
GPT-5.4深夜发布,正中Claude要害!
OpenAI发布GPT-5.4,专为专业工作负载打造,在编程、知识工作和计算机操作方面表现突出。该模型具备1MToken长上下文支持,原生计算机操作能力,在GDPval测试中83%案例优于前代。新增工具搜索功能降低47%Token消耗,联网搜索能力提升17%。GPT-5.4Pro版本针对复杂任务提供极致性能,在BrowseComp基准达89.3%新高。CEO奥特曼称赞其个性化和专业能力提升,标志着
GPT-5.4
为专业工作而打造
三月五日
OpenAI在 ChatGPT(以 GPT‑5.4 Thinking 模式)、API 及 Codex 中发布 GPT‑5.4。
它是目前针对专业化工作负载能力最强、效率最高的前沿模型。同时OpenAI在 ChatGPT 及 API 中发布 GPT‑5.4 Pro,该模型专为在复杂任务中追求极致性能的用户而设计。

在 Gemini 与 Claude 接连占优的一个月之后,OpenAI 终于推出重大更新进行回应。

OpenAI的首席执行官奥特曼深夜发推:
“GPT-5.4 在编程、知识工作、计算机使用等方面表现出色,看到大家如此喜欢它,我感到非常欣慰。但它也是我最喜欢与之交流的模型!我们之前在模型个性方面一直做得不够好,所以现在朝着正确的方向前进,感觉格外令人高兴。”

GPT-5.4 的革命性功能与特点
01
原生操作计算机
在 Codex 与 API 中,GPT‑5.4 是OpenAI发布的第一个具备原生且顶尖计算机使用能力的通用模型,让智能体能够操作计算机,并跨应用程序执行复杂的工作流程。
该模型支持高达 1M Token 的上下文,允许智能体在长周期内进行任务规划、执行与验证。
此外,GPT‑5.4 通过工具搜索功能优化了模型在庞大的工具与连接器生态中的运作方式,帮助智能体在不牺牲智能的前提下,更高效地发现并使用正确工具。

GPT‑5.4 在通用推理、编程和专业知识工作方面都有全面提升,因此能支持更可靠的智能体、更高效的开发流程,并在 ChatGPT、API 和 Codex 中带来更高质量的输出
02
知识型工作
基于 GPT‑5.2 的通用推理能力,GPT‑5.4 在专业人士关注的实际任务中,能够提供更加稳定且精炼的输出。
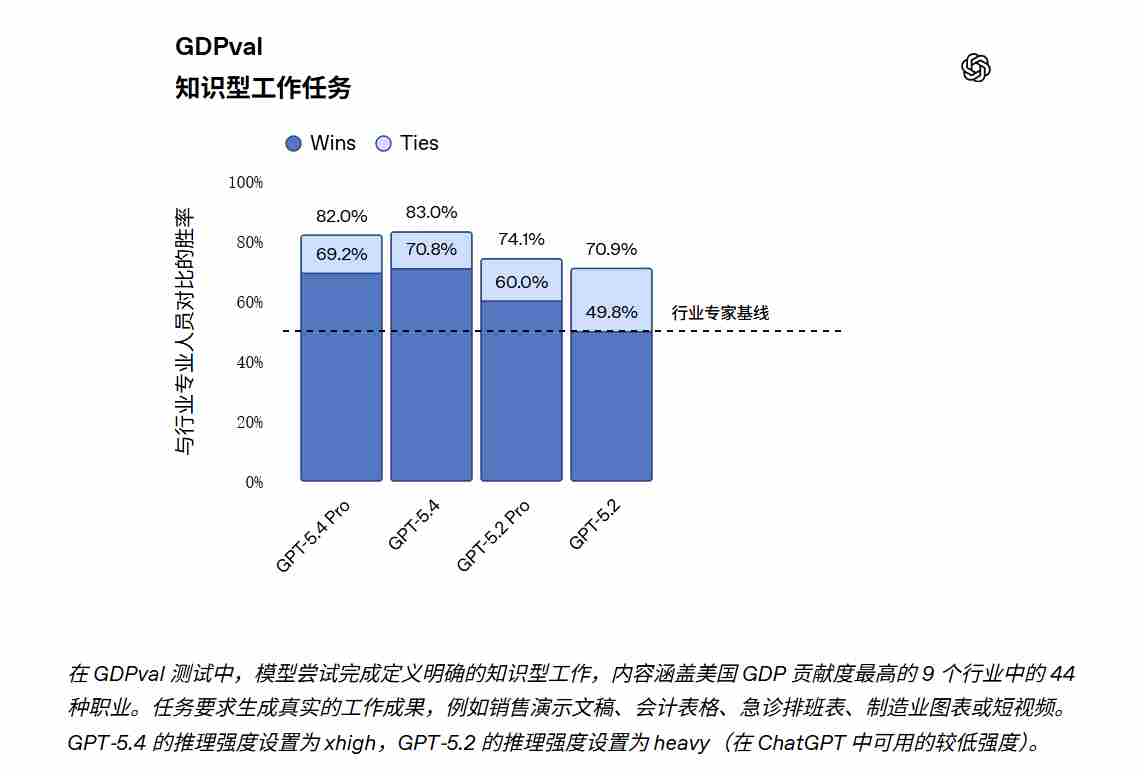
在 GDPval(一项评估智能体在 44 个职业中产出明确知识工作能力的测试)中,GPT‑5.4 刷新纪录。在与行业专业人士的横向评测中,GPT‑5.4 在 83.0% 的案例里达到了持平或更优的水准(GPT‑5.2 为 71.0%)。
03
计算机使用与视觉
GPT-5.4 是 OpenAI 首款原生支持“计算机使用”能力的通用模型,标志着智能体开发迈出关键一步。对于构建跨网页与软件执行任务的智能体,它目前是最佳选择。
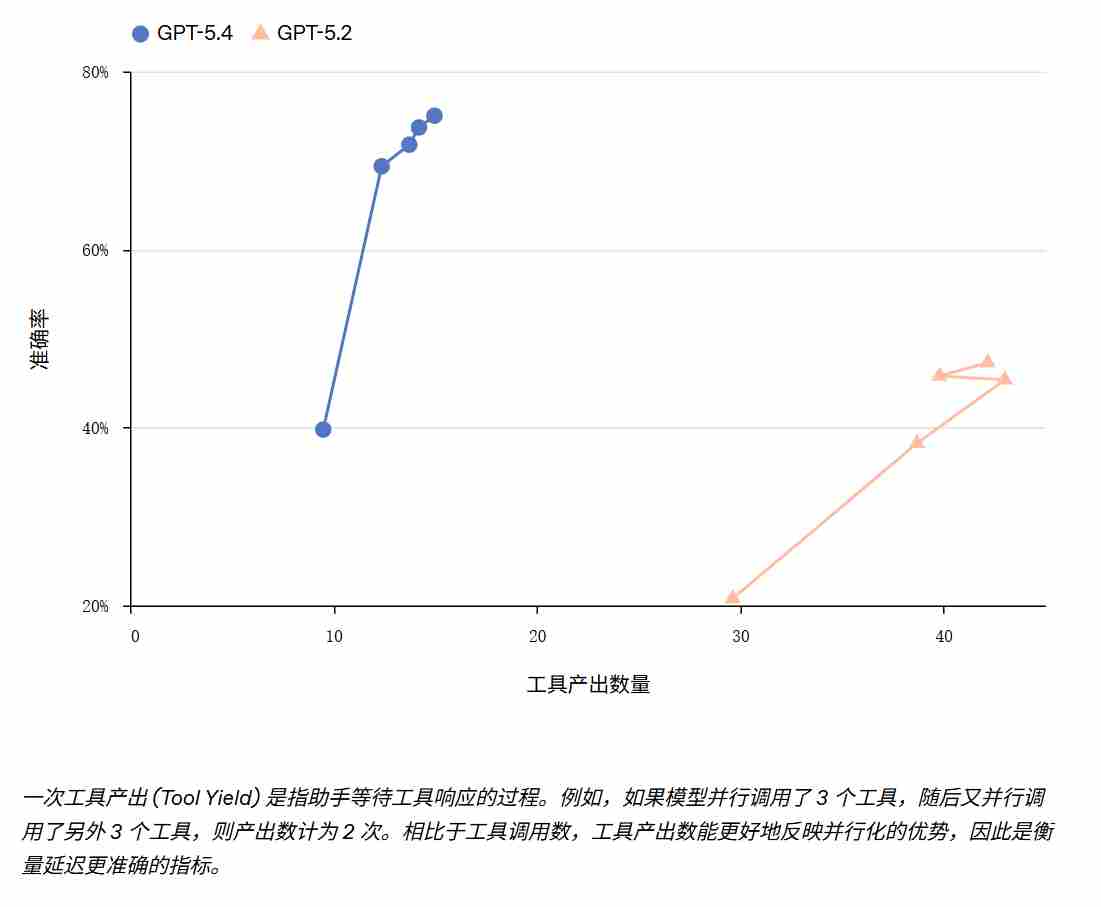
模型专为各种计算机操作负载优化:既能通过 Playwright 等库编写控制代码,也可直接基于屏幕截图发出鼠标/键盘指令。开发者可通过“开发者消息”灵活引导行为,并根据风险偏好自定义确认策略来调节安全级别。
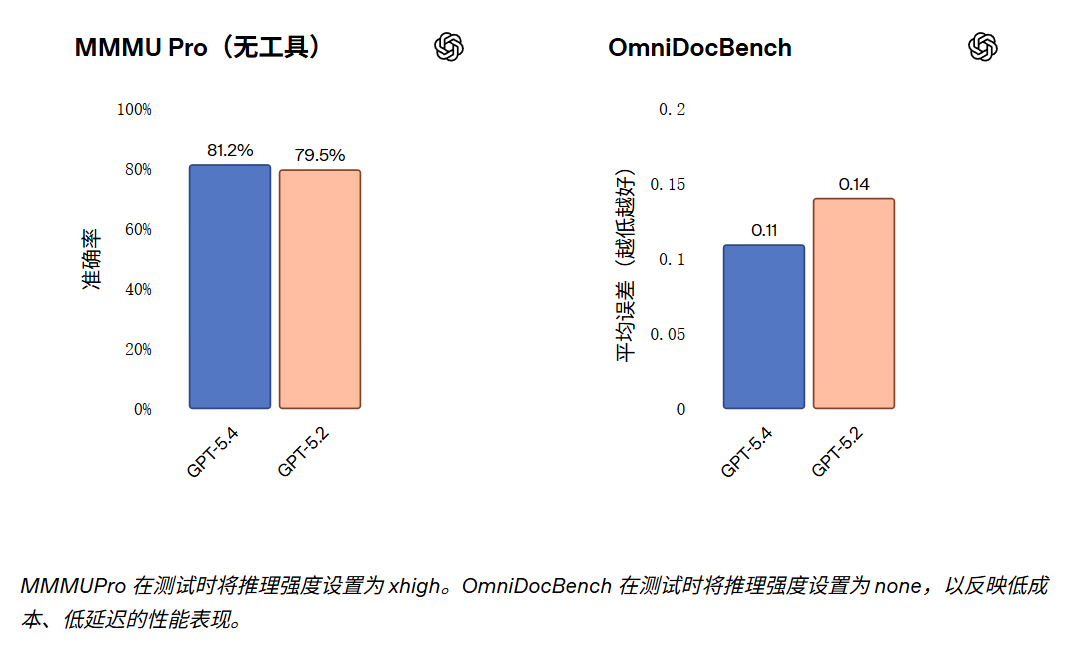
GPT‑5.4 在“计算机使用”方面的提升,源于模型更强的通用视觉感知能力。在评估视觉理解与推理能力的 MMMU-Pro 测试中,GPT‑5.4 在不使用工具的情况下达到了 81.2% 的成功率(GPT‑5.2 为 79.5%);值得注意的是,GPT‑5.4 仅需极少的思考 Token 便在该基准测试中超越了 GPT‑5.2 的表现。此外,视觉感知的提升也转化为更强的文档解析能力:在 OmniDocBench 测试中,GPT‑5.4 的平均误差(通过模型预测值与标准答案之间的归一化编辑距离衡量)降至 0.109,较 GPT‑5.2 的 0.140 有显著提升。
03
Vibe Coding
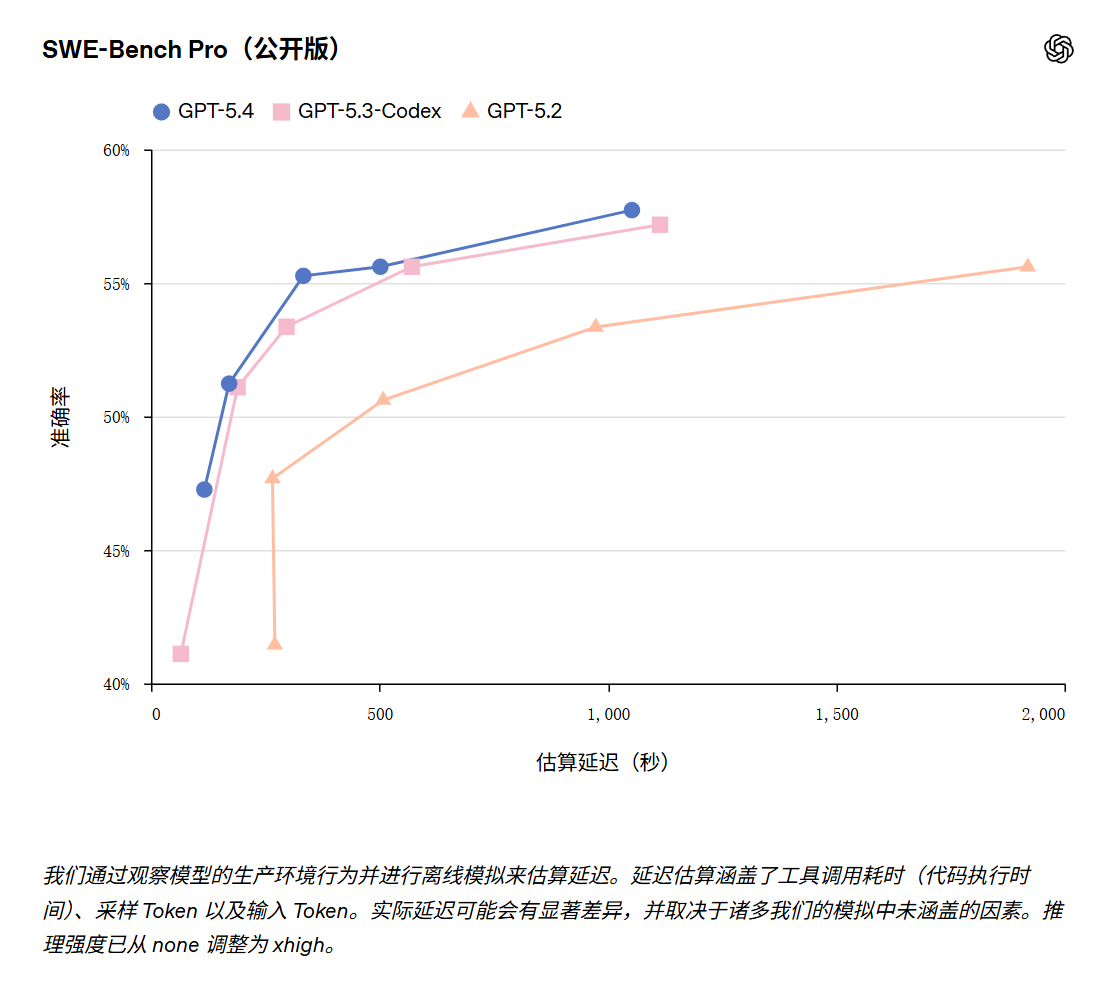
GPT‑5.4 结合了 GPT‑5.3‑Codex 的编程优势,以及领先的知识型工作与“计算机使用”能力。这对于长时间运行的任务至关重要。在这些任务中,模型可以自主使用工具、进行迭代并推进工作,从而减少人工干预。在 SWE-Bench Pro 测试中,GPT‑5.4 的表现超越了 GPT‑5.3‑Codex 或与其持平,同时在各项推理任务中拥有更低的延迟。
开启 Codex 的 /fast 模式后,所有兼容模型(含 GPT-5.4)都能实现速度提升。模型智能和输出质量保持不变,只是响应更快。这让开发者在写代码、反复修改、调试问题时,能更流畅地保持专注和节奏。通过 API 的优先处理服务,开发者同样能享受到这种高速体验。
在实际测试和评估中,GPT-5.4 特别擅长处理那些视觉要求高、复杂度大的前端任务。相比之前发布的任何模型,它生成的界面在美观度和实用性上都有明显进步。
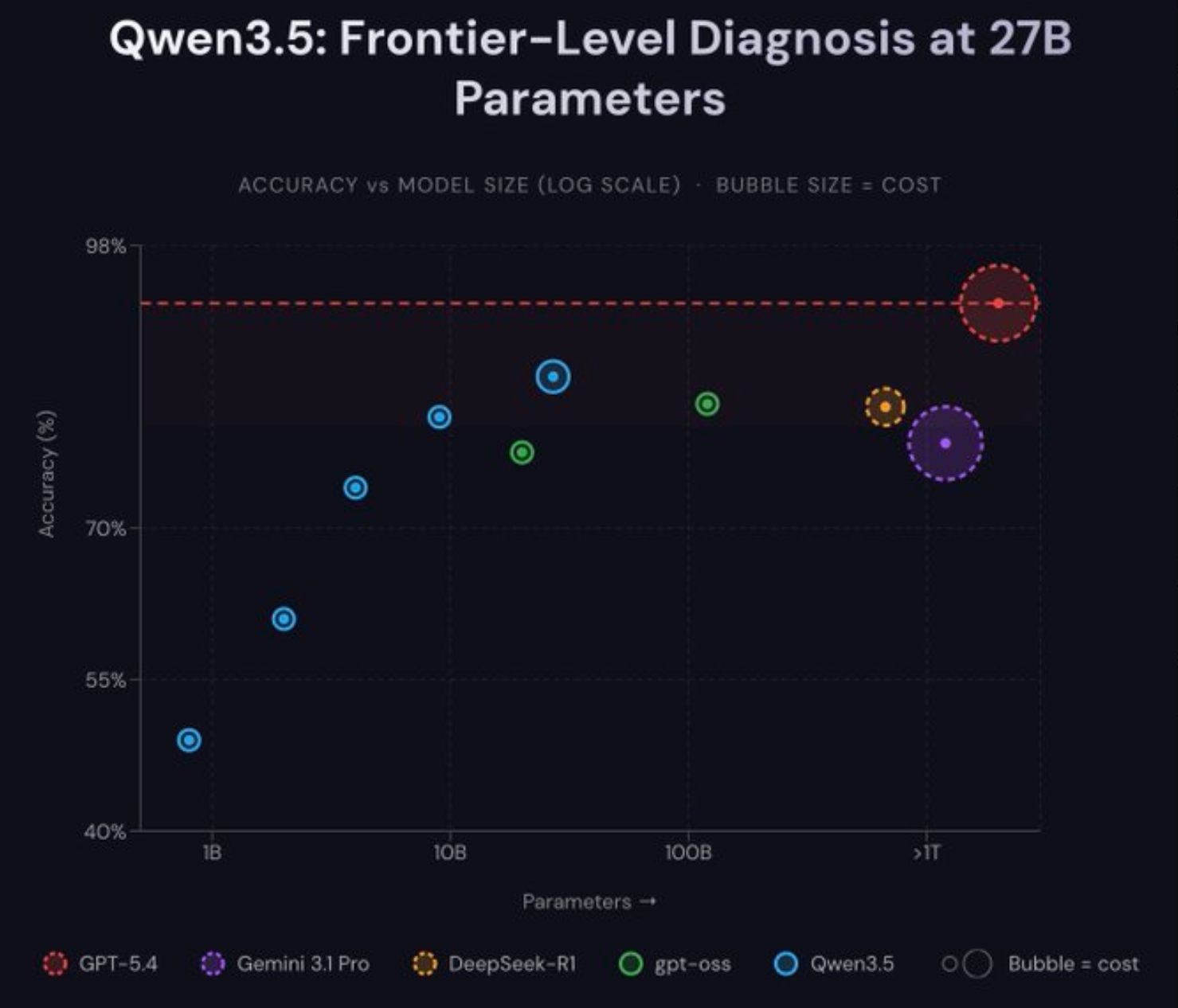
GPT-5.4准确性位居第一名
为了直观展示“计算机使用”与编程能力的融合升级,OpenAI还推出了一项实验性 Codex 技能——“Playwright (Interactive)”。它支持对网页和 Electron 应用进行可视化调试,甚至能在开发过程中同步运行实时测试,帮助快速验证和迭代.
04
工具调用
GPT-5.4 在 API 中引入了 工具搜索(tool search)功能,让模型在面对海量工具时仍能高效运行。
以往,调用工具时必须把所有工具定义一次性塞进提示词里。如果工具生态庞大(比如数千个函数或 MCP 服务器),每次请求都会额外消耗数千甚至数万 Token,不仅成本飙升、响应变慢,还让上下文塞满大量无关信息。
现在,GPT-5.4 改为接收一份精简的可用工具列表 + 工具搜索能力。模型需要某个工具时,会即时查找并加载其完整定义到当前对话中。这种按需加载方式大幅削减了 Token 消耗,保留了缓存效果,让请求更快、更便宜。同时,它让智能体能更可靠地驾驭超大规模工具生态,尤其对那些单个工具定义就占数万 Token 的 MCP 服务器,效率提升特别明显。
实际效果上,OpenAI 在 Scale 的 MCP Atlas 基准中测试了 250 个任务(启用全部 36 个 MCP 服务器):对比直接把所有函数暴露在上下文 vs. 全放工具搜索后面两种模式,结果在准确率相同的前提下,工具搜索模式将总 Token 用量降低了 47%。
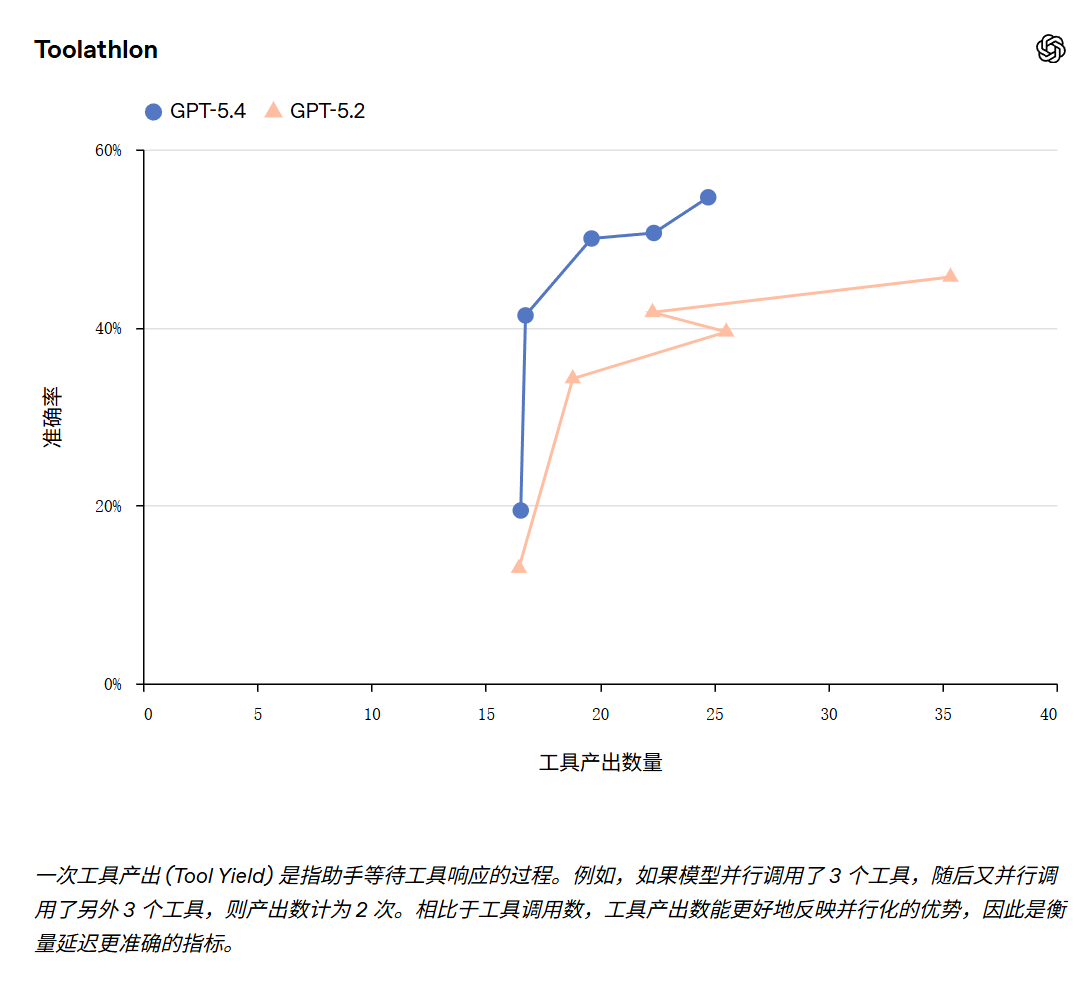
相比 GPT‑5.2,它在 Toolathlon 基准测试中能以更少的轮次达到更高的准确率。该测试旨在评估 AI 智能体利用真实世界工具和 API 完成多步任务的能力 — 例如,智能体需要读取邮件、提取作业附件、上传并评分,最后将结果记录到电子表格中。
针对那些对延迟极度敏感、且倾向于将推理强度设为“无 (None)”的使用场景,GPT‑5.4 相比前代产品有显著提升。
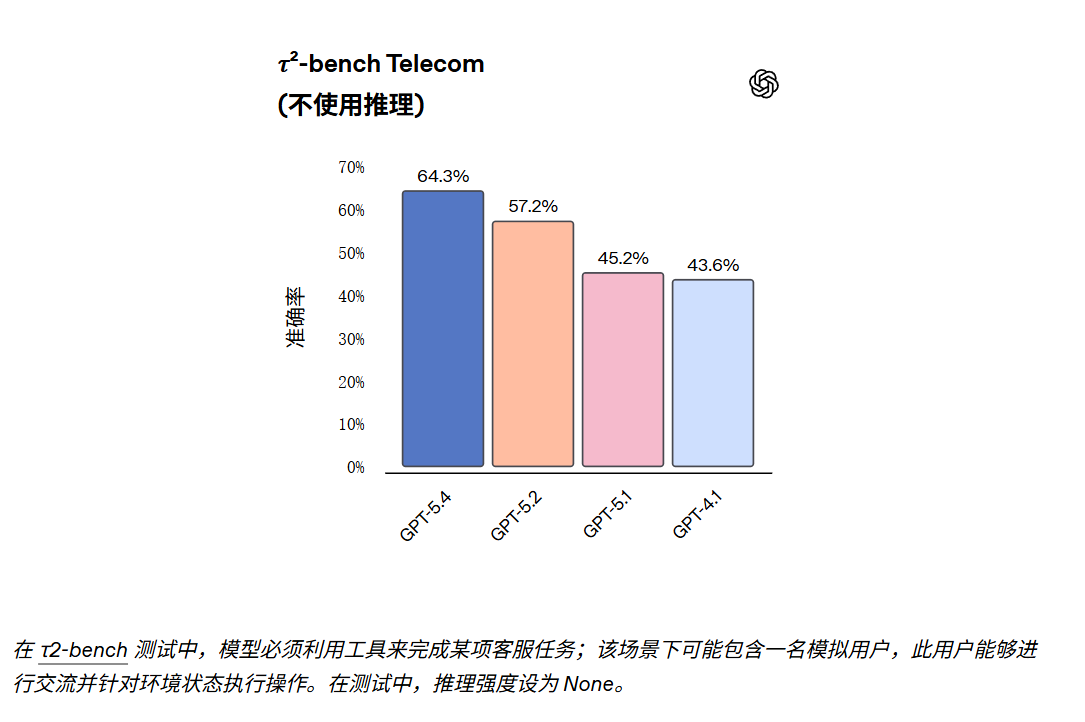
05
更强大的联网搜索能力
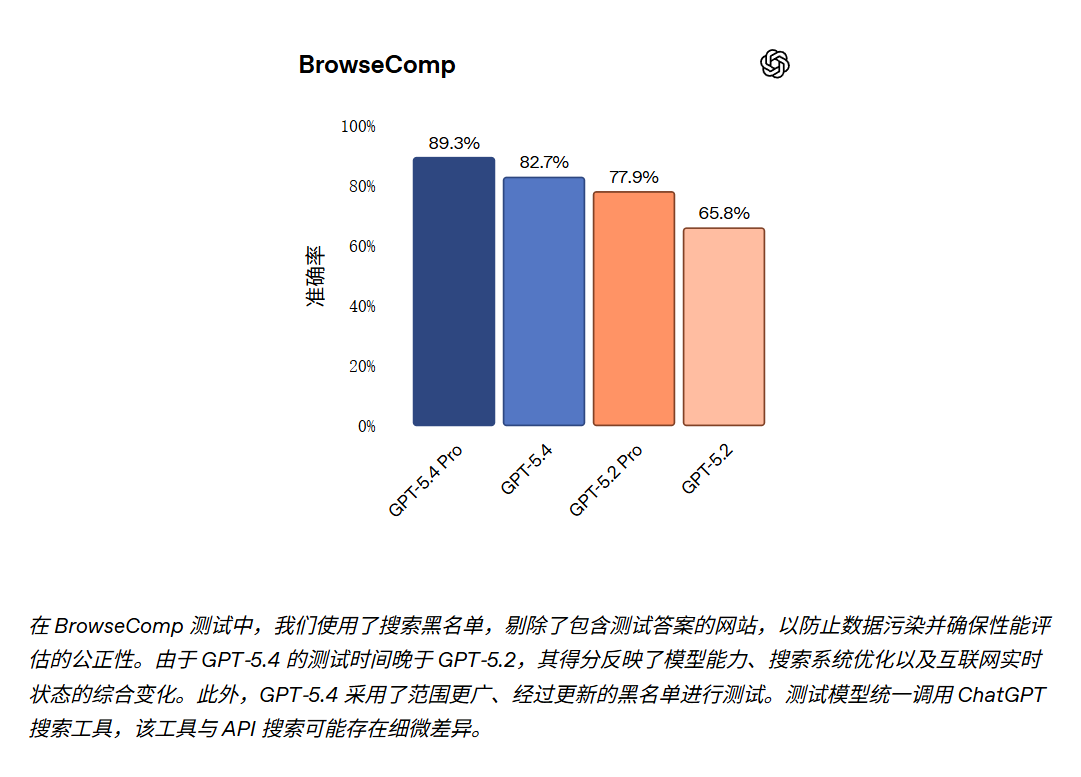
GPT-5.4 在智能体联网搜索(agentic web search)能力上显著领先。在 BrowseComp 基准(专门评估 AI 智能体通过多轮持久浏览网页、挖掘难找信息的表现)中,GPT-5.4 比 GPT-5.2 提升了 17 个百分点,达到 82.7%;而 GPT-5.4 Pro 更创下 89.3% 的新纪录,成为当前最强。
这在实际场景中意味着:GPT-5.4 Thinking(ChatGPT 中的高性能版本)处理需要跨全网多源整合的复杂问题时更可靠。它能坚持多轮搜索,逐步锁定最精准的信源,尤其擅长“大海捞针”式的查询——高效过滤噪声、提炼核心事实,并输出逻辑严谨、证据充分的答案。
GPT-5.4 实际应用案例
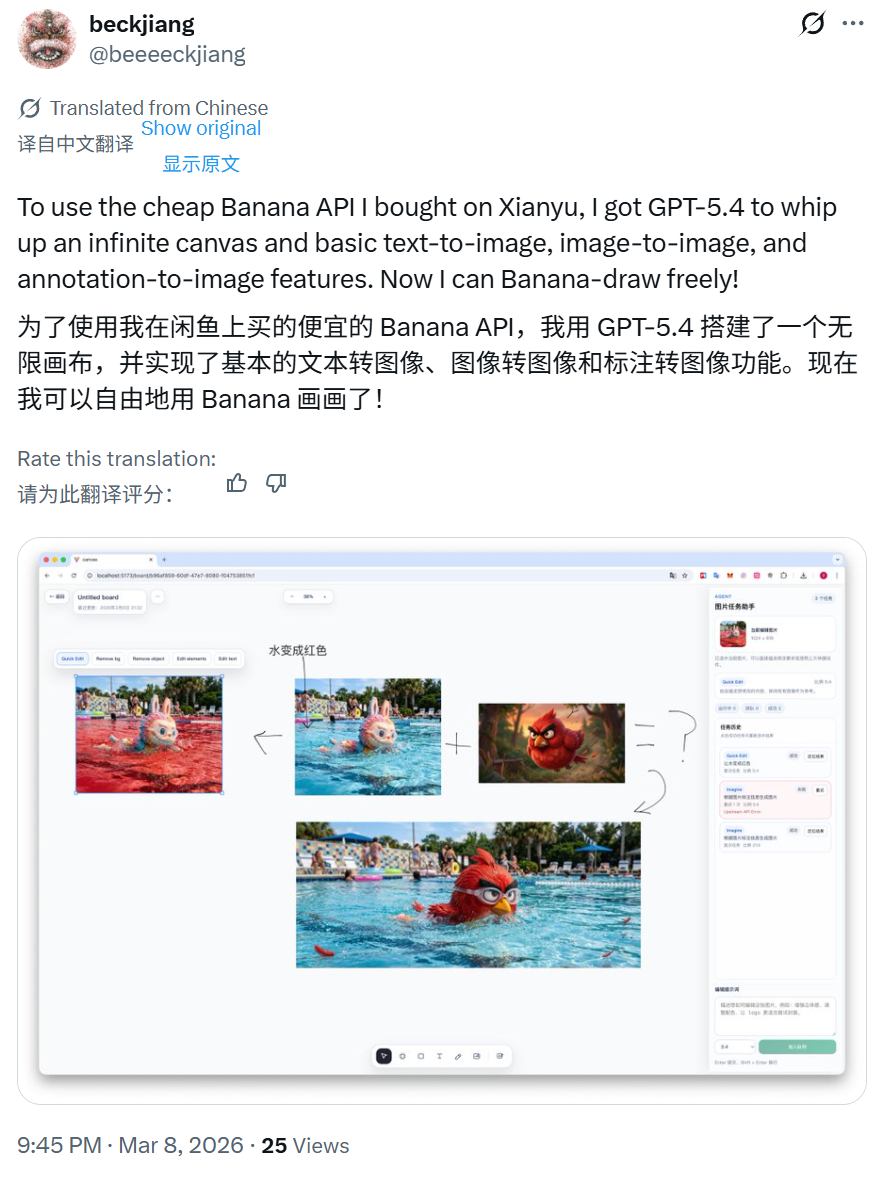
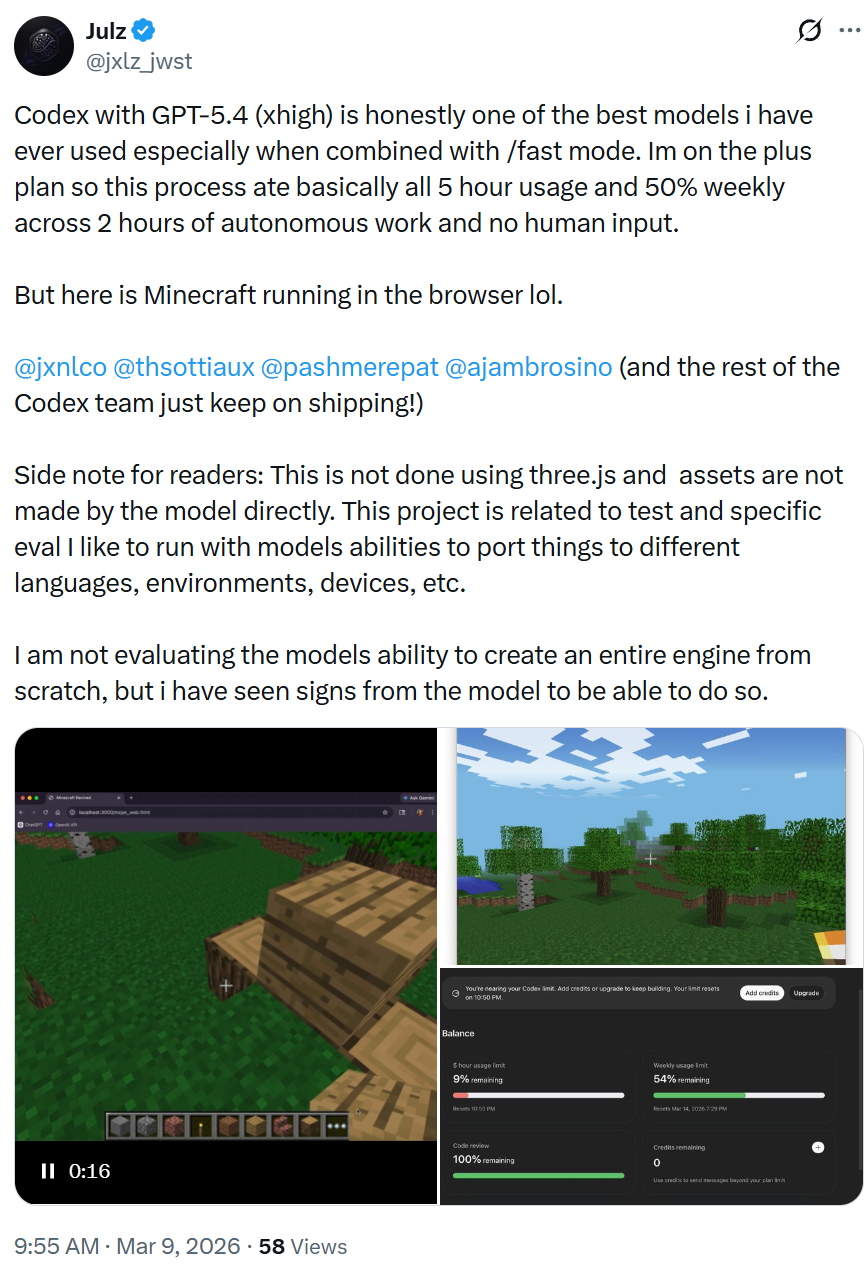
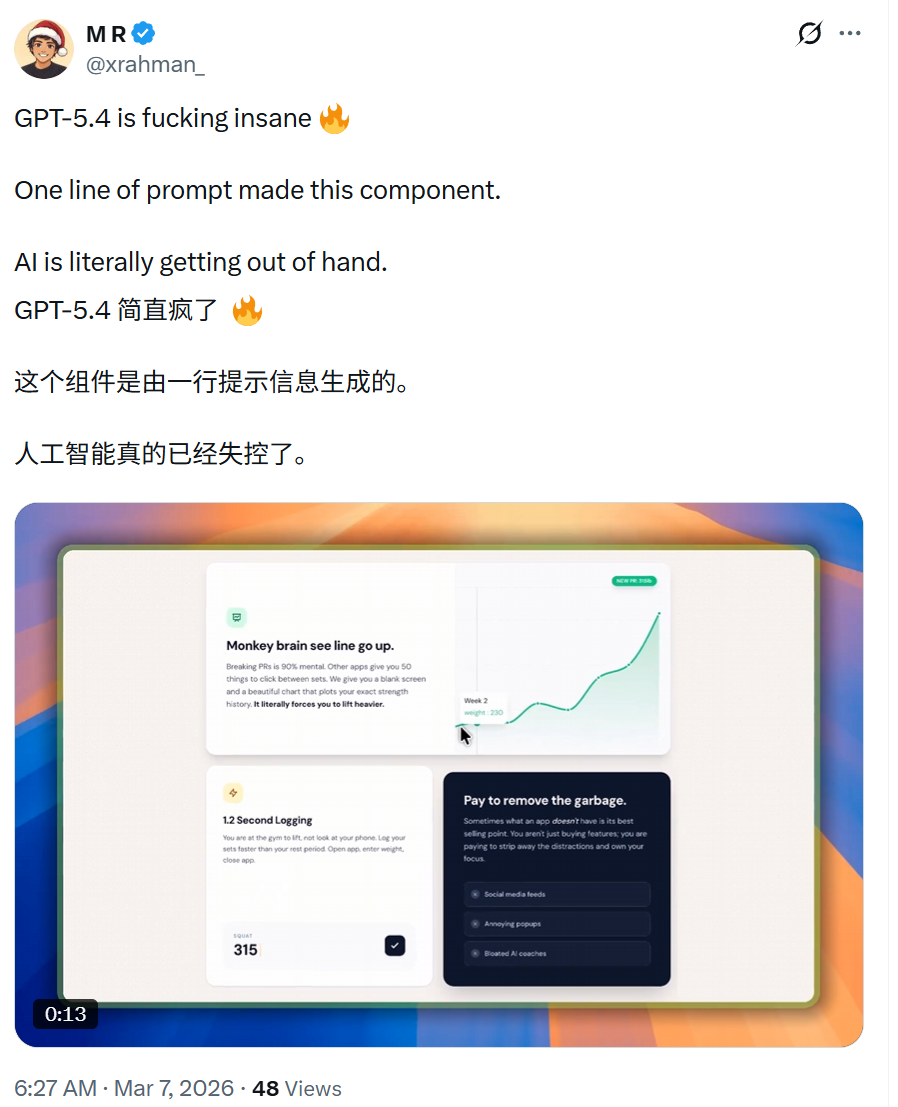
最后,我们想问问大家你最想用 GPT-5.4 创造什么?赶紧用Vibe Coding创作你自己的代码吧!


中科创新烁智(CSCITech)
更多推荐



 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)