增删改查以及导入导出功能,确保了数据的高效管理和灵活应用。系统利用Hadoop生态中的HBase数据库存储结构化租房数据,HBase提供了高效的随机读写能力,支持大规模数据的实时增删改查操作。
在数据增加方面,系统允许用户通过界面输入新的租房信息,这些信息经过验证后存储到HBase中。对于数据删除,系统支持按条件删除特定记录,例如根据房源ID或日期删除过期信息。数据修改功能使用户能够更新已有记录的错误或过时信息,保持数据的准确性。查询功能则允许用户根据各种条件组合检索所需信息,例如按价格区间、区域或朝向查询房源。
在数据导入方面,系统支持从CSV、JSON等常见数据格式批量导入数据到HBase中,利用Hadoop的MapReduce、Spark等计算框架进行分布式数据处理,确保导入过程的高效性。导出功能则允许用户将HBase中的数据导出为Excel、CSV等格式,便于数据共享和进一步分析

展示您要展示的活动信息
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)