
摆脱繁琐命令-让运维更加流畅-阿里云ECS操作系统控制台运维篇
CPU、内存、磁盘、网络,四个核心数据,可以综合所有服务共同查看,也可以分开单独查看,这样可以更好的对整体数据进行把控,服务对比的功能也非常的棒,同样的两个服务进行实际的消耗对比,可以看出两台服务器的示例消耗区别,本工具对于实施运维人员的帮助会非常大,可以尽快的来测试一下哦。
快速文档地址:点击快速访问官方帮助文档
操作系统控制台地址:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台

引言
运维与实施过程中最麻烦的不是时时看着服务器的运行状态,而是每天晚上的日报,每周的周报,还有月报,我带的毕业生们有很多学生是做运维与实施工作的,自己的脚本也都比较全,有了新的好用的脚本我也会分享给学生们,不过这些东西在工作的时候好用,写日报的时候全部服务都连接再查询一下就会非常的麻烦了,有了阿里的操作系统控制台这个服务就大大的方便了数据的监控与汇总,写这类东西就会方便很多,给平时的工作也带来了很多的遍历。

使用与感受
下面是我整个的测试使用过程与最终的使用感受。
1、所遇问题说明
痛点说明
我这里有华北2的四台服务器,好几类服务,如果是使用命令来挨个查询健康状态的话就需要逐一的进行远程连接或者xShell连接后再执行命令,远程连接现在有了一个AI命令助手到时很方便,可以直接询问命令,但是长时间用的命令很熟悉,就是运行的过程比较麻烦。
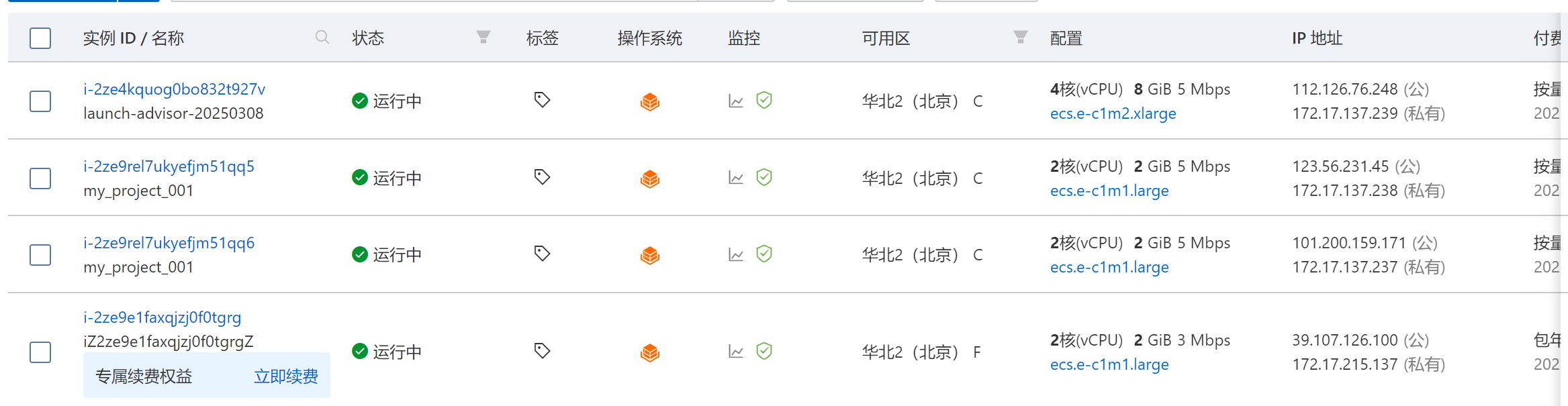
痛点解决
正好操作系统控制台就解决了这个问题,可以将服务器都添加到系统控制台的监控当中。
2、实际操作
这里是整个实际操作的部分。
2.1 添加系统监控管理
我们需要先将需要监控的服务都防止在操作系统控制台的纳管范围内,下图是操作步骤1。

需要点击安装SysOM将未纳管的服务添加到纳管范围,下图是操作步骤2。

安装过程中需要稍事等待,具体效果如下图:

执行安装成功效果:

添加成功效果:
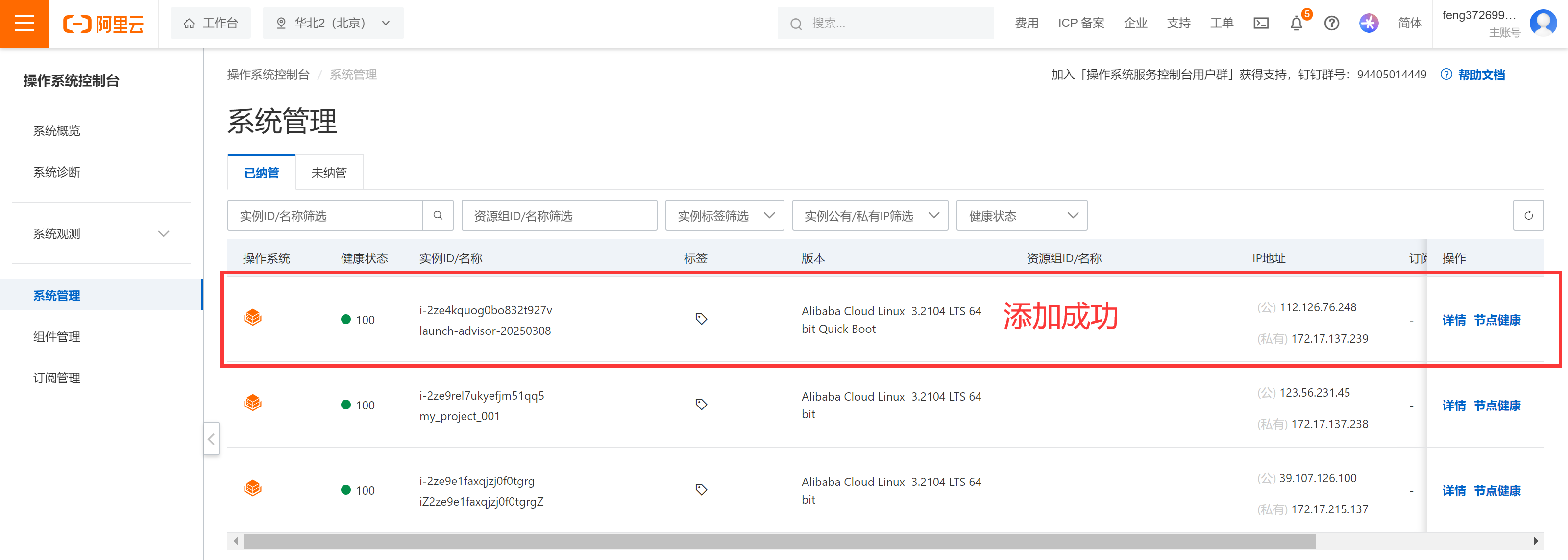
我们可以看到已经将对应的服务器添加到纳管范围内了,这里需要明确一点,当前支持的系统在官方文档中有说明:
本功能目前仅支持中国内地与中国香港。
| 架构 | 操作系统 |
|---|---|
| x86架构 | Alibaba Cloud Linux 2/3CentOS 7.6及以上版本Anolis OS 8.4以上版本 |
| ARM架构 | Alibaba Cloud Linux 3 |
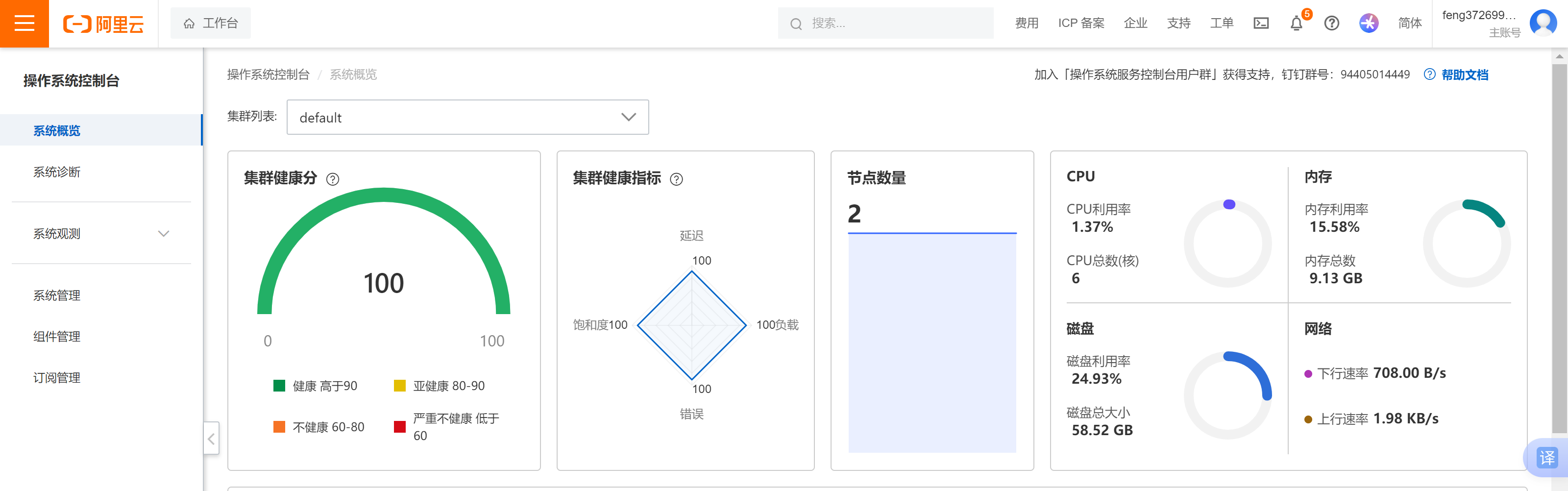
当前集群中关键资源的使用情况:
CPU:集群CPU使用情况。
内存:集群内存使用情况。
磁盘:集群根文件系统使用情况。
网络:集群中所有网络上行及下行速率之和。

2.2 大文件健康状态测试
这里我写了一套增加文件的代码,可以每分钟添加1GB数据,用于磁盘测试。
import os
import time
from datetime import datetime
def create_file(size_mb, file_number):
# 计算文件大小(1GB = 1024*1024*1024 bytes)
size_bytes = size_mb * 1024 * 1024 * 1024
# 生成当前时间戳
timestamp = datetime.now().strftime("%H%M%S")
# 创建文件名
filename = f"test_file_{timestamp}_{file_number}.dat"
try:
# 写入文件
with open(filename, 'wb') as f:
# 每次写入1GB数据
mb_data = b'0' * 1024 * 1024 * 1024
mb_written = 0
while mb_written < size_mb:
f.write(mb_data)
mb_written += 1
print(f"已创建文件: {filename} ({size_mb}GB)")
except Exception as e:
print(f"创建文件时出错: {e}")
def main():
# 设置参数
files_per_minute = 1 # 每分钟创建的文件数
file_size = 50 # 每个文件大小(GB)
total_minutes = 5 # 总运行时间(分钟)
print("开始创建文件...")
# 记录开始时间
start_time = time.time()
file_count = 0
# 主循环
while (time.time() - start_time) < (total_minutes * 60):
# 创建文件
create_file(file_size, file_count)
file_count += 1
# 计算已运行时间
elapsed_minutes = (time.time() - start_time) / 60
print(f"已运行: {elapsed_minutes:.1f}分钟")
# 等待到下一分钟
time.sleep(60 / files_per_minute)
print(f"\n程序结束")
print(f"总共创建了 {file_count} 个文件")
print(f"总数据量: {file_count * file_size}GB")
if __name__ == "__main__":
main()当单独查询这个服务器健康状态的时候,可以清晰的看到对应的效果:

多个节点可以看到集群的数据变化:
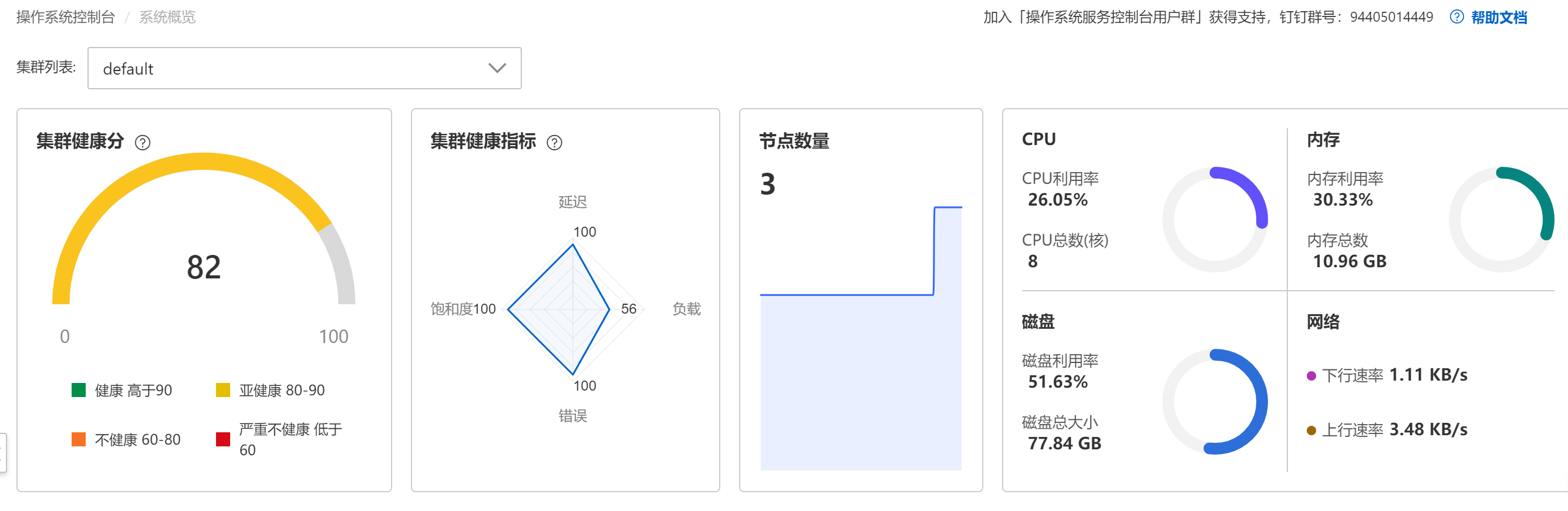
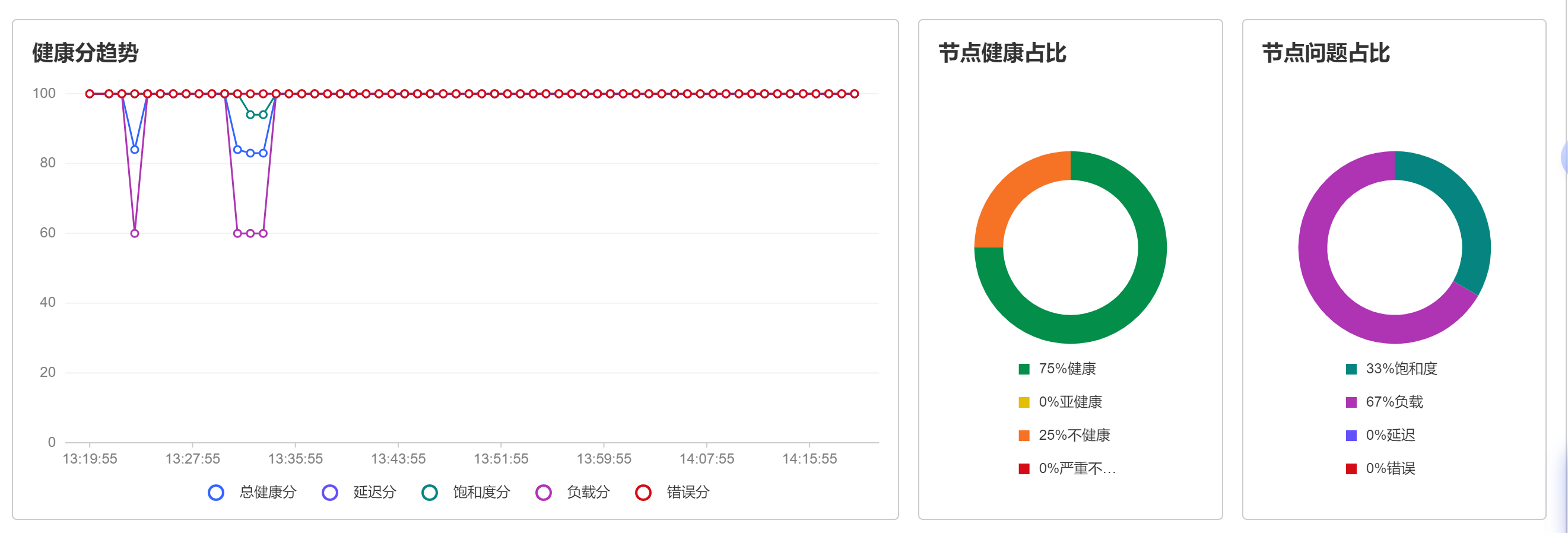
健康趋势分析图
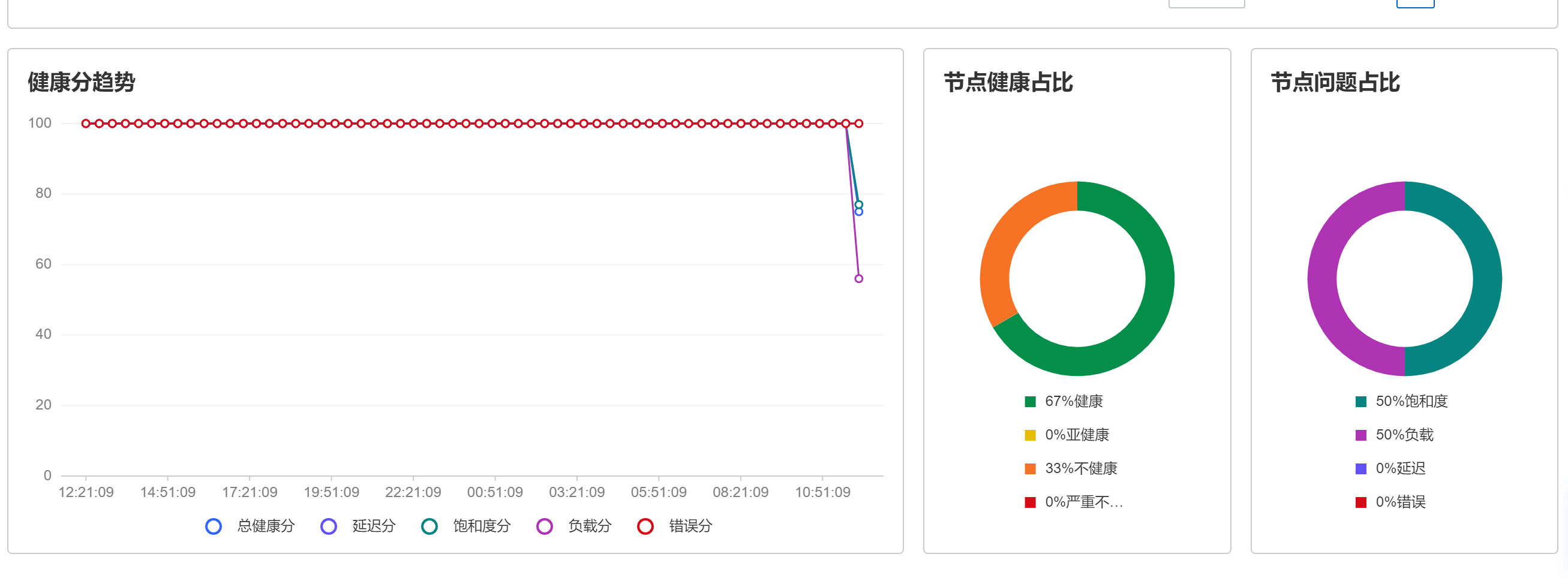
测试文件数据,看着还是很大的,我这里创建很多50MB的数据和一个大的14.99GB的。

删除后的健康值效果:

健康分析趋势持续变化过程:
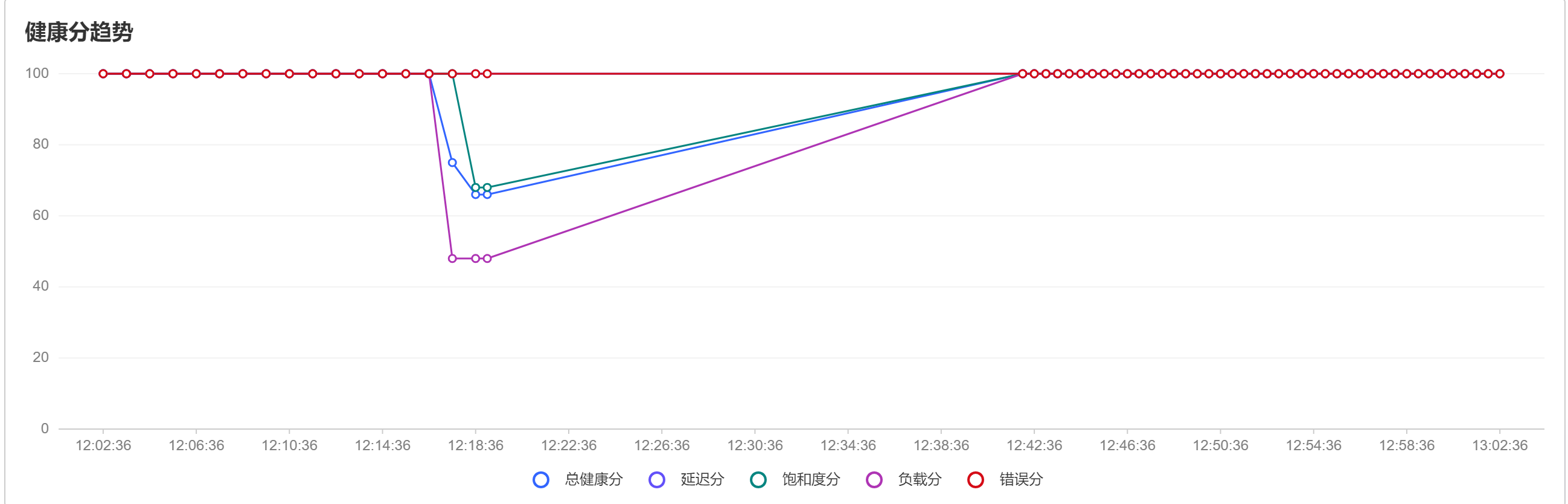
2.3 网络测试
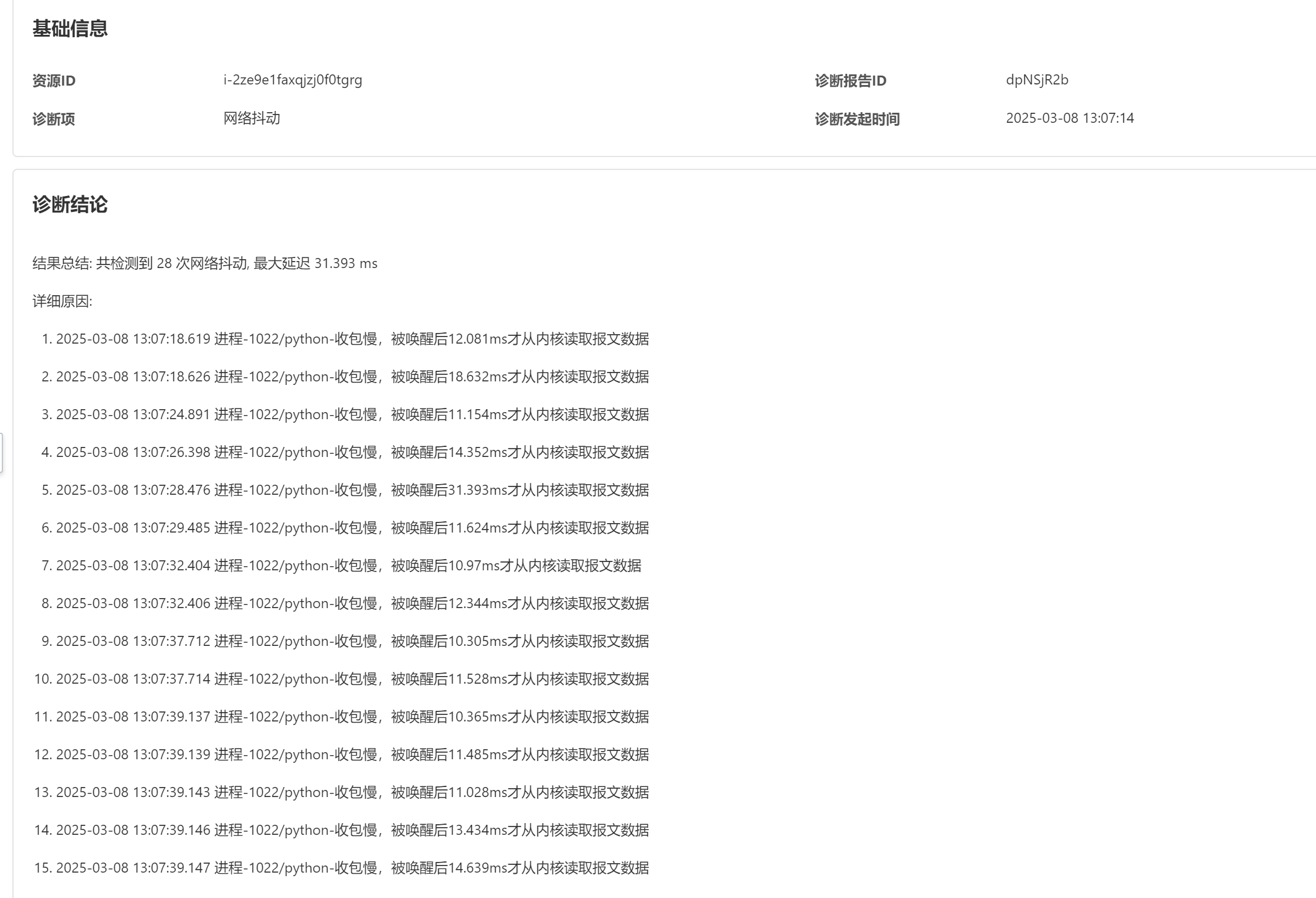
这里我测试的是网络抖动,当我对某个接口进行并发访问的时候可以看到对应的返回结果。

我这里使用的是jmter来做的并发访问:
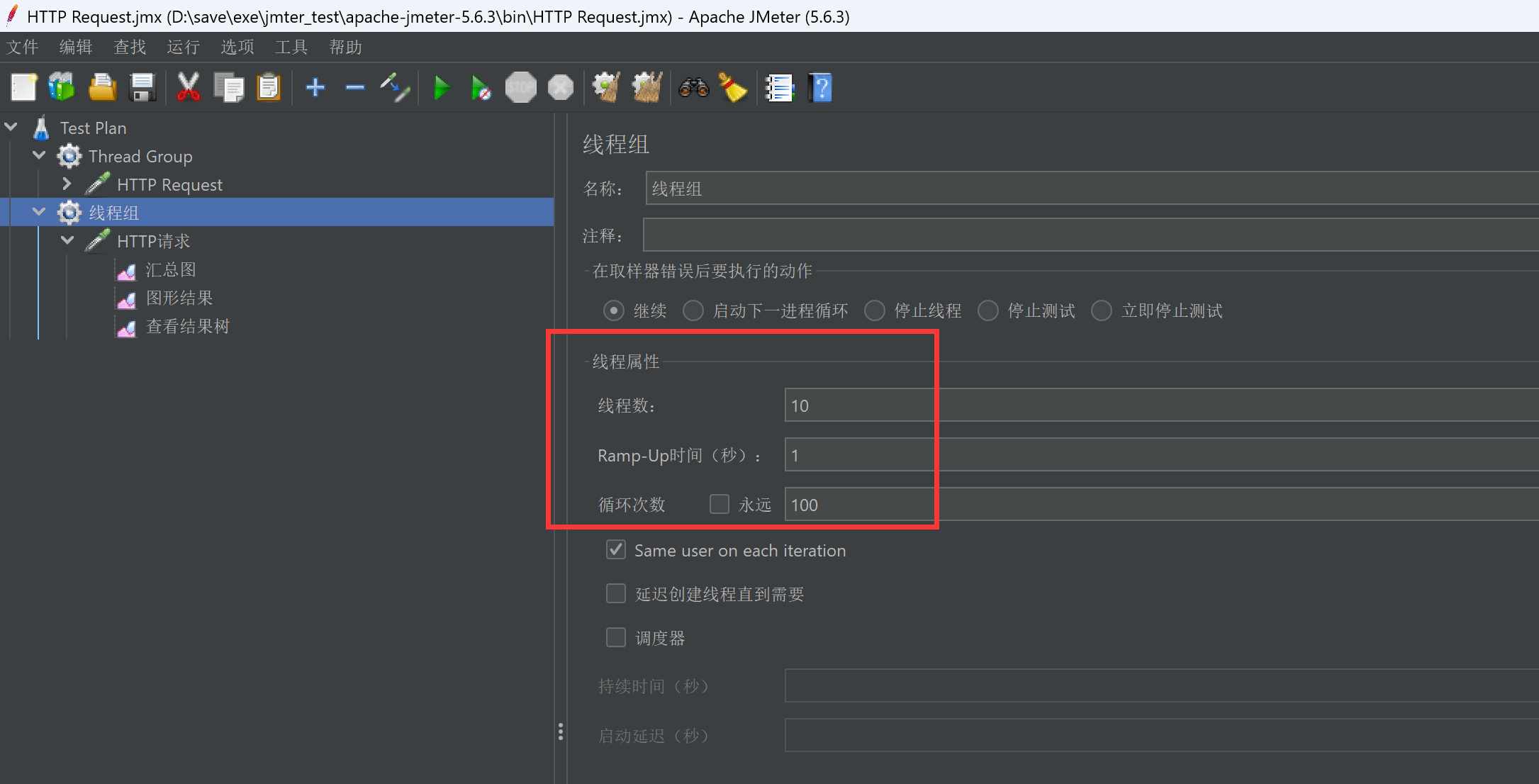
请求的汇总图:
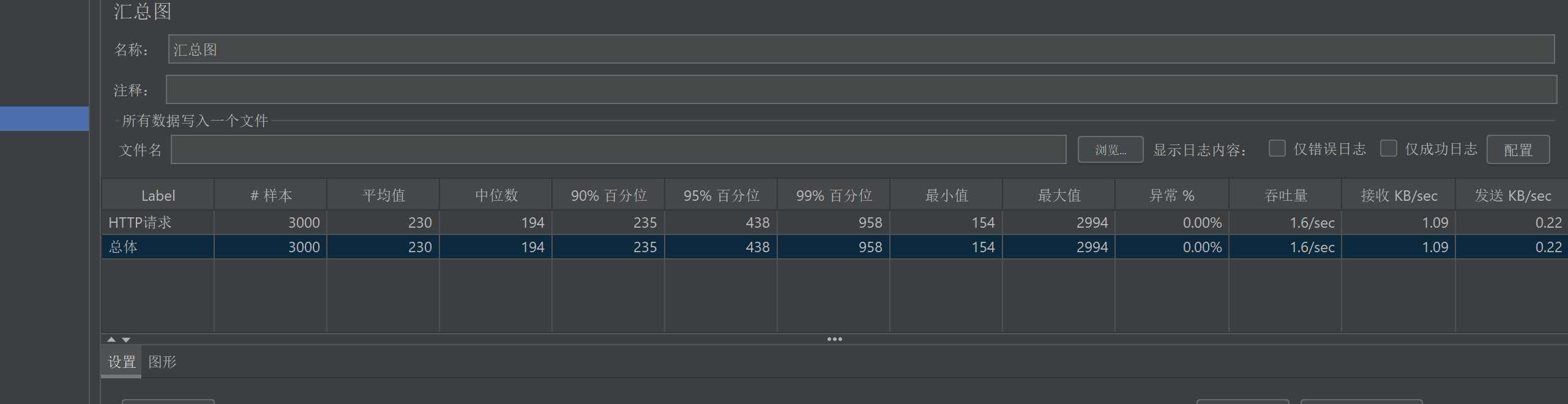
报告详情:
3、使用感受
整体的测试使用下来觉得还是非常的顺畅的,解决了每台服务器都要单独查看状态的繁杂重复性操作,可以快速的给出数据,让运维与实施的时间大幅简短,并且可以在日报、周报、月报中做数据支撑,是非常不错的,如果能在刷新的时间上加上自主性控制就更好了。
总结
CPU、内存、磁盘、网络,四个核心数据,可以综合所有服务共同查看,也可以分开单独查看,这样可以更好的对整体数据进行把控,服务对比的功能也非常的棒,同样的两个服务进行实际的消耗对比,可以看出两台服务器的示例消耗区别,本工具对于实施运维人员的帮助会非常大,可以尽快的来测试一下哦。
另附: OS Copilot实际测评地址:os-copilot安装与多项功能测评-阿里云开发者社区
更多推荐



 43
43 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)